TuGraph平台知识图谱及问答系统
本文以disease3.csv为数据集,搭建基于TuGraph数据库的医疗知识图谱问答系统,实现用户输入问题系统自动查询并返回答案的功能。数据集disease3.csv包含了28条记录,15个属性。
本文以disease3.csv为数据集,搭建基于TuGraph数据库的医疗知识图谱问答系统,实现用户输入问题系统自动查询并返回答案的功能。
数据集disease3.csv包含了28条记录,15个属性。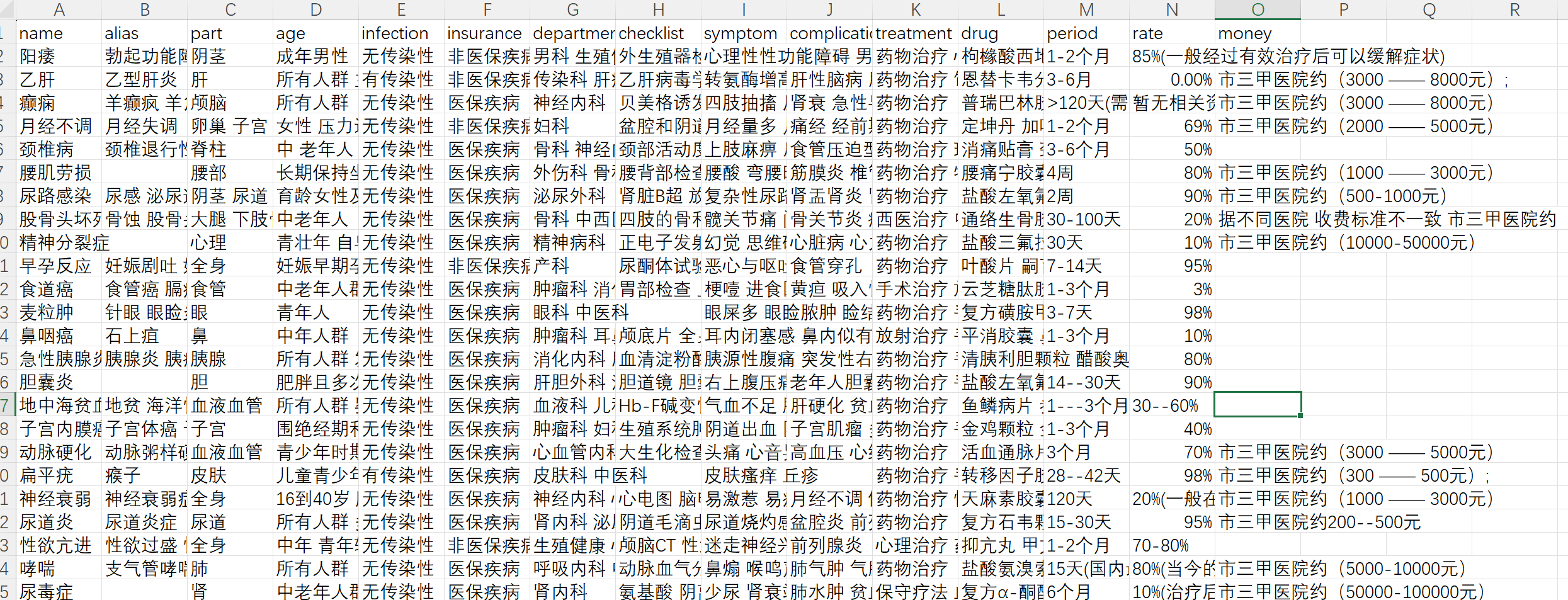
一、TuGraph启动
TuGraph的启动方式与new4j类似,步骤如下:
1.启动docker
2.在powershell中输入命令
docker run -d -v D:\tugraph_test:/mnt -p 7070:7070 -p 7687:7687 docker.1ms.run/tugraph/tugraph-runtime-ubuntu18.04 lgraph_server3.打开浏览器,在地址栏输入localhost:7070,进入TuGraph平台登录界面
4.登录,默认账号admin,密码73@TuGraph,需要修改密码(这里无法跳过)
进入后TuGraph初始界面如下:
二、TuGraph数据导入
Tugraph数据导入需要先写schema(建模),再导入数据。
写schema有三种方法:
1.localhost:7070可视化界面
2.lgraph_import
3.py接口
本文使用localhost:7070可视化界面进行schema的编写,步骤如图所示:
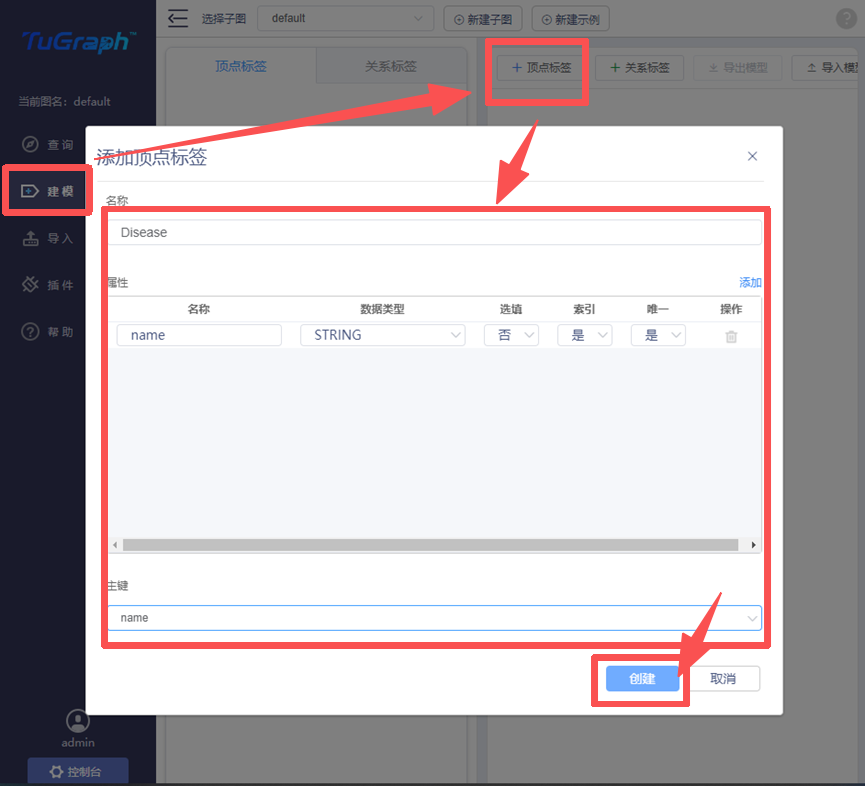
同时,localhost:7070可视化界面也提供了批量导入schema的方法,但需要提前编写好json文件。
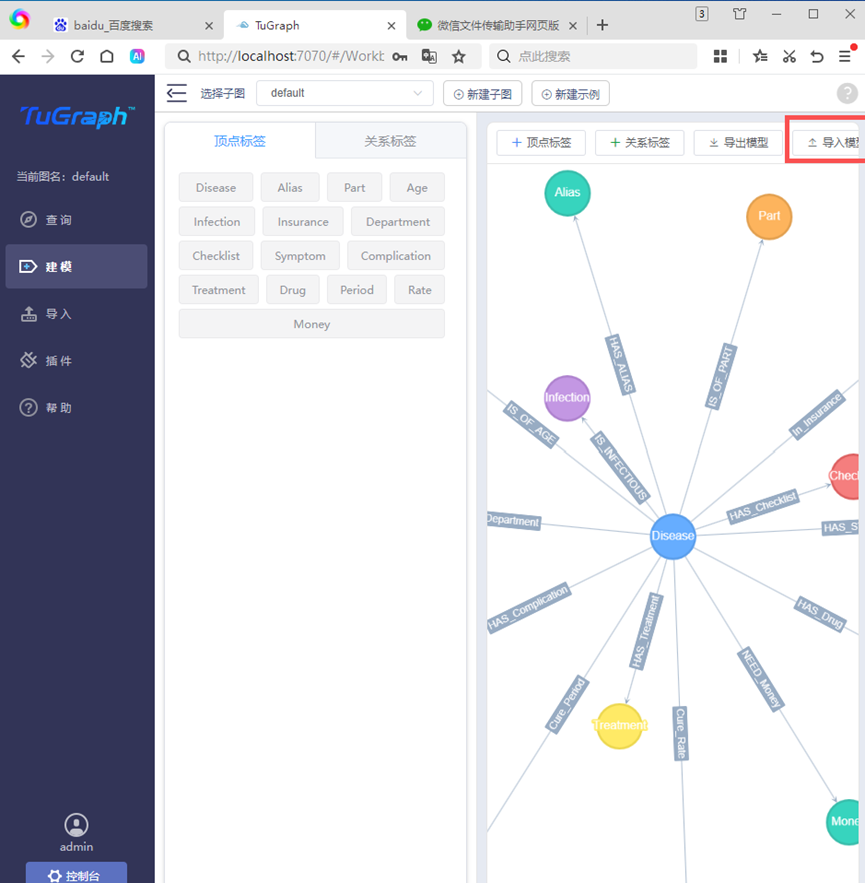
可以使用Python编写json文件,如图所示。
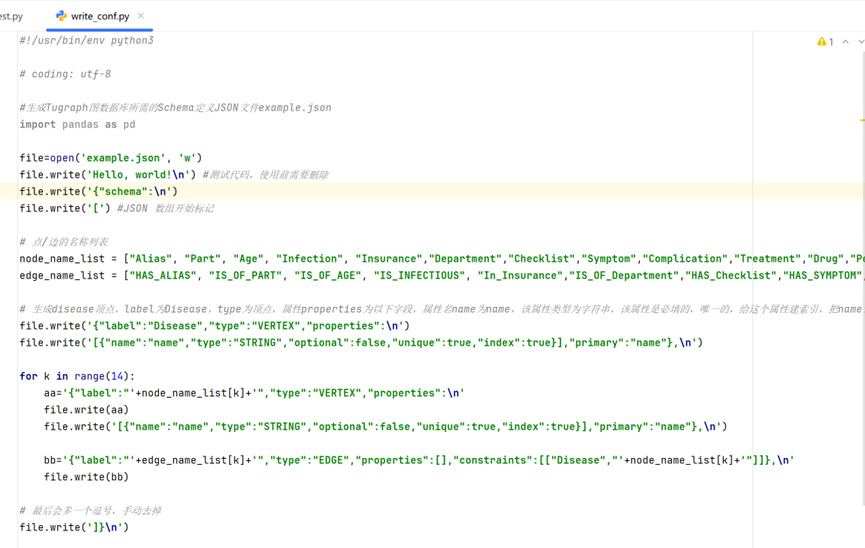
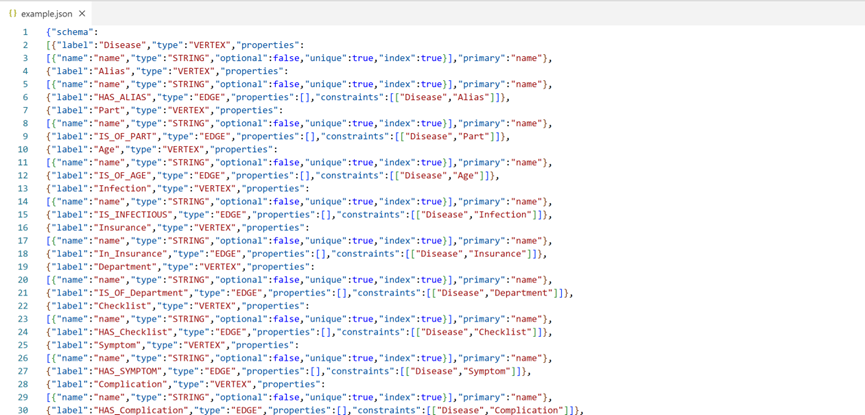
运行write_conf.py得到example.json,将其导入TuGraph。
而后导入数据,导入数据也有以上三种方法,同样本文使用的是可视化界面导入数据的方法,操作步骤如图所示。
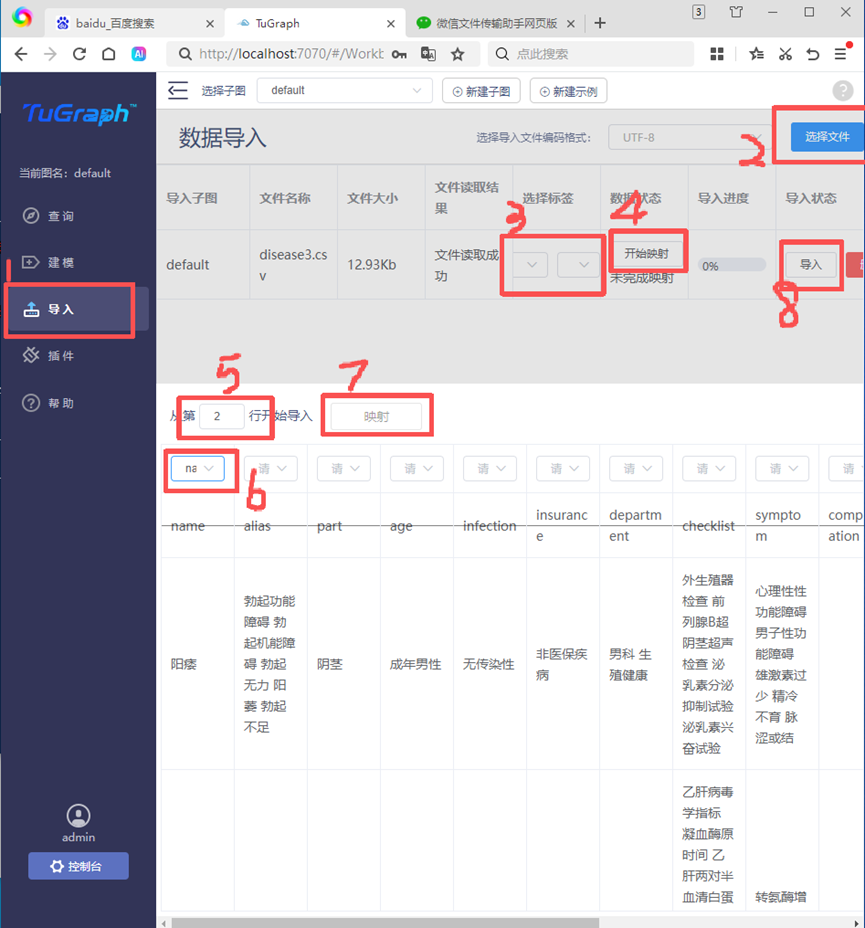
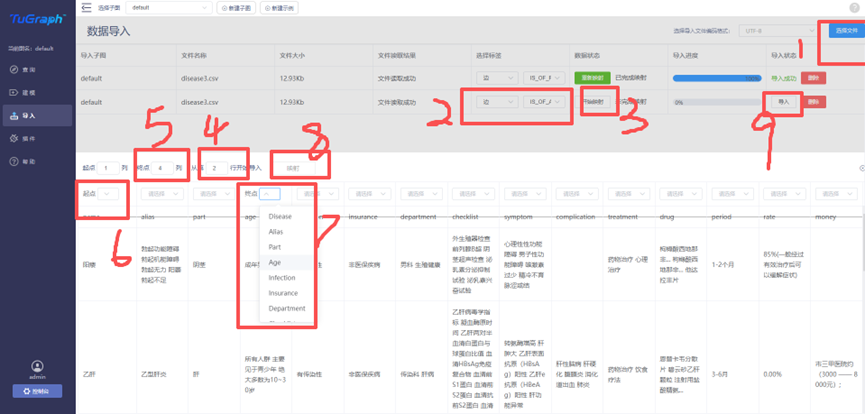
这样导入数据有个问题,就是一些字段连在一起,比如说别名“勃起功能障碍 勃起机能障碍 勃起无力 阳萎 勃起不足”是连在一起作为一个节点的,而我们希望是分开作为多个节点。所以运行write_V_E_files.py,将disease3.csv转成多个csv文件,再导入。
write_V_E_files.py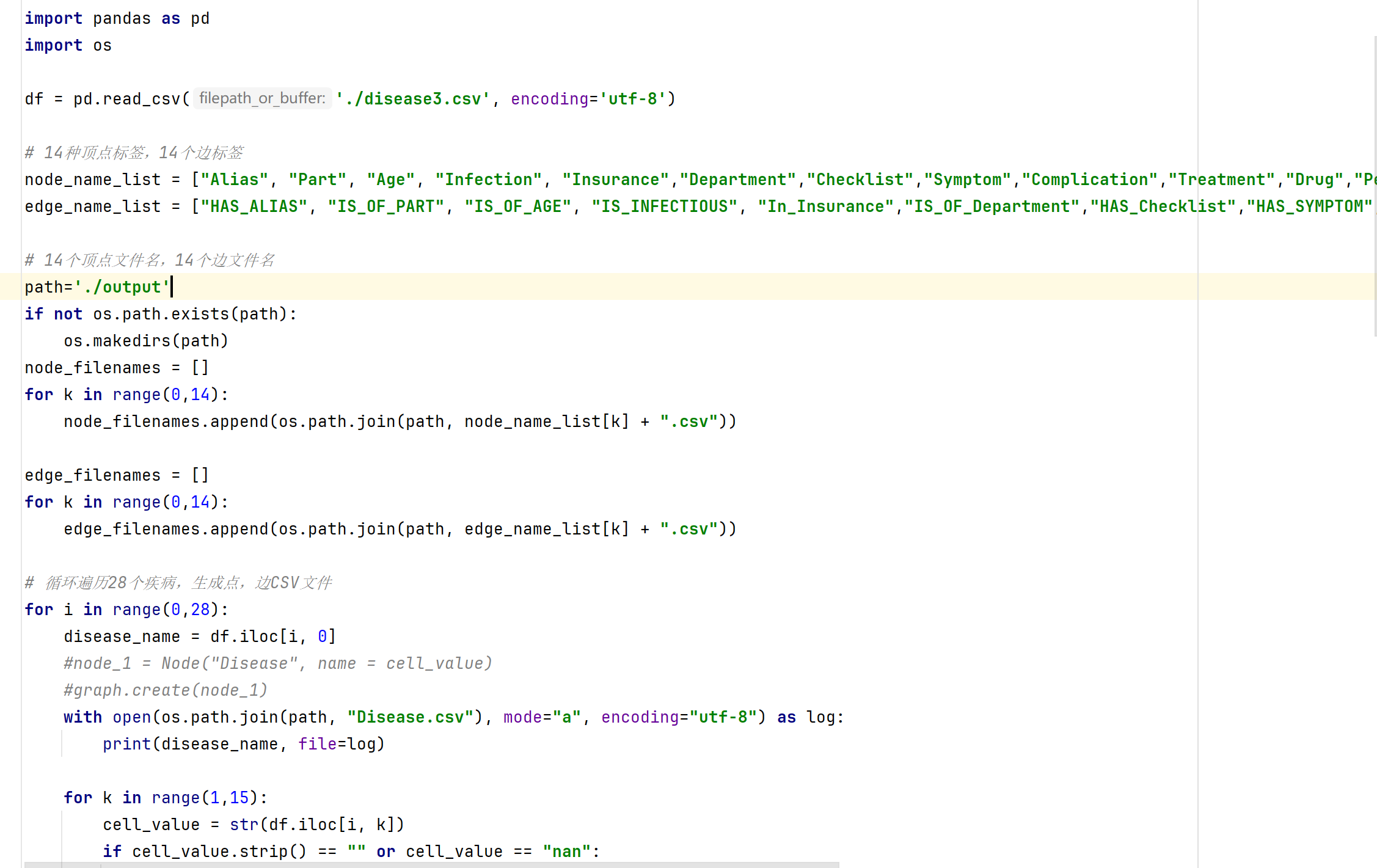
得到15个点文件,14个边文件。点文件只有一列,代表点的名称,边文件有两列,代表起点到终点的映射。
最终导入数据。
三、TuGraph中使用cypher语句、Python交互
通过neo4j包中的GraphDatabase包,实现Python对TuGraph的连接。
# pip install neo4j
from neo4j import GraphDatabase
class MedicalChatbot:
def __init__(self):
# 连接到 TuGraph
self.driver = GraphDatabase.driver(
"bolt://localhost:7687",
auth=("admin", "123456") # 按你的密码修改
)可以在Python中使用Cypher语句进行查询。
with self.driver.session(database="default") as session: # 按你的子图修改
# 查询数据库中所有疾病名称
result = session.run("MATCH (d:Disease) RETURN d.name AS disease_name")
self.disease_list = [record["disease_name"] for record in result if record["disease_name"]]四、对话系统搭建及测试
在Python中通过读取用户输入,提取疾病名称,提取所问关键词,匹配对应的Cypher语句,连接TuGraph获得查询结果,格式化输出实现对话系统。
def query_knowledge_graph(self, text, disease_name):
# 查询知识图谱
with self.driver.session(database="default") as session:
# ------------------ 查询别名 ------------------
if any(k in text for k in ["别名", "别称", "又名"]):
cypher = """
MATCH (d:Disease {name: $name})-[:HAS_ALIAS]->(a)
RETURN a.name AS alias
"""
data = session.run(cypher, name=disease_name)
results = [r["alias"] for r in data]
return self.format_response(results, "alias") def format_response(self, results, query_type):
# 格式化输出
if query_type == "symptom":
return f"可能出现的症状包括:{'、'.join(results)}"通过输入输出测试对话系统。



未来改进之处:
1.本实验仅使用28条数据的数据集,可以使用更完整的数据集提高查询广度。
2.数据导入方法使用的是手动导入,可以使用lgraph_import会py接口方法提高数据导入效率。
3.对话系统仅能识别当前问题中的关键词,在上下文理解、关键词以外的自然语言表达识别中存在缺陷,可以引入大模型极高对话系统智能程度。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)