Llama3.2-vision-11B在Python上的调用
Llama-3.2-Vision对电脑性能的要求比较高,建议一开始就选用比较高配的GPU(例如A100),不然后面环境配好了会发现gpu不够支撑它。多数是如何通过ollama调用它来做一些任务执行,但是有时候需要调用一些更底层的东西就尴尬了。首先,向huggingface申请模型数据并下载,国区不要选China(原因自行脑补)。服了,找了好几天的代码就这么水灵灵地出现在huggingface官网下
最近在CSDN上汲汲寻找这个模型的python调用,竟是一直没找到。多数是如何通过ollama调用它来做一些任务执行,但是有时候需要调用一些更底层的东西就尴尬了。补充一个分享给大家~
首先,向huggingface申请模型数据并下载,国区不要选China(原因自行脑补)。可以使用外网下载到本地后导入,however,更推荐直接在终端使用hug镜像下载!
个人有一个体会就是Llama-3.2-11B-Vision-Instruct比Llama-3.2-11B-Vision要更好使一些~毕竟是经过指令微调的。再Llama-3.2-11B-Vision上跑过几个数据集结果真的不堪入目。。。
关键步骤包括:
#若没有安装依赖,则
pip install -U huggingface_hub
#在终端执行:
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --token 此处补充你的api_key --resume-download --local-dir-use-symlinks False meta-llama/Llama-3.2-11B-Vision --local-dir Llama-3.2-11B-VisionLlama-3.2-Vision对电脑性能的要求比较高,建议一开始就选用比较高配的GPU(例如A100),不然后面环境配好了会发现gpu不够支撑它。我这边是cuda12.1,torch1.2.1,python3.10没有问题~
服了,找了好几天的代码就这么水灵灵地出现在huggingface官网下边。。在python中配置好环境后加入相关代码即可。文件路径记得改为模型在本地的路径!
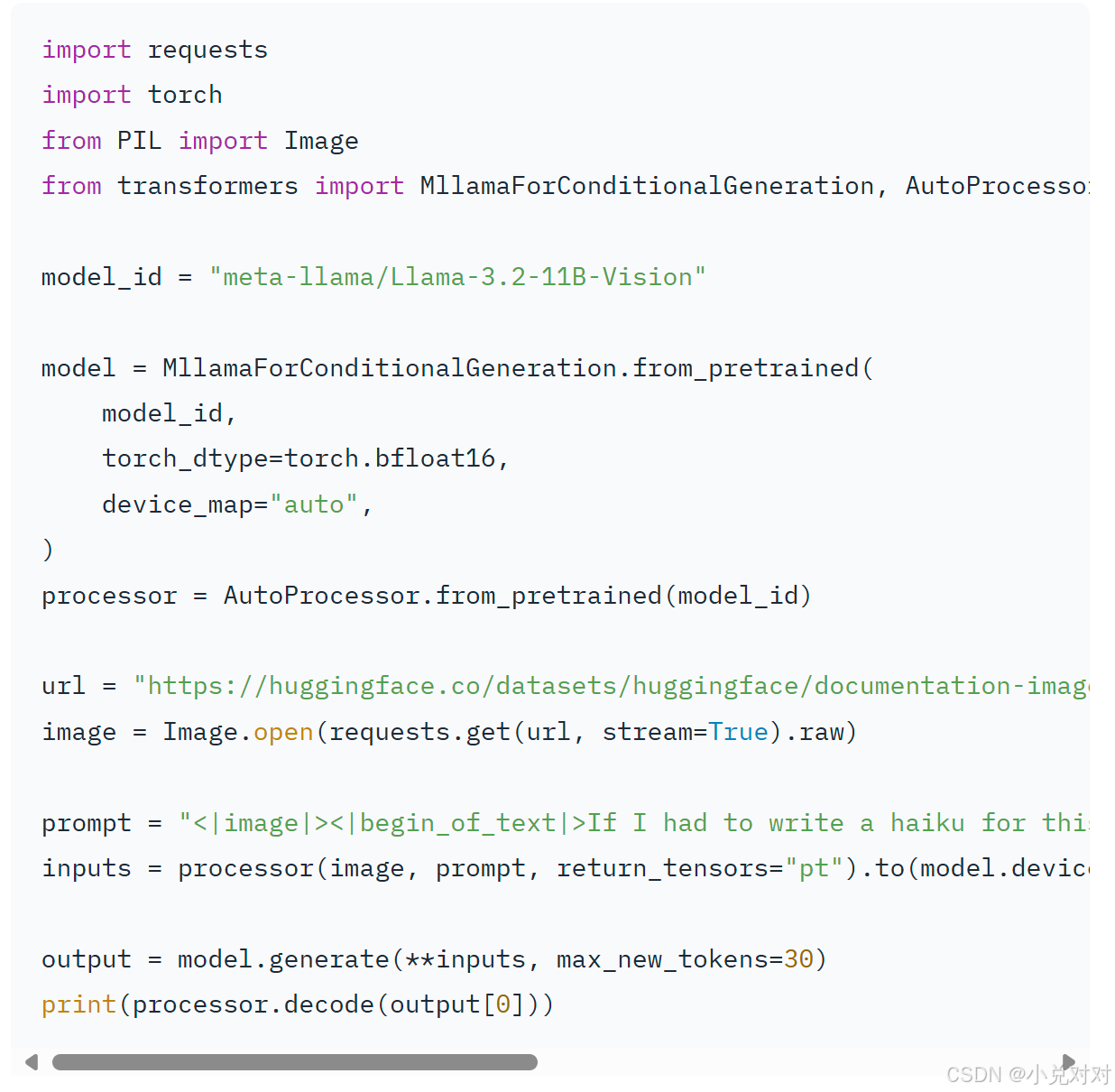
提示词的书写是非常头疼的一步,没写好的话输出总是默认格式,跑了也是白跑。他还新增了一个ipython的角色,一些提示词参考链接:
https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/vision_prompt_format.md
https://huggingface.co/docs/transformers/main/en/chat_templating
再附上一些提供相关信息的连接,慢慢看还是能提高对这个模型底层代码的认知的:
Ollama官网
https://ollama.com/library/llama3.2-vision
Ollama vision 官网(看有些博主会使用api调用,当前前提就得是服务器能连接外网啦)
Llama3.2-vision huggingface链接
https://huggingface.co/meta-llama/Llama-3.2-11B-Vision
稍后看有没有机会出一个论文阅读笔记!!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)