1.ELK企业级日志分析系统
1.ELK日志分析系统
ELK 是企业级日志分析的主流方案,核心由 Elasticsearch、Logstash、Kibana 三款工具组成,可实现日志的采集、存储、分析与可视化。日志主要包括系统日志、应用程序日志和安全日志。
ELK日志系统背景
随着企业数字化转型的持续深入,业务架构逐渐向分布式、微服务化、多终端协同模式演进,服务器集群、容器实例、云服务、数据库、网络设备等各类组件产生的日志数据呈指数级增长。这些日志涵盖系统运行状态、应用访问轨迹、用户操作行为、异常报错信息、安全防护记录等核心数据,是企业运维监控、故障排查、安全审计、业务优化的重要依据。
然而,传统日志管理模式面临诸多难以突破的痛点:
- 日志分散孤立:日志分散存储在不同服务器、容器或应用节点中,缺乏统一存储平台,运维人员需逐节点登录查询,跨系统故障排查效率极低;
- 格式杂乱无章:不同组件(如 Linux 系统、Nginx、Java 应用、MySQL 数据库)输出的日志格式不统一,多为非结构化文本,缺乏标准化字段,难以直接进行统计分析;
- 实时性严重不足:传统日志分析依赖离线统计、脚本查询或人工筛选,无法实时捕捉系统异常、性能瓶颈、安全攻击等关键信息,故障响应与排查延迟高,易造成业务损失;
- 扩展性与容量受限:面对 TB 级甚至 PB 级日志增长,传统存储方案(如本地文件、关系型数据库)难以支撑海量数据的长期存储与快速检索,且无法通过横向扩展满足业务增长需求;
- 合规审计压力大:金融、政务、医疗等行业需满足等保 2.0、PCI DSS、数据安全法等合规要求,需实现日志的完整留存、可追溯查询、安全存储,但传统方案难以满足日志的全生命周期管理与合规校验需求。
为解决上述问题,企业亟需一套统一、高效、可扩展、实时化的日志分析解决方案,实现日志数据的集中采集、结构化处理、海量存储、快速检索与可视化分析。ELK(Elasticsearch+Logstash+Kibana)作为开源生态中成熟的企业级日志分析架构,凭借分布式存储、实时检索、灵活适配、可视化能力强等核心优势,能够完美覆盖 “日志采集 - 清洗转换 - 存储 - 分析 - 可视化 - 告警” 全流程,帮助企业打破日志数据孤岛,提升运维效率、降低故障损失、满足合规要求,为业务持续稳定运行提供坚实的数据支撑,成为企业数字化转型过程中的关键基础设施。
核心技术介绍
Elasticsearch介绍
Elasticsearch(简称ES) 是一个开源的、分布式的、基于 Lucene 构建的 搜索和分析引擎。它能够近乎实时地存储、搜索和分析大量数据。它提供了基于RESTful web接口的一个分布式多用户能力的全文搜索引擎。此外,Elasticsearch是基于java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
Elasticsearch核心概念
- 集群(Cluster):由一个或多个节点组成的集合,共同存储全部数据并提供索引和搜索功能,集群通过唯一的
cluster.name标识(默认值为 “elasticsearch”),企业级部署中需自定义集群名称确保唯一性。 - 节点(Node):集群中的单个服务器,是数据存储和计算的基本单元,每个节点通过
node.name标识。根据功能可分为主节点(Master Node,负责集群管理、分片分配)、数据节点(Data Node,负责数据存储、检索与分析)、协调节点(Coordinating Node,负责请求路由与结果聚合)等,生产环境中建议拆分角色保障稳定性。 - 索引(Index):类似关系型数据库中的 “数据库”,是具有相同结构的文档集合(如 “syslog-2025.11.04” 表示 2025 年 11 月 4 日的系统日志索引)。索引名称需小写,支持通配符匹配(如
syslog-*),便于日志按日期、类型分类管理。 - 类型(Type):早期版本中用于区分索引内不同结构的文档(类似数据库中的 “表”),在 7.x 及以上版本中已被废弃,一个索引仅支持一种文档结构,简化数据模型。
- 文档(Document):Elasticsearch 中的最小数据单元,类似关系型数据库中的 “行”,以 JSON 格式存储(如一条结构化的系统日志记录)。每个文档有唯一的
_id标识,可手动指定或自动生成。 - 字段(Field):文档中的具体数据项,类似关系型数据库中的 “列”(如日志的
timestamp(时间戳)、host(主机名)、log_message(日志内容)等字段)。 - 映射(Mapping):类似关系型数据库中的 “表结构定义”,用于定义文档中字段的类型(如文本型
text、数值型long、日期型date)、分词器、索引规则等。Elasticsearch 支持动态映射(自动识别字段类型)和自定义映射(手动优化字段配置)。 - 分片(Shard):为解决单节点存储容量限制,索引会被拆分为多个分片(默认 5 个主分片),每个分片是独立的 Lucene 索引,可分布在集群不同节点上,实现并行存储与查询,提升系统吞吐量。
- 副本(Replica):主分片的冗余备份(默认 1 个副本),用于保障数据高可用 —— 当主分片所在节点故障时,副本可自动切换为主分片;同时副本也可分担查询请求,提升检索性能。
Logstash介绍
Logstash 是 ELK 架构中的日志采集与数据处理中枢,是一款开源的服务器端数据处理管道工具。它能够从多源采集分散的日志数据,通过灵活的过滤规则完成数据清洗、结构化转换、字段富集等处理,最终将标准化的数据转发至 Elasticsearch 等目标存储,彻底解决日志 “分散、杂乱、非结构化” 的核心痛点,是连接日志数据源与存储分析引擎的关键桥梁。
核心特性
-
多源日志采集能力:支持丰富的输入插件(Input Plugin),可覆盖全场景日志采集需求 —— 包括本地文件(如 Linux
/var/log/messages)、网络端口(TCP/UDP)、消息队列(Kafka/RabbitMQ)、数据库(MySQL/PostgreSQL)、云服务(AWS CloudWatch、阿里云 SLS)、日志转发工具(Filebeat)等,适配系统日志、应用日志、网络设备日志、用户操作日志等各类数据源。 -
灵活的过滤处理机制:
核心的过滤插件(Filter Plugin)是数据结构化的核心,支持多种数据处理操作:
- 通过
grok插件解析非结构化文本日志(如 Nginx 访问日志、Java 堆栈日志)为键值对格式; - 通过
mutate插件修改字段类型、重命名字段、删除冗余字段; - 通过
date插件标准化时间格式(如将不同格式的时间戳统一为 ISO 8601 格式); - 通过
geoip插件补充 IP 地址对应的地理位置(国家、城市)信息; - 通过
json插件直接解析 JSON 格式日志,提取嵌套字段。
- 通过
-
多目标数据输出:通过输出插件(Output Plugin)将处理后的标准化数据转发至核心目标 Elasticsearch,也支持转发至 Kafka、Redis、本地文件、邮件、Webhook 等,适配数据备份、二次处理等多样化需求。
-
可扩展的管道机制:支持多管道配置,可针对不同类型日志(如系统日志、应用报错日志、接口访问日志)创建独立的处理管道,实现日志的分类采集、差异化处理(如不同日志的解析规则、字段过滤策略),提升处理效率与灵活性。
-
高可用与容错保障:支持队列机制(内存队列 / 持久化队列),当 Elasticsearch 等目标服务不可用时,可缓存日志数据避免丢失;通过
sincedb机制记录文件读取位置,实现断点续传,避免日志重复采集或遗漏。
核心架构
Logstash 的核心架构由 “输入(Input)→过滤(Filter)→输出(Output)” 三部分组成,部分场景可增加 “编码 / 解码(Codec)” 组件优化数据传输格式:
- 输入层:采集多源日志数据,将原始日志转换为 Logstash 内部事件格式;
- 过滤层:对原始日志进行清洗、结构化、富集处理,提升数据质量;
- 输出层:将处理后的标准化事件转发至目标存储或系统;
- 编码 / 解码层:支持在输入 / 输出阶段对数据进行编码(如 JSON、CSV)或解码,适配不同数据源与目标的格式要求。
Kibana介绍
Kibana 是 ELK 架构中的可视化分析与操作平台,作为 Elasticsearch 的官方配套工具,它提供了直观的图形化界面,让用户无需编写复杂的 ES 查询语句,即可实现日志数据的检索、可视化分析、集群管理、告警配置等操作。Kibana 是 “让日志数据说话” 的核心入口,降低了日志分析的技术门槛,使运维人员、开发人员、安全审计人员、业务分析师等不同角色都能高效利用日志数据。
核心特性
-
全功能日志检索:提供简洁的查询编辑器,支持两种查询模式 —— 新手友好的 “Kibana Query Language(KQL)”(可视化条件筛选,如按时间范围、字段值过滤)和专业的 “Lucene 查询语法”,可快速检索日志详情。支持日志高亮显示、字段筛选、按字段排序、日志导出等功能,助力快速定位故障根因。
-
丰富的可视化能力
:支持多种图表类型,覆盖各类分析场景:
- 基础图表:折线图(时序趋势分析,如接口访问量变化)、柱状图(分类统计,如不同主机报错次数)、饼图(占比分析,如不同错误类型占比)、表格(详细数据展示);
- 高级图表:热力图(密集数据分布分析,如峰值时段访问分布)、地图(地理信息分析,如用户访问地域分布)、仪表盘(指标数值展示,如当前系统报错率)、Markdown(文档说明与指标注释)。
-
自定义仪表盘(Dashboard):支持将多个可视化图表组合为专属仪表盘,集中展示核心监控指标。例如,运维人员可创建 “系统运维仪表盘”,包含 CPU 使用率、内存占用、磁盘使用率、报错次数、接口响应时间等指标;安全人员可创建 “安全审计仪表盘”,包含异常登录次数、攻击行为统计、敏感操作记录等指标,支持按业务场景灵活定制。
-
索引与数据管理:提供图形化界面管理 Elasticsearch 索引,包括创建索引模式(关联 ES 索引,用于数据查询与可视化)、配置字段映射、管理索引生命周期(ILM,如自动创建、滚动、删除过期索引),无需手动调用 ES RESTful API,降低操作门槛。
-
集群监控与告警:内置 “Stack Monitoring” 功能,可实时查看 Elasticsearch、Logstash、Kibana 组件的运行状态,包括 CPU / 内存 / 磁盘使用率、数据吞吐量、请求延迟、分片状态等指标,及时发现组件异常。支持配置告警规则(如日志报错率超过 5%、ES 磁盘使用率达到 85%),通过邮件、Slack、Webhook 等方式推送告警通知,实现异常及时响应。
-
易用性与扩展性:支持中文界面、自定义主题与导航,操作逻辑简洁直观,非技术人员也可快速上手;通过插件生态扩展功能,如报表导出插件(将仪表盘导出为 PDF/PNG)、高级数据分析插件(机器学习异常检测)、第三方系统集成插件(与 Jenkins、Grafana 联动),适配企业个性化需求。
核心模块
Kibana 的核心功能模块围绕日志分析全流程设计,主要包括:
- Discover(发现):日志检索与详情查看,支持字段筛选、时间范围限定、关键词搜索;
- Visualize Library(可视化库):创建、编辑、管理单个可视化图表;
- Dashboards(仪表盘):组合多个可视化图表,集中展示核心指标;
- Stack Management(堆栈管理):索引模式配置、字段映射管理、索引生命周期管理、用户权限控制;
- Stack Monitoring(堆栈监控):ELK 组件运行状态监控与指标分析;
- Alerts and Actions(告警与操作):配置告警规则与通知方式,实现异常告警自动化。
案例:部署ELK日志分析系统
环境准备
配置和安装ELK日志分析系统,安装集群方式,2个elasticsearch节点,并监控apache服务器日志
主机名和IP地址
| 主机名 | 操作系统 | IP地址 | 主要软件 |
|---|---|---|---|
| node1 | Centos7 | 192.168.108.41/24 | Elasticsearch、Kibana |
| node2 | Centos7 | 192.168.108.42/24 | Elasticsearch |
| apache | Centos7 | 192.168.108.43/24 | Logstash Apache |
基础环境要求
-
操作系统:Centos7(个人推荐64位、内存至少4G、生产环境至少8G、硬盘至少100G)
-
依赖软件:JDK1.8+(Elasticsearch、Logstash 依赖 Java 环境)
-
网络配置:开放端口(Elasticsearch 9200/9300、Logstash 5044、Kibana 5601),确保组件间网络互通。
-
节点:三台服务器,分别为node1,node2和apache
系统环境配置(三个节点)
-
设置ip地址、网关和dns
-
设置主机名,并且配置主机名解析
-
安装JDK并配置环境变量,执行java -version验证是否安装成功
-
关闭防火墙和Selinux
-
配置主机名解析
#node1 node2 apache
#更改ip地址
nmcli connection modify ens33 ipv4.method manual ipv4.address 192.168.108.xx/24 ipv4.gateway 192.168.108.2 ipv4.dns 192.168.108.2 autoconnect yes
#更改主机名
hostnamectl set-hostname node1/node2/apache
#配置主机名解析
vim /etc/hosts
192.168.108.41 node1
192.168.108.42 node2
#安装jdk,若系统有则不用安装
yum install -y java
#安装JDK
yum install -y java-1.8.0-openjdk
#验证
java -version
#关闭防火墙
systemctl disable firewalld --now
#关闭selinux
vim /etc/selinux/config
..... 将enforcing 改为disable,重启后生效
部署Elasticsearch软件
node1节点配置【elasticsearch】服务
1、安装elasticsearch—rpm包,上传elasticsearch-5.5.0.rpm到/opt目录下。
[root@node1 opt]# cd /opt
[root@node1 opt]# rpm -ivh elasticsearch-5.5.0.rpm
2.加载系统服务并设置开机自启
[root@node1 opt]# systemctl daemon-reload
[root@node1 opt]# systemctl enable elasticsearch.service
3.更改elasticsearch配置文件
#备份原有配置文件
[root@node1 opt]# cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
#更改配置.yml配置文件
[root@node1 opt]# vim /etc/elasticsearch/elasticsearch.yml
17/ cluster.name: my-elk-cluster #集群名字
23/ node.name: node1 #节点名字
33/ path.data: /data/elk_data #数据存放路径,目前还没创建
37/ path.logs: /var/log/elasticsearch/ #日志存放路径
43/ bootstrap.memory_lock: false #不在启动的时候锁定内存:锁定物理内存地址,防止es内存被交换出去,也就是避免es使用swap交换分区,频繁的交换,会导致IOPS变高。
55/ network.host: 0.0.0.0 ####提供服务绑定的IP地址,0.0.0.0代表所有地址
59/ http.port: 9200 ####侦听端口为9200
68/ discovery.zen.ping.unicast.hosts: ["node1", "node2"] ####集群发现通过单播实现
#更改完后进一步验证更改内容
#跳过空行和注释行 -v:反向匹配(invert match),即排除匹配到的行。
[root@node1 opt]# grep -v "^#" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-elk-cluster
node.name: node1
path.data: /data/elk_data
path.logs: /var/log/elasticsearch/
bootstrap.memory_lock: false
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["node1", "node2"]
4.创建数据存放路径,更改路径权限
[root@node1 opt]# mkdir -p /data/elk_data
[root@node1 opt]# chown elasticsearch:elasticsearch /data/elk_data/
#验证
[root@node1 opt]# ll /data/
total 0
drwxr-xr-x. 2 elasticsearch elasticsearch 6 Nov 4 16:24 elk_data
5.启动elasticsearch服务,并验证进程是否开启
#服务启动
[root@node1 elasticsearch]# systemctl start elasticsearch.service
#安装net-tools网络工具包
[root@node1 opt]# yum install -y net-tools
#查看进程
[root@node1 elasticsearch]# netstat -antp |grep 9200
[root@node1 opt]# netstat -lntp |grep 9200
tcp6 0 0 :::9200 :::* LISTEN 10202/java
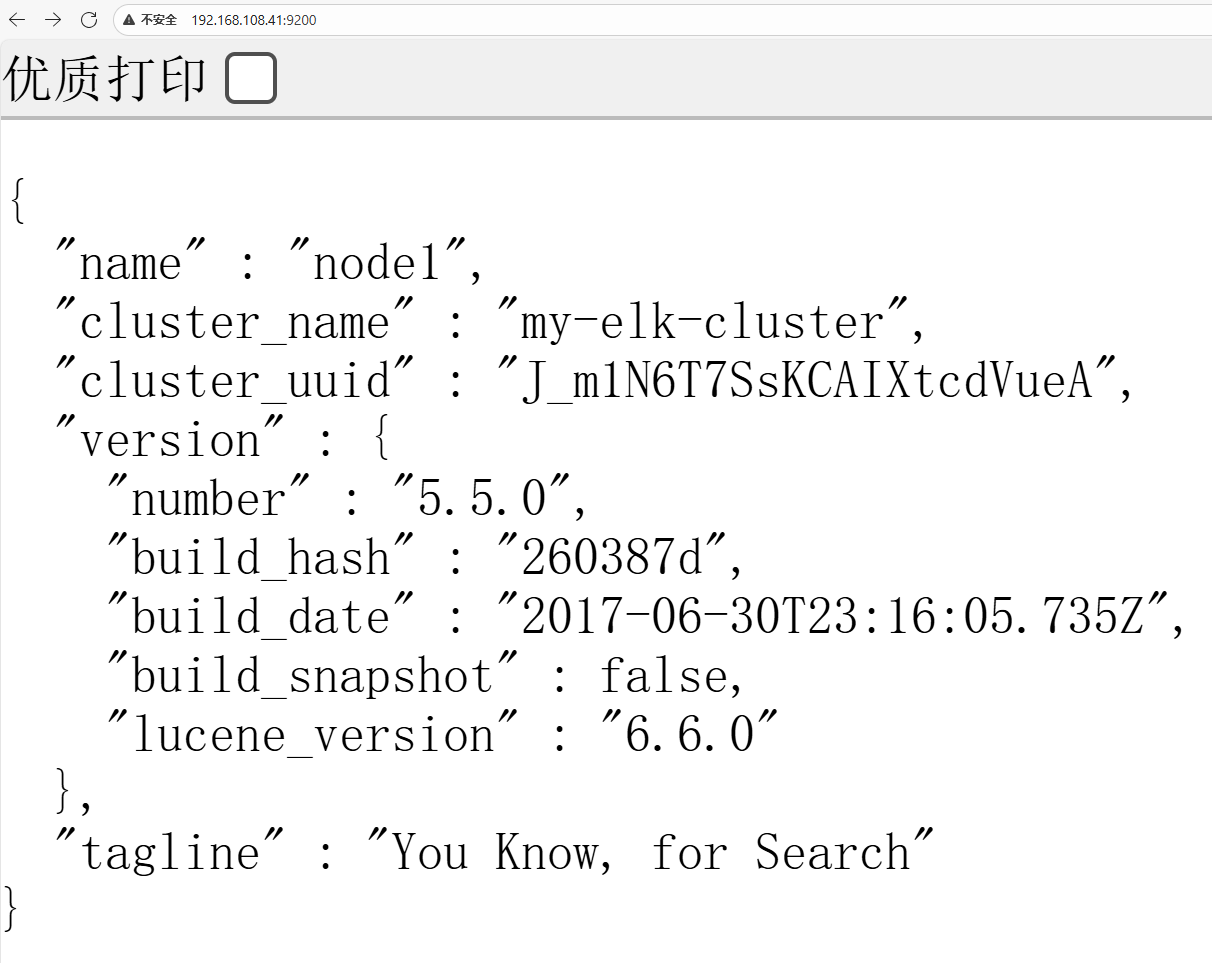
6.用浏览器访问node1,验证是否能在浏览器上看到节点信息: http://192.168.108.41:9200
node2节点配置【elasticsearch】服务
1、安装elasticsearch—rpm包,上传elasticsearch-5.5.0.rpm到/opt目录下。
[root@node2 opt]# cd /opt
[root@node2 opt]# rpm -ivh elasticsearch-5.5.0.rpm
2.加载系统服务并设置开机自启
[root@node2 opt]# systemctl daemon-reload
[root@node2 opt]# systemctl enable elasticsearch.service
3.更改elasticsearch配置文件
#备份原有配置文件
[root@node2 opt]# cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
#更改配置.yml配置文件
[root@node2 opt]# vim /etc/elasticsearch/elasticsearch.yml
17/ cluster.name: my-elk-cluster #集群名字
23/ node.name: node2 #节点名字
33/ path.data: /data/elk_data #数据存放路径,目前还没创建
37/ path.logs: /var/log/elasticsearch/ #日志存放路径
43/ bootstrap.memory_lock: false #不在启动的时候锁定内存:锁定物理内存地址,防止es内存被交换出去,也就是避免es使用swap交换分区,频繁的交换,会导致IOPS变高。
55/ network.host: 0.0.0.0 ####提供服务绑定的IP地址,0.0.0.0代表所有地址
59/ http.port: 9200 ####侦听端口为9200
68/ discovery.zen.ping.unicast.hosts: ["node1", "node2"] ####集群发现通过单播实现
#更改完后进一步验证更改内容
#跳过空行和注释行 -v:反向匹配(invert match),即排除匹配到的行。
[root@node2 opt]# grep -v "^#" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-elk-cluster
node.name: node2
path.data: /data/elk_data
path.logs: /var/log/elasticsearch/
bootstrap.memory_lock: false
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["node1", "node2"]
4.创建数据存放路径,更改路径权限
[root@node2 opt]# mkdir -p /data/elk_data
[root@node2 opt]# chown elasticsearch:elasticsearch /data/elk_data/
#验证
[root@node2 opt]# ll /data/
total 0
drwxr-xr-x. 2 elasticsearch elasticsearch 6 Nov 4 16:51 elk_data
5.启动elasticsearch服务,并验证进程是否开启
#服务启动
[root@node2 elasticsearch]# systemctl start elasticsearch.service
#安装net-tools网络工具包
[root@node2 opt]# yum install -y net-tools
#查看进程
[root@node2 elasticsearch]# netstat -antp |grep 9200
[root@node2 opt]# netstat -lntp | grep 9200
tcp6 0 0 :::9200 :::* LISTEN 9739/java
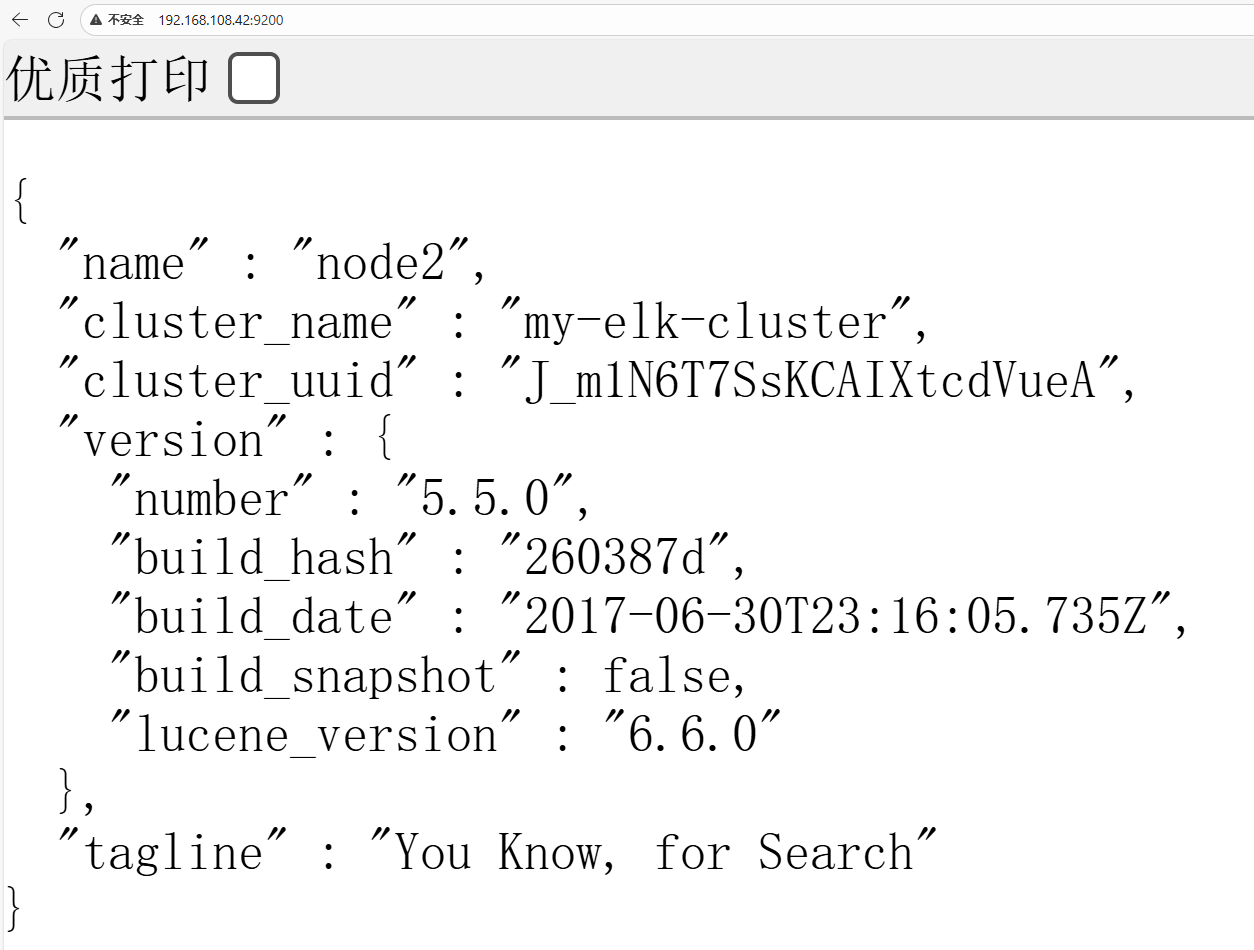
6.用浏览器访问node2,验证是否能在浏览器上看到节点信息: http://192.168.108.42:9200
检查集群的健康和集群状态
/_cluster/health?pretty 是Elasticsearch 提供的一个 RESTful API 接口路径(URL 路径),在浏览器上用node1节点访问这个路径:http://192.168.108.41:9200/_cluster/health?pretty,查看node1节点的状态信息
{
"cluster_name": "my-elk-cluster",
"status": "green",
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
用node2访问这个/_cluster/health?pretty这个路径:http://192.168.108.42:9200/_cluster/health?pretty,查看node2的状态信息
{
"cluster_name": "my-elk-cluster",
"status": "green",
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}
安装elasticsearch-head插件
上述查看集群的方式,不够美观,我们通过安装elasticsearch-head插件来管理集群
node1节点
#上传node-v8.2.1.tar.gz到/opt
yum install gcc gcc-c++ make -y
###编译安装node组件依赖包##耗时比较长 47分钟
[root@node1 opt]# cd /opt
[root@node1 opt]# tar xzvf node-v8.2.1.tar.gz
[root@node1 opt]# cd node-v8.2.1/
[root@node1 node-v8.2.1]# ./configure
[root@node1 node-v8.2.1]# make -j3 (等待时间较长)
[root@node1 node-v8.2.1]# make install
安装phantomjs前端框架
上传软件包到 /usr/local/src/
[root@node1 node-v8.2.1]# cd /usr/local/src/
[root@node1 src]# yum install -y bzip2
[root@node1 src]# tar xjvf phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@node1 src]# cd phantomjs-2.1.1-linux-x86_64/bin
[root@node1 bin]# cp phantomjs /usr/local/bin
安装elasticsearch-head数据可视化工具
[root@node1 bin]# cd /usr/local/src/
[root@node1 src]# tar xzvf elasticsearch-head.tar.gz
[root@node1 src]# cd elasticsearch-head/
[root@node1 elasticsearch-head]# npm install
必须先进入到
elasticsearch-head项目目录(即包含package.json的目录)才能运行npm run start,原因:npm命令的工作机制依赖于当前目录下的package.json文件
修改主配置文件
[root@node1 ~]# cd ~
[root@node1 ~]# vim /etc/elasticsearch/elasticsearch.yml ####下面配置文件,插末尾##
http.cors.enabled: true ##开启跨域访问支持,默认为false
http.cors.allow-origin: "*" ## 跨域访问允许的域名地址
[root@node1 ~]# systemctl restart elasticsearch
启动elasticsearch-head 启动服务器
[root@node1 ~]# cd /usr/local/src/elasticsearch-head/
[root@node1 elasticsearch-head]# npm run start &
[1] 65834
[root@node1 elasticsearch-head]#
> elasticsearch-head@0.0.0 start /usr/local/src/elasticsearch-head
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
#上面都是运行产生的内容
[root@node1 elasticsearch-head]# netstat -lnupt | grep 9100
tcp 0 0 0.0.0.0:9100 0.0.0.0:* LISTEN 65844/grunt
[root@node1 elasticsearch-head]# netstat -lnupt | grep 9200
tcp6 0 0 :::9200 :::* LISTEN 65722/java
node2节点
上传node-v8.2.1.tar.gz到/opt
编译安装node组件依赖包##耗时比较长 47分钟
[root@node2 opt]# yum install gcc gcc-c++ make -y
[root@node2 opt]# cd /opt
[root@node2 opt]# tar xzvf node-v8.2.1.tar.gz
[root@node2 opt]# cd node-v8.2.1/
[root@node2 node-v8.2.1]# ./configure
[root@node2 node-v8.2.1]# make -j3 (等待时间较长)
[root@node2 node-v8.2.1]# make install
安装phantomjs
上传软件包到/usr/local/src/
[root@node2 node-v8.2.1]# cd /usr/local/src/
[root@node2 src]# yum install -y bzip2
[root@node2 src]# tar xjvf phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@node2 src]# cd phantomjs-2.1.1-linux-x86_64/bin
[root@node2 bin]# cp phantomjs /usr/local/bin
安装elasticsearch-head
[root@node2 bin]# cd /usr/local/src/
[root@node2 src]# tar xzvf elasticsearch-head.tar.gz
[root@node2 src]# cd elasticsearch-head/
[root@node2 elasticsearch-head]# npm install
修改主配置文件
[root@node2 ~]# cd ~
[root@node2 ~]# vi /etc/elasticsearch/elasticsearch.yml ####下面配置文件,插末尾##
http.cors.enabled: true ##开启跨域访问支持,默认为false
http.cors.allow-origin: "*" ## 跨域访问允许的域名地址
[root@localhost ~]# systemctl restart elasticsearch
启动elasticsearch-head 启动服务器
[root@node2 ~]# cd /usr/local/src/elasticsearch-head/
[root@node2 elasticsearch-head]# npm run start &
[1] 70986
[root@node2 elasticsearch-head]#
> elasticsearch-head@0.0.0 start /usr/local/src/elasticsearch-head
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
[root@node2 elasticsearch-head]# netstat -lnput | grep 9100
tcp 0 0 0.0.0.0:9100 0.0.0.0:* LISTEN 70997/grunt
[root@node2 elasticsearch-head]# netstat -lnput | grep 9200
tcp6 0 0 :::9200 :::* LISTEN 70870/java
节点验证
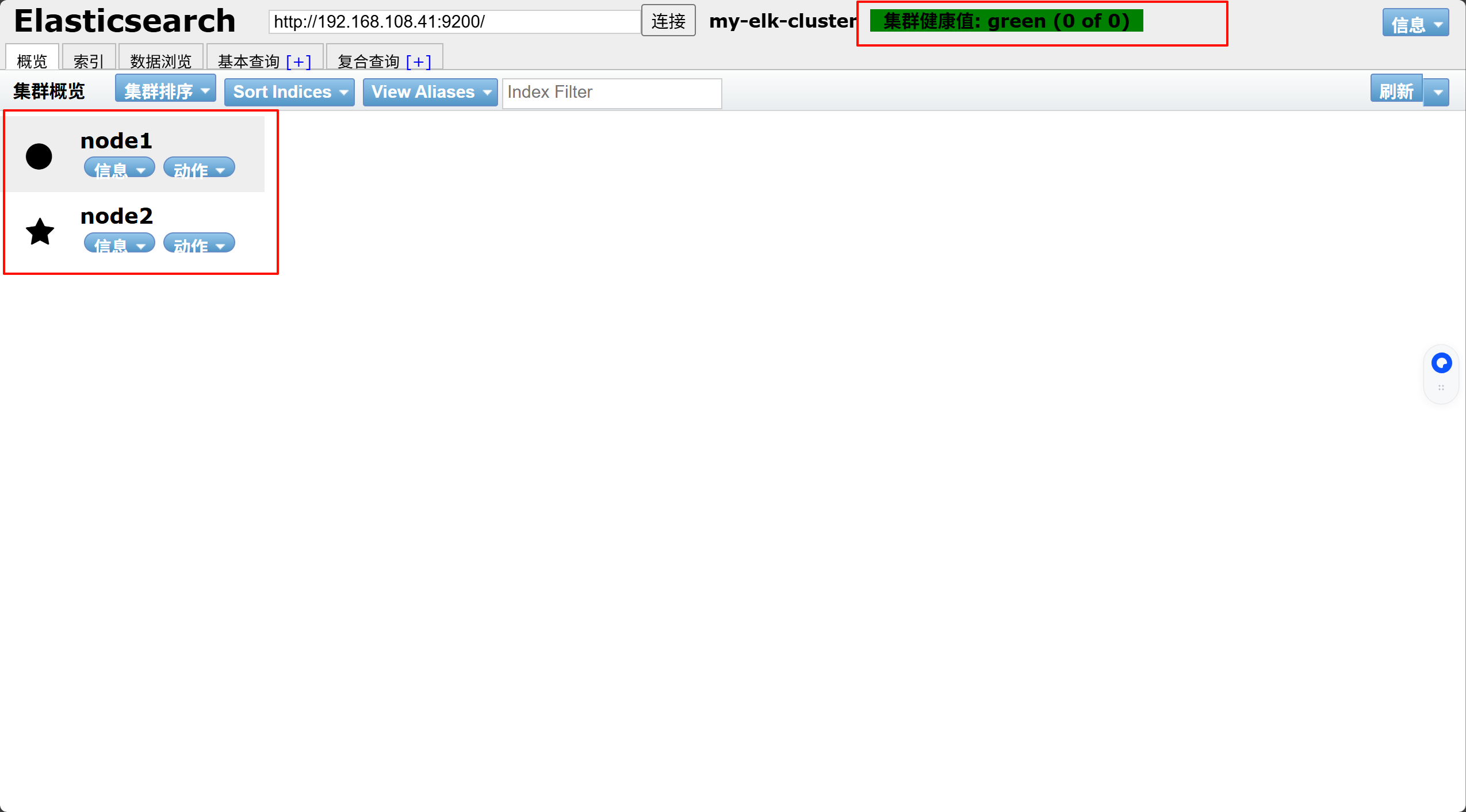
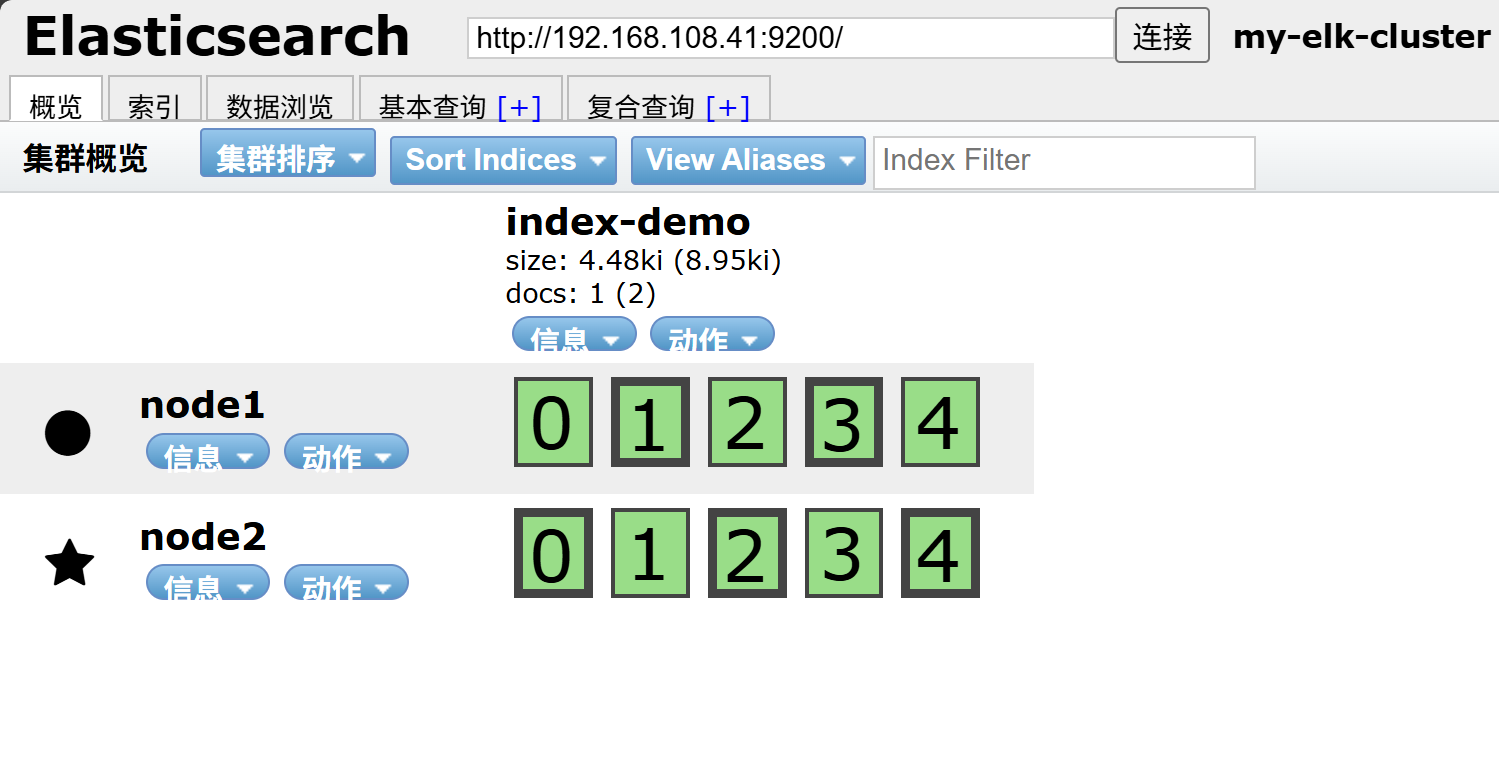
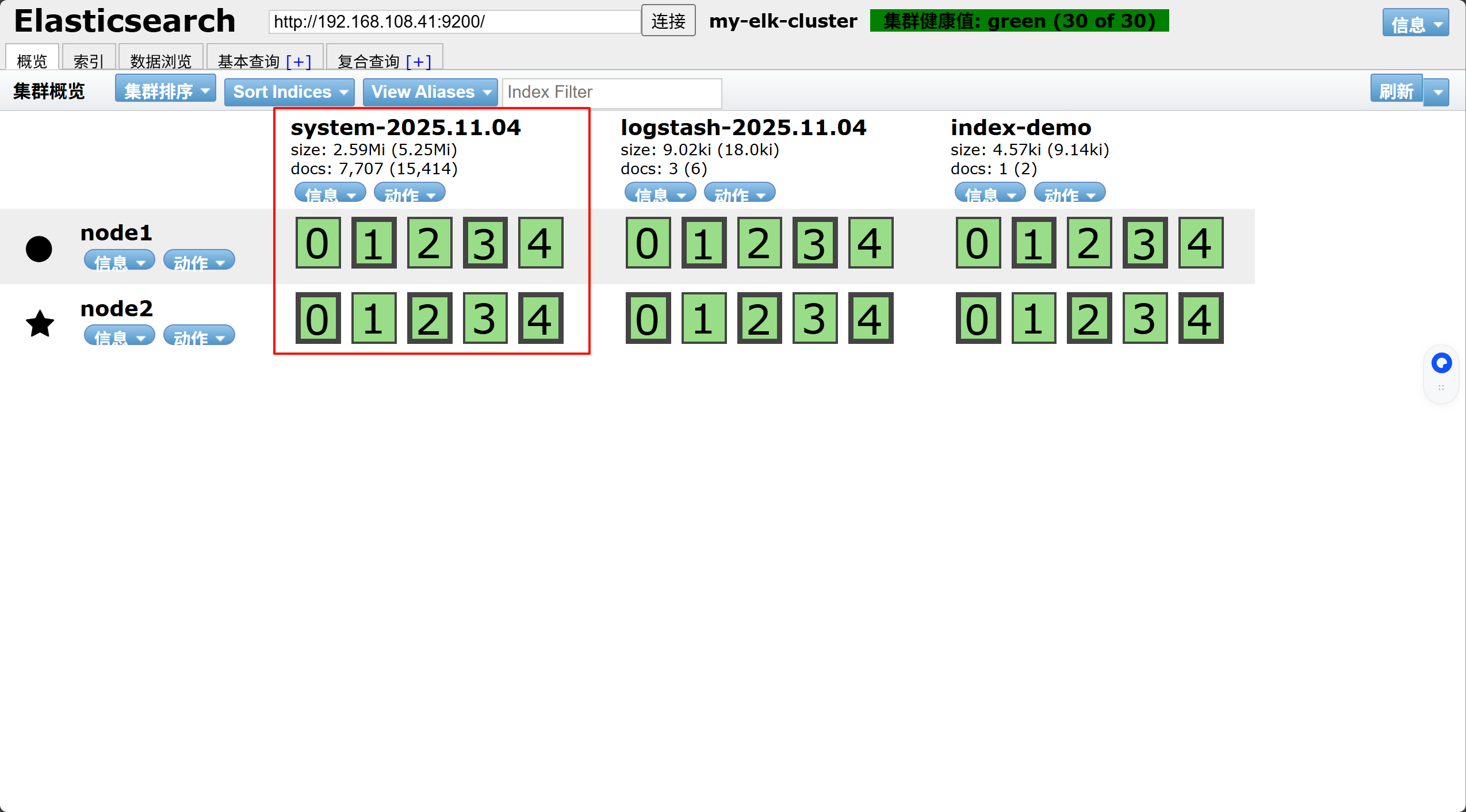
在浏览器输入http://192.168.108.41:9100/ 可以看见群集很健康是绿色
在Elasticsearch 后面的栏目中输入http://192.168.108.41:9200 ,点击连接

然后点连接 会发现:集群健康值: green (0 of 0)
●node1信息动作
★node2信息动作
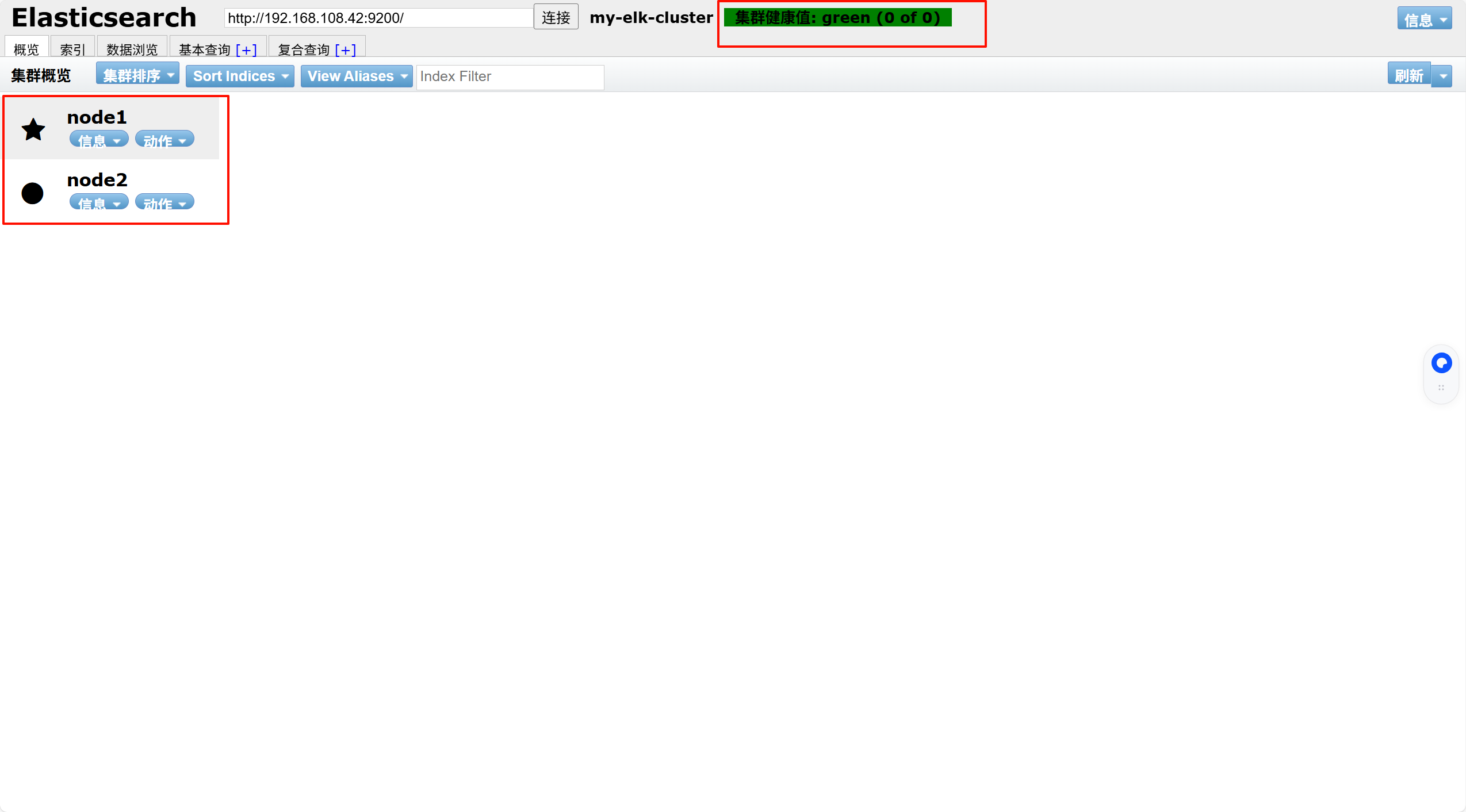
在浏览器输入http://192.168.108.42:9100/ 可以看见群集很健康是绿色
在Elasticsearch 后面的栏目中输入http://192.168.108.42:9200
然后点连接 会发现:集群健康值: green (0 of 0)
●node1信息动作
★node2信息动作

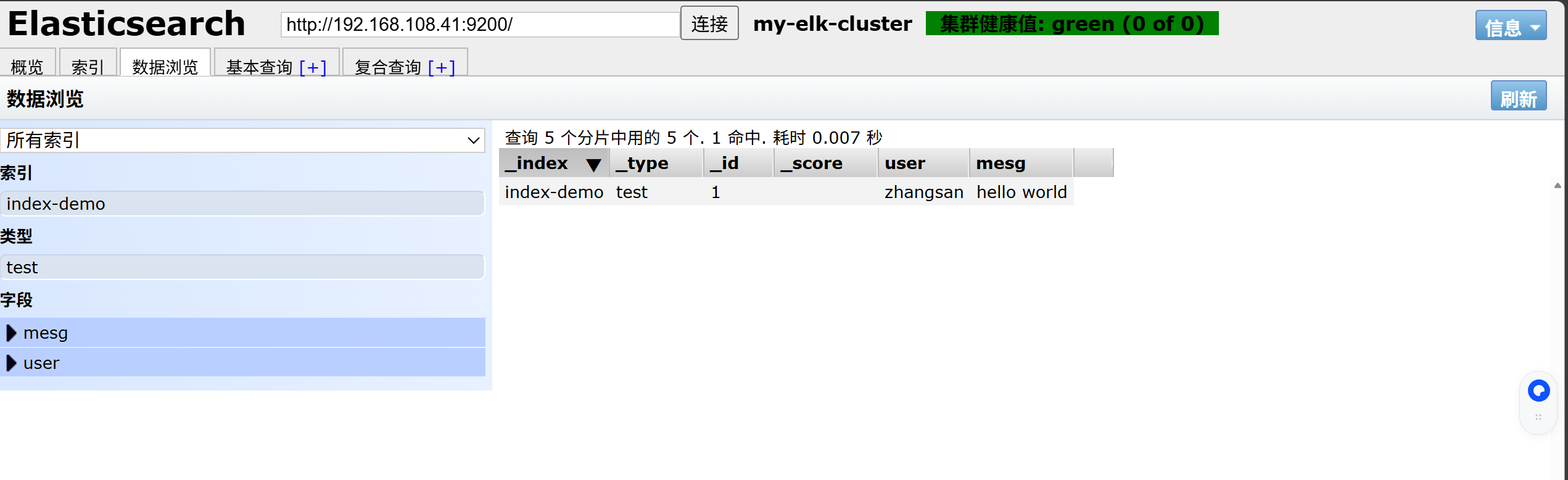
登录 node1主机,索引为index-demo,类型为test,可以看到成功创建
[root@node1 elasticsearch-head]# curl -XPUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
{
"_index" : "index-demo",
"_type" : "test",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"created" : true
}
解析命令
- curl:命令行工具,用于与服务器传输数据
- -XPUT:指定HTTP请求方法为PUT
- ‘localhost:9200/index-demo/test/1?pretty&pretty’:请求URL,包含:
- localhost:9200:ES服务地址和端口
- index-demo:索引名称
- test:文档类型
- 1:文档ID
- pretty:格式化返回结果(重复两次)
- 请求头:
-H 'content-Type: application/json':指定请求内容类型为JSON - 请求体:
-d '{"user":"zhangsan","mesg":"hello world"}':要创建的JSON文档内容
该命令会在ES中创建/更新一个ID为1的文档,包含user和mesg两个字段。如果索引不存在会自动创建。
在浏览器输入http://192.168.108.41:9100/ 查看索引信息
node1信息动作 01234
node2信息动作 01234
●上面图可以看见索引默认被分片5个,并且有一个副本
点击数据浏览,会发现在node1上创建的索引为index-demo,类型为test, 相关的信息
安装logstash并做一些日志搜集输出到elasticsearch中
安装logstash并做一些日志搜集输出到elasticsearch中
再次提醒:更改主机名,关闭防火墙,安装Apache(httpd)服务,并且一定要按照java环境
安装logstash
上传logstash-5.5.1.rpm到/opt目录下
[root@apache ~]# cd /opt
#安装logstash
[root@apache opt]# rpm -ivh logstash-5.5.1.rpm
#启动logstash
[root@apache opt]# systemctl start logstash.service
[root@apache opt]# systemctl enable logstash.service
#建立logstash软连接
[root@apache opt]# ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
功能测试
logstash(Apache)与elasticsearch(node)功能是否正常,做对接测试
Logstash这个命令测试
字段描述解释:
● -f 通过这个选项可以指定logstash的配置文件,根据配置文件配置logstash
● -e 后面跟着字符串该字符串可以被当做logstash的配置(如果是” ”,则默认使用stdin做为输入、stdout作为输出)
● -t 测试配置文件是否正确,然后退出
采用标准输入/标准输出
输入采用标准输入 输出采用标准输出,登录apache节点,在Apache服务器上
#标准输入 输出格式
[root@apache opt]# logstash -e 'input { stdin{} } output { stdout{} }'
。。。。。。。。。。省略此处有报错不一定是真错。。。。。。。。
19:25:38.871 [[main]-pipeline-manager] INFO logstash.pipeline - Starting pipeline {"id"=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>250}
19:25:38.915 [[main]-pipeline-manager] INFO logstash.pipeline - Pipeline main started
The stdin plugin is now waiting for input:
19:25:38.981 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600}
www.baidu.com ####需要输入www.baidu.com
2025-11-04T11:26:02.560Z apache www.baidu.com
www.sina.com.cn ####需要输入www.sina.com.cn
2025-11-04T11:26:10.774Z apache www.sina.com.cn
#ctrl+C表示终止后输入结束 ctr+D表示完成后结束
采用rubydebug显示详细输出
使用rubydebug显示详细输出(可选),codec为一种编解码器
#rubydebug格式
[root@apache opt]# logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }'
ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console.
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
Could not find log4j2 configuration at path //usr/share/logstash/config/log4j2.properties. Using default config which logs to console
19:30:09.111 [[main]-pipeline-manager] INFO logstash.pipeline - Starting pipeline {"id"=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>250}
19:30:09.147 [[main]-pipeline-manager] INFO logstash.pipeline - Pipeline main started
The stdin plugin is now waiting for input:
19:30:09.257 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600}
www.baidu.com
{
"@timestamp" => 2025-11-04T11:30:17.339Z,
"@version" => "1",
"host" => "apache",
"message" => "www.baidu.com"
}
使用logstash将信息写入elasticsearch中,输入、输出对接
[root@apache opt]# logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.100.41:9200"] } }'
。。。。。。。。省略。。。。。。。
The stdin plugin is now waiting for input:
10:40:06.558 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600}
www.baidu.com ###输入内容
www.sina.com.cn ###输入内容
www.google.com.cn ###输入内容
访问测试
登录192.168.108.41 真机
打开浏览器 输入http://192.168.108.41:9100/ 查看索引信息
多出 logstash-2025.11.04
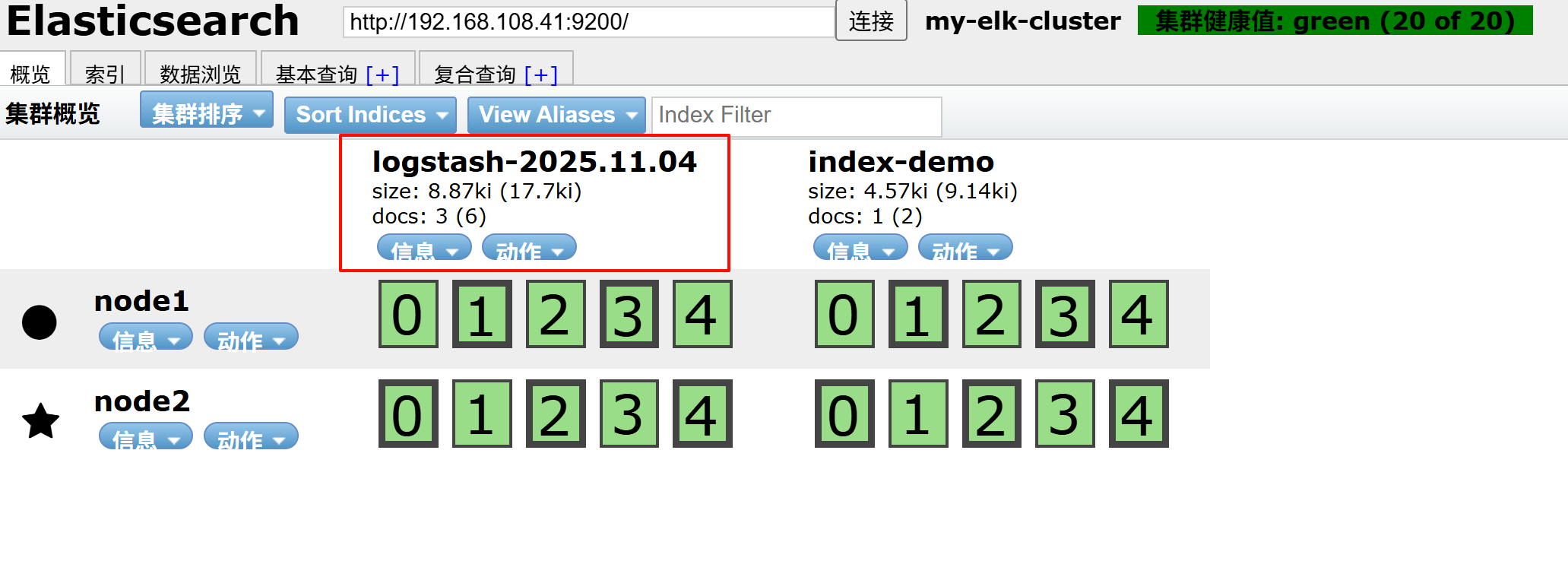
点击数浏览查看响应的内容
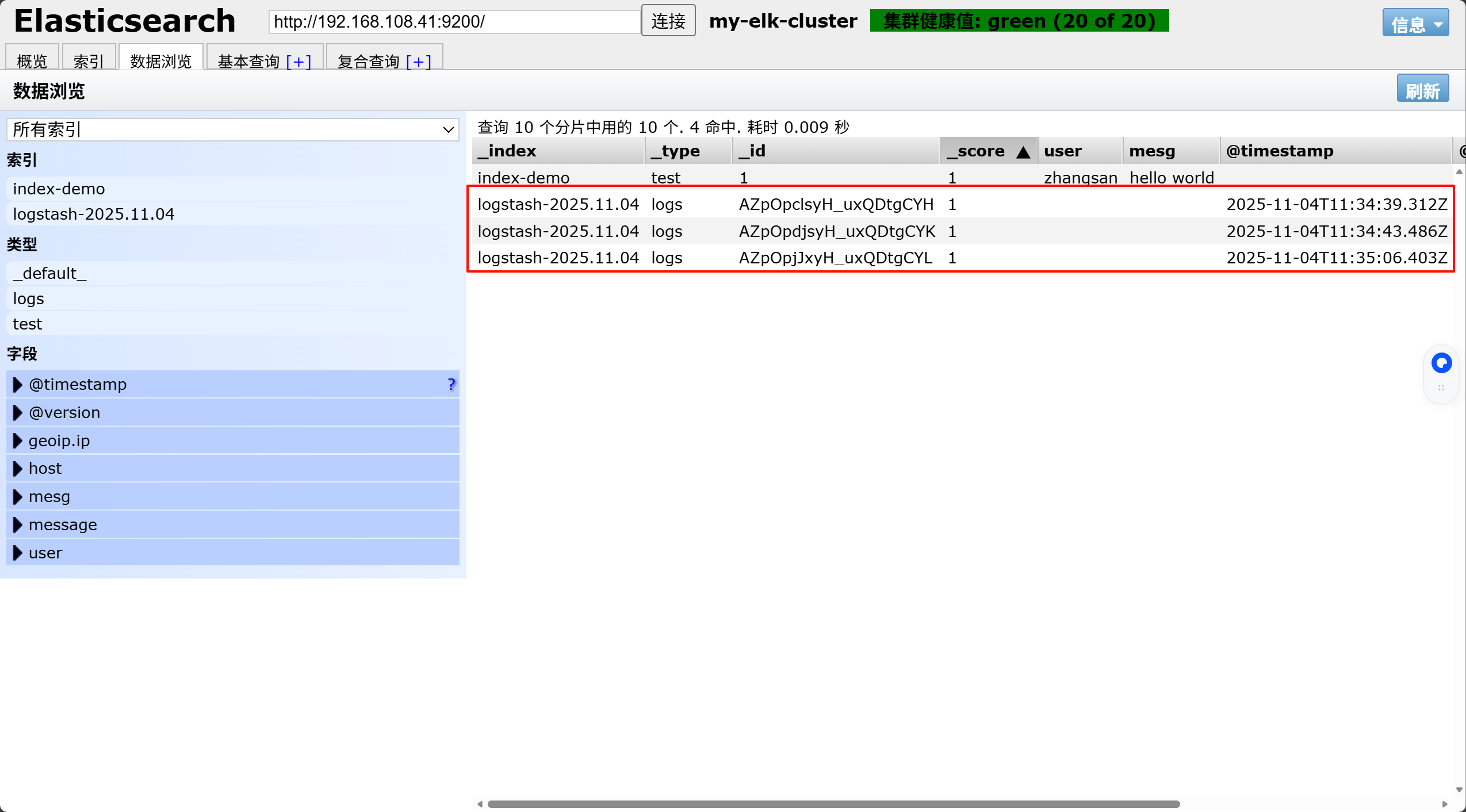
可以看出logstash 可以往 ElasticSearch 中写数据
【登录192.168.100.43 Apache主机 做对接配置】
logstash配置文件
Logstash配置文件主要由三部分组成:input、output、filter(根据需要)
[root@apache opt]# chmod o+r /var/log/messages
[root@apache opt]# ll /var/log/messages
-rw----r--. 1 root root 572555 4月 16 23:50 /var/log/messages
[root@apache opt]# vim /etc/logstash/conf.d/system.conf
input {
file{
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["192.168.100.41:9200"]
index => "system-%{+YYYY.MM.dd}"
}
}
[root@apache opt]# systemctl restart logstash.service
访问测试
登录到node1节点:http://192.168.108.41:9100/ 查看索引信息
多出 system-2025.11.04
在node1节点上安装kibana
上传kibana-5.5.1-x86_64.rpm 到/usr/local/src目录
[root@node1 ~]# cd /usr/local/src/
[root@node1 src]# rpm -ivh kibana-5.5.1-x86_64.rpm
[root@node1 src]# cd /etc/kibana/
[root@node1 kibana]# cp kibana.yml kibana.yml.bak
[root@node1 kibana]# vi kibana.yml
2/ server.port: 5601 #### kibana打开的端口
7/ server.host: "0.0.0.0" ####kibana侦听的地址
21/ elasticsearch.url: "http://192.168.100.41:9200" ###和elasticsearch建立联系
30/ kibana.index: ".kibana" ####在elasticsearch中添加.kibana索引
[root@node1 kibana]# systemctl start kibana.service ###启动kibana服务
[root@node1 kibana]# systemctl enable kibana.service ###开机启动kibana服务
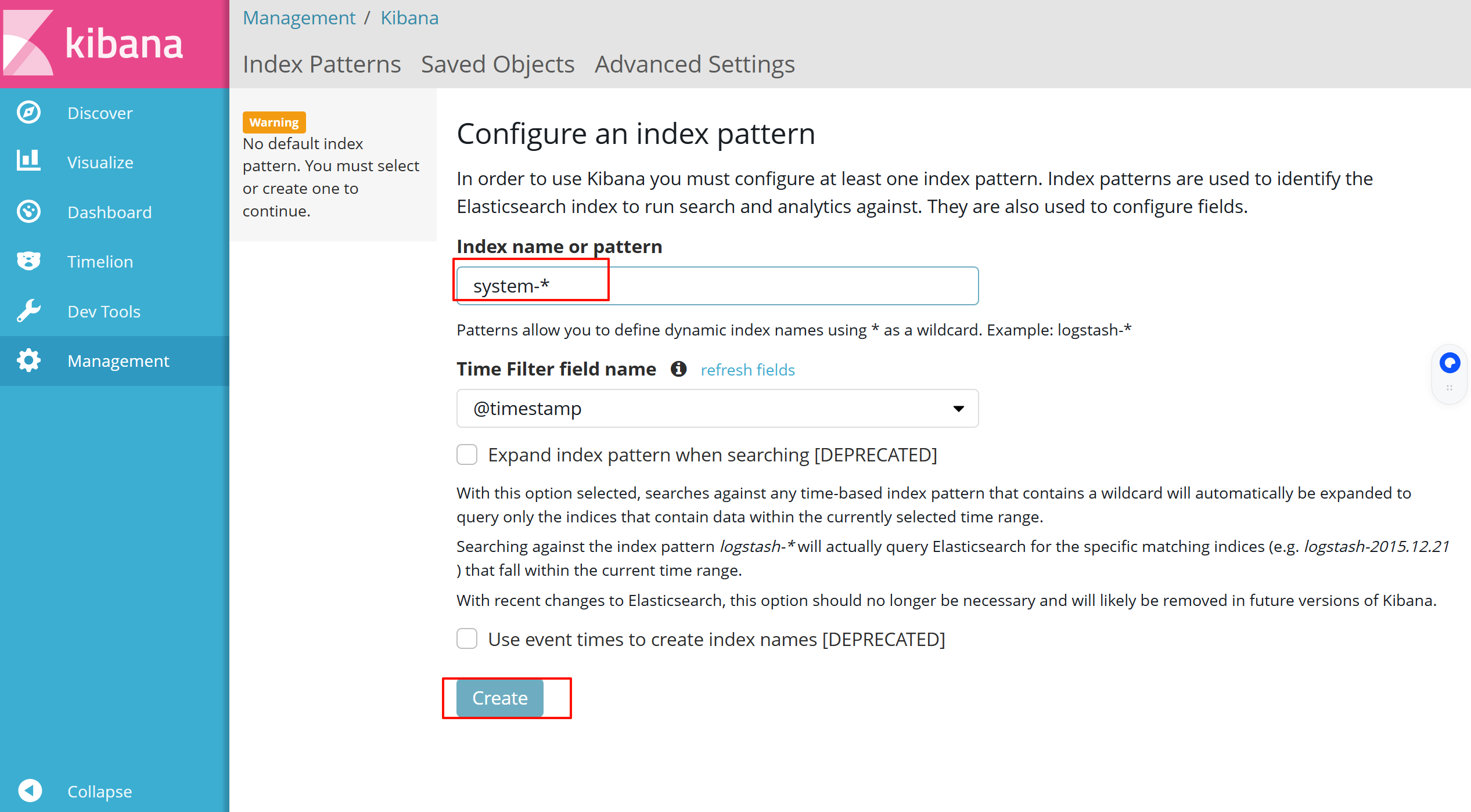
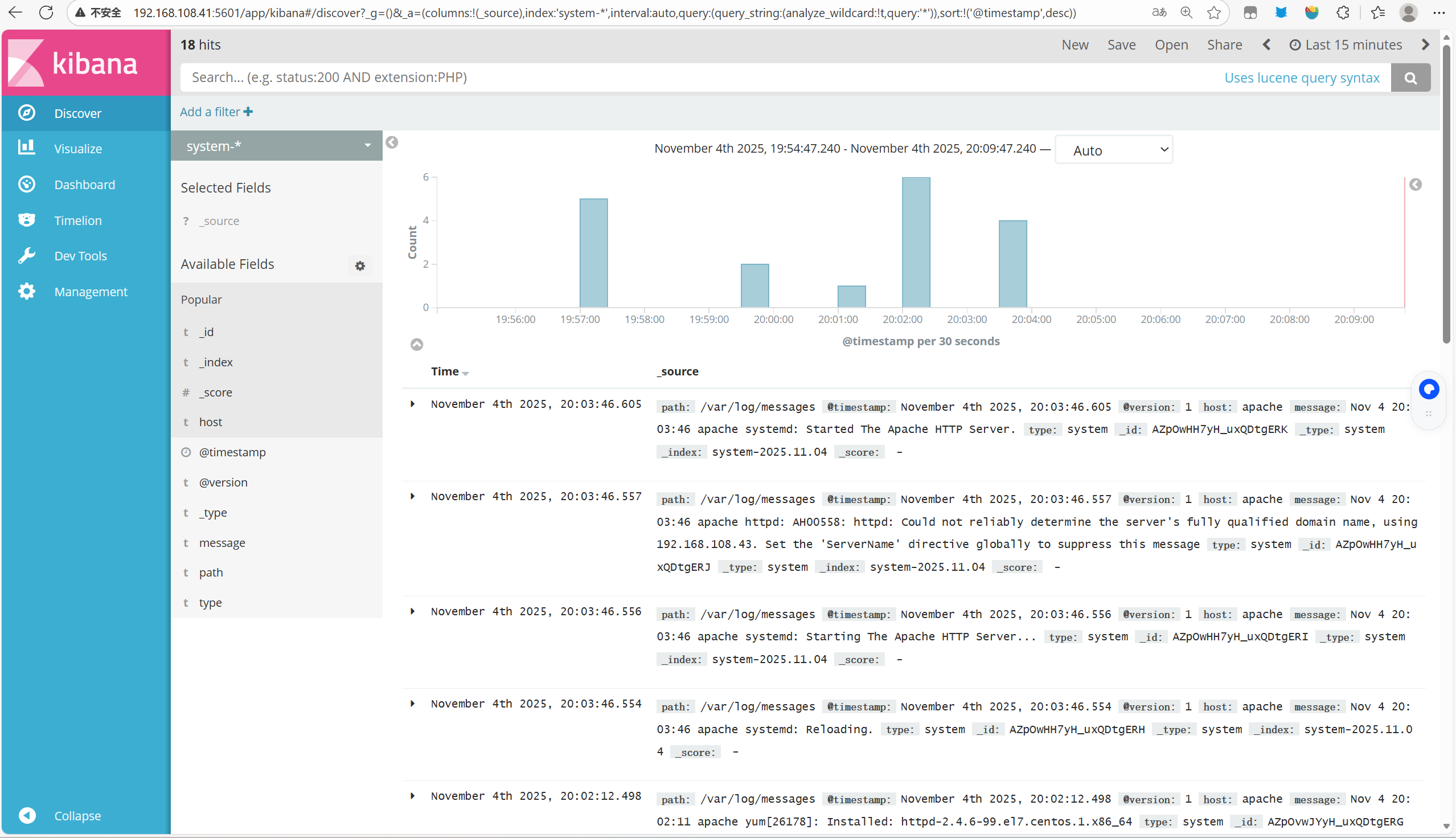
使用浏览器输入192.168.108.41:5601,登录到node1节点
首次登录创建一个索引 名字:system-* ,
这是对接系统日志文件 Index name or pattern
###下面输入system-* 然后点最下面的出面的create 按钮创建
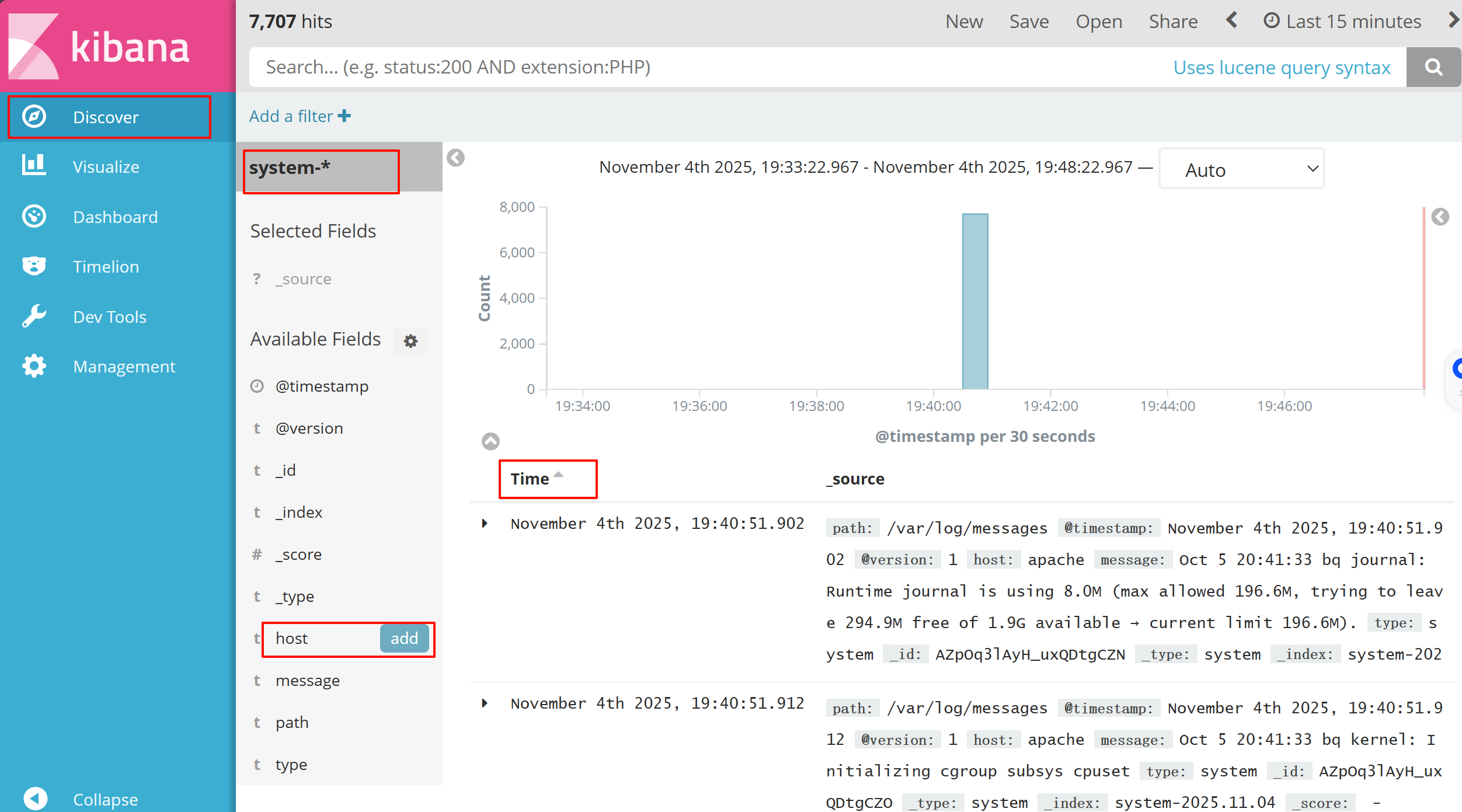
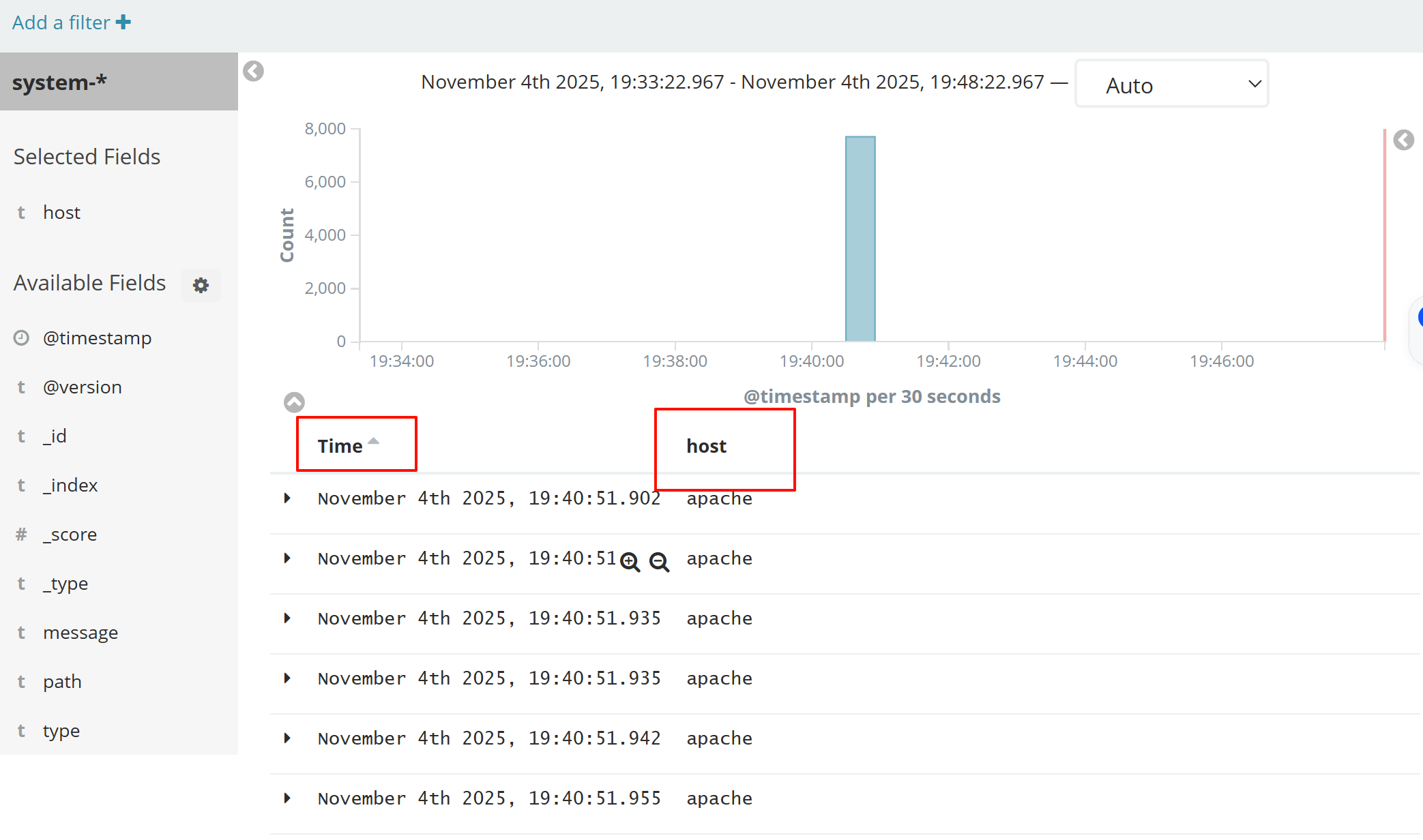
然后点最左上角的Discover按钮 会发现system-*信息
然后点下面的host旁边的add 会发现右面的图只有 Time 和host 选项了 这个比较友好
对接apache节点日志文件
对接Apache主机的Apache 日志文件(访问的、错误的)
[root@apache opt]# cd /etc/logstash/conf.d/
[root@apache conf.d]# touch apache_log.conf
[root@apache conf.d]# vi apache_log.conf
input {
file{
path => "/etc/httpd/logs/access_log"
type => "access"
start_position => "beginning"
}
file{
path => "/etc/httpd/logs/error_log"
type => "error"
start_position => "beginning"
}
}
output {
if [type] == "access" {
elasticsearch {
hosts => ["192.168.108.41:9200"]
index => "apache_access-%{+YYYY.MM.dd}"
}
}
if [type] == "error" {
elasticsearch {
hosts => ["192.168.108.41:9200"]
index => "apache_error-%{+YYYY.MM.dd}"
}
}
}
使用 Logstash 读取并执行配置文件 apache_log.conf
[root@apache conf.d]# /usr/share/logstash/bin/logstash -f apache_log.conf
#Logstash 会读取 apache_log.conf 文件中的配置
#根据配置启动对应的 input → filter → output 流程
#开始处理日志数据(比如解析 Apache 访问日志、发送到 Elasticsearch 等)
登录192.168.108.41---->node1主机
打开输入http://192.168.108.43
 打开浏览器 输入http://192.168.108.41:9100/ 查看索引信息###
打开浏览器 输入http://192.168.108.41:9100/ 查看索引信息###
能发现 apache_error-2025.11.04 apache_access-2025.11.04
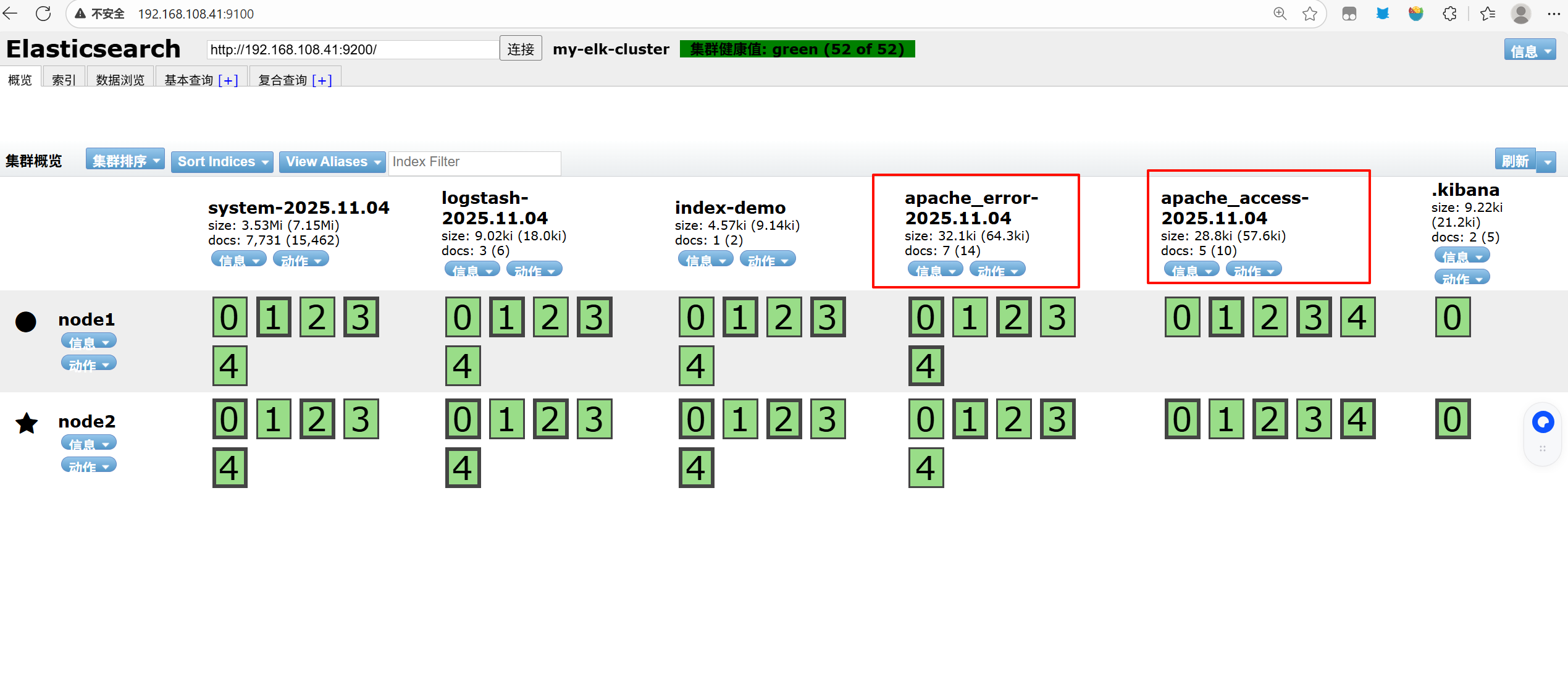
访问http://192.168.108.41:5601
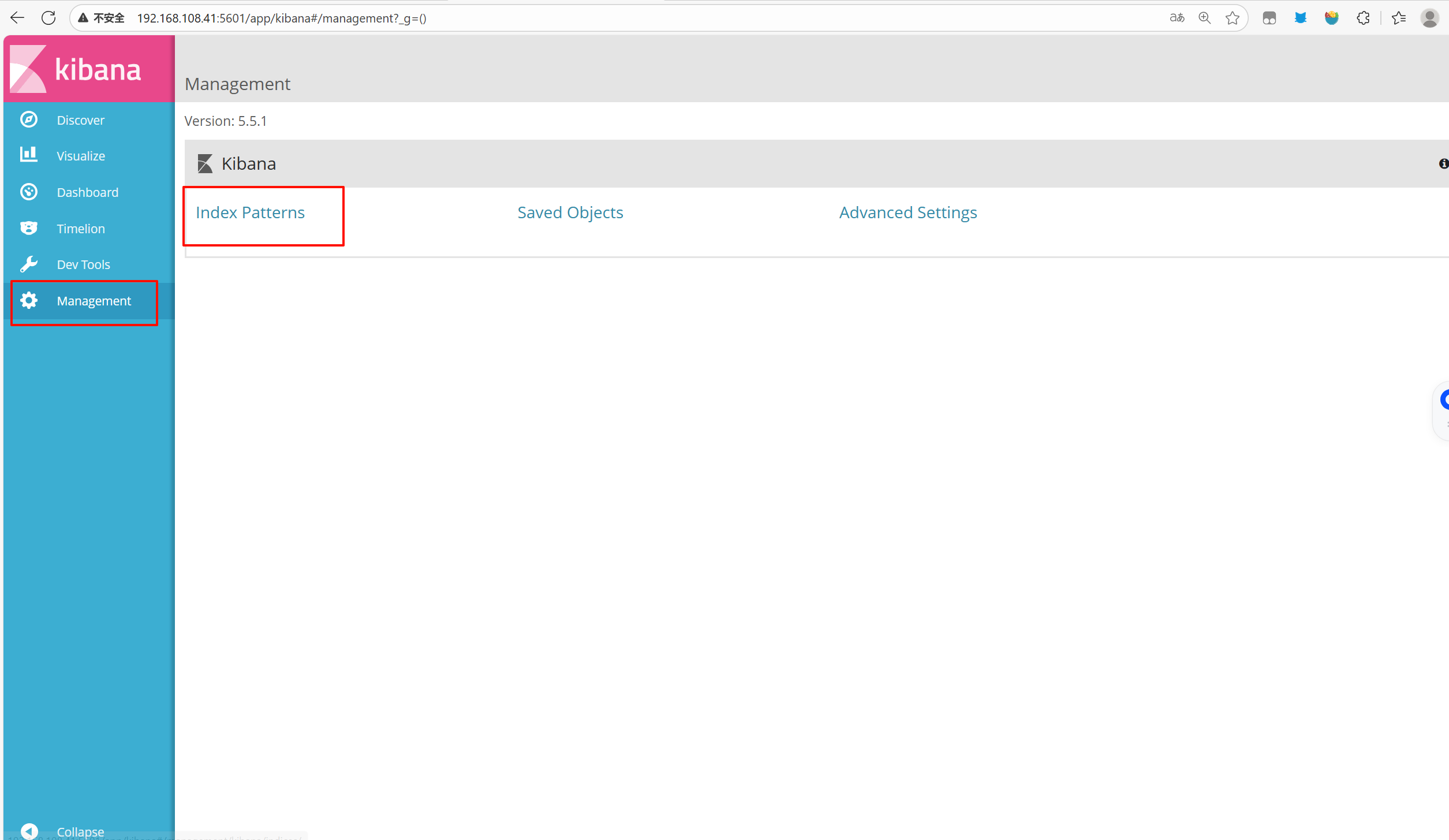
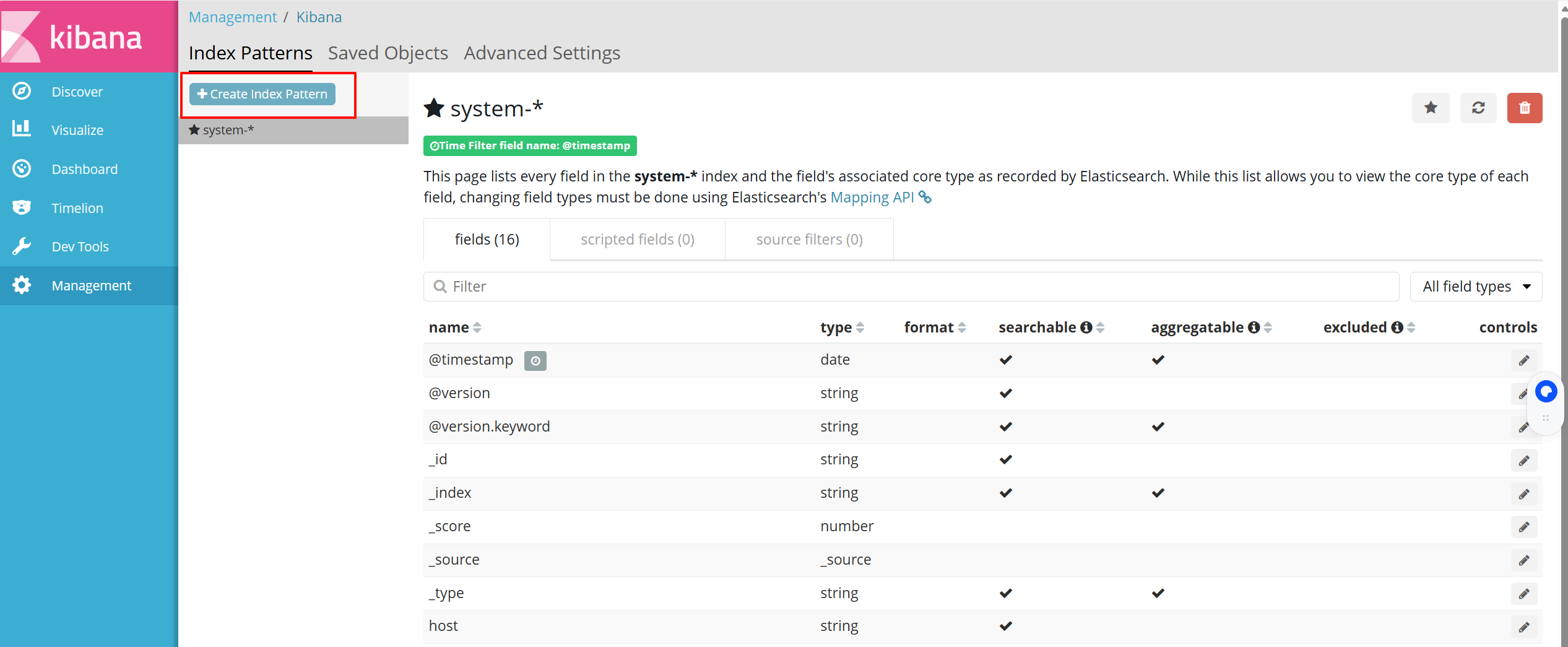
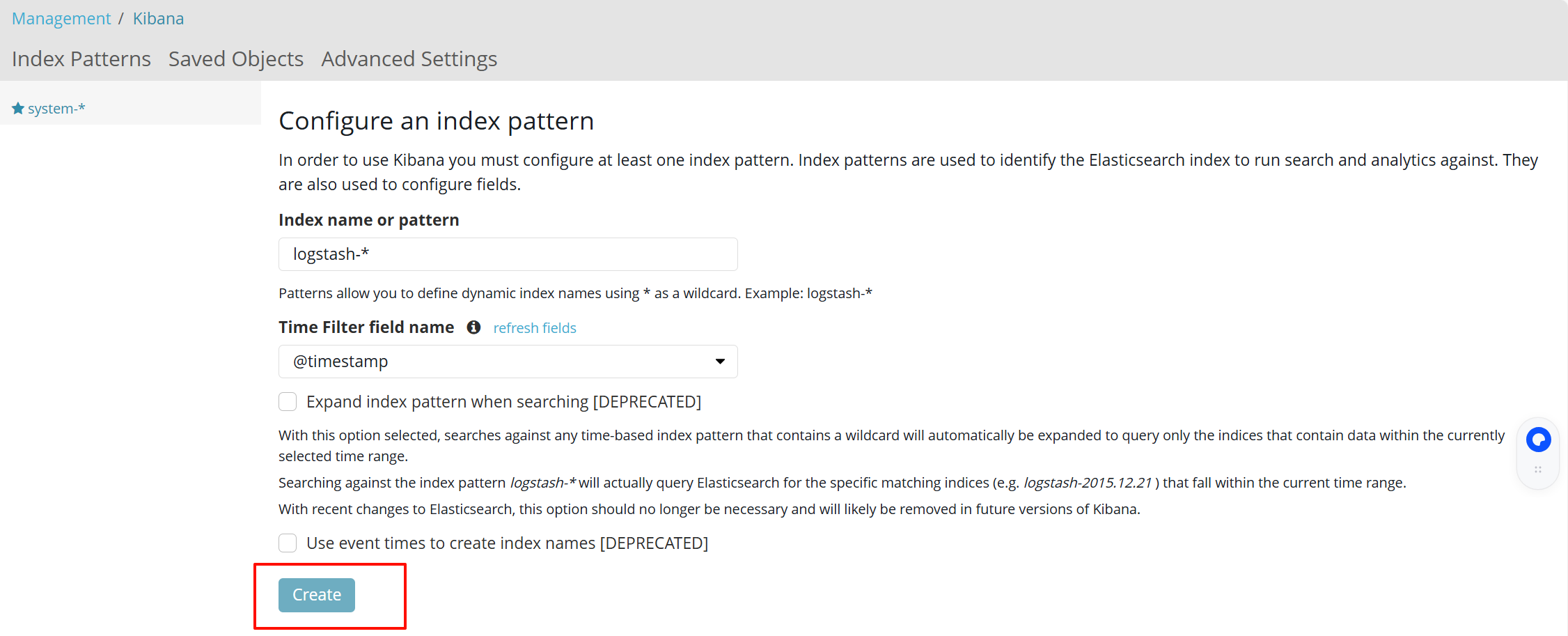
点击左下角有个management选项,点击index patterns—>create index pattern
----分别创建apache_error-* 和 apache_access-* 的索引
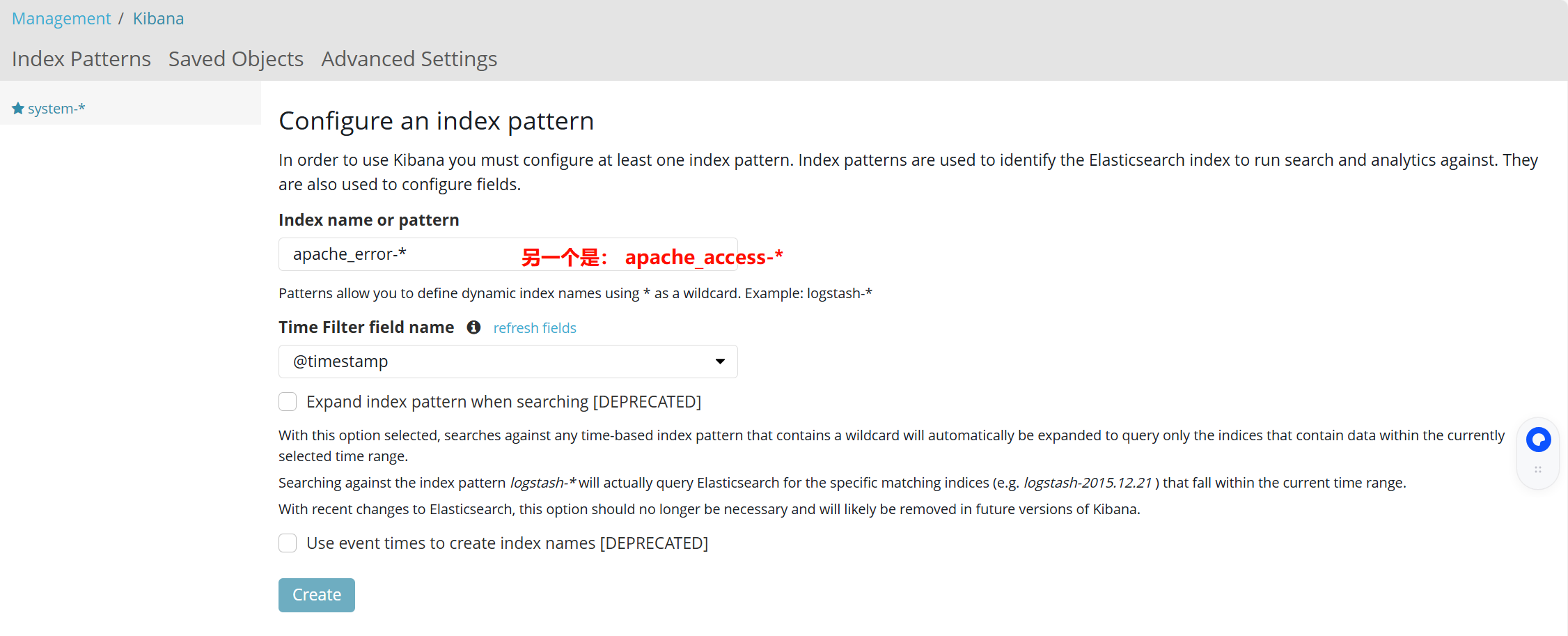
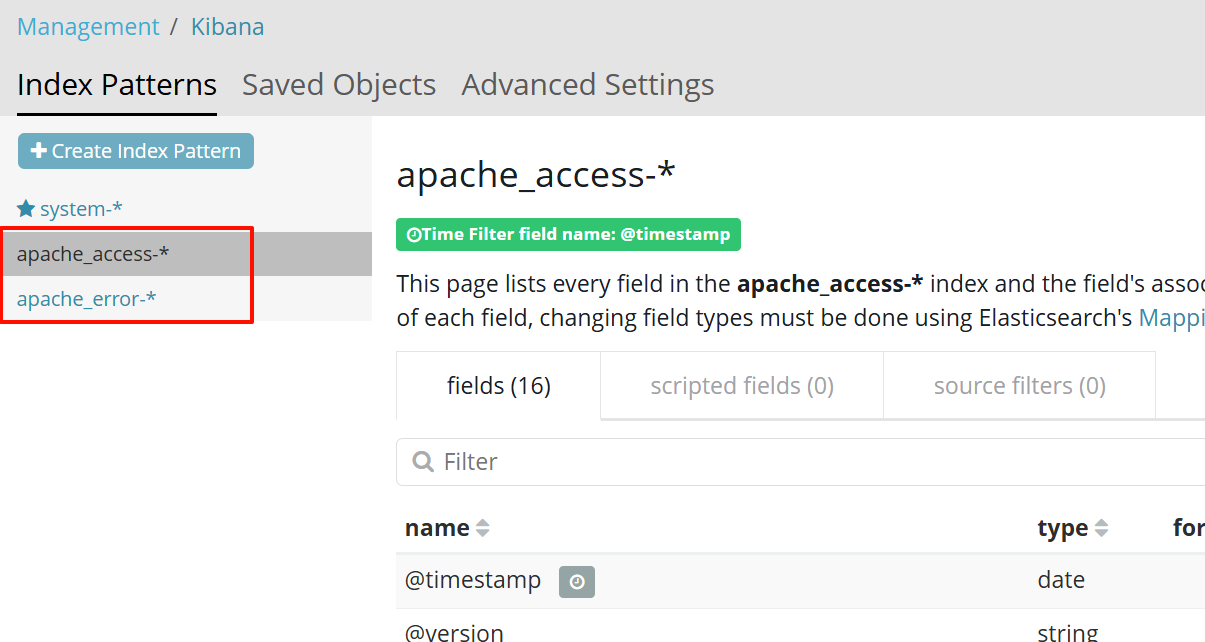
ELK 日志分析系统总结
ELK 日志分析系统(Elasticsearch+Logstash+Kibana)作为企业级日志管理的主流解决方案,通过 “采集 - 处理 - 存储 - 分析 - 可视化” 的全流程闭环设计,完美解决了传统日志管理中 “分散存储、格式杂乱、实时性差、扩展性不足、合规难满足” 的核心痛点,为企业数字化转型提供了关键的数据支撑基础设施。
从核心价值来看,ELK 架构凭借组件间的高效协同,实现了三大核心目标:一是日志集中化管理,通过 Logstash 的多源采集能力打破数据孤岛,将分散在服务器、容器、应用、设备中的日志统一汇聚;二是数据标准化处理,通过 Logstash 的过滤插件完成日志结构化转换,将非结构化文本转化为可分析的键值对数据,提升数据质量;三是高效分析与可视化,依托 Elasticsearch 的分布式存储与实时检索能力,结合 Kibana 的图形化界面,让日志数据从 “无用文本” 转化为 “决策依据”,支撑运维监控、故障排查、安全审计、业务优化等多场景需求。
各组件在架构中各司其职、缺一不可:Elasticsearch 作为 “数据仓库与检索引擎”,保障了海量日志的高效存储与毫秒级查询;Logstash 作为 “数据中枢”,承担了日志采集、清洗、转发的核心任务,是连接数据源与存储引擎的关键桥梁;Kibana 作为 “用户交互入口”,通过可视化图表与仪表盘降低了日志分析的技术门槛,让不同角色用户都能高效利用数据价值。三者的协同能力,使 ELK 具备了分布式扩展、实时响应、灵活适配、易用性强等企业级特性,可轻松应对 TB/PB 级日志规模,适配从中小微企业到大型集团的不同业务场景。
在实际应用中,ELK 系统不仅能显著提升运维效率(如故障排查时间从小时级缩短至分钟级),还能助力企业满足等保 2.0、数据安全法等合规要求,同时通过日志数据分析挖掘业务优化空间(如用户访问行为分析、应用性能瓶颈定位)。随着企业业务架构向分布式、微服务化持续演进,ELK 的扩展性与适配性使其能够随业务增长横向扩展,成为支撑企业持续稳定运行的 “数据基石”。
存储 - 分析 - 可视化” 的全流程闭环设计,完美解决了传统日志管理中 “分散存储、格式杂乱、实时性差、扩展性不足、合规难满足” 的核心痛点,为企业数字化转型提供了关键的数据支撑基础设施。
从核心价值来看,ELK 架构凭借组件间的高效协同,实现了三大核心目标:一是日志集中化管理,通过 Logstash 的多源采集能力打破数据孤岛,将分散在服务器、容器、应用、设备中的日志统一汇聚;二是数据标准化处理,通过 Logstash 的过滤插件完成日志结构化转换,将非结构化文本转化为可分析的键值对数据,提升数据质量;三是高效分析与可视化,依托 Elasticsearch 的分布式存储与实时检索能力,结合 Kibana 的图形化界面,让日志数据从 “无用文本” 转化为 “决策依据”,支撑运维监控、故障排查、安全审计、业务优化等多场景需求。
各组件在架构中各司其职、缺一不可:Elasticsearch 作为 “数据仓库与检索引擎”,保障了海量日志的高效存储与毫秒级查询;Logstash 作为 “数据中枢”,承担了日志采集、清洗、转发的核心任务,是连接数据源与存储引擎的关键桥梁;Kibana 作为 “用户交互入口”,通过可视化图表与仪表盘降低了日志分析的技术门槛,让不同角色用户都能高效利用数据价值。三者的协同能力,使 ELK 具备了分布式扩展、实时响应、灵活适配、易用性强等企业级特性,可轻松应对 TB/PB 级日志规模,适配从中小微企业到大型集团的不同业务场景。
在实际应用中,ELK 系统不仅能显著提升运维效率(如故障排查时间从小时级缩短至分钟级),还能助力企业满足等保 2.0、数据安全法等合规要求,同时通过日志数据分析挖掘业务优化空间(如用户访问行为分析、应用性能瓶颈定位)。随着企业业务架构向分布式、微服务化持续演进,ELK 的扩展性与适配性使其能够随业务增长横向扩展,成为支撑企业持续稳定运行的 “数据基石”。
综上,ELK 日志分析系统凭借成熟的技术架构、丰富的功能特性、强大的生态支持,已成为企业日志管理与数据分析的首选方案,为运维智能化、业务数字化、安全合规化提供了全方位的解决方案,是企业数字化转型过程中不可或缺的核心基础设施。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)