揭秘OpenCV图像处理
图像预处理
一、HSV颜色空间
HSV颜色空间指的是HSV颜色模型,这是一种与RGB颜色模型并列的颜色空间表示法。RGB颜色模型使用红、绿、蓝三原色的强度来表示颜色,是一种加色法模型,即颜色的混合是添加三原色的强度。而HSV颜色空间使用色调(Hue)、饱和度(Saturation)和亮度(Value)三个参数来表示颜色,色调H表示颜色的种类,如红色、绿色、蓝色等;饱和度表示颜色的纯度或强度,如红色越纯,饱和度就越高;亮度表示颜色的明暗程度,如黑色比白色亮度低。
HSV颜色模型是一种六角锥体模型,如下图所示: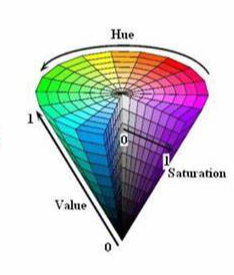
色调H:
使用角度度量,取值范围为0°~360°,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°。它们的补色是:黄色为60°,青色为180°,紫色为300°。通过改变H的值,可以选择不同的颜色
饱和度S:
饱和度S表示颜色接近光谱色的程度。一种颜色可以看成是某种光谱色与白色混合的结果。其中光谱色所占的比例越大,颜色接近光谱色的程度就越高,颜色的饱和度就越高。饱和度越高,颜色就越深而艳,光谱色的白光成分为0,饱和度达到最高。通常取值范围为0%~100%,其中0%表示灰色或无色,100%表示纯色,通过调整饱和度的值,可以使颜色变得更加鲜艳或者更加灰暗。
明度V:
明度表示颜色明亮的程度,对于光源色,明度值与发光体的光亮度有关;对于物体色,此值和物体的透射比或反射比有关。通常取值范围为0%(黑)到100%(白),通过调整明度的值,可以使颜色变得更亮或者更暗。
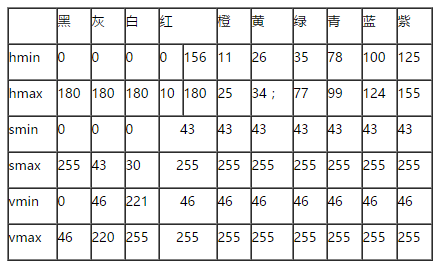
一般对颜色空间的图像进行有效处理都是在HSV空间进行的,然后对于基本色中对应的HSV分量需要给定一个严格的范围,下面是通过实验计算的模糊范围(准确的范围在网上都没有给出)。
H: 0— 180
S: 0— 255
V: 0— 255
此处把部分红色归为紫色范围:
为什么有了RGB颜色空间我们还是需要转换成HSV颜色空间来进行图像处理呢?
- 符合人类对颜色的感知方式:人类对颜色的感知是基于色调、饱和度和亮度三个维度的,而HSV颜色空间恰好就是通过这三个维度来描述颜色的。因此,使用HSV空间处理图像可以更直观地调整颜色和进行色彩平衡等操作,更符合人类的感知习惯。
- 颜色调整更加直观:在HSV颜色空间中,色调、饱和度和亮度的调整都是直观的,而在RGB颜色空间中调整颜色不那么直观。例如,在RGB空间中要调整红色系的颜色,需要同时调整R、G、B三个通道的数值,而在HSV空间中只需要调整色调和饱和度即可。
- 降维处理有利于计算:在图像处理中,降维处理可以减少计算的复杂性和计算量。HSV颜色空间相对于RGB颜色空间,减少了两个维度(红、绿、蓝),这有利于进行一些计算和处理任务,比如色彩分割、匹配等。
因此,在进行图片颜色识别时,我们会将RGB图像转换到HSV颜色空间,然后根据颜色区间来识别目标颜色。
1.1、颜色空间转换cv.cvtColor(src,code,dst,dstCn)
参数解释:
src:输入图像(需要转换的原始图像)code:转换代码(指定转换类型,如cv.COLOR_BGR2GRAY表示 BGR→灰度图)
dst(可选):输出图像(若不指定,函数会自动创建)dstCn(可选):输出图像的通道数,默认-1表示自动根据输入图像和转换代码确定
import cv2 as cv
# 读取图像
img = cv.imread('../images/flower.png')
# 转换为灰度图像
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# 转HSV
hsv = cv.cvtColor(img,cv.COLOR_BGR2HSV)
# 转RGB
rgb = cv.cvtColor(img,cv.COLOR_BGR2RGB)
cv.imshow('img',img)
cv.imshow('gray', gray)
cv.imshow('hsv', hsv)
cv.imshow('rgb', rgb)
cv.waitKey(0)
cv.destroyAllWindows()
| BGR |  |
|---|---|
| GRAY |  |
| HSV |  |
| RGB |  |
二、颜色加法
颜色加法常用于图像融合、增强、叠加等操作,主要方式有 OpenCV 和 NumPy 两种。两者虽结果类似,但底层处理逻辑不同。
在图像处理中,最常见的就是RGB颜色空间。RGB颜色空间是我们接触最多的颜色空间,是一种用于表示和显示彩色图像的一种颜色模型。RGB代表红色(Red)、绿色(Green)和蓝色(Blue),这三种颜色通过不同强度的光的组合来创建其他颜色,广泛应用于我们的生活中,比如电视、电脑显示屏以及上面实验中所介绍的RGB彩色图。
RGB颜色模型基于笛卡尔坐标系,如下图所示,RGB原色值位于3个角上,二次色青色、红色和黄色位于另外三个角上,黑色位于原点处,白色位于离原点最远的角上。因为黑色在RGB三通道中表现为(0,0,0),所以映射到这里就是原点;而白色是(255,255,255),所以映射到这里就是三个坐标为最大值的点。
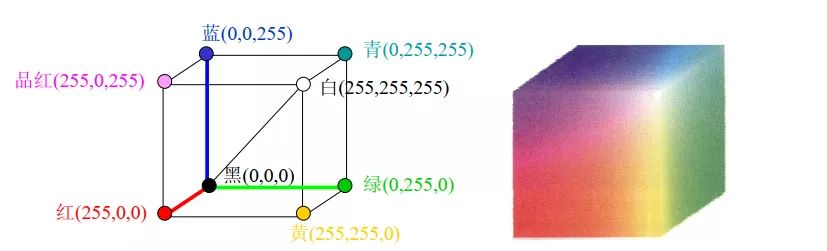
RGB颜色空间可以产生大约1600万种颜色,几乎包括了世界上的所有颜色,也就是说可以使用RGB颜色空间来生成任意一种颜色。
注意:在OpenCV中,颜色是以BGR的方式进行存储的,而不是RGB,这也是上面红色的像素值是(0,0,255)而不是(255,0,0)的原因。
2.1、基本概念
颜色加法是指将两个图像中对应位置的像素值进行加法运算,得到一个新的图像。
- 输入要求:两个图像数组必须具有相同的维度(shape),或能通过广播机制对齐。
- 输出结果:新的图像数组,每个像素值是输入图像对应位置像素值的“加和”。
2.2、基础图像加法方法
| cao | pig |
|---|---|
 |
 |
1️⃣ OpenCV 加法:cv.add(img1, img2)
-
运算规则:逐元素相加,并执行饱和截断操作
-
适用场景:安全图像加法(防止像素溢出)
-
示例:
dst1 = cv.add(cao, pig)
小猪为什么呈现出很亮的颜色?,我们发现小猪背景色为黑色,根据前面的知识知道黑色的通道为(0,0,0)在进行加操作时,背景就自动替换成我们的草地图片,在进行opencv的
cv.add()时是进行饱和操作,故通道的值会整体偏高,但不超过255。我们知道白色是(255,255,255),所以我们进行操作时会无限接近于白色,所以会越来越白(亮)。 -
举例分析:
x = np.uint8([[250]]) y = np.uint8([[10]]) cv.add(x, y) → [[255]]
2️⃣ NumPy 加法:img1 + img2
-
运算规则:逐元素相加,但执行模运算(对256取模)
-
适用场景:了解像素溢出特性、做特殊效果时使用
-
示例:
dst2 = cao + pig
-
举例分析:
x + y → [[4]] # 因为 (250 + 10) % 256 = 4
从图像来进行分析为什么小猪会变得很蓝?我认为应该是小猪的红色值很高,草地的绿色值很高,两个一加超过了256,导致R,G通道的值偏低,而蓝色通道的值偏高所以呈现出蓝色
2.3、加权图像加法
3️⃣ 加权加法cv.addWeighted()
-
语法:
cv.addWeighted(src1, alpha, src2, beta, gamma) -
公式:dst=alpha∗src1+beta∗src2+gammadst = alpha * src1 + beta * src2 + gammadst=alpha∗src1+beta∗src2+gamma
-
含义:
alpha、beta:两个图像的权重;gamma:可选亮度偏移;
-
作用:常用于图像融合、图像淡入淡出、透明度控制等场景。
-
示例:
dst3 = cv.addWeighted(cao, 0.3, pig, 0.7, 10)
2.4、三种方法对比总结表
| 方法名 | 接口名 | 饱和处理 | 支持权重 | 支持偏移 | 备注 |
|---|---|---|---|---|---|
| OpenCV 加法 | cv.add() |
✅ 是 | ❌ 否 | ❌ 否 | 防止像素值溢出 |
| NumPy 加法 | img1 + img2 |
❌ 否(模运算) | ❌ 否 | ❌ 否 | 更快,适合特殊效果 |
| 加权图像加法 | cv.addWeighted() |
✅ 是 | ✅ 是 | ✅ 是 | 图像融合首选方式 |
2.5、注意事项
-
图像形状必须一致:
- 图像
img1.shape == img2.shape,才能逐像素相加。 - 若不一致,可使用 OpenCV 的
resize()或 NumPy 的广播机制。
- 图像
-
可利用广播机制:
- 若某一图像的维度为 1(如
(1, 3)或(1, H, W, 3)),NumPy 会尝试自动扩展; - 用于快速与常数或通道向量相加。
例如:
img + np.array([10, 0, 0]) # 给所有像素的R通道加10 - 若某一图像的维度为 1(如
-
数据类型:
- 图像通常是
uint8类型,加法可能溢出,需注意类型和范围; - 若不希望发生溢出,可先转成
int16进行计算,再剪裁/归一化后转回。
- 图像通常是
三、灰度实验
我们了解了如何在计算机中存储和渲染一张彩色图像,并认识到彩色图像是由红色(R)、绿色(G)和蓝色(B)三个通道共同组成的,那么已有的彩色图是怎么变成灰度图呢?
首先我们需要知道灰度图与彩色图有什么不同。灰度图与彩色图最大的不同就是:彩色图是由R、G、B三个通道组成,而灰度图只有一个通道,也称为单通道图像,所以彩色图转成灰度图的过程本质上就是将R、G、B三通道合并成一个通道的过程。本实验中一共介绍了三种合并方法,分别是最大值法、平均值法以及加权均值法。
3.1、最大值法
对于彩色图像的每个像素,它会从R、G、B三个通道的值中选出最大的一个,并将其作为灰度图像中对应位置的像素值。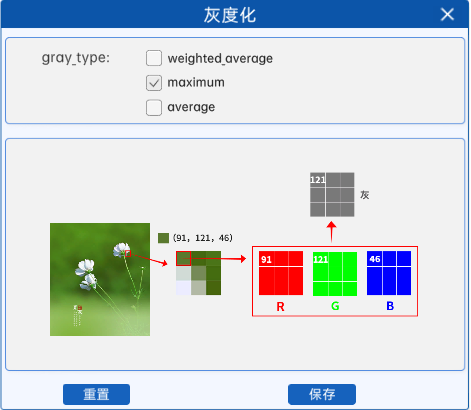
例如某图像中某像素点的像素值如上图所示,那么在使用最大值法进行灰度化时,就会从该像素点对应的RGB通道中选取最大的像素值作为灰度值,所以在灰度图中的对应位置上,该像素点的像素值就是121。
import cv2 as cv
import numpy as np
# 读取图像
flower = cv.imread('../images/flower.png')
shape = flower.shape # 获取图像的形状(h, w, c)
img = np.zeros(shape=(shape[0], shape[1]), dtype=np.uint8)
# 循环遍历每一行
for i in range(shape[0]):
for j in range(shape[1]):
img[i][j] = max(flower[i, j, 0], flower[i, j, 1], flower[i, j, 2])
cv.imshow('gray_flower', img)
cv.waitKey(0)
cv.destroyAllWindows()

3.2、平均值法
对于彩色图像的每个像素,它会将R、G、B三个通道的像素值全部加起来,然后再除以三,得到的平均值就是灰度图像中对应位置的像素值。
例如某图像中某像素点的像素值如上图所示,那么在使用平均值进行灰度化时,其计算结果就是(91+121+46)/3=86(对结果进行取整),所以在灰度图中的对应位置上,该像素点的像素值就是86。
import cv2 as cv
import numpy as np
# 读取图像
flower = cv.imread('../images/flower.png')
shape = flower.shape # 获取图像的形状(h, w, c)
img = np.zeros(shape=(shape[0], shape[1]), dtype=np.uint8)
# 循环遍历每一行
for i in range(shape[0]):
for j in range(shape[1]):
# int(): 防止溢出问题
img[i, j] = (int(flower[i, j, 0]) + int(flower[i, j, 1]) + int(flower[i, j, 2])) // 3
cv.imshow('gray_flower', img)
cv.waitKey(0)
cv.destroyAllWindows()

3.3、加权均值法
对于彩色图像的每个像素,它会按照一定的权重去乘以每个通道的像素值,并将其相加,得到最后的值就是灰度图像中对应位置的像素值。本实验中,权重的比例为: R乘以0.299,G乘以0.587,B乘以0.114,这是经过大量实验得到的一个权重比例,也是一个比较常用的权重比例。
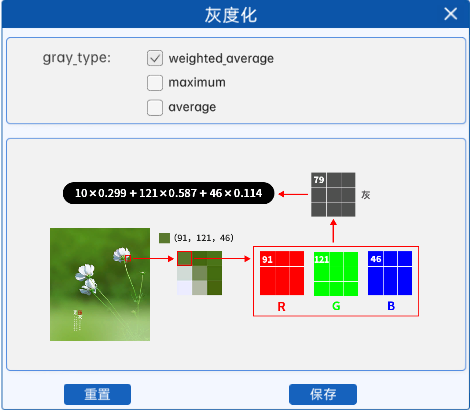
例如某图像中某像素点的像素值如上图所示,那么在使用加权平均值进行灰度化时,其计算结果就是10*0.299+121*0.587+46*0.114=79。所以在灰度图中的对应位置上,该像素点的像素值就是79。
import numpy as np
import cv2 as cv
# 读取图像
flower = cv.imread('../images/flower.png')
shape = flower.shape
img = np.zeros(shape=(shape[0], shape[1]), dtype=np.uint8)
#定义权重
wb,wg,wr = 0.114, 0.587, 0.299
for i in range(shape[0]):
for j in range(shape[1]):
img[i,j] = round(wb*flower[i,j,0] + wg*flower[i,j,1] + wr*flower[i,j,2])
cv.imshow('gray_flower', img)
cv.waitKey(0)
cv.destroyAllWindows()

这2种是最常用的加权均值方式(cv2内置了)
import cv2
# image=cv2.imread('./1.jpg')
# gray=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
gray = cv2.imread("1.jpg",cv2.IMREAD_GRAYSCALE)#0.299R + 0.587G + 0.114*B
print(gray)
cv2.imshow("gray",gray)
cv2.waitKey(0)
3.4、两个极端的灰度值
灰度值为0(纯黑)
灰度值为255(纯白)
四、图像二值化处理
二值化,顾名思义,就是将某张图像的所有像素改成只有两种值之一,其操作的图像也必须是灰度图。也就是说,二值化的过程,就是将一张灰度图上的像素根据某种规则修改为0和maxval(maxval表示最大值,一般为255,显示白色)两种像素值,使图像呈现黑白的效果,能够帮助我们更好地分析图像中的形状、边缘和轮廓等特征。
在本实验中,使用了六种不同的方式来对灰度图进行二值化。
4.1 全局阈值法
✅ cv.threshold() 函数详解
retval, binary = cv.threshold(src, thresh, maxval, type)
📌 参数说明:
| 参数名 | 含义 |
|---|---|
src |
原始图像(必须为灰度图像) |
thresh |
阈值(设定的像素值分界线) |
maxval |
如果像素值满足条件,要赋予的最大值(通常是255) |
type |
阈值类型(如 cv.THRESH_BINARY,详见下方) |
📌 返回值:
| 返回值 | 含义 |
|---|---|
retval(_) |
实际使用的阈值(与 thresh 相同,除非使用自动阈值算法如 OTSU) |
binary |
处理后的二值图像,像素值非 0 即为 maxval |
✅ 举例说明:
_, binary = cv.threshold(img, 127, 255, cv.THRESH_BINARY)
- 如果
img中某像素值 > 127 → 该像素值设为 255 - 否则设为 0
- 得到的
binary即为二值图像
📌 常见阈值类型(type):
| 类型常量 | 名称 | 说明 |
|---|---|---|
cv.THRESH_BINARY |
阈值法 | 超过阈值 → maxval,否则为0 |
cv.THRESH_BINARY_INV |
反阈值法 | 超过阈值 → 0,否则为 maxval |
cv.THRESH_TRUNC |
截断阈值法 | 超过阈值 → 设置为阈值,否则保留原值 |
cv.THRESH_TOZERO |
低阈值零处理 | 超过阈值 → 保留原值,否则为0 |
cv.THRESH_TOZERO_INV |
超阈值零处理 | 超过阈值 → 0,否则保留原值 |
cv.THRESH_OTSU |
OTSU阈值法 | 自动计算最佳阈值(与其他类型“或”组合使用) |
4.1.1. 阈值法(THRESH_BINARY)
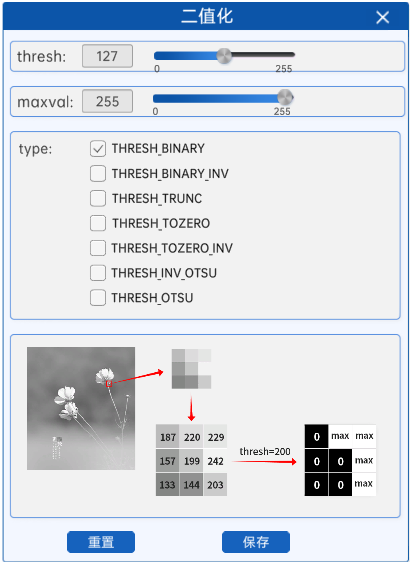
阈值法就是通过设置一个阈值,将灰度图中的每一个像素值与该阈值进行比较,小于等于阈值的像素就被设置为0(黑),大于阈值的像素就被设置为maxval。
 |
 |
|---|---|
| 灰度图 | 二值化图 |
如上图所示,在灰度图中像素值较高的地方,如花瓣、花茎等地方的像素值比阈值高,那么在生成的二值化图中的对应位置的像素值就会被设置为255,也就是纯白色。
import cv2 as cv
img = cv.imread('../images/flower.png', 0)
img = cv.resize(img, (300, 300))
thresh, binary = cv.threshold(img, 127, 255, cv.THRESH_BINARY)
print(f"阈值:{thresh}")
cv.imshow('img', img)
cv.imshow('binary', binary)
cv.waitKey(0)
cv.destroyAllWindows()
4.1.2. 反阈值法(THRESH_BINARY_INV)
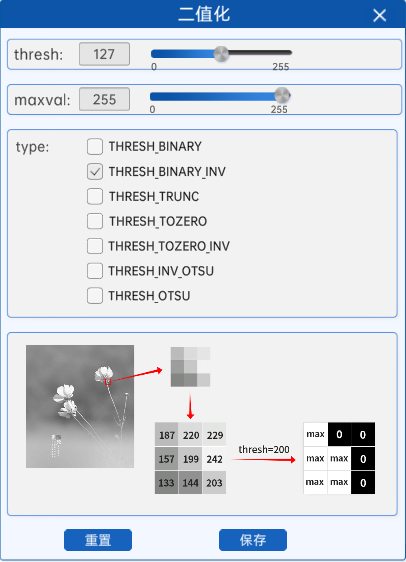
顾名思义,就是与阈值法相反。反阈值法是当灰度图的像素值大于阈值时,该像素值将会变成0(黑),当灰度图的像素值小于等于阈值时,该像素值将会变成maxval。
 |
 |
|---|---|
| 灰度图 | 二值化图 |
如上图所示,使用反阈值法对灰度图进行二值化时,会将灰度图中像素值大于阈值的地方置为0(也就是黑),将灰度图中像素值小于阈值的地方置为255(也就是白)。
import cv2 as cv
img = cv.imread('../images/flower.png')
img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
img = cv.resize(img, (300, 300))
thresh, binary = cv.threshold(img, 127, 255, cv.THRESH_BINARY_INV)
print(f"阈值:{thresh}")
cv.imshow('img', img)
cv.imshow('binary', binary)
cv.waitKey(0)
cv.destroyAllWindows()
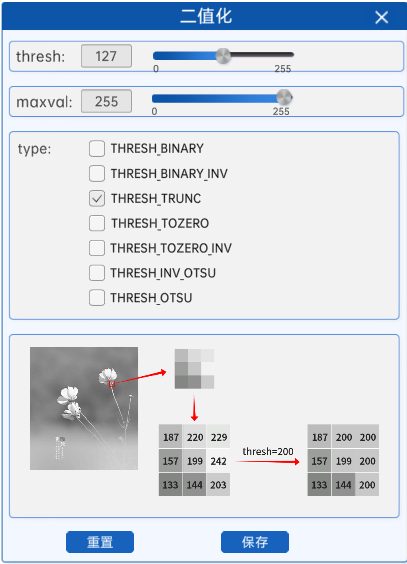
4.1.3. 截断阈值法(THRESH_TRUNC)
截断阈值法,指将灰度图中的所有像素与阈值进行比较,像素值大于阈值的部分将会被修改为阈值,小于等于阈值的部分不变。换句话说,经过截断阈值法处理过的二值化图中的最大像素值就是阈值。
 |
 |
|---|---|
| 灰度图 | 二值化图 |
import cv2 as cv
img = cv.imread('../images/flower.png')
img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
img = cv.resize(img, (300, 300))
_, binary = cv.threshold(img, 127, 255, cv.THRESH_TRUNC)
cv.imshow('binary', binary)
cv.imshow('img', img)
cv.waitKey(0)
cv.destroyAllWindows()
4.1.4. 低阈值零处理(THRESH_TOZERO)
低阈值零处理,字面意思,就是像素值小于等于阈值的部分被置为0(也就是黑色),大于阈值的部分不变。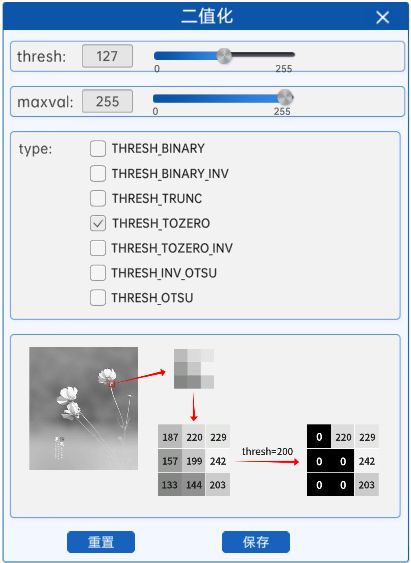
 |
 |
|---|---|
| 灰度图 | 二值化图 |
如上图所示,在灰度图中较亮的部分,其像素值比阈值大,所以在二值化后其像素值并没有发生变化。而灰度图中较暗的部分,也就是像素值较低的地方,由于像素值比阈值小,就会被置为0,对应二值化图中的黑色部分。
import cv2 as cv
img = cv.imread('../images/flower.png')
img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
img = cv.resize(img, (300, 300))
_, binary = cv.threshold(img, 127, 255, cv.THRESH_TOZERO)
cv.imshow('binary', binary)
cv.imshow('img', img)
cv.waitKey(0)
cv.destroyAllWindows()
4.1.5. 超阈值零处理(THRESH_TOZERO_INV)
超阈值零处理就是将灰度图中的每个像素与阈值进行比较,像素值大于阈值的部分置为0(也就是黑色),像素值小于等于阈值的部分不变。
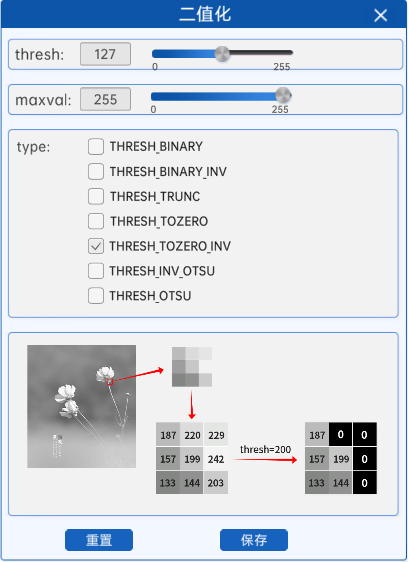
 |
 |
|---|---|
| 灰度图 | 二值化图 |
如上图所示,在灰度图中较亮的部分,其像素值比阈值大,所以在二值化后其像素值会被置为0(也就是黑色),对应二值化图中的黑色部分。而灰度图中较暗的部分,也就是像素值较低的地方,由于像素值比阈值小,将不会发生改变。
import cv2
image = cv2.imread('1.jpg', cv2.THRESH_TOZERO)
# #二值化
#image要二值化的灰度图 127代表阈值超过就取0 255最大值 cv2.THRESH_BINARY_INV二值化的类型
_, binary = cv2.threshold(image, 127, 255, cv2.THRESH_TOZERO_INV)
cv2.imshow('Binary Image', binary)
cv2.waitKey(0)
以上介绍的二值化方法都需要手动设置阈值,但是在不同的环境下,摄像头拍摄的图像可能存在差异,导致手动设置的阈值并不适用于所有图像,这可能会导致二值化效果不理想。因此,我们需要一种能自动计算每张图片阈值的二值化方法,能够根据每张图像的特点自动计算出适合该图像的二值化阈值,从而达到更好的二值化效果。这种二值化方法可以在不同环境下适用,提高图像处理的准确性和鲁棒性。
4.1.6. OTSU阈值法
在介绍OTSU阈值法之前,我们首先要了解一下双峰图的概念。
双峰图就是指灰度图的直方图上有两个峰值,直方图就是对灰度图中每个像素值的点的个数的统计图,如下图所示。
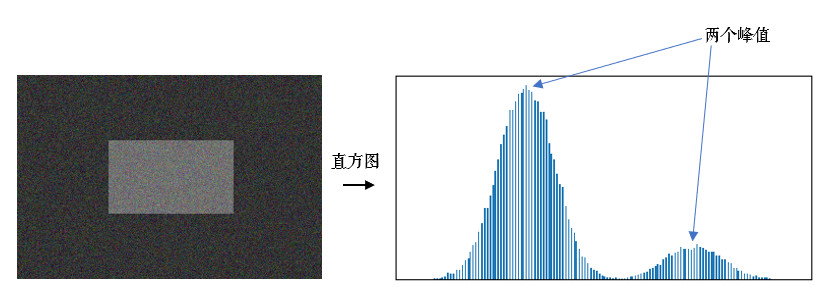
OTSU算法是通过一个值将这张图分前景色和背景色(也就是灰度图中小于这个值的是一类,大于这个值的是一类),通过统计学方法(最大类间方差)来验证该值的合理性,当根据该值进行分割时,使用最大类间方差计算得到的值最大时,该值就是二值化算法中所需要的阈值。通常该值是从灰度图中的最小值加1开始进行迭代计算,直到灰度图中的最大像素值减1,然后把得到的最大类间方差值进行比较,来得到二值化的阈值。以下是一些符号规定:
T:阈值
N0N_{0}N0:前景像素点数
N1N_{1}N1:背景像素点数
ω0\omega_{0}ω0:前景的像素点数占整幅图像的比例
ω1\omega_{1}ω1:背景的像素点数占整幅图像的比例
U0\mathcal{U_{0}}U0:前景的平均像素值
U1\mathcal{U_{1}}U1:背景的平均像素值
U\mathcal{U}U:整幅图的平均像素值
rows×cols:图像的行数和列数
下面举个例子,有一张大小为4×4的图片,假设阈值T为1,那么:

也就是这张图片根据阈值1分为了前景(像素为2的部分)和背景(像素为0)的部分,并且计算出了OTSU算法所需要的各个数据,根据上面的数据,我们给出计算方差的公式:
g=ω0(μ0−μ)2+ω1(μ1−μ)2 g=\omega_{0}(\mu_{0}-\mu)^{2}+\omega_{1}(\mu_{1}-\mu)^{2} g=ω0(μ0−μ)2+ω1(μ1−μ)2
g就是前景与背景两类之间的方差,这个值越大,说明前景和背景的差别就越大,效果就越好。OTSU算法就是在灰度图的像素值范围内遍历阈值T,使得g最大,基本上双峰图片的阈值T在两峰之间的谷底。
通过OTSU算法得到阈值之后,就可以结合上面的方法根据该阈值进行二值化,在本实验中有THRESH_OTSU和THRESH_INV_OTSU两种方法,就是在计算出阈值后结合了阈值法和反阈值法。
注意:使用OTSU算法计算阈值时,组件中的thresh参数将不再有任何作用。
import cv2 as cv
img = cv.imread('../images/flower.png')
img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
img = cv.resize(img, (300, 300))
thresh0, binary0 = cv.threshold(img, 127, 255, cv.THRESH_OTSU)
thresh1, binary1 = cv.threshold(img, 0, 255, cv.THRESH_BINARY_INV | cv.THRESH_OTSU)
print(f"阈值:{thresh0}")
print(f"阈值:{thresh1}")
cv.imshow('binary0', binary0)
cv.imshow('binary1', binary1)
cv.imshow('img', img)
cv.waitKey(0)
cv.destroyAllWindows()
阈值:132.0
阈值:132.0
当使用 OTSU 阈值法(cv.THRESH_OTSU)时,返回的阈值不再是我们手动设定的值,而是由算法自动计算得出。OTSU 方法通过最大化类间方差(类内最小方差)来自动确定一个全局最优阈值,用于图像的二值化处理。
4.2自适应二值化
与二值化算法相比,自适应二值化更加适合用在明暗分布不均的图片,因为图片的明暗不均,导致图片上的每一小部分都要使用不同的阈值进行二值化处理,这时候传统的二值化算法就无法满足我们的需求了,于是就出现了自适应二值化。
自适应二值化方法会对图像中的所有像素点计算其各自的阈值,这样能够更好的保留图片里的一些信息。自适应二值化组件内容如下图所示:
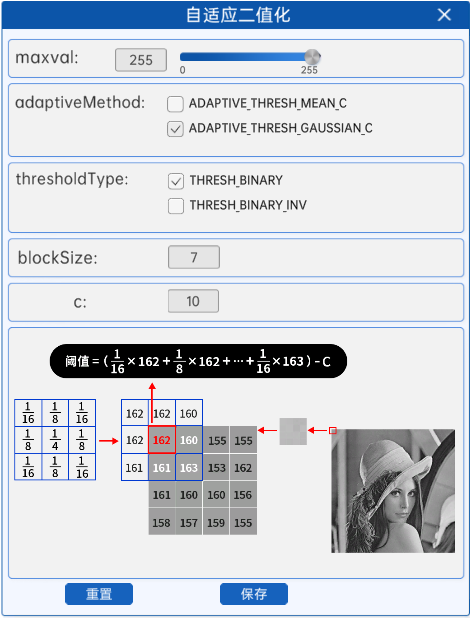
📌 自适应阈值法 cv2.adaptiveThreshold() 参数详解
dst = cv2.adaptiveThreshold(src, maxValue, adaptiveMethod, thresholdType, blockSize, C)
✅ 一、函数用途
cv2.adaptiveThreshold() 是一种局部阈值处理方法,适用于光照不均匀的图像。它会对图像的每一个小区域计算不同的阈值,进行二值化处理,从而提升在阴影、光斑环境下的分割效果。
✅ 二、参数详解
| 参数名 | 类型 | 说明 |
|---|---|---|
src |
uint8灰度图 |
输入图像,必须为灰度图像(8位单通道) |
maxValue |
int | 设置像素值最大值(通常为 255) |
adaptiveMethod |
int | 自适应方法,用于计算每个小区域的阈值 |
- cv2.ADAPTIVE_THRESH_MEAN_C:平均值 |
||
- cv2.ADAPTIVE_THRESH_GAUSSIAN_C:加权高斯平均 |
||
thresholdType |
int | 二值化类型:只能使用以下两种之一 |
- cv2.THRESH_BINARY:大于阈值为 maxValue,其他为 0 |
||
- cv2.THRESH_BINARY_INV:小于阈值为 maxValue,其他为 0 |
||
blockSize |
int(奇数) | 用于计算阈值的小区域窗口大小,通常为奇数(如 3、5、7、9…)区块越大,区块越平滑;区块越小,区块越锐利 |
C |
int/float | 从局部阈值中减去的常数(用于微调结果),最终阈值 = 块值 - C |
✅ 三、处理逻辑示意
局部阈值 = mean/gaussian(window) - C
每个像素点的二值化结果由其所在 block 的局部阈值决定
4.2.1. 取均值
比如一张图片的左上角像素值如下图所示:
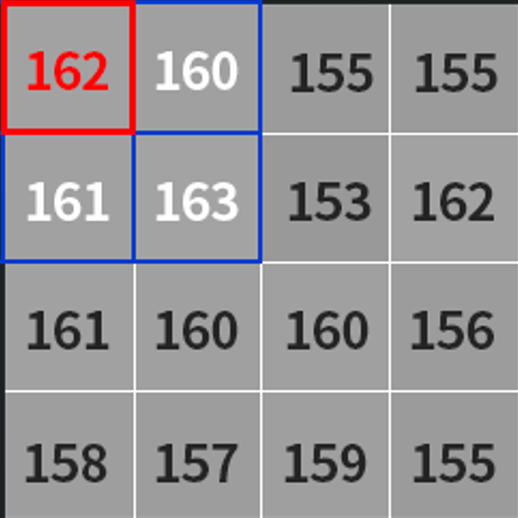
假如我们使用的小区域是3*3的,那么就会从图片的左上角开始(也就是像素值为162的地方)计算其邻域内的平均值,如果处于边缘地区就会对边界进行填充,填充值就是边界的像素点,如下图所示:
 那么对于左上角像素值为162的这个点,161(也就是上图中括号内的计算结果,结果会进行取整)就是根据平均值计算出来的阈值,接着减去一个固定值C,得到的结果就是左上角这个点的二值化阈值了,接着根据选取的是阈值法还是反阈值法进行二值化操作。紧接着,向右滑动计算每个点的邻域内的平均值,直到计算出右下角的点的阈值为止。我们所用到的不断滑动的小区域被称之为核,比如3*3的小区域叫做3*3的核,并且核的大小都是奇数个,也就是3*3、5*5、7*7等。
那么对于左上角像素值为162的这个点,161(也就是上图中括号内的计算结果,结果会进行取整)就是根据平均值计算出来的阈值,接着减去一个固定值C,得到的结果就是左上角这个点的二值化阈值了,接着根据选取的是阈值法还是反阈值法进行二值化操作。紧接着,向右滑动计算每个点的邻域内的平均值,直到计算出右下角的点的阈值为止。我们所用到的不断滑动的小区域被称之为核,比如3*3的小区域叫做3*3的核,并且核的大小都是奇数个,也就是3*3、5*5、7*7等。
import cv2 as cv
img = cv.imread('../images/flower.png')
img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
img = cv.resize(img, (300, 300))
auto_mean = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_MEAN_C,cv.THRESH_BINARY,7,4)
cv.imshow('auto_mean', auto_mean)
cv.waitKey(0)
cv.destroyAllWindows()
4.2.2. 加权求和
对小区域内的像素进行加权求和得到新的阈值,其权重值来自于高斯分布。
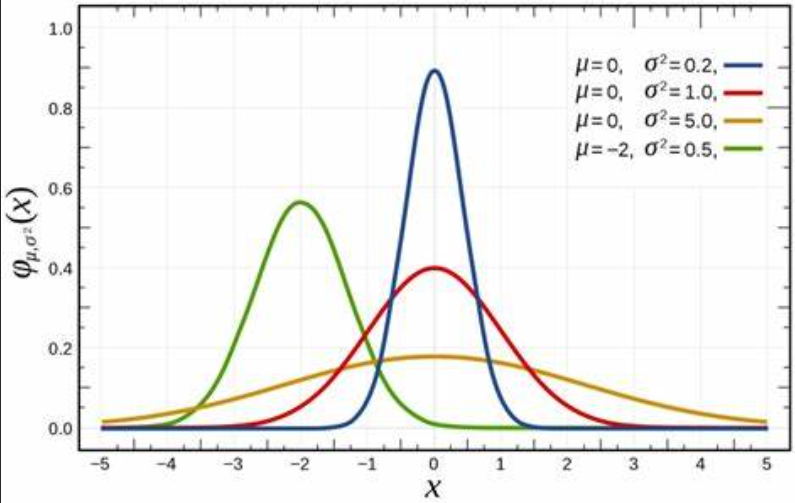
高斯分布,通过概率密度函数来定义高斯分布,一维高斯概率分布函数为:
p(y)=1σ2πe−(y−μ)22σ2 p(y)={\frac{1}{\sigma{\sqrt{2\pi}}}}e^{{\frac{-(y-\mu)^{2}}{2\sigma^{2}}}} p(y)=σ2π1e2σ2−(y−μ)2
通过改变函数中和的值,我们可以得到如下图像,其中均值为,标准差为。
 此时我们拓展到二维图像,一般情况下我们使x轴和y轴的相等并且,此时我们可以得到二维高斯函数的表达式为:
此时我们拓展到二维图像,一般情况下我们使x轴和y轴的相等并且,此时我们可以得到二维高斯函数的表达式为:
g(x,y)=12πσ2e−(x2+y2)2σ2 g(x,y)=\frac{1}{2\pi\sigma ^{2}}e^{-\frac{(x^{2}+y^{2})}{2\sigma^{2}}} g(x,y)=2πσ21e−2σ2(x2+y2)
高斯概率函数是相对于二维坐标产生的,其中(x,y)为点坐标,要得到一个高斯滤波器模板,应先对高斯函数进行离散化,将得到的值作为模板的系数。例如:要产生一个3*3的高斯权重核,以核的中心位置为坐标原点进行取样,其周围的坐标如下图所示(x轴水平向右,y轴竖直向上)
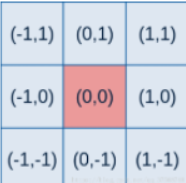
将坐标带入上面的公式中,即可得到一个高斯权重核。
而在opencv里,当kernel(小区域)的尺寸为1、3、5、7并且用户没有设置sigma的时候(sigma <= 0),核值就会取固定的系数,这是一种默认的值是高斯函数的近似。
| kernel尺寸 | 核值 |
|---|---|
| 1 | [1] |
| 3 | [0.25, 0.5, 0.25] |
| 5 | [0.0625, 0.25, 0.375, 0.25, 0.0625] |
| 7 | [0.03125, 0.109375, 0.21875, 0.28125, 0.21875, 0.109375, 0.03125] |
比如kernel的尺寸为3x3时,使用
[0.250.50.25]×[0.25 0.5 0.25] \left[\begin{array}{c}{{0.25}}\\ {{0.5}}\\ {{0.25}}\end{array}\right]\times\left[0.25~~~~0.5~~~~0.25\right]
0.250.50.25
×[0.25 0.5 0.25]
进行矩阵的乘法,就会得到如下的权重值,其他的类似。
kernel=[0.0625 0.125 0.06250.125 0.25 0.1250.0625 0.125 0.0625] kernel=\left[\begin{array}{c}{{0.0625~~~0.125~~~0.0625}}\\{{0.125~~~~0.25~~~~0.125}}\\ {{0.0625~~~0.125~~~0.0625}} \end{array}\right] kernel=
0.0625 0.125 0.06250.125 0.25 0.1250.0625 0.125 0.0625
通过这个高斯核,即可对图片中的每个像素去计算其阈值,并将该阈值减去固定值得到最终阈值,然后根据二值化规则进行二值化。
而当kernels尺寸超过7的时候,如果sigma设置合法(用户设置了sigma),则按照高斯公式计算.当sigma不合法(用户没有设置sigma),则按照如下公式计算sigma的值:
σ=0.3∗((ksize−1)∗0.5−1)+0.8 \sigma=0.3*\big((k s i z e-1)*0.5-1\big)+0.8 σ=0.3∗((ksize−1)∗0.5−1)+0.8
用在 OpenCV 的高斯模糊(如 cv.GaussianBlur())中的情况,而在 cv.adaptiveThreshold() 中其实没有 sigma 这个参数可设置!
🔍 重点来了:
cv.adaptiveThreshold() 背后如果使用了 cv.ADAPTIVE_THRESH_GAUSSIAN_C:
它的行为是:
- 使用 二维高斯核 给每一个小区域(如 5x5、7x7)计算加权平均;
- 高斯核的权重是根据默认公式计算的;
- 你无法手动设置 sigma!
这跟 cv.GaussianBlur() 不一样:
GaussianBlur()明确支持手动设置sigmaX和sigmaYadaptiveThreshold()是封装好的工具,内部自动选取高斯核(基于blockSize)
某像素点的阈值计算过程如下图所示:
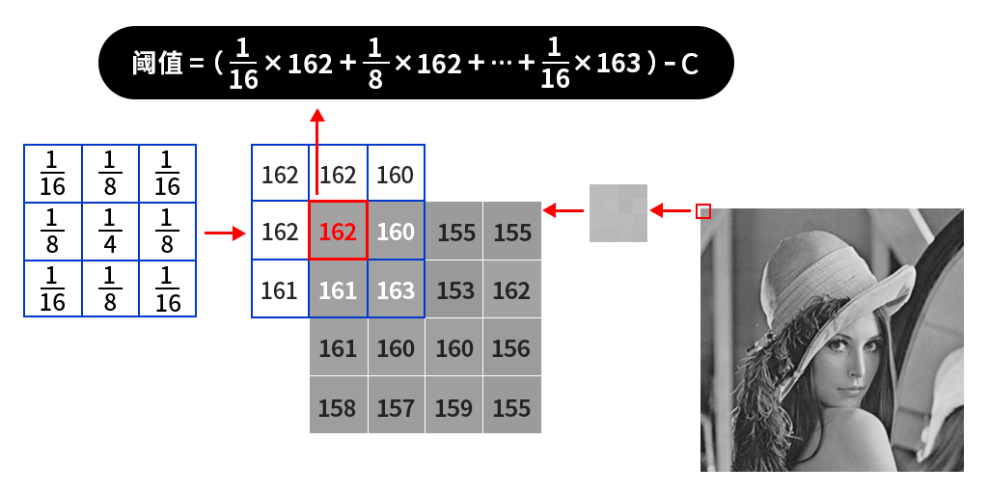
首先还是对边界进行填充,然后计算原图中的左上角(也就是162像素值的位置)的二值化阈值,其计算过程如上图所示,再然后根据选择的二值化方法对左上角的像素点进行二值化,之后核向右继续计算第二个像素点的阈值,第三个像素点的阈值…直到右下角(也就是155像素值的位置)为止。
当核的大小不同时,仅仅是核的参数会发生变化,计算过程与此是一样的。
import cv2 as cv
img = cv.imread('../images/flower.png')
img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
img = cv.resize(img, (300, 300))
auto_gauss= cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_GAUSSIAN_C,cv.THRESH_BINARY,5,6)
cv.imshow('auto_gauss', auto_gauss)
cv.waitKey(0)
cv.destroyAllWindows()
五、图像翻转
5.1cv.flip() 函数参数详解:flipCode 的含义
📌 函数原型:
dst = cv.flip(src, flipCode)
参数 flipCode 的三种情况(重点):
flipCode 值 |
翻转方向 | 说明 |
|---|---|---|
0 |
沿 X 轴 翻转 | 即上下镜像(垂直方向) |
> 0 |
沿 Y 轴 翻转 | 即左右镜像(水平方向) |
< 0 |
同时沿 X 和 Y 翻转 | 即对角镜像(上下 + 左右同时) |
💡 注意事项:
- flipCode 是一个整数,不仅限于
0、1、-1,其他正负整数也适用:cv.flip(img, 2)和cv.flip(img, 1)效果一样(都是左右翻转);cv.flip(img, -2)和cv.flip(img, -1)效果一样(都是对角翻转)。
- 实际行为只与 flipCode 的正负和是否为 0 有关,而不是具体值。
5.2 代码展示
📍1. 沿 X 轴翻转(上下镜像)
import cv2 as cv
face = cv.imread('../images/face.png')
# flipCode = 0 垂直翻转 沿X轴 上下翻转
flip_0 = cv.flip(face, 0)
cv.imshow('Face', face)
cv.imshow('Flip_0', flip_0)
cv.waitKey(0)
cv.destroyAllWindows()
 |
 |
|---|---|
| 原图 | 垂直翻转 |
📍2. 沿 Y 轴翻转(左右镜像)
import cv2 as cv
face = cv.imread('../images/face.png')
# flipCode > 0 水平翻转 沿y轴 左右翻转
flip_1 = cv.flip(face, 1)
cv.imshow('Face', face)
cv.imshow('Flip_1', flip_1)
cv.waitKey(0)
cv.destroyAllWindows()
|
 |
|---|---|
| 原图 | 水平翻转 |
📍3. 沿 X 和 Y 同时翻转(对角线镜像)
import cv2 as cv
face = cv.imread('../images/face.png')
# flipCode < 0 垂直+水平翻转
flip_ = cv.flip(face, -1)
cv.imshow('Face', face)
cv.imshow('Flip_', flip_)
cv.waitKey(0)
cv.destroyAllWindows()
|
 |
|---|---|
| 原图 | 垂直+水平翻转 |
六、仿射变换(Affine Transformation)
6.1 、什么是仿射变换?
仿射变换是一种二维线性几何变换,它可以对图像进行 旋转、平移、缩放、剪切 等操作。变换前后的图形之间满足以下性质:
✅ 基本特性:
- 保持直线性:直线变换后仍为直线
- 保持平行性:平行线依然平行
- 比例不变性:线段间的比例关系保持
- ❌ 不保持角度与长度
6.2 、仿射变换矩阵
仿射变换通过一个 2×3 的矩阵 实现:
公式:
[x′y′]=[abtxcdty][xy1] \begin{bmatrix} x' \\ y' \end{bmatrix} = \begin{bmatrix} a & b & t_x \\ c & d & t_y \end{bmatrix} \begin{bmatrix} x \\ y \\ 1 \end{bmatrix} [x′y′]=[acbdtxty]
xy1
也可扩展为 3×3齐次坐标形式:
[x′y′1]=[abtxcdty001][xy1] \begin{bmatrix} x' \\ y' \\ 1 \end{bmatrix} = \begin{bmatrix} a & b & t_x \\ c & d & t_y \\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} x \\ y \\ 1 \end{bmatrix}
x′y′1
=
ac0bd0txty1
xy1
6.3 、常见仿射变换类型
1️⃣ 图像旋转(Rotation)
目标:以任意点为中心将图像旋转某一角度。
📌 旋转矩阵(绕原点):
[cosθ−sinθsinθcosθ] \begin{bmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{bmatrix} [cosθsinθ−sinθcosθ]
📌 旋转 + 平移矩阵(绕任意点):
完整的仿射矩阵形式如下(旋转中心为 (tx,ty)(t_x, t_y)(tx,ty)):
M=[cosθ−sinθ(1−cosθ)tx+tysinθsinθcosθ(1−cosθ)ty−txsinθ] M= \begin{bmatrix} \cos\theta & -\sin\theta & (1 - \cos\theta)t_x + t_y\sin\theta \\ \sin\theta & \cos\theta & (1 - \cos\theta)t_y - t_x\sin\theta \end{bmatrix} M=[cosθsinθ−sinθcosθ(1−cosθ)tx+tysinθ(1−cosθ)ty−txsinθ]
📌 OpenCV调用:
M = cv2.getRotationMatrix2D(center=(cx, cy), angle=theta, scale=1)
rotated_img = cv2.warpAffine(img, M, (w, h))
2️⃣ 图像平移(Translation)
将图像在 xxx、yyy 方向分别移动 txt_xtx、tyt_yty:
M=[10tx01ty] M = \begin{bmatrix} 1 & 0 & t_x \\ 0 & 1 & t_y \end{bmatrix} M=[1001txty]
M = np.float32([[1, 0, tx], [0, 1, ty]])
translated_img = cv2.warpAffine(img, M, (w, h))
3️⃣ 图像缩放(Scaling)
缩放因子分别为 sxs_xsx 和 sys_ysy:
M=[sx000sy0] M = \begin{bmatrix} s_x & 0 & 0 \\ 0 & s_y & 0 \end{bmatrix} M=[sx00sy00]
M = np.float32([[sx, 0, 0], [0, sy, 0]])
scaled_img = cv2.warpAffine(img, M, (w, h))
4️⃣ 图像剪切(Shearing)
- 沿 x 轴剪切:
M=[1shy0010] M = \begin{bmatrix} 1 & sh_y & 0 \\ 0 & 1 & 0 \end{bmatrix} M=[10shy100]
- 沿 y 轴剪切:
M=[100shx10] M = \begin{bmatrix} 1 & 0 & 0 \\ sh_x & 1 & 0 \end{bmatrix} M=[1shx0100]
M = np.float32([[1, shy, 0], [0, 1, 0]]) # x轴剪切
sheared_img = cv2.warpAffine(img, M, (w, h))

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)