AI大模型应用面试题-(Java后端开发必备知识)看这个足够了
LangChain框架介绍Chains
1. 什么是RAG?流程是什么?
1.1 分析:
RAG (Retrieval Augmented Generation 检索增强生成) 是一种结合信息检索和生成式模型的技术方案、其主要流程包括两个核心环节:
-
检索 (Retrieval): 基于用户的输入、从外部知识库中检索与查询相关的文本片段、通常使用向量化表示和向量数据库进行语义匹配。
-
生成 (Generation): 将用户查询与检索到的内容作为上下文输入给生成模型(如 GPT等)、由模型输出最终回答。
即我们在本地检索到相关的内容、把它增强到提示词里、然后再去做结果生成。
简单来说就是利用外部知识弥补补充模型生成能力、既能保证回答的准确性、又能在知识库更新时及时反映最新信息(还有一点就是部分业务是内部文档、网上没有、因此可以本地提供知识来增强 AI 的知识)
1.2 面试参考回答:
RAG就是结合信息检索和生成式模型的技术。主要流程包括两个核心环节:
检索:基于用户的输入、从外部知识库(如数据库、文档、网页)检索与问题相关的信息。通常使用向量化表示和向量数据库进行语义匹配。将知识库中的文档进行预处理、分块、清洗并转换为向量表示、存储在向量数据库中。常用的如 Faiss、Milvus等向量数据库存储所有文档向量。用户提问后、对问题进行向量化、并在数据库中执行最近邻搜索、找出语义最相近的 N 条内容
然后就是增强:也可以说是构建 Prompt
-
将检索到的信息作为上下文、输入给生成模型(如 GPT)。
-
相比纯生成模型、RAG 能引用真实数据、减少幻觉(胡编乱造)
最后就是由将增强后的上下文输入到大型语言模型、综合已有上下文生成最终生成最终的回答或内容。
一句话总结: RAG = 向量搜索引擎 + 大模型、让 AI 回答更靠谱、减少幻觉
在这里补充一下MySQL的幻读是什么:
-
幻读:指一个事务多次执行同一个查询、查询某个符合查询条件的数量、但是前后两次查询到的数量不一致。比如事务A执行查询的数量、在此期间另一个事务插入了符合该查询条件的新数据、导致前后查询的结果不一致。幻读可能导致数据的不完整性。
幻读的关键在于 多次查询的结果集数量不一致 导致幻读的原因是插入或者删除
-
多次执行相同的查询。
-
导致不一致的原因是其他事务的插入(INSERT)或删除(DELETE)
-
常用的数据库(如MySQL InnoDB)在可重复读级别通过快照读(MVCC)避免不可重复读、通过间隙锁来避免幻读
补充一下锁的知识:
-
行级锁:InnoDB 引擎是支持行级锁的、而 MyISAM 引擎并不支持行级锁。
-
记录锁:锁住的是一条记录。而且记录锁是有 S 锁和 X 锁之分的,满足读写互斥,写写互斥
-
间隙锁(Gap Lock ):只存在于可重复读隔离级别、目的是为了解决可重复读隔离级别下幻读的现象。
-
Next-Key Lock 称为临键锁、是 Record Lock + Gap Lock 的组合。是锁定一个范围、并且锁定记录本身。
-
插入意向锁、当插入位置的下一条记录有间隙锁、那么就会生成插入意向锁、然后进入阻塞状态
-
1.3 RAG的详细工作流程
流程:
-
用户提问
-
Embedding向量化 -
向量数据库检索相关文档
-
构建
Prompt(问题 + 检索内容) -
生成模型生成回答
-
输出最终答案
1.4 理解
我们可以把 RAG 想象成是一个"问答助手"、它不仅会说话(生成能力)、还会查资料(检索能力)、就像你的一个特别靠谱的朋友:
-
你问了个问题
-
它先去资料库查一查
-
找到几段靠谱的资料
-
把你的问题+查到的内容一起喂给AI
-
大脑理解后组织语言
-
告诉你一个又准又通顺的答案
想象考试时:
-
传统 AI (如 ChatGPT): 只能靠死记硬背课本内容答题。
-
RAG 版 AI: 允许开卷考试,、先翻书找知识点、再组织答案、结果更准、更新、更靠谱
1.5 优点
-
提高准确性: 通过检索相关知识、减少模型"
幻觉" (生成不准确或虚构信息) 问题、提升输出的可信度。 -
知识更新及时: 能够获取最新的信息、避免模型因训练数据过时而导致的知识滞后
-
适应专业领域: 可整合特定领域的专业知识库、提供更精准的领域答案
-
降低训练成本: 不需要对模型进行大规模重新训练、减少了计算资源和时间成本
-
减少幻觉: 依靠真实数据、而非仅靠模型记忆。
-
动态更新: 知识库可随时更新、无需重新训练模型。
-
可解释性: 能提供引用来源、增强可信度。
1.6 应用场景
-
企业知识管理: 构建内部知识库、快速检索和生成相关信息、提升员工工作效率。
-
智能客服: 提供准确、快速的客户问题解答、增强用户体验。
-
专业咨询: 在法律、医疗、金融等领域、提供基于最新和专业知识库的咨询服务。
-
内容创作: 辅助生成新闻、报告、文章等、确保内容的准确性和时效性。
2.介绍一下RAG的工作流程
参考面试回答:
RAG(检索增强生成)的完整流程可分为5个核心阶段:
-
用户提问
-
数据准备:清洗文档、分块处理(如PDF转文本切片)
-
向量化:使用嵌入模型(如BERT、BGE)将文本转为向量。也就是
Embedding向量化 -
索引存储:向量存入数据库(如Milvus、Faiss、Elasticsearch)。
-
检索增强:用户提问向量化后检索相关文档。也就是构建
Prompt(问题 + 检索内容) -
生成答案:将检索结果与问题组合输入大模型生成回答。
流程图:
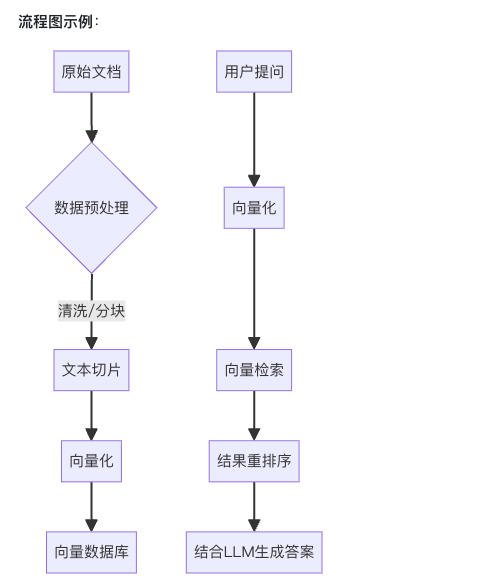
生成阶段的Prompt设计示例
示例Prompt模板(网页2)
prompt = "用户问题: {query}\n相关文档: {doc1}\n{doc2}\n请结合以上信息回答。"可以进行上下文压缩:对检索结果摘要(如RAPTOR树状摘要)减少冗余输入
后面会有一个
Prompt专题去分析Prompt
3.在 RAG 中的 Embedding 嵌入是什么
3.1 简单介绍一下:
简单说就是把文本内容、图像、音频、视频等形式的信息映射为高维空间中的密集向量(一串数字)
这个过程叫 “嵌入”(Embedding)
向量就是语义空间中的坐标、捕捉对象之间的语义关系和隐含的意义。
每个向量就像文本的“数字指纹”、包含了文本的语义信息、比如“猫”和“狗”的向量会很接近
“开心”和“悲伤”的向量会远离。
即语义相近的对象在向量空间中彼此邻近、而语义相异的对象则相距较远
3.2 为什么需要 Embedding
因为传统检索依赖关键词匹配、难以解决同义词、上下文和多样化表达的问题。
而 Embedding 将文本映射到高维向量空间、使得例如“汽车维护”与“汽车保养”等概念能够通过向量距离自动匹配
如果仅仅是“识别字符”、那么比如用户问“如何煮奶茶”、搜索可能漏掉“奶茶制作步骤”这样的同义表达。所以需要进化到理解含义
在 RAG(Retrieval-Augmented Generation)系统中,Embedding 嵌入是将文本语义映射为稠密向量的核心过程,其本质是通过深度学习模型捕获文本的潜在语义特征,实现语义空间的数学表达。以下是其关键解析:
3.3 Embedding 的核心作用
1. 语义向量化
将文本(词、句、段落)转换为固定维度的实数向量(如 768 维)、使语义相似的文本在向量空间中距离相近。
例如:
"机器学习" → [0.23, -0.45, ..., 0.78]
"深度学习" → [0.25, -0.43, ..., 0.76]
2. 跨模态对齐
统一查询(Query)与文档块(Chunk)的向量空间、支撑高效的语义相似度计算(如余弦相似度)。
3.4 参考面试回答:
Embedding是RAG系统的核心组件、Embedding(嵌入)技术本质上是将文本、图像等非结构化数据转换为高维向量的过程。在实际应用中Embedding解决了传统关键词检索的局限性。
比如用户询问'如何煮奶茶'时、传统检索可能无法找到包含'奶茶制作步骤'的文档、因为它们字面上不匹配。
而通过Embedding、系统能够理解这两个表达在语义上的相似性、从而返回相关内容。
Embedding的工作原理是通过深度学习模型(如BERT、Sentence-Transformers等)将文本映射到768维或更高的向量空间。在这个空间中、'猫'和'狗'的向量会彼此接近、而'开心'和'悲伤'的向量则相距较远、这种距离关系准确反映了词语间的语义关联。
在RAG系统中、Embedding的核心价值在于建立查询和文档之间的语义桥梁。当系统收到用户问题后、会将其转化为向量、然后在预先索引的文档向量库中寻找最相似的内容、无论它们在字面表达上是否匹配。这种基于语义的检索方式大幅提升了信息获取的准确性和完整性、为生成模型提供了更高质量的上下文信息,从而产生更精准的回答
4. 有哪些 Embedding Model(嵌入模型)
在 RAG 中、常用的 Embedding Model(嵌入模型)主要分为以下几类:
-
text-embedding-ada-002(2022年12月发布):OpenAI 的第二代模型,支持多语言,性价比高,适合大多数场景(如文档检索、相似度匹配)。 -
text-embedding-3-small(large):OpenAI 推出的第三代高效模型,性能更强,MIRACL(multi-language retrieval)比上代从 31.4% 提升到了 44.4%,MTEB(Massive Text Embedding Benchmark)从 61.0% 提升到了 62.3%,且价格更低。 -
Sentence-BERT(SBERT):基于BERT优化,大幅提升句子嵌入速度和相似度计算效果,开源且免费(如 all-mpnet-base-v2 性能最好,而 all-MiniLM-L6-v2 速度最快)。 -
Gemini Embedding:在 MTEB 基准测试中表现出色,目前排名第一。
-
Cohere Embedd:有 embed-english-light-v2, embed-english-v3等模型
-
BGE(BAAI General Embedding):智源研究院研发、专为中文优化(如bge-large-zh)、在中文MTEB榜单排名前列。
-
M3E(Moka Massive Mixed Embedding):开源轻量模型、专为中文优化、适合本地部署。
对我们实战而言:中文选BGE/M3E,英文选OpenAI/Cohere,轻量部署选Sentence-BERT
2.什么是LangChain
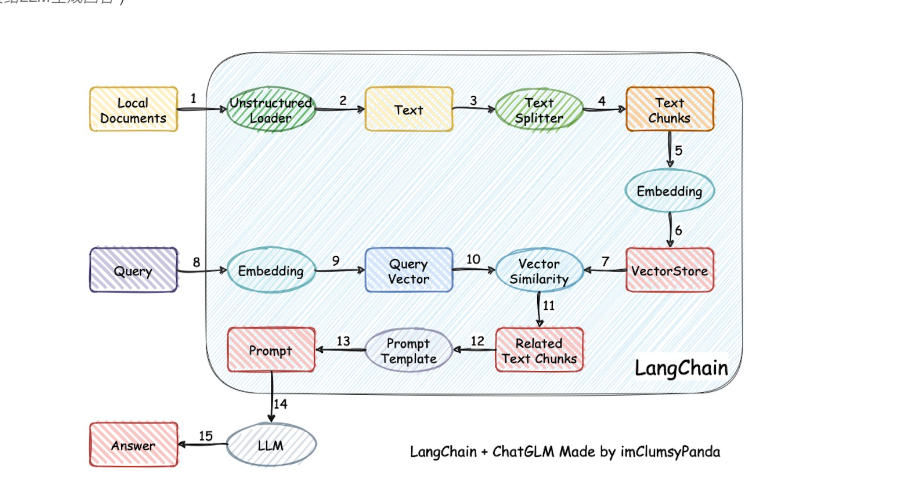
LangChain框架介绍
2.1 回答分析:
LangChain 是一个开源框架、专为快速构建复杂的大语言模型应用而设计。
简单来说就是它集成和内置了很多我们开发 AI 大模型应用需要的东西、如内置文档加载器、向量数据库、HTTP API 封装、云服务适配器等、让咱们开箱即用、有点像咱们 Java 届的 Spring
它通过模块化组件 (Agents、Memory、Tools 等) 和预制工具链、解决了传统LLM开发中的三大痛点:
-
上下文管理:通过
Memory组件(如对话历史缓存、实体关系跟踪)实现长对话连贯性。 -
多工具协同:支持动态调用外部API、数据库、搜索引擎等工具(如
GoogleSearchTool)
例如在回答"2025年全球GDP排名"时自动刷新实时数据查询
复杂任务编排:通过 Chains(链)和 Agents(代理)将多个LLM调用和工具操作组合成工作流
例如"分析财报→提取关键指标→生成可视化建议"的端到端流程
2.2 优点:
-
内置
RetrievalQA等预制链、5行代码即可实现知识库问答系统。 -
支持OpenAI、Hugging Face、Anthropic等模型、甚至可混合调用多个模型(如用GPT-4生成创意、用Claude审核规性)。
-
提供 LangSmith 平台、支持全链路监控、成本分析和性能优化(如乐天集团通过LangSmith将API调用成本降低60%)。
2.3 部分技术模块介绍
Chains(链):
-
LLMChain: 基础链、直接调用LLM(如生成摘要)。
-
RetrievalQA: 结合向量数据库实现"先检索后生成",例如从企业文档中提取答案。
-
RouterChain: 动态路由请求到不同链(如"中文问题→中文链、技术问题→技术知识库链")
Agents(代理):
-
ReAct: 通过"思考-行动-观察"循环解决问题(如"用户问'杭州今天天气如何?'→调用天气API→返回结果")。
-
OpenAI Function Calling:直接调用函数(如 get_current_time())、无需手动解析JSON。
Memory(记忆):
-
ConversationBufferMemory: 存储对话历史(如"用户之前询问过订单状态、需保持上下文")。
-
VectorStoreRetrieverMemory: 将记忆存储在向量数据库中、支持语义检索
如"用户提到'上周会议记录' 自动关联相关文档"
2.4 能力
-
组件化架构:提供可插拔的模块(如文本加载器、向量数据库接口、提示词模板)、像搭积木一样组合数据处理流程。
-
链式任务编排:支持创建多步骤工作流(Chain)、例如:网页抓取→文本摘要→情感分析→结果存储,形成端到端的智能处理流水线。
-
上下文感知:通过记忆机制保留对话/任务历史、使模型能基于上下文进行连贯决策(如持续追踪用户需求变更)。
-
工具集成扩展:允许接入500+外部工具(计算器、搜索引擎、业务系统API),突破纯文本交互限制,执行实际业务操作。
2.5 参考面试回答:
LangChain 是一个开源框架、专为快速构建复杂的大语言模型应用而设计。
简单来说就是它集成和内置了很多我们开发 AI 大模型应用需要的东西、如内置文档加载器、向量数据库、HTTP API 封装、云服务适配器等、让咱们开箱即用、有点像咱们 Java 届的 Spring。
主要支持复杂任务编排:通过 Chains(链)和 Agents(代理)将多个LLM调用和工具操作组合成工作流
以及实现上下文管理Memory(记忆):通过 Memory 组件(如对话历史缓存、实体关系跟踪)实现长对话连贯性。
3. 什么是向量数据库
3.1 向量数据库的工作原理
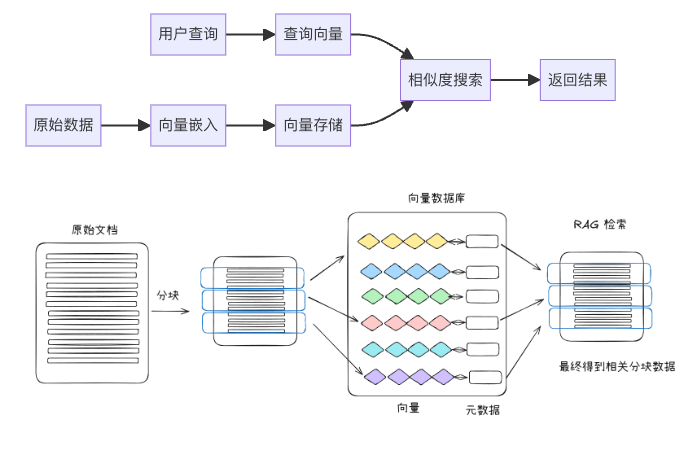
向量数据库是一种专门设计用来存储和管理向量嵌入的数据库系统。
它可以将非结构化数据(如文本、图片、音频等)转换成高维向量的形式进行存储、并通过高效的相似性搜索算法,快速找到与目标向量最接近的数据项。
3.2 向量数据库主要解决以下下核心问题
在基于大模型的应用开发中、向量数据库主要解决以下下核心问题:
1. 高效的相似性搜索==非结构化数据的语义化检索
-
问题:传统数据库依赖关键词匹配,无法理解语义(例如搜索"车
",无法自动关联"汽车""车辆") -
解决:将数据转换为向量后、直接通过向量距离(如余弦相似度)衡量语义相关性、实现"
意图匹配"而非字面匹配。通过将用户查询转换为向量、可以快速找到语义相似的内容、这对于实现智能问答、推荐系统等功能至关重要。
2. 海量数据处理
能够高效处理大模型生成的海量数据、传统数据库难以处理百万甚至上亿的数据点、而向量数据库专门针对这种场景进行了优化。
3. 实时交互支持==大模型上下文的高效关联
-
问题:大模型(如 GPT)的输入长度有限、难以直接处理海量知识库。
-
解决:通过向量数据库预先存储结构化段、实时检索最相关的 Top-K 内容作为上下文输入、支持 RAG(检索增强生成)等场景。在需要实时用户交互的应用中(如聊天机器人)、向量数据库可以确保快速检索相关上下文信息、提供实时响应。
4. 与传统数据库的区别
传统数据库采用行列结构存储数据、主要用于精确匹配查询、而向量数据库针对高维向量数据优化、支持近似最近邻(ANN)搜索算法、更适合语义相似性搜索。可以理解为TopN系列
5. 降低推理成本与延迟
-
问题:若每次查询都重新计算全量数据的嵌入向量、计算开销极大。
-
解决:向量数据库预先向量化并建立索引(如 HNSW、IVF)、实现亚秒级检索、避免重复编码。
6. 动态更新外部知识
-
问题:大模型静态训练数据无法及时反映最新信息(如新闻、股价)。
-
解决:向量数据库支持实时插入新数据向量、保证检索结果的时效性。
7.主流向量数据库
FAISS:Facebook开发的向量检索库
Milvus:开源的向量数据库系统(非常重要)
Annoy:Spotify开发的近似最近邻搜索库
8.性能优化考虑
索引技术:使用高效的索引方法提升搜索性能
查询优化:采用低延迟的查询处理机制
扩展性:支持分布式部署和水平扩展
9. 典型应用场景
|
场景 |
案例 |
向量数据库的作用 |
|
智能问答 |
企业知识库客服 |
检索与用户问题最相关的产品文档段落 |
|
推荐系统 |
电商商品推荐 |
根据用户行为向量匹配相似商品 |
|
多模态搜索 |
以图搜图、视频片段检索 |
跨模态向量相似性比对(如图像→文本) |
|
异常检测 |
金融交易反欺诈 |
识别与历史欺诈模式相似的交易行为向量 |
10. 技术特性对比
|
维度 |
传统数据库(MySQL/ES) |
向量数据库(Milvus/Pinecone) |
|
数据类型 |
结构化数据(表格/JSON) |
非结构化数据向量化 |
|
检索方式 |
精确匹配、布尔查询 |
相似度搜索(ANN 近似最近邻) |
|
索引结构 |
B树、倒排索引 |
HNSW、IVF-PQ、LSH |
|
适用场景 |
事务处理、统计分析 |
语义搜索、AI 推荐增强 |
总结
向量数据库是大模型时代的记忆中枢、通过语义化存储与毫秒级检索,解决了非结构化数据处理、动态知识更新、上下文精准关联等核心挑战、成为构建 RAG、个性化推荐等 AI 应用的必备基础。
3.3 参考面试回答:
关于向量数据库我的理解是:
向量数据库它可以将非结构化数据(如文本、图片、音频等)转换成高维向量的形式进行存储、通过向量数据库预先存储结构化段、实时检索最相关的 Top-K 内容作为上下文输入、并通过高效的相似性搜索算法、快速找到与目标向量最接近的数据项。
传统数据库采用存储数据、主要用于精确匹配查询、常用的检索方式就是精确匹配、索引结构有像B+树或者倒排索引的结构。
而向量数据库针对高维向量数据优化、支持近似最近邻(ANN)搜索算法、更适合语义相似性搜索。可以理解为TopN系列、检索TopK相关内容作为上下文输入。向量数据库预先向量化并建立索引(如 HNSW、IVF),实现亚秒级检索。代表性的向量数据库就是Milvus:一个开源的向量数据库系统
4.说一下Milvus 和 MogMongoDBoDB
MongoDB本身不是专门的向量数据库、而是一个文档型NoSQL数据库、主要设计用于存储和查询JSON类似的文档数据。
MongoDB确实在近期版本中添加了向量搜索功能:
-
MongoDB Atlas(云服务)提供了Vector Search功能
-
MongoDB 6.0+版本支持向量索引和向量相似性搜索
这些功能使MongoDB能够部分实现向量数据库的能力、但它的核心架构和设计理念与专门的向量数据库(如Milvus、Pinecone、Qdrant等)有本质区别:
-
专门的向量数据库从底层就针对高维向量检索进行了优化
-
向量数据库提供更丰富的ANN算法和索引选项
-
向量数据库在大规模向量集合上的查询性能通常更优
虽然MongoDB可以处理向量数据、但它更准确地应该被描述为"具有向量搜索能力的文档数据库"而非纯粹的向量数据库
4.常用的向量数据库有什么?如何选型
是否需全托管?
├─ 是 → Pinecone
└─ 否 → 数据规模?
├─ <1M → Chroma/Redis
├─ 1M-100M → Qdrant/Milvus
└─ >100M → Milvus 集群/Zilliz Cloud
是否需要多模态?
├─ 是 → Weaviate
└─ 否 → 是否需要强过滤?
├─ 是 → Qdrant
└─ 否 → 现有 ES 生态?
├─ 是 → Elasticsearch 向量扩展
└─ 否 → Milvus
5. 向量数据库的核心原理是什么?核心技术是什么
参考面试回答:
向量数据库的核心原理是通过将高维数据(如图像、文本)转换为多维向量、并基于相似性度量(如余弦相似度、欧氏距离),利用高效的索引结构和近似最近邻(ANN)算法、快速检索与目标最相似的向量结果。
这一过程可概括为三个关键步骤:
首先是向量化:我们通过嵌入模型将非结构化数据映射为稠密向量、比如用BERT处理文本、ResNet处理图像、或CLIP处理多模态数据。这些模型能捕获数据的语义或特征信息、通常生成128到2048维的向量
其次是索引构建:为了高效检索、我们会采用分层导航小世界图(HNSW)等结构预处理向量。HNSW能将搜索复杂度降至对数级O(log N)。同时我们还会利用乘积量化(PQ)来压缩向量、减少内存占用、以及通过倒排索引(IVF)缩小搜索范围。
最后是近似搜索:在实际应用中我们允许一定误差来提升速度。ANN算法会在准确性和效率间寻找平衡点、确保在毫秒级延迟内返回Top-K相似结果、同时保持95%以上的召回率。
总的来说就四个核心层:向量化引擎->索引结构 ->相似度计算->搜索
原始数据 → 向量化 → 索引构建(HNSW/PQ/LSH) → 输入查询向量 → ANN近似搜索 → 返回Top-K结果
分析:
其核心技术架构包含四个核心层:
-
向量化引擎
-
通过嵌入模型(Embedding Model)将非结构化数据(文本/图像/视频)映射为稠密向量
-
典型模型:BERT(文本)、ResNet(图像)、CLIP(多模态)
-
输出维度:通常128-2048维(如OpenAI text-embedding-3-large输出3072维)
-
-
索引结构
-
分层导航小世界图(HNSW):建立多层图结构实现对数级搜索复杂度(O(log N))
-
乘积量化(PQ):将高维向量分解为低维子空间进行压缩,降低内存占用
-
倒排索引(IVF):通过聚类建立倒排列表,仅搜索相关分区
-
-
相似度计算
-
距离度量:欧式距离(L2)、内积(IP)、余弦相似度(归一化后等价于IP)
-
近似最近邻(ANN)算法:在精度与速度间权衡,召回率可达95%+时延迟<10ms
-
-
分布式架构
-
水平扩展:通过一致性哈希实现数据分片(如Milvus的DataNode集群)
-
流批一体:支持实时写入与批量导入(QPS>10万级)
-
混合存储:热数据存内存/Pmem\冷数据落盘(如磁盘SSD+Optane分层)
-
6. 说一下Milvus 和 MongoDB
MongoDB本身不是专门的向量数据库、而是一个文档型NoSQL数据库、主要设计用于存储和查询JSON类似的文档数据。
MongoDB确实在近期版本中添加了向量搜索功能:
-
MongoDB Atlas(云服务)提供了Vector Search功能
-
MongoDB 6.0+版本支持向量索引和向量相似性搜索
-
MongoDB支持树、哈希、文本、地理空间索引
-
支持精确匹配、范围查询、聚合 |
这些功能使MongoDB能够部分实现向量数据库的能力、但它的核心架构和设计理念与专门的向量数据库(如Milvus、Pinecone、Qdrant等)有本质区别:
-
专门的向量数据库从底层就针对高维向量检索进行了优化
-
向量数据库提供更丰富的ANN算法和索引选项
-
向量数据库在大规模向量集合上的查询性能通常更优
虽然MongoDB可以处理向量数据、但它更准确地应该被描述为"具有向量搜索能力的文档数据库"而非纯粹的向量数据库
Milvus是一个开源的向量设计的数据库系统 提供高效的相似性搜索
技术架构就是采用云原生架构、分离存储与计算。
支持高性能索引:支持HNSW、LSH、PQ等多种向量索引
7. 向量数据库中三种核心索引与压缩技术
它们是向量数据库中三种核心索引与压缩技术,用于加速高维向量的相似性搜索:
HNSW(Hierarchical Navigable Small World)图
-
在高维空间中、将所有向量组织成多个“小世界”图。
-
查询时、从上层稀疏图逐层跳转到最相似邻居、逐层下探到密集的底层图、快速找到最近邻近点。
-
构建多层图结构、每一层都是一个“小世界”网络。上层节点稀疏、像“高速公路”、能快速跳跃式定位大致范围;下层节点密集、像“小路”,用于精细搜索
-
例如在1000万向量中找相似向量、HNSW可能先通过上层快速到邻近区域、再通过下层在该区域内精确查找。
-
在大规模向量数据(如亿级向量)中、查询速度与精度的平衡表现优秀、是目前许多向量数据库(如 Milvus)的常用索引技术。
LSH(Locality-Sensitive Hashing)哈希
-
利用一组专门设计的哈希函数、把相似向量映射到同一个或相邻的哈希桶。
-
查询时只需查对应桶的候选项、再做精确排序、极大缩小搜索范围。
-
设计特殊的哈希函数、使相似向量以较高概率映射到同一个哈希桶、不相似向量尽量分散到不同桶。
-
查询时、只需要查查询向量所在桶及相邻桶、而非全部数据。例如在图像去重中、相似图片的向量会“扔”到同一桶、直接在桶内排重更高效。
-
适合处理高维数据(如文本、图像特征向量),在推荐系统、图像检索等海量数据近似查询场景中应用广泛。
PQ(Product Quantization)量化
-
将高维向量均匀分成若干子、对每块分别做聚类,用“
码字”来近似原始子向量。 -
存储时只保存每块的码字索引、检索时通过预先计算好的子块距离表快速估算向量间距离。
-
将高维向量(如1024维)拆分成多个低维子向量(如16个64维),对每个子向量单独进行聚类,生成聚类中心。
-
存储时、用索引中心的编号(而非原始数据)表示向量。例如一个1024维向量,拆成16块,每块用8位编码,大大减少存储空间
-
用于压缩存储数据、降低内存/磁盘占用,同时加速向量距离计算(只需计算编码对应中心的距离),常用于工业级向量检索系统
8. 说一下向量数据库中的ANN算法
8.1 ANN是什么
分析:
ANN 是近似最近邻的缩写、它不是某种具体算法、而是一类通过牺牲一定精确性来换取搜索速度的算法框架或者技术
其核心是在海量高维向量中、快速找到与目标向量"近似相似"的结果、而非耗费大量时间寻找绝对精确的最近邻。
因为当数据量达到百万甚至十亿级时、暴力遍历所有向量计算距离(精确搜索)会遇到无法接受
而ANN通过智能索引和近似策略、实现毫秒级响应、满足实时搜索需求。
8.2 为何需要ANN
-
维度灾难突破
-
高维向量(128-4096维)的精确最近邻计算面临计算量爆炸问题:
-
10亿条向量的线性扫描需 3.2TB 内存带宽(假设每向量1KB)
-
精确计算时间复杂度 O(N*d)(N为数据量,d为维度)
-
-
实时性要求
-
典型应用场景对延迟有严苛要求:
-
推荐系统:<50ms
-
RAG问答:<200ms
-
图像检索:<100ms
-
ANN 可将延迟降低 100-1000 倍(相比精确搜索)
-
-
存储优化需求
-
通过量化/压缩技术(如 PQ、SQ8):
-
3072维向量从 12KB (float32) 压缩至 768B (SQ8)
-
存储成本降低 94%,内存带宽需求同步下降
-
-
规模扩展能力
-
支持亿级数据实时检索:
-
HNSW 索引在 1亿数据集上可达 99%召回@10ms
-
IVF_PQ 方案可实现 10亿级数据亚秒级响应
-
8.3 ANN 大家族:
实际上:HNSW、LSH、PQ都是实现 ANN 的具体技术/算法
-
HNSW:图结构(Graph-based ANN)
-
LSH:哈希分桶(Hash-based ANN)
-
PQ:向量量化(Quantization-based ANN)
8.4 参考面试回答:
在向量数据库中、ANN(近似最近邻)算法是核心技术之一。ANN并非单一算法、而是一类通过牺牲一定精确性来换取搜索速度的技术框架。当我们处理百万或十亿级的高维向量数据时、传统的精确搜索因计算复杂度O(N*d)而难以满足实时需求。
ANN的核心价值在于解决了三大挑战:
首先是维度灾难问题:高维空间中的精确计算代价极高;其次是实时性要求、如推荐系统需<50ms响应、RAG问答需<200m。最后是存储优化、通过压缩技术可将存储成本降低94%。
实现ANN的主流技术主要有三类:
基于图结构的HNSW、通过构建多层图实现对数级复杂度
基于哈希的LSH、将相似向量映射到相同桶中
以及基于量化的PQ、通过分解压缩向量减少存储和计算开销。
以HNSW为例、它能在1亿数据规模下、以10ms的延迟达到99%的召回率
这些算法在实际应用中通常会组合使用、如Milvus等向量数据库常用IVF+PQ的组合方案、在保持高召回率的同时实现亚秒级响应。
8.5 拓展题:
百万级数据的查询是否也可以用这种变成向量这种来查询?比如向量化的一些细节、像维度什么的?为什么定这个维度?具体查的时候怎么操作?
百万级数据完全适合使用向量化查询方式。与传统关系型数据库相比、向量数据库在处理语义相似性搜索时有明显优势。
关于向量化细节、维度选择是个关键问题。通常我们使用的维度在128到2048之间
比如OpenAI的text-embedding-3-large是3072维。维度选择存在权衡:维度越高、语义信息保留越完整、但计算成本和存储需求也越大。
我们通常根据应用场景和模型特性来确定最佳维度、例如简单文本可能用384维足够、而复杂多模态内容可能需要1024维以上才能保持信息完整性。
在实际查询操作中、流程大致是:
首先将查询语句转换为同样维度的向量
然后使用ANN算法找到数据库中相似向量。具体来说如果使用HNSW索引、系统会从入口点开始、在图结构中逐层导航、快速缩小搜索范围
如果使用IVF+PQ组合、则先定位到相关聚类中心(倒排列表)、再在量化后的向量上计算近似距离。最后返回相似度最高的Top-K结果。
在百万级数据量下、这些算法通常能在10-50ms内完成查询、召回率在95%以上。
9. 向量数据库的搜索方法是什么?
参考面试回答:
-
余弦相似度:衡量两个向量的方向相似性、不关心向量长度、取值范围[-1, 1]。值越大方向越接近(比如“猫”和“狗”的文本向量)。
-
欧几里得距离(欧氏距离):计算两个向量在空间中的“
直线距离”、取值>0、距离越小向量越相似(比如两张图片的像素特征向量)。 -
曼哈顿距离:计算两个向量在各维度上的差值绝对值之和、类似“
在城市街区中沿道路行走的距离”、取值>0。适用于网格状数据(如地图坐标)。
简单来说:余弦比方向、欧氏比“绝对距离”、曼哈顿比“线性累加距离”。
因此:
-
文本、推荐系统常用余弦相似度(不关心文本长度,只看语义方向)
-
图像、视频检索常用欧氏距离(直接比较像素特征的空间差异)
-
网格数据(如城市坐标、表格数据)常用曼哈顿距离(符合实际移动逻辑、稀疏数据的处理)
10. 什么是MCP?
简单介绍一下:
MCP(Model Context Protocol、模型上下文协议)
旨在为大型语言模型(LLMs)和 AI 助手提供一个统一、标准化的接口、使其能够无缝连接并交互各种外部数据源、工具等、让模型不依赖于预训练数据、还能在需要时动态获取最新的上下文信息、调用外部工具、执行特定任务。
简单来说就是它为 AI 应用架构提供了一种“即插即用”的方式、类似于 USB-C 让不同设备能够通过相同的接口连接一样。总结就是 MCP 的是创建一个通用标准、使 AI 应用程序的开发和集成变得更加简单和统一。
可以将 MCP(模型上下文协议)比作 AI 世界中的 USB-C 接口。在传统的计算机环境中、只要外设(如鼠标、键盘或 U 盘)符合 USB 标准、系统便能识别并使用它们。
同样地MCP 为大型语言模型(LLM)提供了一个统一的通信协议、使得各种数据源和工具只需遵循 MCP 的规范、便可与 LLM 无缝对接。
这意味着:无论是数据库、API 还是其他服务、只要通过 MCP 接入、LLM 都能理解并利用这些资源、从而扩展其功能和应用范围。
MCP 的作用主要体现在以下几个方面:
-
标准化数据接入:通过 MCP、我们无需为每个模型编写单独的代码、而是通过统一的协议接口、实现一次集成,随处连接。这大大简化了模型与外部系统的集成过程。
-
增强模型能力:MCP 使得模型能够实时访问最新的数据和工具、例如直接从 GitHub 获取代码库信息、或从本地访问文件。这不仅提升了模型的实用性、也拓展了其应用场景。
-
提升系统可维护性:通过标准化的协议、系统的各个组件可以更加模块化地协作、降低了维护成本和出错概率。
MCP 为啥如此重要?
以前如果想让我们的数据、基本只能靠预训练数据上传数据、既麻烦又低效。而且就算是很强大的 AI 模型、也会有数据隔离的问题、无法直接访问新数据、每次有新的数据进来、都要重新训练或上传扩展起来比较困难。
现在MCP 解决了这个问题、它突破了模型对静态知识库的依赖、使其具备更强的动态交互能力、能够像人类一样调用搜索引擎、访问本地文件、连接 API 服务、甚至直接操作第三方库。
所以 MCP 相当于在 AI 和数据之间架起了一座桥、不管是获取最新的天气和新闻、还是进行数据分析、自动化办公,都能轻松搞定。
更重要的是只要大家都遵循 MCP 这套协议、AI 就能无缝连接本地数据、互联网资源、开发工具、生产力软件,甚至整个社区生态、实现真正的“万物互联”、这将极大提升 AI 的协作和工作能力
参考面试回答:
MCP模型上下文协议)是为大型语言模型提供的一个统一标准化接口、让AI能够无缝连接各种外部数据源和工具。
可以将它比作AI世界的USB接口—只要遵循这个协议标准、任何数据源或工具都能与语言模型实现即插即用
比如说传统的AI只能依赖预训练的静态知识,无法获取实时数据。而通过MCP,模型可以动态访问最新信息,比如查询搜索引擎、读取本地文件、调用第三方API,甚至直接操作各种工具库。比如说可以访问Github、IDEA
从计算机网络角度来看,MCP确实可以理解为"一个Better HTTP"
就像HTTP定义了网页浏览器和服务器之间交互的标准、MCP定义了AI模型和各种外部资源之间的交互标准。
HTTP让任何浏览器都能访问任何网站、MCP则让任何兼容的AI模型都能访问任何遵循这个协议的数据源或工具。
HTTP有请求方法(GET, POST等)、状态码和标准化的头部信息、MCP也定义了AI如何请求信息、接收响应以及处理各种情况的标准方式
这个协议最大的价值是标准化、它是MCP的核心价值 - 你不需要为每个AI模型和每个工具之间的连接编写专门的代码、只要双方都支持MCP协议、它们就能自动"对话"。这大大简化了系统集成、降低了开发成本、也提高了系统的可扩展性
总结就是 MCP 创建一个通用标准、使 AI 应用程序的开发和集成变得更加简单和统一
11. MCP和Function Calling区别是什么
MCP
MCP 是一个抽象层面的协议标准。它规定了上下文与请求的结构化传递方式、并要求通信格式符合 JSON-RPC 2.0 标准、它提供了标准化的通信机制、确保不同模型之间的兼容性。我们只需按照协议开发一次接口、即可被多个模型调用,避免了为每个模型单独适配的繁琐工作。
Function Calling
Function Calling 则是某些大模型(如 OpenAI 的 GPT-4)提供的特有接口特性。它以特定的格式让 LLM 能产出一个函数调用请求、然后应用可以读取这个结构化的请求去执行对应的操作并返回结果。但这个特性本身并不要求消息一定是 JSON-RPC 格式、也不一定遵守 MCP 的上下文管理方式。它是由大模型服务提供商定义的一种调用机制、与 MCP 所定义的协议与标准没有内在依赖或直接关联。
两者比较
其实 MCP 和 Function Calling 两者是完全不同层面的东西、MCP 是一个更底层、更通用的抽象标准、相当于一个基础设施、而 Function Calling 则是大模型一个特定的服务、更偏向与具体实现。
以支付系统来举例子:以前的 Function Calling 相当于请求各个支付系统、微信、支付宝、银联、每个系统都需要单独对接。而 MCP 相当于支付网关、只需要对接支付网关、后面对接各种支付系统都是支付网关做、我们不用管
因此 MCP 协议通过统一通信规范和资源定义标准、实现了“一次开发,全平台通用”的目标。
借助 MCP我们只需按照协议开发一次接口、便可无缝适配 ChatGPT、Deepseek 等不同模型、显著降低了集成成本和复杂性
协同工作场景
在实际系统中二者常配合使用:
客户端 → MCP协议 → 模型服务集群 → Function Calling → 天气API
客户端 → MCP协议 → 模型服务集群 → Function Calling → 数据库
客户端 → MCP协议 → 模型服务集群 → Function Calling → 企业内部系统
典型工作流:
-
客户端通过MCP协议发送请求到模型服务
-
大模型在处理过程中触发Function Calling
-
通过MCP协议建立的通道获取外部工具结果
-
最终响应通过MCP协议返回客户端
参考面试回答:
MCP 是一个标准协议、主要是为了统一大模型之间的通信方式、像是搭了一个通用的高速路、大家按标准走、开发一次就能兼容很多模型、省得每个模型单独适配,很省事。
Function Calling 是大模型自己的内置功能,比如 GPT-4,它可以在对话中主动“叫外卖”或者“查天气”,它会给出一个结构化的调用指令,我们应用拿到后,自己去执行对应的操作。
但每个厂商(OpenAI、AnthropicDeepSeek)设计的 Function Calling 细节都不一样,没有统一标准。不统一、也不一定用标准格式。
简单理解、MCP 是打通底层基础设施、Function Calling 是模型内部的一种功能。
实际工作里一般是一起用的:MCP打通外部接口、模型用Function Calling触发操作、最后再通过MCP返回结果。举个例子你用MCP(普通话)告诉AI你要干什么、AI内部用Function Calling(技能)去完成任务、然后再用MCP(普通话)把结果告诉你。
总结就是:MCP解决统一标准、Function Calling解决模型的功能、两者配合。
12. 大模型输出出现重复和幻觉如何解决
回答重点:
在大模型(LLM)输出中,、出现重复和幻觉是两个常见的问题。
重复指的是模型在生成文本时出现内容重复的现象、而幻觉则是指模型生成了看似合理但实际上不真实或不准确的信息。为了解决这两个问题、可以通过微调(fine-tuning)的方法进行优化
具体来说微调可以通过以下方式来减少重复和幻觉:
-
数据质量控制:确保用于微调的数据是高质量的、包含准确、真实的信息,避免模型学习到错误或重复的模式。
-
引入惩罚机制:在训练过程中、对模型生成重复或不真实内容的行为进行惩罚,引导模型生成多样且准确的内容。
-
领域特定微调:针对特定领域(如医疗、金融等)进行微调、使模型在该领域内生成更准确的内容、降低幻觉发生的概率。
-
参数高效微调(PEFT):采用低秩适配(LoRA)等方法、在不改变模型主体结构的情况下、进行小范围的参数调整,提高微调效率,减少幻觉的产生。
-
增强训练策略:引入合成任务(如SynT5)或噪声增强微调(NoiseFIT)、通过设计特定任务或在训练中加入噪声,增强模型的鲁棒性,减少幻觉的生成。
-
强化学习与人类反馈(RLHF):结合人类反馈进行强化学习、使模型在生成内容时更加符合真实世界的知识逻辑,降低幻觉的风险。
-
检索增强生成(RAG):结合外部知识库,在生成过程中引入相关的真实信息,帮助模型生成更准确的内容。
扩展知识:
幻觉的成因:
幻觉是指模型生成的内容看似真实、但实际上是虚构的。其成因主要有:
-
数据问题:训练数据中可能包含错误或不准确的信息、导致模型学习到错误的知识。
-
模型结构限制:某些模型在处理复杂推理或长距离依赖关系时存在困难、可能导致生成不准确或虚构的内容。
-
上下文信息不足:在生成响应时、如果模型缺乏足够的上下文信息、可能无法理解问题的真实意图,从而生成与事实不符的内容。
微调的注意事项:
-
数据质量:确保用于微调的数据集质量高、避免引入错误信息。
-
过拟合风险:在微调过程中、模型可能会过度拟合训练数据、导致在新数据上的表现不佳。
-
评估指标:在微调后、需要使用合适的评估指标(如BLEU、ROUGE等)来评估模型的性能、确保其生成内容的质量。
参考面试回答:
在大模型生成内容时、出现重复和幻觉是两个常见的问题。重复指的是模型在生成文本时出现内容重复的现象、而幻觉则是指模型生成了看似合理但实际上不真实或不准确的信息。为了解决这两个问题、可以通过微调(fine-tuning)的方法进行优化
为了解决这些问题、首先微调是非常有效的手段。
首先可以确保用于训练的数据质量、要高质量的真实的信息。我们可以减少模型学到错误的信息。特别是领域特定的微调、能帮助模型更准确地生成内容,避免在特定领域(比如医疗、金融)中产生幻觉。
此外在训练过程中引入惩罚机制、比如对模型生成重复或不准确内容进行惩罚、也能够引导模型生成更为多样和真实的内容。
另一个有效的策略是使用参数高效微调(PEFT)、通过像LoRA这样的技术、在不改变模型主体结构的情况下调整部分参数、从而提高微调效率并减少幻觉的产生。
同时强化学习与人类反馈(RLHF)也是一种非常有用的方法、结合人类的评价、模型可以在生成内容时更符合实际世界的逻辑,降低幻觉的风险。
最后检索增强生成(RAG)技术也能够显著提高模型输出的准确性、通过在生成过程中引入外部知识库、确保模型生成的信息更为真实和可靠。
总的来说:通过微调、引入惩罚机制、领域特定训练和强化学习等方法、可以有效减少大模型的重复和幻觉问题

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)