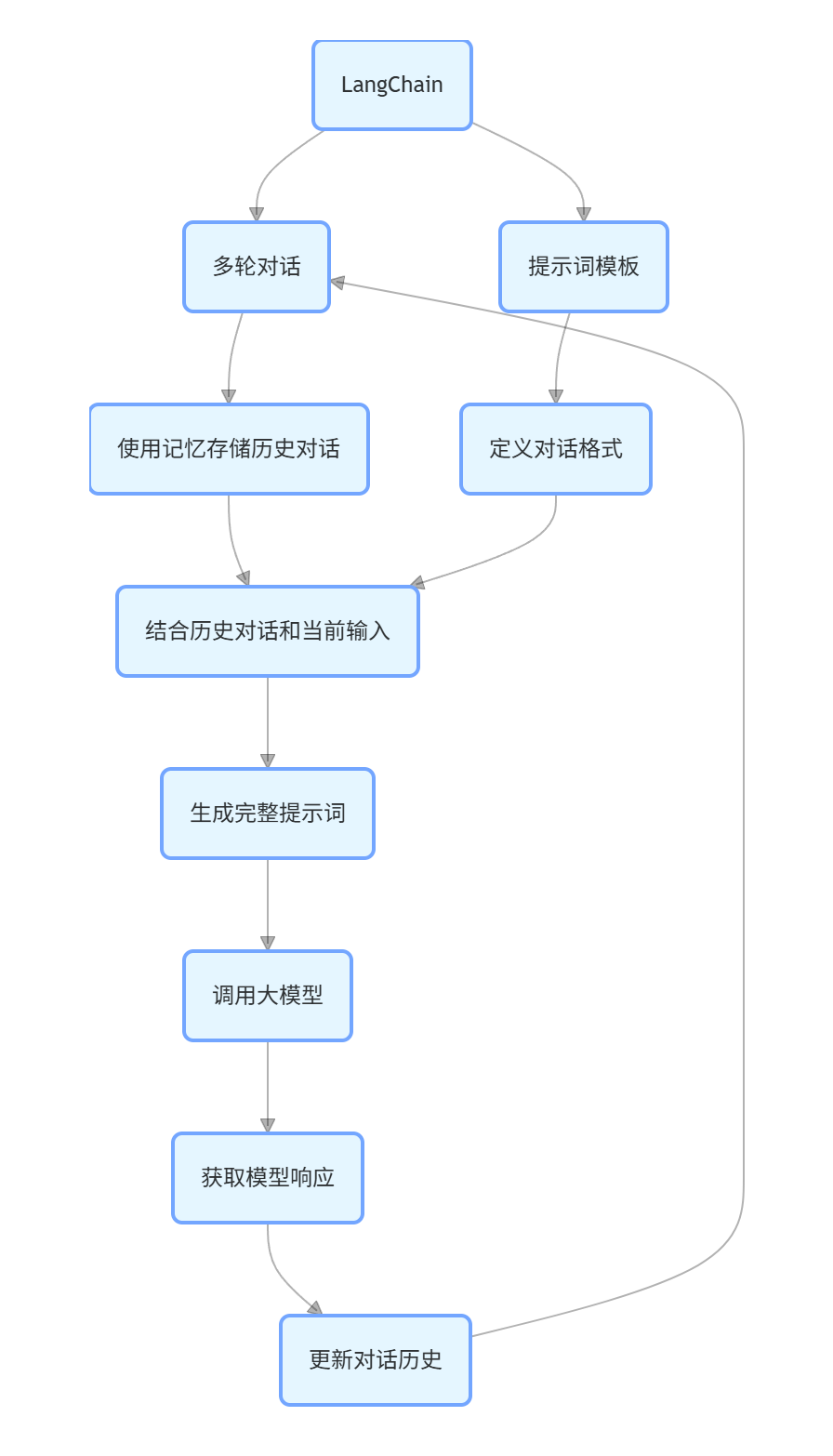
使用LangChain结合讯飞星火认知大模型实现交互式多轮对话
使用LangChain框架构建提示此模板,实现与大模型进行交互式对话。
上篇中提及了调用星火认知大模型的配置以及websocket协调的配置,这篇不这部分相关代码。
首先需要设置大模型环境变量,初始化 WebSocket类生成构造大模型所需要的信息,构建CustomSparkLLM(LLM)类实现与星火认知大模型交互,以上具体方法及代码在上一篇中。
使用LangChain框架
在实现了基本问答(单论对话)的情况下,想要实现交互式多轮对话、对话历史和上下文管理,LangChain框架便尤为重要,我们需要使用LangChain框架中提供的核心组件:ConversationChain、ConversationBufferMemory
通过以下两行代码导入这两个方法:
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain具体使用方法如下:
memory = ConversationBufferMemory(k=3)使用了LangChain提供的一个“对话链”,用于实现多轮对话。它会自动将历史对话(由 memory 管理)和当前用户输入拼接成 prompt,传递给大模型,并返回模型的回复。k=3则是只保留近三轮对话,这样做可以避免prompt过长,如果不定义大模型需要识别大量的对话以及无关内容。
conversation = ConversationChain(
llm=llm,
memory=memory,
prompt=prompt,
verbose=True
)创建多轮对话链对象conversation,将自定义的CustomSparkLLM 实例(llm)、上文提及的ConversationBufferMemory 实例(memory)、下文将会提到的提示词模板PromptTemplate 实例(prompt)传入对话链对象中,同时启用详细日志(verbose=True)也可以理解成大模型的思考过程,这会使运行时会在控制台输出 prompt 拼接结果、调用链路等调试信息,便于开发和排查问题。
提示词模板
提示词模板可定义
- 如何把历史对话、用户输入等内容拼接成最终传递给大模型的 prompt。
- 模型的身份、语气、回答方式
- 每次传递给模型的内容结构一致,减少模型理解上的歧义,提高回答的准确性和连贯性。
- 自动插入历史对话(如 {history}),让模型“看到”之前的交流,实现多轮对话的上下文连贯。
- 根据不同业务需求,灵活调整模板内容,实现问答、总结、翻译、代码生成等多种场景。
本次我们需要使用提示词模板明确对话的格式和上下文,使大模型接收历史对话和当前问题,更好的理解上下文。
from langchain.prompts import PromptTemplate首先从 LangChain 框架中导入 PromptTemplate 类,方便我们在代码中创建和管理提示词模板(Prompt)。
template = """
你是一个智能助手。以下是你和用户的对话历史:
{history}
用户: {input}
AI:"""
prompt = PromptTemplate(
input_variables=["history", "input"],
template=template
)template 变量定义了大模型每次收到的完整提示词格式,{history} 会被自动替换为多轮对话的历史内容,{input} 会被自动替换为用户当前输入的问题,PromptTemplate 用于将这个模板和变量绑定,后续由 LangChain 自动填充内容。构造提示词模板的自由度非常高,可根据自己所需修改其中内容。
以下是运行结果:
欢迎进入多轮对话,输入exit退出。
你:你好,你是谁
> Entering new ConversationChain chain...
Prompt after formatting:
你是一个智能助手。以下是你和用户的对话历史:
用户: 你好,你是谁
AI:
> Finished chain.
AI: 你好,我叫讯飞星火认知大模型,是科大讯飞构建的智能助手。
我可以帮助你解决各种问题,比如回答问题、提供建议和帮助学习等。你有什么需要帮忙的吗?
你:使用python实现杨辉三角形
> Entering new ConversationChain chain...
Prompt after formatting:
你是一个智能助手。以下是你和用户的对话历史:
Human: 你好,你是谁
AI: 你好,我叫讯飞星火认知大模型,是科大讯飞构建的智能助手。
我可以帮助你解决各种问题,比如回答问题、提供建议和帮助学习等。你有什么需要帮忙的吗?
用户: 使用python实现杨辉三角形
AI:
> Finished chain.
AI: ### 步骤一:理解问题
**描述**:用户希望使用Python编程语言实现杨辉三角形。杨辉三角形是一种数字排列,其中每个数是其上方两个数的和,常用于组合 数学中。
**决定**:需要进一步分解任务,确定实现杨辉三角形的具体方法和步骤。
---
### 步骤二:设计解决方案
**描述**:为了实现杨辉三角形,可以采用以下几种方法之一:
1. **迭代法**:逐行计算并存储每一行的数字。
2. **递归法**:利用递归关系生成每一行的数字。
3. **动态规划**:优化递归方法,避免重复计算。
考虑到效率和代码简洁性,选择迭代法来实现杨辉三角形。
**决定**:准备编写具体的Python代码,实现杨辉三角形的生成。
---
### 步骤三:编写代码
**描述**:根据设计的迭代法,编写Python代码来生成杨辉三角形。代码将包括必要的依赖项导入(如果有),定义生成杨辉三角的函 数,以及展示结果的部分。
**决定**:提供最终的Python代码实现。
---
```python
# 导入必要的依赖项
def generate_pascals_triangle(num_rows):
"""
生成杨辉三角形的前num_rows行。
:param num_rows: 要生成的杨辉三角形的行数
:return: 包含杨辉三角形各行的列表
"""
triangle = []
for row_num in range(num_rows):
row = [1] # 每行的第一个元素总是1
if triangle:
last_row = triangle[-1]
# 计算中间的元素
row += [sum(pair) for pair in zip(last_row, last_row[1:])]
row.append(1) # 每行的最后一个元素总是1
triangle.append(row)
return triangle
def print_pascals_triangle(triangle):
"""
打印杨辉三角形。
:param triangle: 包含杨辉三角形各行的列表
"""
for row in triangle:
print(' '.join(map(str, row)).center(len(' '.join(map(str, triangle[-1])))))
if __name__ == "__main__":
try:
num = int(input("请输入要生成的杨辉三角形的行数: "))
if num <= 0:
print("请输入一个正整数。")
else:
triangle = generate_pascals_triangle(num)
print_pascals_triangle(triangle)
except ValueError:
print("输入无效,请输入一个整数。")
```
你:5
> Entering new ConversationChain chain...
Prompt after formatting:
你是一个智能助手。以下是你和用户的对话历史:
Human: 你好,你是谁
AI: 你好,我叫讯飞星火认知大模型,是科大讯飞构建的智能助手。
我可以帮助你解决各种问题,比如回答问题、提供建议和帮助学习等。你有什么需要帮忙的吗?
Human: 使用python实现杨辉三角形
AI: ### 步骤一:理解问题
**描述**:用户希望使用Python编程语言实现杨辉三角形。杨辉三角形是一种数字排列,其中每个数是其上方两个数的和,常用于组合 数学中。
**决定**:需要进一步分解任务,确定实现杨辉三角形的具体方法和步骤。
---
### 步骤二:设计解决方案
**描述**:为了实现杨辉三角形,可以采用以下几种方法之一:
1. **迭代法**:逐行计算并存储每一行的数字。
2. **递归法**:利用递归关系生成每一行的数字。
3. **动态规划**:优化递归方法,避免重复计算。
考虑到效率和代码简洁性,选择迭代法来实现杨辉三角形。
**决定**:准备编写具体的Python代码,实现杨辉三角形的生成。
---
### 步骤三:编写代码
**描述**:根据设计的迭代法,编写Python代码来生成杨辉三角形。代码将包括必要的依赖项导入(如果有),定义生成杨辉三角的函 数,以及展示结果的部分。
**决定**:提供最终的Python代码实现。
---
```python
# 导入必要的依赖项
def generate_pascals_triangle(num_rows):
"""
生成杨辉三角形的前num_rows行。
:param num_rows: 要生成的杨辉三角形的行数
:return: 包含杨辉三角形各行的列表
"""
triangle = []
for row_num in range(num_rows):
row = [1] # 每行的第一个元素总是1
if triangle:
last_row = triangle[-1]
# 计算中间的元素
row += [sum(pair) for pair in zip(last_row, last_row[1:])]
row.append(1) # 每行的最后一个元素总是1
triangle.append(row)
return triangle
def print_pascals_triangle(triangle):
"""
打印杨辉三角形。
:param triangle: 包含杨辉三角形各行的列表
"""
for row in triangle:
print(' '.join(map(str, row)).center(len(' '.join(map(str, triangle[-1])))))
if __name__ == "__main__":
try:
num = int(input("请输入要生成的杨辉三角形的行数: "))
if num <= 0:
print("请输入一个正整数。")
else:
triangle = generate_pascals_triangle(num)
print_pascals_triangle(triangle)
except ValueError:
print("输入无效,请输入一个整数。")
```
用户: 5
AI:
> Finished chain.
AI: ```
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
```完整代码如下:
from langchain.llms.base import LLM
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain, ConversationChain
from pydantic import Field
import os
import json
import websocket
import datetime
import hashlib
import base64
import hmac
import time
from urllib.parse import urlparse
import ssl
from wsgiref.handlers import format_date_time
from datetime import datetime
from time import mktime
import _thread as thread
import sys
from urllib.parse import urlencode
from langchain.memory import ConversationBufferMemory
from langchain.prompts import PromptTemplate
from langchain.chains import ConversationChain
# 设置环境变量
os.environ['SPARK_APPID'] = 'YOU_APPID'
os.environ['SPARK_API_KEY'] = 'YOU_API_KEY'
os.environ['SPARK_API_SECRET'] = 'YOU_API_SECRET'
class Ws_Param(object):
def __init__(self, APPID, APIKey, APISecret, Spark_url):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.host = urlparse(Spark_url).netloc
self.path = urlparse(Spark_url).path
self.Spark_url = Spark_url
def create_url(self):
now = datetime.now()
formatted_date = format_date_time(mktime(now.timetuple()))
signature_origin = "host: " + self.host + "\n"
signature_origin += "date: " + formatted_date + "\n"
signature_origin += "GET " + self.path + " HTTP/1.1"
signature_sha = hmac.new(self.APISecret.encode('utf-8'),
signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha_base64 = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = f'api_key="{self.APIKey}", algorithm="hmac-sha256", headers="host date request-line", signature="{signature_sha_base64}"'
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
v = {
"authorization": authorization,
"date": formatted_date,
"host": self.host
}
return self.Spark_url + '?' + urlencode(v)
class CustomSparkLLM(LLM):
appid: str = Field(default_factory=lambda: os.environ['SPARK_APPID'])
api_key: str = Field(default_factory=lambda: os.environ['SPARK_API_KEY'])
api_secret: str = Field(default_factory=lambda: os.environ['SPARK_API_SECRET'])
spark_url: str = "wss://spark-api.xf-yun.com/v4.0/chat"
domain: str = "4.0Ultra"
@property
def _llm_type(self) -> str:
return "spark"
def _call(self, prompt: str, stop=None) -> str:
response = self._get_spark_response(prompt)
return response
def _get_spark_response(self, prompt: str) -> str:
# 创建WebSocket连接
wsParam = Ws_Param(self.appid, self.api_key, self.api_secret, self.spark_url)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(
wsUrl,
on_message=self._on_message,
on_error=self._on_error,
on_close=self._on_close,
on_open=self._on_open
)
# 设置认证信息
ws.appid = self.appid
ws.api_key = self.api_key
ws.api_secret = self.api_secret
ws.domain = self.domain
ws.prompt = prompt
ws.response = ""
ws.is_closed = False # 添加标志来跟踪连接状态
# 在新线程中运行WebSocket
thread.start_new_thread(self._run_websocket, (ws,))
# 等待响应,直到连接关闭或超时
timeout = 30 # 设置30秒超时
start_time = time.time()
while not ws.is_closed and time.time() - start_time < timeout:
time.sleep(0.1)
if not ws.is_closed:
ws.close()
return "Error: Response timeout"
return ws.response
def _run_websocket(self, ws):
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
def _on_message(self, ws, message):
try:
data = json.loads(message)
if data["header"]["code"] != 0:
ws.response = f"Error: {data['header']['message']}"
ws.close()
return
content = data["payload"]["choices"]["text"][0]["content"]
ws.response += content
# 只有当状态为2(表示回答结束)时才关闭连接
if data["header"]["status"] == 2:
ws.close()
except Exception as e:
print(f"Error processing message: {str(e)}")
ws.response = f"Error processing response: {str(e)}"
ws.close()
def _on_error(self, ws, error):
ws.response = f"Error: {str(error)}"
ws.close()
def _on_close(self, ws, close_status_code, close_msg):
ws.is_closed = True # 标记连接已关闭
def _on_open(self, ws):
# 构建请求数据
data = {
"header": {
"app_id": ws.appid,
"uid": "12345"
},
"parameter": {
"chat": {
"domain": ws.domain,
"temperature": 0.88,
"max_tokens": 4096
}
},
"payload": {
"message": {
"text": [
{"role": "user", "content": ws.prompt}
]
}
}
}
# 发送请求
ws.send(json.dumps(data))
llm = CustomSparkLLM() # 提到全局
def chat_with_llm(question: str) -> str:
"""与讯飞星火大模型进行对话"""
response = llm._call(question)
return response
if __name__ == "__main__":
# 限制历史长度,防止prompt过长
memory = ConversationBufferMemory(k=3) # 只保留最近3轮
template = """
你是一个智能助手。以下是你和用户的对话历史:
{history}
用户: {input}
AI:"""
prompt = PromptTemplate(
input_variables=["history", "input"],
template=template
)
conversation = ConversationChain(
llm=llm,
memory=memory,
prompt=prompt,
verbose=True
)
# 交互式多轮对话
print("欢迎进入多轮对话,输入exit退出。")
while True:
user_input = input("你:")
if user_input.strip().lower() in ["exit", "quit"]:
break
try:
ai_response = conversation.predict(input=user_input)
print("AI:", ai_response)
except Exception as e:
print("发生错误:", e) 
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)