程序员必学:NLP大模型底层原理详解,从基础到Transformer,建议收藏
文章介绍了自然语言处理(NLP)的发展与核心技术,包括NLP的四种类型和预处理流程。详细阐述了文本表示方法,从离散式到分布式向量表示。重点讲解了Seq2Seq模型的Encoder-Decoder架构及RNN基础,分析了Attention机制如何解决长距离信息弱化问题。最后深入解析了Transformer模型及其self-attention结构,展示了Multi-Head attention机制,为
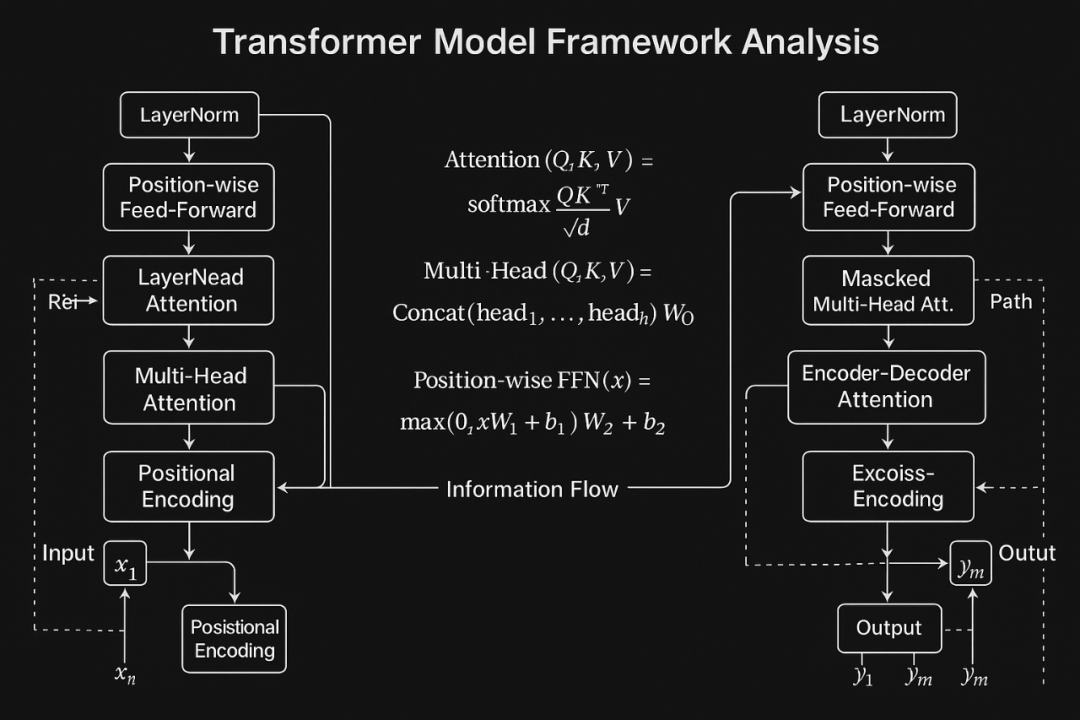
一、自然语言处理(NLP,natural language processing)
人工智能发展非常迅速,尤其是约2020年前以来爆发时发展出大语言模型如Chatgpt和Deepseek。其中,NLP自然语言处理就是在机器语言和人类语言之间沟通的桥梁,可以实现人机交流的目的。目前最典型的NLP应用包括手机电脑的聊天机器人、语音识别和机器翻译等,已经延伸各行各业发挥作用。
机器只能以数字的形式进行理解和学习,其中有文本出现则需要将其转化为“数字”,也就是机器可以理解的NLP处理。NLP的类型分为四种:类别到序列、序列到类别、同步的序列到序列、异步的序列到序列。其中类别到序列种类进行文本的生成和图像描述生成,序列到序列类型进行文本挖掘、文本分类和情感分析,同步的序列到序列进行中文分词、词性标注和实体识别,异步的序列到序列进行机器翻译、自动摘要生成和问答系统运行。
NLP预处理也分成多个步骤为收集数据、清洗数据、分词、标准化与特征提取。首先需要收集数据建立语料库,常见方式是直接下载开源免费语料库,比如维基百科语料库。下载完成后需要对数据进行整理叫做数据清洗,也就是把不能直接使用的预料数据转化成易于处理的格式,比如大量的无用符号和特殊文本。第三步是进行分词,是NLP的基础任务,将清洗好的语料库比如句子、段落分解为字词单位,为后续处理分析做准备。进一步需要进行标准化,包括去掉停用词、词汇表、训练数据等等,是为了给后续处理提供一些必要的基础数据。最后是特征提取,将文本的原始特征转化为具体特征,转化方式有两种包括统计和Embedding(嵌入),预处理完成后即可建模。
NLP文本是使用向量(一串数字)来表示,比如图片等结构化数据可以转换为数字等表达形式,文字等非结构化数据也需要转化为数字形式,才能让计算机理解解读。计算机对文字的理解其实是计算机对数字所表示的空间及位置的理解。那么NLP文本的表示形式则分为词向量和句子向量,其中词向量分为离散式表示(discrete representation)和分布式表示(distribute representation)。离散式表示又分为one-hot编码、词袋模型编码、词频-逆文档频率法IF-IDF。分布式表示(周围词表示该词)分为共现矩阵、word2vec、SKIP-GRAM、GloVe、ELMO。句子向量表示形式只有doc2vec这一种。
二、代码学习Seq2seq模型:Encoder-Decoder模型
Encoder编码器是将输入的问题转化为数学问题,用简练的信息表示重要的特征
Decoder解码器是求解数学问题,并转化为现实解决方案。
关系如下,Encoder把东西解析为向量,然后模型学习,然后Decoder输出解决方案。
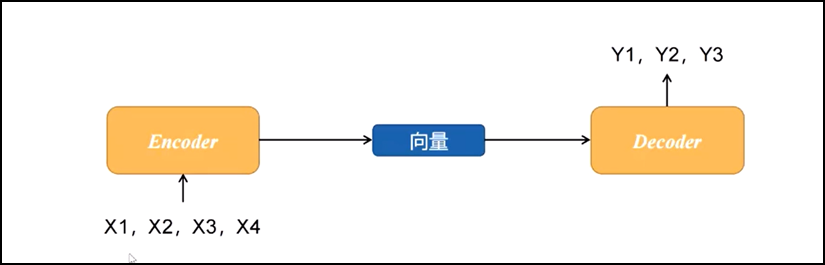
常见的Seq2Seq模型的输入序列和输出序列是可变的,比如翻译任务、文本摘要任务。它属于Encoder-Decoder框架。
l RNN循环神经网络模型是基本自然语言处理模型,可以简单表示为Yt=RNN(Xt, Ht-1)=RNN(Xt, Xt-1,…X1)
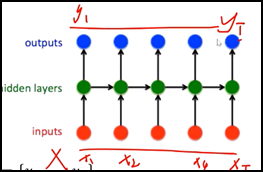
l Seq2Seq模型:不要求输入和输出序列长度可以变化、可以不同。Content向量本质就是最后一个隐藏层状态、是一组浮点数,长度是隐藏层神经元数量。
缺点是输入的特征太多,content vector会丢失远距离信息,而且错误还会进行累加。

三、Attention模型
模拟人类视觉注意力机制,快速从大量信息中筛选出高价值手段。
l 参数少:与CNN、RNN对比,难度小参数少,算力要求小
l 速度快:解决了RNN不能并行计算的问题,还不依赖上一步处理结果,可以像CNN一样并行处理
l 效果好:解决长距离信息弱化的问题,太长文本也不会丢失重要信息
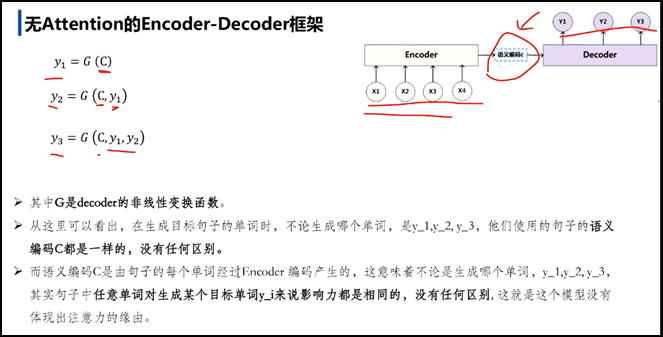
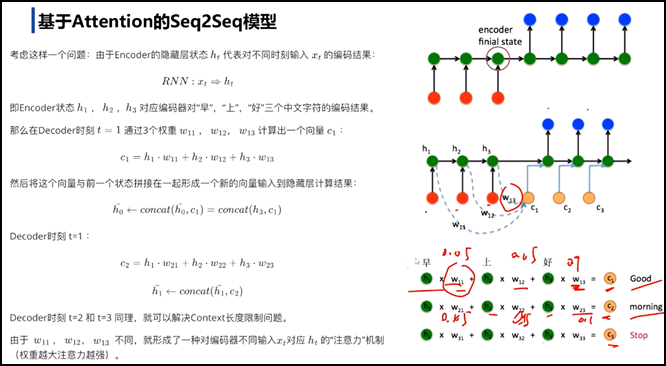
ü 举例子对比,无attention的Encoder-Decoder框架
ü 基于attention的Encoder-Decoder框架

ü 基于attention的Seq2Seq模型
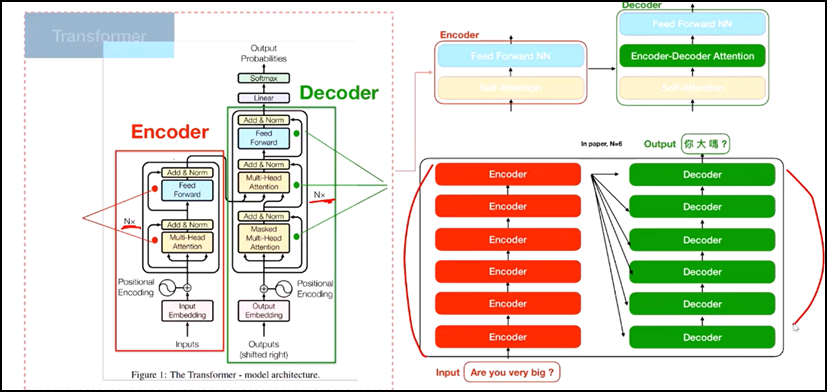
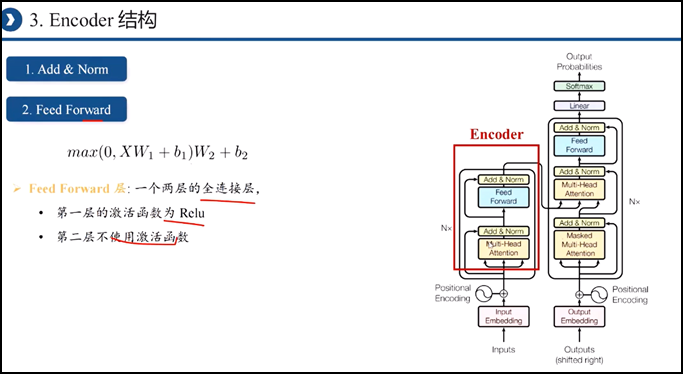
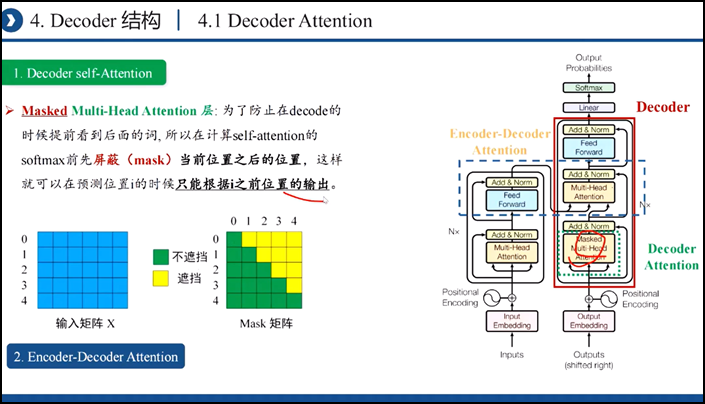
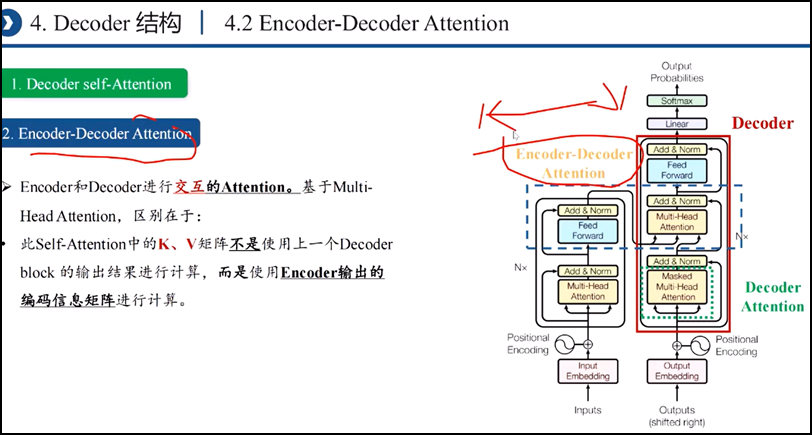
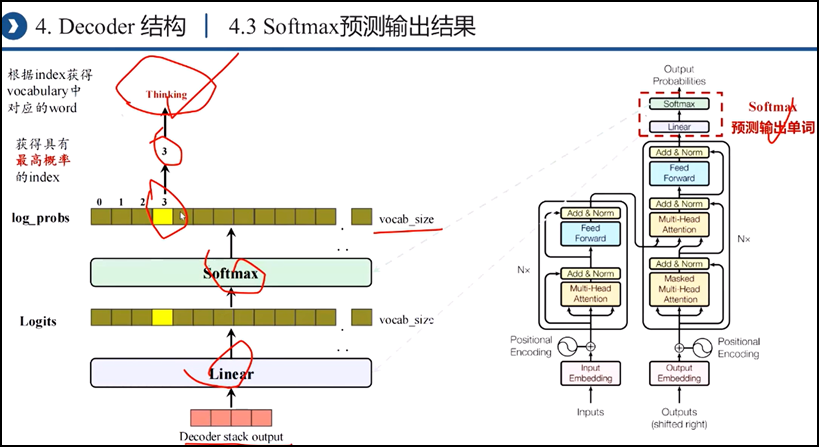
四、Transformer模型:直接基于self-attention结构,取代了之前的NLP的常用的RNN神经网络结构
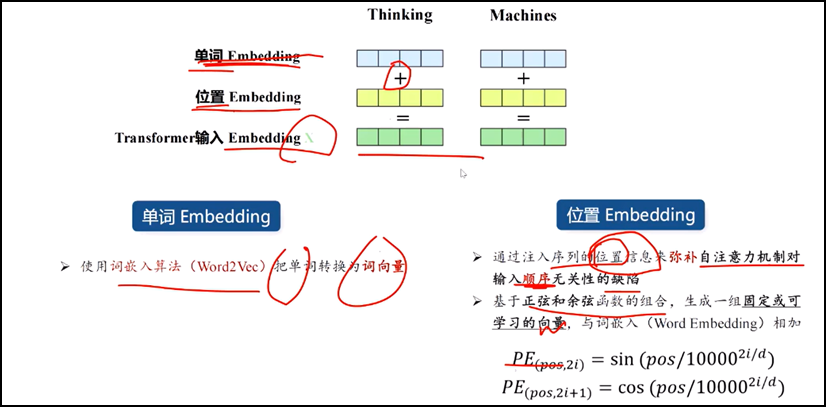
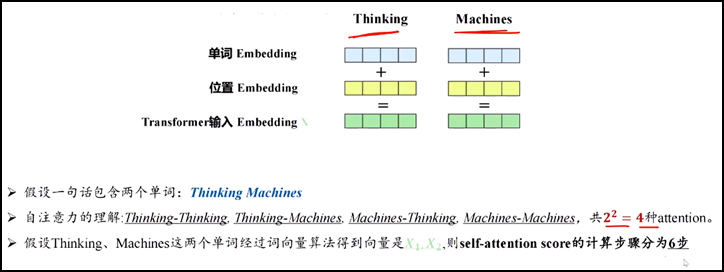
1.Transformer的输入
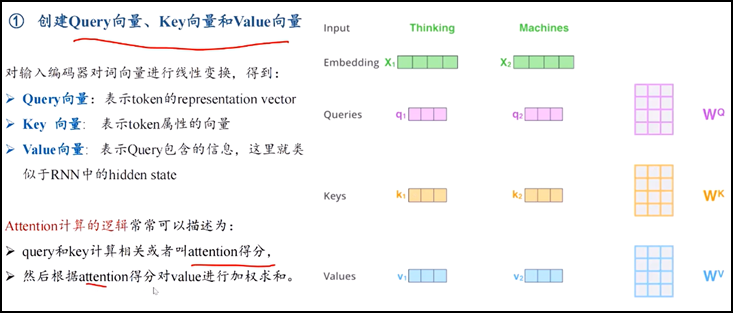
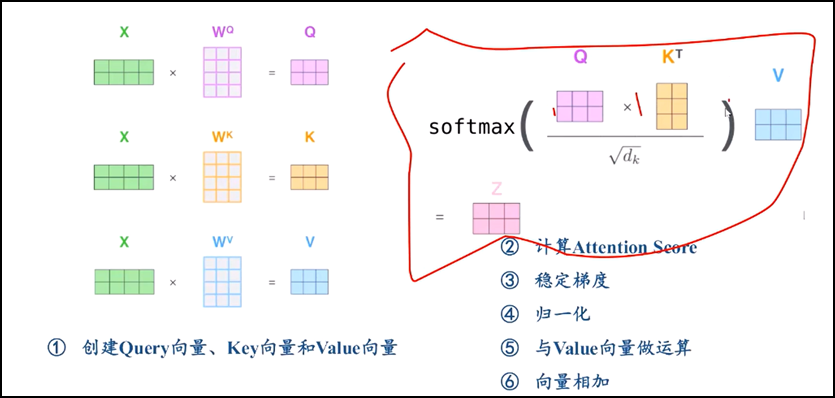
2.Self-attention整体理解

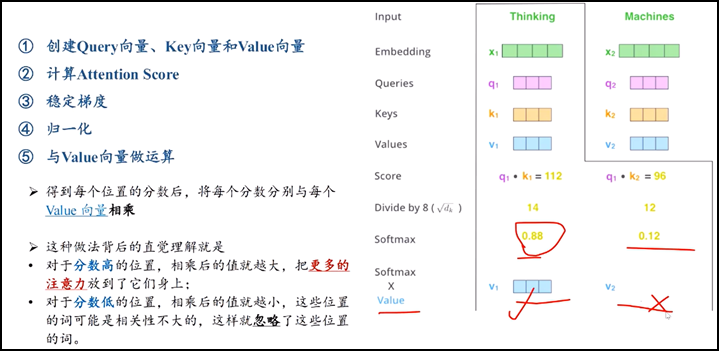
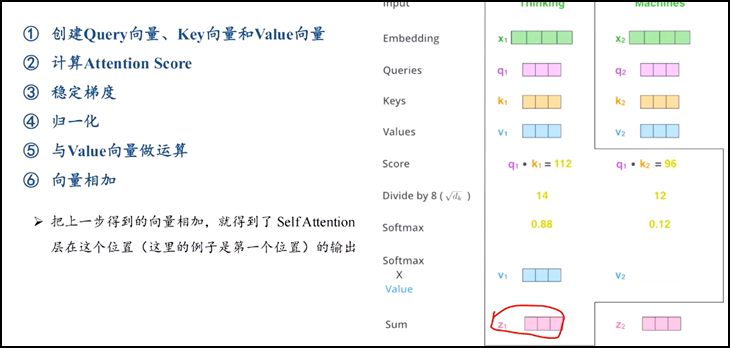
3.计算方法:
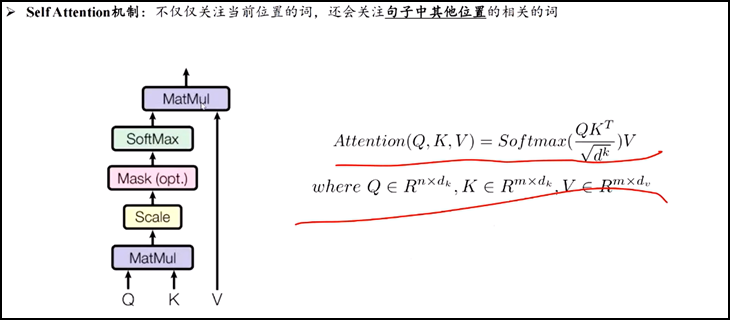
l 举例子 thinking和machines两个输入单词



4.实际计算本质方法:矩阵计算
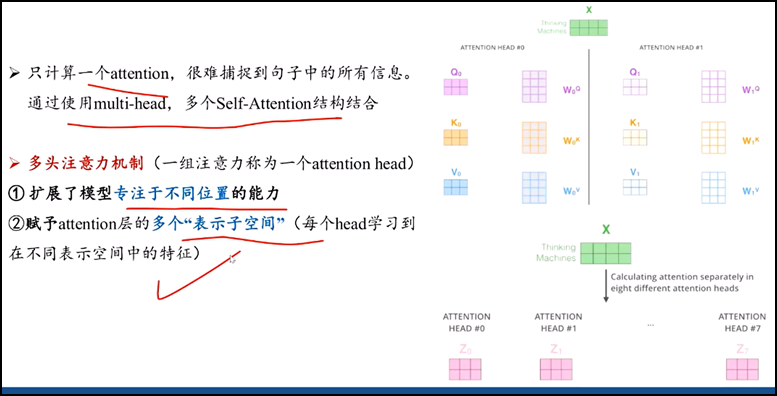
- Multi-Head attention 机制
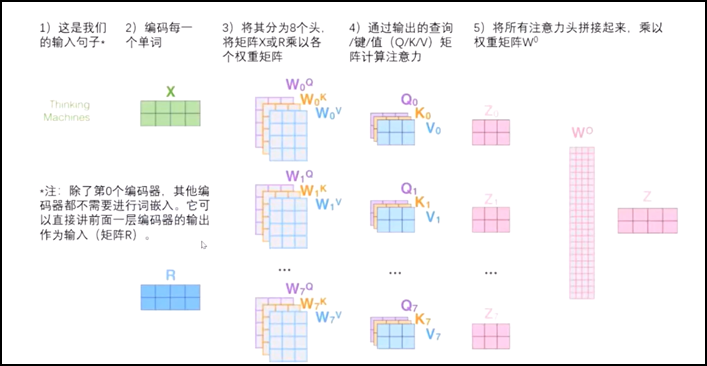
比如下面这个是8头注意力
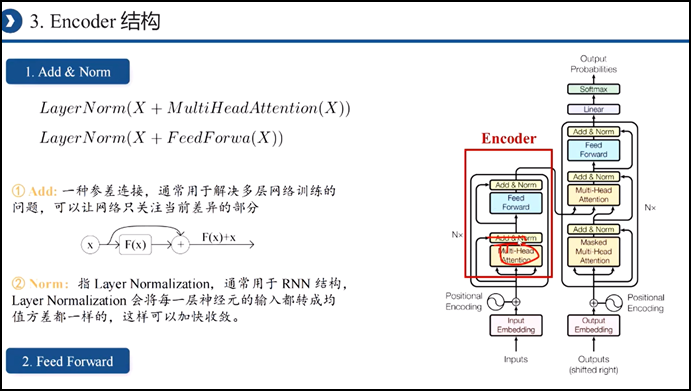
五、文章中self-attention is all you need里的transformer模型解析
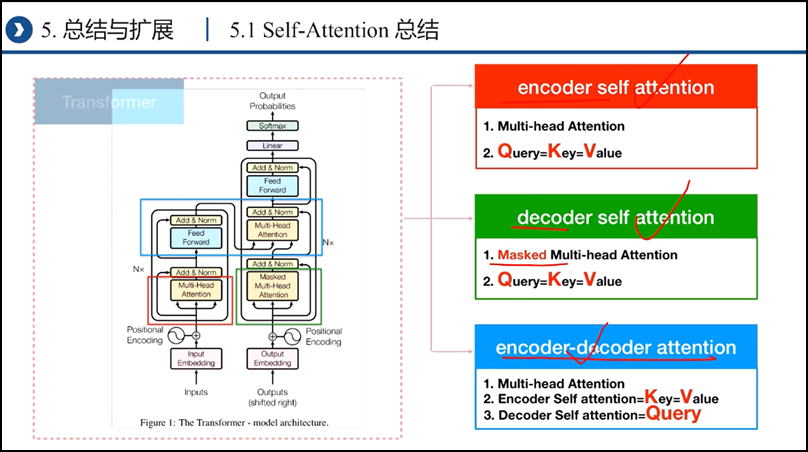
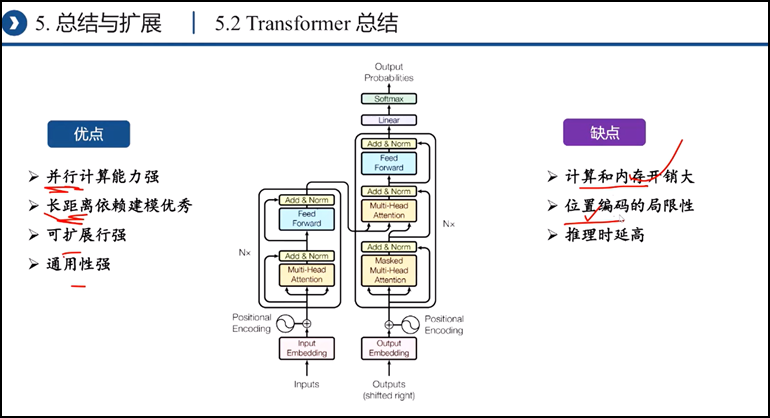
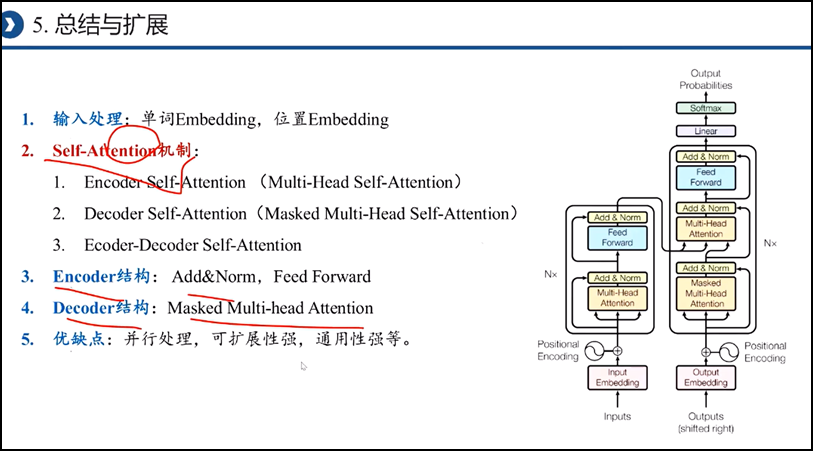
最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献393条内容
已为社区贡献393条内容

所有评论(0)