【小白必看】解锁 Transformer 核心!一文吃透自注意力机制原理与实践
【小白必看】解锁 Transformer 核心!一文吃透自注意力机制原理与实践
在深度学习的技术浪潮中,Transformer架构堪称“革命性突破”——从NLP领域的GPT、BERT,到计算机视觉领域的ViT(视觉Transformer),再到多模态任务的CLIP,其身影无处不在。而支撑Transformer强大能力的“核心引擎”,正是自注意力机制。它彻底改变了序列数据的建模方式,今天我们就从“需求起源-核心优势-计算链路-实践价值”四个维度,全方位拆解这一关键技术。
一、为什么自注意力是序列建模的“破局者”?——直面传统模型的痛点
在自注意力出现前,序列数据(如文本、语音、视频帧)的建模主要依赖循环神经网络(RNN) 和卷积神经网络(CNN) ,但两者都存在难以回避的局限:
-
RNN的“顺序枷锁”:RNN需按时间步依次处理序列(比如先算“我”,再算“喜欢”,最后算“苹果”),无法并行计算,训练效率极低;更关键的是,处理长序列(如1000字以上的文章)时,梯度会随时间步衰减或激增(梯度消失/爆炸),导致无法捕捉“开头”与“结尾”的长距离依赖(比如翻译“小明昨天买的书,今天他送给了小红”时,RNN可能忘记“他”指代“小明”)。
-
CNN的“局部局限”:CNN通过卷积核提取局部特征(比如3×3卷积核只能覆盖文本中3个连续的词),若要捕捉全局关系,需堆叠多层卷积,不仅增加计算量,还会导致“远距离信息传递损耗”——比如文本中“地球”和“月球”相隔10个词,CNN很难直接建立两者的“卫星绕行星”关联。
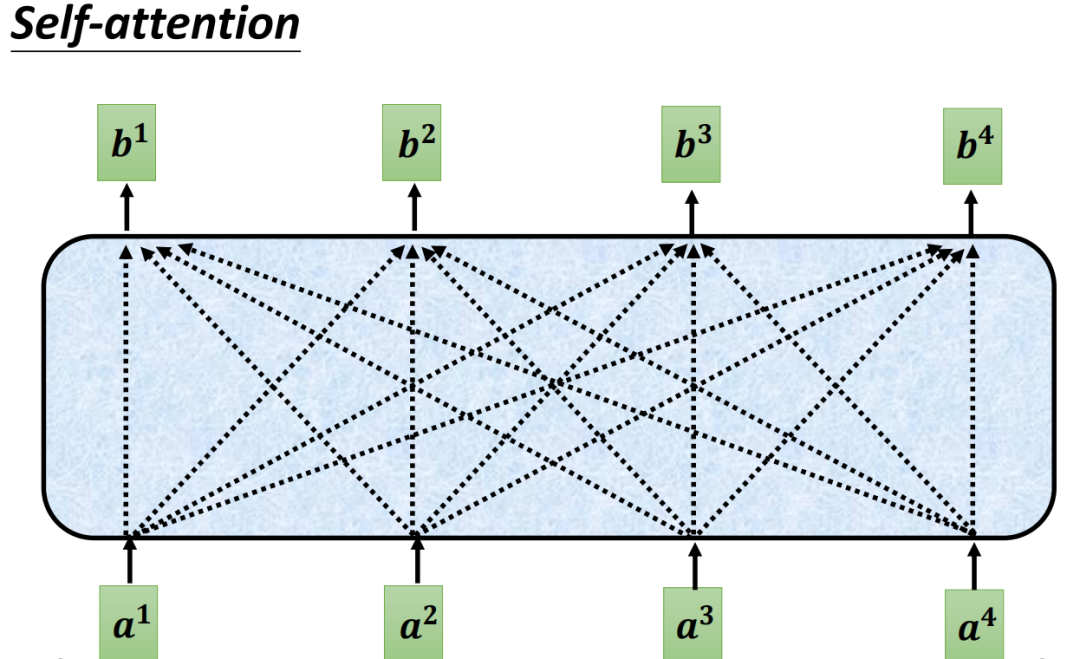
自注意力机制的出现,恰好打破了这两大局限:它能并行处理序列中所有位置,同时直接计算任意两个位置的关联度,让每个输出都能“看见”整个序列的全局信息。如下图所示,每个输出向量b₁、b₂、b₃,都会综合考虑所有输入向量a₁、a₂、a₃的信息,实现“全局视野”。
二、自注意力机制的5大核心优势:不止“全局”与“并行”
自注意力的价值远不止“解决RNN和CNN的问题”,其设计本身还带来了多重优势,这也是Transformer在各类任务中表现出色的关键:
1. 极致的并行计算能力
自注意力无需像RNN那样“等待前一个时间步计算完成”,也无需像CNN那样“滑动卷积核逐步扫序列”——它能一次性计算所有位置的注意力关联,在GPU等并行算力支持下,训练效率可提升数倍。例如处理1024个token的文本,RNN需1024步串行计算,而自注意力仅需1步即可完成全局关联计算,这让百万级token的长文本任务(如书籍摘要)成为可能。
2. 无距离限制的长序列处理
无论两个元素在序列中相隔多远(比如第1个词和第1000个词),自注意力都能直接计算它们的关联度,无需通过多层传递。例如在法律文档分析中,自注意力能轻松关联“合同开头的甲方名称”与“结尾的责任条款”,而RNN往往会因距离过远丢失这种关键依赖。
3. 动态自适应的注意力分配
自注意力会根据输入内容“动态调整关注重点”:面对不同序列,它能自动给“相关度高的信息”分配高权重,给“无关信息”分配低权重。比如处理两个含“苹果”的句子——“苹果发布新款手机”和“我爱吃苹果”时,自注意力会分别将“苹果”的注意力集中在“发布”“手机”和“吃”上,精准捕捉不同语境下的语义差异。
4. 全局语义的完整捕捉
与CNN的“局部优先”不同,自注意力在计算每个位置的输出时,会强制关联整个序列的所有信息。例如在文本生成任务中,当生成“小明每天早上都要喝”的下一个词时,自注意力会同时参考“小明”(主体)、“早上”(时间)、“喝”(动作)的全局信息,最终生成“牛奶”而非“电脑”,避免局部视角导致的语义偏差。
5. 可解释性的“可视化窗口”
相比于深度学习中常见的“黑盒模型”,自注意力的注意力权重可直接可视化,让我们能“看见”模型的决策逻辑。例如在机器翻译任务中,将“猫追老鼠”翻译成英文“Cat chases mouse”时,通过可视化注意力权重,能清晰看到“Cat”的注意力集中在“chases”和“mouse”上,“mouse”的注意力集中在“chases”上——直观体现了“主语-谓语-宾语”的语义关联,为模型调优和错误分析提供了明确依据。
三、自注意力机制的完整计算链路(附实例拆解)
为了让大家彻底理解自注意力的“工作流程”,我们以中文句子“我喜欢苹果”为例(3个词,每个词用3维向量表示),一步步拆解计算过程。
1. 第一步:词嵌入(Embedding)——把文字变成“数字语言”
自注意力无法直接处理文字,需先将每个词转换为固定维度的向量(即词嵌入),让模型能通过向量运算捕捉语义。
- 常见的词嵌入方法包括:one-hot编码(简单但维度爆炸)、Word2Vec(通过上下文训练语义向量)、GloVe(基于全局词频优化),以及当前主流的预训练词嵌入(如BERT的词嵌入)。
- 实例:假设“我”的向量为[0.1, 0.2, 0.3],“喜欢”为[0.4, 0.5, 0.6],“苹果”为[0.7, 0.8, 0.9],则输入序列构成3×3的矩阵X(行数=词数,列数=向量维度)。
2. 第二步:位置编码(Positional Encoding)——给序列“加序号”
自注意力本身是“无顺序的”——它会平等对待“我喜欢苹果”和“苹果喜欢我”,但序列顺序对语义至关重要(前者是正常表达,后者语义混乱)。因此,必须通过位置编码给每个词注入“位置信息”。
常见的位置编码方式有两种:
-
绝对位置编码:给每个位置分配一个固定向量,最常用的是“正弦余弦编码”。对于第pos个位置、第i维的编码值,计算公式为:
当i为偶数时:PE(pos,i)=sin(pos100002i/dmodel)PE(pos, i) = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right)PE(pos,i)=sin(100002i/dmodelpos)
当i为奇数时:PE(pos,i)=cos(pos100002i/dmodel)PE(pos, i) = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right)PE(pos,i)=cos(100002i/dmodelpos)
其中dmodeld_{model}dmodel是词嵌入的维度(如3维)。这种编码的优势是无额外参数,且能灵活扩展到训练时未见过的更长序列(比如训练时处理512个词,推理时处理1024个词仍有效)。 -
相对位置编码:不关注“绝对位置”,而是关注“两个词的相对距离”。例如在句子“小明昨天去公园,他今天在家”中,“他”与“小明”的相对距离是4,相对位置编码会让“他”的注意力优先关联“小明”,帮助模型解决指代消解问题。
3. 第三步:生成Query、Key、Value——构建“查询-匹配-取值”体系
自注意力的核心逻辑是“通过查询(Query)匹配关键信息(Key),再提取对应内容(Value)”,这需要通过三个可学习的矩阵WQW_QWQ、WKW_KWK、WVW_VWV实现:
-
三个矩阵均为随机初始化,后续通过反向传播(梯度下降)优化,维度通常与词嵌入维度一致(如3×3)。
-
对输入矩阵X(已加位置编码)分别进行线性变换,得到三个矩阵:
Query=X×WQQuery = X \times W_QQuery=X×WQ(每个词的“查询向量”,代表“我要找什么”)
Key=X×WKKey = X \times W_KKey=X×WK(每个词的“关键向量”,代表“我能提供什么信息”)
Value=X×VVValue = X \times V_VValue=X×VV(每个词的“价值向量”,代表“我提供的信息内容”)例如:若WQ=[100010001]W_Q = \begin{bmatrix}1&0&0\\0&1&0\\0&0&1\end{bmatrix}WQ= 100010001 (单位矩阵),则Query与X相同,即“我”的Query为[0.1, 0.2, 0.3],以此类推。
4. 第四步:计算注意力分数(Attention Scores)——衡量“关联紧密程度”
注意力分数是“Query与Key的相似度”,用来判断“当前词需要关注其他词的程度”。
-
计算方式:将Query矩阵的每一行(单个词的Query)与Key矩阵的每一列(所有词的Key)做点积运算,得到注意力分数矩阵。
-
公式:Attention Scores=Query×KeyTdkAttention\ Scores = \frac{Query \times Key^T}{\sqrt{d_k}}Attention Scores=dkQuery×KeyT
这里除以dk\sqrt{d_k}dk(dkd_kdk是Key的维度)是为了避免维度过大导致点积结果溢出——当dkd_kdk较大时(如512),点积结果可能远超Softmax函数的敏感区间,导致梯度消失,缩放后可让分数分布更合理。 -
实例:假设Query为[0.1,0.2,0.3]、[0.4,0.5,0.6]、[0.7,0.8,0.9],Key与Query相同,则“喜欢”(第2行Query)与“苹果”(第3列Key)的点积为0.4×0.7 + 0.5×0.8 + 0.6×0.9 = 0.28 + 0.4 + 0.54 = 1.22,除以3≈1.732\sqrt{3}≈1.7323≈1.732后,注意力分数约为0.704,代表“喜欢”与“苹果”的关联度较高。
5. 第五步:Softmax归一化——把分数变成“概率权重”
对注意力分数矩阵的每一行(每个词的注意力分数)做Softmax运算,将分数转化为0-1之间的概率分布,确保:
- 每个词对其他词的“关注权重”总和为1;
- 关联度高的词获得更高的权重,关联度低的词权重趋近于0。
例如:若“喜欢”的注意力分数经过Softmax后为[0.1, 0.2, 0.7],则代表“喜欢”会将70%的注意力放在“苹果”上,20%放在自身,10%放在“我”上——符合“喜欢”的语义逻辑(核心关注对象是“苹果”)。
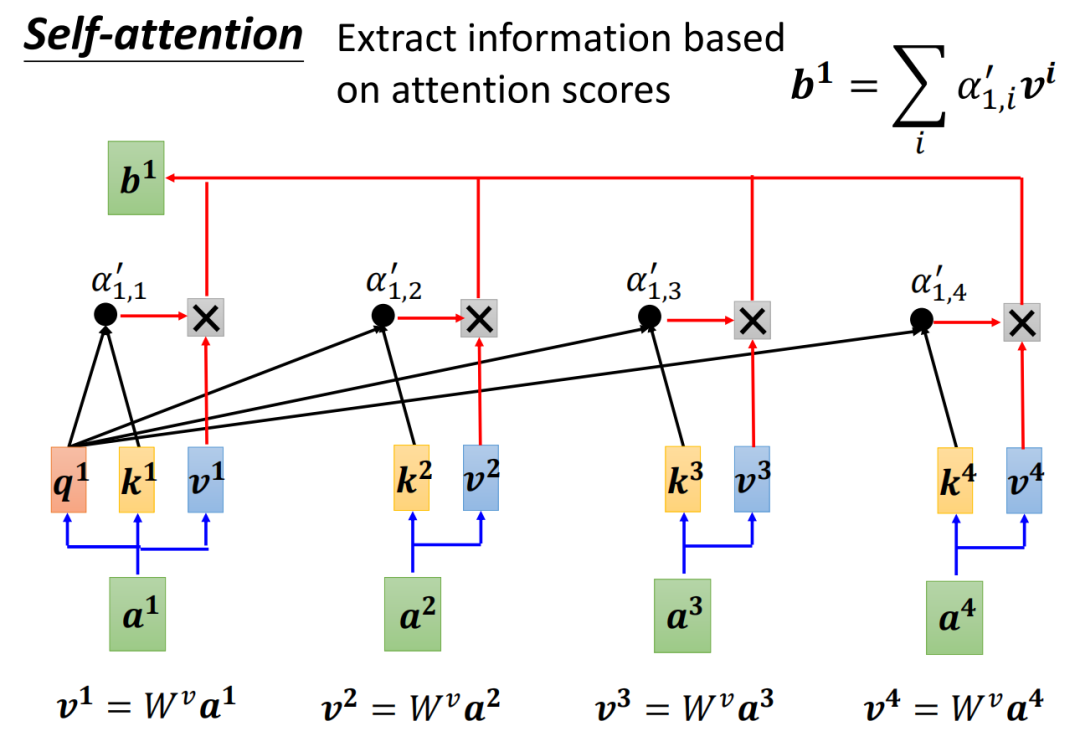
6. 第六步:计算最终输出——加权聚合“有价值的信息”
将Softmax后的注意力权重矩阵与Value矩阵相乘,得到自注意力的输出。这一步的核心是“根据注意力权重,对所有词的Value进行加权求和”,让输出向量融合“全局相关信息”。
-
为什么用Value而不是Key?
Key的作用是“匹配Query的需求”(判断关联度),而Value才是“实际的语义内容”——就像你在图书馆查书(Query是“机器学习”),Key是书的标签(“机器学习入门”),Value是书的正文内容。只有找到匹配的标签(Key),才能提取对应的正文(Value),最终形成有意义的知识(输出)。 -
实例:若“喜欢”的注意力权重为[0.1, 0.2, 0.7],Value矩阵与输入X相同,则“喜欢”的输出向量为:
0.1×[0.1,0.2,0.3] + 0.2×[0.4,0.5,0.6] + 0.7×[0.7,0.8,0.9] = [0.01+0.08+0.49, 0.02+0.1+0.56, 0.03+0.12+0.63] = [0.58, 0.68, 0.78]
这个向量综合了“我”“喜欢”“苹果”的信息,且重点突出了“苹果”的语义,完美体现了自注意力的“全局加权”逻辑。
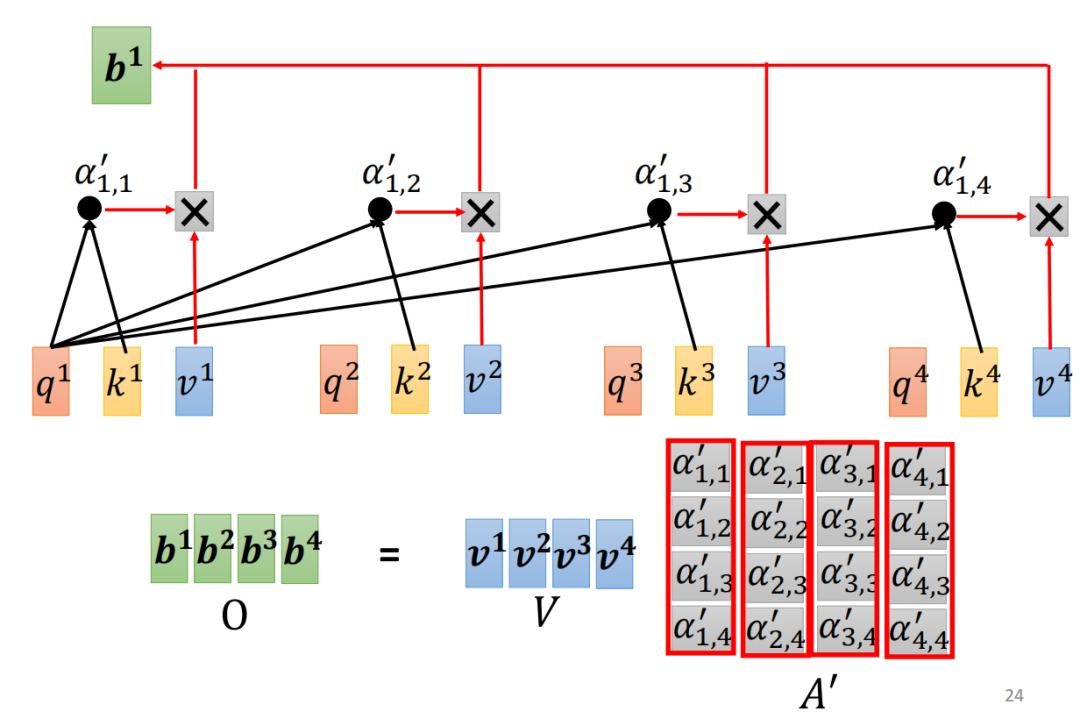
最终输出矩阵的形状与输入矩阵一致(3×3),每个行向量都包含了“全局相关信息”,为后续Transformer的编码器/解码器处理打下基础。
四、总结:自注意力的价值与未来方向
自注意力机制不仅是Transformer的“核心”,更是深度学习序列建模的“范式革新”——它用“全局并行”打破了RNN的效率瓶颈,用“动态关联”弥补了CNN的局部局限,同时通过可解释性为模型优化提供了抓手。如今,自注意力已从NLP、CV渗透到语音识别(如Whisper模型)、多模态(如CLIP模型)、推荐系统(如基于用户行为序列的注意力推荐)等领域,成为通用人工智能的关键技术之一。
当然,自注意力也存在优化空间:比如标准自注意力的计算复杂度为O(n2)O(n^2)O(n2)(n为序列长度),处理超长序列(如10000个token)时仍有压力。因此,稀疏自注意力(如Longformer)、线性注意力(如Performer)等改进方案不断涌现,旨在平衡“全局视野”与“计算效率”。
理解自注意力,就等于掌握了Transformer的“密码”——无论是调优现有模型,还是探索新的应用场景,这份对“核心动力”的认知,都将成为你深入深度学习领域的重要基石。如果觉得本文有帮助,欢迎点赞关注,后续我们将进一步拆解Transformer的编码器、解码器结构,以及实战中的调优技巧!
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
为什么要学习大模型?
我国在A大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着AI技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国AI产业的创新步伐。加强人才培养,优化教育体系,国际合作并进是破解困局、推动AI发展的关键。


👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献388条内容
已为社区贡献388条内容

所有评论(0)