图像预处理
今天继续说openCV中的基础操作目录一、图像翻转(图像镜像旋转):cv2.flip(img,flipcode)二、图像仿射变换:cv2.warpAffine(img,M,dsize)(一)参数(二)仿射变换的基本性质(三)仿射变换的基本原理(四)常见仿射变换的类型三、插值方法(一)最近邻插值:CV2.INTER_NEAREST(二)双线性插值:CV2.INTER_LINEAR(三)像素区域插值:
前言:
今天继续说openCV中的基础操作
目录
一、图像翻转(图像镜像旋转):cv2.flip(img,flipcode)
二、图像仿射变换:cv2.warpAffine(img,M,dsize)
(一)参数
(二)仿射变换的基本性质
(三)仿射变换的基本原理
(四)常见仿射变换的类型
三、插值方法
(一)最近邻插值:CV2.INTER_NEAREST
(二)双线性插值:CV2.INTER_LINEAR
(三)像素区域插值:cv2.INTER_AREA
(四)双三次插值:cv2.INTER_CUBIC
(五)Lanczos插值:cv2.INTER_LANCZOS4
四、边缘填充
(一)边界复制(BORDER_REPLICATE)
(二)边界反射(BORDER_REFLECT)
(三)边界常数(BORDER_CONSTANT)
(四)边界包裹(BORDER_WRAP)
五、图像矫正(透视变换)
六、图像色彩空间转换
(一)RGB颜色空间
(二)颜色加法
(三)颜色加权法:cv2.addWeighted(src1,alpha,src2,deta,gamma)
(四)RGB转Gray(灰度)、RGB转HSV :cv2.cvtColor(img,code)
七、灰度实验
(二)最大值法
(三)平均值
(四)加权均值法
(五)两个极端的灰度值
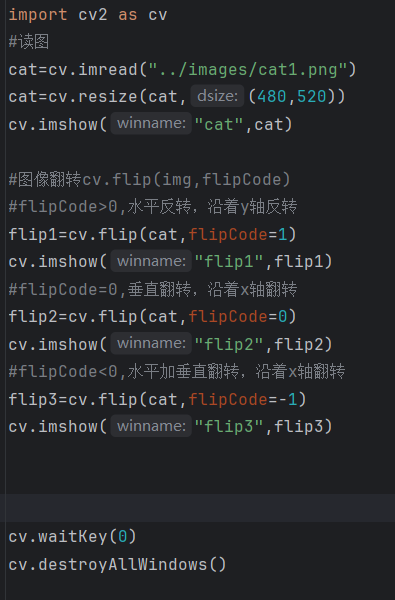
一、图像翻转(图像镜像旋转):cv2.flip(img,flipcode)
在openCV中,图片的镜像旋转是以图像的中心为原点进行镜像翻转的。
(一)参数
img:要翻转的对象
flipcode:指定翻转类型的标志
flipcode=0: 垂直翻转,图片像素点沿x轴翻转
flipcode>0: 水平翻转,图片像素点沿y轴翻转
flipcode<0: 水平垂直翻转,水平翻转和垂直翻转的结合
案例:

二、图像仿射变换:cv2.warpAffine(img,M,dsize)
仿射变换(Affine Transformation)是一种线性变换,保持了点之间的相对距离不变
(一)参数
img:输入图像
M:2x3的变换矩阵,类型为np.float32
dize:输出图像的尺寸,形式为(windth,height)
(二)仿射变换的基本性质
保持直线
保持平行
比例不变性
不保持角度和长度
(三)仿射变换的基本原理
线性变换:
仿射的目标是在二维空间中讲图像坐标的点映射到新的位置,通常使用矩阵乘法的形式:
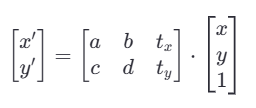
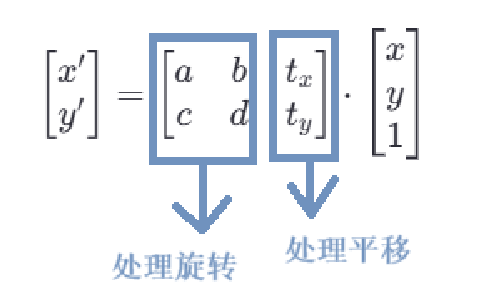
其中a,b,c,d是线性变换部分的系数,控制旋转旋转、缩放和剪切,t_x,t_y是平移部分的系数,控制图像在平面上运动
(四)常见仿射变换的类型
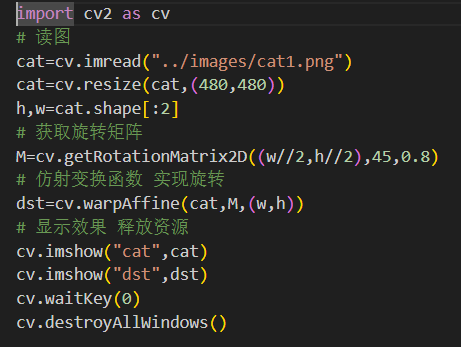
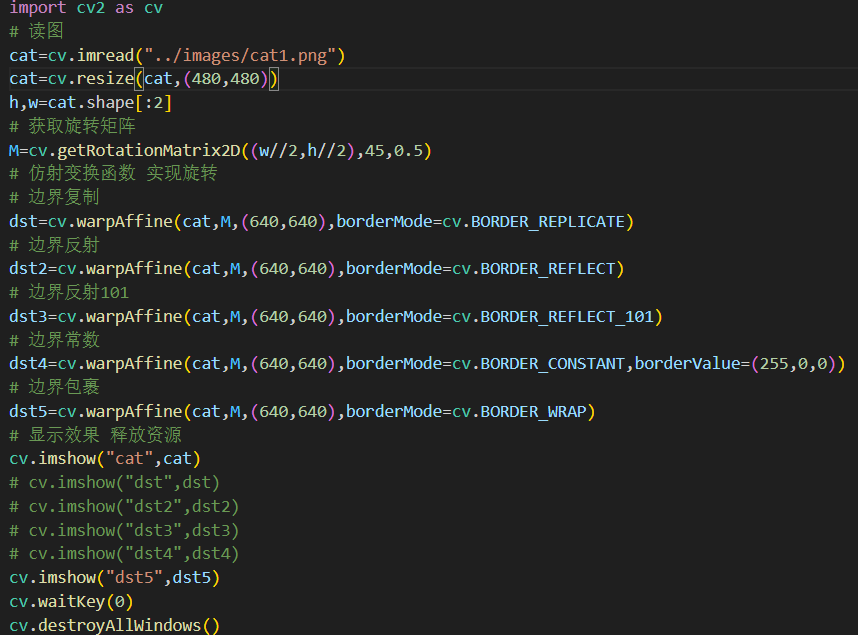
1、旋转:绕着某个点或轴旋转一定角度:cv2.getRotationMatrix2D(center,angle,scale)
center:旋转中心点的坐标,格式为
(x,y)
angle:旋转角度,单位为度,正值表示逆时针旋转负值表示顺时针旋转。
scale:缩放比例,若设为1,则不缩放。
返回值:M,2x3的旋转矩阵
案例
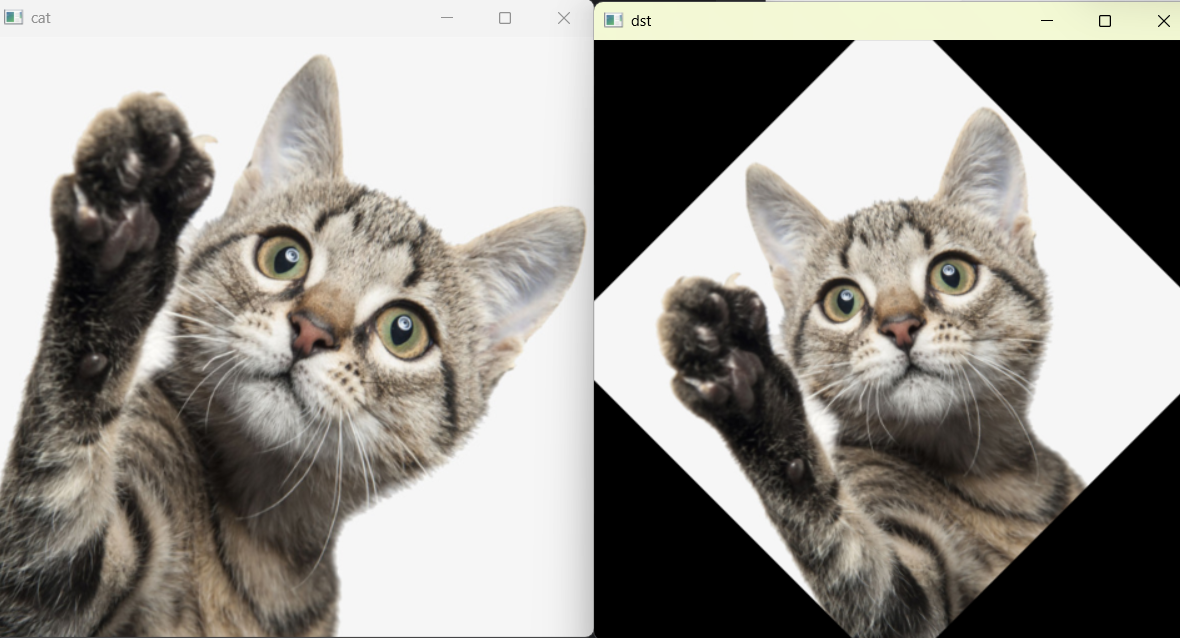
2、平移:仅改变物体的位置,不改变其形状和大小:
在矩阵形式下:
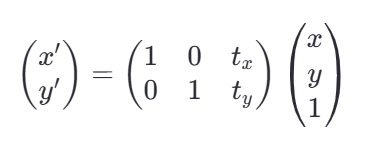
案例:
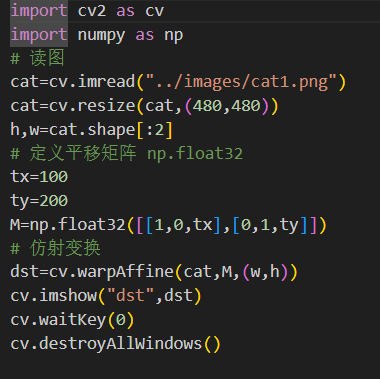

3、 缩放:改变物体的大小:
假设要把图像的宽高分别缩放为0.5和0.8,那么对应的缩放因子sx=0.5,sy=0.8。
在矩阵形式下表示为:
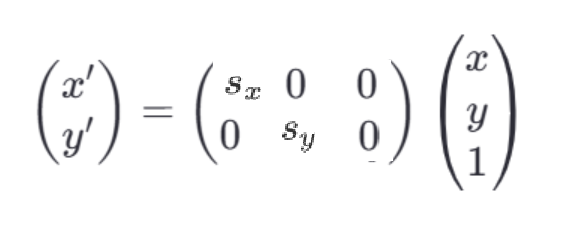
相较于图像旋转中只能等比例的缩放,图像缩放更加灵活,可以在指定方向上进行缩放。
案例:
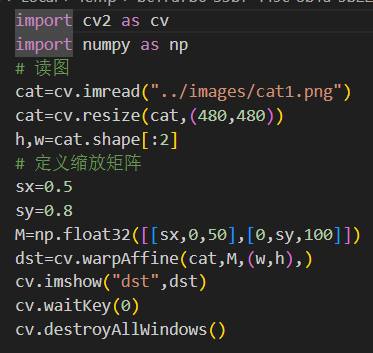

4、剪切:使物体发生倾斜变形,以便其在某个方向上倾斜,它将对象的形状改变为斜边平行四边形,而不改变其面积。
在矩阵形式下表示为:shy和shx分别对应沿x轴和y轴方向上的剪切因子。
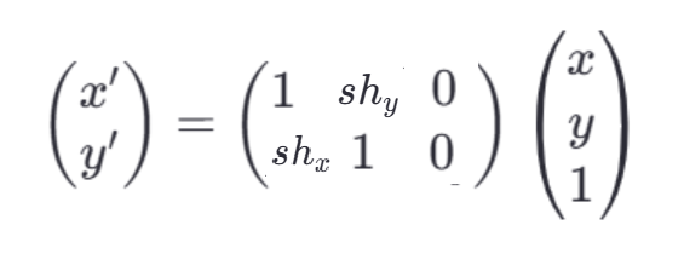
理解:
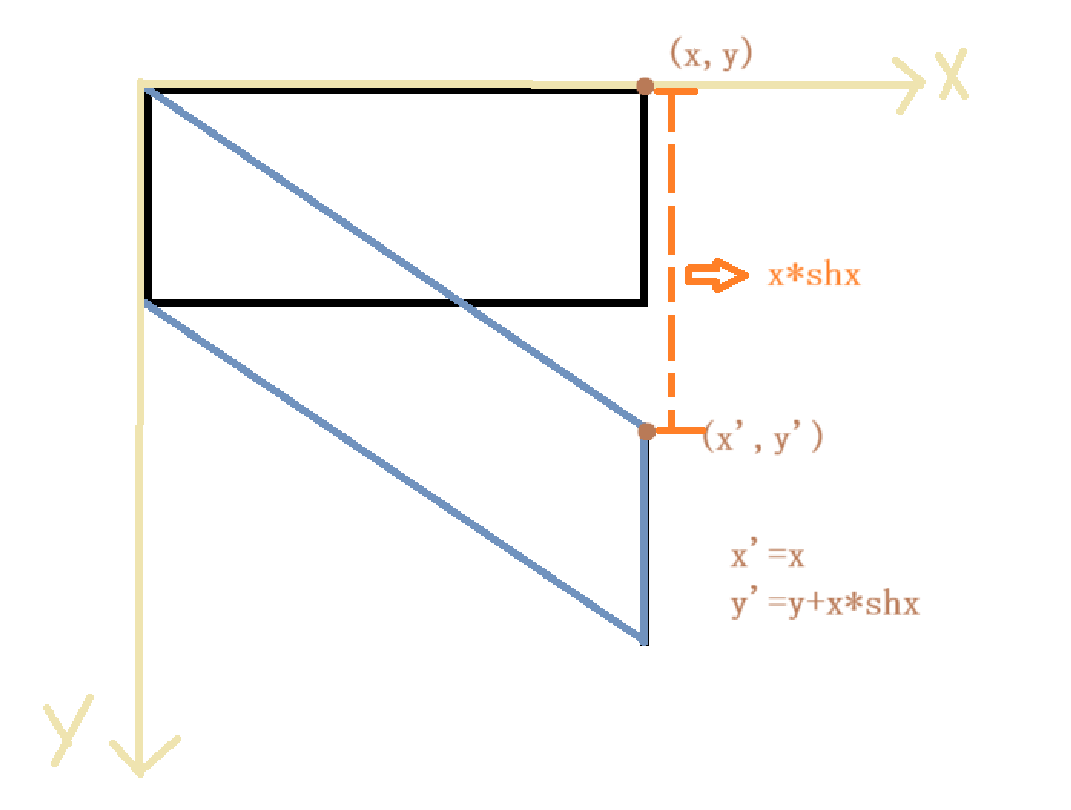
案例:

三、插值方法
在图像处理和计算机图形学中,插值(Interpolation)是一种通过已知数据点之间的推断或估计来获取新数据点的方法。它在图像处理中常用于处理图像的放大、缩小、旋转、变形等操作,以及处理图像中的像素值。
图像插值算法是为了解决图像缩放或者旋转等操作时,由于像素之间的间隔不一致而导致的信息丢失和图像质量下降的问题。当我们对图像进行缩放或旋转等操作时,需要在新的像素位置上计算出对应的像素值,而插值算法的作用就是根据已知的像素值来推测未知位置的像素值。
(一)最近邻插值:CV2.INTER_NEAREST
new_img1=cv.warpAffine(img,M,(w,h),flags=cv.INTER_NEAREST)
最近邻插值是最简单的插值方法,它将新的像素值设置为距离它最近的已知像素的值。
可能造成图像的块状效果,过度不自然。
目标点与原图像点之间的计算公式:(后面都沿用此公式)
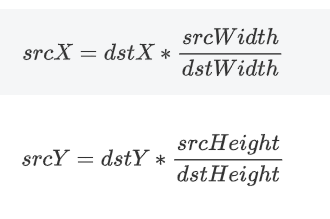
其中:dstX:目标图像中某点的x坐标,
dstY:目标图像中某点的y坐标,
srcWidth:原图的宽度,
dstWidth:目标图像的宽度;
srcHeight:原图的高度,
dstHeight:目标图像的高度。
srcX和srcY:目标图像中的某点对应的原图中的点的x和y的坐标。
(二)双线性插值:CV2.INTER_LINEAR
双线性插值是一种图像缩放、旋转或平移时进行像素值估计的插值方法。当需要对图像进行变换时,特别是尺寸变化时,原始图像的某些像素坐标可能不再是新图像中的整数位置,这时就需要使用插值算法来确定这些非整数坐标的像素值。
我们以一个例子来说明:
根据缩放比例计算出新图像中的某点所对应的原图像的点P,其周围的点分别为Q12、Q22、Q11、Q21, 要插值的P点不在其周围点的连线上,这时候就需要用到双线性插值了。首先延申P点得到P和Q11、Q21的交点R1与P和Q12、Q22的交点R2,如下图所示:
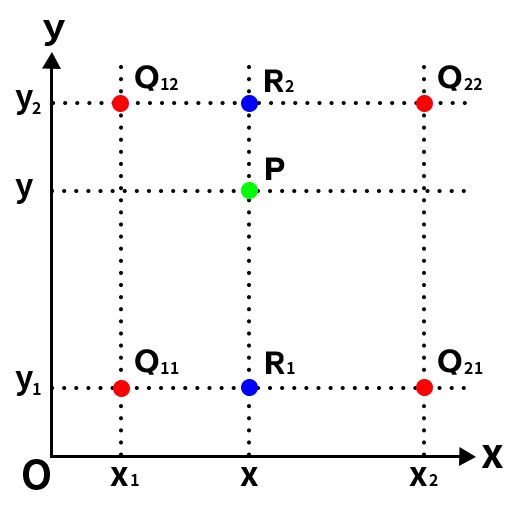
然后根据Q11、Q21得到R1的插值,根据Q12、Q22得到R2的插值,然后根据R1、R2得到P的插值即可,这就是双线性插值。以下是计算过程:
首先计算R1和R2的插值:
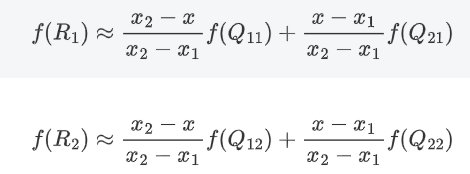
然后根据R1和R2计算P的插值 :
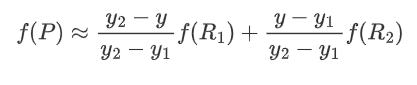
这样就得到了P点的插值。如果先在y方向插值、再在x方向插值,其结果与按照上述顺序双线性插值的结果是一样的。
(三)像素区域插值:cv2.INTER_AREA
像素区域插值主要分两种情况,缩小图像和放大图像的工作原理并不相同。
-
当使用像素区域插值方法进行缩小图像时,它就会变成一个均值滤波器,其工作原理可以理解为对一个区域内的像素值取平均值。
-
当使用像素区域插值方法进行放大图像时
-
如果图像放大的比例是整数倍,那么其工作原理与最近邻插值类似;
-
如果放大的比例不是整数倍,那么就会调用双线性插值进行放大。
-
(四)双三次插值:cv2.INTER_CUBIC
与双线性插值法相同,该方法也是通过映射,在映射点的邻域内通过加权来得到放大图像中的像素值。不同的是,双三次插值法需要原图像中近邻的16个点来加权,也就是4x4的网格。
(五)Lanczos插值:cv2.INTER_LANCZOS4
Lanczos插值方法与双三次插值的思想是一样的,不同的就是其需要的原图像周围的像素点的范围变成了8*8,并且不再使用BiCubic函数来计算权重,而是换了一个公式计算权重。
插值案例:
四、边缘填充
为什么要填充边缘呢? 图像在旋转之后原图的部分已经看不到了,新的图像中的部分区域其实是什么都没有的,因此我们需要对空出来的区域进行一个填充。除此之外,后续的一些图像处理方式也会用到边缘填充,这里介绍五个常用的边缘填充方法。
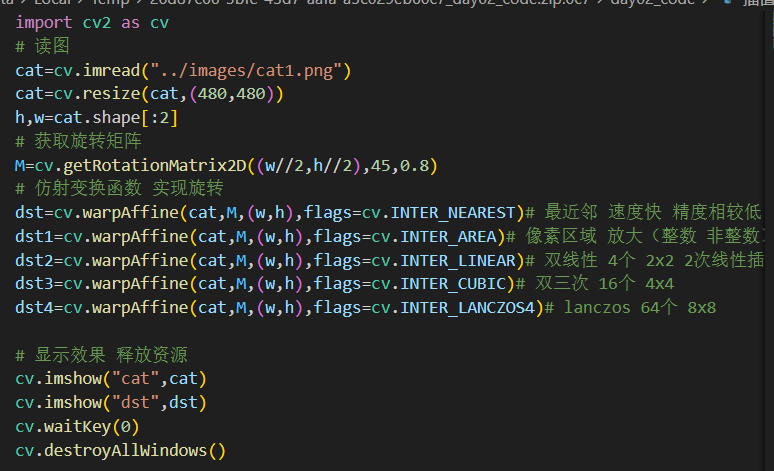
(一)边界复制(BORDER_REPLICATE)
边界复制会将边界处的像素值进行复制,然后作为边界填充的像素值,如下图所示,可以看到四周的像素值都一样。
new_img=cv.warpAffine(img,M,(w,h),cv.INTER_LANCZOS4,borderMode=cv.BORDER_REPLICATE)
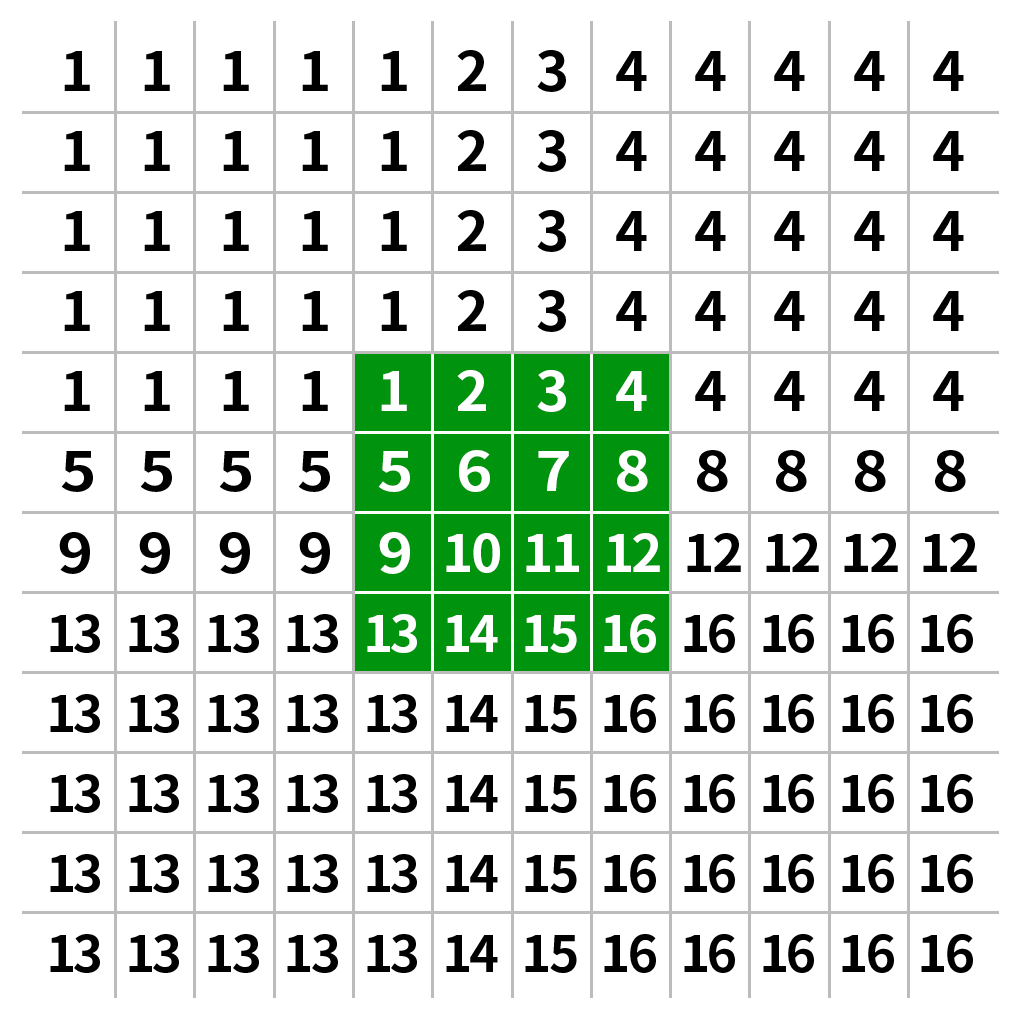
(二)边界反射(BORDER_REFLECT)
与边界反射不同的是,不再反射边缘的像素点,如下图所示:
new_img=cv.warpAffine(img,M,(w,h),cv.INTER_LANCZOS4,borderMode=cv.BORDER_REFLECT_101)
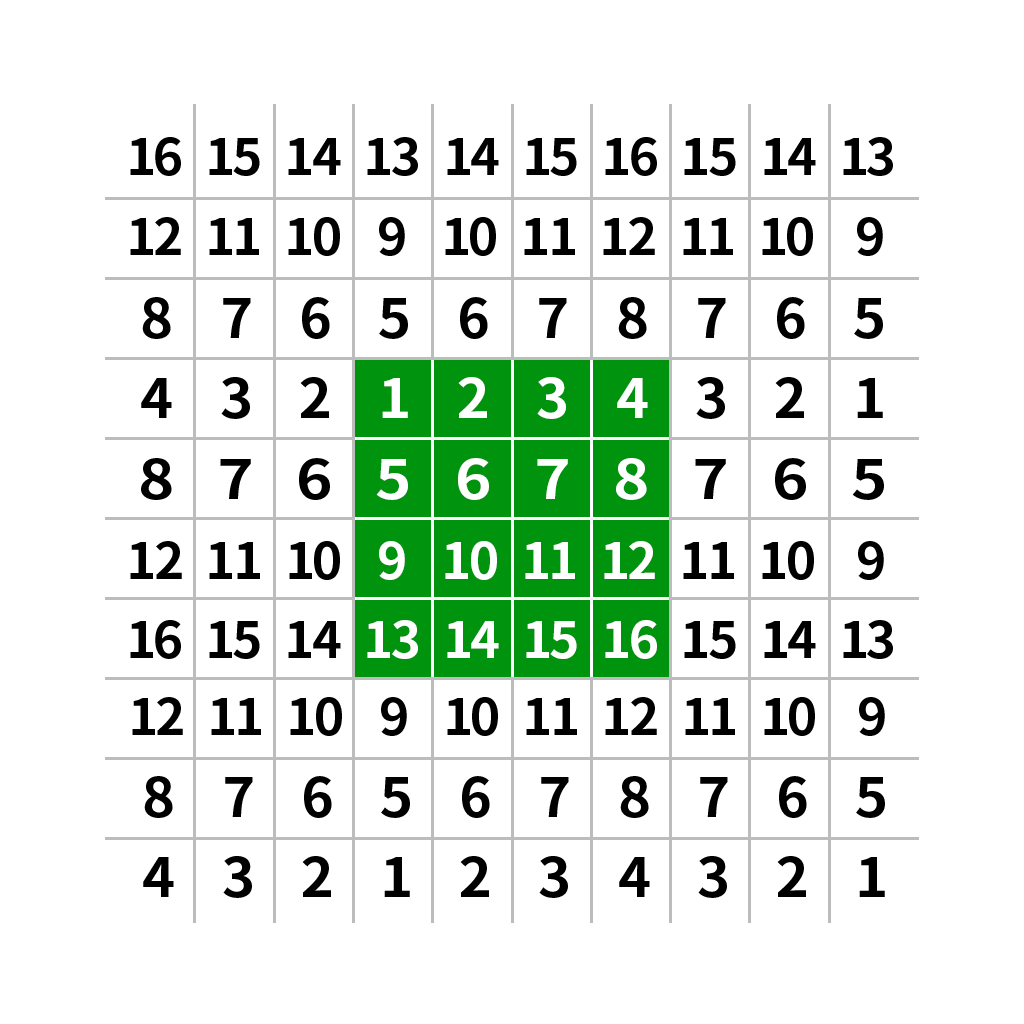
(三)边界常数(BORDER_CONSTANT)
当选择边界常数时,还要指定常数值是多少,默认的填充常数值为0,如下图所示。
new_img=cv.warpAffine(img,M,(w,h),cv.INTER_LANCZOS4,borderMode=cv.BORDER_CONSTANT,borderValue=(0,0,255))
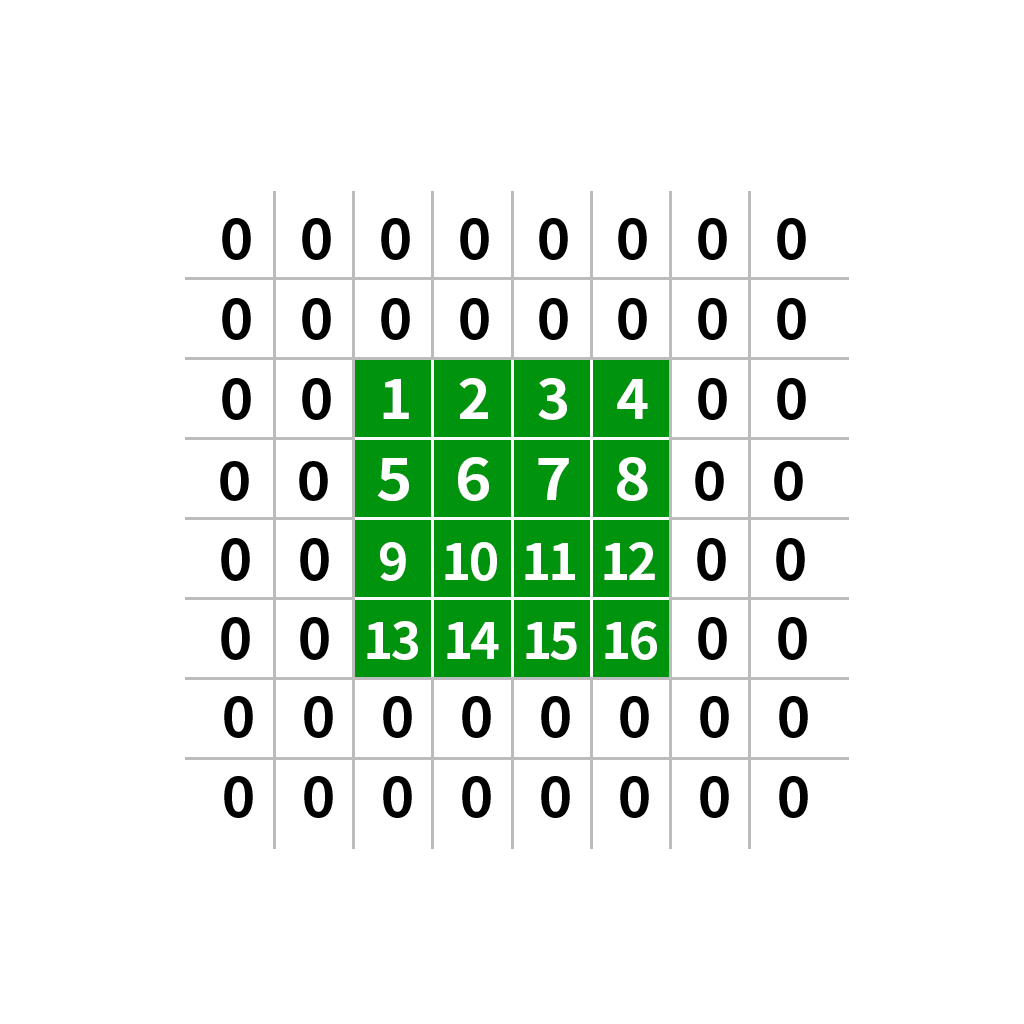
(四)边界包裹(BORDER_WRAP)
new_img=cv.warpAffine(img,M,(w,h),cv.INTER_LANCZOS4,borderMode=cv.BORDER_WRAP)
填充案例:
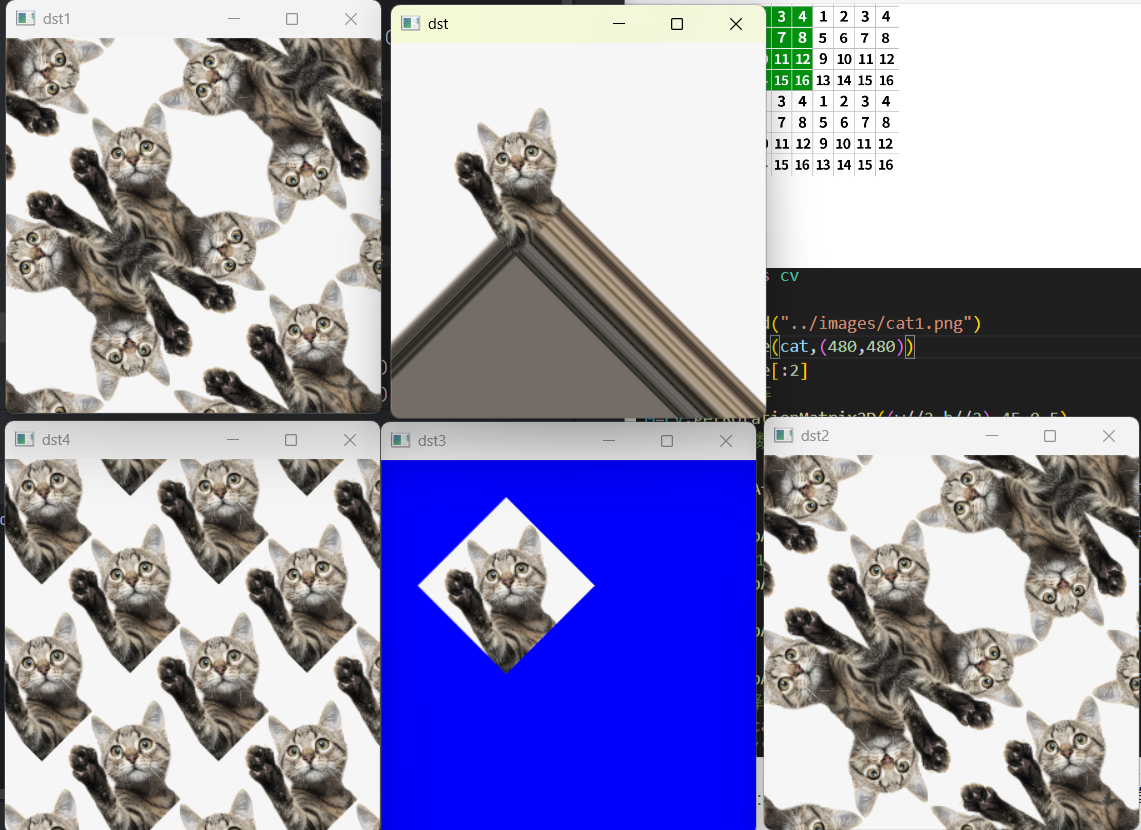
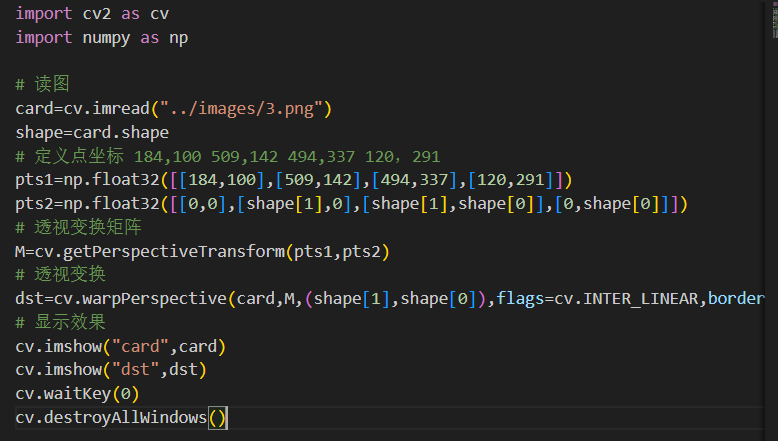
五、图像矫正(透视变换)
透视变换是把一个图像投影到一个新的视平面的过程,在现实世界中,我们观察到的物体在视觉上会受到透视效果的影响,即远处的物体看起来会比近处的物体小。透视投影是指将三维空间中的物体投影到二维平面上的过程,这个过程会导致物体在图像中出现形变和透视畸变。透视变换可以通过数学模型来校正这种透视畸变,使得图像中的物体看起来更符合我们的直观感受。通俗的讲,透视变换的作用其实就是改变一下图像里的目标物体的被观察的视角。
假设我们有一个点 (x,y,z)在三维空间中,并且我们想要将其投影到二维平面上。我们可以先将其转换为齐次坐标,(x,y,z),然后进行透视投影,得到了经过透视投影后的二维坐标(x′,y′)。通过将 X和Y 分别除以Z,我们可以模拟出真实的透视效果。
透视变换矩阵:
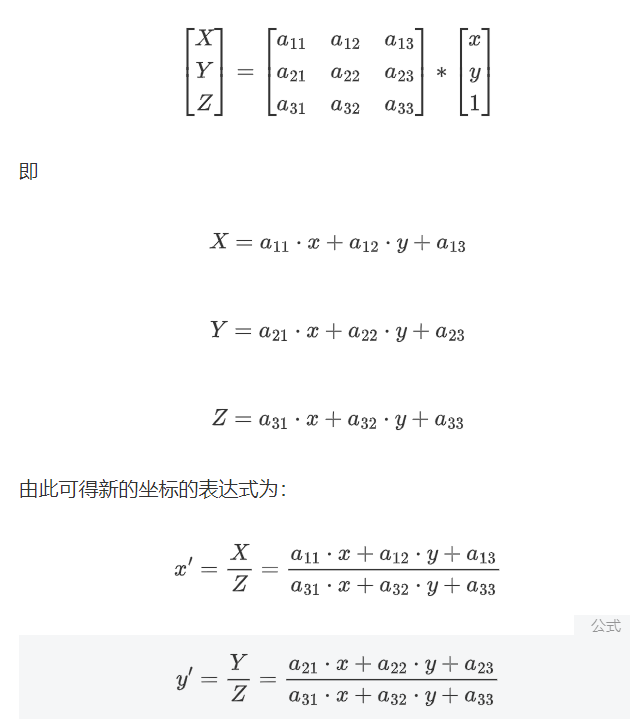
其中x、y是原始图像点的坐标,x'、y'是变换后的坐标,a11,a12,…,a33则是一些旋转量和平移量
-
M=getPerspectiveTransform(src,dst)
在该函数中,需要提供两个参数:
src:原图像上需要进行透视变化的四个点的坐标,这四个点用于定义一个原图中的四边形区域。
dst:透视变换后,src的四个点在新目标图像的四个新坐标。
该函数会返回一个透视变换矩阵,得到透视变化矩阵之后,使用warpPerspective()函数即可进行透视变化计算,并得到新的图像。该函
数需要提供如下参数:cv2.warpPerspective(src, M, dsize, flags, borderMode)
src:输入图像。
M:透视变换矩阵。这个矩阵可以通过getPerspectiveTransform函数计算得到。
dsize:输出图像的大小。它可以是一个Size对象,也可以是一个二元组。
flags:插值方法的标记。
borderMode:边界填充的模式。
# 原图中卡片的四个角点:左上、右上、左下、右下
[[178, 100], [487, 134], [124, 267], [473, 308]]
案例:
六、图像色彩空间转换
OpenCV中,图像色彩空间转换是一个非常基础且重要的操作,就是将图像从一种颜色表示形式转换为另一种表示形式的过程。通过将图像从一个色彩空间转换到另一个色彩空间,可以更好地进行特定类型的图像处理和分析任务。常见的颜色空间包括RGB、HSV、YUV等。
- 色彩空间转换的作用
-
节省计算资源
-
提高图像处理效果
-
(一)RGB颜色空间
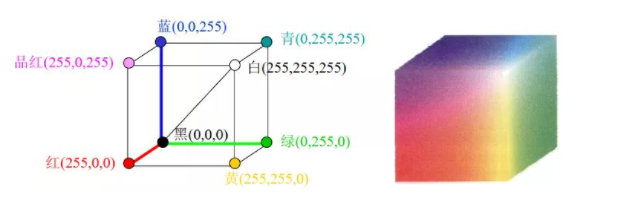
在图像处理中,最常见的就是RGB颜色空间。RGB颜色空间是我们接触最多的颜色空间,是一种用于表示和显示彩色图像的一种颜色模型。RGB代表红色(Red)、绿色(Green)和蓝色(Blue),这三种颜色通过不同强度的光的组合来创建其他颜色,广泛应用于我们的生活中,比如电视、电脑显示屏以及上面实验中所介绍的RGB彩色图。
RGB颜色模型基于笛卡尔坐标系,如下图所示,RGB原色值位于3个角上,二次色青色、红色和黄色位于另外三个角上,黑色位于原点处,白色位于离原点最远的角上。因为黑色在RGB三通道中表现为(0,0,0),所以映射到这里就是原点;而白色是(255,255,255),所以映射到这里就是三个坐标为最大值的点。
(二)颜色加法
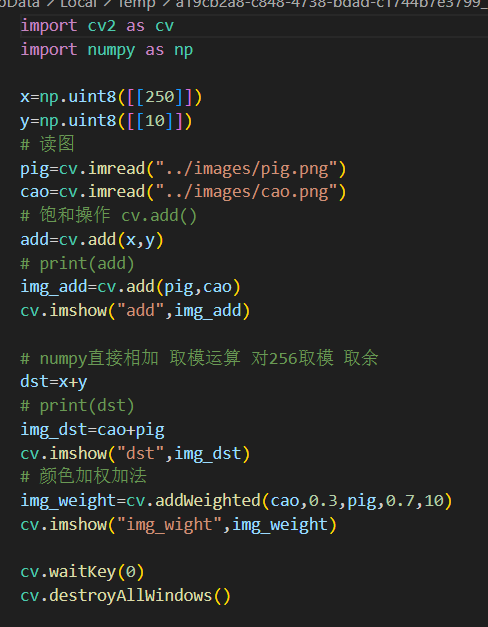
可以使用OpenCV的cv.add()函数把两幅图像相加,或者可以简单地通过numpy操作添加两个图像,如res = img1 + img2。两个图像应该具有相同的大小和类型。
OpenCV加法和Numpy加法之间存在差异。OpenCV的加法是饱和操作,而Numpy添加是模运算。
(三)颜色加权法:cv2.addWeighted(src1,alpha,src2,deta,gamma)
-
src1、src2:输入图像。 -
alpha、beta:两张图象权重。 -
gamma:亮度调整值。-
gamma > 0,图像会变亮。 -
gamma < 0,图像会变暗。 -
gamma = 0,则没有额外的亮度调整。
-
这本质也是加法,按照一定的权重值将两张图像混合在一起。
案例:
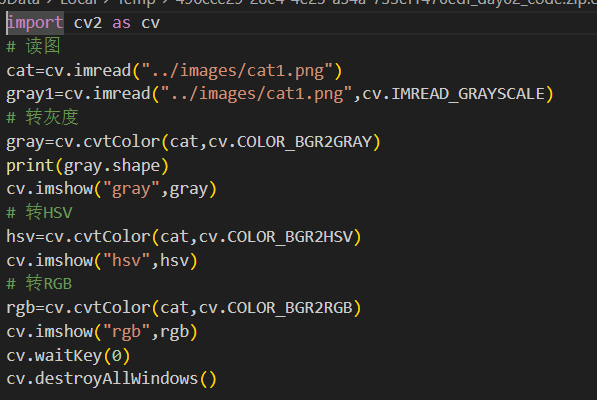
(四)RGB转Gray(灰度)、RGB转HSV :cv2.cvtColor(img,code)
cv2.cvtColor是OpenCV中的一个函数,用于图像颜色空间的转换。可以将一个图像从一个颜色空间转换为另一个颜色空间,比如从RGB到灰度图,或者从RGB到HSV的转换等。
-
img:输入图像,可以是一个Numpy数组绘着一个OpenCV的Mat对象-
Mat是一个核心的数据结构,主要用于存储图像和矩阵数据。在 Python 中使用 OpenCV 时,通常直接处理的是 NumPy 数组,cv2模块自动将Mat对象转换为 NumPy 数组。二者之间的转换是透明且自动完成的。例如,当你使用cv2.imread()函数读取图像时,返回的是一个 NumPy 数组,但在C++中则是Mat对象。
-
-
code:指定转换的类型,可以使用预定义的转换代码。-
例如
cv2.COLOR_RGB2GRAY表示从rgb到灰度图像的转换。
-
案例:
七、灰度实验
将彩色图像转换为灰度图像的过程称为灰度化,这种做法在图像处理和计算机视觉领域非常常见。
灰度图与彩色图最大的不同就是:彩色图是由R、G、B三个通道组成,而灰度图只有一个通道,也称为单通道图像,所以彩色图转成灰度图的过程本质上就是将R、G、B三通道合并成一个通道的过程。
(一)灰度图
灰度图像与黑白图像不同,在计算机图像领域中黑白图像只有黑色与白色两种颜色;但是,灰度图像在黑色与白色之间还有许多级的颜色深度。灰度图像经常是在单个电磁波频谱如可见光内测量每个像素的亮度得到的,用于显示的灰度图像通常用每个采样像素8位的非线性尺度来保存,这样可以有256级灰度。

(二)最大值法
对于彩色图像的每个像素,它会从R、G、B三个通道的值中选出最大的一个,并将其作为灰度图像中对应位置的像素值。
案例: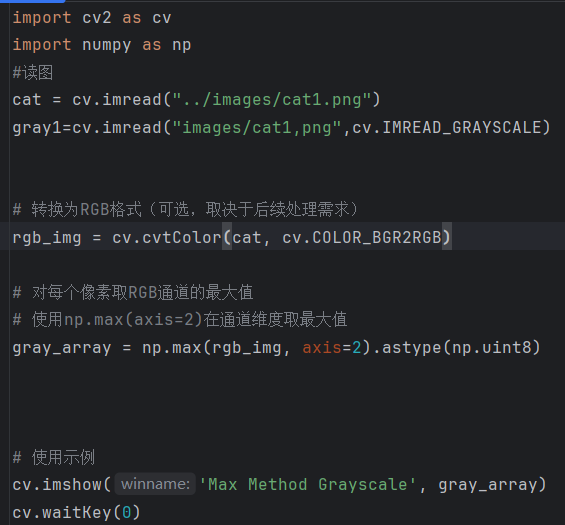
(三)平均值法
对于彩色图像的每个像素,它会将R、G、B三个通道的像素值全部加起来,然后再除以三,得到的平均值就是灰度图像中对应位置的像素值。
案例:
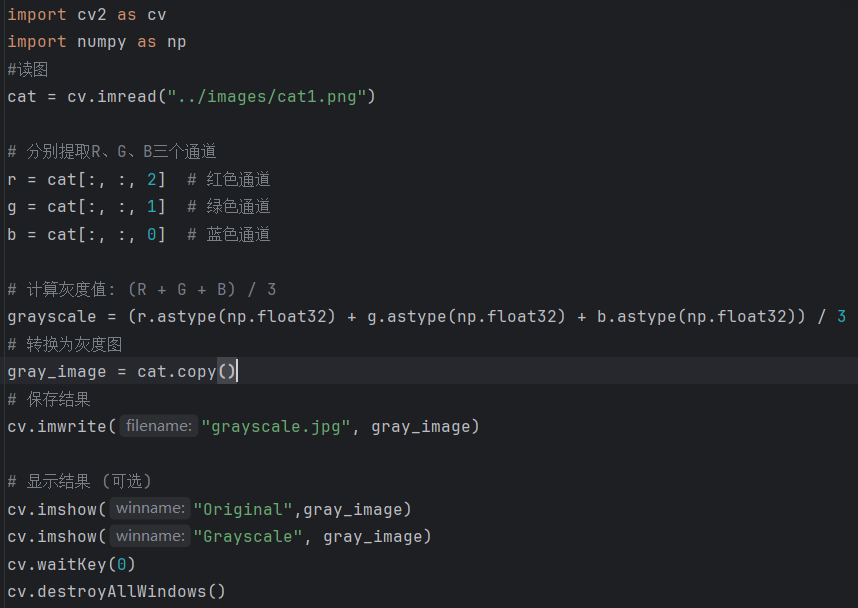
(四)加权均值法
对于彩色图像的每个像素,它会按照一定的权重去乘以每个通道的像素值,并将其相加,得到最后的值就是灰度图像中对应位置的像素值。
所使用的权重之和应该等于1。这是为了确保生成的灰度图像素值保持在合理的亮度范围内,并且不会因为权重的比例不当导致整体过亮或过暗。
(五)两个极端的灰度值
在灰度图像中,“极端”的灰度值指的是亮度的两个极端:最暗和最亮的值。
-
最暗的灰度值:0。这代表完全黑色,在灰度图像中没有任何亮度。
-
最亮的灰度值:255。这代表完全白色,在灰度图像中具有最大亮度。

小结:今天的东西有点多,加油加油

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)