【dify实战】身份证信息提取助手搭建指南
操作上,需先点击视觉模型节点的配置入口(即 “视觉按钮”),在图片识别参数设置中,将 “待识别图片文件” 指定为迭代流程中的 “当前项(item)”—— 这一配置的核心作用是,让模型在每次迭代时,自动读取当前循环到的单张图片,确保批量上传的所有图片能被逐个处理,而非一次性处理整个文件列表。通过这种设置,迭代逻辑与视觉识别形成精准联动:每轮迭代调用一次视觉模型,仅针对当前 item(单张图片)执行分
大家好,欢迎欢迎来到我的小屋,今天想和大家分享一款身份证信息提取工具 —— 它的核心功能是提取身份证信息,同时也适用于更广泛的图片信息提取场景。
具体来说,这个工具需要实现以下功能:打造一个能提取身份证信息的智能处理模块,支持批量上传多张图片,对上传的图片进行分析过滤后,自动识别其中包含的身份证信息,最终输出仅包含姓名、地址、身份证号三项内容的 JSON 格式结果。
一、问题分析
通过对需求的梳理,可提炼出以下核心要点,构成身份证信息提取智能体的完整功能框架:
1.批量图片上传能力
支持一次性选择并上传多张图片文件,满足批量处理需求
2.图片分析过滤能力
具备智能识别机制,可自动筛选出包含身份证信息的图片,过滤无效内容
3.身份证信息识别能力
精准提取身份证上的核心信息字段,限定为姓名、地址、身份证号三项关键内容
4.标准化输出能力
将识别结果以 JSON 格式规范呈现,输出内容仅包含上述三项信息,保证数据结构的简洁性与一致性
二、工作流搭建
结合 Dify 的功能支持,上述核心需求要点可通过工作流实现完整落地,搭建后的工作流逻辑与需求要点高度匹配,具体的流程如下:
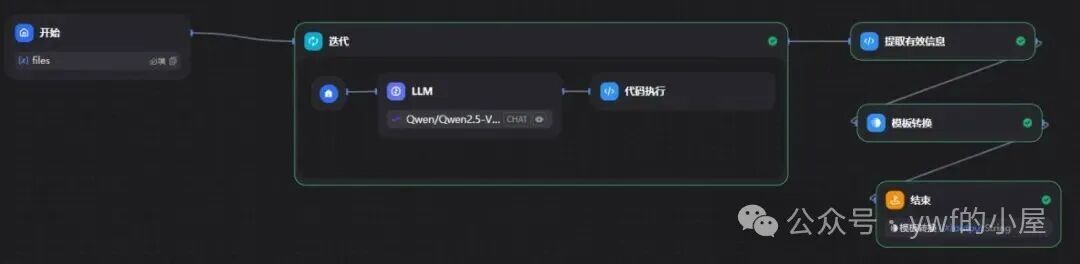
结合此前提炼的 “批量上传、分析过滤、信息识别、JSON 输出” 四大核心需求要点,我们可逐一拆解 Dify 工作流的实现逻辑与对应价值,明确每个环节如何精准承接需求:
1、对应 “批量图片上传能力”:从源头解决多文件处理入口问题
在dify中开始节点中设置文件列表,就可以实现批量上传多个文件,这里要选择设置上传图片
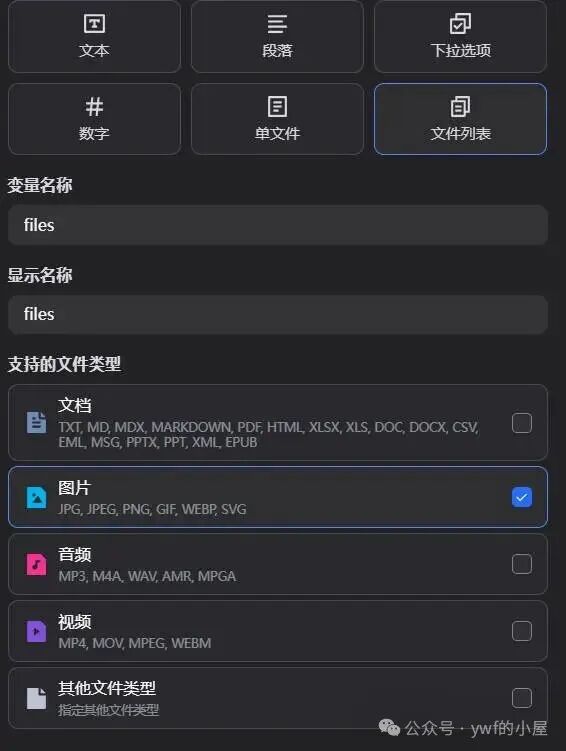
详细操作步骤如下:
1、从开始节点进入流程配置
2、依次执行:添加变量 → 选择文件列表类型 → 指定图片文件格式
3、系统默认支持上传 10 个文件,若需处理更多文件,需修改环境变量配置文件.env 中的参数:WORKFLOW_FILE_UPLOAD_LIMIT,将其值调整为所需数量即可。
2、迭代设置:实现批量文件的逐个精准处理
在本工作流中,迭代设置是衔接 “批量上传” 与 “逐一处理” 的核心环节,其设计完全贴合 “对多个文件逐个执行识别逻辑” 的需求,具体实现逻辑与价值如下:
迭代的核心作用
当系统通过开始节点获取到批量上传的图片列表后,需要对每张图片依次执行 “分析过滤→信息识别” 的完整流程 —— 这正是迭代节点的核心价值:将批量文件集合拆解为单个元素,逐个传入后续处理链条,确保每张身份证图片都能被独立分析、精准识别,避免因 “批量混处理” 导致的信息错乱或遗漏。
工作流中的迭代配置逻辑
在 Dify 工作流中,配置迭代节点时需指定 “迭代对象” 为前面上传的 “图片文件列表”,系统会自动触发循环机制:
1、从文件列表中取出第一张图片,执行后续的分析过滤与信息识别流程;
2、完成后自动取出第二张图片,重复相同流程;
3、直至所有上传的图片均被处理完毕,迭代过程终止。
迭代配置如下图:
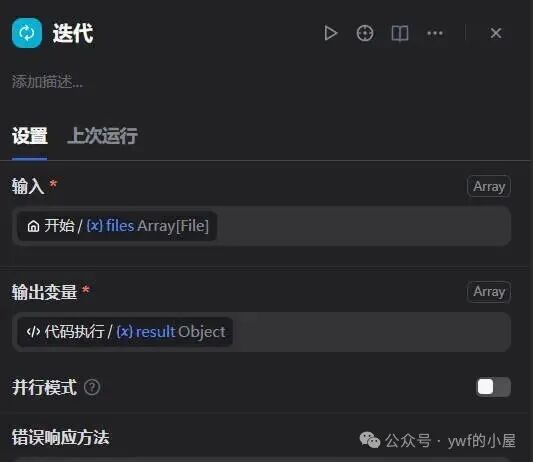
·输入变量:选择批量上传的文件
·输出变量:这里我配置的是通过代码节点信息提取的结果
3、LLM:分析过滤-信息提取
在迭代流程的每一步,系统会对单张图片依次执行 “分析过滤” 与 “信息提取” 两大核心处理逻辑。具体实现上,可依托多模态大模型完成视觉与文本的协同识别 —— 我当前选用的是 qianwen-2.5vl-32B 视觉大模型,若需灵活替换,也可选择 doubao-seed-1.6 等其他多模态模型,二者均能稳定支撑该场景下的图片分析与信息提取需求。
实现该逻辑所用的系统提示词如下:
请执行以下任务:首先判断输入的图片是否为身份证图像(需覆盖大陆居民身份证正反面识别逻辑)。若判定为身份证:精准提取证件上的姓名、地址(常住户口所在地地址)、身份证号字段;注意处理遮挡 / 脱敏场景(如遇遮挡,按规则用 * 替换遮盖内容,保证格式合规);严格遵循身份证字符排版、字体规范解析信息(如地址字段的省市区层级、身份证号校验逻辑)。输出格式要求:json{"is_id_card": true/false,"data": {"name": "姓名","address": "地址","id_number": "身份证号"}}若不是身份证,is_id_card 为 false,data 留空或按需简化;若为身份证但部分字段无法识别(如遮挡严重),对应字段用合理占位(如 ****)填充,保证 JSON 结构完整。额外要求:需校验身份证号的合法性(含位数、校验码规则),异常情况在 data.id_number 标注说明(如 "id_number": "格式异常(校验码不符)" );区分身份证正反面内容整合(正面:姓名、性别、民族、出生日期、住址、公民身份号码、签发机关;反面:国徽、有效期限 ,核心提取姓名、地址、身份证号即可,地址取正面 “住址” 字段 )。
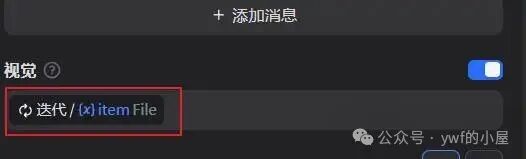
操作上,需先点击视觉模型节点的配置入口(即 “视觉按钮”),在图片识别参数设置中,将 “待识别图片文件” 指定为迭代流程中的 “当前项(item)”—— 这一配置的核心作用是,让模型在每次迭代时,自动读取当前循环到的单张图片,确保批量上传的所有图片能被逐个处理,而非一次性处理整个文件列表。
通过这种设置,迭代逻辑与视觉识别形成精准联动:每轮迭代调用一次视觉模型,仅针对当前 item(单张图片)执行分析过滤与信息提取,既保证了处理的独立性,又通过循环机制覆盖了全部上传文件,完美适配批量识别场景。
4、代码节点:实现识别结果的精准解析与规范化
在视觉大模型节点完成信息识别后,需配置代码执行节点对模型输出结果进行结构化处理,确保最终数据符合预期格式。
该节点的核心作用是对大模型返回的原始识别结果进行两层处理:首先清除文本中可能存在的冗余标记(如特殊分隔符、代码块标识),再通过 JSON 解析将非结构化文本转换为键值明确的字典格式,最终输出仅包含姓名、地址、身份证号的规范数据,为后续的 JSON 格式化输出奠定基础。
用到的代码如下:
import jsonimport redef main(text: str) -> dict:"""删除</think>...<|FunctionCallEnd|>标签及其内部内容并返回规范化结果字典"""text = re.sub(r'<think>.*?</think>', '', text, flags=re.DOTALL)# 提取 JSON 部分(去除 ```json 标记)json_str = re.sub(r'^```json\n|\n```$', '', text, flags=re.MULTILINE)try:# 解析 JSON 数据parsed_data = json.loads(json_str)# 返回包含规范化问题的字典return {"result": parsed_data}except json.JSONDecodeError:# 处理 JSON 解析失败的情况return {"result": None}except Exception as e:return {"result": None}
5、迭代完成:提取身份证有效信息
迭代处理流程已执行完毕,输出结果为当前识别图片对应的身份证信息解析成果。该功能通过代码节点实现,具体所用代码如下:
def main(result_list: list) -> dict:"""筛选出result_list中is_id_card为True的条目参数:result_list: 包含身份证识别结果的列表,每个元素为包含is_id_card和data的字典返回:包含所有is_id_card为True的条目的字典,键为'valid_results'"""# 筛选出is_id_card为True的结果valid_results = [item for item in result_list if item.get('is_id_card', False)]# 返回整理后的结果return {'valid_results': valid_results}
6、模板转换
模板转换节点的作用是对输出结果进行格式转换。在此环节中,具体功能为将列表(list)形式的结果转换为字符串(string)格式,以便能在 Dify 控制台中正常输出展示。
转换过程可理解为:通过代码逻辑遍历列表中的各项元素,按照预设的拼接规则(如添加分隔符、换行符等)将其整合为一个完整的字符串,确保信息的完整性与可读性,从而适配 Dify 控制台的输出要求。
三、总结
本次基于 Dify 搭建身份证信息提取工具工作流,核心是围绕 “需求 - 落地 - 优化” 层层推进,形成精准高效的批量处理方案,心得可凝练为三点:
1、需求拆解定框架,锚定核心不偏离
先深度梳理需求,提炼 “批量上传、分析过滤、信息识别、标准化输出” 四大核心要点,明确关键边界 —— 如上传支持多图且可调整数量上限、识别仅提取姓名 / 地址 / 身份证号、输出锁定 JSON 格式。清晰的需求框架,让后续节点选择与参数配置更精准,避免流程冗余。
2、节点联动筑闭环,破解批量处理痛点
以 “迭代 + LLM + 代码” 为核心实现协同:迭代节点将批量图片拆解为单个 “item”,确保独立处理;引入 qianwen-2.5vl-32B 等多模态模型,通过提示词完成 “是否为身份证判断 + 核心信息提取 + 身份证号校验”;代码节点清除冗余标记、解析 JSON 并筛选有效结果,再经模板转换适配控制台输出,形成 “上传 - 处理 - 识别 - 输出” 完整闭环。
3、细节优化提实效,平衡灵活与规范
注重实用细节打磨:上传环节明确.env 文件参数修改方法以适配不同量级需求;识别环节加入遮挡脱敏、身份证号校验规则保障合规准确;代码节点设置异常处理避免流程中断。既满足批量处理灵活性,又靠规范逻辑与容错设计提升工具稳定性。
综上,本次搭建以需求为导向,用节点联动落地功能,靠细节优化保障体验,不仅实现工具目标,也为同类图片信息提取工作流提供可复用思路。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)