大模型解密之--多模态常见架构与模态对齐方法
对于不同模态的数据,先使用特定模型进行编码 然后使用交叉注意力模块将不同模态的数据映射到一个空间中,然后再使用transformer进行计算PCME的核心思想是将不同模态的数据表示为概率分布,通过均值和方差来捕捉数据的不确定性和多样性。通过局部注意力机制和特定的损失函数,PCME能够有效地处理图像和文本之间的一对多对应关系,并提供更可解释的嵌入表示。
不同模态数据对齐常见架构
Perceiver架构
架构简要描述:
-
对于多模态数据,先使用模态特定的编码器对每个模态的数据进行编码,
-
通过交叉注意力模块将不同模态的特征映射到一个统一的潜在空间中,
-
在潜在空间中使用Transformer进行深度处理。
这种处理流程不仅能够有效地融合不同模态的数据,还能捕捉它们之间的内在关系,为多模态任务(如跨模态检索、多模态生成等)提供了强大的支持
1.多模态数据的处理流程
对于多模态数据,处理流程通常包括以下几个步骤:
1.1 模态特定的编码
输入数据:不同模态的数据(如图像、音频、文本等)首先被输入到模型中。 模态特定的编码器:每个模态的数据通过一个专门为其设计的编码器进行处理。这些编码器通常是针对该模态的特征提取网络,例如: 图像:使用卷积神经网络(CNN)提取图像特征。 音频:使用一维卷积网络或循环神经网络(RNN)提取音频特征。 文本:使用Transformer或RNN提取文本特征。 这些编码器将高维的原始数据转换为低维的特征表示。
1.2 特征融合
交叉注意力模块:将不同模态的特征表示通过交叉注意力模块进行融合。交叉注意力模块的作用是将不同模态的特征映射到一个统一的特征空间中,同时捕捉不同模态之间的关系。 统一特征空间:通过交叉注意力模块,不同模态的特征被编码到一个低维的潜在空间(latent space)中。这个潜在空间是模型的“通用语言”,不同模态的数据在这个空间中可以进行交互和比较。
1.3 深度处理
Transformer tower:在统一的潜在空间中,使用Transformer架构对特征进行深度处理。Transformer通过自注意力机制捕捉特征之间的全局依赖关系,进一步优化特征表示。 迭代处理:Perceiver架构通过多次迭代(交替使用交叉注意力模块和Transformer塔)逐步完善特征表示,使得模型能够更好地捕捉不同模态之间的复杂关系。
1.4 解码与输出
模态特定的解码器:从统一的潜在空间中解码出每个模态的重建数据。每个模态的解码器负责将低维的特征表示还原为原始数据。 重建损失:通过最小化输入数据和重建数据之间的差异来训练模型,确保模型能够准确地重建每个模态的数据。
2.Perceiver架构的核心机制
Perceiver架构的核心机制可以总结为以下几点:
2.1 交叉注意力模块
输入映射:将不同模态的特征通过交叉注意力模块映射到一个低维的潜在空间中。 复杂度优化:通过引入潜在数组(latent array),将全连接注意力的复杂度从 O(M 2) 降低到 O(MN), 其中 M 是输入数据的维度,N 是潜在数组的维度。
2.2 Transformer tower
深度处理:在潜在空间中使用Transformer架构对特征进行深度处理,捕捉全局依赖关系。 迭代优化:通过多次迭代(交替使用交叉注意力模块和Transformer塔),逐步完善特征表示。
2.3 统一特征空间
多模态融合:通过交叉注意力模块和Transformer塔,将不同模态的数据融合到一个统一的特征空间中,使得不同模态的数据可以进行交互和比较。 灵活性:Perceiver架构能够处理多种模态的数据,无需为每种模态设计特定的模型。
注:交叉注意力模块的作用 交叉注意力模块的作用不仅仅是将特征的维度统一,更重要的是通过注意力机制学习不同模态之间的关系,从而实现语义和上下文的对齐。具体来说:
-
注意力机制:交叉注意力模块通过查询(Query)、键(Key)和值(Value)的机制,让不同模态的特征相互影响,学习它们之间的关系。
-
特征融合:通过交叉注意力,模型可以将不同模态的特征融合到一个统一的表示中,使得这些特征在语义和上下文上具有一致性。
3.总结
对于不同模态的数据,先使用特定模型进行编码 然后使用交叉注意力模块将不同模态的数据映射到一个空间中,然后再使用transformer进行计算
Probabilistic Cross-Modal Embedding(PCME)
PCME通过将不同模态的数据表示为概率分布,而不是传统的确定性嵌入,从而更好地捕捉图像和文本之间的一对多(one-to-many)对应关系
1.模态特定的编码器
PCME使用模态特定的编码器对不同模态的数据进行编码:
-
视觉编码器:通常基于ResNet或Vision Transformer(ViT),将图像数据编码为特征表示。
-
文本编码器:使用预训练的GloVe词嵌入和双向GRU(或Transformer)将文本数据编码为特征表示。
2.映射为正态分布
编码后的特征被进一步处理,以表示为一个正态分布。具体来说:
-
均值(Mean, μ):表示嵌入空间中的中心位置。
-
方差(Variance, σ²):表示嵌入空间中的不确定性或分布的宽度。
3.局部注意力机制
为了更有效地聚合空间特征,PCME在均值和方差的计算中引入了局部注意力机制: 局部注意力分支:通过自注意力机制聚合空间特征,然后通过一个带有sigmoid激活函数的线性层进行处理。
-
均值模块:在局部注意力分支的输出上应用LayerNorm(LN)和L2归一化。
-
方差模块:不使用sigmoid和LayerNorm,以避免过度限制方差的表示。
4.损失函数
PCME使用以下损失函数来训练概率映射:
-
软对比损失(Soft Contrastive Loss):用于训练概率映射,以捕捉样本之间的相似性。
-
KL散度损失(KL Divergence Loss):防止学习到的方差坍缩为零。
-
均匀性损失(Uniformity Loss):确保嵌入在单位超球面上均匀分布。
5.整体架构
以下是PCME的整体架构的详细步骤:
5.1 输入编码
-
图像输入:通过视觉编码器(如ResNet或ViT)提取特征。
-
文本输入:通过文本编码器(如预训练的GloVe和双向GRU)提取特征。
5.2 特征映射为正态分布
-
均值计算:使用局部注意力分支聚合空间特征。通过一个带有sigmoid激活函数的线性层处理特征。应用LayerNorm和L2归一化。
-
方差计算:使用局部注意力分支聚合空间特征。通过一个线性层处理特征(不使用sigmoid和LayerNorm)。
5.3 损失函数
-
软对比损失:用于训练概率映射,捕捉样本之间的相似性。
-
KL散度损失:防止方差坍缩为零。
-
均匀性损失:确保嵌入在单位超球面上均匀分布。
6.训练和优化
-
训练过程:首先对头模块进行预训练,然后对整个模型进行端到端的微调。
-
优化器:使用AdamP优化器,结合余弦学习率调度器进行稳定训练。
7.总结
PCME的核心思想是将不同模态的数据表示为概率分布,通过均值和方差来捕捉数据的不确定性和多样性。通过局部注意力机制和特定的损失函数,PCME能够有效地处理图像和文本之间的一对多对应关系,并提供更可解释的嵌入表示。
Adversarial Cross-Modal Retrieval(对抗式跨模态检索)
1.对抗性学习框架
ACMR的核心是两个过程的相互作用:特征映射器(Feature Mapper)和模态分类器(Modality Classifier)。特征映射器的目标是在公共子空间中生成模态不变的表示,以混淆模态分类器;模态分类器则试图根据生成的表示区分不同的模态。这种相互作用以极小化极大博弈的形式实现。
-
特征映射器:执行表征学习的主要任务,生成模态不变的表示,同时保留数据中潜在的跨模态语义结构。
-
模态分类器:作为对手,试图根据项目的模态来区分它们,引导特征映射器的学习。
2.三重约束
为了使具有相同语义标签的不同模态项的表示之间的差距最小化,同时使语义不同的图像和文本之间的距离最大化,ACMR对特征映射器施加了三重约束:
-
标签预测:通过分类器预测映射特征的语义标签,确保模态内的区分性。
-
结构保存:通过三元组损失确保语义相似的跨模态项在共同子空间中尽可能接近,语义不同的项尽可能远离。
-
正则化:防止过拟合,确保学习到的特征表示具有良好的泛化能力。
3.优化过程
ACMR通过联合最小化对抗性损失和嵌入损失来优化特征映射器和模态分类器。对抗性损失用于训练模态分类器,而嵌入损失则结合了模态内区分性和模态间不变性。
4.总结
对抗式跨模态检索(Adversarial Cross-Modal Retrieval, ACMR)是一种基于对抗学习的跨模态检索方法,旨在通过对抗性学习找到一个有效的共同子空间,使得不同模态的数据可以直接相互比较。
CLIP(Contrastive Language–Image Pre-training)
CLIP的设计目标是使模型能够处理各种视觉和语言任务,而无需针对每个任务进行大量的标注数据。 以下是CLIP的核心内容和特点:
1.模型架构
CLIP的架构由两个主要部分组成: 视觉编码器:用于将图像映射到一个低维的嵌入空间。 文本编码器:用于将文本(如标题或描述)映射到相同的嵌入空间。
1.1 视觉编码器
视觉编码器基于Vision Transformer(ViT)或ResNet架构。ViT将图像分割成固定大小的块(patches),然后将这些块视为序列输入到Transformer模型中。ResNet则是一个经典的卷积神经网络(CNN),通过卷积层和残差块提取图像特征。
1.2 文本编码器
文本编码器是一个基于Transformer的模型,通常使用预训练的词嵌入(如BERT的词嵌入)作为输入。文本编码器将输入的文本序列编码为一个固定大小的嵌入向量。
2.对比学习
CLIP的核心思想是通过对比学习来训练模型。具体来说,模型的目标是使得匹配的图像和文本对在嵌入空间中的距离更近,而不匹配的对距离更远。这通过以下步骤实现:
2.1 数据采样
从大规模的图像-文本对数据集中采样,形成正样本对(匹配的图像和文本)和负样本对(不匹配的图像和文本)。
2.2 损失函数
使用对比损失函数(如InfoNCE损失)来优化模型。对于每个正样本对,模型需要最大化其相似度,同时最小化与其他负样本对的相似度。
3.训练过程
CLIP在大规模的图像-文本对数据集上进行训练,这些数据集通常包含数十亿对图像和文本。训练过程中,模型逐步学习如何将图像和文本映射到一个共同的嵌入空间,使得语义相关的对彼此更接近。
4.优势
CLIP的主要优势在于其通用性和灵活性:
-
零样本学习能力:CLIP能够在没有标注数据的情况下处理新的任务,通过将图像和文本映射到一个共同的嵌入空间,实现零样本分类和检索。
-
大规模数据预训练:CLIP在大规模数据上进行预训练,能够学习到丰富的语义信息,从而在多种任务中表现出色。
-
多模态理解:CLIP能够同时处理图像和文本,提供更全面的理解和生成能力。
5.局限性
-
计算资源需求高:训练CLIP需要大量的计算资源和数据。
-
对数据质量的依赖:CLIP的性能高度依赖于训练数据的质量和多样性。
-
生成能力有限:CLIP主要用于检索和分类任务,其生成能力相对有限。
6.总结
CLIP 的核心能力是将图像和文本映射到同一个向量空间,这样你就可以:
-
把数据库中的所有图片编码成向量(只做一次,保存下来);
-
把用户输入的文本描述也编码成向量;
-
然后计算相似度,比如余弦相似度,找出最接近的图片。
clip是由OpenAI提出的一种用于连接图像和文本的模型,旨在通过对比学习(contrastive learning)的方式,学习一个联合的图像和文本嵌入空间。在这个空间中,语义相关的图像和文本对彼此更接近,而语义不相关的则更远。
多模态大模型编码方案
LLAVA
直接使用LLAVA的图像编码器编码图像,然后使用LLAVA的文本编码器编码文本。二者在同一个向量空间中,可以直接进行余弦相似度的计算
imagebind
直接将所有的模态都编码成向量,然后进行相似度计算(在同一个向量空间内)
ImageBind 在预训练是先执行图文匹配 然后使不同模态都和图像对齐,从而实现多模态对齐
多模态RAG架构
根据华为最新提出的综述A Survey on Multimodal Retrieval-Augmented Generation,将多模态架构演变总结为MRAG1.0,MRAG2.0,MRAG3.0,论文地址如下:
https://arxiv.org/abs/2504.08748
MRAG1.0
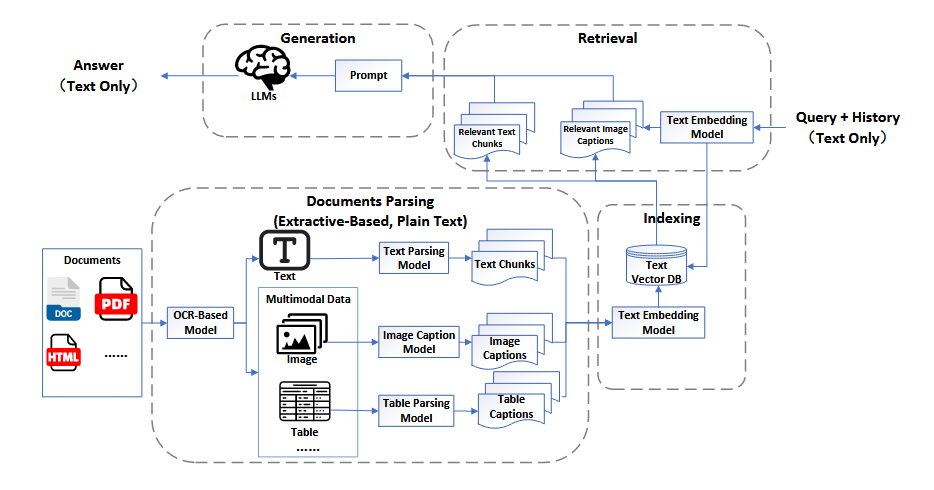
MRAG1.0作为多模态检索增强生成(MRAG)的首个阶段,是在传统检索增强生成(RAG)的基础上进行的初步拓展。它尝试将多模态数据(如文本、图像等)纳入检索和生成流程中,以增强大型语言模型(LLMs)在处理复杂任务时的能力。该阶段的核心在于将多模态数据转换为文本形式(如生成图像的标题),以便利用现有的文本处理技术进行检索和生成。尽管这种做法在一定程度上保留了多模态信息,但由于转换过程中的信息丢失,其对多模态数据的利用效率并不高,且在检索准确性和生成质量方面仍存在较大提升空间。
MRAG2.0
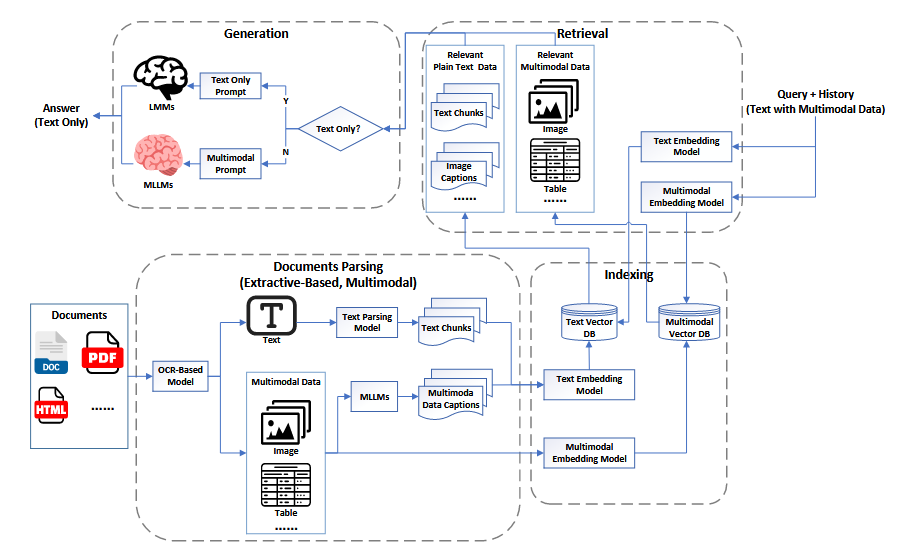
MRAG2.0标志着MRAG系统进入了一个全新的阶段,即“真正的多模态”时代。与MRAG1.0相比,它不再将多模态数据转换为文本,而是直接保留和处理原始的多模态数据。这一改变使得系统能够更全面地利用多模态信息,从而在检索和生成任务中实现更高的准确性和效率。MRAG2.0通过引入多模态大型语言模型(MLLMs),显著提升了系统对多模态数据的理解和处理能力。它不仅支持用户以多模态形式进行查询,还能直接从多模态知识库中检索相关信息,并生成包含多模态元素的回答。这种对原始多模态数据的直接处理,减少了信息转换过程中的损失,为多模态信息检索和生成带来了质的飞跃。
InternLM-XComposer2 就是MRAG2.0的一个例子,使用其编码器对文本图像进行编码后对齐,然后再计算相似度
MRAG3.0
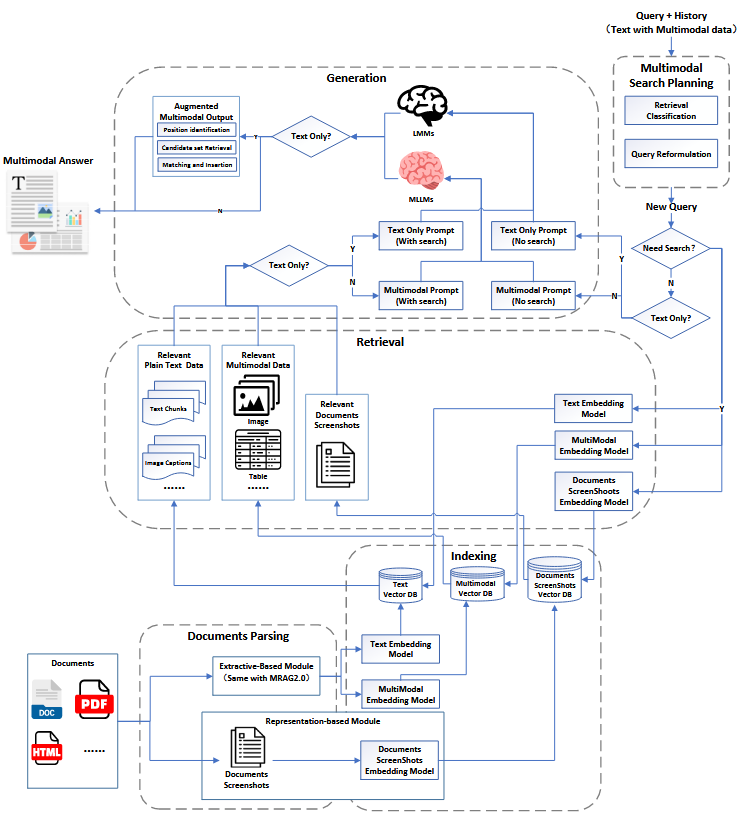
MRAG3.0是MRAG系统发展的最新阶段,它在多个关键方面进行了创新和优化,实现了端到端的多模态处理能力。这一阶段的核心特点是引入了多模态输出能力,使得系统能够生成包含多种模态(如文本、图像、视频等)的综合回答。此外,MRAG3.0还扩展了系统的应用场景,通过模块调整和功能整合,将多模态理解和生成能力统一起来,从而能够处理更广泛的多模态任务。例如,在视觉问答(VQA)场景中,MRAG3.0能够动态规划搜索路径,高效检索相关知识,并生成准确且信息丰富的回答。在多模态生成任务中,它能够根据输入的多模态数据生成高质量的多模态输出,如根据文本描述生成相应的图像或视频内容。MRAG3.0的这些改进,不仅提升了系统的性能,也为多模态信息处理领域带来了新的可能性和发展方向。
MRAG3.0的案例有InternLM-XComposer-2.5
LlamaIndex 框架
LlamaIndex 专注于数据摄取、索引和检索,特别擅长处理非结构化和半结构化数据,并将其高效地转化为LLM可用的上下文 多模态嵌入 (Multi-modal Embeddings): 这是实现跨模态检索的关键。 LlamaIndex 不直接处理图像或视频本身,而是通过多模态嵌入模型将不同模态的数据转化为统一的向量空间中的嵌入向量。这些嵌入向量能够捕捉不同模态数据的语义信息,使得不同模态的数据之间可以通过向量相似度进行比较和检索。
识别不同模态的数据: LlamaIndex 能够识别 Document 对象中包含的文本内容和图像内容。 通常,当你通过 SimpleDirectoryReader 等加载器加载包含图像(例如,通过 PyMuPDF4LLM 从 PDF 中提取图像,或者直接加载图像文件)以及相关文本的文档时, LlamaIndex 会识别出这些不同类型的信息。为每种模态选择并应用合适的嵌入模型,这是“自动处理”的核心。LlamaIndex 不会尝试用一个文本嵌入模型去嵌入图像,反之亦然。相反,它会:
-
对于文本数据: 使用预先配置的文本嵌入模型(例如,OpenAI 的 text-embedding-ada-002)来生成文本的向量嵌入。
-
对于图像数据: 使用专门的图像嵌入模型(例如,CLIP 模型)来生成图像的向量嵌入。
将不同模态的嵌入存储到统一的向量空间(或协调的多个向量存储): 虽然是不同的模型生成了不同的嵌入,但 LlamaIndex 的目标是将它们存储在一个能够进行跨模态检索的结构中。这通常有两种实现方式:
-
单一多模态向量存储: 如果你使用的是像 Cohere MultiModal Embeddings 或 VoyageAI Multi-Modal Embeddings 这样本身就能将文本和图像映射到同一语义空间中的嵌入模型,那么 LlamaIndex 可以将所有这些不同模态的嵌入存储到一个单一的向量数据库中。这样,文本查询可以直接在包含图像嵌入的向量空间中进行相似性搜索。
-
协调的多个向量存储: 另一种常见的方式是,LlamaIndex 会在内部维护(或让你配置)独立的向量存储来分别存储文本嵌入和图像嵌入。例如,一个 vector_store 用于文本,一个 image_store 用于图像。当 MultiModalVectorStoreIndex.from_documents() 被调用时,它会智能地将文本内容发送到文本嵌入模型并存储到文本向量存储,将图像内容发送到图像嵌入模型并存储到图像向量存储。
榜单
文本嵌入模型榜单
MTEB : Massive Text Embedding Benchmark
github : https://github.com/embeddings-benchmark/mteb
huggingface : https://huggingface.co/spaces/mteb/leaderboard
paper : https://paperswithcode.com/paper/mteb-massive-text-embedding-benchmark
多模态嵌入模型榜单
MMEB :Massive Multimodal Embedding Benchmark
paper https://arxiv.org/pdf/2410.05160
leadervoard https://huggingface.co/spaces/TIGER-Lab/MMEB-Leaderboard
图像编码器(Image Encoder)
常用的图像编码器(指将图像转换为可用于检索、分类或下游任务的向量表示)在工业界的模型主要有以下这些:
| 编码器 | 简介 | 特点 |
|---|---|---|
| CLIP (ViT / ResNet) | OpenAI 提出的跨模态模型,将图像和文本映射到同一语义空间 | 支持零样本分类、跨模态检索;语义强,常与 SentenceTransformer 结合使用 |
| ResNet (50/101/152) | CNN 经典架构,用于图像分类、提取特征 | 稳定、泛化强,常用于下游视觉任务的 backbone |
| Vision Transformer (ViT) | 用 Transformer 替代 CNN 的图像建模方法 | 结构简洁,易于与文本模型统一(如 CLIP) |
| EfficientNet | Google 提出的高效 CNN 架构 | 参数少、推理快,适合移动端和实时系统 |
| ConvNeXt | 模拟 ViT 的 CNN 结构,兼容传统与新型方法 | 在 ImageNet 上表现优异,适合替代 ResNet |
| DINO / DINOv2 | 自监督视觉预训练模型(Meta) | 能学到丰富的语义信息,适合无标签图像场景 |
| BLIP / BLIP-2 | 多模态编码器,支持图像→文本生成与理解 | 强跨模态能力,可用于 VQA、图像描述生成等 |
视频编码器(Video Encoder)
常用的视频编码器(指将视频转换为可用于检索、分类或下游任务的向量表示)在工业界的模型主要有以下这些(即代表模型视角):
| 编码器 | 简介 | 特点 |
|---|---|---|
| VideoMAE | 视频 Masked AutoEncoder,自监督学习空间+时间特征 | 对视频建模能力强,常用于动作识别和事件检索 |
| TimeSformer | 空间维度与时间维度用分离的 Transformer 编码 | 更适合长视频建模,易于理解局部与整体语义 |
| SlowFast Networks | 使用慢分支处理语义,快分支捕捉动作 | 在动作识别领域表现优秀(如 Kinetics) |
| I3D (Inflated 3D ConvNet) | 将 2D CNN 扩展为 3D,用于视频时序建模 | 是很多动作识别模型的基础组件 |
| X3D / R(2+1)D | 更轻量的 3D CNN 模型 | 适合移动或嵌入式端部署 |
| VIT + CLIP (VideoCLIP) | 使用文本引导学习视频语义 | 可实现视频与文本之间的对齐与检索 |
视频 = 一系列帧(Frames) + 时间顺序 编码流程通常包括两步: 帧级特征提取(Spatial Encoding):从每一帧中提取视觉特征(如 CNN、ViT)。 时序建模(Temporal Encoding):将帧的特征组合,建模时间维度(如 RNN、Transformer)。
在方法类别视角下,视频编码主要有以下几种方法:
| 方法类别 | 示例模型 | 优点 | 缺点 | 具体描述 |
|---|---|---|---|---|
| 2D CNN + RNN/Transformer | VideoBERT, S2VT | 简洁易实现 | 时间建模弱 | 每一帧使用 ResNet、Inception、VGG 提取图像特征;然后将帧序列送入 LSTM、GRU 或 Transformer,建模时间关系 |
| 3D CNN | I3D, R(2+1)D | 强时空建模 | 模型重,效率低 | 使用 3D 卷积(如 I3D、C3D、R(2+1)D)一次性编码多个帧,提取局部空间+时间特征。 |
| ViT + Temporal Transformer | TimeSformer, ViViT | 表现优越,适配大模型 | 资源要求高 | 每帧用 ViT、Swin Transformer 提取图像 patch 级特征; 然后用时序 Transformer(如 TimeSformer)建模序列关系。 |
| CLIP/VIT + Pooling | CLIP, CoCa | 快速,适合检索 | 时序信息缺失 | 从视频采样若干关键帧或 Clip(如每隔几帧提一个片段),提取特征; 然后进行聚合(如平均池化、Attention)得到视频整体表示。 |
近期视频编码方法
VideoMAE V2的视频编码部分 -----华为诺亚方舟
MAE 的核心思想是一种简单而高效的图像自监督学习方法。其主要步骤和理念如下:
-
随机掩码 (Random Masking): 从输入的图像中随机遮盖掉大部分 (例如75%或更高比例) 图像块 。
-
编码器处理可见块 (Encoder on Visible Patches): 将剩余的、未被遮盖的少量图像块输入到一个标准的 Transformer 编码器中进行处理,学习这些可见部分的特征表示。由于只处理少量图像块,这大大降低了计算量和内存消耗。
-
轻量级解码器重建 (Lightweight Decoder for Reconstruction): 使用一个轻量级的解码器,结合编码器输出的可见块特征以及被遮盖块的位置信息,来尝试重建原始图像中被遮盖掉的像素内容。
-
像素级重建损失 (Pixel-level Reconstruction Loss): 模型的学习目标是最小化重建图像与原始图像在被遮盖区域的像素差异 (通常使用均方误差损失)。
视频采样
在视频预处理阶段,首先需要对视频进行采样,以提取出具有代表性的帧序列。采样策略的选择对于模型的性能和效率至关重要。 在VideoMAE V2中,作者采用了以下采样策略:
-
采样间隔(stride):根据不同的数据集和任务需求,选择合适的采样间隔。例如,在Something-Something数据集上,采样间隔为2;在其他数据集上,采样间隔为4。这种策略可以减少计算量,同时保留视频的关键信息。
-
帧数:通常选择固定数量的帧作为输入,例如16帧。这样可以保证输入数据的一致性,便于模型处理。
立方体嵌入
立方体嵌入是将采样后的视频帧转换为模型可以处理的标记(token)序列的过程。具体步骤如下:
-
局部时空特征编码:将每个采样帧划分为多个小块(patches),每个小块称为一个“立方体”(cube)。这些立方体包含了局部的时空信息。
-
嵌入层(embedding layer):通过一个嵌入层将每个立方体映射到一个固定维度的向量空间中,得到对应的标记。嵌入层通常是一个线性变换,可以学习到输入数据的特征表示。
-
位置嵌入(positional embedding):为了保留时空信息,将位置嵌入添加到每个标记中。位置嵌入可以是学习到的参数,也可以是预定义的函数,用于表示每个立方体在视频中的位置信息。
掩码操作
掩码操作是VideoMAE V2的核心创新之一,它通过丢弃部分标记来提高预训练的效率。具体步骤如下:
-
编码器掩码(Encoder Masking):在编码器中,随机选择一部分标记进行丢弃,只保留一部分可见标记(visible tokens)。这种高比例的掩码操作(例如90%)可以显著减少编码器的输入长度,从而提高计算效率。
-
解码器掩码(Decoder Masking):在解码器中,进一步选择一部分标记进行丢弃,只重建部分标记。这种双重掩码策略可以进一步减少计算量,同时保持重建任务的挑战性和意义。
编码器
编码器是基于Vision Transformer(ViT)的架构,负责处理可见标记并生成潜在特征表示。具体步骤如下:
-
输入处理:将经过掩码操作后的可见标记输入到编码器中。
-
多头自注意力机制(Multi-Head Self-Attention, MHA):编码器通过多头自注意力机制处理输入标记,捕捉标记之间的时空关系。每个头可以关注不同的特征子空间,从而提高模型的表达能力。
-
前馈网络(Feed-Forward Network, FFN):在每个Transformer层中,除了自注意力机制外,还包含一个前馈网络,用于进一步处理特征。
-
层归一化(Layer Normalization):在每个Transformer层的输出上应用层归一化,以稳定训练过程并提高模型的泛化能力。
-
输出特征:经过多层Transformer处理后,编码器输出每个可见标记的潜在特征表示。
总结
视频编码部分在VideoMAE V2中起着至关重要的作用。通过合理的采样策略、立方体嵌入、掩码操作和编码器的设计,模型能够高效地处理大规模视频数据,并生成具有强大表示能力的特征。这些特征可以用于多种下游任务,如动作识别、动作检测和时间动作检测等,展示了VideoMAE V2作为通用视频表示学习器的有效性。
videoGPT
算法流程
-
一段视频通过分段式采样策略选出 T 帧,并被划分为 K 个视频片段。
-
图像编码器独立处理这 T 帧中的每一帧(以较高分辨率),提取详细的空间特征。
-
视频编码器处理这 K 个视频片段(每个片段包含 n 帧,以较低分辨率),提取全局的时间上下文特征。
-
这两组不同的特征分别通过视觉适配器模块进行投影(降维)并池化,
-
拼接起来送入大型语言模型进行后续的理解和生成任务。
对于具体的视频片段 使用了InternVideo-v2 作为视频编码器 这个视频编码器的输入是一段视频片段,它可以直接输出一段特征张量
总结
视频编码 时空结合 空间就是采样后的每一帧使用图像编码器编码结果 时间就是在时间维度使用多头自注意力机制或别的手段由于视频的数据量大,通常对于整段视频进行处理时需要降低分辨率
音频编码器(Audio Encoders)
| 编码器/模型 | 简介 | 应用场景 | 特点 |
|---|---|---|---|
| Wav2Vec 2.0 (Facebook/Meta) | 自监督学习原始波形,提取语音特征 | 语音识别、说话人识别 | 支持 fine-tune,可处理嘈杂环境 |
| HuBERT | 隐式聚类 + 自监督对比学习 | 语音识别、说话风格提取 | 表达更丰富语义,适合多任务 |
| Whisper (OpenAI) | 强大的端到端语音识别模型 | 语音转写、翻译、字幕生成 | 多语言支持,兼容跨模态系统 |
| YAMNet | Google 提出的用于环境音分类模型 | 音频分类、事件检测 | 轻量级,预训练模型开源 |
| VGGish | 基于 VGG 的音频特征提取器 | 音频检索、情感分析 | 特征兼容广泛 |
| PANNs | CNNs for Audio Tagging and Sound Event Detection | 环境声音识别、声景分析 | 多种音频标签和事件检测支持 |
| AudioCLIP | 用 CLIP 思路学音频-图像-文本联合语义空间 | 音频检索、跨模态检索 | 跨模态对齐强,适合 multimodal |
| CLAP (Contrastive Language-Audio Pretraining) | 音频与文本对齐模型(如“狗叫声”<->文本描述) | 文本→音频检索、音频分类 | 类似于 CLIP,但作用于音频与语言 |
| BEATs (Meta) | 基于 HuBERT 的音频自监督模型 | 音频识别、音乐理解 | 更通用,适合迁移到其他模态 |
在多模态学习场景中,音频数据的编码方式主要分为以下几类,每种方式根据任务和场景不同(如情感识别、语音识别、音视频理解、多模态检索等)有所侧重:
传统音频编码方式:
| 编码方式 | 简介 | 常用工具 |
|---|---|---|
| MFCC(Mel-Frequency Cepstral Coefficients) | 提取音频信号的倒谱系数,模拟人耳听觉特性,常用于语音识别和情感识别。 | librosa、python_speech_features |
| Log-Mel Spectrogram | 将音频信号转换为 Mel 频率域下的对数功率谱图,是深度学习中最常用的输入表示之一 | librosa.feature.melspectrogram |
| Spectrogram / STFT(短时傅里叶变换) | 对音频信号进行时频分析,提取时域与频域联合特征 | librosa.stft |
| Chroma Features | 提取音高相关的音频特征,适合用于音乐类型分析 | librosa.feature.chroma_stft |
深度学习音频编码:
将时域转为频域 再使用神经网络 比如CNN Transformer
| 模型类型 | 代表模型 / 方法 | 简介 |
|---|---|---|
| CNN-based | VGGish(Google)、PANNs(Pretrained Audio Neural Networks) | 将音频转换为频谱图,然后使用 CNN 提取特征。 |
| Transformer-based | AST(Audio Spectrogram Transformer)、BEATs(by Microsoft)、HTS-AT | 将音频频谱图作为输入,使用 Transformer 提取全局上下文特征 |
| 自监督音频编码器 | wav2vec 2.0(Facebook)、HuBERT、data2vec、WavLM | 直接从原始波形学习强特征表示,适用于语音识别、情感识别等任务 |
| CLAP / AudioCLIP / AudioALBEF | 音频-文本对比学习编码器 | 学习统一的音频-文本表示,用于多模态检索或匹配任务 |
融合预训练多模态模型中的音频编码器
log-mel spectrogram(对数梅尔频谱图) 将音频转为频谱,使用神经网络进行处理后和其他模态一起训练 在多模态框架中,音频编码往往与文本、图像结合,例如:CLIP4Clip、Merlot, VATT(Video-Audio-Text Transformer)LAVENDER、MURAL、FLAVA:将音频作为与图像和文本等量的重要模态,进行共同训练。
音频一般被处理为 log-mel spectrogram,然后送入 ViT 或 CNN-Transformer 混合模型。
多模态统一编码器
已经在 视频 + 音频 + 图像 + 文本上 对齐完毕,直接编码便可以进行相似度计算来检索
| 模型名称 | 支持模态 | 是否已对齐 | 是否开源 | 编码器可直接用? |
|---|---|---|---|---|
| ImageBind (Meta) | 图像、文本、音频、视频、IMU、深度图 | ✅ | ✅ | ✅ |
| UniSim (Meta) | 图像、视频、音频、文本、3D | ✅ | ✅ | ✅ |
| FLAVA (Meta) | 图像、文本(支持扩展) | ✅ | ✅ | ✅ |
| X-CLIP / VideoCLIP / UMT | 视频、文本 | ✅ | 部分 | ✅ |
| PaLI / PaLI-X (Google) | 图像、文本、OCR、少量视频 | ✅ | ❌ | ❌ |
| OpenFlamingo | 视频、图像、文本、少量音频 | ✅ | ✅ | ✅ |
| GIT / Unified-IO | 图像、文本、音频 | ✅ | ✅ | ✅ |

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)