大模型推理显存优化系列(3):FlowMLA——面向高吞吐的DP MLA零冗余显存优化
本文将介绍蚂蚁集团ASystem团队在推理显存优化上的新工作FlowMLA
文章作者:陶思睿 张锐 赵军平
系列文章回顾⬇️
本期我们将介绍蚂蚁集团ASystem团队在推理显存优化上的新工作FlowMLA,以提高DeepSeek等大模型推理性能(batch增加2.8x),适合带有DP并行(包括DP+TP并行)下显存受限场景(需要带NVLink)。方案对精度无影响,且无需额外微调操作,目前正在提交到开源社区(SGLang等)。
背景与问题
DeepSeek大模型推理
以DeepSeek为代表的大模型得到广泛普及,为了提升规模部署的性能并降低成本,DeepSeek官方开源了一系列优化技术,开源社区包括SGLang、vLLM等做了很多持续努力,一时间仿佛全民上阵,使得推理性能包括延迟和吞吐得到了快速优化。我们注意到,不同的业务场景对延迟和吞吐指标存在一定偏好,例如强化学习(RL)倾向长序列、高吞吐。本文侧重优化吞吐指标,对延迟指标无优化或略微牺牲。
显存压力问题
DeepSeek的MLA架构(及其他MQA)在典型attention并行策略下会面临显存容量方面的技术挑战,特别是国内普遍使用的H800机型。
-
TP并行下的KV cache显存冗余:MLA在decode阶段通过矩阵吸收的等价计算,将实际KV头数压缩至1,显著降低了KV cache的显存占用。然而,这种设计的一个副作用是,TP并行处理Attention时,每个rank需要冗余复制所有的KV cache,导致巨大的显存压力(特别是大batch、长序列下),基本不推荐单独使用。特别是H800 80GB的显存容量已经捉襟见肘。
-
DP并行下的attention权重冗余:为了解决了KV cache的冗余问题,Deepseek官方报告中采用了DP与TP(或SP)混合的attention并行策略。这个手段不小心又引入了一个副作用,每个DP rank不得不冗余存储attention权重。两者其害取其轻,大家尽力了。
注:以上的技术分析主要围绕attention module,和MoE部分无关,MoE可以采用常见的EP或TP并行。
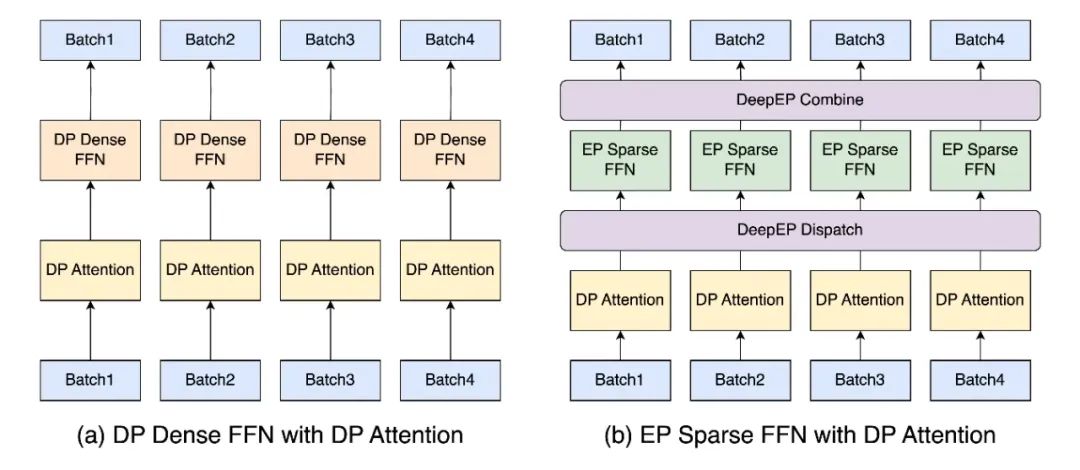
图1:DP attention混合并行部署方案 (图源https://lmsys.org/blog/2025-05-05-large-scale-ep/)
现在,MLA权重冗余开销成为一些典型场景下制约吞吐的首要瓶颈。特别是,只有数台H800机器部署满血版Deepseek R1 BF16模型(例如用于RL场景下的样本生成),单卡attention权重占用近22GB,严重挤压了KV cache空间,而KV cache的大小基本直接决定了batch size和吞吐上限。
为此,我们提出显存优化方案FlowMLA来重点优化attention权重冗余问题。
注:显存容量因素可能直接影响了一些条件下AMD MI300 vs. H100/H200的推理性能(见AMD的评测链接中文版、英文版)。
FlowMLA思路:以通信换显存,释放更多KV cache
我们借鉴训练场景ZeRO的思想,将attention权重分片至多卡,计算时通过all gather通信取回,以释放显存空间来支持大batch推理。这样带来的额外开销是每层引入了一次通信操作。进一步,我们通过设计layer间的计算-通信overlap的设计来掩盖通信开销。因此,FlowMLA的核心设计包括:
-
double buffer:两块共享的显存分别用于当前层的attention计算及下一层的weight prefetch。
-
overlapping: 当前层的计算与下一层attention权重的prefetch并发起来,隐藏prefetch开销。
-
layer-wise scheduling: 细粒度分层的计算和通信调度,异步流水执行。
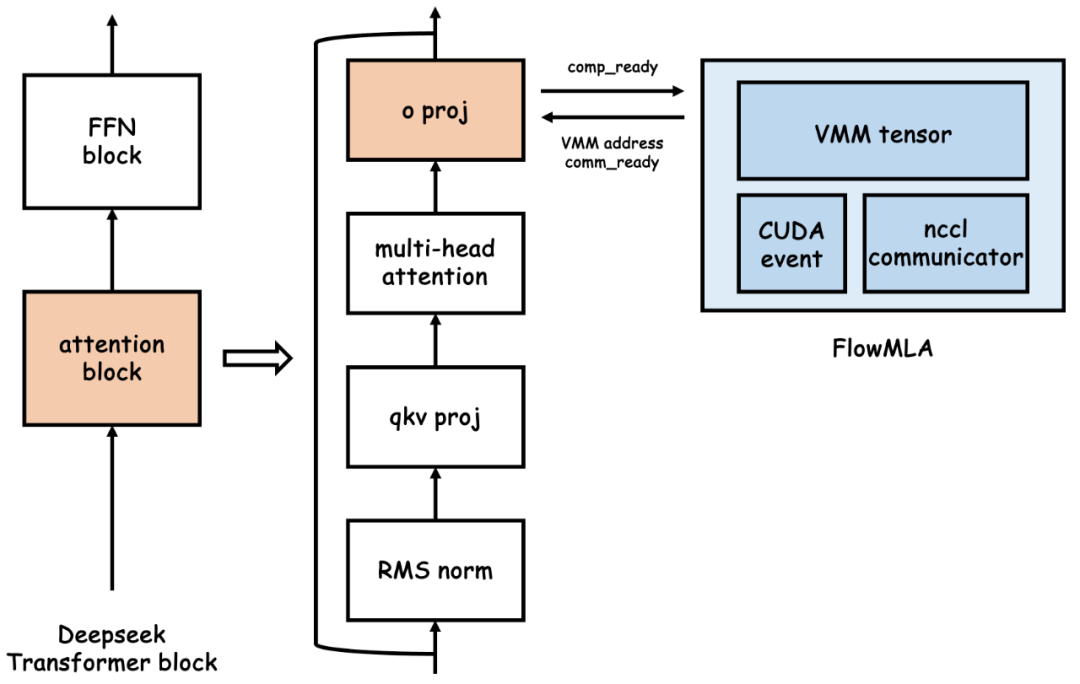
图2:FlowMLA模块示意(以o_proj为例)
FlowMLA设计
以下重点介绍分层的显存复用和流水通信overlap的设计。
1.显存分区
-
私有显存区(每卡固定):存储本地权重分片(图3实线块),总大小为weight / dp_size。
-
共享显存区(跨层复用):all gather后完整权重的暂存区(图3虚线块),分奇/偶层复用,总大小为 2 * (weight / n_layers) * (dp_size - 1) / dp_size。
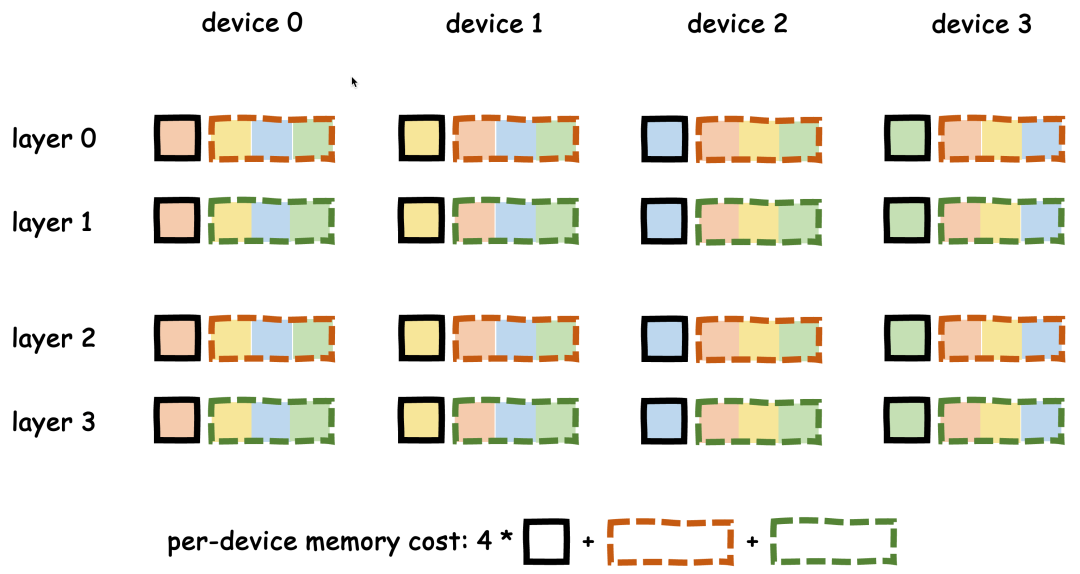
图3:FlowMLA显存复用机制,以4层模型 & DP4为例
我们扩展了此前介绍的kv cache显存优化工作vTensor(详见大模型推理显存优化系列(1):vTensor)的使用场景,同样也是借助cuda VMM(Virtual Memory Management) 来实现权重的sharding和re-sharding(类似ZeRO-3)。
2. 异步预取
接下来我们考虑计算-通信流水线。当第i层attention计算完成时,我们立即发起非阻塞all gather操作,跨GPU收集第i+2层所需的权重分片。该预取操作与当前层的后续计算及第i+1层的计算并行执行,实现通信时延的有效隐藏。为保障计算正确性,奇数层与偶数层分别复用各自共享显存区,comp_stream和comm_stream间通过cuda event同步状态,如图4所示。在具体实现中,我们的统一管理两类cuda stream:comp_stream上完成所有计算,奇数层、偶数层的权重预取在各自的comm_stream上执行。我们通过适当的stream管理使得上述操作完美兼容cuda graph。
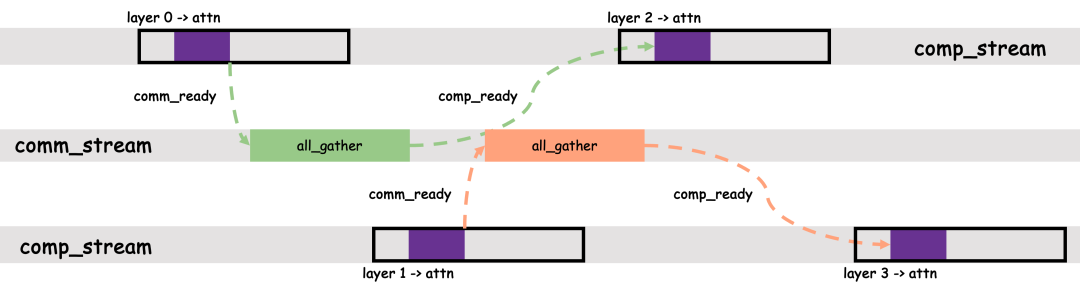
图4:计算-通信流水线,以4层模型为例
FlowMLA实现
基于SGLang,针对占MLA权重超过60%的o_proj进行了开发实现,并向SGlang社区提交了PR (https://github.com/sgl-project/sglang/pull/7005),用户可以通过--vtensor_enable启动命令一键开启优化。
FlowMLA使得8xH20机可开启DP attention部署满血版FP8 Deepseek R1,这是SGlang开源版此前难以达到的。
FlowMLA结果对比
硬件环境:H20 SXM *8(单机, NVLink 900GB/s);H800 SXM *32(四机,NVLink 400GB/s),cuda 12.4,GPU驱动版本535
软件版本:sglang v0.4.7
负载情况:input 1024,output 2048,占用满KV cache空间的batch size
关注指标:output tok/s
8xH20 FP8 FlowMLA启动和测试命令示意:
python3 -m sglang.launch_server --model-path /path-to-DeepSeek-R1-FP8 --tp 8 --trust-remote-code --attention-backend flashinfer --port 8008 --speculative-num-steps 0 --speculative-eagle-topk 1 --speculative-num-draft-tokens 0 --disable-radix-cache --enable-dp-attention --mem-fraction-static 0.965 --cuda-graph-bs 136 --chunked-prefill-size 1024 --max-prefill-tokens 1024 --dp 8 --vtensor-enable
python -m sglang.bench_serving --backend sglang --model /path-to-DeepSeek-R1-FP8 --port 8008 --dataset-name random --random-input-len 1024 --random-output-len 2048 --random-range-ratio 1 --dataset-path /path-to-ShareGPT-dataset实验结果:
|
8xH20,DeepSeek FP8模型 |
32xH800 DeepSeek BF16模型 |
||||
|
DP w/o FlowMLA |
TP w/o FlowMLA |
ours (DP) |
DP w/o FlowMLA |
ours (DP) |
|
|
每卡吞吐 (tokens/s) |
(显存不足,无法运行) |
128 |
181 |
280 |
400 |
|
batch size |
52 |
136 |
30 |
83 |
|
实验结果表明,
-
8卡H20场景下,FlowMLA的DP attention相比于TP attention基线提升batch 2.6x和吞吐41%。且基线DP无法运行。
-
32卡H800场景下,FlowMLA可增加DP attention batch 2.8x,吞吐提升43%。
注:由于batch的提升以及异步通信对SM的占用,TPOT有所下降,可通过NCCL_MAX_CTAS控制NCCL的SM占用(推荐用最新版的NCCL 2.27.*)。
profile结果展示,对于8xH20 FP8的部署场景,batch size为1时就能做到通信时延的完美隐藏。

图5:通过torch profiler抓取的单请求下推理过程
小结
FlowMLA通过权重分片+显存复用+异步流水,释放了DP MLA中的冗余显存,极大地提升了系统吞吐。不止MLA,其他无法充分TP的GQA、MQA模型理论上均可基于该方法进一步提升。
进一步工作:
-
针对TP MLA场景下的KV cache冗余进行优化。
-
对qkv_proj的sharding实现。
-
支持更多的模型。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)