喂饭级教程:基于饼干哥哥的思路,用n8n和多维表格搭建一个“增量更新”的7x24自动化选题流
在研究了饼干哥哥的自动化选题方案后,我发现了一个致命问题:如果直接设置定时任务,系统会每天重复抓取、分析和存储同一篇文章,导致数据冗余和资源浪费。这促使我重构了整个流程,打造了一个真正“精明”的7x24小时自动化系统。
大家好,我是万涂幻象,一名专注商业 AI 智能体开发与企业系统落地的实践者。
长期聚焦定制化业务系统开发、多维表格定制、Prompt定制、智能体设计、自动化工作流构建、ComfyUI工作流与AI视频制作,致力于为各行各业打造能创造增长、构筑优势的AI落地解决方案。
在这里,持续分享前线实战案例与结构化落地方法,文末还有实用资源推荐,欢迎收藏~
前几天,刷到饼干哥哥AGI那篇讲自动化选题的文章,写得挺好。他那个思路,用n8n去抓公众号文章,再用AI分析数据、做成报告,非常聪明。
但我这个搞开发出身的,看完心里就“咯噔”一下,犯“洁癖”了。
我发现个疙瘩:他那个流程,如果我直接拿来设置成定时任务,每天跑一次,会发生什么?
它会每天把所有文章(包括昨天的、前天的)重新抓一遍、重新存一遍。
这意味着,我的飞书多维表格里,同一篇文章会出现两次、三次...马上就是一大堆重复数据。这简直是灾难。
更要命的是,n8n会傻乎乎地把这些老文章再扔给AI去做一次摘要,再转一次Markdown...
“极致了”API的公众号数据(阅读量、点赞量、转发量、收藏数、评论数)确实需要更新,这没毛病。但上面这些“转格式”、“AI摘要”是固定不变的,这才是真正又慢又烧钱的重复劳动!
在我看来,一个好的自动化系统,必须是“懒惰”且“精明”的。
所以,我花了点时间,把这套流程彻底重构了一版。
核心逻辑就一句话:先问,再写。
在n8n准备把一篇文章塞进飞书之前,它得先去飞书“敲门”:“嘿,这篇文章你有了吗?”
-
飞书说“没有”(新文章),OK,走“全套流程”:转Markdown、AI写摘要、调“极致了”拿数据、新建一条记录。
-
飞书说“有了”(老文章),好,走“精简流程”:跳过转Markdown、跳过AI摘要,只调“极致了”API拿个最新数据、更新一下那条旧记录。
就这么个小小的“查重更新”逻辑,我的飞书表格永远是干干净净的、没有重复。
AI摘要的钱,只花在刀刃(新文章)上。
数据API的调用,也变成了有意义的“更新”,而不是无效劳动。
这,在我这,才算是个能7x24小时踏实跑的“活”系统。
今天我就把这套“喂饭级”的部署方案,和这个“增量更新”的工作流,从0到1完完整整给你“盘”明白。
01|开工之前:咱们的“家伙事儿”
这套系统,说白了就是搭个小乐高。在开始前,你得知道这几个“零件”分别是干嘛的。
我用大白话给你过一遍:
✅ Wechat2RSS 这玩意儿是个工具。公众号是个封闭的黑盒子,这家伙能把公众号文章转成n8n能看懂的RSS标准格式。
这是个付费服务,我用的是15元/月的私有化部署,图个稳定。
✅ n8n 这就是咱们的“自动化中枢”。一个可视化的自动化工具,所有的工作流逻辑,比如“定时触发”、“获取A”、“发给B”、“如果C就D”...都在这跑。
✅ Zeabur 这是我们的“运行环境”。n8n和Wechat2RSS这些程序,总得有个地方7x24小时跑着吧?Zeabur就是干这个的,一个云部署平台。
为啥选它?因为它有每月5美金的免费额度。 跑咱们这个小工作流,绰绰有余,等于白嫖。
✅ 飞书多维表格 这就是我们的“数据仓库”。所有抓来的文章、摘要、数据,最后都存在这。飞书的好处是,它本身就带了AI能力(比如智能标签)和强大的公式,方便我们做后续分析。
✅ AI大模型 / 极致了数据API 这是我们的“API能力接口”。比如DeepSeek,我们用它来写文章摘要。比如“极致了”API,我们用它来获取阅读量、点赞量。需要的时候,n8n会去调用它们。

02|第一步:把“运行环境”跑起来 (Zeabur部署)
这部分,我带你走一遍,绝对“喂饭级”。
✅ 搞定 Wechat2RSS 服务
-
先去
https://wechat2rss.xlab.app/deploy/私有化部署。 -
一定留对邮箱,几分钟后你就会收到包含“激活码”的邮件。

✅ 注册 Zeabur 部署平台
-
打开
https://zeabur.com/,正常注册。 -
【关键】 注册完,建议你先去个人设置里把手机号给绑了。这是个“坑”,新用户不绑手机,一会儿部署n8n会一直卡住不动。很怪,但管用。
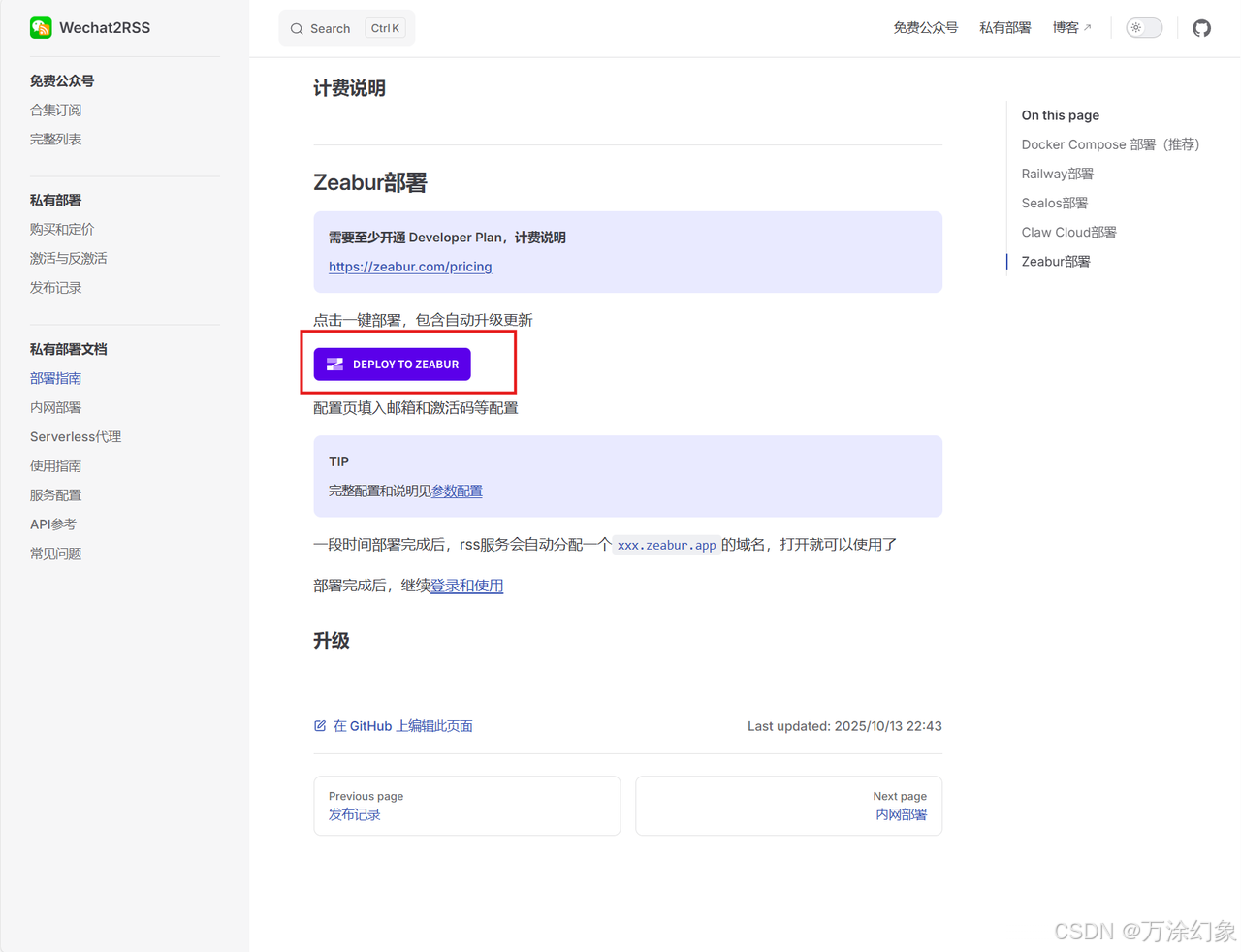
✅ 部署 Wechat2RSS 到 Zeabur
-
回到Wechat2RSS的部署页面 (
https://wechat2rss.xlab.app/deploy/deploy.html)。 -
直接点“一键部署到Zeabur”。
-
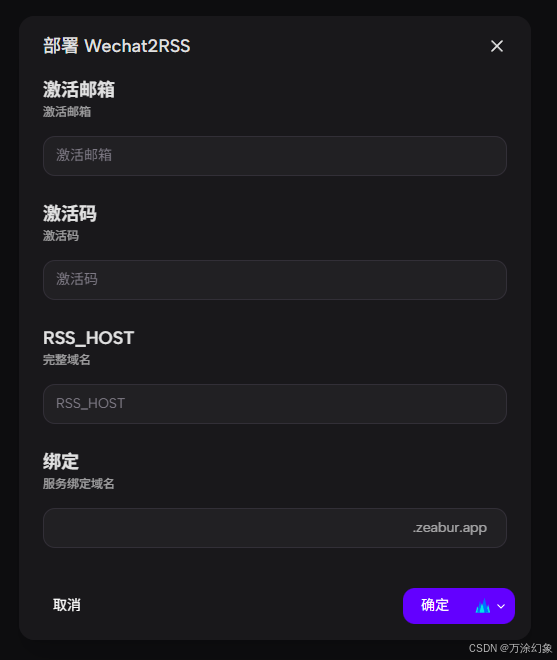
它会跳转到Zeabur,弹窗让你填参数:
-
绑定域名: 先填这个! 这是你服务最后的主地址。你自己起个二级域名,比如
my-rss.zeabur.app,系统提示绿字(可用)就行。 -
RSS_HOST: 把上面你刚填的“绑定域名”(
my-rss.zeabur.app)完整地复制粘贴到这里。 -
【重点】 如果本地没有部署n8n,不要填
192.168.1.1:8080之类的本地地址,否则100%报错! -
激活邮箱、激活码: 填你邮件里收到的。
-
-
点“确定”,等等待即可。
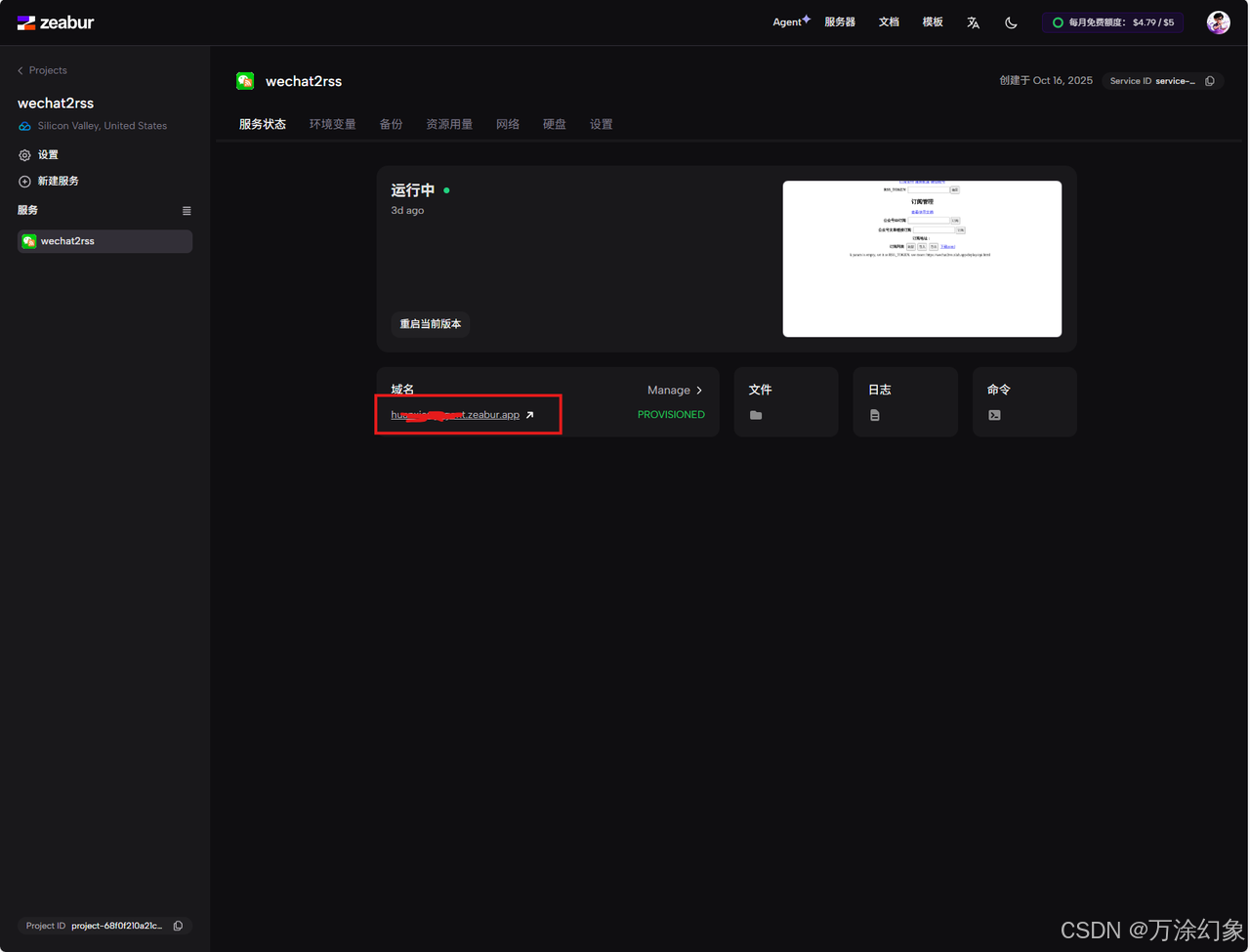
✅ 4. 配置 Wechat2RSS
-
访问你刚部署好的域名(比如
my-rss.zeabur.app)。
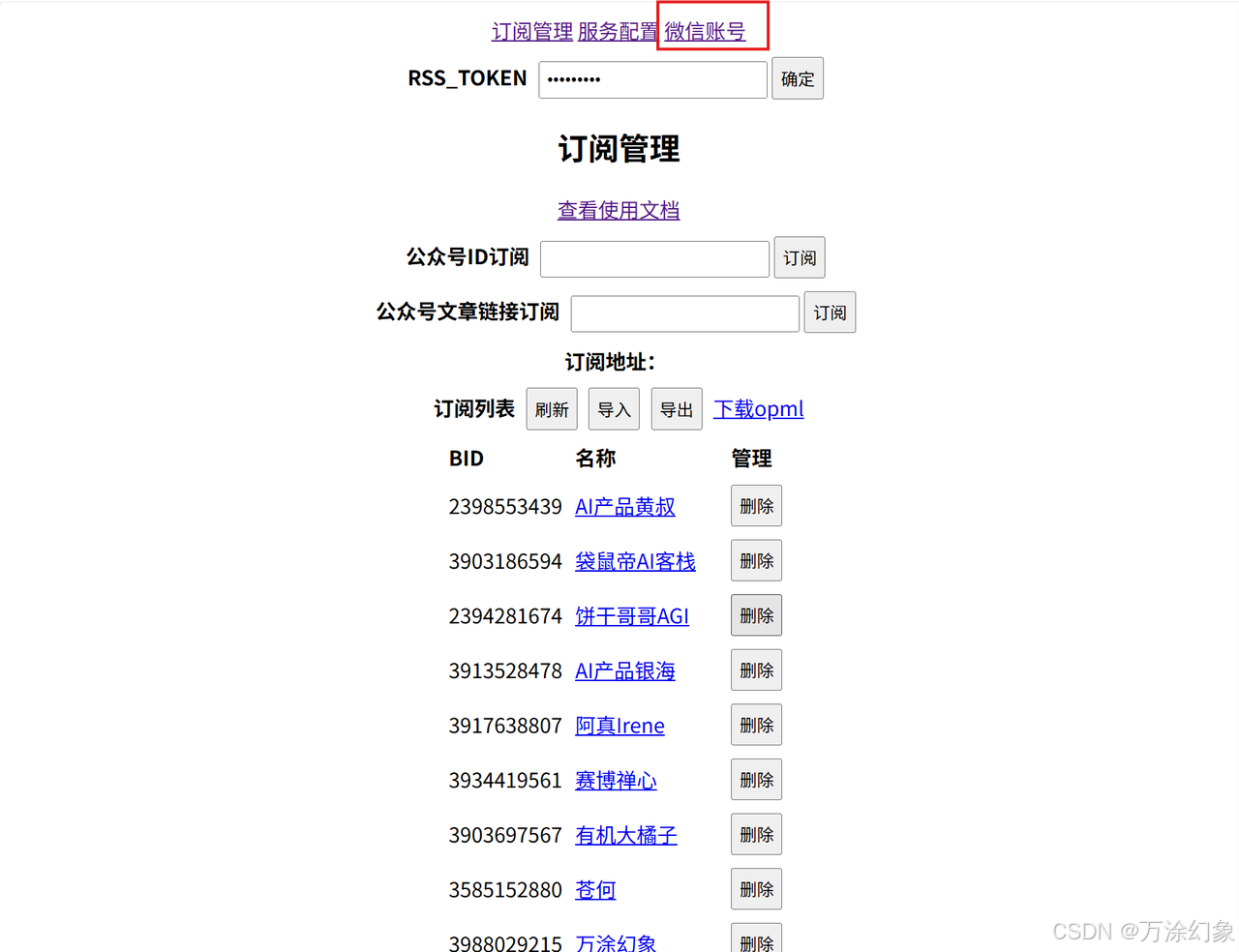
-
点右上角“微信账号”。
-
它管你要
RSS_Token。这玩意儿在哪? -
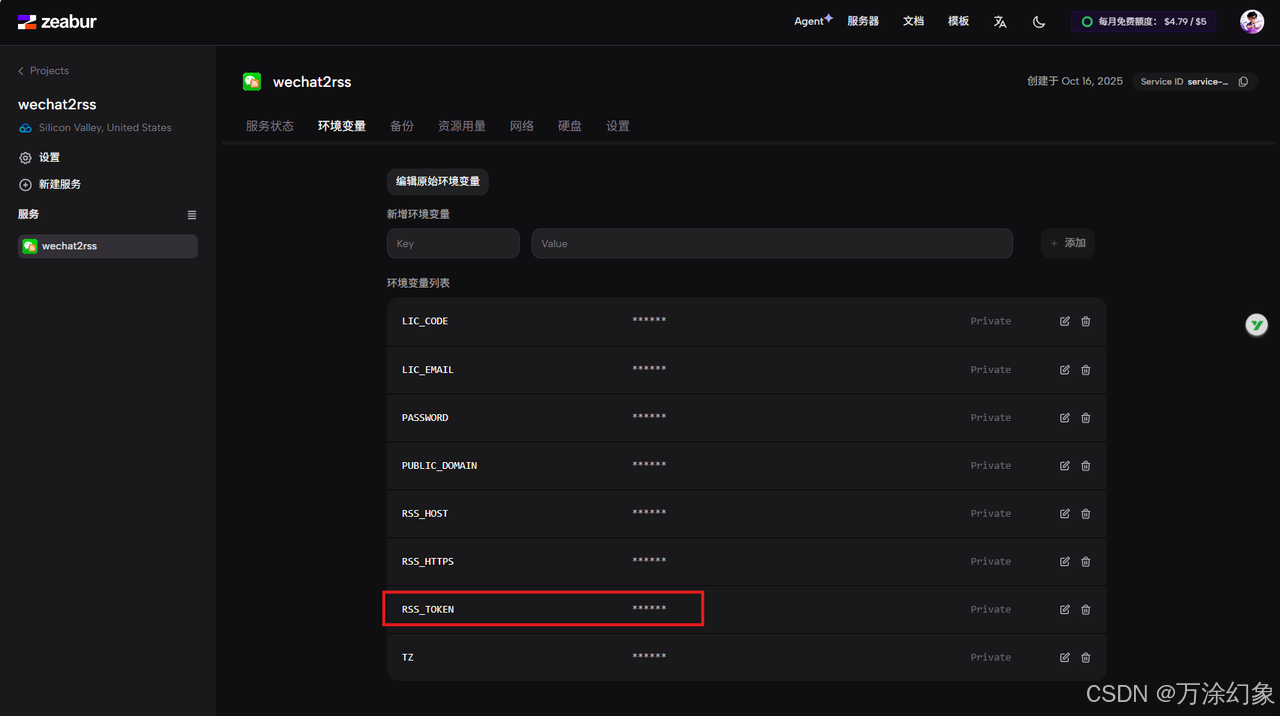
回到Zeabur,在你的Wechat2RSS服务里,点“Variable”(变量),就能看到
RSS_TOKEN,点一下复制,粘贴回去。
-
点“登录微信账号”,用“微信读书”App扫码授权。
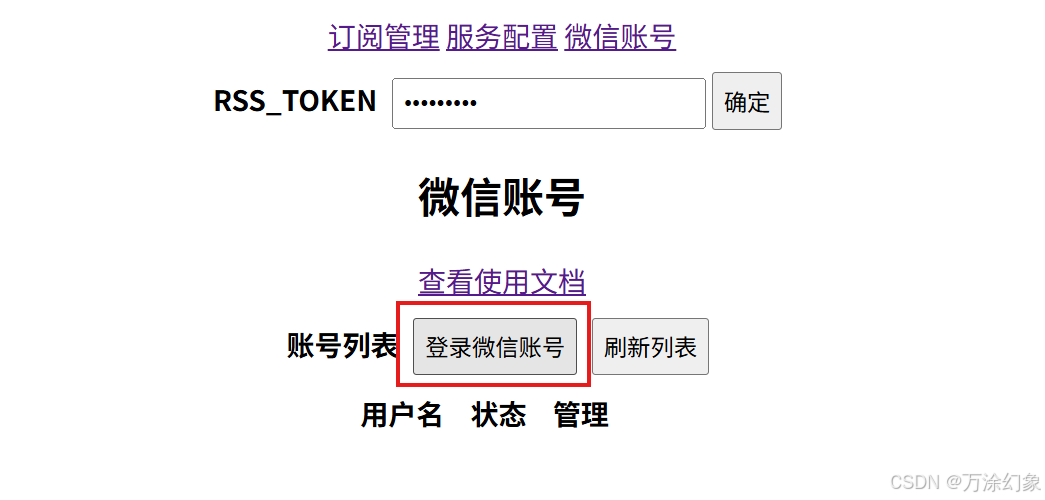
-
完事。现在你可以在“订阅管理”里,用文章链接去添加你想监控的公众号了。
✅ 部署 n8n 到 Zeabur
-
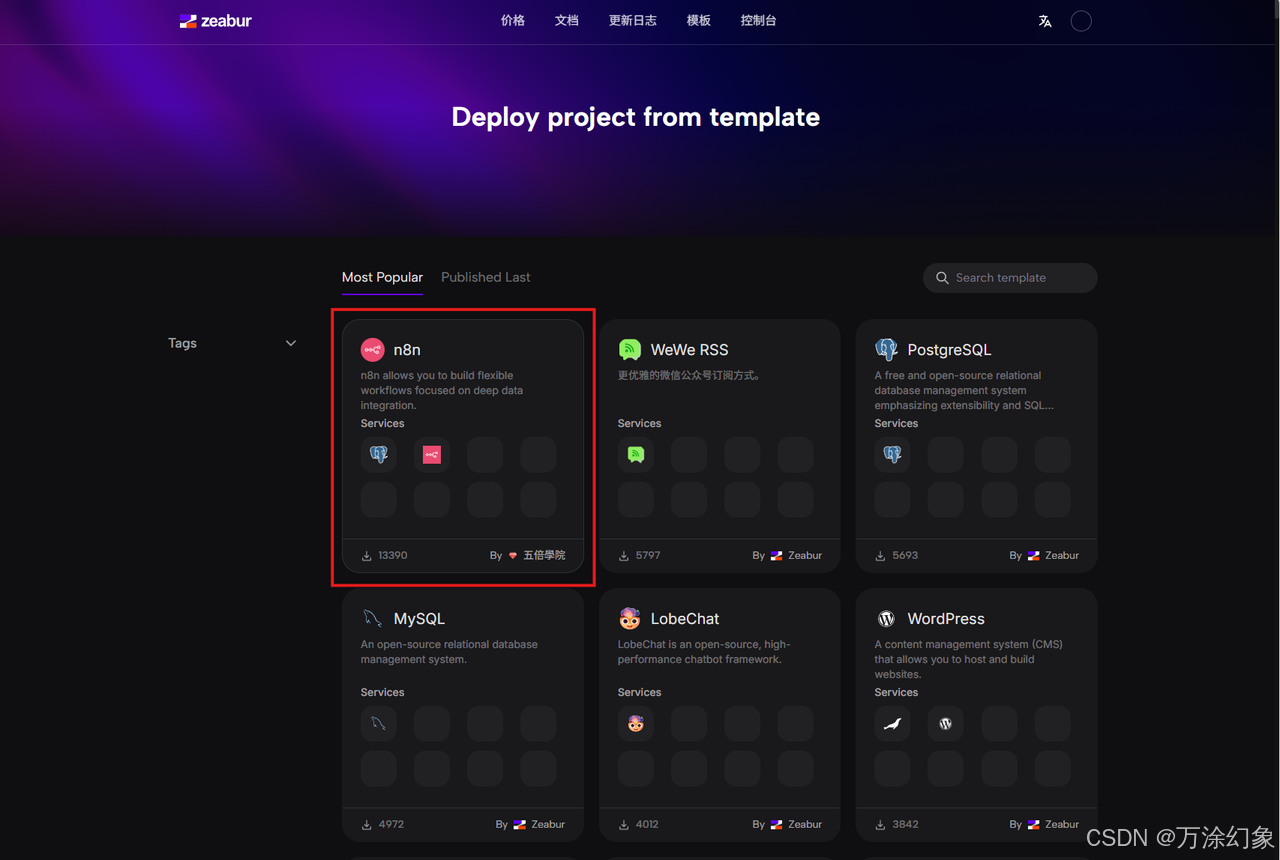
回到Zeabur首页,点“模版”。
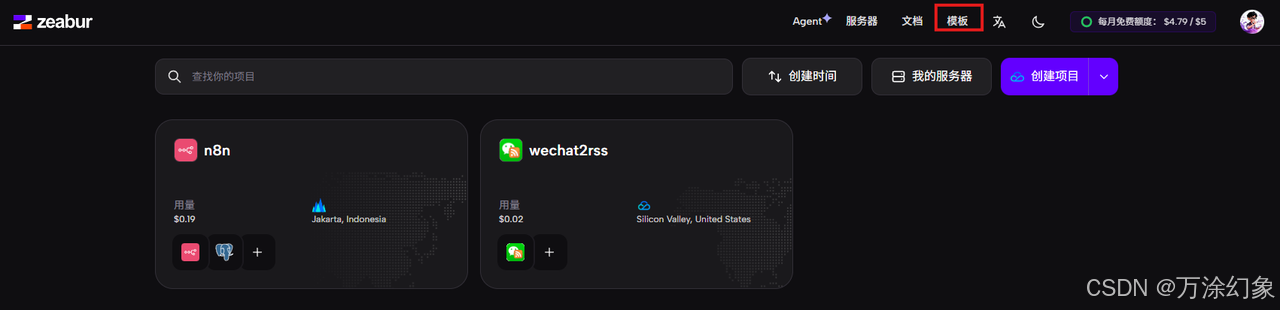
-
找到 n8n,点它,“Deploy”(部署)。
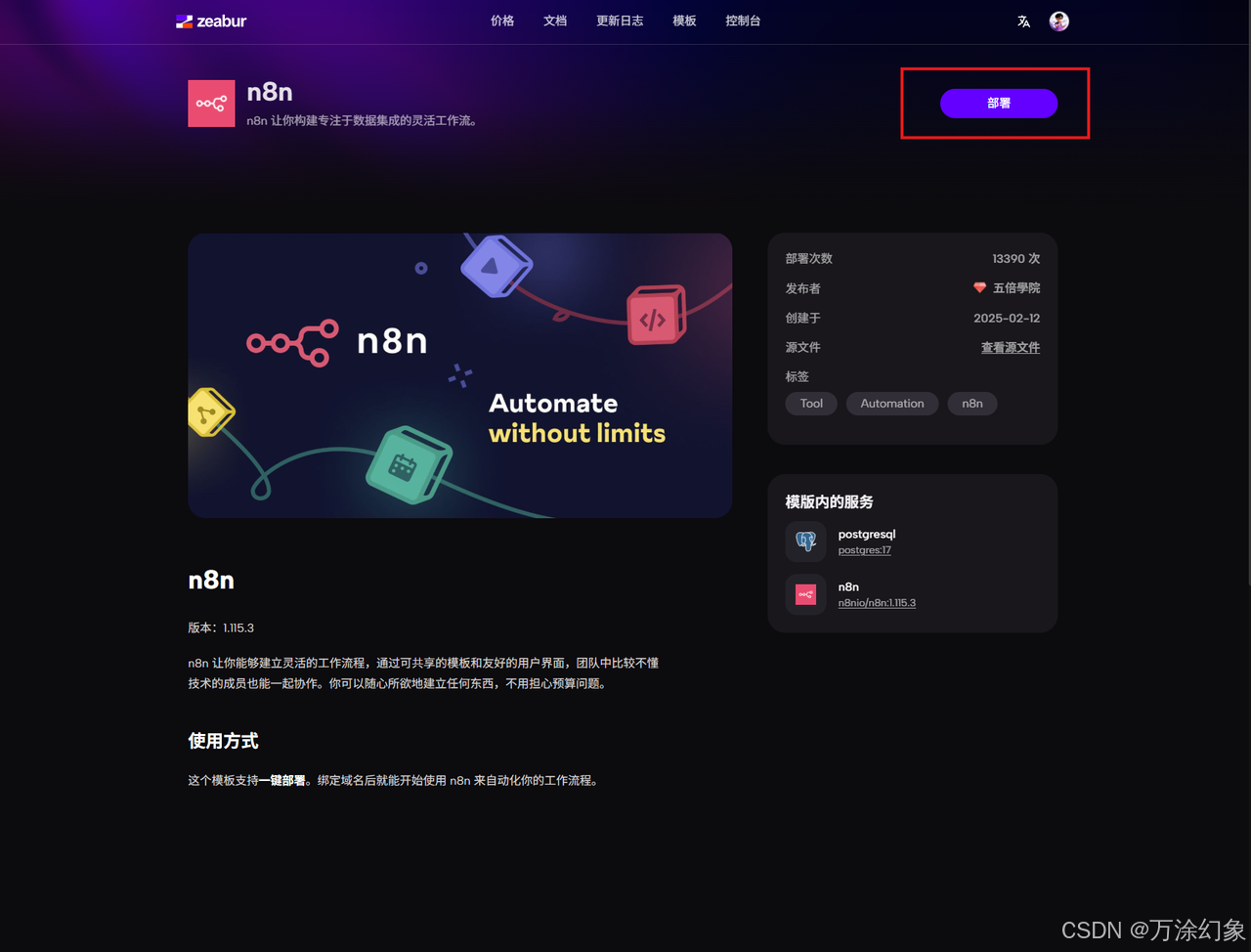
-
还是起个二级域名,比如
my-n8n.zeabur.app。
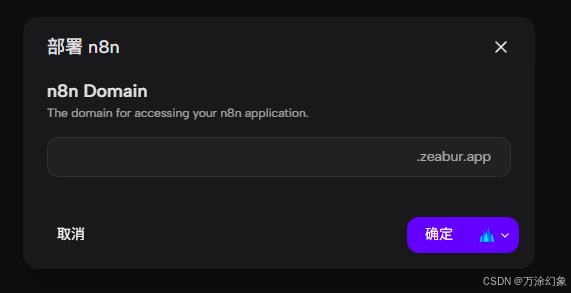
-
点“确定”,等待即可。
-
访问你的n8n域名,设置管理员邮箱和密码。
好了。到此为止,你的服务都已经在7x24小时在线运行了。
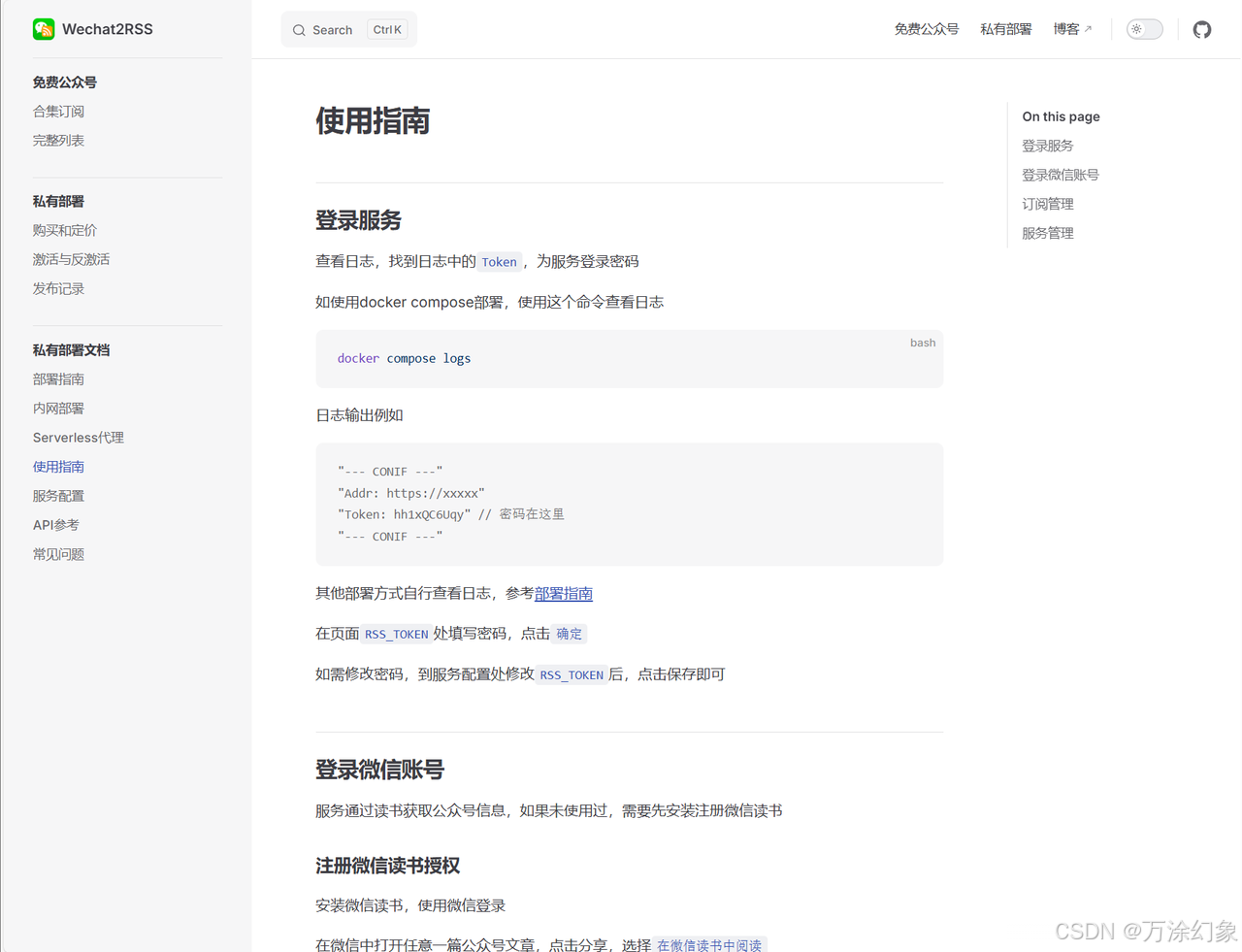
03|第二步:n8n 的核心逻辑 (工作流配置)
这才是本次的重点。你可以在公众号直接发送“n8n”获取工作流源码,或者跟着我的操作自己搭一遍。
我把这个流程拆成几大块,给你“盘”清楚。
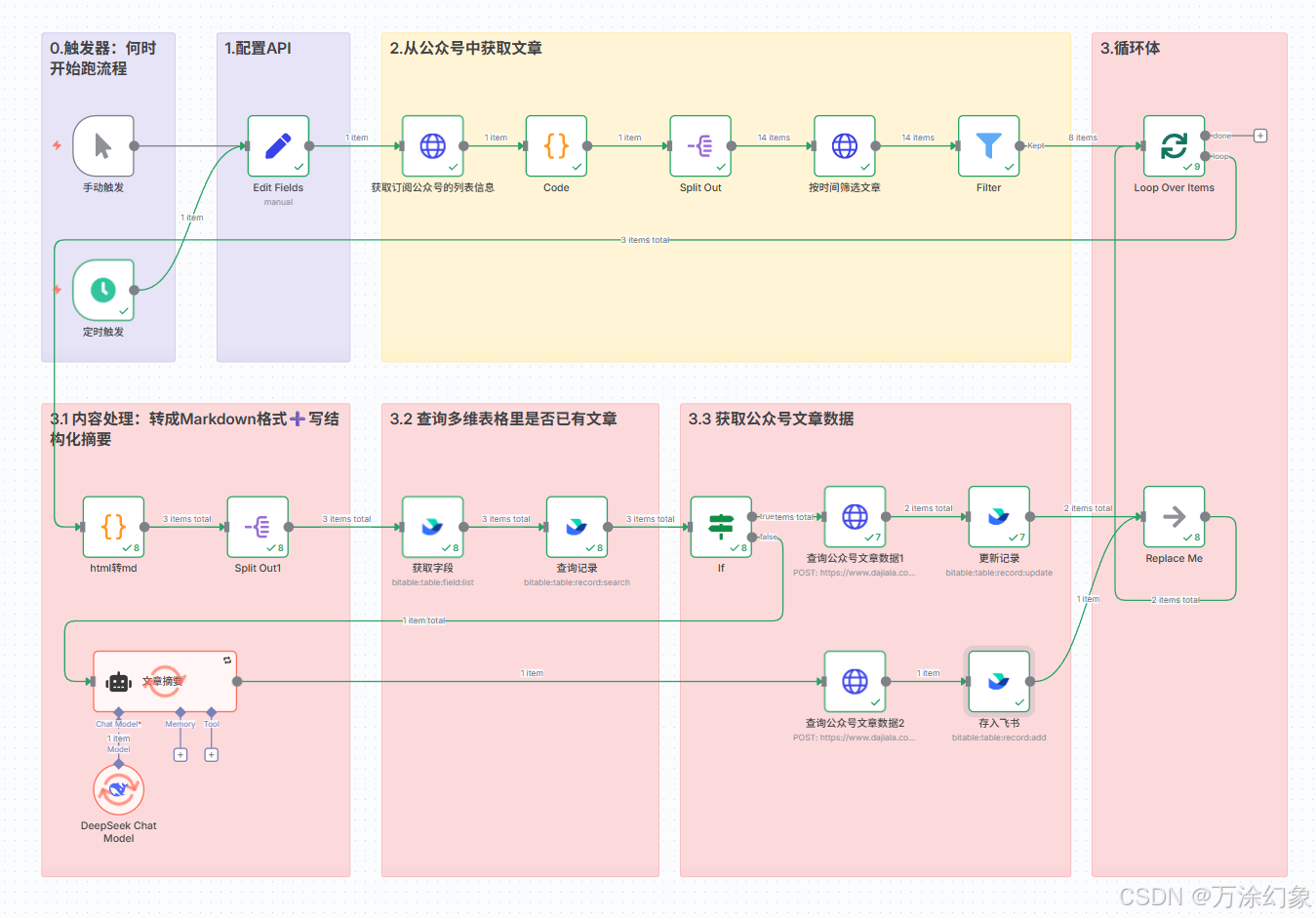
✅ 触发器 与 数据源 (Node 0 & 2)
-
触发器: 先用“手动触发”,跑通流程。咱们要的是自动化。所以加个用
Schedule Trigger(定时触发),我设置的是每6小时跑一次。
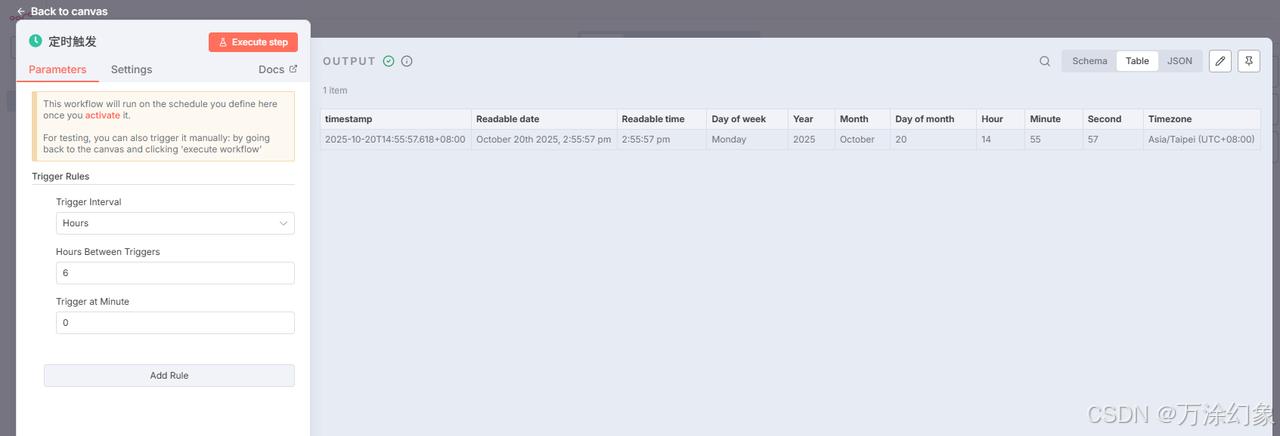
-
HTTP Request (获取列表): 调用你的Wechat2RSS API,获取所有订阅号的列表。
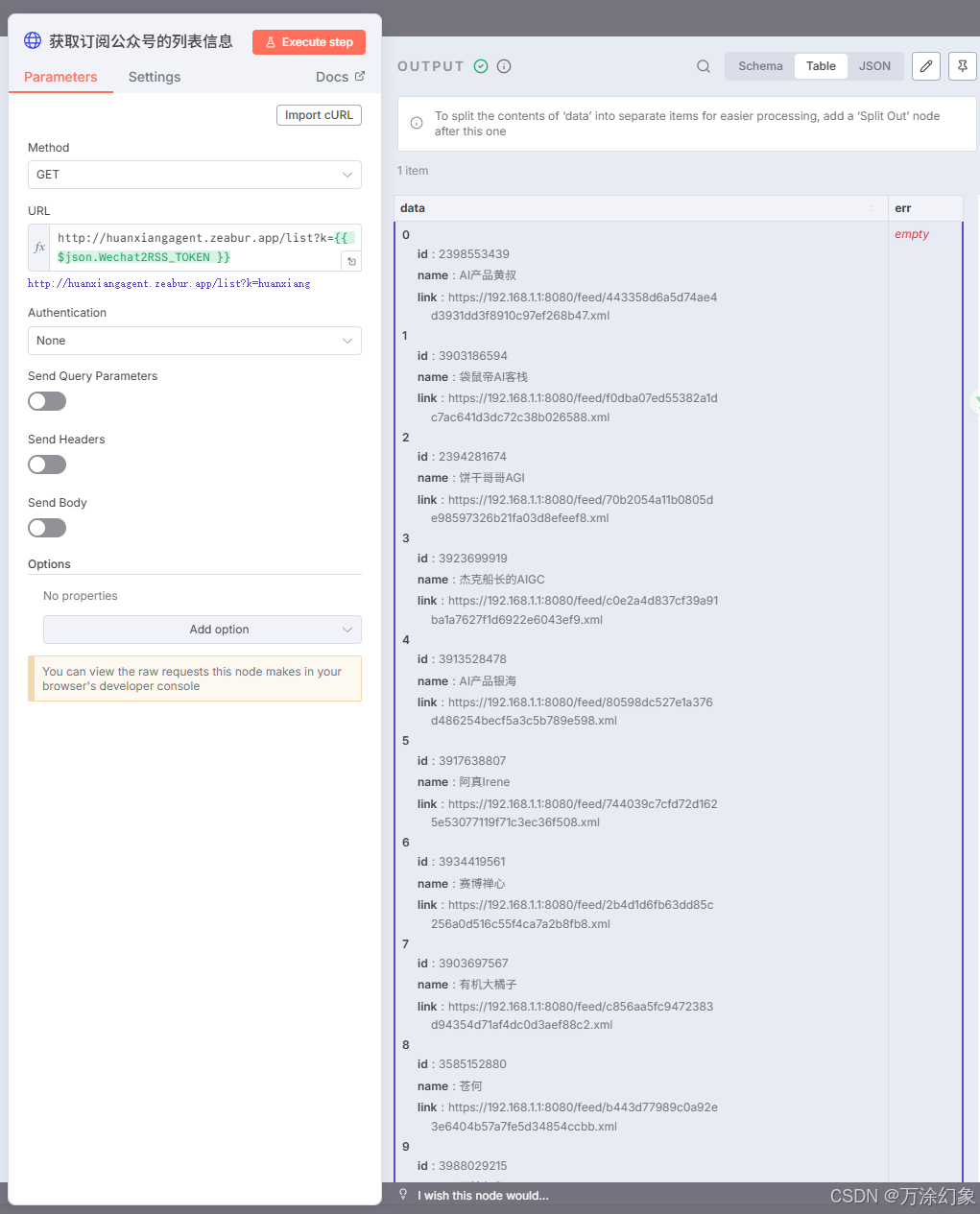
-
Split Out (拆分): 把一堆公众号拆成一个一个的,方便后面挨个处理。
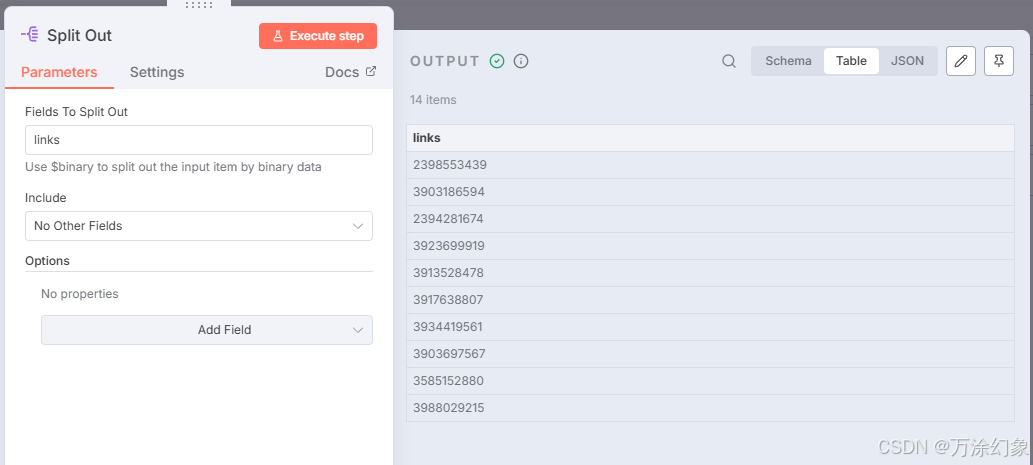
-
按时间筛选文章 (Filter): 这是省钱第一步。 在这里加个节点,只允许“过去2天内”的文章通过。我不想处理一个月前的老黄历。
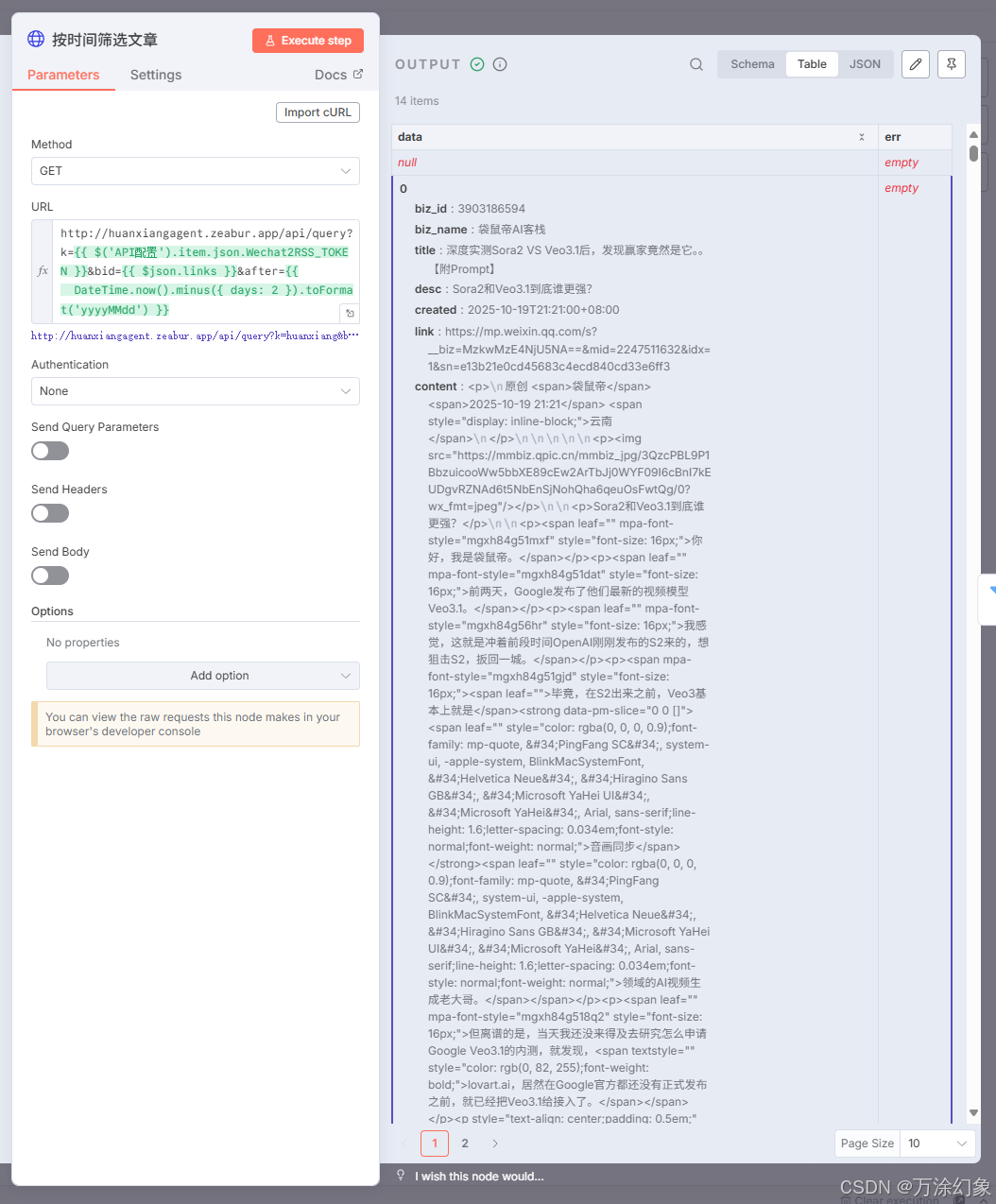
-
Filter (过滤): 过滤掉那些没发文章的空数据。
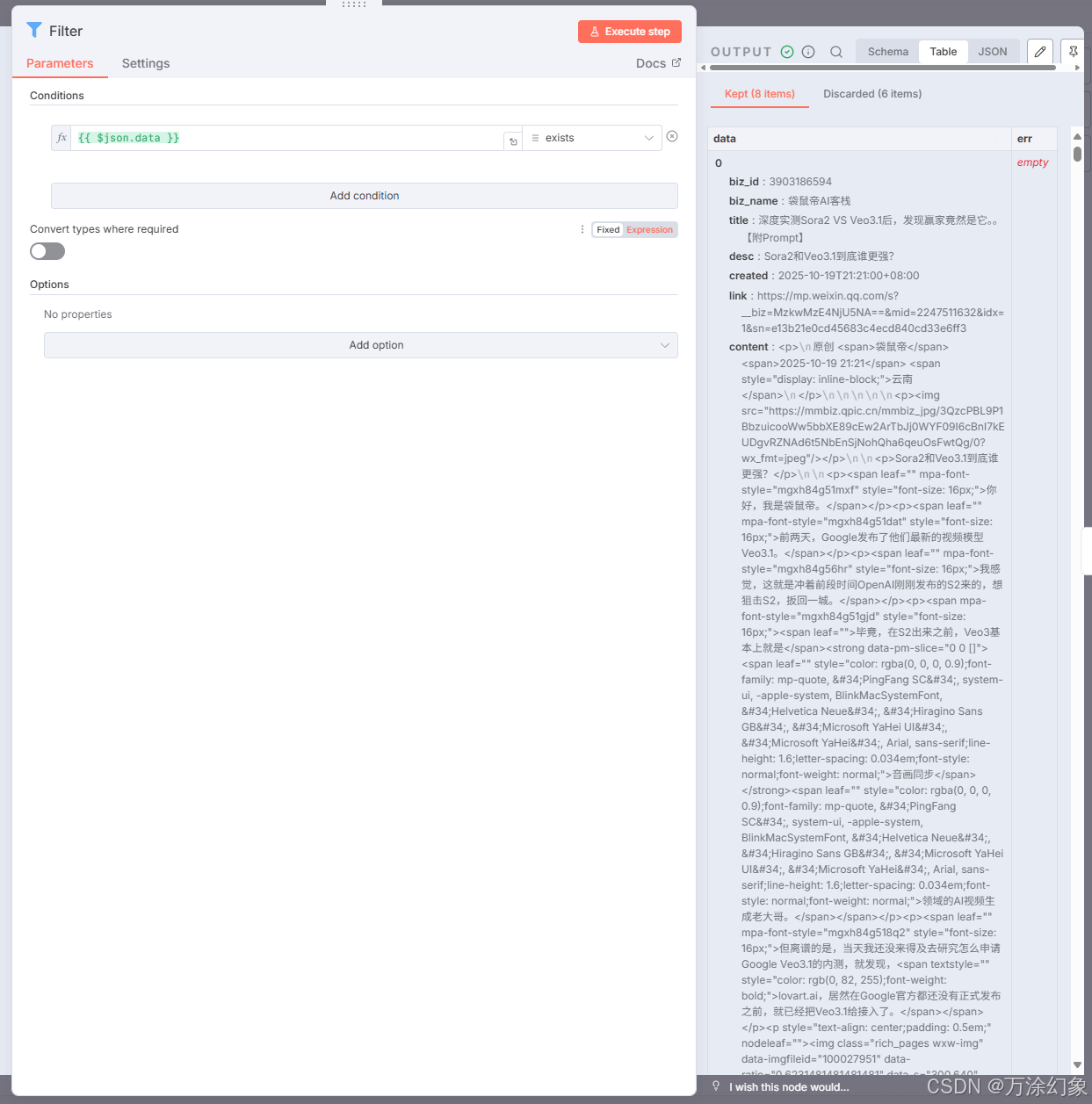
✅ 集中管理“钥匙” (Node 1: Edit Fields)
-
这是我的一个开发习惯,为了方便和安全。
-
我在触发器后面加了一个
Edit Fields节点。 -
说白了,这就是个“配置中心”。 我把所有需要用到的API Key和ID,比如“极致了数据API”、“Wechat2RSS_TOKEN”、“飞书多维表格Token”和“ID”,全都集中写在这个节点里。
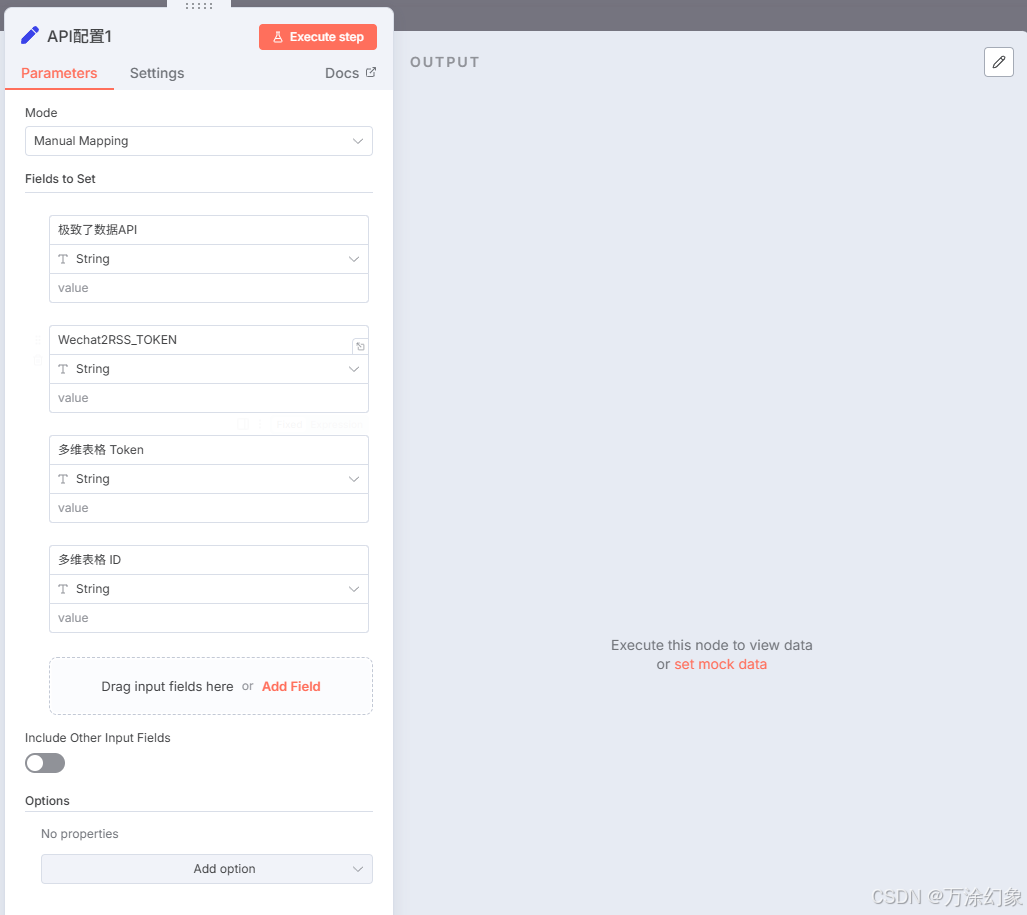
-
好处是啥?
-
安全: 以后我分享工作流的JSON文件,只要删掉这个节点,就不会把我的密钥泄露出去。
-
方便: 哪天我的Token过期了,我不需要去一个个节点里(比如飞书节点、HTTP节点)到处找,我只需要在这一个地方改,整个工作流就全更新了。
-
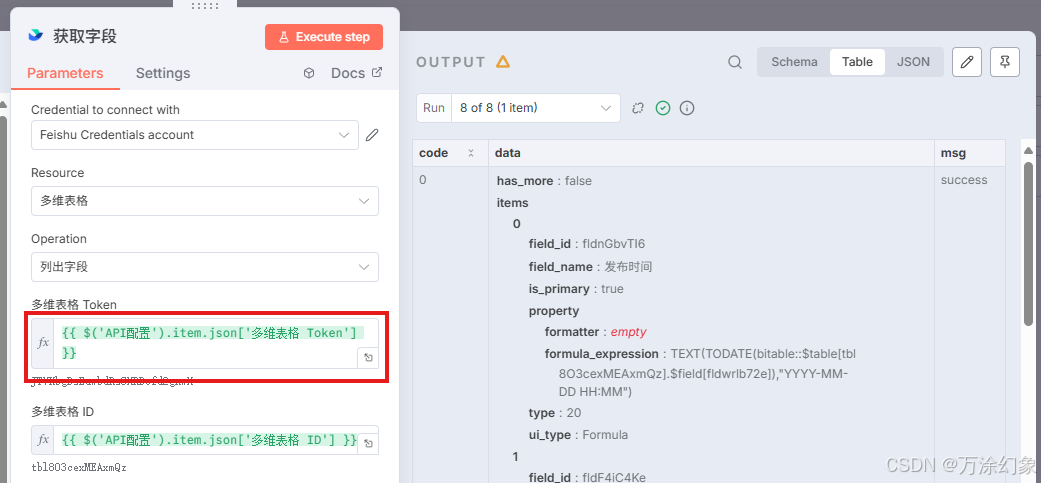
-
后面的节点,比如飞书节点,它不直接填Key,而是通过表达式(expressions)来引用这个
Edit Fields节点里的值。
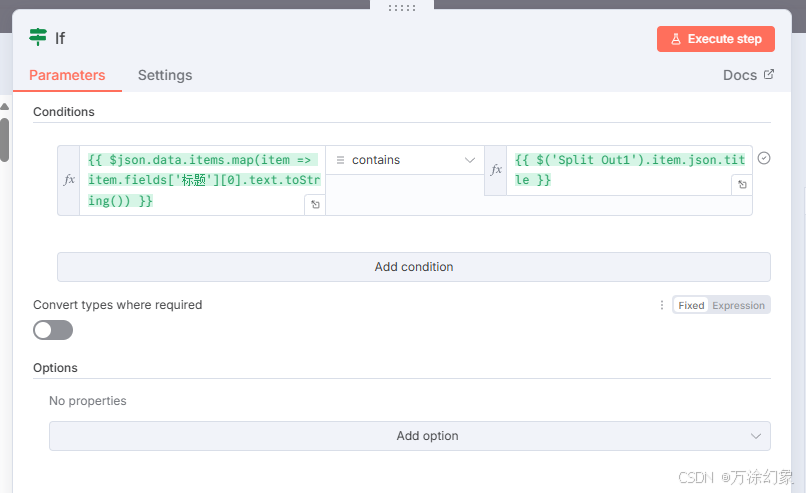
✅ 核心:“查重更新”逻辑 (Node 3.2 & IF)
这是我“魔改”的核心,看仔细了。
-
Search Record (查询记录): 我们拿到一篇文章的URL后,第一件事,就是去飞书多维表格里“查询”。查询的条件就是“标题、账号”。
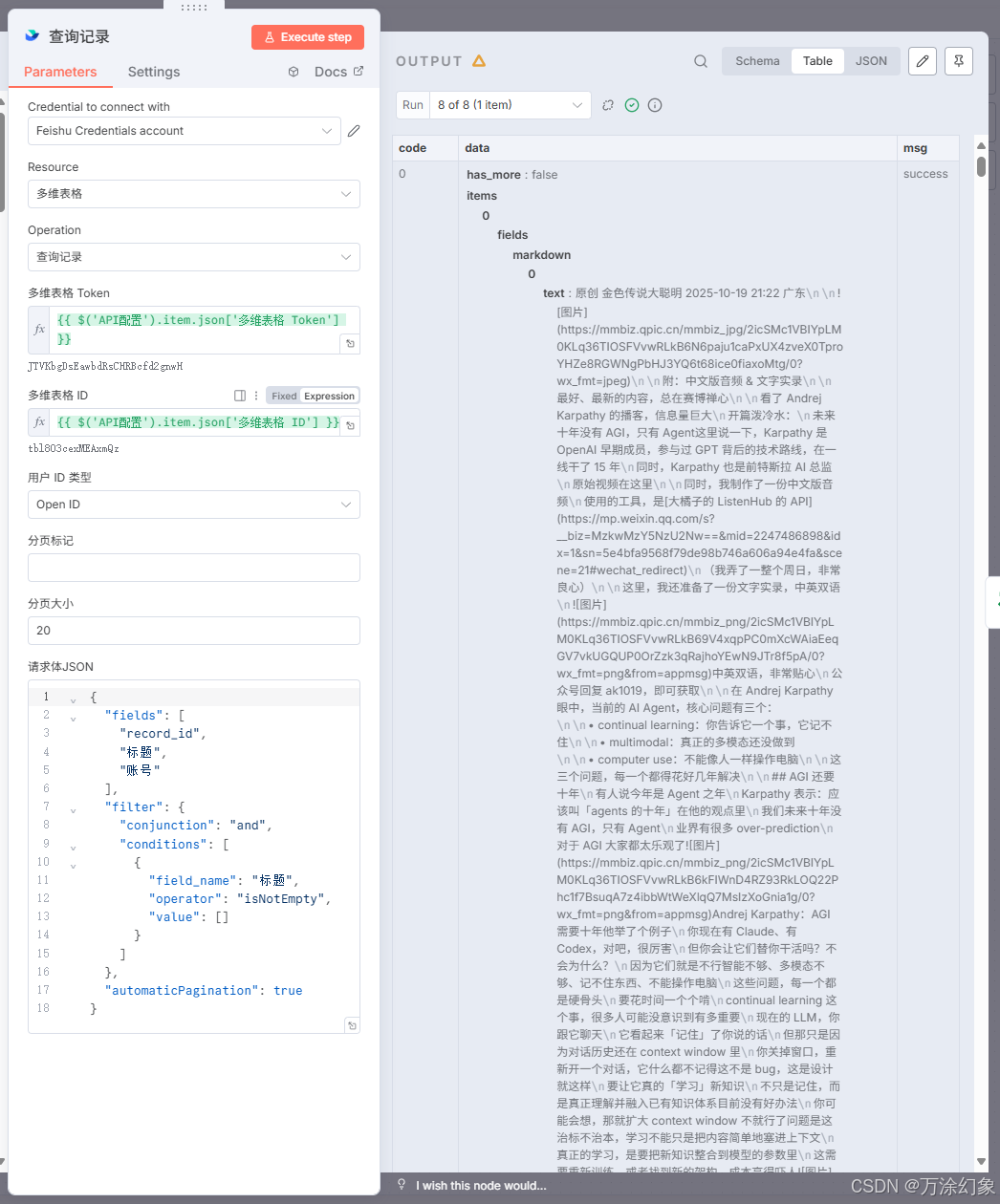
-
IF (如果节点): 这个节点会判断上一步的查询结果。
-
如果“查询”没找到数据(新文章): 流程会走向
True(或False,取决于你怎么设) 的分支,也就是“新文章处理”路径。 -
如果“查询”找到了数据(老文章): 流程会走向另一个分支,也就是“老文章更新”路径。
-
✅ 路径A:“新文章”全套服务 (Node 3.1 & 3.3)
这条路是给新来的文章走的,给它“总统级”待遇。
-
html2md (转格式): 公众号原文是HTML,又乱又大。用一个Code节点把它转成干净的Markdown。
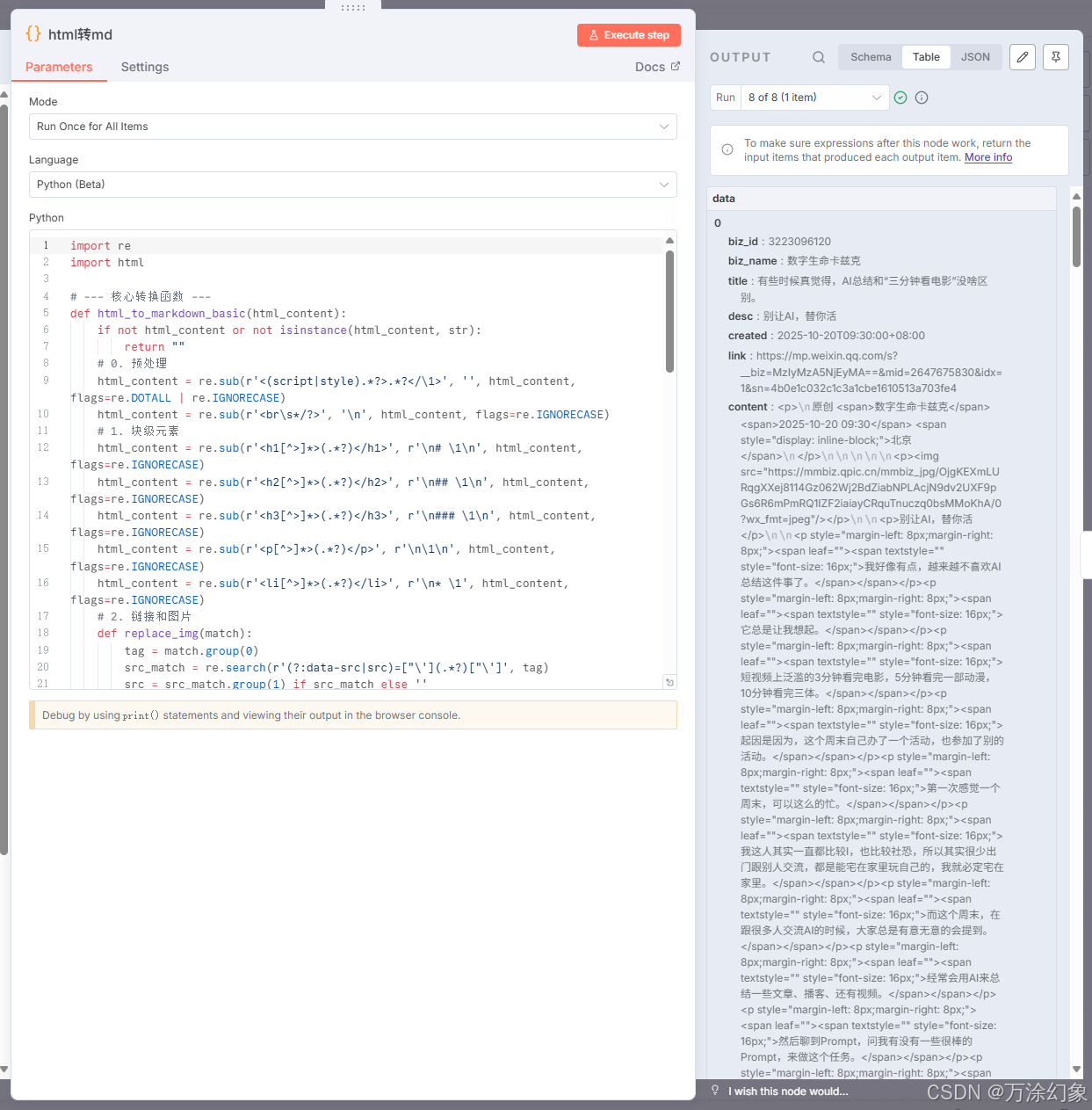
-
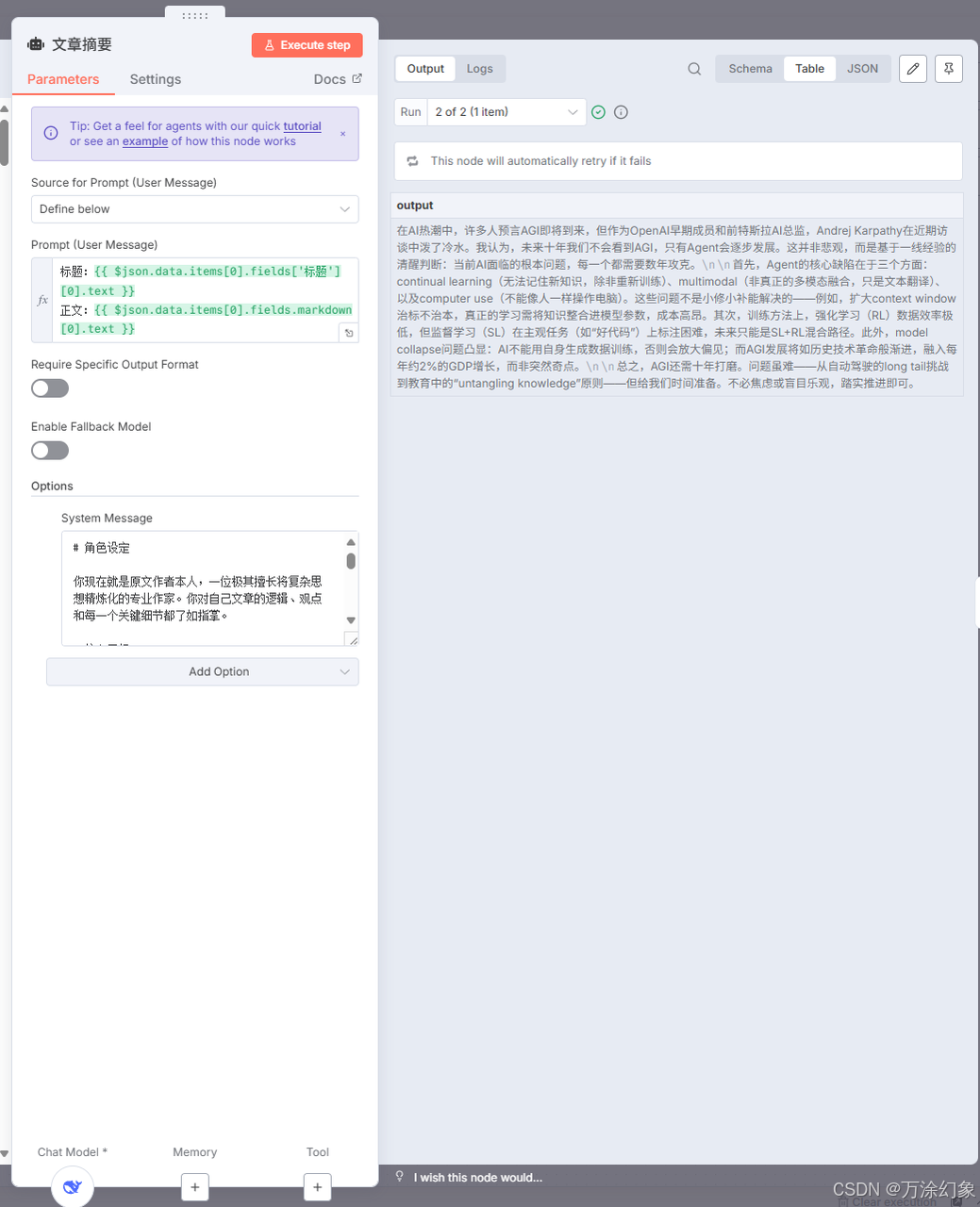
文章摘要 (AI总结): Markdown还是太长。调用大模型(DeepSeek或Claude)的Chat节点,用Prompt喂给它,让它吐一个500字的结构化摘要。
-
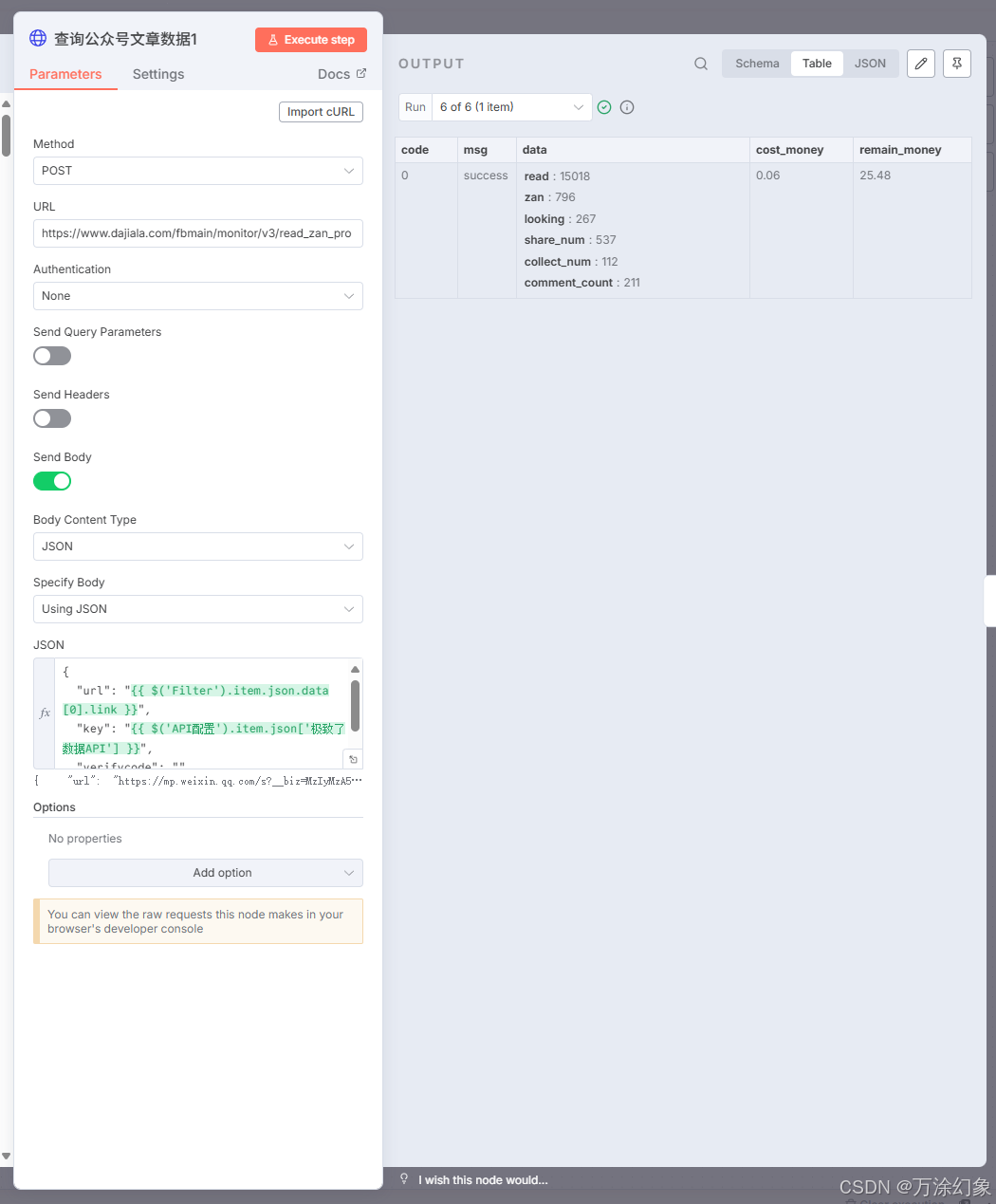
查询公众号文章数据 (调API): 用
HTTP Request节点,去调用“极致了”的API,传入文章URL,拿到阅读、点赞、在看等数据。
-
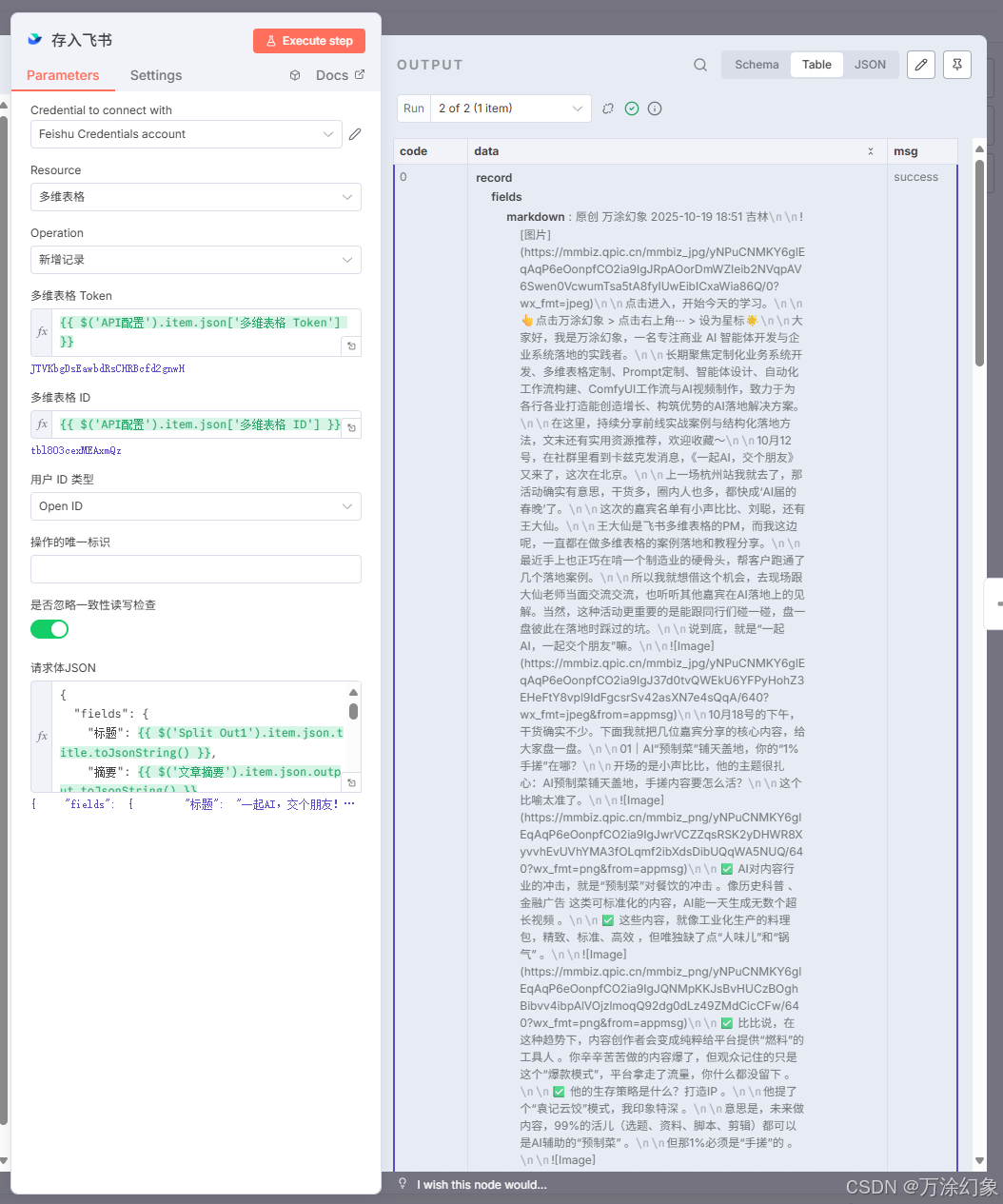
存入飞书 (Save to Feishu): 最后,把文章标题、URL、摘要、Markdown原文、所有数据,新建一条记录,存进飞书。
✅ 路径B:“老文章”精简服务 (Node 3.3)
这条路是给已经“登记在册”的老文章走的。
-
查询公众号文章数据 (调API): 看! 我们跳过了转格式、AI摘要。只跑这一个API,拿到它“最新”的阅读和点赞数。
-
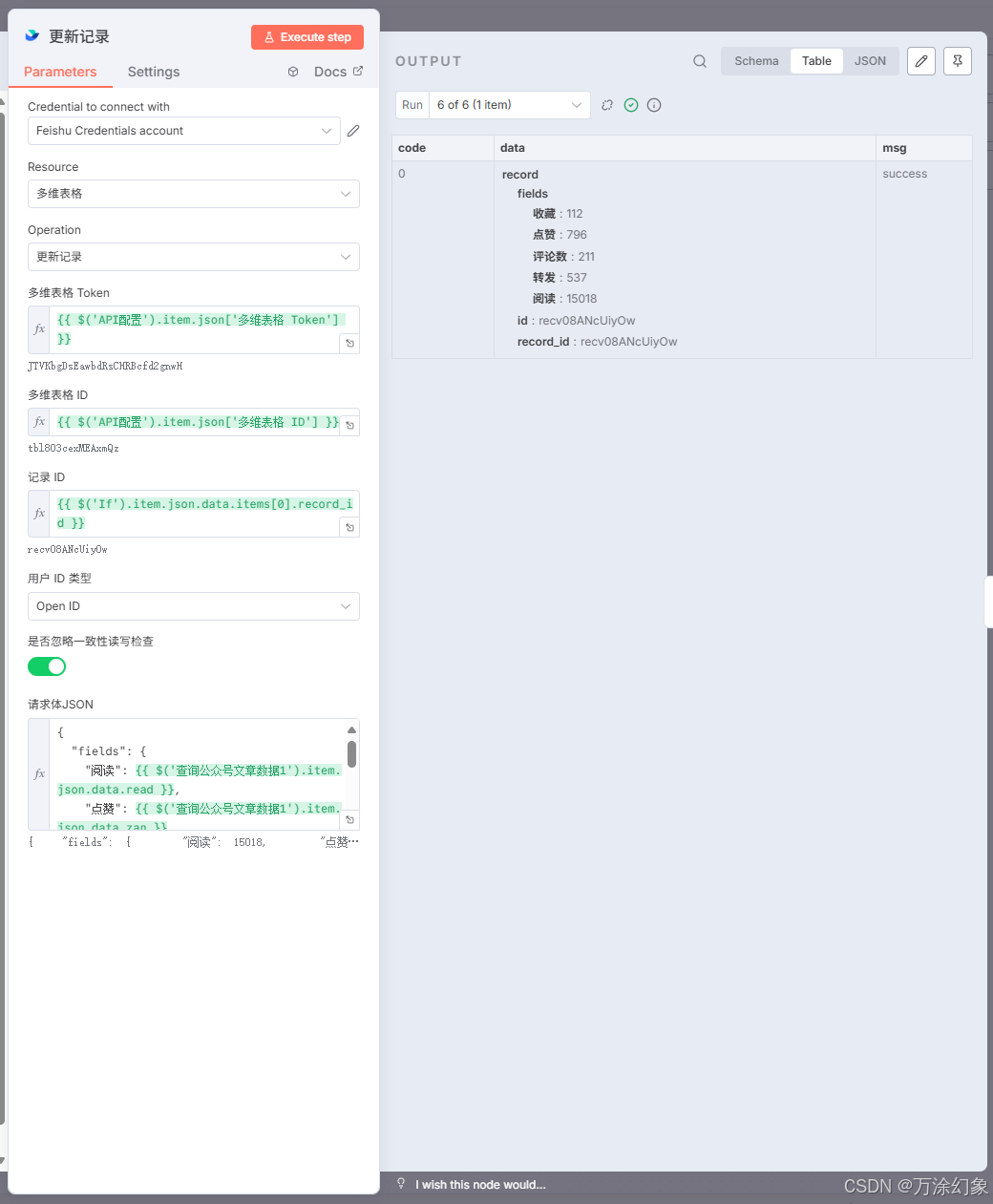
更新记录 (Update Feishu): 用上一步在“查询记录”时拿到的
Record ID,更新飞书里那条老记录的数据字段。
这套逻辑跑下来,你的飞书表里永远都是唯一、最新的数据。
04|第三步:把关键节点都配通 (节点配置)
你把流程搭好后,有几个“插头”是必须你自己配的。
✅ AI摘要节点 (OpenAI / DeepSeek)
-
双击那个 “Chat Model” 节点。
-
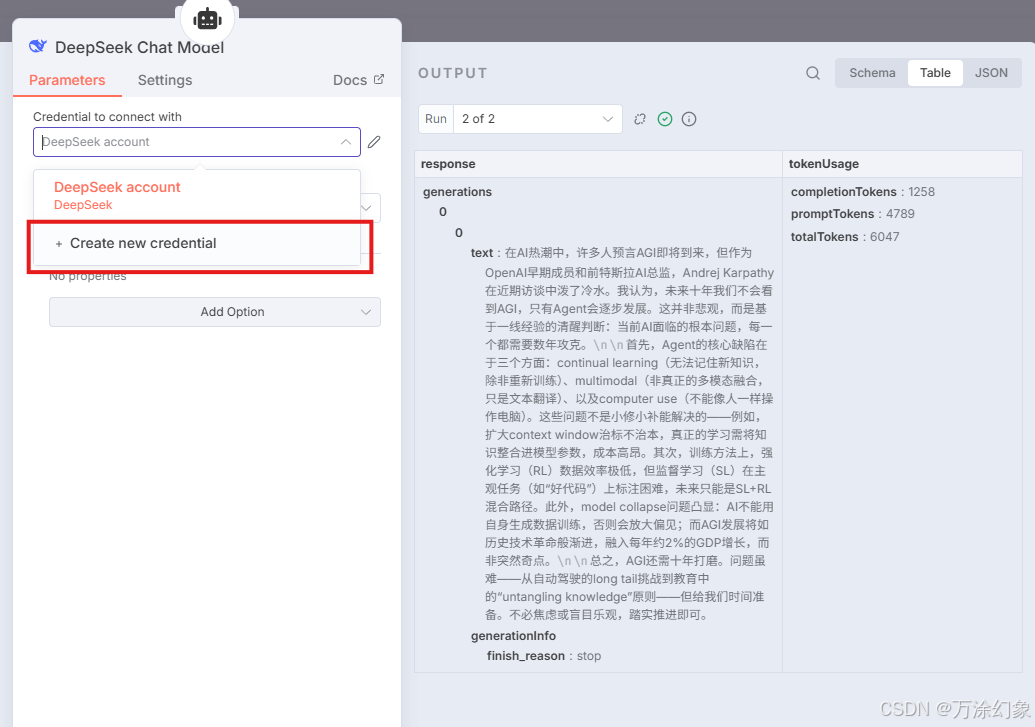
Credentials (凭证): 你得新建一个。
-
如果你用DeepSeek,
Base URL填https://api.deepseek.com/v1。 -
API Key就填你自己的Key。
-
🎯 让AI帮你写“结构化摘要”
这是我从饼干哥哥那里学来的,一个高质量的摘要Prompt,能极大提升后续AI分析的质量。我按我的风格改写了下。
【提示词】👇
# 角色设定
你现在就是原文作者本人,一位极其擅长将复杂思想精炼化的专业作家。你对自己文章的逻辑、观点和每一个关键细节都了如指掌。
# 核心目标
将你(即作者)自己写的长篇文章,亲自改写成一篇**结构完整、信息齐全、逻辑严密**的精简短文。
想象一下,这是为那些时间极其宝贵但又必须掌握你思想精华的核心读者(比如投资人、合作伙伴、高级决策者)准备的“**浓缩精华版**”。它本身就是一篇独立、完整、且有说服力的作品。
# 核心任务与严格约束
1. **视角:** **必须**使用第一人称或原文的叙事口吻,完全代入作者角色。**严禁**使用“本文认为”、“作者指出”等任何第三方、抽离的分析性语言。
2. **内容:** **必须**囊括原作中所有重要的关键要素,尤其是核心论点、支撑论据和最终结论。信息不能有关键性遗漏。
3. **结构:** 重写后的短文必须拥有清晰的“引言-论证-结论”结构,逻辑流畅,而不是一个简单的要点列表。
4. **字数:** 成品总字数**严格控制在 500 字以内**。
# 写作框架与关键要素清单
请在下笔前,在脑中构思好,并严格按照以下框架和要素清单来重构你的文章:
**1. 引言与破题 (约100字):**
- **引入问题:** 像原文一样,用一个引人入胜的钩子或一个核心问题开篇。
- **亮出观点:** 直接、清晰地提出你的核心观点或本文旨在证明的最终结论。开门见山,让读者立刻知道你的主张。
**2. 核心论证与支撑 (约300字):**
- **逻辑链条:** 按照原文的逻辑顺序,依次呈现支撑你核心观点的 2-3 个主要分论点。
- **精炼论据:** 对于每一个分论点,用一两句话配上最关键、最无法或缺的论据来支撑它。这些论据可能是:
- **一个核心数据**
- **一个典型案例**
- **一句权威引述**
- **一个关键的逻辑推导**
- **过渡衔接:** 确保论点之间的过渡自然、流畅,体现出原文的思考脉络。
**3. 结论与升华 (约100字):**
- **重申观点:** 简要回顾你的论证,再次强调你的核心观点,形成逻辑闭环。
- **价值升华:** 像原文结尾一样,提供一个具有启发性的思考、一个最终的建议、或一个面向未来的展望,提升文章的价值感。
---
**指令开始:**
好了,现在请你以创作者本人的身份,将我下方粘贴的你的长文,严格遵循以上所有要求,亲自改写成一篇 500 字以内的精华短文。
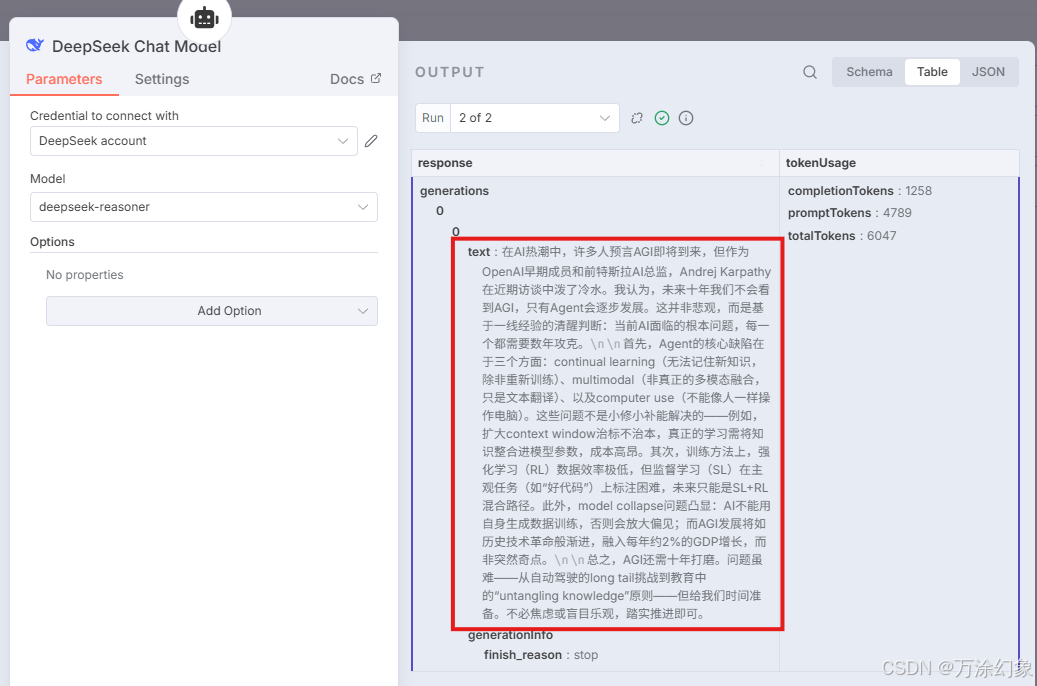
直接给我结果即可,其他的什么的都不要说。【预期效果展示】👇
✅ 飞书节点 (Feishu)
这块最繁琐,但你只用配一次。
搞定飞书应用:
- 打开
https://open.feishu.cn/,登录,进“开发者后台”。 - “创建应用”,随便填个名,比如“自媒体动态监控”。
- 左侧菜单“权限管理”,搜“多维表格”,开通所有权限(读取、写入、编辑...)。
- 左侧菜单“应用发布”,创建版本,“确认发布”。
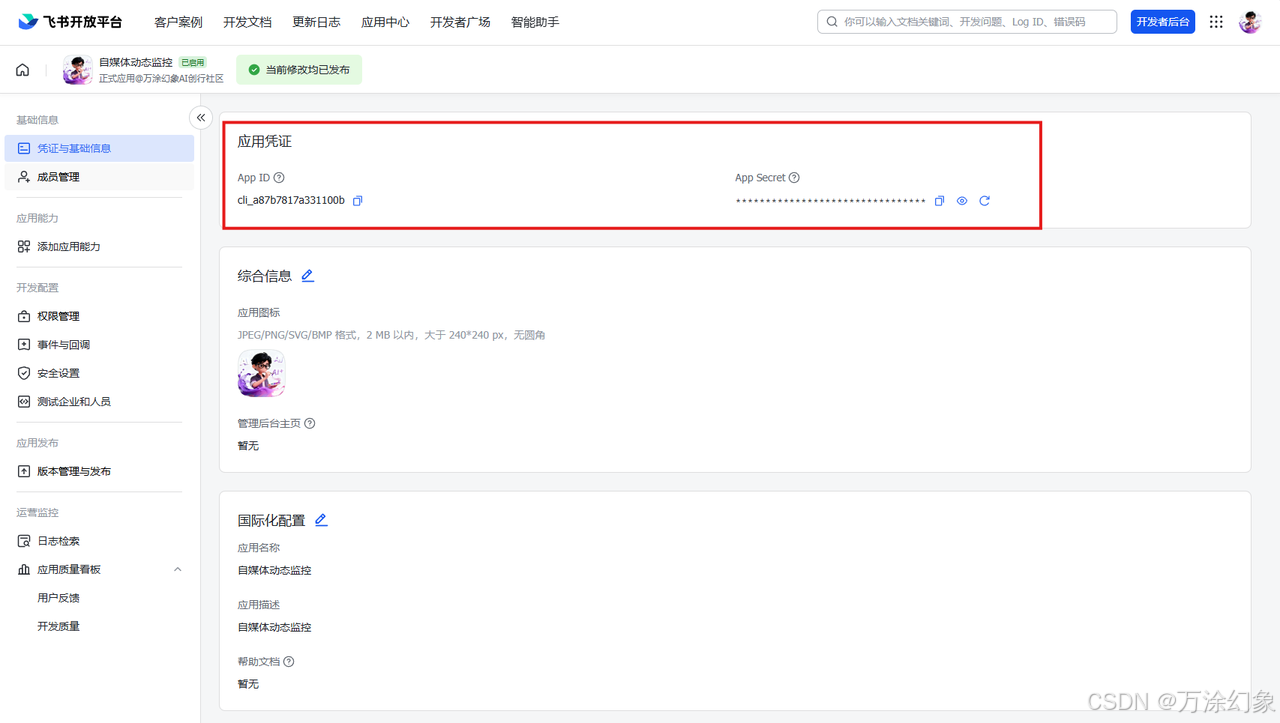
- 左侧菜单“凭证与基础信息”,把
App ID和App Secret复制出来,存好。
搞定多维表格:
-
在你的飞书里,新建一个多维表格。或者公众号私信“多维表格”,直接获取模板
-
关键: 在表格右上角“...”里,找到“应用”,把你刚发布的“自媒体动态监控”添加到这个表格里。
-
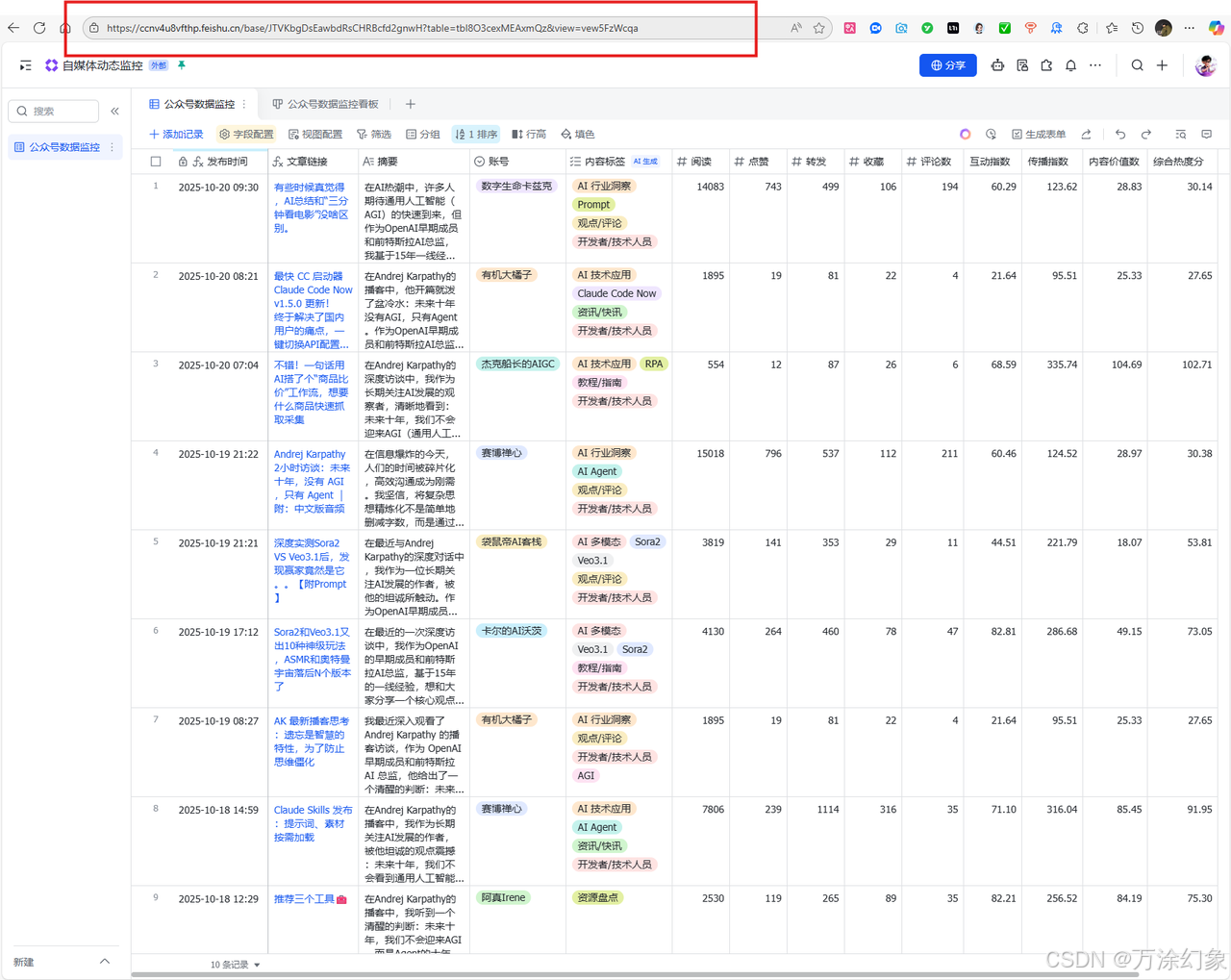
看浏览器地址栏,
https://.../base/GWgGb4Sw...bcU?table=tbl...bv&view=...-
base/后面?前面那串 (GWgGb4Sw...bcU),是你的 Base Token (或叫 App Token)。 -
table=后面&前面那串 (tbl...bv),是你的 Table ID。
-
-
把这俩也复制出来。
配置n8n节点:
-
回到n8n,双击“飞书”节点。
-
【关键区别】 n8n的节点配置分为两部分:“凭证”和“参数”。
-
Credentials (凭证): 这是n8n用来加密存储
App ID和App Secret的地方。-
点击“新建”,它会弹出一个新窗口。
-
把你从飞书开发者后台拿到的
App ID和App Secret直接粘贴进去,然后保存。 -
注意: 这两个值是用来创建n8n的安全凭证的,所以它们不放在我们前面的
Edit Fields节点里。
-
-
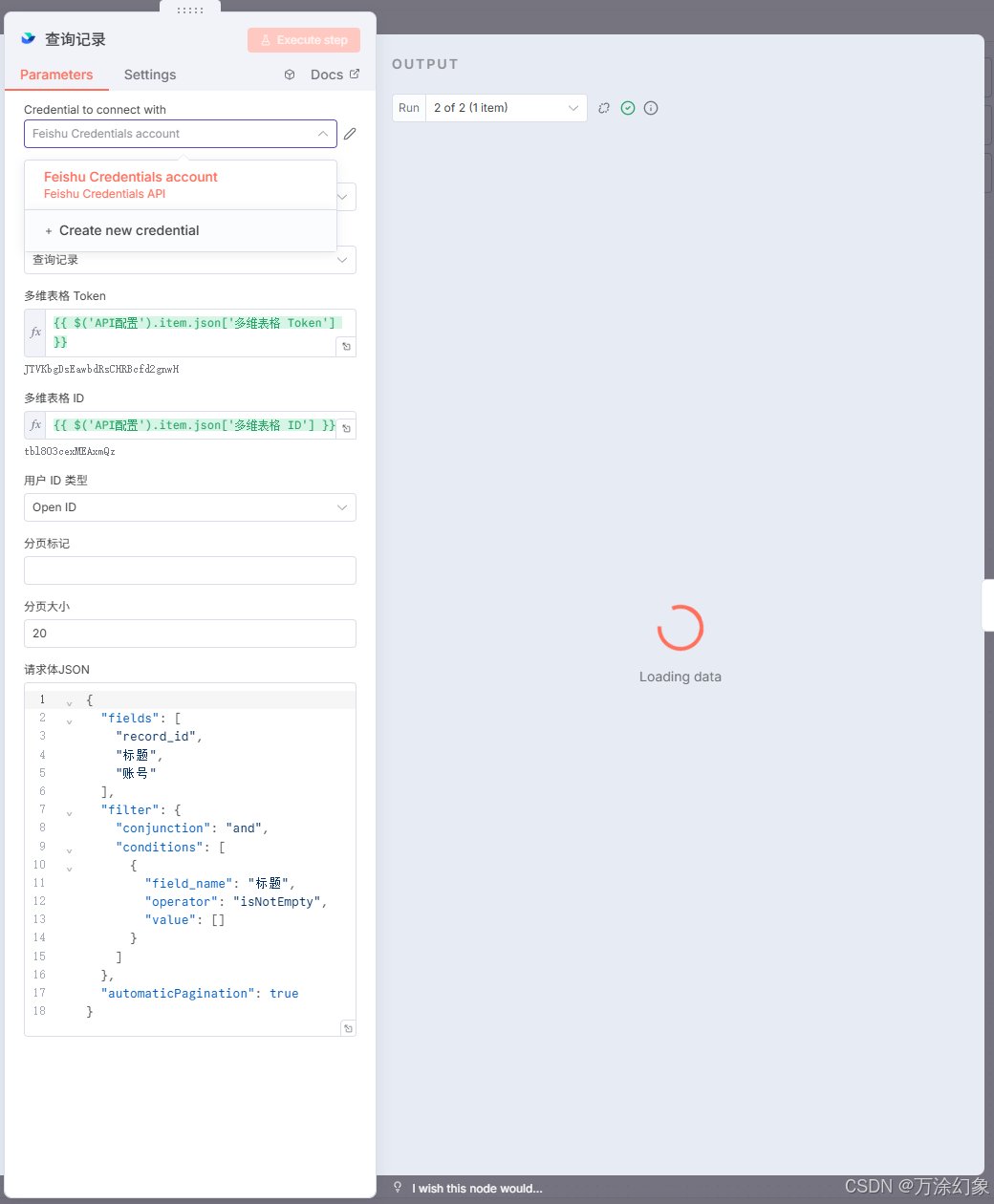
Base Token / Table ID: 这两个才是节点运行需要的“参数”,我们把这两个值放进“API配置”里。
-
在
Base Token字段,不要手动粘贴,而是点击旁边的“齿轮”图标,选择“添加表达式”(Add Expression)。 -
输入
{{ $json['多维表格 Token'] }}(或者你在Edit Fields里起的名字),让它从我们第一步的“配置中心”动态读取。 -
同理,在
Table ID字段,也用表达式{{ $json['多维表格 ID'] }}来引用。
-
搞定。现在你的n8n有权读写你的飞书了。
05|第四步:让数据“开口说话” (飞书多维表格分析)
数据存进来了,但还是死的。饼干哥哥的分析思路很好,咱们可以“拿来主义”。
✅ 用AI打标签
-
在飞书表格里,新建一个“智能标签”字段(或叫“AI生成选项”)。
-
用下面这个Prompt,让飞书AI自动给每篇文章分类。
🎯 让飞书多维表格AI自动给文章“归档分类”
【饼干哥哥的原创提示词】👇
## 角色
你是一名专业的 AI 内容分析师。你的任务是深入阅读并理解一篇文章,然后根据我提供的多维内容标签体系,为这篇文章精准地打上一组关键词标签。
## 任务
分析下方提供的文章全文,并从以下四个维度中,为每个维度选择 1-2 个最贴切的标签。最终输出一个包含所有选定标签的 JSON 数组(一个简单的字符串列表)。
## 标签体系说明
### 1. 主题域 (Topic Domain) - 文章的核心领域是什么?
- **AI 技术应用**: 侧重于使用AI解决具体问题,如自动化工作流、AI Agent、AI编程等。
- **AI 数据分析**: 侧重于使用AI进行数据处理、洞察和可视化。
- **AI 多模态**: 侧重于AI在图像、视频、音频等方面的生成与交互玩法。
- **AI 行业洞察**: 侧重于宏观新闻、趋势分析、大佬观点或产品评测。
### 2. 核心要素 (Core Element) - 文章具体讨论了什么工具、技术或概念?
- 从文章中提取最关键的 1-2 个工具、平台、技术或概念名称。
- 示例: "n8n", "GPT-4", "Midjourney", "Agent", "Prompt Engineering", "RAG"。
### 3. 内容形式 (Content Format) - 这篇文章是怎么写的?
- **教程/指南**: 提供详细的操作步骤,有明确的教学目的。
- **案例分析**: 深入剖析一个具体的项目或事件。
- **资源盘点**: 汇总整理一系列工具、资料或信息。
- **观点/评论**: 表达作者对某个主题的深度见解。
- **资讯/快讯**: 报道最新的行业动态或产品发布。
### 4. 目标读者 (Target Audience) - 这篇文章最适合谁看?
- **初学者/入门者**: 内容浅显易懂,适合新手。
- **开发者/技术人员**: 包含代码、API等技术细节。
- **产品/运营**: 关注产品设计、用户增长和运营效率。
- **营销/市场人员**: 关注内容创作和营销策略。
- **创业者/管理者**: 关注商业模式、战略和管理。 【预期效果展示】👇
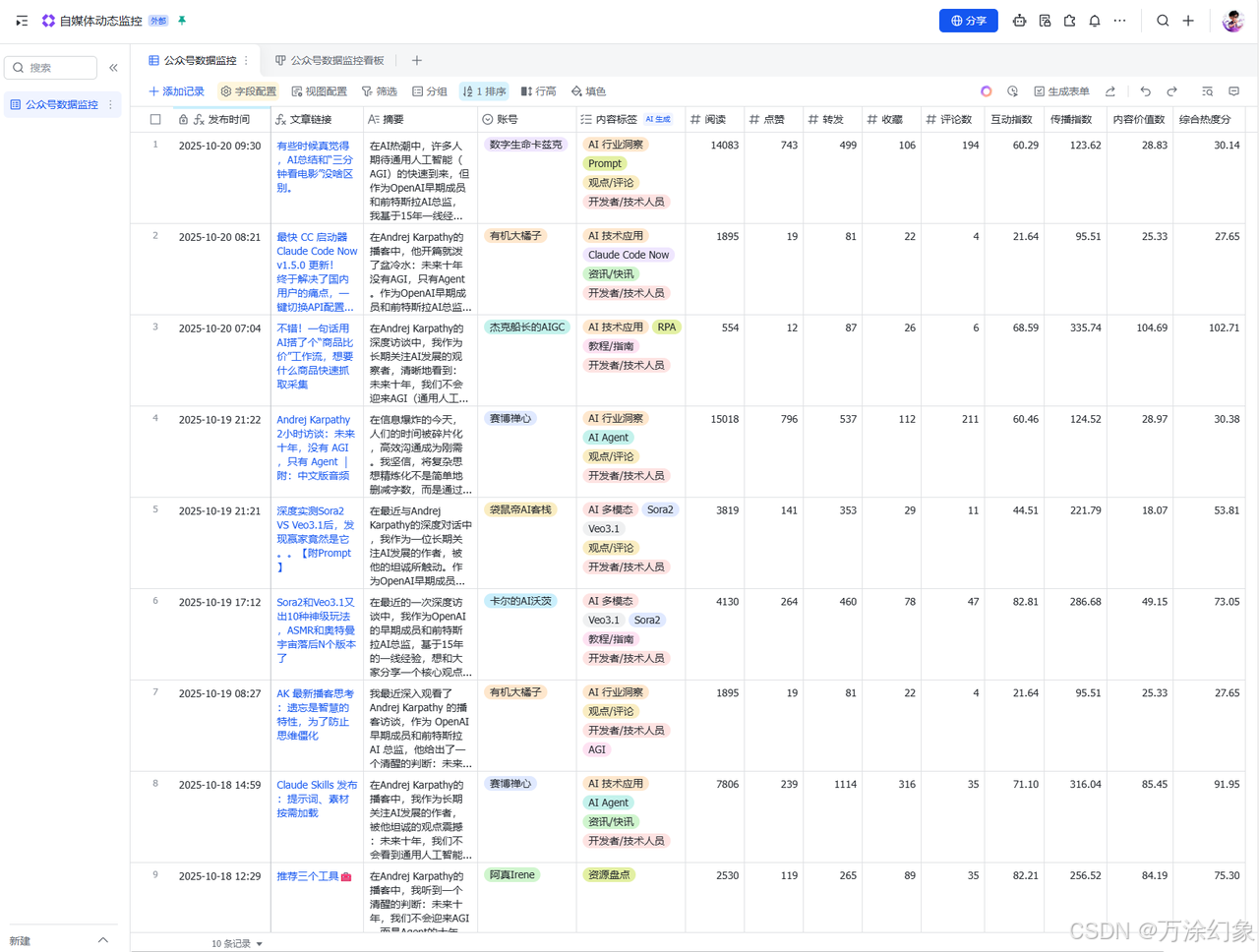
✅ 建立“黄金指标”
别只看“阅读量”,那都是虚的。在飞书里新建几个“公式”字段,计算真正的“爆款指数”。
-
互动率 (看内容吸不吸引人)
-
公式:
( {点赞数} + {在看数} ) / {阅读数} * 1000
-
-
传播指数 (看裂变能力,这是爆款核心)
-
公式:
( {转发数} * 2 + {在看数} ) / {阅读数} * 1000(转发权重给2,因为它最猛)
-
-
内容价值指数 (看干不干货)
-
公式:
( {收藏数} * 2 + {评论数} ) / {阅读数} * 1000(收藏权重给2,代表“想再看一遍”)
-
-
综合热度分 (一锤定音)
-
公式:
( {点赞数}*1 + {在看数}*2 + {评论数}*3 + {收藏数}*4 + {转发数}*5 ) / {阅读数} * 100
-
有了这些指标,你每天只需要打开飞书,按“综合热度分”或“传播指数”排个序。
过去24小时,哪个选题在“爆”,一目了然。
写在最后:别做“收藏家”,要做“系统工程师”
这个流程搭完,我心里那个“疙瘩”总算解开了。
我们最开始的那个冲动,是“哇,这个选题流好酷,我要一个”。这只是一个“收藏家”的思维。
但作为实践者,我们必须多问一句:“这个系统有‘病’吗?它跑起来会不会浪费我的资源?它够不够‘懒’?”
从“一键抓取”到“查重更新”,这看是一个小小的“IF”节点,在我看来,这是“脚本”和“系统”的根本区别。
一个“脚本”是短视的,它只管完成当下的任务。
一个“系统”是有远见的,它会考虑自己7x24小时运行下去的成本、效率和健壮性。
我们做AI落地,做自动化流程,就是在构建一个个这样的“系统”。
不要只满足于“它能跑”,要去追求“它跑得漂亮、跑得精明”。把时间花在设计这种“精明”的系统上,远比你手动去Excel里删重复数据,要值钱得多。
# 固定资源推荐
除了阅读文章,如果你希望有一个能随时提问、随时给答案的AI学习“陪练”,我把我积累的许多结构化知识,都放进了一个可以对话的AI知识库里。
很多朋友用过后觉得很方便,所以我把它的固定入口放在这里,希望能帮你更快地解决问题。
👉 点击直达:万涂幻象AI创行社区知识库
如果本文内容对您有启发,欢迎点个【赞】、【在看】或【转发】支持一下;也可以加个星标⭐,第一时间收到更多实战案例。
感谢您的阅读,我们下次再见👋!
#万涂幻象 #万涂幻象AI创行社区 #n8n #多维表格

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)