FINE-GRAINED ABNORMALITY PROMPT LEARNING FOR ZERO-SHOT ANOMALY DETECTION
目前的零样本异常检测 (ZSAD) 方法在促使大型预先训练的视觉语言模型在不使用任何特定于数据集的训练或演示的情况下检测目标数据集中的异常方面取得了显著的成功。然而,这些方法通常集中在制作/学习提示上,这些提示只捕捉异常的粗粒度语义,例如,地毯上的“损坏”、“不完美”或“有缺陷”等高级语义。因此,它们在识别具有独特视觉外观的各种异常细节方面的能力有限,例如,地毯上的色渍、割伤、孔洞和线等特定缺陷类
摘要:
目前的零样本异常检测 (ZSAD) 方法在促使大型预先训练的视觉语言模型在不使用任何特定于数据集的训练或演示的情况下检测目标数据集中的异常方面取得了显著的成功。然而,这些方法通常集中在制作/学习提示上,这些提示只捕捉异常的粗粒度语义,例如,地毯上的“损坏”、“不完美”或“有缺陷”等高级语义。因此,它们在识别具有独特视觉外观的各种异常细节方面的能力有限,例如,地毯上的色渍、割伤、孔洞和线等特定缺陷类型。为了解决这一限制,我们提出FAPrompt,这是一个新颖的框架,旨在学习细粒度异常提示以获得更准确的零样本异常检测能力。为此,我们在 FAPrompt 中引入了一个新的复合异常提示模块,用于学习一组互补的、分解的异常提示,其中每个异常提示由一个共享的正常标记和几个可学习的异常标记组成。另一方面,细粒度的异常模式可能因数据集而异。为了增强它们的跨数据集泛化性,我们进一步引入了一个数据依赖的异常先验模块,该模块学习从每个查询/测试图像中导出异常特征作为样本异常,然后再将异常提示置于给定的目标数据集中。在 19 个真实世界数据集(涵盖工业缺陷和医学异常)中进行的综合实验表明,FAPrompt 在图像和像素级 ZSAD 任务中的性能至少比最先进的方法高出 3%-5% AUC/AP。代码可在 GitHub - mala-lab/FAPrompt: Official PyTorch implementation of "Fine-grained Abnormality Prompt Learning for Zero-shot Anomaly Detection". 获取。
一、引言
异常检测 (AD) 是计算机视觉中的一项关键任务,旨在识别与大多数数据明显不同的实例。它具有广泛的实际应用,例如工业检测和医学成像分析(Pang et al., 2021;Cao等人,2024 年)。传统的 AD 方法侧重于使用大型训练样本来学习专门的检测器。因此,这些方法通常依赖于特定于应用程序的、精心策划的数据集来训练检测模型,这使得它们不适用于由于数据隐私问题而无法进行此类数据访问的应用程序场景,或者由于新部署环境或数据集中的其他自然变化引起的大量分布变化而导致测试数据与训练集显着不同的应用程序场景。零样本 异常检测(ZSAD) 旨在学习通用模型以检测目标数据集中的异常,而无需使用任何特定于数据集的训练或演示,最近已成为解决传统 AD 方法这一局限性的一种有前途的方法。
近年来,大型预训练视觉语言模型 (VLM),如 CLIP(Radford等人,2021 年)在广泛的视觉任务中展示了令人印象深刻的零/少样本识别能力,包括 ZSAD 任务(Chen 等人,2023b;Jeong 等人, 2023;邓等人,2023 年;周 等人, 2024)。为了将 VLM 用于 AD,方法制作/学习文本提示从 VLM 中提取正常/异常的文本语义以匹配视觉异常。这些方法,如 WinCLIP(Jeong 等人., 2023)和 AnoVL (邓 等人., 2023),试图通过在文本提示中包含各种预定义的状态感知标记(例如,使用 'damaged'、'imperfect' 或 'defective' 来描述地毯等不同对象上的缺陷)或域感知标记(例如,'industrial'、'manufacturing' 或 'surface')来捕获一系列异常语义以获得更好的ZSAD。其他(周 et al., 2024;2022a;b) 使用可学习的文本提示来提取更多通用特征来表示正常/异常类别,例如 AnomalyCLIP(周 等人, 2024)。然而,这些方法主要集中在异常的粗粒度语义上,在识别具有独特视觉外观的各种异常细节方面的能力有限,例如,特定的缺陷类型,如地毯上的色渍、切口、孔洞和线,如图 1 左所示,导致无法检测到与粗粒度异常模式不同的异常。最近的一种方法 AnomalyGPT (Gu 等人, 2023) 通过额外的大型语言模型 (LLM) 使用异常对象的详细文本描述来处理这个问题,但它需要来自目标数据的参考样本,这与 ZSAD 的任务不同。它还严重依赖昂贵的人工注释来提供详细的文本描述。
为了解决这些问题,我们提出了一个新的框架,即 FAPrompt,旨在学习细粒度的异常提示以获得更准确的 ZSAD。与以前的提示方法相比,FAPrompt 专注于学习可以建模各种细粒度异常语义的提示,而无需详细的人工注释或文本描述,如图 1 左底部所示。为此,我们在 FAPrompt 中引入了一个新的复合异常提示模块,即 CAP,用于在正常提示的基础上学习一组互补的、分解的异常提示,其中每个异常提示都是由正常提示中相同词元和几个可学习的异常词元组成的。这种设计的洞察力源于我们的观察,即每个异常图案都可以被认为是一些意想不到的图案叠加在常见的正常图案之上,例如地毯正常纹理上的色渍。这种复合提示策略可以很容易地学习不同的异常语义,同时保持异常提示与正常提示的良好接近。这有助于避免学习与正常提示相距太远的琐碎异常提示,缺乏区分正常样本和异常样本的可区分性。
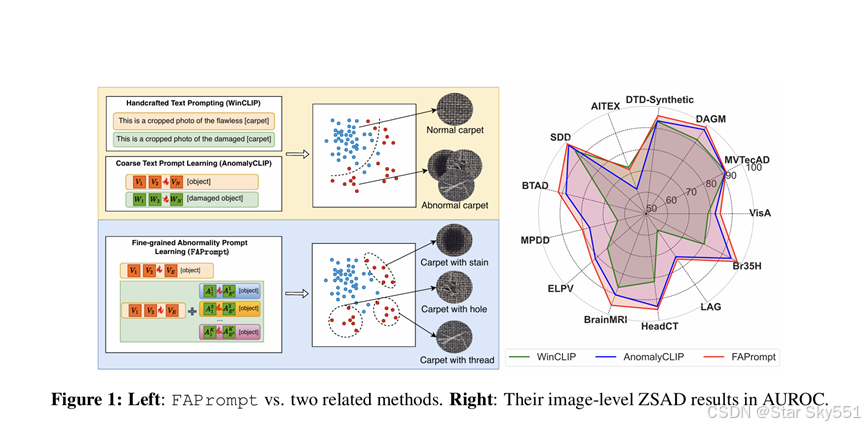
图1
另一方面,细粒度的异常模式可能因数据集而异。因此,为了实现更好的跨数据集泛化,学习到的细粒度异常提示应该适应任何目标测试数据集。因此,我们进一步引入了一个数据依赖的异常先验模块,即 DAP,以增强 CAP 中异常标记的跨数据集泛化性。它学习从每个查询/测试图像中派生异常特征作为样本异常,然后将 CAP 中的异常提示动态调整到给定的目标数据集。CAP 和 DAP 之间的这种交互能够学习具有细粒度语义并适应不同测试数据集的异常提示,从而在各种图像 AD 数据集中实现更好的 ZSAD,如图 1 右所示。
因此,我们做出以下主要贡献。
-
我们提出了一种新的 ZSAD 框架 FAPrompt。与仅捕获异常的粗粒度语义的现有方法不同,FAPrompt 提供了一种学习自适应细粒度异常语义的有效方法,而无需依赖详细的人工注释或文本描述。
-
为了实现这一目标,我们首先在 FAPrompt 中引入了一个新的复合异常提示模块(CAP)。它通过复合 正常-异常 标记设计和异常提示之间的正交约束,在正常提示之上学习一小组互补的、分解的异常提示。
-
我们进一步引入了数据依赖性异常先验模块 (DAP)。它学习从异常图像中选择最相关的异常特征,同时避免从正常图像中选择最相关的异常,以便在 CAP 中学到的细粒度异常适应给定的目标数据集。
-
对 19 个不同的真实世界工业和医学图像 AD 数据集的综合实验表明,在图像和像素级检测任务中,FAPrompt 的 AUC/AP 至少比最先进的 ZSAD 模型高出 3%-5%。
二、相关工作
2.1常规异常检测
多年来,引入了不同类型的 AD 方法。特别是,一类分类方法(Tax & Duin,2004;Yi & Yoon, 2020;Bergman & Hoshen, 2020;Chen et al., 2022;Ruff et al., 2020)旨在使用支持向量紧凑地描述正常数据。基于重建的方法(Akcay et al., 2019;Schlegl et al., 2019;Zavrtanik 等人,2021b;Yan et al., 2021;Zaheer等人,2020 年;Zavrtanik等人,2021a;Park等人,2020 年;Hou et al., 2021;Xiang et al., 2023;Liu et al., 2023;Yao et al., 2023b;a) 训练模型以重建正常图像,并通过更高的重建误差来识别异常。基于距离的方法(Pang et al., 2018;Defard 等人,2021 年;Cohen & Hoshen, 2020;Roth et al., 2022)通过测量测试图像与正常图像之间的距离来检测异常。知识蒸馏方法(邓和李,2022 年;Bergmann et al., 2020;Salehi et al., 2021;Wang et al., 2021;Cao et al., 2023;Tien et al., 2023;Zhang et al., 2023)专注于从预训练模型中提炼正常模式,并通过比较提炼特征和原始特征之间的差异来检测异常。但是,这些方法通常依赖于特定于应用程序的数据集来训练检测模型,从而限制了它们在由于隐私问题、专有限制或资源限制而限制数据访问的实际场景中的适用性。此外,当训练数据和测试数据的分布之间存在显著差异时,这些方法往往会遇到困难。
2.2零样本异常检测
ZSAD 之所以成为可能,是因为开发了大型预训练基础模型,例如视觉语言模型 (VLM)。CLIP(Radford等人,2021 年)已被广泛用作 VLM,以在视觉数据上启用 ZSAD(Jeong等人,2023 年;周 et al., 2024;邓等人,2023 年;Chen et al., 2023a)。CLIP-AC 通过使用为 ImageNet 数据集设计的文本提示来适应 ZSAD,如 (Radford等人,2021 年)。通过使用专为工业 AD 数据集设计的手动定义的文本提示,WinCLIP (Jeong et al., 2023) 与 CLIP-AC 相比实现了更好的 ZSAD 性能,但它通常不能很好地推广到无缺陷的 AD 数据集。APRIL GAN (Chen等人,2023a) 通过使用带注释的辅助 AD 数据调整一些额外的线性层,将 CLIP 适应 ZSAD。AnoVL (邓 et al., 2023) 在 CLIP 中引入了域感知文本提示和测试时间调整,以提高 ZSAD 性能。AnomalyCLIP(周 et al., 2024)采用可学习的、与对象无关的文本提示来为正常和异常类提取更多通用的文本特征。所有这些方法都集中在制作/学习提示上,这些提示只捕获异常的粗粒度语义,无法检测到表现出与这些粗略异常模式不同的模式的异常。还有许多其他研究利用 CLIP 进行异常检测,但它们旨在增强少样本的能力(Gu 等人,2023 年;Zhu & Pang, 2024)或常规异常检测任务(Joo等人,2023;Wu et al., 2024a;b;c).
三、方法论
3.1 准备工作
问题陈述:设 表示由正常样本和异常样本组成的辅助训练数据集,其中
是一组 N 个图像,
包含相应的 Ground Truth 标签和像素级异常掩码。每个图像
都用
标记,其中
表示正常图像,
表示异常图像。异常掩码
提供
的像素级注释。在测试阶段,我们会看到一组目标数据集,
,其中每个
是来自目标应用程序数据集的测试集,该数据集具有与训练数据
中的样本不同的正常样本和异常样本。ZSAD 的目标是在辅助数据集
上开发模型,并能够泛化以检测
中不同测试集中的异常。特别是,给定来自
的输入 RGB 图像
,其中 h 和 w 分别表示
的高度和宽度,因此需要 ZSAD 模型输出图像级异常分数
和像素级异常映射
。图像级异常分数
提供图像是否异常的全局评估,而像素级异常映射
表示每个像素异常的可能性。
和
中的值都位于 [0, 1] 中,其中值越大表示异常的可能性越高。
VLM Backbone:为了实现准确的 ZSAD,通常需要大型预训练的 VLM。遵循现有方法(Chen等人,2023b;邓等人,2023 年;Jeong et al., 2023;周 et al., 2024),在我们的研究中使用了预训练的 CLIP (Radford et al., 2021),它包括一个视觉编码器 和一个文本编码器
,其中视觉和文本表示通过对 Web 缩放的文本 - 图像对进行预训练很好地对齐。
3.2 FAPROMPT 概述
在这项工作中,我们提出了一个 ZSAD 框架 FAPrompt 来学习自适应细粒度异常语义,而无需依赖详细的人工注释或文本描述。图 2 说明了 FAPrompt 的整体框架,它由两个新模块组成,包括复合异常提示模块 (CAP) 和数据依赖性异常先验模块 (DAP)。更具体地说,提出的 CAP 模块旨在指定细粒度异常提示的设计。CAP 的关键特性是通过复合提示方法获取异常提示,其中我们有一个正常提示,并在其上添加多个异常提示。然后,CLIP 的文本编码器 处理这些正常和异常文本提示,以分别生成相应的正常和异常文本嵌入。对于给定的图像
,FAPrompt 提取一个图像标记嵌入
和一组嵌入
的补丁标记,其中 l 和 d 分别表示
的长度和维度。然后根据图像和文本嵌入之间的相似性使用
学习提示,其中细粒度的异常提示在用于相似性计算之前被聚合到异常提示原型中。此外,引入 DAP 模块,提高细粒度异常提示的跨数据集泛化能力。DAP 根据给定的查询/测试图像
得出最相关的异常特征,在根据给定目标数据集的特征动态调整 CAP 中的异常提示之前,作为样本级异常。在训练过程中,CLIP 的原始参数保持冻结状态,只有文本编码器层中附加的可学习 Token 以及正常和细粒度的异常提示得到优化。下面我们将详细介绍这些模块。
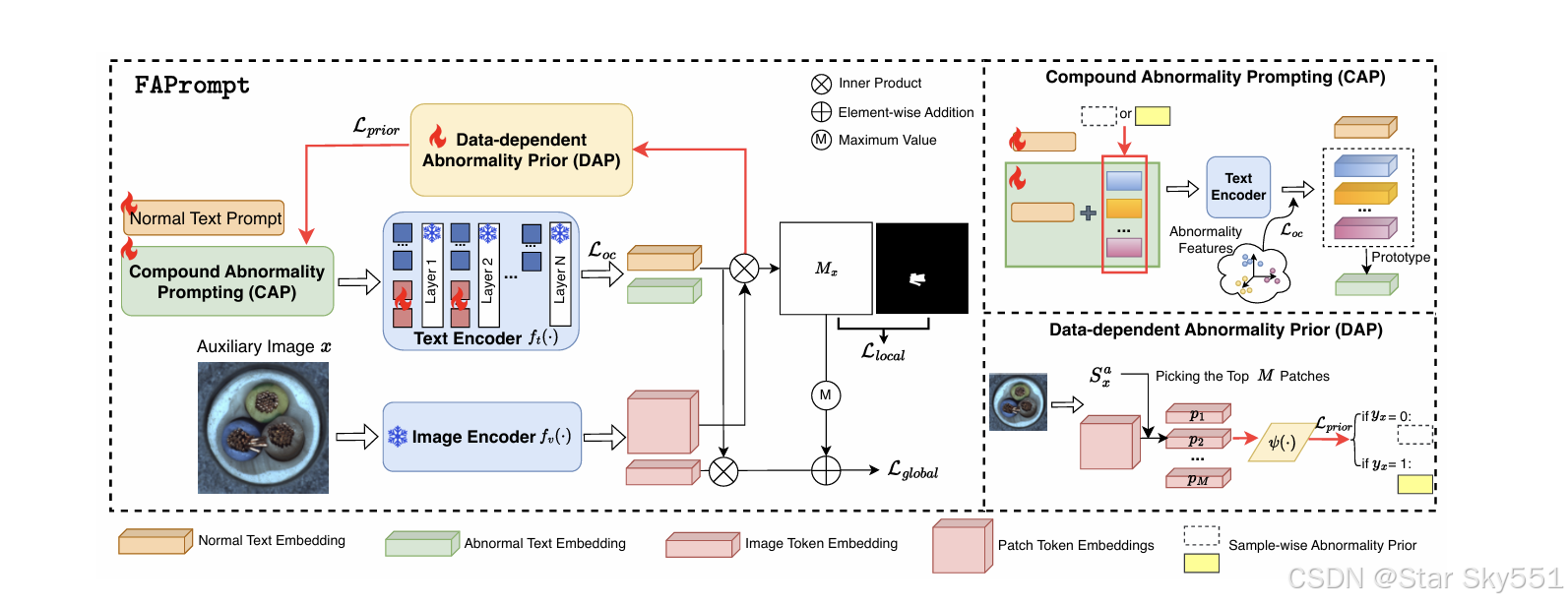
图2 FAPPrompt概述
3.3 复合异常提示学习
通过复合正常和异常标记学习细粒度异常:以前依赖于粗粒度可学习文本提示的方法无法捕获细粒度的异常语义来检测不同数据集中的各种异常。为了解决这个问题,我们提出了新颖的 CAP 模块。核心见解是,异常样本通常表现出与正常样本不同程度的偏差,但仍属于同一类别。CAP 通过学习一组基于共享正常提示构建的互补、分解的异常提示来对此进行建模。根据以前的工作(周 等., 2024),将一组可学习的法线词元和固定词元 'object' 连接起来,以定义正常文本提示 。对于异常提示,CAP 旨在学习一小组互补语义提示,表示为
,其中每个
由正常提示
中相同词元的复合体和一些可学习的异常词元组成。从形式上讲,正常提示和异常提示可以定义为:
其中和
分别是可学习的正常和异常标记。这种复合提示策略使得在保持异常提示与正常提示较近的同时,能够轻松地学习不同的异常语义,支持非平凡的、语义上有意义的异常提示的学习
学习互补异常提示:为了捕获互补的细粒度异常并减少异常提示捕获的冗余信息,必须最大限度地增加细粒度异常之间的多样性。一种简单的方法是使用来自不同异常类型的样本在单独的、带注释的子集上训练不同的异常提示。但是,这需要大量的人工注释。为了解决这个问题,我们建议在 CAP 的异常提示中添加一个正交约束损失 作为鼓励这种多样性的替代方法。从形式上讲,其目标可以表述为:
其中文本编码器 用于提取异常提示的嵌入,
表示内积,
返回绝对值,
表示向量的范数。
为了给细粒度异常提供更有代表性的嵌入,我们通过 .正常的文本提示嵌入是
。
3.4 学习先验选择数据依赖性异常
ZSAD 中的一个问题是,细粒度的异常模式可能与测试数据集的辅助数据集有很大不同。除了学习一组互补的细粒度异常提示外,还必须确保将学习的细粒度异常模式推广到目标测试数据集。受 CoCoOp 中的实例条件信息设计的启发 (周 等人., 2022a),我们引入了 DAP 模块,通过自适应选择最异常区域的嵌入作为每个图像输入之前的样本异常,从而增强 CAP 中异常标记的跨数据集泛化性。特别是,给定一个查询/测试图像 ,DAP 选择最异常的图像补丁作为异常,然后再被送入 CAP,以辅助异常提示学习。它通过挑选 token 嵌入与异常提示原型
最相似的前 M 个块来实现这一点:
其中 表示转置操作,
是以
为中心的块标记嵌入,
是补丁级别的异常分数。相应的正常分数可以通过
使用与方程 3 中分子中的
的相似性来计算。
设 是 x 的前 M 个块嵌入,FAPrompt 然后添加额外的可学习层
,即异常先验网络,以基于
对样本异常先验进行建模。然后将这个先验的
作为数据依赖性异常特征合并到 CAP 中异常提示的可学习异常标记中,以动态地将学习到的细粒度异常适应给定的目标数据集,每个单独的异常提示按如下方式进行优化:
其中 是与异常标记具有相同维度的基于向量的先验,⊕ 表示元素加法。因此,异常提示集更新为
和异常提示原型可以相应地细化为
DAP 的目标是引入样本异常信息。然而,正常图像的前 M 个补丁没有异常,因此,简单地将先前的 应用于正常图像会在可学习的异常标记中引入噪声,从而破坏细粒度异常的学习。为了解决这个问题,我们提出了一个异常先验学习损失
,如果
是异常图像,则
是从最异常的 M 个补丁映射的特征,如果是正常图像,则将其最小化为零向量。从形式上讲,
可以定义如下:
其中,是
的一个元素..
3.5 训练与推理
训练:在训练过程中,FAPrompt 首先使用 生成一个面向异常的分割图
,其条目通过方程 3 计算,其中
替换为先验启用的
:
其中 是一个整形和插值函数,用于将补丁级异常分数转换为二维分割图。同样,我们可以根据先验启用的正常分数
生成分割图
。让
表示查询图像 x
的真实掩码,按照 AnomalyCLIP(周 等人, 2024),FAPrompt 中用于优化像素级 AD 的学习目标可以定义为:
其中 是全一矩阵,
和
分别表示焦点损失(Lin et al., 2017)和骰子损失(Li et al., 2019b)。为了确保 DAP 中排名靠前的异常特征定位的准确性,我们应用相同的学习目标来优化分割图
和
,它们分别来自正态性导向的分数
和异常导向的分数
对于图像级监督,FAPrompt 首先根据它与两个提示嵌入 和
的余弦相似度来计算查询图像 x 被归类为异常的概率:
然后,最终图像级异常分数定义为此图像级分数与从异常分数映射得出的最大像素级异常分数的平均值:
其中 表示
和
的最大异常分数的平均值。遵循以前的方法(Zhu & Pang, 2024;Chen 等人,2023a;周 et al., 2024;Jeong等人,2023 年),
被视为
的互补异常评分并纳入方程 9,因为
有助于检测局部异常区域。然后,通过最小化
上的以下损失来优化图像级异常分数
:
其中 由
中的类不平衡引起的焦点损失函数指定。总体而言,FAPrompt 通过最小化以下组合损耗进行优化,该损失集成了局部和全局目标,以及 CAP 和 DAP 模块的两个约束:
推理:在推理过程中,给定一个测试图像 x′,它通过 CLIP 的视觉编码器馈送以生成分割图 、
、
和
。然后,通过对这些分割图进行平均来计算像素级异常图
,如下所示:
其中是元素级减法,图像级异常得分
由公式9计算
四、实验
数据集:为了验证FAPrompt的有效性,我们在19个公开可用的数据集上进行了广泛的实验,包括九个流行的工业缺陷检测数据集(MVTecAD(Bergmann等人,2019年),VisA(Zou等人,2022年),DAGM(Wieler和Hahn,2007年),DTD-合成(Aota等人,2023年),AITEX(Silvestre-Blanes等人,2019年),SDD(Tabernik等人,2020年),BTAD(Mishra等人,2023年)。 2021 年)、MPDD(Jezek 等人,2021 年)和 ELPV(Deitsch 等人,2019 年))和大脑、眼底、结肠、皮肤和甲状腺等不同器官的十个医学异常检测数据集(BrainMRI(Salehi 等人,2021 年)、HeadCT(Salehi 等人,2021 年)、LAG(Li 等人,2019a)、Br35H(Hamada)、CVC-ColonDB(Tajbakhsh 等人,2015 年)、CVC ClinicDB(Bernal 等人,2015 年)、 Kvasir (Jha et al., 2020), Endo (Hicks et al., 2021), ISIC (Gutman et al., 2016), TN3K (Gong et al., 2021)) (有关数据集的详细信息,请参见附录 A)。
为了评估 ZSAD 性能,默认情况下,模型在 MVTecAD 数据集上进行训练,并在其他数据集的测试集上进行评估,而无需任何进一步的训练或微调。我们通过将训练数据更改为 VisA 数据集来获得 MVTecAD 上的 ZSAD 结果。
竞争方法和评估指标:我们将我们的方法 FAPrompt 与几种最先进的方法进行了比较,包括五种基于文本提示的手工方法原始 CLIP(Radford 等人,2021 年)、CLIP-AC 和 WinCLIP(Jeong 等人,2023 年)、APRIL-GAN(Chen 等人,2023a)和 AnoVL(邓等人,2023 年)——以及三种基于可学习文本提示的方法 CoOp(周 et al.,2022b)、CoCoOp(周 et al.,2022a)、 和 AnomalyCLIP(周 et al., 2024)。
至于评估指标,我们遵循以前的作品(Jeonget al.,2023;Zhouet al.,2024)并使用两个流行度量:AUROC(Area Under the Receiver Operating Characteristic)和平均精度(AP)来评估图像级AD性能;对于像素级AD性能,我们采用AUROC和Area under per region overlap(PRO)来提供更多详细分析。
实施细节:遵循以前的方法(Zhouetal.,2024;Chenetal.,2023a),我们使用相同的 CLIP实现,OpenCLIP(Ilharcoetal.,2021),使用公开可用的预训练 VIT-L/14@336pxbackbone。CLIP中 visual 和 textencoder 的参数都保持冻结状态。默认情况下,可学习的标记嵌入附加到文本编码器的前九层,每层的标记长度为 4。可学习的 正常 和 异常文本提示 的长度默认分别为 5和 2。DAP 模块中的细粒度异常提示数和选中的补丁 Token 均设置为 10。我们使用初始学习率为 1e-3 (10^-3)的 Adam 优化器。FAPrompt 和竞争方法的更多实现细节在附录 B 中提供。
4.1 主要结果
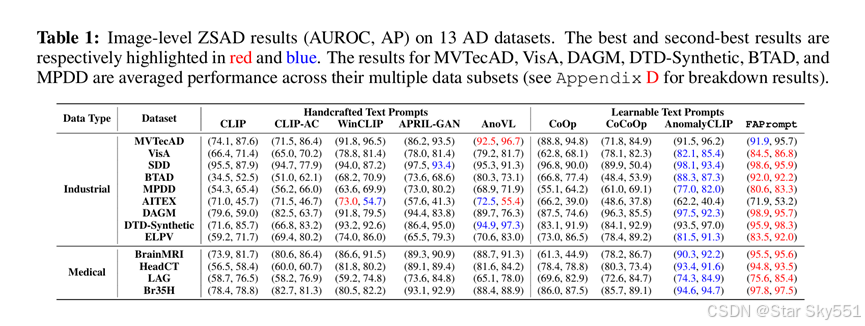
图像级ZSAD表现:表1表示FAPrompt的图像级ZSAD结果,与13AD数据集中的8个最先进的方法进行了比较,包括9个工业缺陷AD数据集和4个医学AD数据集。结果表明,FAPrompt在几乎所有数据集上都明显优于目前最好的模型。平均而言,与最好的竞争方法相比,它实现了 3.7% 的 AUROC 和 4.9% 的 APonindustrialAD数据集和 5.2%的 AUROC 和 3.4%的 AP在医学AD数据集。特别是,CLIP-AC 的弱点可以归因于其过于简化的文本提示设计。通过利用更精心设计的手工提示,WinCLIP实现了比CLIP和CLIP-AC更好的结果,同时保留了免训练的性质。APRIL-GAN 和 AnoVL 通过在文本提示中使用额外的可学习层和/或域感知令牌,对 WinCLIP 进行了改进。然而,它们严重依赖敏感的手工制作的文本提示和捕获主要是粗粒度的语义异常,导致性能不佳当面对异常时,这与预定义的文本描述并不适合,例如,BTAD、MPDD、BrainMRI、HeadCT 和 Br35H。
对于文本提示学习方法,CoOp and CoOpare专为通用视觉任务而设计,即区分不同的对象,因此它们具有弱能力,无法理解同一对象上正常与异常的差异。AnomalyCLIP通过学习与对象无关的文本提示为 AD,展示了跨不同数据集的强大泛化功能,显著提高了性能。但是,AnomalyCLIP会忽略精细的异常细节。FAPrompt 通过其两个新颖的模块 CAP 和 DAP 克服了这一限制。
像素级ZSAD表现:我们还将我们的 FAPrompt 与 最先进的 方法在表 2 中的 14 个 AD数据集上的像素级 ZSAD 结果进行了比较。类似的观察结果可以作为图像级结果得出。特别是,CLIP 和 CLIP-AC 是手工制作的基于文本提示的方法中最弱的,主要是由于文本提示设计不合适。凭借更好的提示工程(并适应 ADinsomecases),WinCLIP、APRIL-GAN 和 AnoVL 表现出更好的性能。对于可学习的文本提示方法,CoOp 由于在适应数据集上过度拟合而表现出较差的性能,而 CoCoOp 通过引入实例条件信息来缓解这一限制,实现了对 CoOp 的实质性改进和 AnomalyCLIP 的竞争性能。FAPrompt 在识别各种像素级异常方面表现出卓越的性能,在几乎所有数据集中都明显优于最先进的模型。它超越了工业AD数据集上2.7%的AUROC和4.4%的AP的最佳竞争方法,在医学AD数据集上超过了3.0%的AUROC和3.7%AP,这证明了在FAPrompt中自适应捕获细节异常语义在不同数据集中的有效性。
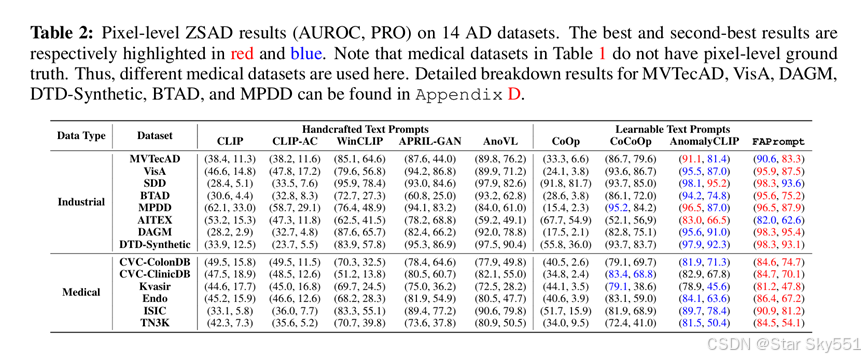
学习互补异常的表现:为了评估 FAPrompt 学习到的异常提示的互补性,我们实证评估了每个异常提示的可区分性及其与其他提示的差异。为此,我们计算图像的补丁级异常分数 ,基于其补丁标记嵌入与每个个体异常提示嵌入(而不是异常提示嵌入的原型)的相似性,然后通过图 3 所示 t-SNE. 将每个样本的异常分数投影到一个二维空间中。在示例数据集上,可以得出两个关键的观察结果:i) 尽管有轻微的重叠,对于每个单独的异常提示,正常样本和异常样本分布在不同的组中,表明每个异常提示学习到不同的异常模式;ii) 正常样本和异常样本之间有明确的区分,用于每个异常提示的异常评分,表明在 FAPrompt 中学习的每个提示的良好区分能力。类似的模式可以在其他数据集中找到(见附录 C.3)。
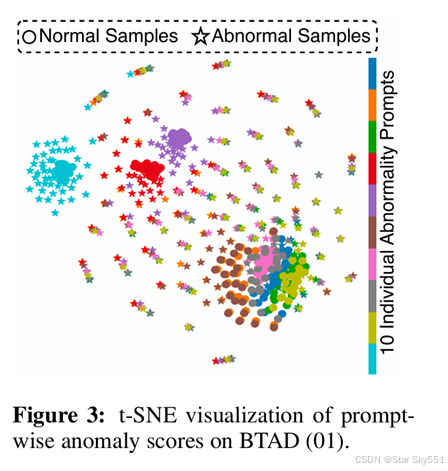
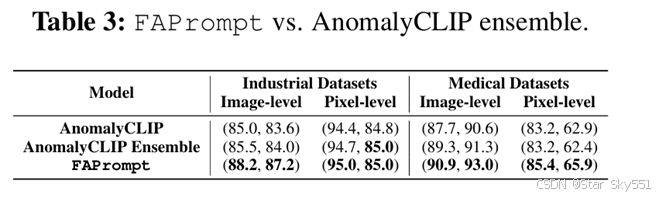
为了了解更多异常,一种简单的解决方案是通过使用 10 个异常提示的集合来学习多个异常提示,每个异常提示都由具有不同随机种子的辅助数据集上的 AnomalyCLIP 调优学习。我们认为,这种简单的策略导致了对高度冗余的异常提示的学习,而不是在 FAPrompt 中学习的互补提示。我们将 FAPrompt 与 表3 中的集成方法进行比较的结果证明了这一点。很明显,集成方法可以在一定程度上改善 AnomalyCLIP,但其异常提示在图像和像素级 ZSAD结果中都远不如 FAPrompt 有效,尽管在 FAPrompt 中没有使用集成策略。这展示了在 FAPrompt 中学到的异常提示在捕获细粒度异常细节方面的有效性。
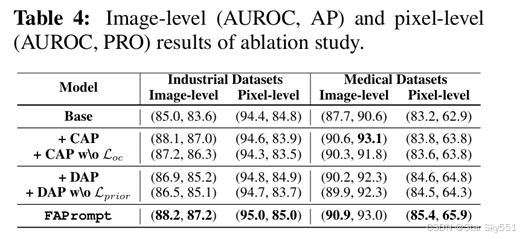
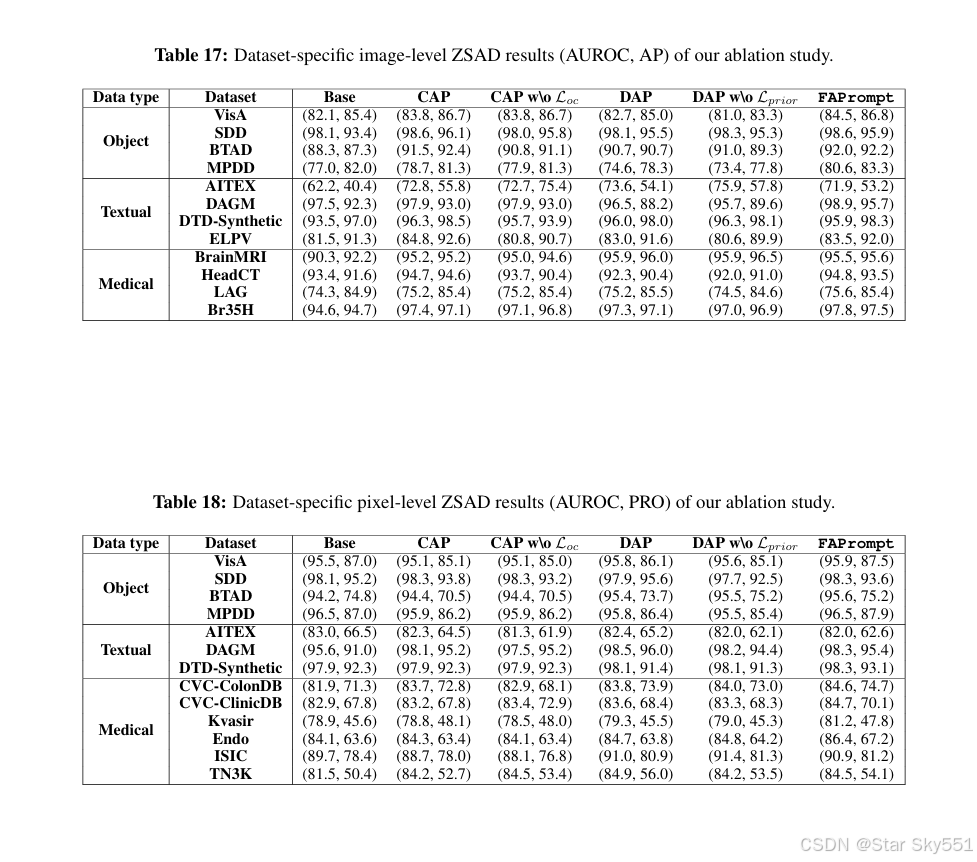
4.2 消融实验
模块消融:我们的消融研究结果基于 18 个工业和医学数据集的平均性能,如表 4 所示,其中 AnomalyCLIP 用作我们的基础模型(Base),我们的两个模块中的每一个都分别添加到该基础模型(即“+CAP”和“+DAP”)上。数据集方面的性能可以在附录 D.2 中找到。可以看出,单独应用 CAP 会导致图像级 ZSAD 性能的显著提高,因为在学习细粒度异常细节时是可托的。为了证明正交约束损失 () 在 CAP 中很重要,我们进一步评估了去除
的性能,表示为 '+CAP w\o
'。结果表明,
施加的正交约束有助于 CAP 模块以更有效的方式工作,证明了它在鼓励 CAP 中独特和互补的细粒度异常模式的学习方面的有效性。
如表 4 所示,当独立应用 DAP 时,它不仅会大幅提高图像级性能,还会大幅提高像素级性能。在医学数据集上,改进更加明显。结果显示,去除 可能会从正常样本中引入不相关的先验数据,并导致像素级性能显著下降。当应用所有组件时,完整模型 FAPrompt 将实现其最佳性能。这表明 CAP 和 DAP 之间的交互能够学习异常提示,这些异常提示可以捕获细粒度的语义并适应不同的测试数据集。
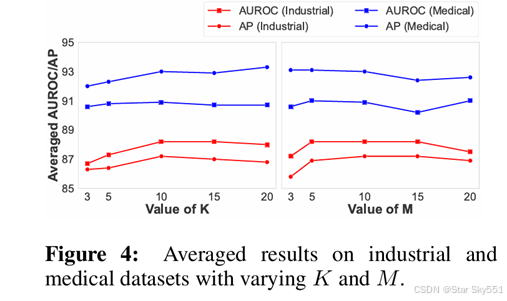
超参数敏感性分析:我们分析了图 4 中 FAPrompt 的两个关键超参数在图像级性能方面的敏感性,包括 CAP 中异常提示 K 的数量和 DAP 中选定的补丁标记 M 的数量(类似的结果可以在附录 C.4 中找到像素级结果)。特别是,性能会随着 K 的增加而提高,通常在 K=10 时达到峰值。当选择 K 超过 10 时,性能可能会略有下降。这表明,虽然增加提示的数量有助于捕获更广泛的异常,但过大的 K 值可能会在提示中引入噪声或冗余。对于选定的 Tokens 数量,M,表现表现出类似的模式,在中等值时表现最佳。这表明选择过多的异常补丁候选可能会将噪声或不太相关的补丁引入 CAP,从而导致学习效果较差的细粒度异常。
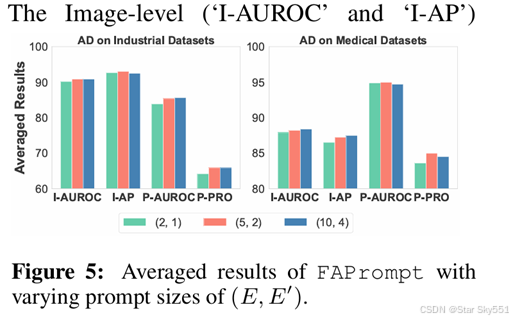
此外,我们还评估了 CAP 模块中可学习正常和异常标记 {E,E′} 长度的敏感性。像素级 ZSAD 结果如图 5 所示。总体而言,(5, 2) 设置最适合工业和医疗异常检测,从而产生强大的 ZSAD 性能。较长的提示长度,例如 (10,4),可以引入更多复杂性,而不会明显提高性能,尤其是在像素级性能方面。使用较短的提示长度,例如,设置 (2, 1),缺乏足够的容量来支持 ZSAD 任务,导致性能始终较弱。
五、结论
在本文中,我们提出了FAPrompt,一个新颖的框架通过学习自适应细粒度异常语义来增强CLIP在ZSAD中的性能。FAPrompt引入了一个复合异常提示 (CAP) 模块,可生成互补异常提示,而无需依赖详尽的人工注释。此外,它还包含一个数据依赖型异常先验 (DAP) 模块,该模块可以优化这些提示以改进跨数据集泛化。CAP 和 DAP 之间的交互使模型能够学习自适应细粒度异常语义。对 19 个数据集的广泛实验表明,FAPrompt 的性能明显优于最先进的 ZSAD 方法。
六、附录
A 数据集详情
A.1 训练和测试的数据统计
我们进行了广泛的实验19个真实世界异常检测(AD)数据集,包括9个工业缺陷检测数据集(MVTecAD(Bergmannet al.,2019)、VisA(Zouet al.,2022)、DAGM(Wieler&Hahn, 2007)、DTD-Synthetic (Aotaet al., 2023)、AITEX(Silvestre Blanesetal.,2019)、SDD(Taberniketal.,2020)、BTAD(Mishraetal.,2021)、MPDD(Jezeketal.,2021)、ELPV(Deitschetal.,2019))和tenmedicalanomalydetectiondatasets(BrainMRI(Salehi et al., 2021)、HeadCT(Salehi et al., 2021)、LAG(Li et al., 2021)2019a)、Br35H(Hamada)、CVC ColonDB(Tajbakhshetal.,2015)、CVC-ClinicDB(Bernaletal.,2015)、Kvasir(Jhaetal.,2020)、Endo(Hicksetal.,2021)、ISIC(Gutmanetal.,2016)、TN3K(Gongetal.,2021))。
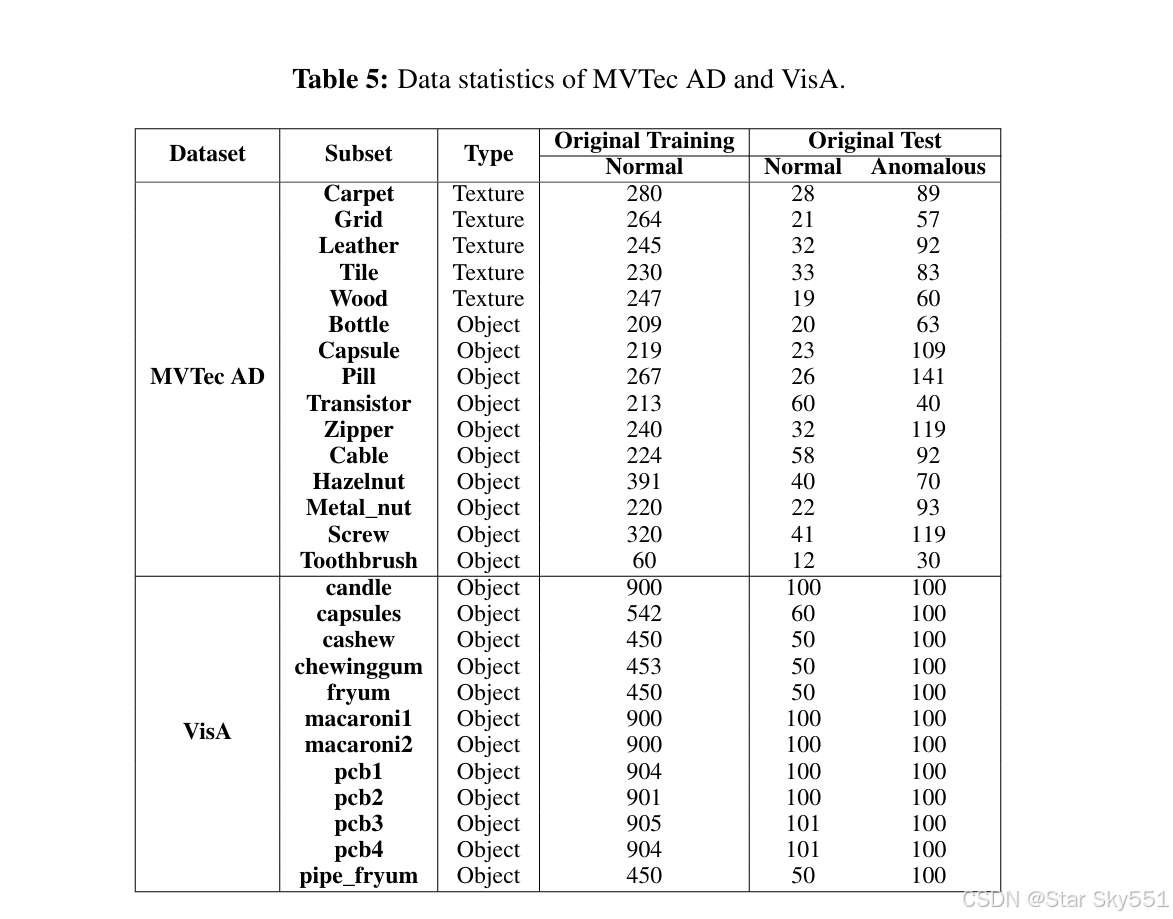
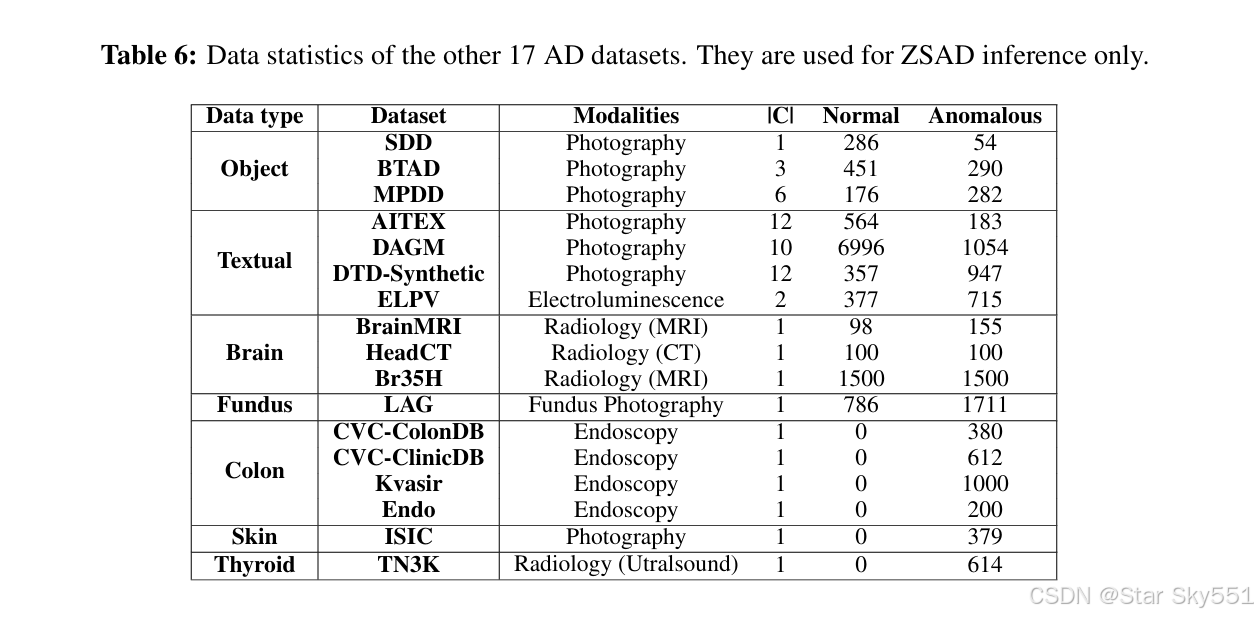
为了评估ZSAD性能,MVTecAD的完整数据集,包括训练集和测试集,被用作辅助训练数据,AD模型在其上进行训练,随后在其他18个数据集的测试集上进行评估,无需任何进一步的训练。我们在 VisA 的完整数据集上训练模型时评估 MVTecAD.Table5 提供了 MVTecAD和 VisA 的数据统计数据,而 Table6 显示了其他 17 个数据集的测试集统计数据。
B 实施细节
B.1 模型配置的详细信息。
以下前作(Dengetal.,2023;Chenetal.,2023a;Zhouetal.,2024),FAPrompt 采用 CLIP 的改进版本——OpenCLIP(Ilharcoetal.,2021)及其公开可用的预训练脊椎 VIT-L/14@336px——作为 VLMbackbone,在保留其原始结构的同时增强了模型对局部特征的关注。继 周 et al. (2024),在补丁特征提取过程中,我们从视觉编码器的第 6 层开始,将视觉编码器中原来的 Q-Kself-attention 机制替换为 V-Vself-attention 机制。CLIP 中视觉编码器和文本编码器的参数在整个实验过程中都被冻结。
受前人作品启发(Jiaetal.,2022;Zhouetal.,2024;Khattaketal.,2022 年),我们使用文本提示调优,通过在 CLIP 的文本编码器中添加额外的可学习词元嵌入来细化 CLIP 的原始文本空间.默认情况下,可学习的标记嵌入被附加到文本编码器的前 9 层以优化文本空间,每层的标记长度为 4。CAP 中可学习的 正常提示 和 异常 token 的长度分别设置为 5 和 2。DAP 中的细粒度异常提示数(K)和选定的补丁 Token(M) 均设置为 10。为了与VIT-L/14@336px的维度保持一致,将网络的异常配置为输入和输出维度分别为768×M和768,并包括一个大小为(768×M)/16的隐藏层,并激活了ReLU。
我们使用初始学习率为 1e-3 的 Adam 优化器来更新模型参数。输入图像的大小调整为 518×518,批量大小为 8。这种大小调整也适用于其他基线模型,以便进行公平比较,同时保留其原始数据预处理方法(如果适用)。在所有实验中,训练进行了 7 个 epoch。在推理阶段,应用 σ=10 的高斯滤波器来平滑异常分数图。所有实验均在单个 GPU (NVIDIAGeForceRTX3090) 上使用 PyTorch 进行。
B.2 实施比较方法
为了评估 FAPrompt 的效率,我们将其性能与八个最先进的 (SotA) 基线进行比较。CLIP(Ilharcoetal.,2021)、CLIP-AC(Ilharcoetal.,2021)、WinCLIP(Jeonget al.,2023)、APRIL-GAN(Chenet al.,2023a)、CoOp(Zhouet al.,2022b)和 AnomalyCLIP(Zhouet al.,2024)的结果均来自 AnomalyCLIP,除了新添加的数据集(SDD、AITEX、ELPV、LAG)。为了公平地比较,这些实现遵循 AnomalyCLIP 的设置,我们使用官方实现 AnoVL(Denget al., 2023)和 CoCoOp(Zhouetal.,2022a)。为了将 CoCoOp 适配到 ZSAD,我们将其可学习的文本提示模板替换为正常和异常文本提示模板,这与 CoOpin 现有的 ZSAD 研究的实现是一致的。所有其他参数与其原始论文中指定的参数保持一致。
C 附加结果
C.1 FAPROMPT 的模型复杂性 VS.最先进方法的复杂性
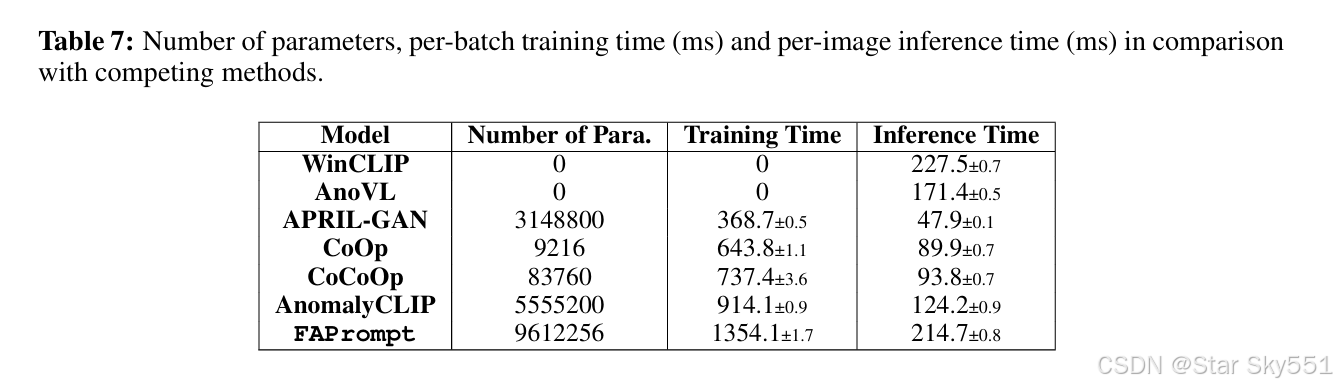
我们将 FAPrompt 的模型复杂性与 Table7 中的 最先进的方法进行了比较,评估了参数的数量、每批训练时间和每张图像的推理时间。为了公平比较,所有方法的批量大小都设置为 8,不包括无训练方法 WinCLIP 和 AnoVL.虽然 FAPrompt 引入了额外的可训练参数,导致训练时间略长,但与竞争方法相比,这种较小的计算开销导致性能大幅提高。此外,由于训练是离线执行的,因此在实际应用程序中,这种训练计算开销通常可以忽略不计。在推理时间方面,我们的方法仍然合理高效且响应迅速。
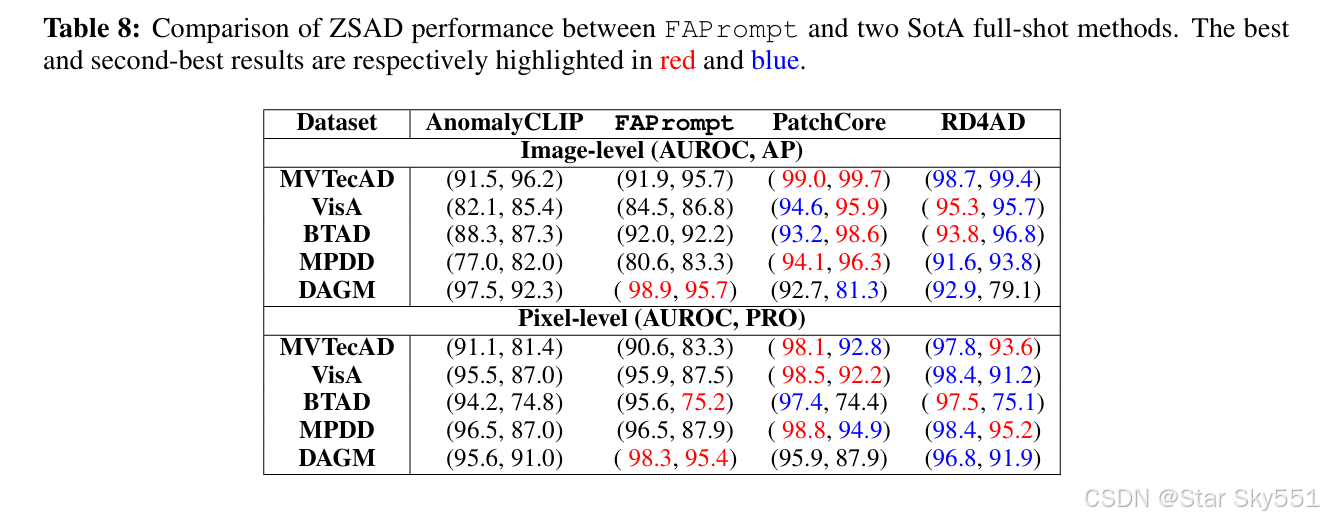
C.2 与最先进的全样本方法比较
我们还对五个最常用的数据集进行了实验,以检查 FAPromptt 和两种 SotA 全样本方法之间的性能差距,即 PatchCore(Rothet al.,2022)和 RD4AD(邓和李,2022)。请注意,这与 PatchCore 和 RD4AD利用每个测试数据集初始化检测的完整训练数据,而像 FAPrompt 这样的 ZSAD 方法使用任何此类训练数据并不公平。尽管 PatchCore 和 RD4AD 中特定于数据集的训练数据利用不公平,但 FAPrompt 获得了令人印象深刻的检测性能,进一步缩小了 ZSAD 和全样本方法之间的性能差距。
C.3 T-SNE可视化提示级异常分数
为了探索 FAPrompt 中异常提示的互补性,我们可视化了 VisA 数据集中不同类别的异常评分映射 的二维 t-SNE 结果。图 6 显示了来自 VisA 的另外三个数据集上的此类结果,以证实我们基于图 3 讨论的分析。
C.4 超参数敏感性分析
在图 7 中,我们展示了 CAP 中异常提示的数量 (K) 和 DAP 中选定的补丁标记 (M) 数量的灵敏度的像素级结果。结果的趋势与图 4 中所示的图像级性能一致。
C.5 定性结果的FAPROMPT
我们将 FAPrompt 生成的异常图与其他 ZSAD 模型跨各种数据集生成的异常图进行了比较,如图 8.APRIL-GAN和异常 CLIP分别被选为手工制作和可学习文本提示竞争对手的代表。可视化结果表明,与其他两种方法相比,FAPrompt 在工业和医疗领域的分割明显更准确。特别是,尽管没有从医疗数据中获取任何附加信息或培训,但 FAPrompt 有效地定位异常病变/肿瘤区域,突出了FAPrompt 学习的细粒度异常语义的跨数据集泛化优越性。
我们还提供了额外的像素级异常分数映射在多样化数据集上,以进一步展示 FAPromptin 的强大分割能力图 9至18.具体来说,对于工业 AD 数据集,我们选择了三个对象类别(VisA 中的胶囊、pipe_fryum 和 MPDD 中的 metal_plate)和三个纹理类别(MVTecAD 和 AITEX 中的网格、瓦片)进行可视化。对于医疗 AD 数据集,我们将大脑、结肠、皮肤和甲状腺异常的像素级异常检测性能可视化。
C.6 失败案例和局限性
虽然提议的 FAPrompt 在没有任何特定于数据集的参考文献的情况下展示了各种类别的有希望的检测结果,但在某些情况下它可能会失败。图 19 说明了其中一些失败的情况。某些情况可归因于注释错误。例如,包含多种类型的异常但仅部分标记的图像可能会因标记不一致而导致分割错误,如图 中的污点缺陷所示。19(1).此外,一些医学数据集中的仪器伪影经常被误解为异常,导致检测错误,例如,图 19(2)。在其他情况下,FAPrompt 可能会在如图 19(3)-(6) 所示的异常情况下失败,其中异常区域可能太小、太微妙或被其他可疑区域所掩盖(根据 FAPrompt 的解释)。然而,如图 9 至图 18 所示,FAPrompt 始终致力于识别最可能的异常区域,而不依赖目标数据集的任何参考。展望未来,结合更多的先验知识,例如,来自上下文示例、知识图谱或大型语言模型 (LLM),将有助于提供更多判别性信息,以实现更准确的异常检测。
D 详细的实证结果
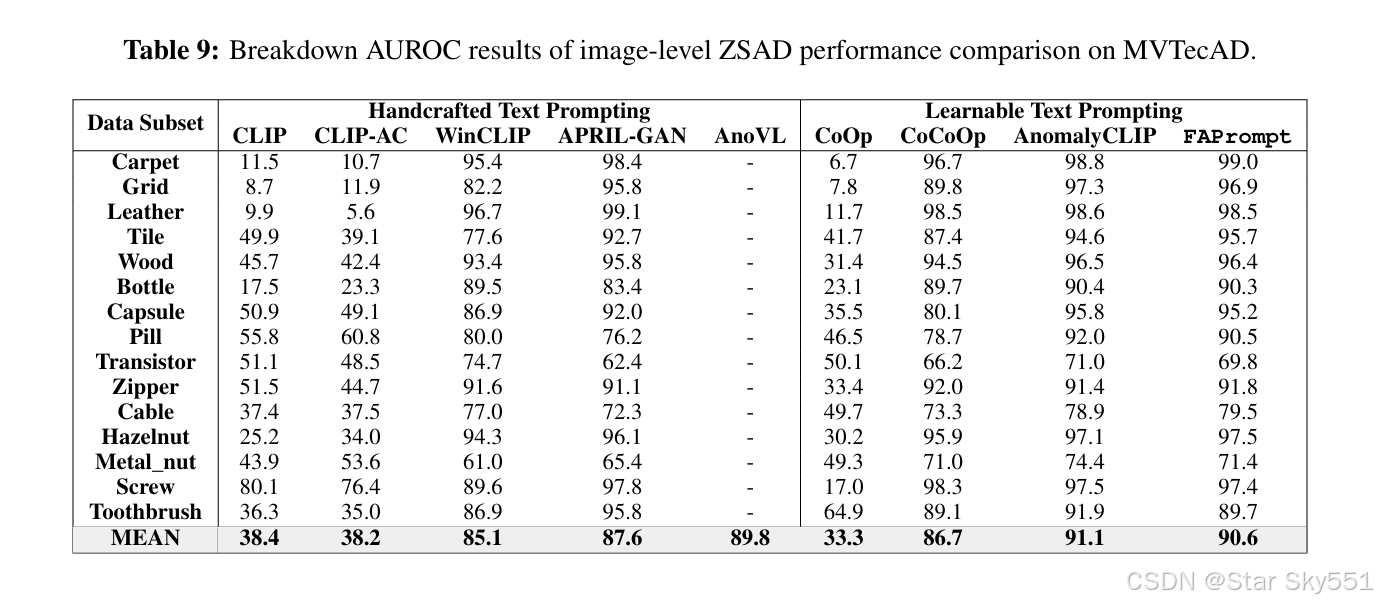
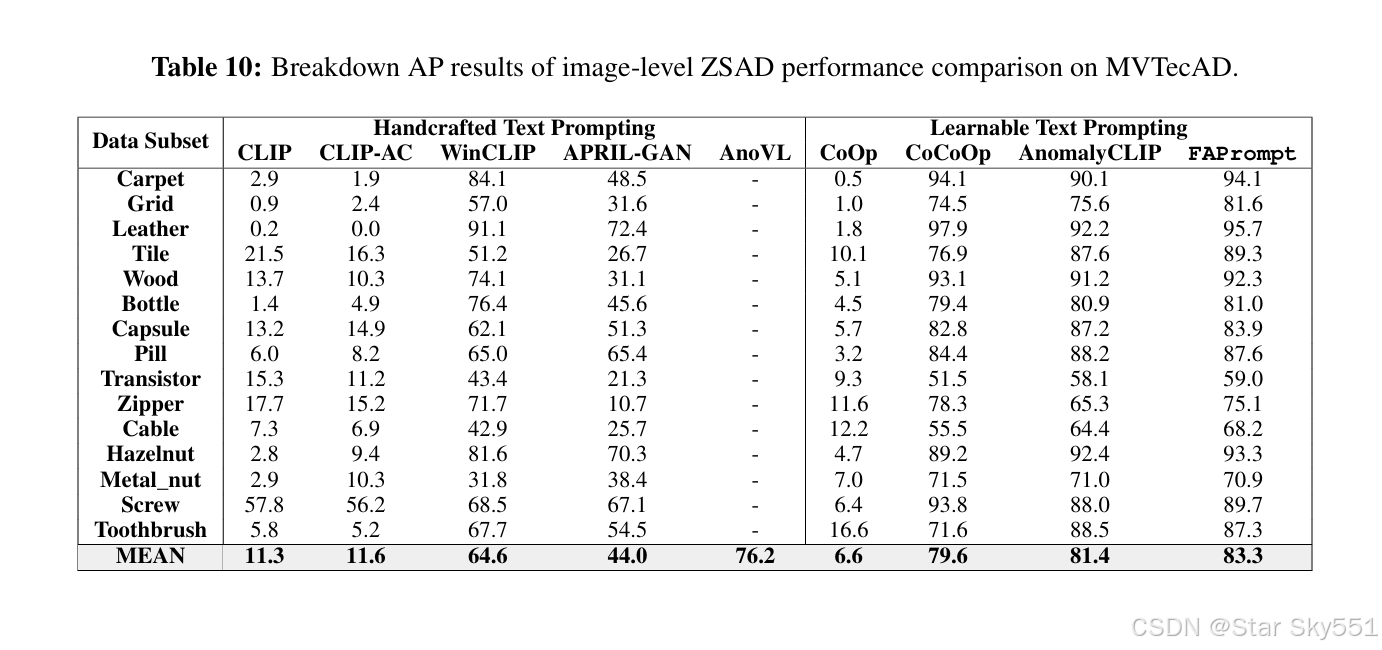
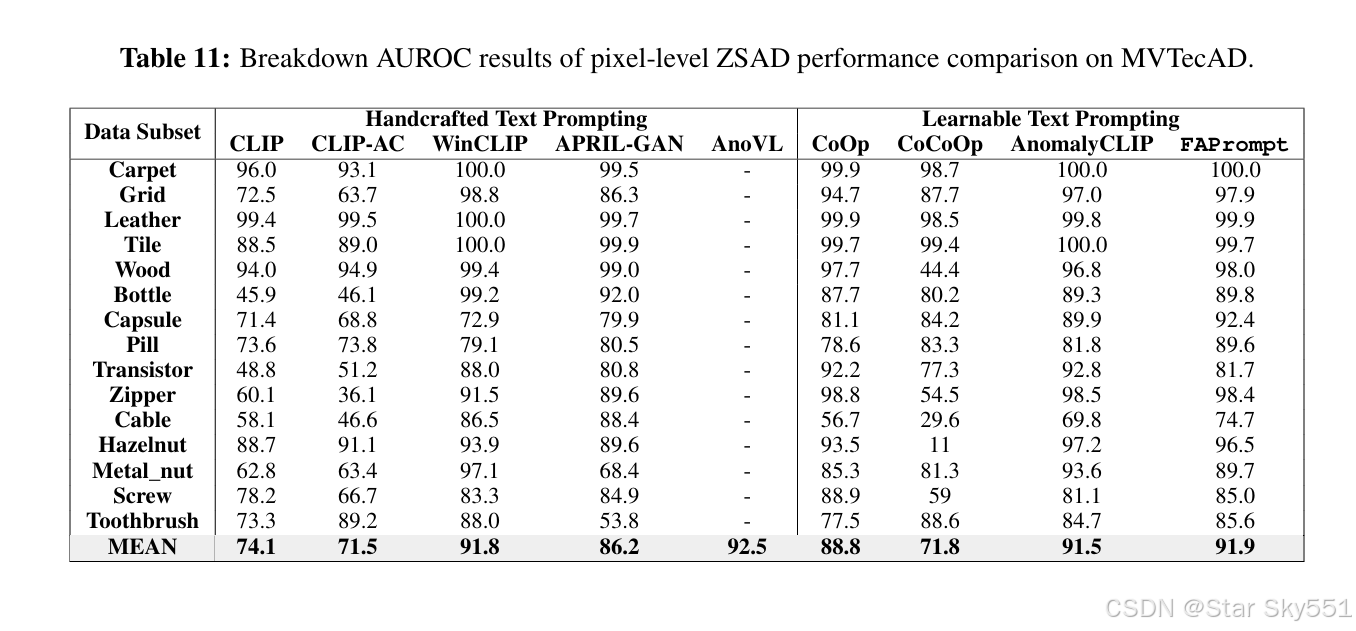
D.1 VISA 和 MVTECAD 的细分结果
表 9 到 16 详细记录了 FAPrompt 对 MVTecAD 和 VisA 数据集每个类别中的八种 最先进方法的 ZSAD 结果。
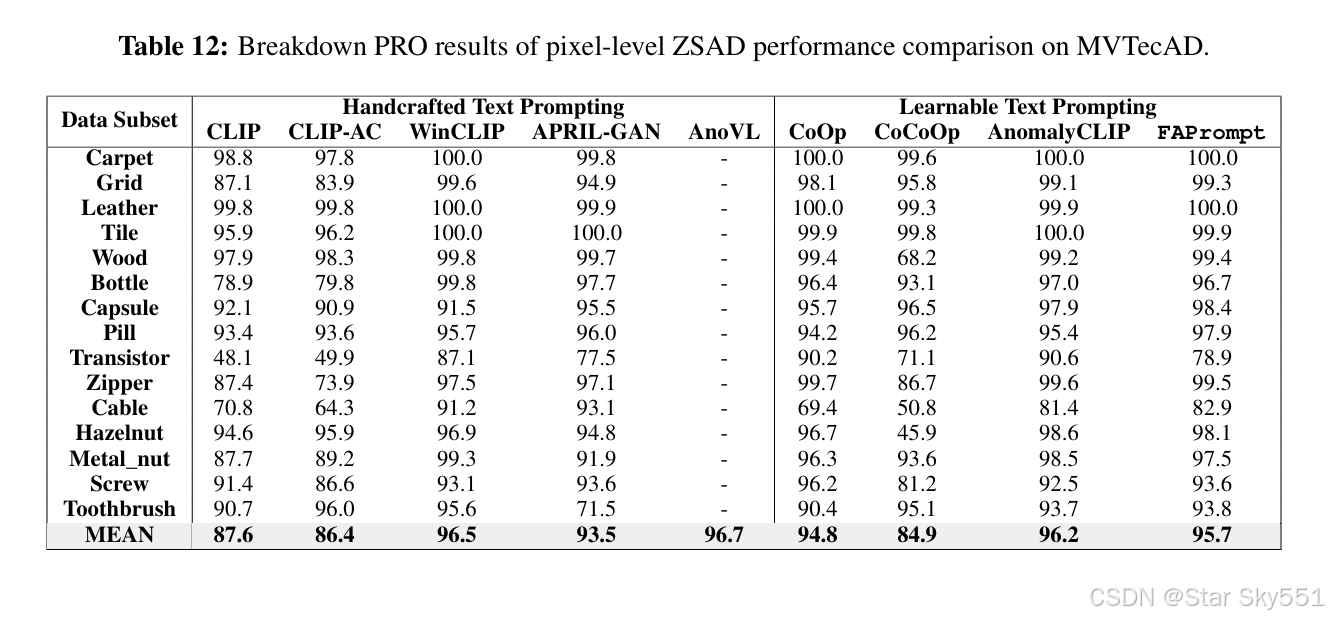
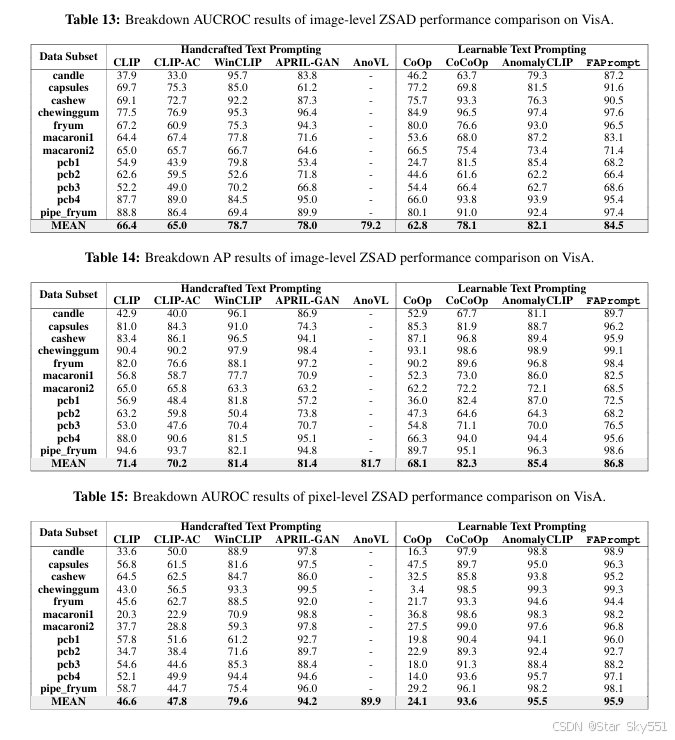
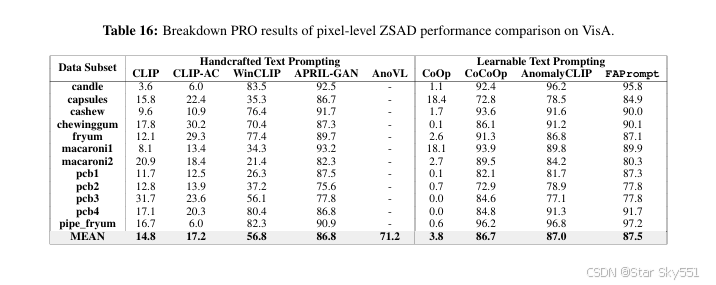
D.2 特定数据集的结果消融研究
在本节中,我们分别介绍了 Table17 和 Table18 中模块消融的数据集特定图像级和像素级 ZSAD 结果。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)