视听导航文献整理(Audio-Visual Embodied Navigation)
小记:最近阅读了具身智能方向下,导航任务下的子任务:视听导航的相关文献。作为入门小白,记录了一些笔记,包括相关的会议信息、评估指标以及整理了我认为文献中的重点。由于想要锻炼阅读英文水平,所以记录的内容大多数是英文。
文章目录
- 前言
- Audio-Visual Embodied Navigation
-
- Conference
- Evaluate Metrics
- Audio-Visual Embodied Navigation
-
- (2020-03-08) Chuang Gan | Look, listen, and act: towards audio-visual embodied navigation
- (2020-08-21) Changan Chen | SoundSpaces: audio-visual navigation in 3D environments
- (2021-02-11) Changan Chen | Learning to set waypoints for audio-visual navigation
- (2021-04-07) Changan Chen | Semantic audio-visual navigation
- (2022) Yinfeng Yu | Sound adversarial audio-visual navigation
- (2022-10-05) Yinfeng Yu | Pay self-attention to audio-visual navigation
- (2023-01-03) Abdelrahman Younes | Catch me if you hear me: audio-visual navigation in complex unmapped environments with moving sounds
- (2023-01-23) Changan Chen | SoundSpaces 2.0: a simulation platform for visual-acoustic learning
前言
小记:最近阅读了具身智能方向下,导航任务下的子任务:视听导航的相关文献。作为入门小白,记录了一些笔记,包括相关的会议信息、评估指标以及整理了我认为文献中的重点。由于想要锻炼阅读英文水平,所以记录的内容大多数是英文。
Audio-Visual Embodied Navigation
Conference
classification
-
ICLR,
即国际学习表征会议(International Conference on Learning Representations),是一个自2013年起每年举办一次的国际会议,专注于深度学习和表征学习领域的研究。该会议已经成为深度学习领域的顶级会议之一,与AAAI、CVPR、ACL及NIPS等老牌学术会议齐名,并被中国计算机学会(CCF)评为一类会议 -
NeurIPS
(Neural Information Processing Systems )是神经信息处理系统会议和研讨会(之前也叫NIPS),每年举办一次。是机器学习领域的顶级会议,与ICML,ICLR并称为机器学习领域难度最大,水平最高,影响力最强的会议!NeurIPS是CCF 推荐A类会议,Core Conference Ranking推荐A*类会议,H5 index高达278! -
RAL
全称:IEEE Robotics and Automation Letters,IEEE机器人与自动化协会(IEEE Robotics & Automation Society, RAS)于2015年6月1日推出RAL期刊。因自2020年起,TRO便不再接收短文,所以许多短小精悍的工作会转投到RAL,因此RAL又被称为小TRO,但是说实话,从论文质量来看,RAL还是比TRO差很多的。但是能中一篇RAL也是非常厉害的,RAL只是比TRO差一些,但在机器人领域依然是TOP级别的期刊。RAL的影响因子自2019年的3.6一路飙升到2022年的5.2。机器人期刊的影响因子不能和材料化学领域内的期刊相比,他们的影响因子动不动十几,二十几的,毕竟领域不一样。 -
ICRA
IEEE International Conference on Robotics and Automation,即IEEE机器人和自动化国际会议,由IEEE Robotics and Automation Society (RAS,机器人和自动化学会)主办,该领域规模(千人以上)和影响力最大的顶级国际会议。 -
BMVC
British Machine Vision Conference (BMVC) 会议是 CCF C类会议。BMVC 其实已经有三十年的历史了,被公认为是继 ICCV/CVPR/ECCV 三大视觉顶会之后,排名第四的计算机视觉会议,很多知名教授(比如牛津大学的Andrew Zisserman)在 BMVC 上发表过很多文章。虽然它是一个国际会议,但名字里有个 British,所以很多人会误解它只是一个地区性会议,间接影响了投稿论文和参与者数量。 -
CVPR
CVPR全称是IEEE Conference on Computer Vision and Pattern Recognition,即IEEE国际计算机视觉与模式识别会议。该会议一般在6月举行,举办地是美国,是一个一年一次的会议。
Audio-Visual Embodied Navigation
-
ICLR
-
(2020-08-21) Changan Chen
SoundSpaces: audio-visual navigation in 3D environments -
(2021-02-11) Changan Chen
Learning to set waypoints for audio-visual navigation -
(2022) Yinfeng Yu
Sound adversarial audio-visual navigation
-
-
NeurIPS
- (2023-01-23) Changan Chen
SoundSpaces 2.0: a simulation platform for visual-acoustic learning
- (2023-01-23) Changan Chen
-
RAL
- (2023-01-03) Abdelrahman Younes
Catch me if you hear me: audio-visual navigation in complex unmapped environments with moving sounds
- (2023-01-03) Abdelrahman Younes
-
ICRA
- (2020-03-08) Chuang Gan
Look, listen, and act: towards audio-visual embodied navigation
- (2020-03-08) Chuang Gan
-
BMVC
- (2022-10-05) Yinfeng Yu
Pay self-attention to audio-visual navigation
- (2022-10-05) Yinfeng Yu
-
CVPR
- (2021-04-07) Changan Chen
Semantic audio-visual navigation
- (2021-04-07) Changan Chen
Evaluate Metrics
(2018-07-18) Peter Anderson
On evaluation of embodied navigation agents
-
three types of goals:
1 PointGoal
2 ObjectGoal
3 AreaGoal -
Generalization and Exploration
1 No prior exploration
2 Pre-recorded prior exploration
3 Time-limited exploration by the agent -
Evaluation Measures
1 The agent must be equipped with a special action that indicates that it has concluded the navigation episode and is ready to be evaluated.
2 SPL, short for Success weighted by (normalized inverse) Path Length.
Audio-Visual Embodied Navigation
- (2021-04-07) Changan Chen
Semantic audio-visual navigation
- success rate: the fraction of successful episodes;
- success weighted by inverse path length (SPL): the standard metric that weighs successes by their adherence to the shortest path;
- success weighted by inverse number of actions (SNA) : this penalizes collisions and in-place rotations by counting number of actions instead of path lengths;
- average distance to goal (DTG): the agent’s distance to the goal when episodes are finished;
- success when silent (SWS): the fraction of successful episodes when the agent reaches the goal after the end of the acoustic event.
-
(2022-10-05) Yinfeng Yu
Pay self-attention to audio-visual navigation -
(2023-01-03) Abdelrahman Younes
Catch me if you hear me: audio-visual navigation in complex unmapped environments with moving sounds- Dynamic Success weighted by Path Length (DSPL)
where i is the current episode count, N is the total number of episodes, Si represents whether this episode is successful or not, gi is the shortest geodesic distance between the agent’s start location and the closest position the agent could have caught the sound source at, and pi is the length of the path taken by the agent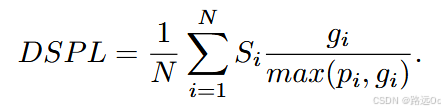
- Dynamic Success weighted by Path Length (DSPL)

Audio-Visual Embodied Navigation
(2020-03-08) Chuang Gan | Look, listen, and act: towards audio-visual embodied navigation
-
ENVIRONMENT
multi-modal virtual environment on top of the AI2-THOR platform ,
which contains a set of scenes built by using the Unity Game engine.
We further incorporate an spatial audio software development kit, Resonance Audio API ,
into the Unity game engine to support the audiovisual embodied navigation task.
An agent equipped with a camera and a microphone can then leverage two different sensing modalities (egocentric RGB images and sound) to perceive and navigate through the scenes. -
Problem Setup
explore-and-act and non-exploration for seeking the sound sources. -
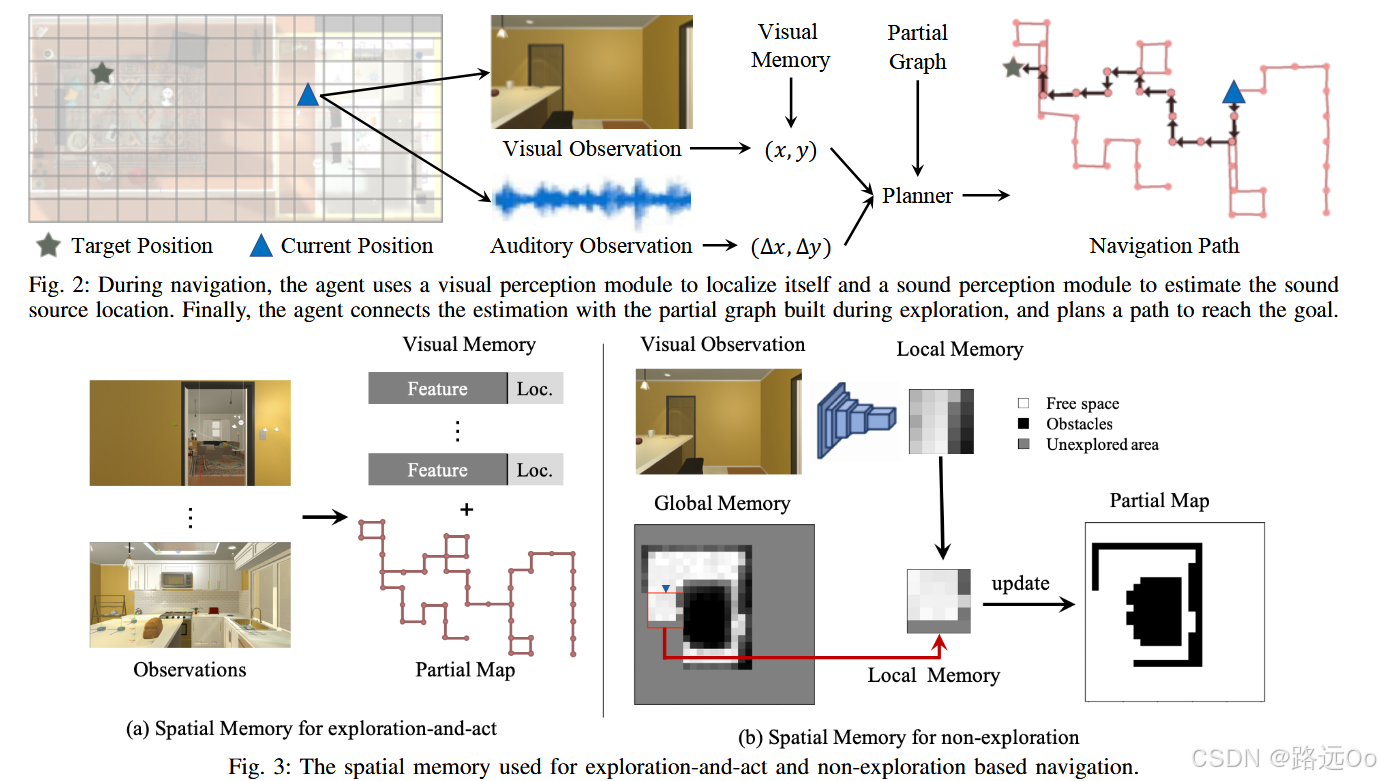
-
Greedy Search (A). This is a sound-only baseline.
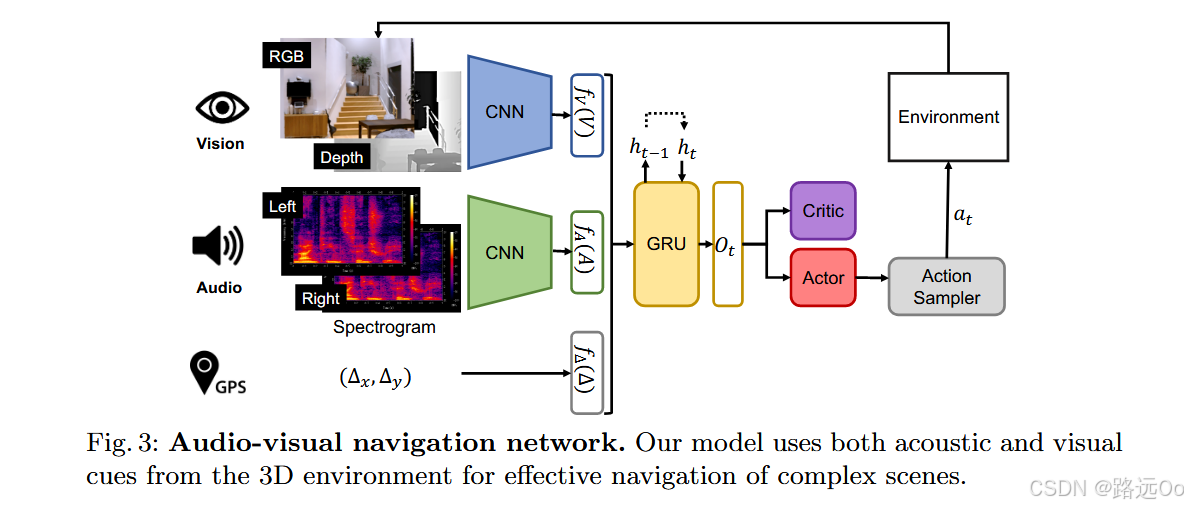
A3C (V) [45]. Asynchronous advantage actor-critic (A3C) is a state-of-the-art Deep RL based approach for navigation. This is a goal-oriented, vision-only navigation baseline without memory.
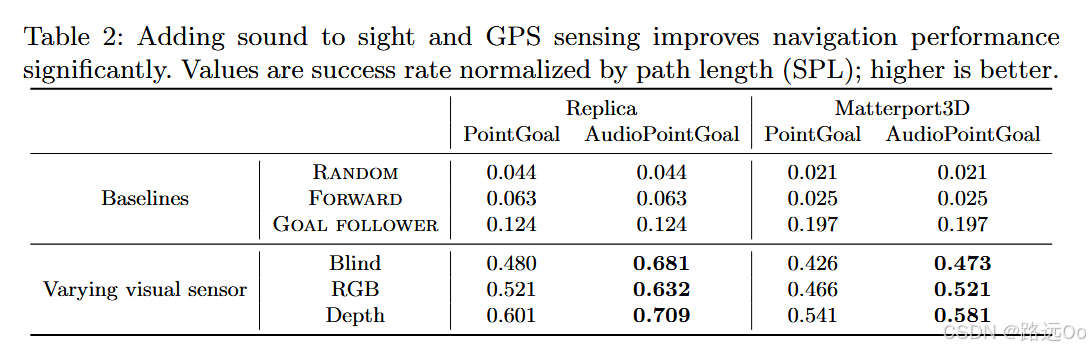
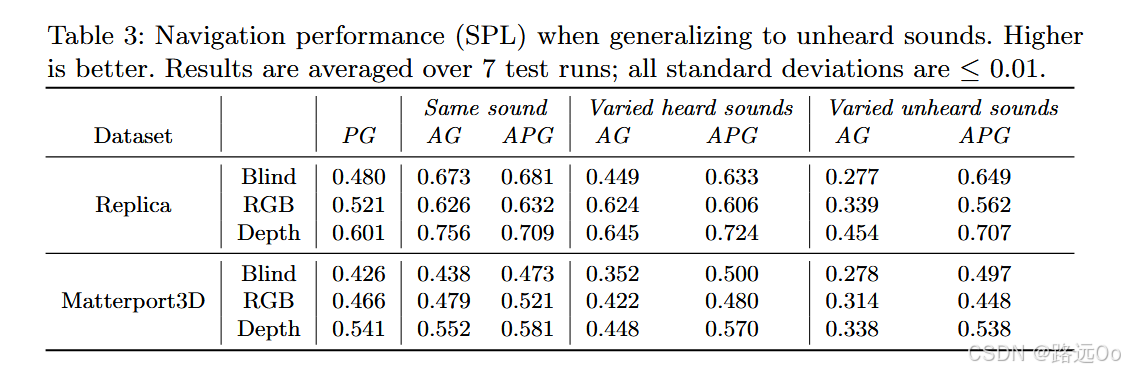
(2020-08-21) Changan Chen | SoundSpaces: audio-visual navigation in 3D environments
-
SoundSpaces: a first-of-its-kind dataset of audio renderings based on geometrical acoustic simulations for two sets of publicly available 3D environments (Matterport3D and Replica)
-
two variants of the navigation task:
(1) AudioGoal, where the target is indicated by the sound it emits,
(2) AudioPointGoal, where the agent is additionally directed towards the goal location at the onset. -
-

-
-
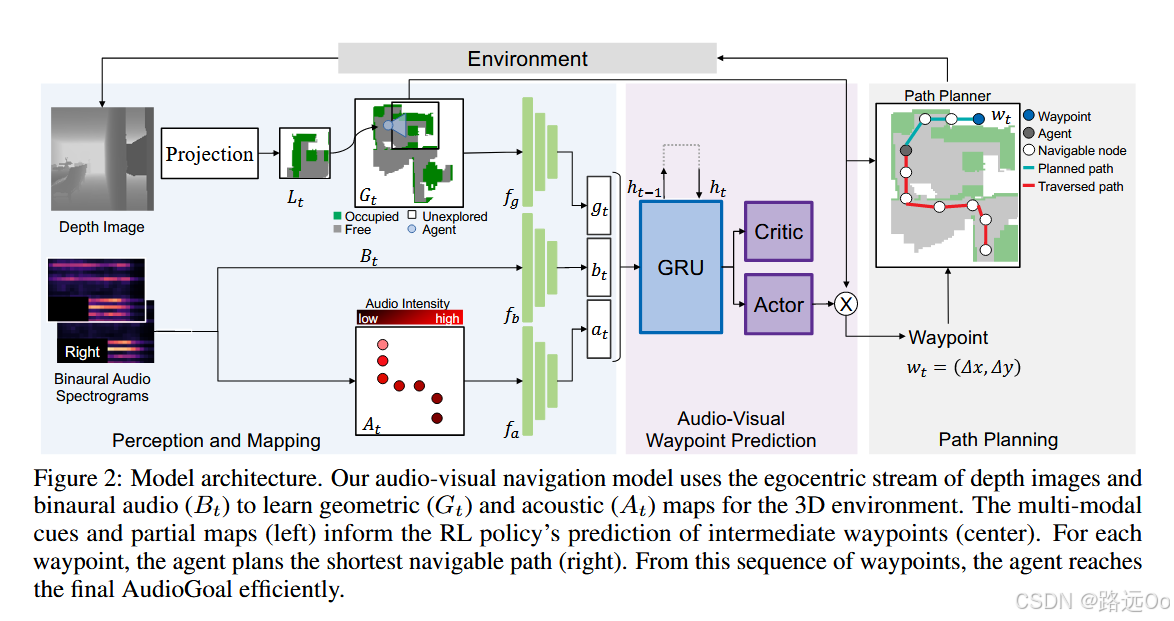
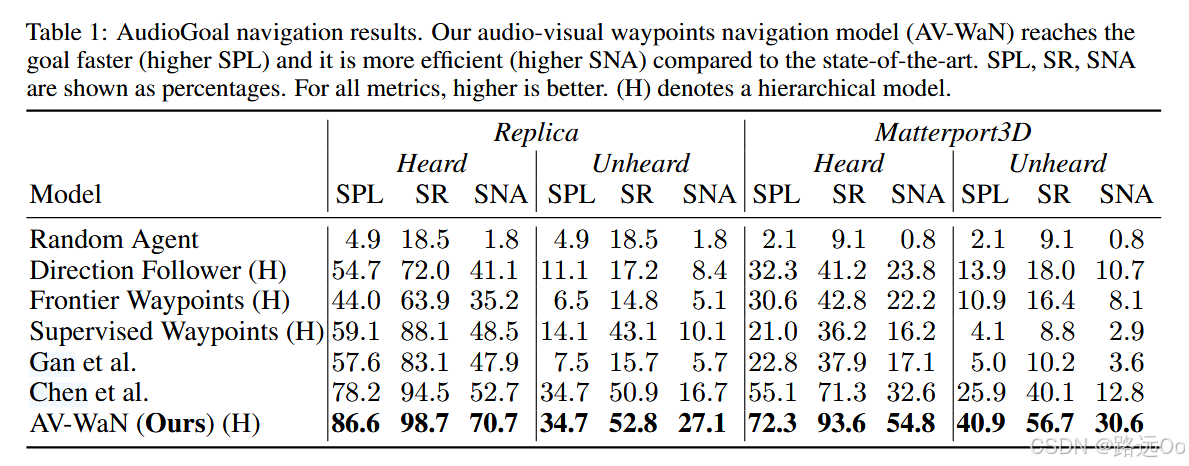
(2021-02-11) Changan Chen | Learning to set waypoints for audio-visual navigation
- a reinforcement learning approach to audio-visual navigation with two key novel elements:
- waypoints that are dynamically set and learned end-to-end within the navigation policy, and
- an acoustic memory that provides a structured, spatially grounded record of what the agent has heard as it moves.


(2021-04-07) Changan Chen | Semantic audio-visual navigation
-
semantic audio-visual navigation
objects in the environment make sounds consistent with their semantic meaning (e.g., toilet flushing, door creaking) and acoustic events are sporadic or short in duration -
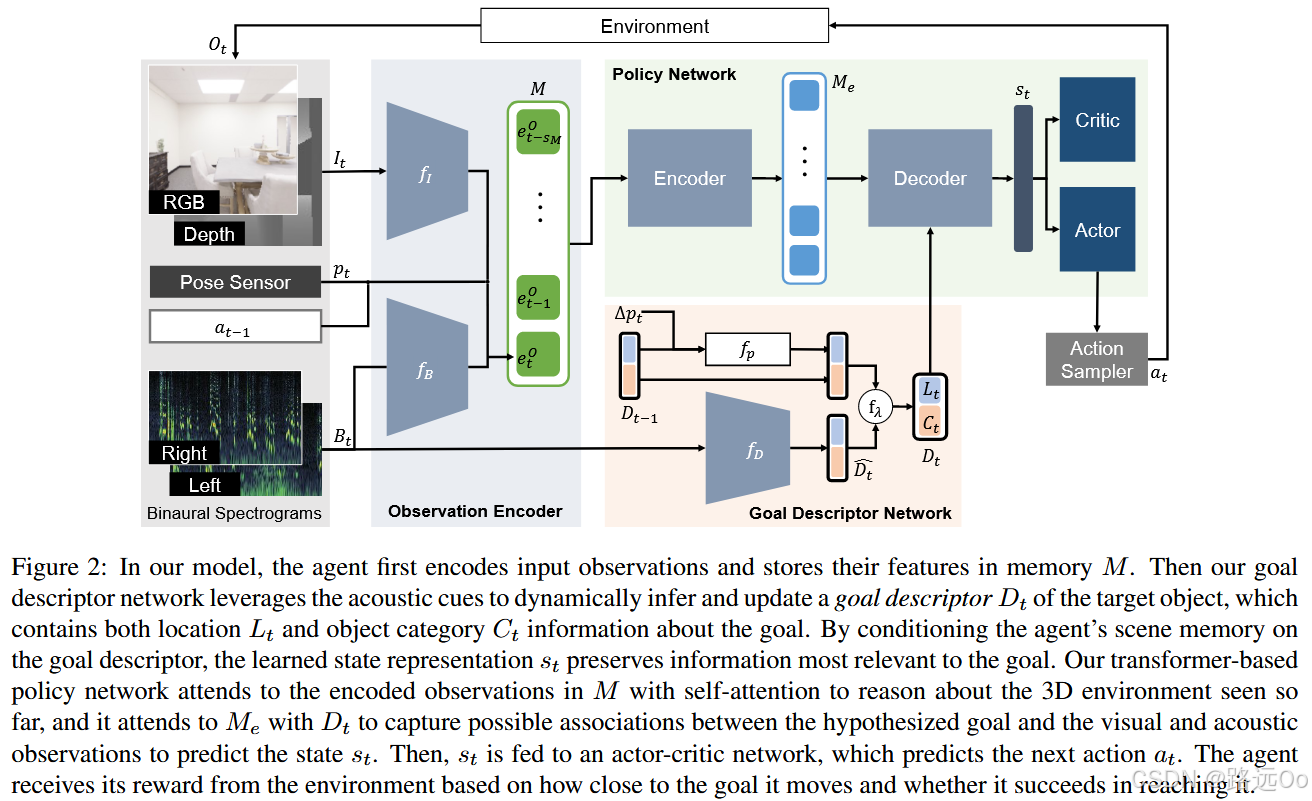
-
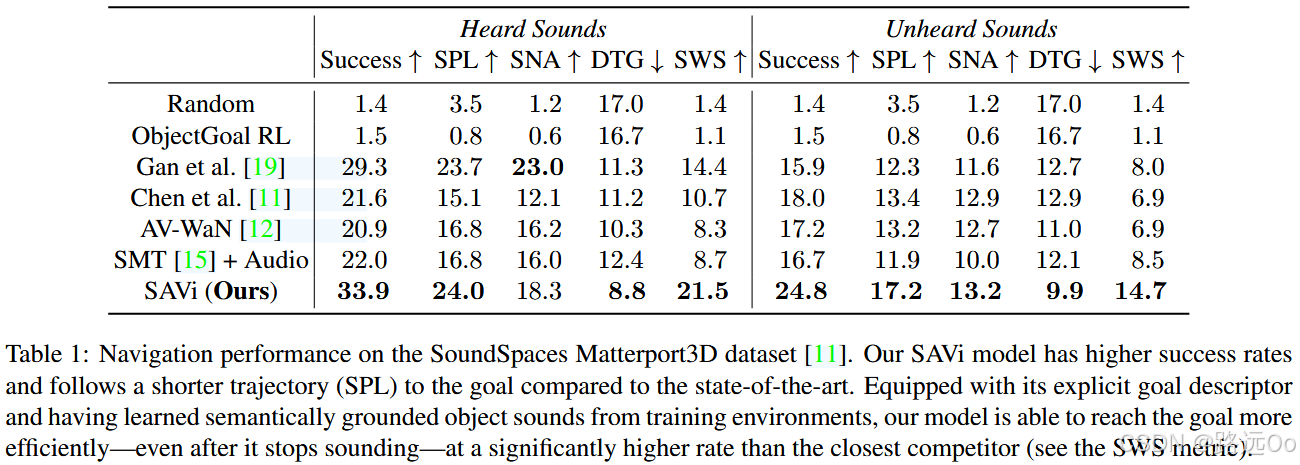
- success rate: the fraction of successful episodes;
- success weighted by inverse path length (SPL): the standard metric that weighs successes by their adherence to the shortest path;
- success weighted by inverse number of actions (SNA) : this penalizes collisions and in-place rotations by counting number of actions instead of path lengths;
- average distance to goal (DTG): the agent’s distance to the goal when episodes are finished;
- success when silent (SWS): the fraction of successful episodes when the agent reaches the goal after the end of the acoustic event.

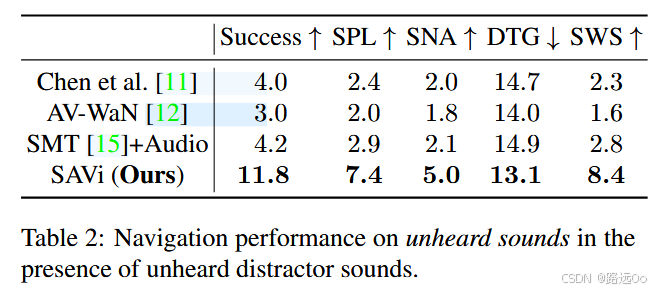
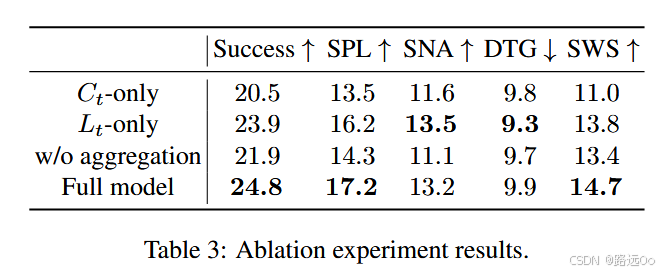
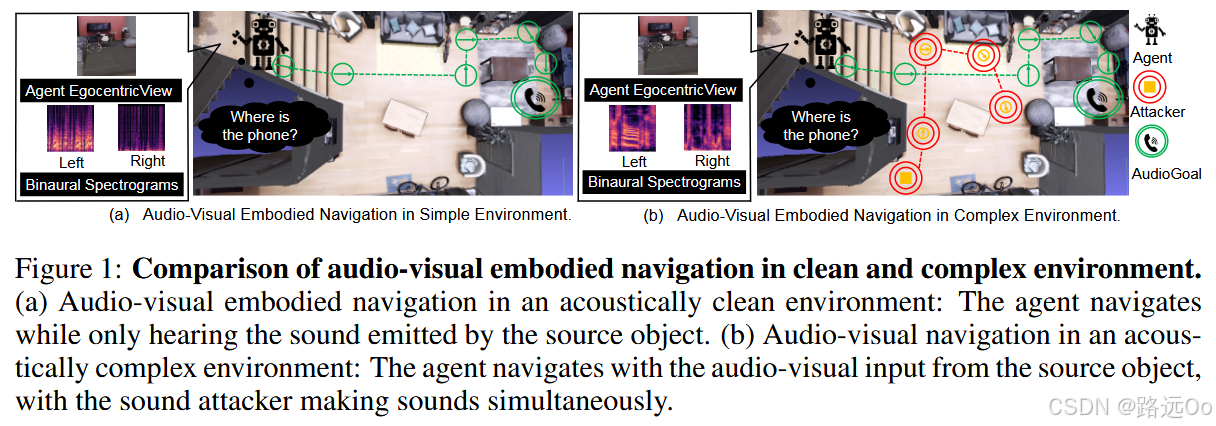
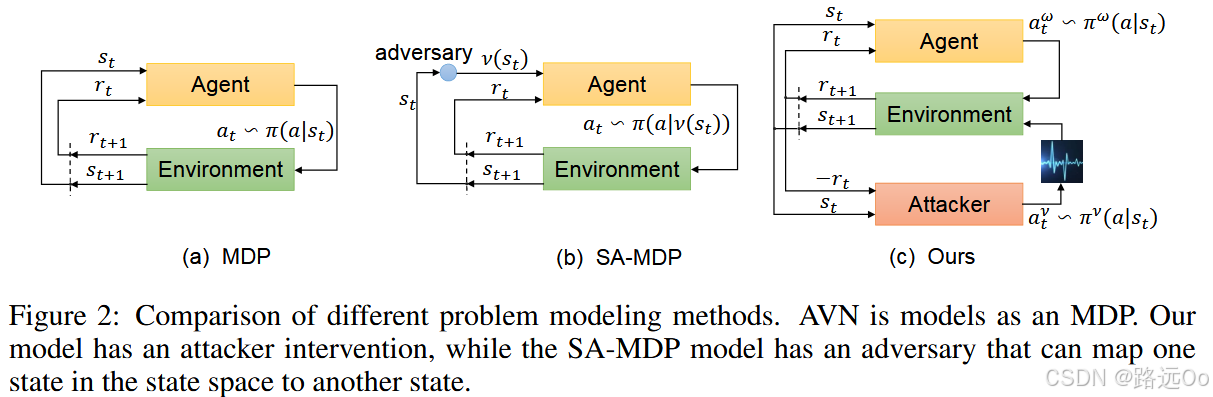
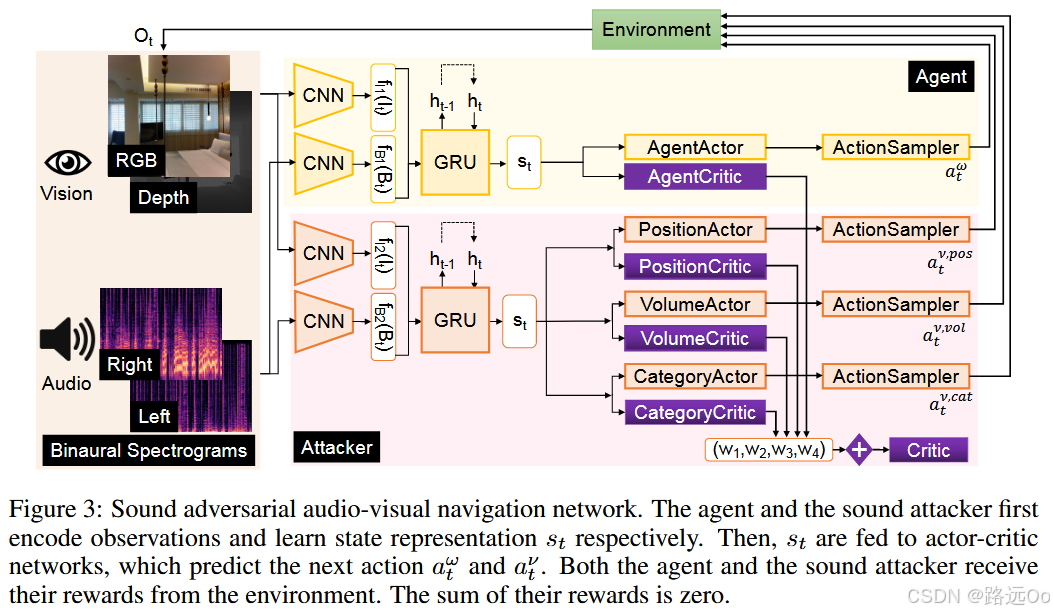
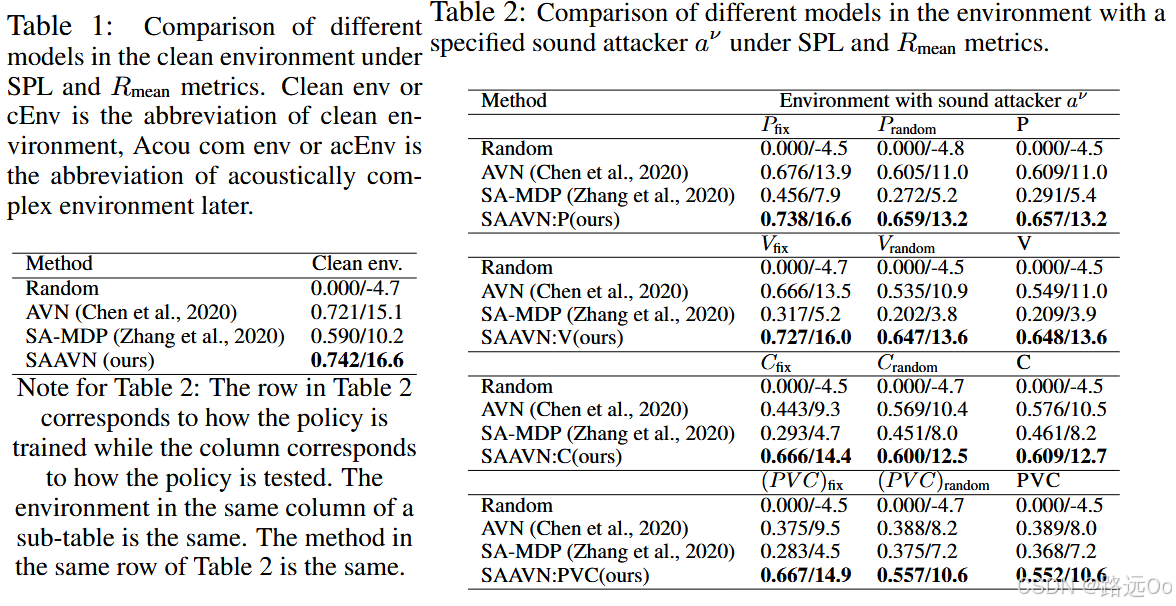
(2022) Yinfeng Yu | Sound adversarial audio-visual navigation
-
Sound Adversarial Audio-Visual Navigation (SAAVN)
construct a sound attacker to intervene environment for audio-visual navigation that aims to improve the agent’s robustness.
develop a joint training paradigm for the agent and the attacker. -
-
-
-
(2022-10-05) Yinfeng Yu | Pay self-attention to audio-visual navigation
-
propose a end-to-end framework (FSAAVN) to address a currently under-researched problem: audio-visual navigation to chase a moving sound target
design a novel audio-visual fusion module (FSA) to learn a context-aware strategy to determine the relative contribution of each modal in real-time -
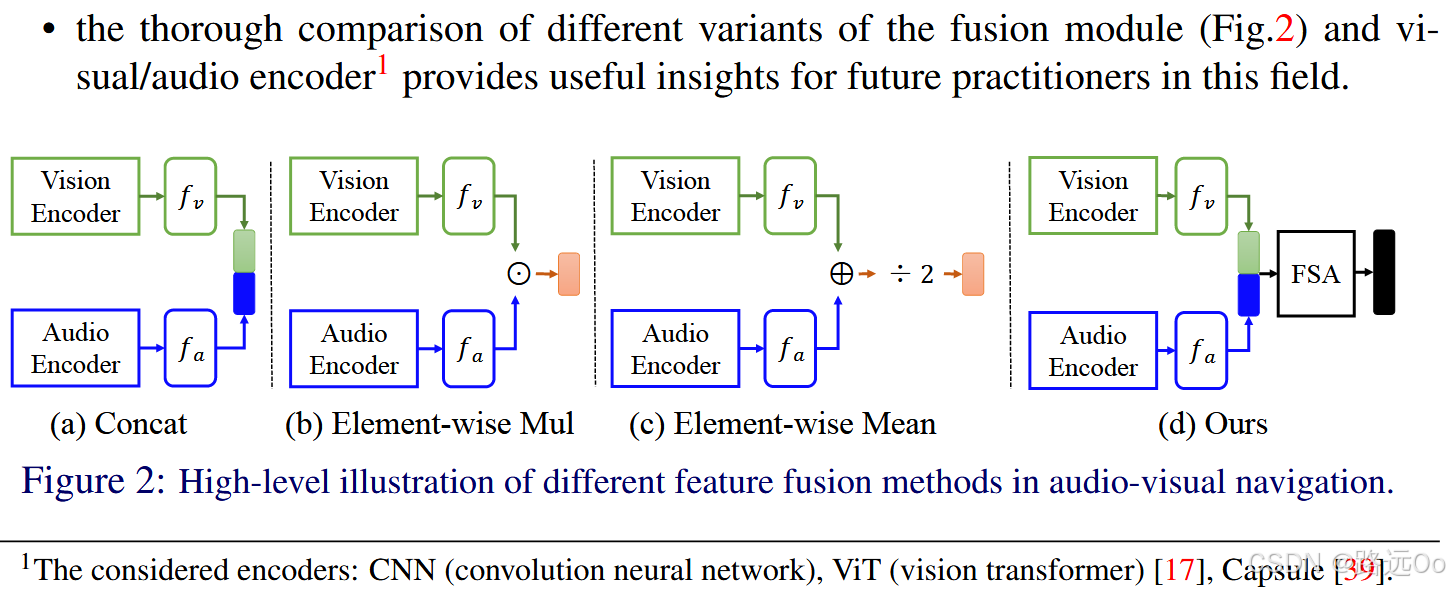
-

-
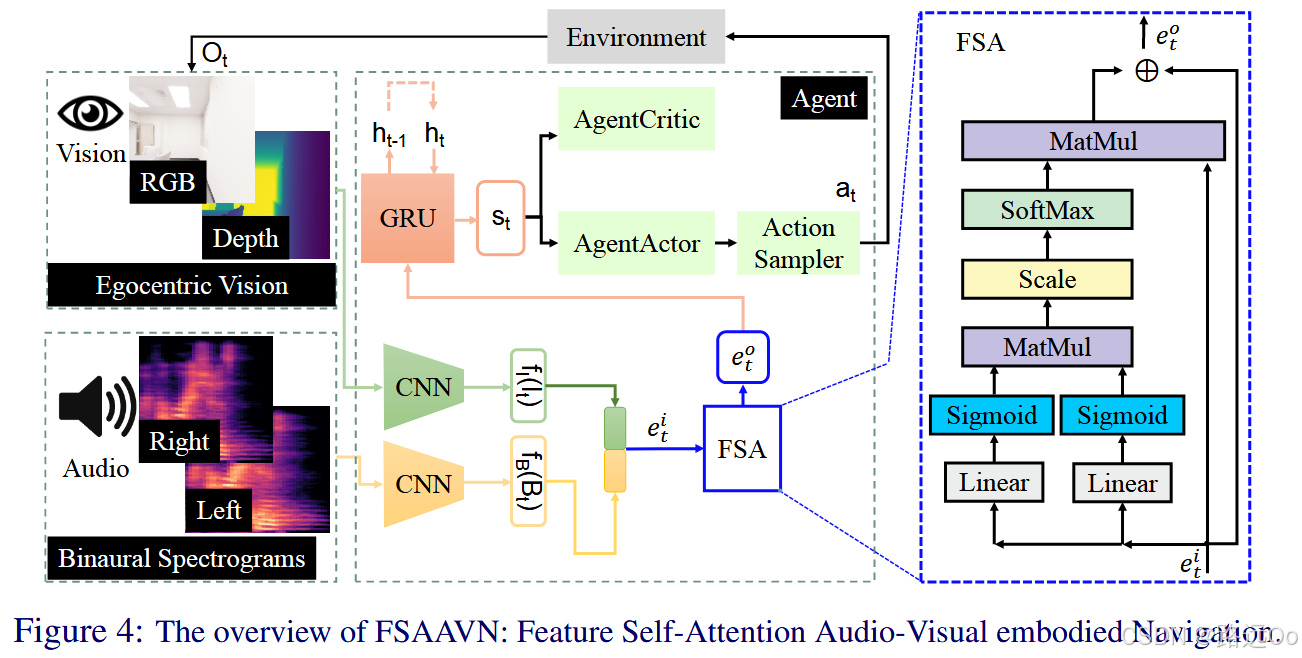
-

-
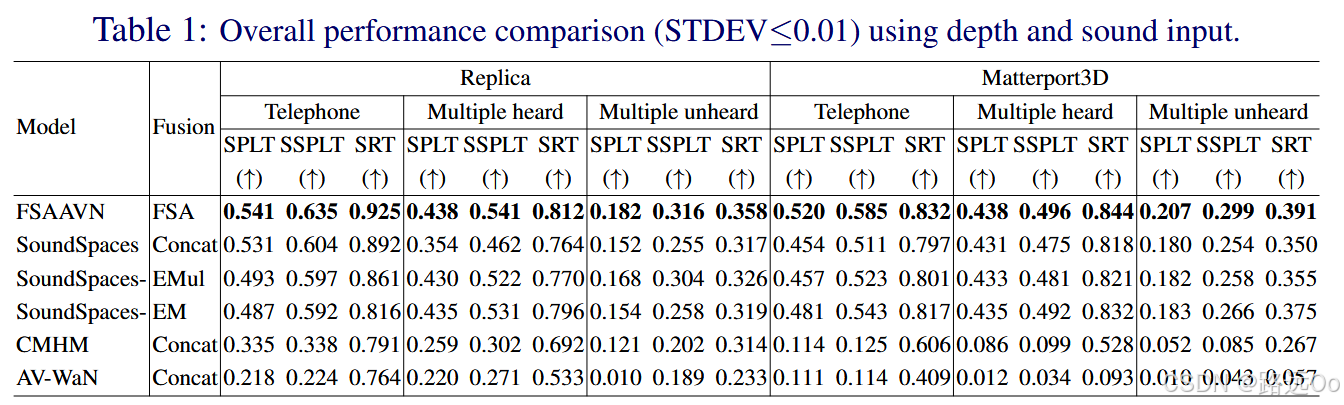
-
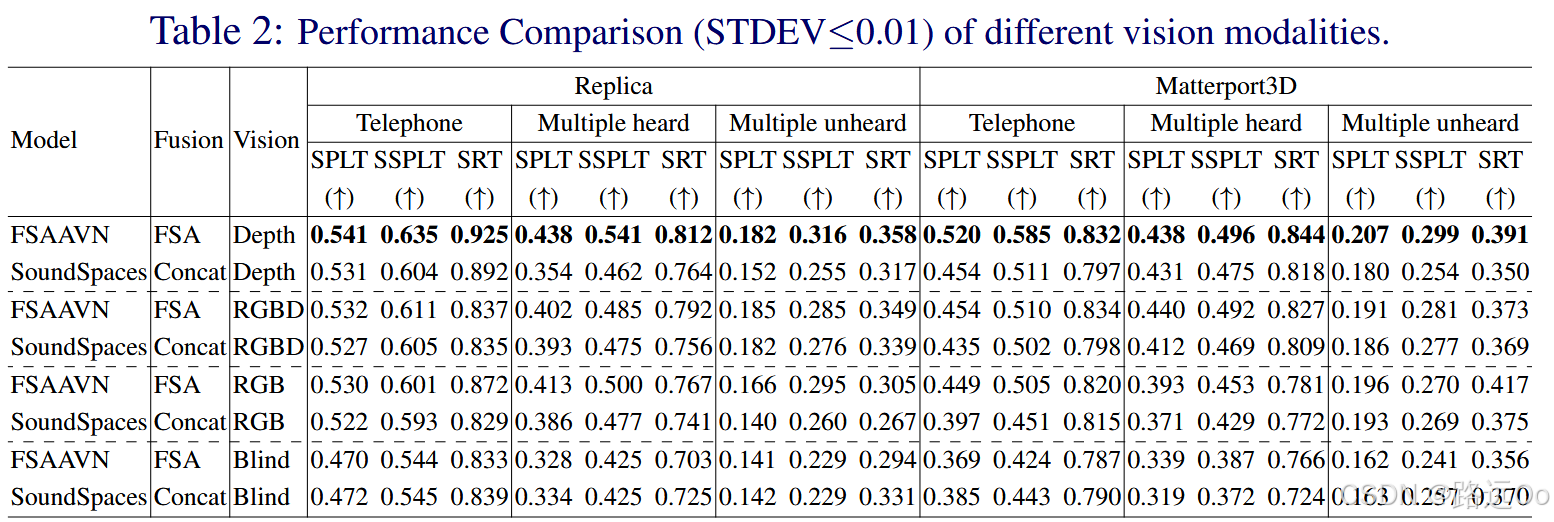
-
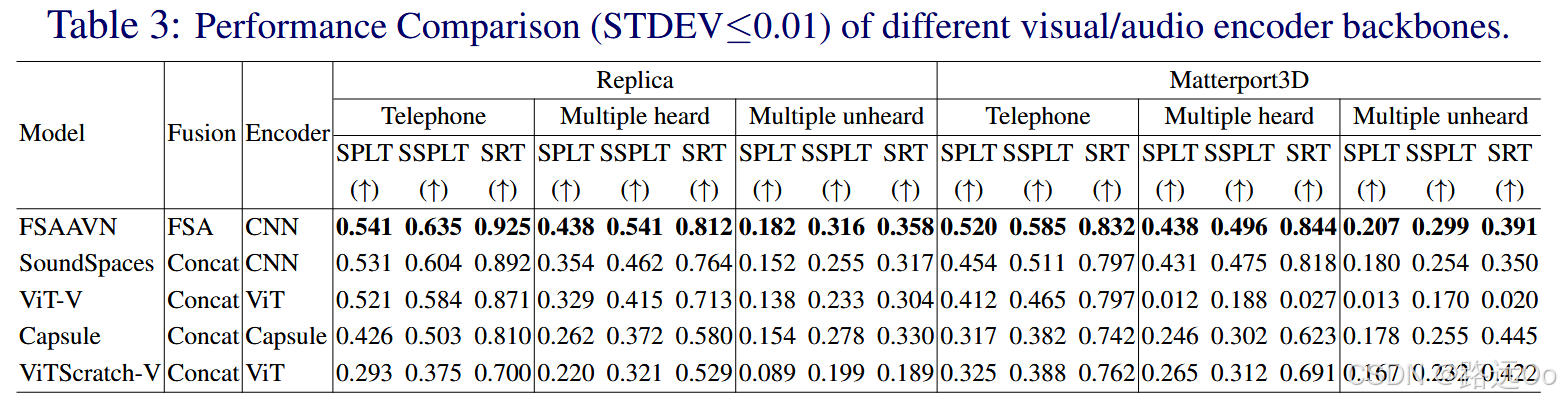
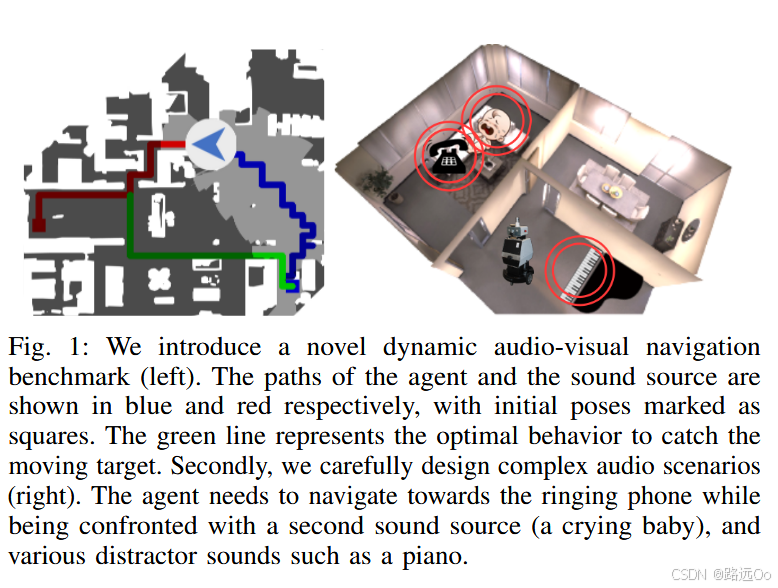
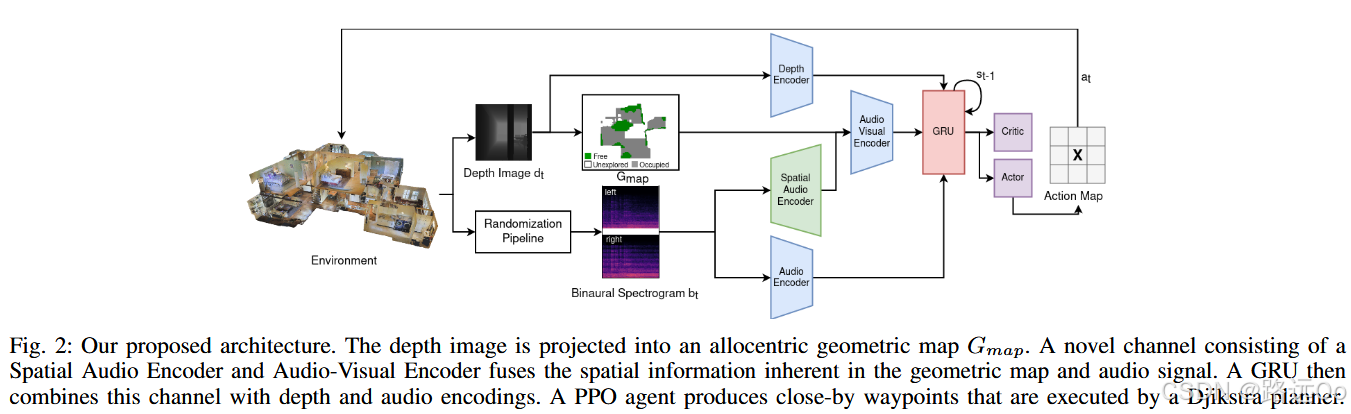
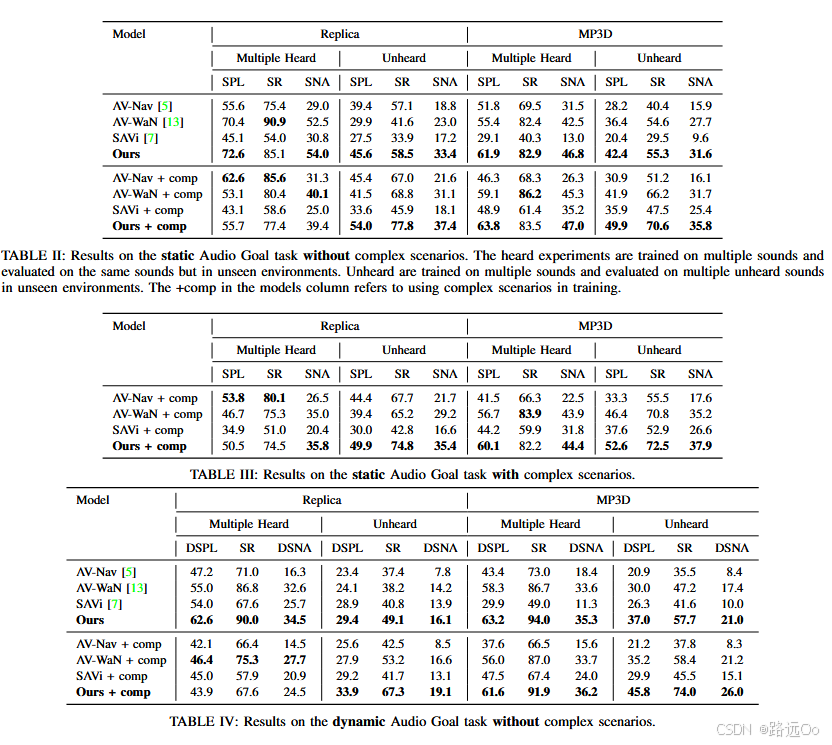
(2023-01-03) Abdelrahman Younes | Catch me if you hear me: audio-visual navigation in complex unmapped environments with moving sounds
-
novel dynamic audio-visual navigation benchmark which requires catching a moving sound source in an environment with noisy and distracting sounds.
novel task where the agent tracks a moving sound source using only acoustic and visual observations. -
Dynamic Success weighted by Path Length (DSPL)
where i is the current episode count, N is the total number of episodes, Si represents whether this episode is successful or not, gi is the shortest geodesic distance between the agent’s start location and the closest position the agent could have caught the sound source at, and pi is the length of the path taken by the agent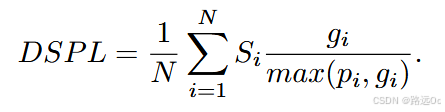
-
-

-
-

-
-

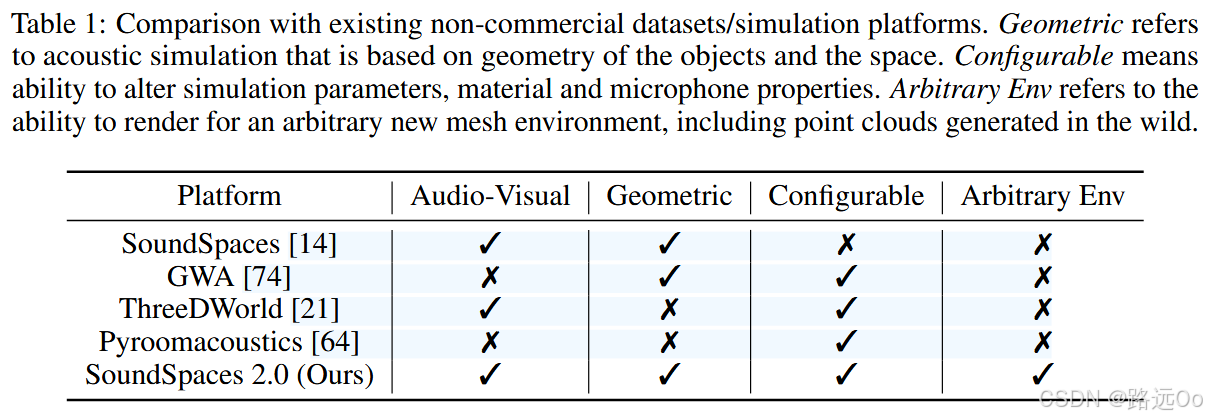
(2023-01-23) Changan Chen | SoundSpaces 2.0: a simulation platform for visual-acoustic learning
-
SoundSpaces 2.0, a platform for on-the-fly geometry-based audio rendering for 3D environments.
SoundSpaces 2.0, which performs on-the-fly geometry-based audio rendering for arbitrary environments. It allows highly realistic rendering of arbitrary camera views and arbitrary microphone placements for waveforms of the user’s choosing, accounting for all major real-world acoustic factors: direct sounds, early specular/diffuse reflections, reverberation, binaural spatialization, and frequency-dependent effects from materials and air absorption
-
-
3 SoundSpaces 2.0 Audio-Visual Rendering Platform
-
3.1 Rendering Pipeline and Simulation Enhancements
-
3.2 Continuity
-
Spatial continuity.
-
Acoustic continuity.
-
-
3.3 Configurability
-
Simulation parameters.
-
Microphone types.
-
Custom HRTFs.
head-related transfer functions (HRTFs) -
Material modeling.
-
-
3.4 Generalizability
-
Generalization to scene datasets.
(e.g., Gibson [81], HM3D [59], Ego4D [26], Matterport3D [11], Replica [71]), as well as any future assets that become available -
Generalization to shoebox rooms.
-
Generalization to the real world.
-
-
-

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)