开源智能语音转写工具IntraScribe
简单来说,IntraScribe就像一个为你的内部网络量身打造的“专属智能速记员团队”。它在保障数据绝对安全的前提下,将录音实时变成可编辑、可总结的结构化文字,彻底改变了会议、课堂等场景下的信息记录与整理方式。如果你对具体的部署步骤、硬件配置要求或者二次开发感兴趣,我可以为你提供更详细的信息。
IntraScribe是一款完全本地化部署的智能语音转写与协作平台,专为对数据安全和隐私保护有极高要求的企业、政府、教育等机构设计。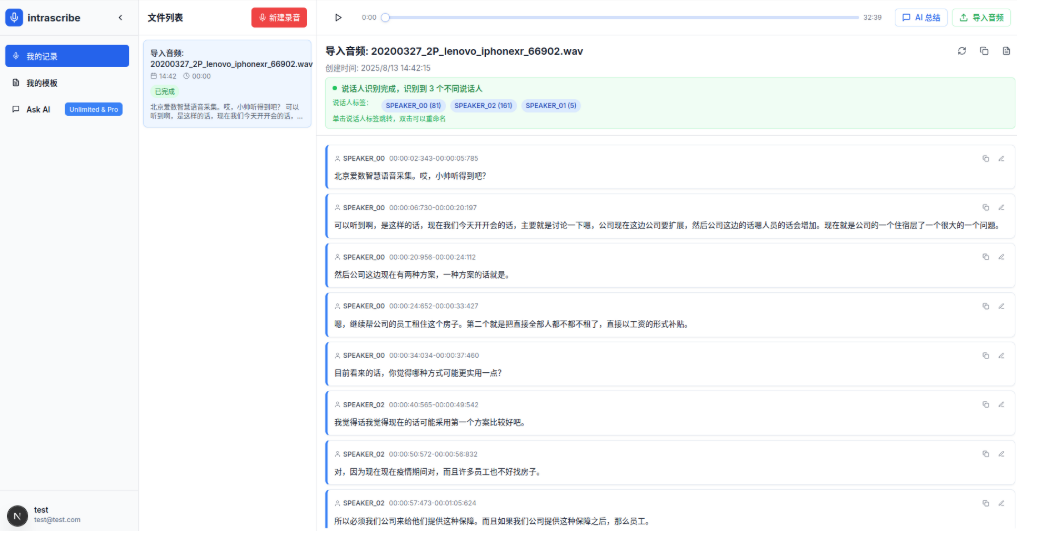
🎯 核心定位:本地优先,为安全而生
与依赖云服务的传统工具不同,IntraScribe最大的特点是**“内网优先与隐私保护”**。它可以离线或在内网环境中部署,所有音频数据和转写文本都保存在本地服务器,确保敏感信息(如企业会议、课堂内容、医疗法律对话)完全可控、不外泄,这在遵守数据保护法规时至关重要。
✨ 核心功能一览
| 功能模块 | 具体描述 | 解决的问题 |
|---|---|---|
| 实时语音转写 | 通过浏览器WebRTC技术实现“边说边出文字”,延迟通常低于500毫秒。 | 让会议或课堂的实时记录成为可能。 |
| 说话人分离 | 基于 pyannote.audio 模型,能自动区分并标记对话中不同的发言人。 |
告别“发言人A、B”,自动识别“张三、李四”。 |
| AI智能总结 | 集成LiteLLM,可根据模板一键生成结构化的会议纪要和标题。 | 将冗长录音快速提炼为待办事项和摘要,提升效率。 |
| 批量转写与编辑 | 支持会后对录音文件进行高质量批量转写,并提供友好的Web界面进行文本和发言人修正。 | 既保证最终文本质量,又方便人工校对与知识沉淀。 |
🖥️ 技术架构:如何实现本地化?
IntraScribe采用现代化的微服务架构,保证了其灵活性和可扩展性:
- 前端:使用 Next.js + React + TypeScript 构建,用户体验流畅。
- 后端:基于 Python 的 FastAPI 框架,将语音识别、说话人分离、AI总结等功能模块化。
- 核心模型:支持调用本地部署的语音识别模型(如FunASR) 和轻量化大语言模型(通过LiteLLM集成)。
- 数据管理:使用 Supabase(PostgreSQL)作为数据底座,统一管理用户认证、音频文件和实时数据同步。
🚀 适用场景
如果你所处的环境符合以下任一情况,那么IntraScribe会是一个非常合适的选择:
- 数据敏感型组织:如政府、金融、法务、医疗、研发部门,有严格的合规要求。
- 内网隔离环境:如企业内部部署的系统,无法连接外部互联网。
- 低延迟要求场景:如生产指挥、现场调度,无法忍受云服务1-2秒的网络延迟。
- 教育与学术机构:用于课堂录制、研讨会,便于后续复习与知识管理。
📦 如何获取与部署?
IntraScribe是一个开源项目(采用MIT许可证),你可以自由地在本地服务器上部署它。其部署主要分为以下几步:
- 准备环境:确保服务器已安装 Node.js、Python、FFmpeg 等基础依赖。
- 启动数据库:使用 Supabase CLI 在本地启动并初始化数据库。
- 配置与启动:分别启动后端服务(通常是FastAPI应用)和前端Web应用。
- 访问使用:在浏览器中访问前端地址(如
http://localhost:3000),注册账号后即可开始使用。
请注意:首次运行时,系统可能需要从网络下载语音模型,但后续所有流程都可以在无网络环境下运行。
如果你需要一个现成的、开箱即用的云端录音转文字手机App,那么 App Store 上的 iTranscribeAI 可能更合适,但它无法满足内网部署的需求。而“Interscriber”是另一个由瑞士团队开发的转录项目,虽然功能类似,但它是一个不同的独立产品,请注意区分。
💎 总结
简单来说,IntraScribe就像一个为你的内部网络量身打造的“专属智能速记员团队”。它在保障数据绝对安全的前提下,将录音实时变成可编辑、可总结的结构化文字,彻底改变了会议、课堂等场景下的信息记录与整理方式。
如果你对具体的部署步骤、硬件配置要求或者二次开发感兴趣,我可以为你提供更详细的信息。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)