我用人人都能用的AI工具,做了个“智能博物官”,十一假期再也不会走马观花
如何利用Qwen3-Omni大模型和LlamaFactoryOnline工具打造专属“智能博物官”?相比通用AI的干瘪回答,微调后的模型能提供生动专业的文物解读,让参观体验焕然一新。整个过程仅需2小时18分钟,操作简单,让普通游客也能拥有私人文化顾问级别的导览服务。
逛博物馆最尴尬的是什么?
是站在一件国宝前,除了“真好看”、“真古老”,再也憋不出第三句话。
是租了讲解器,听到的都是百度百科上能查到的冰冷介绍。
是想问讲解员一个问题,看着周围一圈人,又把话咽了回去。
上周,我提前为十一假期准备了一个秘密武器——用最新的Qwen3-Omni大模型和Llama Factory Online工具,微调了一个属于我自己的“智能博物官”。
先看一个会让你决定动手的瞬间:
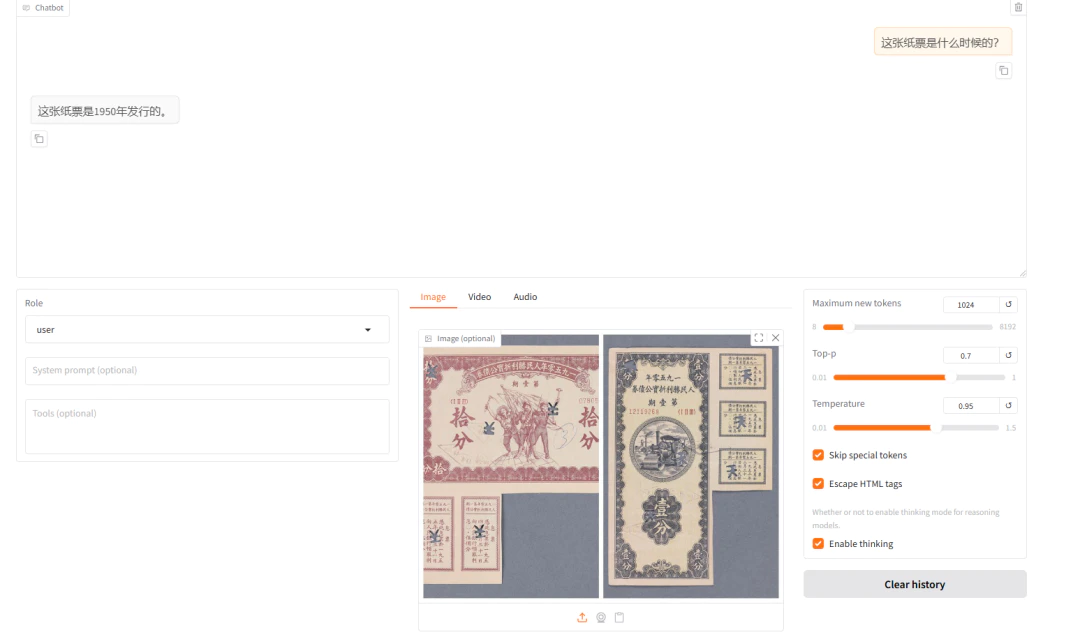
我拿一个通用AI模型和一张纸票做了个测试。我(拍了一张纸票的特写):“这张纸票是什么时候的?”
而经过我微调后的“博物官”是这么回答的:
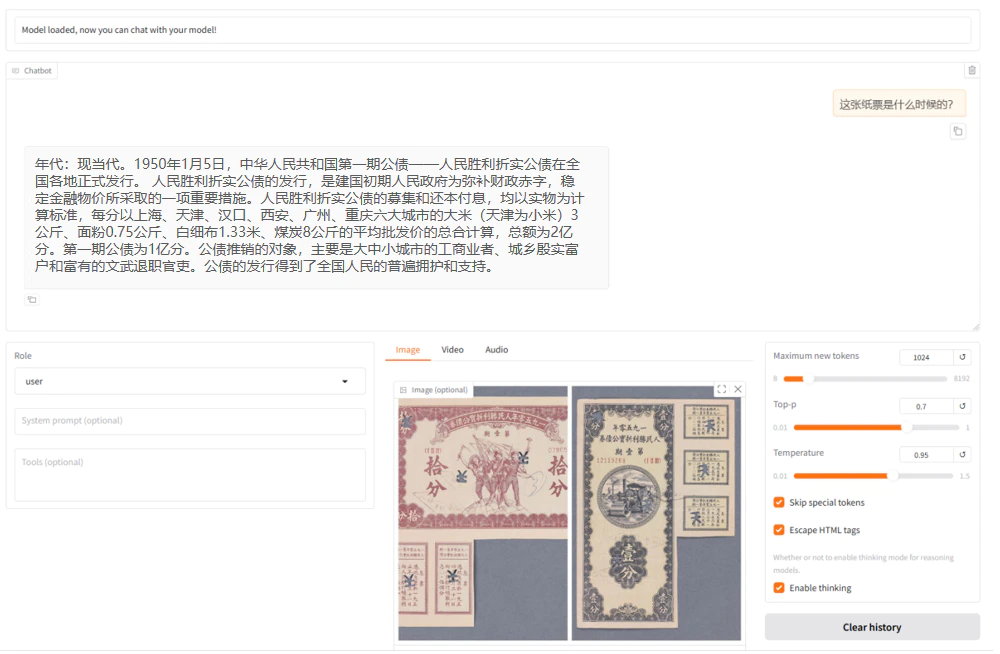
这种质的飞跃,来自于一次极其简单的“模型调教”。
我是怎么做到的?三步极简操作:
整个过程简单得超乎想象:
-
准备“教材”:收集文物资料、专家讲解稿
-
上“实训平台”:在Llama Factory Online上传数据,选择Qwen3-Omni模型
-
一键“开练”:点击开始训练,喝杯咖啡的时间,你的“私人博物官”就毕业了
接下来,我将分享完整的微调流程,包括数据准备、微调训练、模型评估、模型对话以及后续进阶优化,展示如何把通用大模型快速适配成专属你的“私人博物官”。
操作步骤
1️⃣配置概览
|
配置参数 |
配置项 |
是否预置 |
说明 |
|---|---|---|---|
|
模型 |
Qwen3-Omni-30B-A3B-Instruct |
是 |
经过指令微调,参数量约305亿(30.5B),单步推理时激活约30亿 (3B) 参数,能够无缝处理文本、图像、音频和视频,并同时生成文本和自然语音回复。 |
|
数据集 |
alpaca_museum_multimodal |
是 |
包含丰富的文物图像、详细的文本描述以及相关的知识图谱信息。 |
|
GPU |
H800*1(推荐) |
- |
- |
|
微调方法 |
lora |
- |
显著降低计算与存储成本,兼具高性能与部署灵活性。 |
2️⃣资源消耗预览
使用推荐资源(H800*1)进行微调时微调过程总时长约2h18min。
3️⃣操作详情
安装llamafactory
使用已注册的LLaMA Factory Online账号登录平台,选择[实例空间]菜单项,进入实例空间页面,如下图所示。
单击上图“开始微调”按钮,进入[配置资源]页面,选择GPU资源,卡数填写1,其他参数保持为默认值,然后单击“启动”按钮,启动实例。
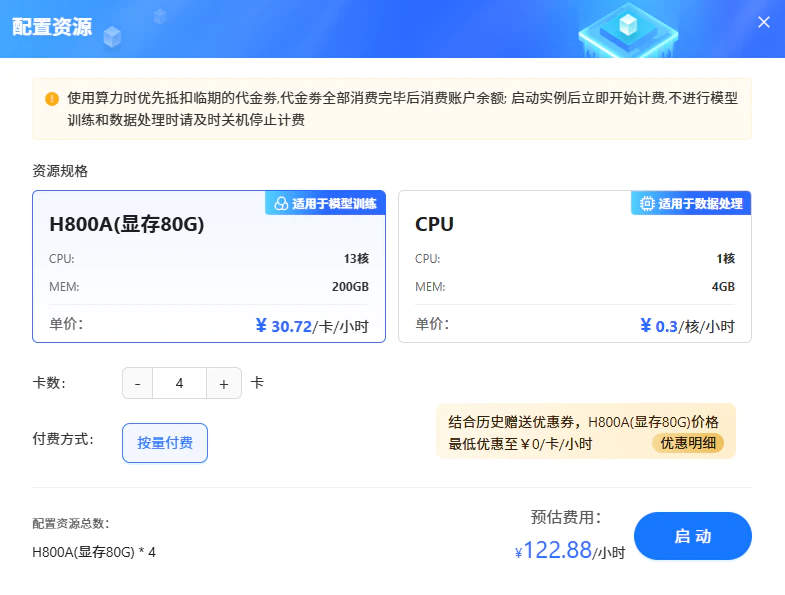
实例启动后,可启动VSCode或者JupyterLab专属数据处理,本次实践我们使用JupyterLab专属数据处理。
创建并配置用于数据处理的python环境。在JupyterLab中单击“Terminal”进入终端。
执行如下命令,创建一个虚拟环境,python版本选择3.12。
conda create -n omini python=3.12 -y
conda activate omini执行如下命令,下载安装llamafactory。
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]" --no-build-isolation安装完成后:
a. 执行如下命令,安装支持Omini模型的Transform和accelerate版本。
pip install git+https://github.com/huggingface/transformers
pip install accelerateb. 单击链接下载flashatten,选择“flash_attn-2.8.3+cu12torch2.8cxx11abiTRUE-cp312-cp312-linux_x86_64”版本进行下载。
下载完成后上传至/workspace目录下,并执行如下命令安装flashatten。
pip install /workspace/flash_attn-2.8.3+cu12torch2.8cxx11abiTRUE-cp312-cp312-linux_x86_64.whlc. 替换llamafactory源码文件,单击下载loader.py文件,并放至/workspace/LLaMA-Factory/src/llamafactory/data/目录下进行替换。
启动llamafactory服务,可以通过6666端口号启动。
GRADIO_SERVER_PORT=6666 llamafactory-cli webui访问llamafactory服务。通过对外服务网址进行llamafactory的访问。
模型训练
在微调页面,配置如下参数:
-
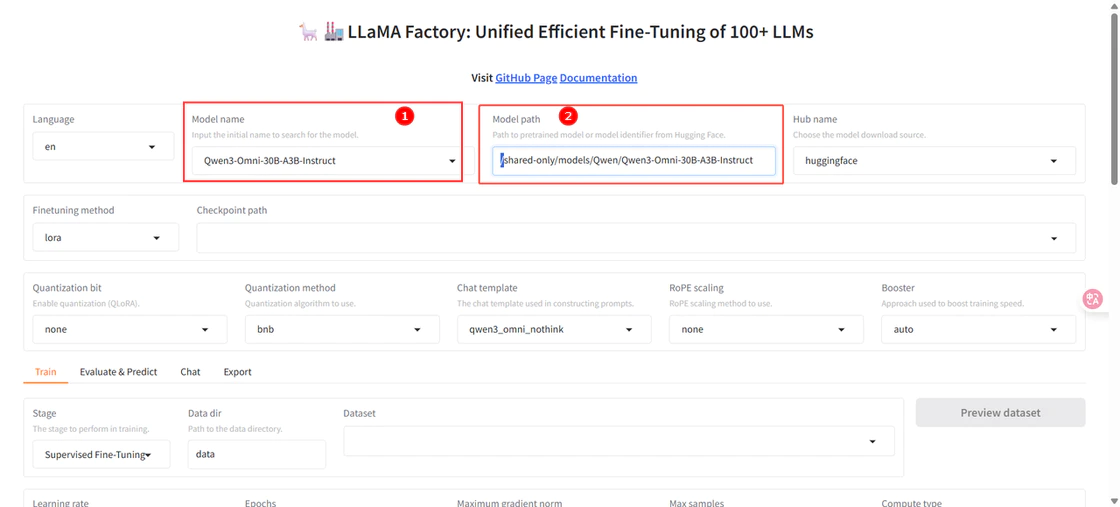
模型选择:
Qwen3-Omni-30B-A3B-Instruct,如图①; -
模型路径:在预置路径前加上
/shared-only/models/,如图②。
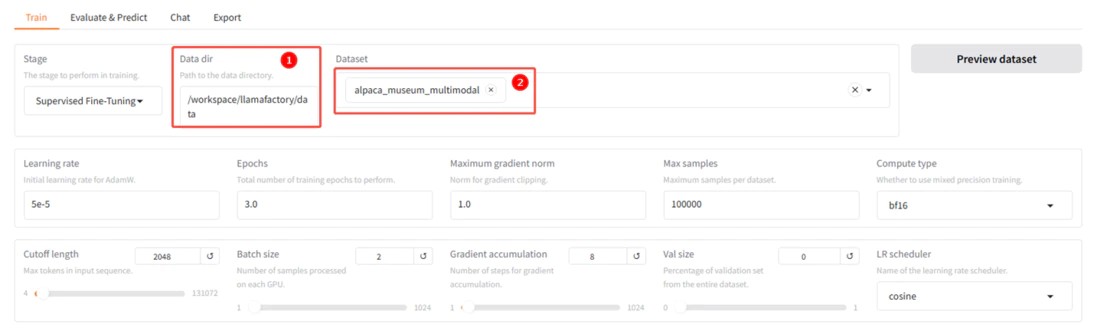
修改数据集路径,并加载数据集。
-
数据集路径:设置为
/workspace/llamafactory/data,如图①; -
数据集:选择内置的数据集
alpaca_museum_multimodal,如图②。
单击“开始(start)”,启动微调。
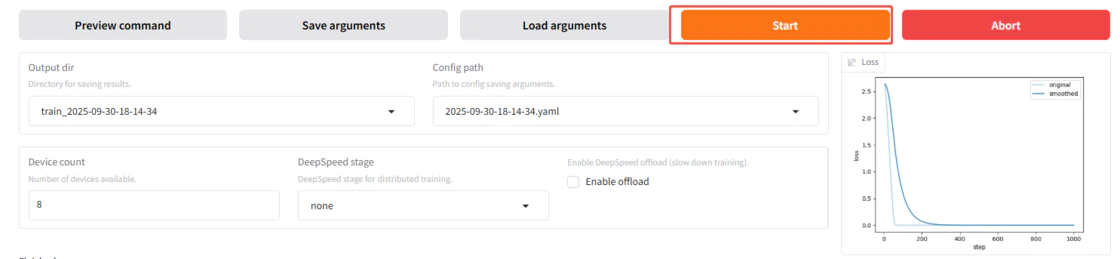
💡提示:训练的模型权重文件保存在/workspace/saves目录下,训练完成后可以在对应目录下找到模型文件。提示
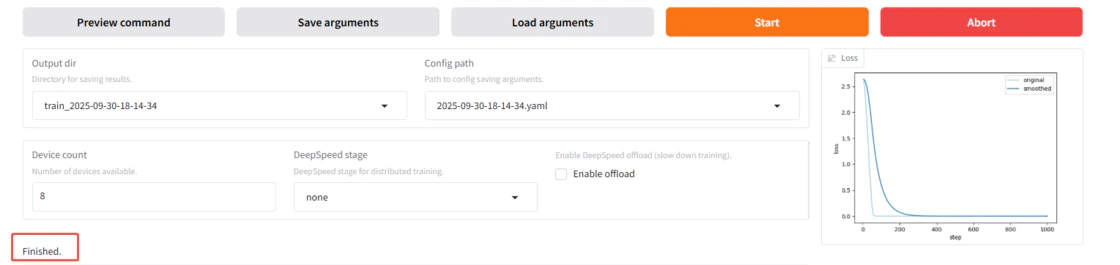
训练完成后如下图所示。
模型对话
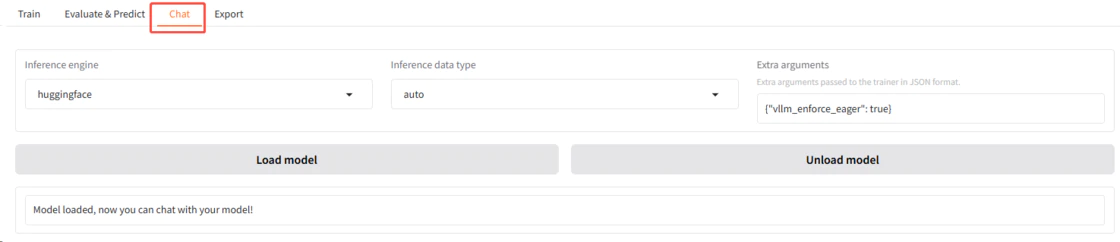
切换到对话(chat)页面,进行对话。
a. 单击“chat”页签,如下图所示。
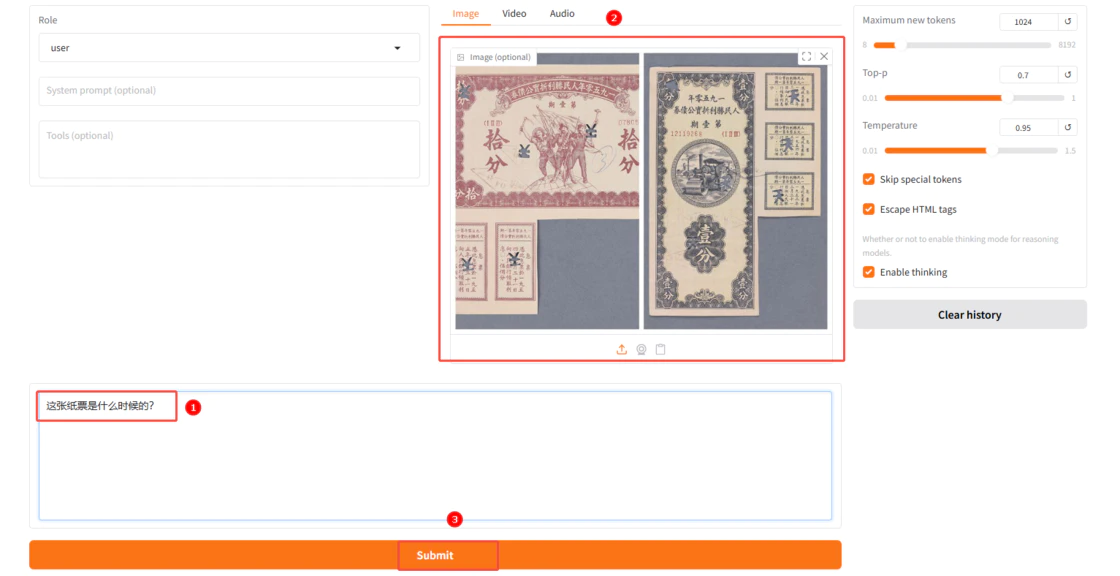
b. 输入您的问题(如图①),并且上传一张博物馆藏图片(如图②),然后单击“提交(submit)”(如图3)。
微调前的模型回答如下:
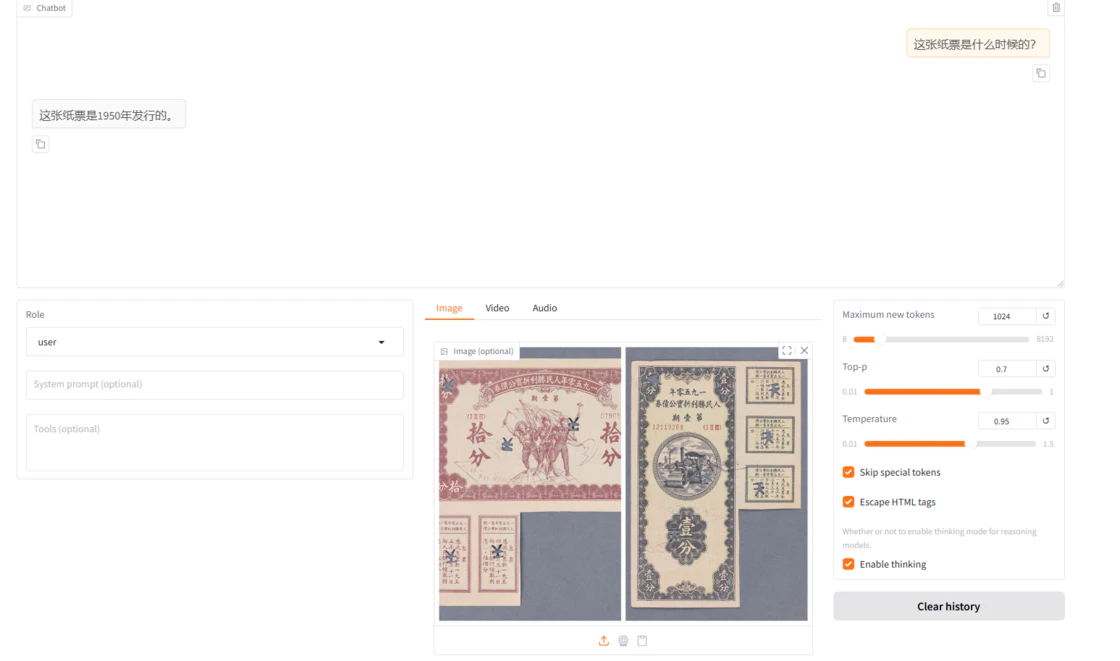
c. 单击“加载模型”按钮,加载微调后的模型,使用加载好的微调模型进行对话。输入同一个问题,观察模型回答,示例如下图所示。
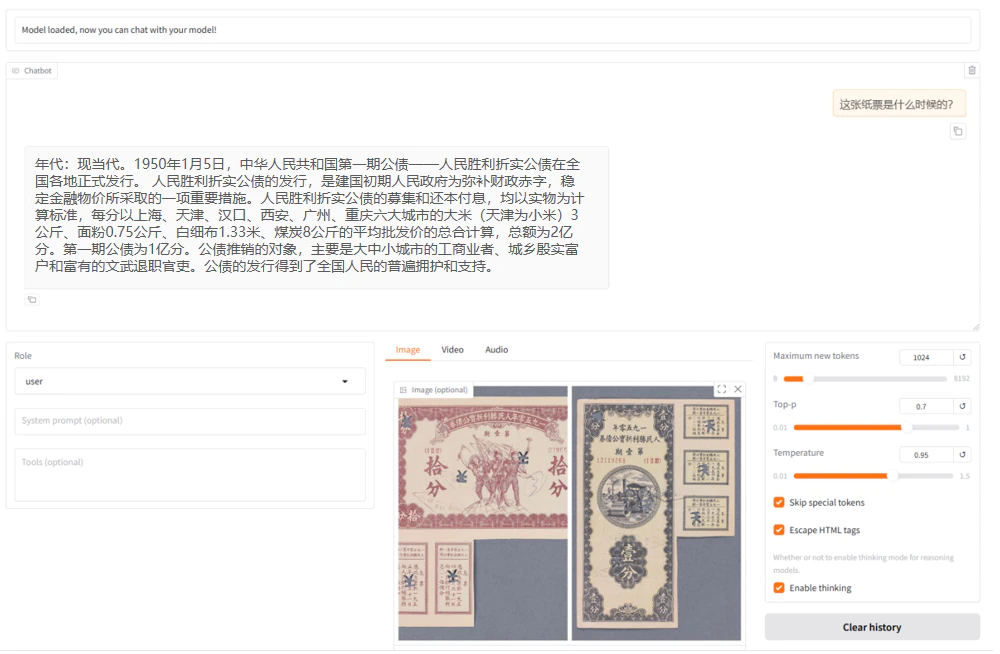
综合看来通过使用微调后的模型进行对话,可以获得更具参考价值的回答。相较于原生模型,后者往往提供的是宽泛且笼统的可能性描述,而经过特定任务或数据集微调的模型能够基于实际的图片场景生成更为精准、有针对性的回答。
总结
基于Qwen3-Omni-30B-A3B-Instruct模型微调,让每一位游客都能拥有 “私人文化顾问”:无需争抢资源,不必受制于固定流程,只需通过拍摄、语音等自然交互方式,便能获得深度、连贯且个性化的文化解读。这既是对十一黄金周博物馆服务压力的精准纾解,更是对 “从信息传递到文化共鸣” 的智能导览演进方向的生动实践,让文化遗产的魅力在科技赋能下真正触达人心。
微调的魅力就在于,它能让模型在特定领域内大放异彩。无论是用于客户服务、内容创作还是数据分析,一个经过精细微调的模型,都能带来超乎想象的效率提升。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)