NeurIPS 2025 高分论文!快手可灵团队提出OmniSync:通用唇形同步的终极解法?
如果没有这种采样策略,生成的人脸通常与原始图像存在明显的错位,包括明显的面部错位问题。在扩散的早期阶段,强引导有助于建立正确的唇形,而在后期阶段,过度的引导可能会破坏精细的纹理细节。通过在每个阶段提供合适的训练信号,即使没有完美配对的数据,也能实现稳定的学习,从而使模型能够在保持身份一致性的同时,有效地泛化到各种不同的真实场景。与其他 SOTA 方法相比之下,OmniSync 能够始终保持人物特征
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
2025 年的视频生产方式彻底变了,唇形同步(lip-sync,Lip Synchronization)已从“视频后期小技术”转变成 → “ AIGC 视频生成的地基技术”。
-
视频创作从“人拍”转向“ AI 生成”,口型逼真度成为决定真实感的核心瓶颈
-
多语言内容爆炸式增长,跨语种唇形同步成为刚需
-
AI 主播、AI 数字人全面上岗:Lip Sync = 职业素质


虽然 AI 视频生成技术取得新突破,生成的视频越来越逼真,但当前“嘴巴”仍然容易穿帮。嘴巴不跟音频走、牙齿和舌头消失、嘴周边模糊、甚至嘴巴像贴图一样左右漂移……这些问题,成为 AI 视频生产流程里最扎眼的瑕疵。
一句话总结:高精度唇形同步成为 2025 年 AI 视频生成的一块“硬骨头”。
现有唇形同步技术为何仍然不够?
-
依赖脸部区域 masks → 容易漏形、穿帮、边缘不自然
-
靠参考帧 → 姿态变化就翻车
-
长时长推理 → 身份漂移
-
遇到动漫/非人类角色 → 大面积失效
那么 2025 年有没有好用的唇形同步技术推荐?答案是:有的。
本文将介绍 NeurIPS 2025 顶会上的 OmniSync:一个真正意义上的“通用唇形同步框架”,这个工作让整个AI视频生成领域“眼前一亮”,也成功获评为 Spotlight(焦点论文)。

单位:快手可灵团队, 中国人民大学, 清华大学
论文链接:
https://arxiv.org/abs/2505.21448
主页链接:
https://ziqiaopeng.github.io/OmniSync/
基准测试链接:
https://huggingface.co/datasets/ZiqiaoPeng/AIGC_LipSync_Benchmark
一、OmniSync 到底解决了什么问题?
现有方法的关键痛点:
(1)Mask-based Inpainting:嘴周边边界模糊、漏形、风格不一致
(2)Pose & Identity Drift:头动大一点就“假”
(3)Weak Audio Conditioning:音频信号弱 → 模型容易被视觉信息“压制”
OmniSync 是一个几乎“通吃所有视频类型”的通用唇形同步框架:
-
不用 Mask
-
不用参考帧
-
无限时长推理
-
能处理真人、卡通、AI 生成视频、甚至非人类角色
-
关键指标全面实现 SOTA 性能
二、OmniSync 核心技术解析
OmniSync:一个通用唇形同步框架,包含三个关键组件:
1)Mask-Free(无需掩码)的训练范式,消除了对参考帧和显式掩码的依赖;
2)基于流匹配的渐进式噪声初始化策略,有效稳定早期去噪过程,并缓解姿态不一致和身份漂移;
3)动态时空无分类器引导(DS-CFG),可对音频 influence 进行精细控制,解决音频驱动生成中的弱信号问题。
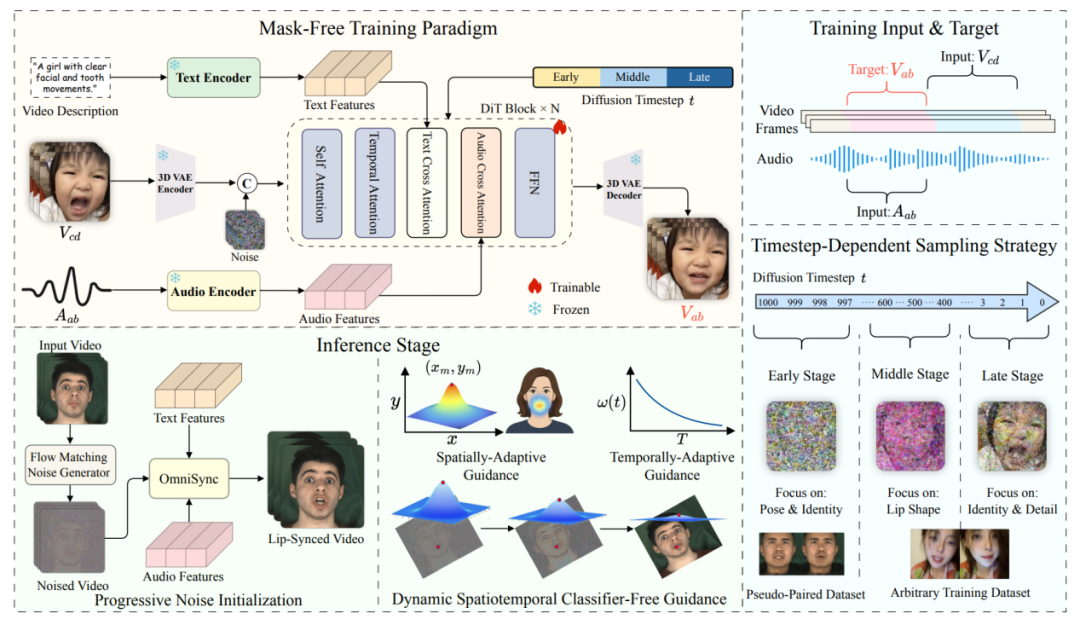
图. OmniSync 框架
2.1 Mask-Free 训练范式
可灵团队利用扩散模型的渐进式去噪(progressive denoising)特性,引入了一种新的训练策略:根据扩散时间步(diffusion timesteps)动态调整数据采样方式。这样即使没有完美配对的样本,也能实现稳定的学习。
目标:通过迭代去噪来学习条件生成过程映射 (Vcd, Aab) → Vab,其中 V 代表视频帧,A 代表音频。
采用流匹配(Flow Matching)作为训练目标。给定一个输入视频片段 Vcd(帧 c 到 d )和一个目标音频片段 Aab(帧 a 到 b ),该模型通过扩散过程生成相应的视频片段 Vab:
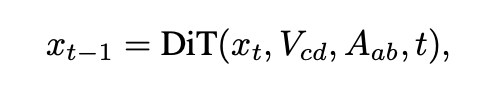
用于训练的 CFM 损失函数定义如下:
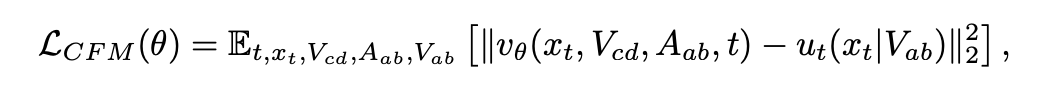
核心:Timestep-Dependent 采样策略
本文方法的关键在于认识到扩散过程可以分解为不同的阶段,每个阶段都有不同的学习需求。具体来说,早期阶段侧重于生成基本的面部结构,包括姿态和身份信息;中期阶段主要生成由音频驱动的唇部运动;而后期阶段则进一步完善身份细节和纹理。为了充分利用这种自然演进过程,该方法针对不同的阶段使用了不同的数据集。
对于负责生成整体面部结构的早期时间步(大约 t ≈ T),采用来自受控实验室环境的伪配对数据。这些样本保持几乎相同的姿态信息,仅在唇部运动上存在差异,从而为结构特征提供稳定的学习信号,并确保输入和输出之间的姿态对齐。
在中期和后期时间步,过渡到更多样化的数据,从任意视频中采样。在中期时间步,模型学习根据音频输入生成唇形;而在后期时间步(大约 t ≈ 0),模型则专注于完善身份细节并确保纹理一致性。这种与时间步相关的训练策略可以形式化为:
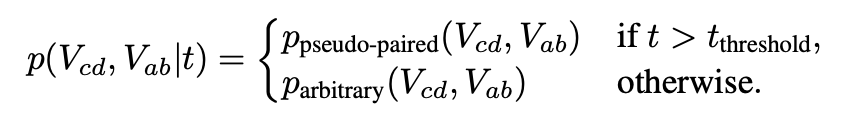
条件生成过程可以用数学公式表示为:
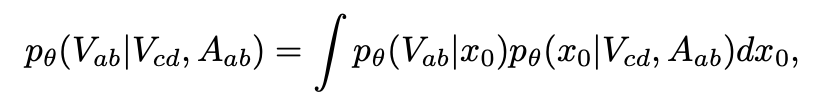
这种渐进式训练方法与扩散模型的自然学习进程高度契合。通过在每个阶段提供合适的训练信号,即使没有完美配对的数据,也能实现稳定的学习,从而使模型能够在保持身份一致性的同时,有效地泛化到各种不同的真实场景。
2.2 Progressive Noise Initialization
可灵团队提出了一种基于流匹配(Flow-Matching)的渐进式噪声初始化策略,该策略改进了传统的扩散过程。
核心:流匹配噪声初始化。从具有可控噪声水平的原始视频帧进行初始化,这模拟了扩散轨迹中的一个中间状态,对应于归一化参数 τ。初始化过程通过将这种可控噪声添加到原始视频帧中来实现:
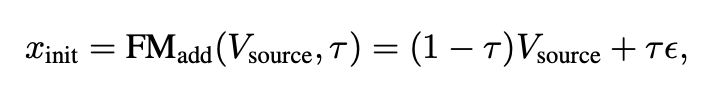
这种初始化策略具有两个显著优势。首先,它绕过了扩散的早期阶段(从 T 到 tstart ),而该阶段会形成面部的整体结构。这确保了头部姿态和整体结构直接从源帧继承。其次,它仅对剩余的 tstart 到 0 步进行去噪,从而降低了计算需求。
完整的渐进式去噪过程可以表示为:
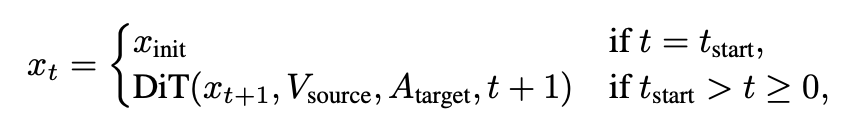
这种方法有效地创建了一个两阶段过程:(1)使用受流匹配启发的噪声添加方法进行初始化,使系统达到与时间步 tstart 等效的状态;(2)从 tstart 到 0 进行引导式去噪,重点是根据目标音频修改嘴部区域,同时保留源帧的整体面部结构、身份特征和头部姿态。通过跳过基本结构形成的早期噪声阶段,这样既保持了空间一致性,又为精确修改嘴巴区域提供了足够的灵活性。
图. 渐进式噪声初始化策略
2.3 DS-CFG(Dynamic Spatiotemporal Classifier-Free Guidance)
可灵团队提出了动态时空无分类器引导(DS-CFG)方法,这是一种能够对生成过程进行精细控制的新方法,涵盖空间和时序两个维度。该方法针对帧的不同区域和扩散过程的不同阶段应用不同的引导强度,从而在唇部同步精度和整体视觉质量之间实现最佳平衡。
核心:空间自适应引导。空间自适应的关键在于,音频信息主要影响嘴部区域,而其他面部区域则应基本保持不变。该方法通过高斯加权空间引导矩阵来实现这一点,该矩阵将引导强度集中在与语音相关的区域周围:
这种空间自适应确保音频条件能够强烈影响嘴唇及其周围区域,同时将对其他面部特征的影响降至最低。
核心:时序自适应引导。可灵团队观察到:音频条件在扩散过程的不同阶段发挥着不同的作用。在扩散的早期阶段,强引导有助于建立正确的唇形,而在后期阶段,过度的引导可能会破坏精细的纹理细节。为了解决这个问题,可灵团队采用了一种随时序递减的引导策略:
这种时序适应性确保在形成粗略结构的早期和中期扩散阶段提供强有力的引导,并在精细细节和纹理细化的后期阶段逐渐降低其影响。
核心:统一动态时空Classifier-Free Guidance(DS-CFG)。结合空间和时序自适应,DS-CFG 方法对标准 CFG 公式进行了修改:
通过 DS-CFG ,实现了对生成过程的精确控制,有效解决了音频驱动生成中音频信号弱的问题。
图. DS-CFG
三、AIGC-LipSync Benchmark:行业首个 AI 视频唇形同步评测集
为了全面评估当前人工智能生成内容(AIGC)环境下唇形同步方法的性能,快手可灵团队精心构建了 AIGC-LipSync 基准测试,这是首个针对各种人工智能生成视频的唇形同步评估套件。
AIGC-LipSync 基准测试包含 615 个视频片段,这些视频由最先进的文本转视频模型(例如 Kling、Dreamina、Wan 和 Hunyuan 生成。所有原始视频素材均下载自Civitai 等公开社区,确保了数据集的多样性和代表性,能够更严格地测试模型的泛化能力和鲁棒性。
该基准测试专门捕捉了具有挑战性的视觉场景,例如大幅度的面部运动、侧面视角、多变的光照、遮挡和风格化的角色——这些都是传统基准测试无法处理的。在所有数据中,约有 450 个视频包含逼真的人类角色,约 125 个视频包含具有独特艺术风格的风格化角色,以及约 40 个视频包含更具挑战性、非典型的类人角色。这些视频片段的平均时长约为 6 秒,平均分辨率为 976x1409 像素,平均帧速率保持在 30.00 FPS,为详细的同步分析提供了充足的数据。
如下图所示,AIGC-LipSync 基准测试中的代表性示例展示了其内容的多样性及其固有的挑战。
图. AIGC-LipSync 基准测试样本
四、OmniSync 性能评估
快手可灵团队使用一套全面的指标,将 OmniSync 与包括 Wav2Lip、VideoReTalking、TalkLip、MuseTalk 和 LatentSync 等在内的最先进方法进行对比评估。
在视觉质量评估方面,采用 FID(Fréchet Inception Distance)来衡量帧级保真度,采用 FVD(Fréchet Video Distance)来衡量时序一致性,并采用 CSIM(Cosine Similarity)来量化身份保持度。感知质量的评估则使用 no-reference 指标,包括 NIQE(自然图像质量评估器)、BRISQUE(盲/无参考图像空间质量评估器)和 HyperIQA。对于视听同步,通过测量预测的和真实面部特征点在嘴部区域之间的 LMD(Landmark Distance),以及 LSE-C(唇形同步误差 - 置信度)来评估唇形同步质量。
4.1 定量评估
-
在 HDTF 数据集上的表现
重点:FID、FVD、CSIM、NIQE、BRISQUE、HyperIQA 和 LMD 指标全部 SOTA!

在 HDTF 数据集上,OmniSync 与 LatentSync 相比,其将 FID 降低了 7.8%,FVD 降低了 8.0%,并且在 BRISQUE 指标上比 Diff2Lip 显著提升了 23.2%。在唇形同步方面,OmniSync 实现了最低的 LMD 值,比 IP-LAP 低 7.8%。具体实验数据详见下表:
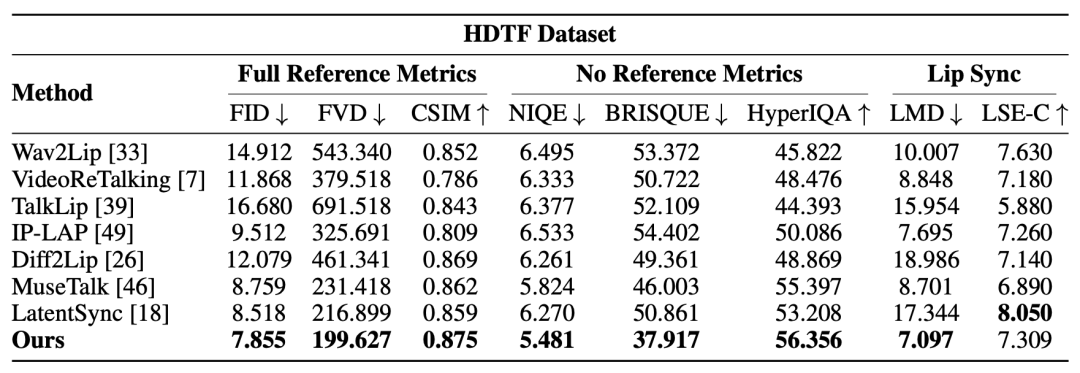
表. 在 HDTF 数据集上的定量比较
-
在 AIGC-LipSync 基准上的表现
在极具挑战性的 AIGC-LipSync 基准测试中,OmniSync 展现了卓越的性能,与 LatentSync 相比,FID 降低了 30.5%,FVD 降低了 19.7%,同时身份保留效果也得到了提升。更重要的是,OmniSync 在所有视频中实现了 97.40% 的成功率,远高于 MuseTalk (92.20%) 和其他方法(低于 75%)。对于风格化角色,OmniSync 成功率达到了 87.78%,优于 MuseTalk (67.78%),这充分证明了 OmniSync 能够处理包括风格化角色在内的各种视觉表现形式。
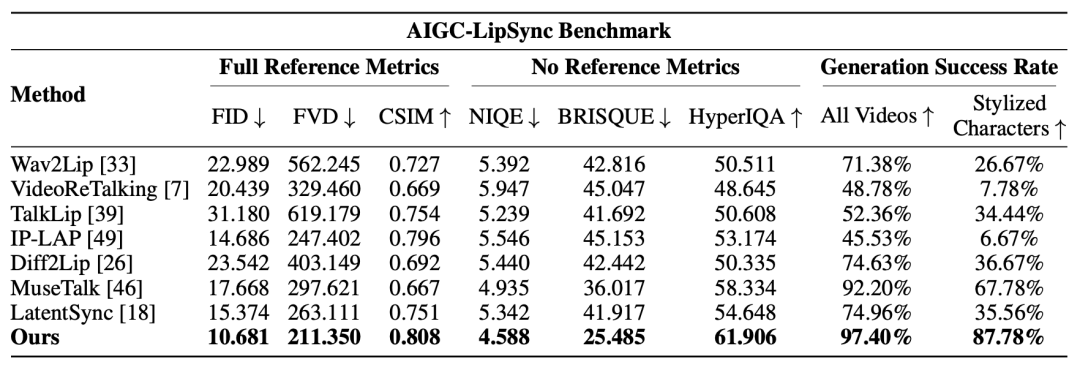
表. 在 AIGC-LipSync 数据集上的定量比较
4.2 定性评估
下图展示了 OmniSync 与现有方法的定性比较。OmniSync 能够生成更自然的面部表情和更出色的唇形同步效果。与其他 SOTA 方法相比之下,OmniSync 能够始终保持人物特征,并生成逼真、富有表现力的唇部动作,展现出稳健的性能,有效地平衡了音频和视觉线索,解决了音频条件较弱的问题。

图. 与以往方法在不同主题和音素上的定性比较。OmniSync 能够实现更准确的唇形同步和更好的身份识别保留
重点:OmniSync 在五项主观指标全部第一!
为了评估感知质量,可灵团队开展了一项用户研究,共有 39 名参与者,他们评估了由 OmniSync 和七种竞争方法生成的 32 组视频。参与者使用 5 分制李克特量表,根据五个标准对每个视频进行评分:唇形同步准确性、角色身份保持、时间稳定性、图像质量和视频真实感。如下表所示,OmniSync 在所有指标上均优于所有竞争方法,均取得了更高的分数。
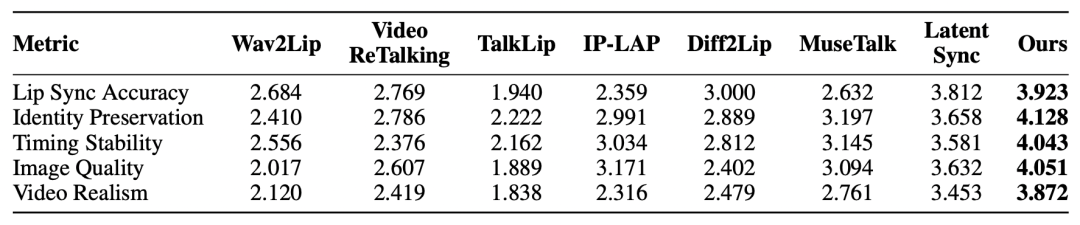
表. 用户研究结果比较了各种音频驱动的唇形同步方法
由上可知,OmniSync 整体的性能跟其他 SOTA 方法相比,属于是降维打击级表现。

4.3 消融实验
OmniSync 的三大组件是一个高度协同的系统。为了阐明每个核心组件的贡献,可灵团队针对三个关键模块开展了消融实验(Ablation Study):Timestep-Dependent 采样策略、渐进式噪声初始化以及动态时空无分类器引导(DS-CFG)机制。
消融实验的定量结果数据如下图所示:
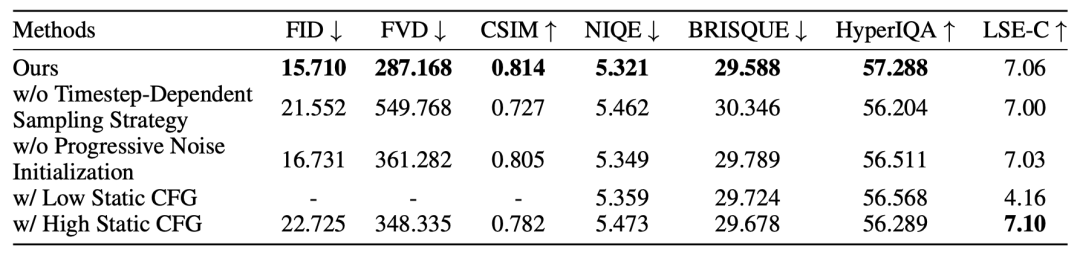
图. Ablation Study
消融实验结果分析:
-
移除【Timestep-Dependent 采样策略】会导致身份保持和姿态一致性显著下降,CSIM 值降低 10.7%,FID 和 FVD 值大幅增加。如果没有这种采样策略,生成的人脸通常与原始图像存在明显的错位,包括明显的面部错位问题。这验证了采用早期扩散步骤对齐伪配对数据的设计选择,这对于生成结构稳定的输出至关重要。
-
移除【渐进噪声初始化】会导致明显的时序不一致性和 FVD 值增加,这证实了流匹配初始化在保持空间锚定和运动一致性方面的重要性。
-
DS-CFG 通过在早期扩散阶段施加强烈的局部引导,并在后续步骤中逐渐减弱引导强度,实现了最佳平衡。低 CFG 提供的音频处理不足,导致唇部动作不够清晰,而高 CFG 虽然改善了同步性,但会在面部细节中引入明显的伪影和失真。
这些结果证实,在生成式视频内容中,跨时间和空间维度的动态控制对于产生富有表现力且视觉上连贯的唇形同步至关重要。
五、效果展示
看完下面 OmniSync 的视频效果,绝对会让你眼前一亮。
六、总结:OmniSync 的行业意义
从“可用”到“通用”的跨越!OmniSync 是第一个真正能适配 AI 视频生态的唇形同步技术,引入三项关键创新技术,实现了跨越多种视觉表征的精确唇部运动,还建立了 AIGC-LipSync 基准测试——首个用于评估各种 AIGC 环境下唇形同步的综合评测集。
OmniSync 在各种挑战性场景下均表现出卓越的性能,为将唇形同步集成到更广泛的 AI 视频生成生态系统中奠定了坚实的基础,将成为未来 AI 视频生产流水线中不可缺少的关键组件。
整理不易,请点赞和在看![]()

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献105条内容
已为社区贡献105条内容

所有评论(0)