让开发者翘首以盼的 LLM 入门与实战指南——《图解大模型:生成式 AI 原理与实战》重磅上市!
让开发者翘首以盼的 LLM 入门与实战指南——《图解大模型:生成式 AI 原理与实战》重磅上市!
一本让开发者与 AI 从业者翘首以盼的 LLM 入门与实战指南——《图解大模型:生成式 AI 原理与实战》重磅上市!
本书由 Jay Alammar 与 Maarten Grootendorst 联袂创作,两位在大模型与自然语言处理领域具有广泛影响力的专家,内容融合广受欢迎的图解系列精华,一经推出便获得业内高度评价。
从基础概念、核心原理到应用实践,本书用超过 300 幅可视化图解,搭建出一条清晰、系统、低门槛的大模型学习路径。

无论你是 AI 初学者,还是希望深入掌握 Transformer 架构、掌握生成式 AI 核心能力的从业者,甚至是希望真正“搞懂大模型”的普通读者,这本书都将是不可或缺的学习宝典。
目前本书还没有中文版PDF,英文版PDF已打包整理好!

让所有的技术难点都可视化
LLM 很复杂,但学习它不该是痛苦的。
为帮助读者轻松、高效地掌握大模型核心知识与技能,全书绘制了 300+ 幅全彩图示,配合直观讲解,从底层逻辑到实战部署,层层拆解,看图也能学懂大模型。
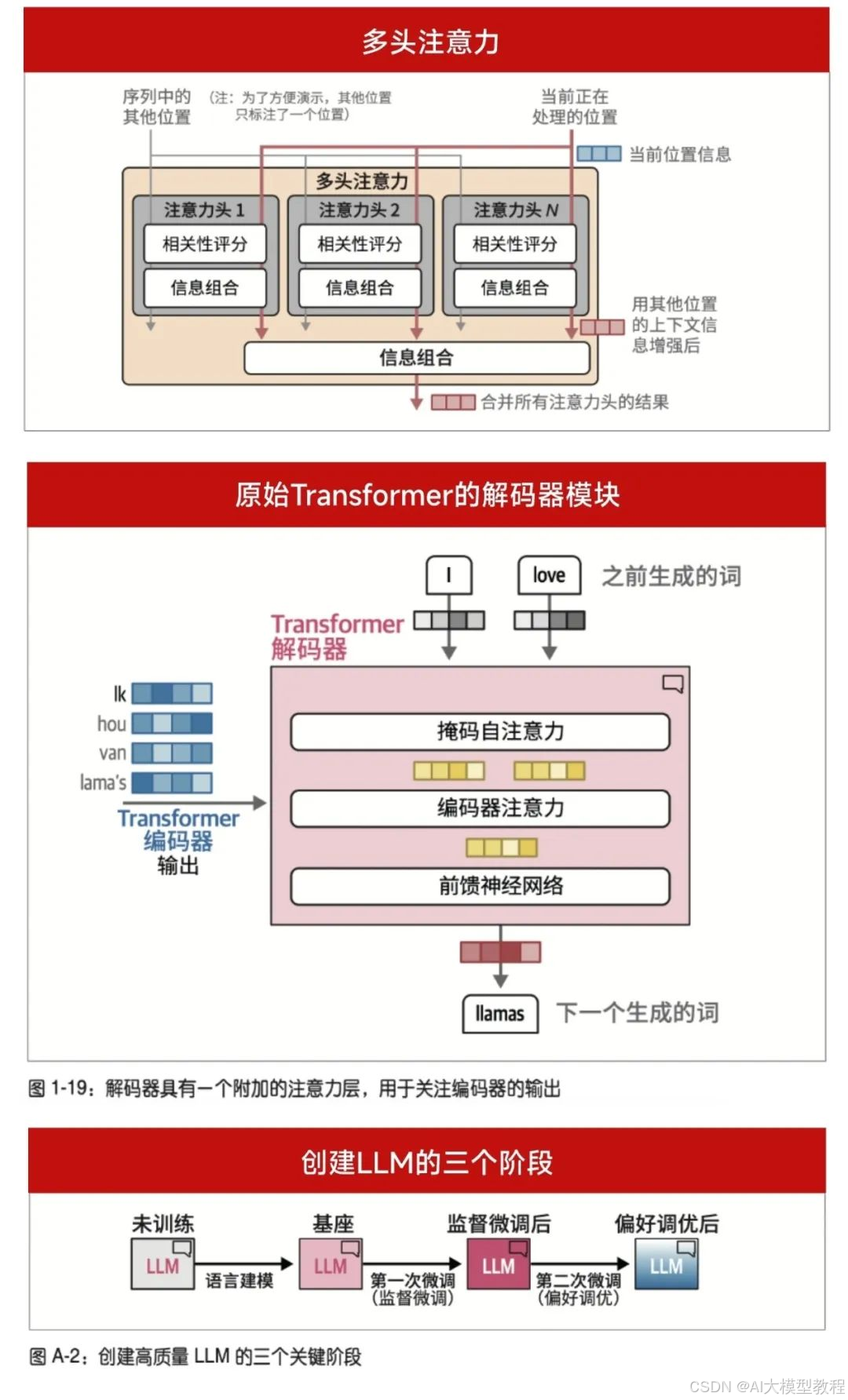
Transformer 的注意力机制、微调流程、嵌入向量如何工作?——不再是 “文字迷宫”,而是 “图解让人一目了然”。
系统全面的知识架构
全书精心编排了 12 章内容,架构清晰,循序渐进,为读者搭建起从基础认知到高阶应用的完整学习阶梯,共分为四个部分:
内容亮点,中文版专属!
第四部分“图解 DeepSeek-R1”(附录)是中文版独有的重磅内容:18 幅精心绘制的图解,深入剖析 DeepSeek 的底层原理。当前,深入浅出地解读 DeepSeek-R1 技术原理的资料仍然稀缺,这一部分堪称超值“彩蛋”,强烈推荐阅读!

第一部分 “理解语言模型”(第 1 - 3 章):聚焦于夯实基础,深入剖析语言模型的核心概念。
从词元这一文本处理的基本单元讲起,阐述其在模型中的角色;引入嵌入概念,解释如何将单词或文本转化为计算机可理解的向量形式,实现语义的数字化表达;Transformer 架构更是讲解重点,通过详细拆解其结构与运行机制,让读者明白这一支撑现代大语言模型的底层架构是如何运作的,为后续深入学习筑牢根基。
即使是初次接触大模型的新手,也能在这部分内容引导下,顺利建立起对语言模型的初步认知。
第二部分 “使用预训练语言模型”(第 4 - 9 章):带领读者从理论走向实践,着重介绍如何运用现有的预训练大模型解决实际问题。
覆盖了文本分类任务,教会读者如何让模型自动识别文本所属类别,如新闻分类、情感分析等场景应用;聚类技术可将相似文本聚为一类,助力信息整理与分析;语义搜索使搜索结果不再局限于关键词匹配,而是基于语义理解,大大提升搜索精准度;文本生成能根据给定提示创作连贯文本,像智能写作助手、故事生成器等皆基于此技术;此外,还涉及多模态扩展,打破单一文本模态限制,融合图像、音频等多种信息,拓宽大模型应用边界,全方位提升读者对大模型应用能力的掌握。
第三部分 “训练和微调语言模型”(第 10 - 12 章):深入探讨模型优化的关键环节。
详细讲解嵌入模型构建,如何打造更贴合特定任务的文本向量表示;分类任务优化围绕提升模型在分类场景中的准确率、召回率等指标展开,介绍一系列调优技巧;生成模型微调则针对生成内容的质量、风格等方面进行定制,使模型能适应如个性化写作、特定领域对话生成等特定需求。
这部分内容对于期望深入掌握模型定制,提升模型性能以适配实际业务的读者而言,极具价值。
本书实操性超棒,每章节均贴心配备相应开源代码,这些代码全部托管于 GitHub 平台,方便读者随时获取。并且,代码支持在 Google Colab 平台上直接运行,无需复杂的本地环境搭建,打开即跑,边学边练,真正做到“看得懂、学得会、跑得动”。
目前本书还没有中文版PDF,英文版PDF已打包整理好!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献470条内容
已为社区贡献470条内容

所有评论(0)