Jetson AGX Orin 复现 FoundationPose 问题记录
Jetson aarch64 架构下,pip 的构建隔离机制会创建完全隔离的临时环境来编译 pytorch3d,这个临时环境默认不会安装 torch(即使当前环境有),而 pytorch3d 的 setup.py 第一行就导入 torch,导致必报 ModuleNotFoundError.第一次接触linux系统和orin,一开始绕了很多弯路,光刷机和torch版本匹配就搞了好久。发现原因是cuD
第一次接触linux系统和orin,一开始绕了很多弯路,光刷机和torch版本匹配就搞了好久。
后来按照如下教程进行Jetson AGX Orin Jetpack 6.2 的复现:
在 Jetson 上跑通 FoundationPose!从零部署 NVIDIA 6D 位姿估计系统实战全流程_在jetson上跑通foundationpose-CSDN博客
记录过程中遇到的一些问题
首先,因为python版本问题,模型需要python3.9以上,刷机把jetpack从5.1升到了6.2,预设版本如下:
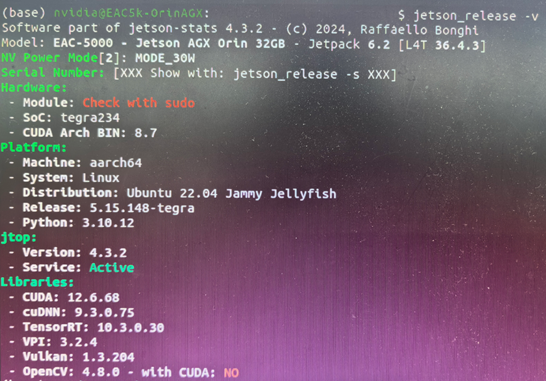
前几步很顺利,克隆项目、安装依赖、GCC/G++、配置架构;
安装pytorch2.3.0、torchvision0.18.0、torchaudio2.3.0后安装pytorch3d时pip install -e .出现问题:
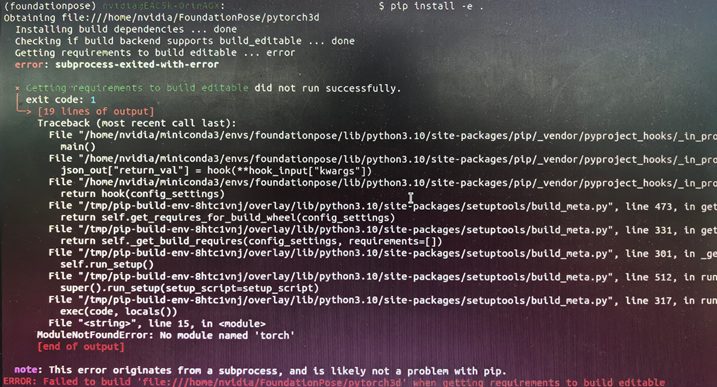
编译pytorch3d时,构建环境未识别到环境中的torch
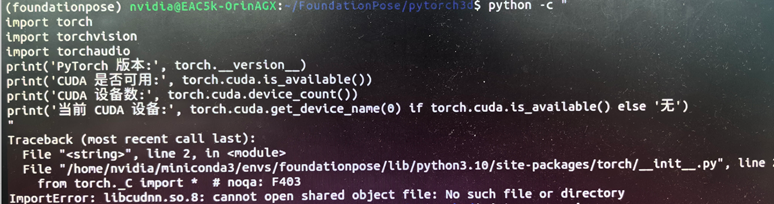
发现原因是cuDNN版本不匹配,找不到lincudnn.so.8,进而识别不到torch。
系统预设是cudnn9,torch2.3.0匹配的是cudnn8,一开始想提升torch版本,官网找到有配套vision、audio的最高版本即torch2.3.0, 更高级的torch2.4.0等无法找到匹配的vision、audio;
换了个思路把cudnn版本降至8.9.7,先卸载cuDNN9.3:
# 卸载cUDNN 9 运行库、开发库、示例包
sudo apt-get remove --purge -y libcudnn9-cuda-12 libcudnn9-dev-cuda-12 libcudnn9-samples nvidia-cudnn nvidia-cudnn-dev
# 清理输出中提示的无用依赖
sudo apt-get autoremove -y
# 清理apt缓存
sudo apt-get clean
# 刷新系统库缓存
sudo ldconfig验证一下:
dpkg -l | grep cudnn
ls -l /usr/lib/aarch64-linux-gnu/libcudnn*.so* #无libcudnn9 相关文件
ls -l /usr/local/cuda/lib64/libcudnn*.so* #无libcudnn9 相关文件
到官网 cuDNN Archive | NVIDIA Developer 下载 cudnn-local-repo-ubuntu2204-8.9.7.29_1.0-1_arm64.deb
安装cuDNN8本地仓库包:
# 切换到下载目录(路径不同需修改)
cd ~/Downloads
# 安装本地仓库包(会提示密钥问题,执行下一步即可)
sudo dpkg -i cudnn-local-repo-ubuntu2204-8.9.7.29_1.0-1_arm64.deb
#复制密钥到系统密钥目录
sudo cp /var/cudnn-local-repo-ubuntu2204-8.9.7.29/cudnn-local-80EFB423-keyring.gpg /usr/share/keyrings/
#刷新apt源
sudo apt-get update安装cuDNN 8核心组件:
#安装cuDNN8运行库
sudo apt-get install -y libcudnn8=8.9.7.29-1+cuda12.2
#安装cuDNN8开发库
sudo apt-get install -y libcudnn8-dev=8.9.7.29-1+cuda12.2
#刷新系统库缓存
sudo ldconfig卸载适配cuDNN9的pytorch,重新安装:
#卸载现有PyTorch
pip uninstall -y torch torchvision torchaudio
#安装适配 CUDA 12.6+ cuDNN8 的PyTorch(Jetson aarch64 专用版本)
pip install torch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 \
--extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v62/pytorch
#升级 pip 和 setuptools (解决构建环境依赖问题)
pip install --upgrade pip setuptools wheel setuptools-scm
#安装 pytorch3d 编译必需的依赖
pip install ninja cmake pybind11
#先清理之前的构建缓存
rm -rf build/ dist/ *.egg-info
#手动设置环境变量,强制构建环境使用当前环境的torch
export PYTHONPATH=/home/nvidia/miniconda3/envs/foundationpose/lib/python3.10/ \
site-packages:$PYTHONPATH
#重新尝试以开发模式安装
pip install -e . -v发现又报错:ERROR: Failed to build 'file:///home/nvidia/FoundationPose/pytorch3d' when getting requirements to build editable.
问了豆包:Jetson aarch64 架构下,pip 的构建隔离机制会创建完全隔离的临时环境来编译 pytorch3d,这个临时环境默认不会安装 torch(即使当前环境有),而 pytorch3d 的 setup.py 第一行就导入 torch,导致必报 ModuleNotFoundError.
rm -rf build/ dist/ *.egg-info
rm -rf /tmp/pip-build-env-*
pip uninstall -y pytorch3d
# 安装编译工具
pip install --upgrade ninja cmake pybind11 setuptools-scm
pip install fvcore iopath # pytorch3d 依赖的核心库
echo 'export TORCH_CUDA_ARCH_LIST="8.7"' >> ~/.bashrc
source ~/.bashrc
# 清理所有残留缓存
rm -rf build/ dist/ *.egg-info
rm -rf /tmp/pip-build-env-*
# 关闭构建隔离,强制使用当前环境依赖编译
pip install -e . --no-build-isolation -v编译成功。
往下进行,安装pybind11发现cmake版本过低,卸了重装:
sudo apt remove -y cmake cmake-data
sudo apt autoremove -y
pip install cmake==3.25.0 --force-reinstall
cmake --version
rm -rf CMakeCache.txt CMakeFiles/
cmake .. -DCMAKE_BUILD_TYPE=Release -DPYBIND11_INSTALL=ON -DPYBIND11_TEST=OFF -DPYTHON_EXECUTABLE=/home/nvidia/miniconda3/envs/foundationpose/bin/python
make -j6
sudo make install安装mycpp时发现缺少BoostSystem开发包,安上:
cd ~/FoundationPose/mVcpp
rm -rf build && mkdir -p build && cd build && cmake .. && make -j$(nproc)
sudo apt update && sudo apt install -y libboost-system-dev
rm -rf CMakeCache.txt CMakeFiles/
sudo apt install -y libboost-program-options-dev
rm -rf *
cmake .. -DPYTHON_EXECUTABLE=/home/nvidia/miniconda3/envs/foundationpose/bin/python
make -j$(nproc)最后运行demo时出现报错:
![]()
原因:
- Jetson Orin 系统 CUDA 版本为 12.6,但 PyTorch 编译依赖 CUDA 12.2,版本不匹配导致 CuDNN 卷积引擎失效;
- AMP(自动混合精度)开启后,float16 精度与 Orin CUDA 核心不兼容;
- 部分配置文件中 enable_amp: true 未关闭,加剧精度冲突
解决方案:
cd ~/FoundationPose/bundlesdf/mycuda
#用vim打开setup.py
vim setup.py将c++14改成17:

创建软链接指向cuda12.2:
#停止所有 CUDA 相关进程(避免软链接占用)
sudo killall -9 nvcc python
#重新创建软链接指向有nvcc的cuda-12.6(保证编译工具可用)
sudo ln -s /usr/local/cuda-12.6 /usr/local/cuda需要修改优先级确保12.2优先级最高,否则还是12.6
#编辑 .bashrc,确保12.2 优先级最高
vim ~/.bashrc
#找到所有包含cuda-12.6的行,注释/删除;并添加以下内容到文件末尾,强制优先使用CUDA 12.2:
export PATH=/usr/local/cuda-12.2/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64:$LD_LIBRARY_PATH
# Orin 架构适配
export TORCH_CUDA_ARCH_LIST="8.7"
# CUDNN 路径适配(Jetson 专属)
export CUDNN_INCLUDE_DIR=/usr/include
export CUDNN_LIB_DIR=/usr/lib/aarch64-linux-gnu
# 生效配置
source ~/.bashrc
#重新打开终端,验证 nvcc版本12.2
nvcc -V关闭amp:
sed -i 's/enable_amp: true/enable_amp: false/g' ~/FoundationPose/estimater.py
sed -i '/nn.Conv2d/ s/$/, dtype=torch.float32/' \ ~/FoundationPose/learning/models/network_modules.py
sed -i '/@torch.cuda.amp.autocast()/d' \ ~/FoundationPose/learning/training/predict_pose_refine.
echo "代码修改完成:已关闭 AMP + 强制卷积 float32 精度"
export TORCH_CUDNN_DISABLED=1 #完全禁用 CUDNN
export TORCH_CUDA_ARCH_LIST="8.7" # 强制 orin 架构
export CUDA_HOME=/usr/local/cuda-12.2 #指定CUDA 12.2
export CUBLAS_WORKSPACE_CONFIG=:4096:8 #解决内存碎片
export PYTHONWARNINGS="ignore" #屏蔽无关警告
export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64:$CONDA_PREFIX/lib/python3.10/site-packages/torch/lib:$LD_LIBRARY_PATH全局查找enable_amp所有配置文件,修改amp状态:
conda activate foundationpose && \
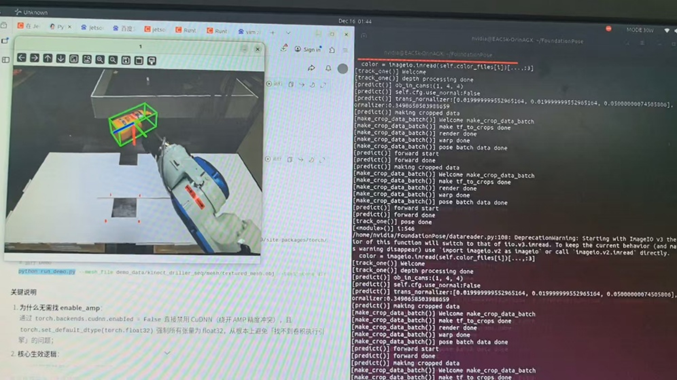
grep -rn "enable amp" ~/Foundationpose --include="*.py" --include="*.yaml" --include="*.cfg” && \ echo "=====以上是 enable_amp 所有配置位置 ====="运行成功:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)