收藏必备!2025年RAG不落后:父子文档索引解决检索与理解的“不可能三角“
文章介绍父子文档索引(Parent-Child Indexing)这一高阶RAG技术,用于解决传统RAG中的"上下文碎片化"问题。该技术将检索粒度与理解粒度解耦:使用小粒度子文档进行精确检索,通过ID映射召回包含完整上下文的大粒度父文档供LLM生成回答。这种策略既保证了检索的精确性,又确保了生成时拥有完整的上下文,特别适用于法律文档、技术手册等逻辑严密的信息场景,实现了"既见树木,又见森林"的数据
前言
2025 年,仍然存在很多关于“RAG是否过时”的讨论。随着支持超长上下文模型的发展,似乎把整本书丢给 AI 就能解决所有问题。
但现实的工程实践告诉我们:成本、延迟和精度的“不可能三角”依然存在,这就是为什么高阶RAG技术在今天仍然被广泛使用。
但在构建企业级知识库时,我们经常遇到一种“为了检索而牺牲理解”的现象:为了让检索更精准,我们往往倾向于将文档切分得很细(比如 200 字一段)。结果是,AI 成功检索到了包含关键词的那一段话,却丢失了这段话紧密依赖的前置条件或核心结论。
这就是“上下文碎片化”。
今天,我们不谈具体的代码实现细节,而是从数据策略的角度,深入探讨一种能够兼顾“检索精度”与“上下文完整性”的高阶策略——父子文档索引(Parent-Child Indexing)。
01 检索粒度 vs 理解粒度
在传统的 RAG 流程中,我们面临一个两难的选择:
-
切分粒度过大(例如 1000 token/块):
-
优势:上下文完整,AI 读到了前因后果,回答质量高。
-
劣势:检索精度下降。一段 1000 token 的文本中,可能只有一句是用户需要的。大量的无关信息稀释了向量的特征,导致检索不到。
-
切分粒度过小(例如 200 token/块):
-
例子:用户问“合同违约怎么赔偿?”
-
小块检索:找到了“赔偿金额为合同总额的 30%”。
-
丢失的上下文:这一条款的前置条件是“在不可抗力之外的情况”。因为切分太细,这个前置条件在上一段,没被一起检索出来。
-
结果:AI 给出了错误的、绝对化的回答。
-
优势:检索非常敏锐,能精准定位到具体的细节。
-
劣势:语义断裂。
结论:检索需要“显微镜”(小粒度),但生成需要“广角镜”(大粒度)。 传统的单一分块策略无法同时满足这两个需求。
02 父子文档索引
父子文档索引的核心逻辑非常简单且有力:将“检索单元”和“生成单元”解耦。
我们不再直接索引那个用来给 LLM 阅读的“大文档”,而是:
-
存储父文档(Parent Chunk):保持较大的粒度(甚至全文),包含完整的逻辑和上下文。
-
生成子文档(Child Chunk):将父文档进一步切分为多个细小的片段。
-
建立映射:子文档只负责被检索,一旦命中,系统不返回子文档本身,而是通过 ID 索引,召回其所属的父文档。
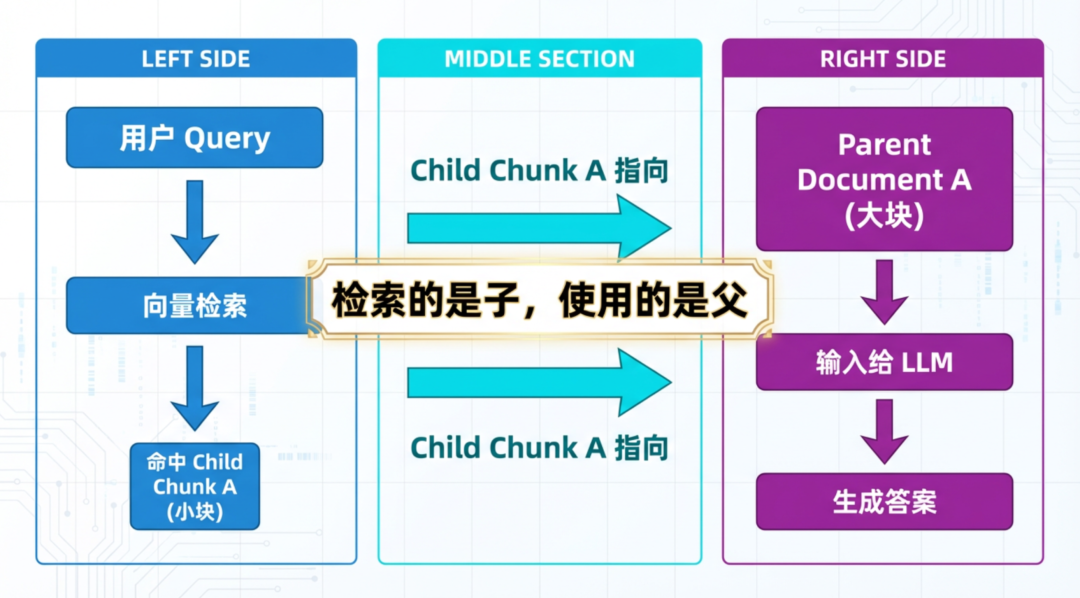
这种策略达成了一个完美的效果:用最敏锐的触角去探测信息,用最完整的全貌去回答问题。
03 Dify 中的架构实现
一些低代码开发平台如dify就内置了这种模式。我们可以通过分析它的实现逻辑,来理解这套机制在工程上是如何落地的。
根据 Dify 的技术架构,数据模型被设计为两层:
- DocumentSegment (父段落):
- 这是较大的文本块,或者是整个文档。
- 它存储了实际的内容,是最终提供给 LLM 的上下文来源。
- ChildChunk (子段落):
- 这是从父段落中进一步切分出来的。
- 关键点:它不仅存储了切分后的文本,还存储了
index_node_id(索引节点 ID)。 - 在向量数据库中,实际进行向量化(Embedding)和存储的,主要是这些 ChildChunk。
Dify 的处理流程:
- 入库时:系统先将文档切分为父段落(如按段落切分),然后对每个父段落进行二次切分(如按句子切分),生成子段落并建立索引。
- 检索时:用户的提问与 ChildChunk 进行相似度匹配。
- 召回时:一旦某个 ChildChunk 被命中,系统会自动通过关联键,找到它对应的 DocumentSegment。
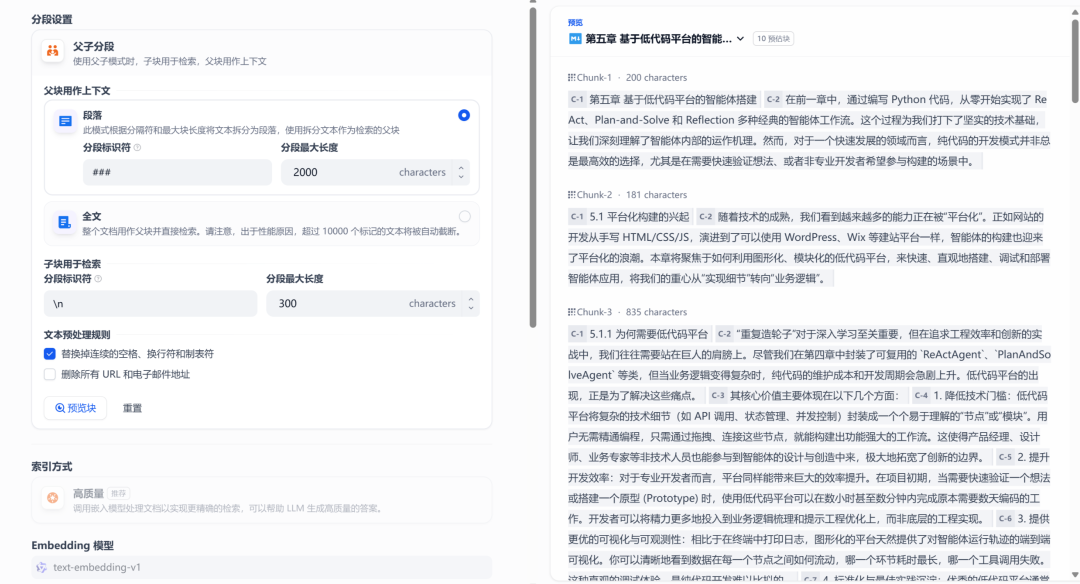
这是在Dify中基于知识库的配置界面,可以根据自己的文档具体特征进行调参与召回测试:
04 通用代码实现逻辑(python 伪代码)
如果你不使用 Dify,而是想在自己的项目中(基于 LangChain 或原生 python)复现这个逻辑,核心在于ID 映射的管理。
以下是一个通用的实现思路,适用于任何向量数据库(Milvus, FAISS, Chroma):`import uuid
class ParentChildIndexer:def __init__(self):
self.doc_store = {} # 存储父文档 (Key: Parent_ID, Value: Content)
self.vector_store = [] # 存储子文档向量 (实际应用中应为向量数据库)def add_document(self, full_text):# 1. 切分父文档 (大块)
parent_chunks = split_text(full_text, chunk_size=1000)
for parent in parent_chunks:
# 生成父文档 ID
parent_id = str(uuid.uuid4())
# 存储父文档内容 (用于生成)
self.doc_store[parent_id] = parent.page_content
# 2. 切分子文档 (小块)
child_chunks = split_text(parent.page_content, chunk_size=200)
for child in child_chunks:
# 3. 关键步骤:在子文档元数据中记录父文档 ID
child_metadata = {
"parent_id": parent_id,
"content": child.page_content
}
# 将子文档向量化并存入向量库
self.vector_store.add(child.page_content, metadata=child_metadata)
def retrieve(self, query):# 1. 检索子文档
matched_child = self.vector_store.search(query, top_k=1)
# 2. 获取父文档 ID
parent_id = matched_child.metadata["parent_id"]
# 3. 召回完整的父文档内容return self.doc_store.get(parent_id)`
这段代码展示了最纯粹的逻辑:存储分离,ID 关联。
05 适用场景与业务价值
这项技术并非在所有场景下都是必须的。它主要解决的是“逻辑严密、信息分散”的场景痛点。
1.法律与合同审查
- 痛点:条款之间存在复杂的引用关系。
- 价值:通过子块精准定位到“违约责任”这一条款,然后召回包含该条款所在的整个章节(父文档),确保 AI 看到该条款适用的前提条件。
2.技术文档与故障排查
- 痛点:报错代码通常很短,但解决方案很长。
- 价值:用户搜索报错代码(子块),系统召回包含该报错代码的完整解决方案步骤(父文档),而不是只返回报错代码那一行。
3. 研报与长文分析
- 痛点:关键数据点(如“净利润增长 20%”)散落在长文中。
- 价值:通过数据点(子块)定位到该数据所在的段落或章节(父文档),让 AI 能够分析数据背后的原因描述。
还有很多场景,这里就不一一列举了,大家可以自行探索。
06 结语
回到文章开头提到的那个“不可能三角”。在 2025 年,我们依然坚持使用 RAG,本质上是因为我们不仅追求 AI 回答的广度(能读多少书),更追求它回答的精度(读懂了哪一页)。
父子文档索引(Parent-Child Indexing) 的技术价值,可以用一句话总结:它实现了“检索单元”与“生成单元”的工程解耦。
- 对“子文档”做减法:让向量检索只需专注于最细微的语义匹配,像探针一样敏锐,不再被长文中的噪音干扰。
- 对“父文档”做加法:让 LLM 接收到的上下文始终是逻辑完整的篇章,像阅读理解一样,不再被断章取义的碎片误导。
这种策略的意义,远不止于企业文档。
想象一下,如果你是一位正在写论文的研究者,你不需要 AI 仅仅把几篇文献里含有“神经网络”的孤立句子丢给你,你需要的是它通过一个概念,帮你把那篇论文的核心论证段落完整提取出来;
如果你是一位维护复杂系统的工程师,你不需要 AI 只展示报错的那一行代码,你需要的是它通过报错信息,自动定位并展示出包含该错误的完整函数模块。
这才是 RAG 进化的正确方向: 从单纯的“关键词搬运工”,进化为具备上下文感知能力的“逻辑分析师”。
掌握了父子索引策略,你就掌握了“既见树木,又见森林”的数据治理能力。无论模型如何迭代,这种对数据结构的深刻理解,永远是你构建高质量 AI 应用的核心壁垒。
普通人如何抓住AI大模型的风口?
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
AI大模型开发工程师对AI大模型需要了解到什么程度呢?我们先看一下招聘需求:

知道人家要什么能力,一切就好办了!我整理了AI大模型开发工程师需要掌握的知识如下:
大模型基础知识
你得知道市面上的大模型产品生态和产品线;还要了解Llama、Qwen等开源大模型与OpenAI等闭源模型的能力差异;以及了解开源模型的二次开发优势,以及闭源模型的商业化限制,等等。

了解这些技术的目的在于建立与算法工程师的共通语言,确保能够沟通项目需求,同时具备管理AI项目进展、合理分配项目资源、把握和控制项目成本的能力。
产品经理还需要有业务sense,这其实就又回到了产品人的看家本领上。我们知道先阶段AI的局限性还非常大,模型生成的内容不理想甚至错误的情况屡见不鲜。因此AI产品经理看技术,更多的是从技术边界、成本等角度出发,选择合适的技术方案来实现需求,甚至用业务来补足技术的短板。
AI Agent
现阶段,AI Agent的发展可谓是百花齐放,甚至有人说,Agent就是未来应用该有的样子,所以这个LLM的重要分支,必须要掌握。
Agent,中文名为“智能体”,由控制端(Brain)、感知端(Perception)和行动端(Action)组成,是一种能够在特定环境中自主行动、感知环境、做出决策并与其他Agent或人类进行交互的计算机程序或实体。简单来说就是给大模型这个大脑装上“记忆”、装上“手”和“脚”,让它自动完成工作。
Agent的核心特性
自主性: 能够独立做出决策,不依赖人类的直接控制。
适应性: 能够根据环境的变化调整其行为。
交互性: 能够与人类或其他系统进行有效沟通和交互。

对于大模型开发工程师来说,学习Agent更多的是理解它的设计理念和工作方式。零代码的大模型应用开发平台也有很多,比如dify、coze,拿来做一个小项目,你就会发现,其实并不难。
AI 应用项目开发流程
如果产品形态和开发模式都和过去不一样了,那还画啥原型?怎么排项目周期?这将深刻影响产品经理这个岗位本身的价值构成,所以每个AI产品经理都必须要了解它。

看着都是新词,其实接触起来,也不难。
从0到1的大模型系统学习籽料
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师(吴文俊奖得主)
给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。
- 基础篇,包括了大模型的基本情况,核心原理,带你认识了解大模型提示词,Transformer架构,预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门AI大模型
- 进阶篇,你将掌握RAG,Langchain、Agent的核心原理和应用,学习如何微调大模型,让大模型更适合自己的行业需求,私有化部署大模型,让自己的数据更加安全
- 项目实战篇,会手把手一步步带着大家练习企业级落地项目,比如电商行业的智能客服、智能销售项目,教育行业的智慧校园、智能辅导项目等等

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

AI时代,企业最需要的是既懂技术、又有实战经验的复合型人才,**当前人工智能岗位需求多,薪资高,前景好。**在职场里,选对赛道就能赢在起跑线。抓住AI这个风口,相信下一个人生赢家就是你!机会,永远留给有准备的人。
如何获取?
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献378条内容
已为社区贡献378条内容

所有评论(0)