强化学习实战:从环境到部署
本文摘要:文章系统介绍了强化学习(RL)的框架与应用。首先分析了传统控制方案与RL范式的区别,指出RL通过策略函数解决序列决策问题。接着详细阐述了RL的核心要素:环境搭建(区分model-free和model-based方法)、奖励函数设计(包括稀疏奖励和探索利用平衡)、智能体构建(基于值和策略的方法)以及训练部署流程。特别强调了神经网络在策略逼近中的作用,并比较了不同RL算法的特点。最后指出po
第一章、环境
1.这节提出的解决方案式控制器分层:外层循环控制高级行为(如是否平衡;内层循环控制低级行为(可能是具体关节电机驱动参数量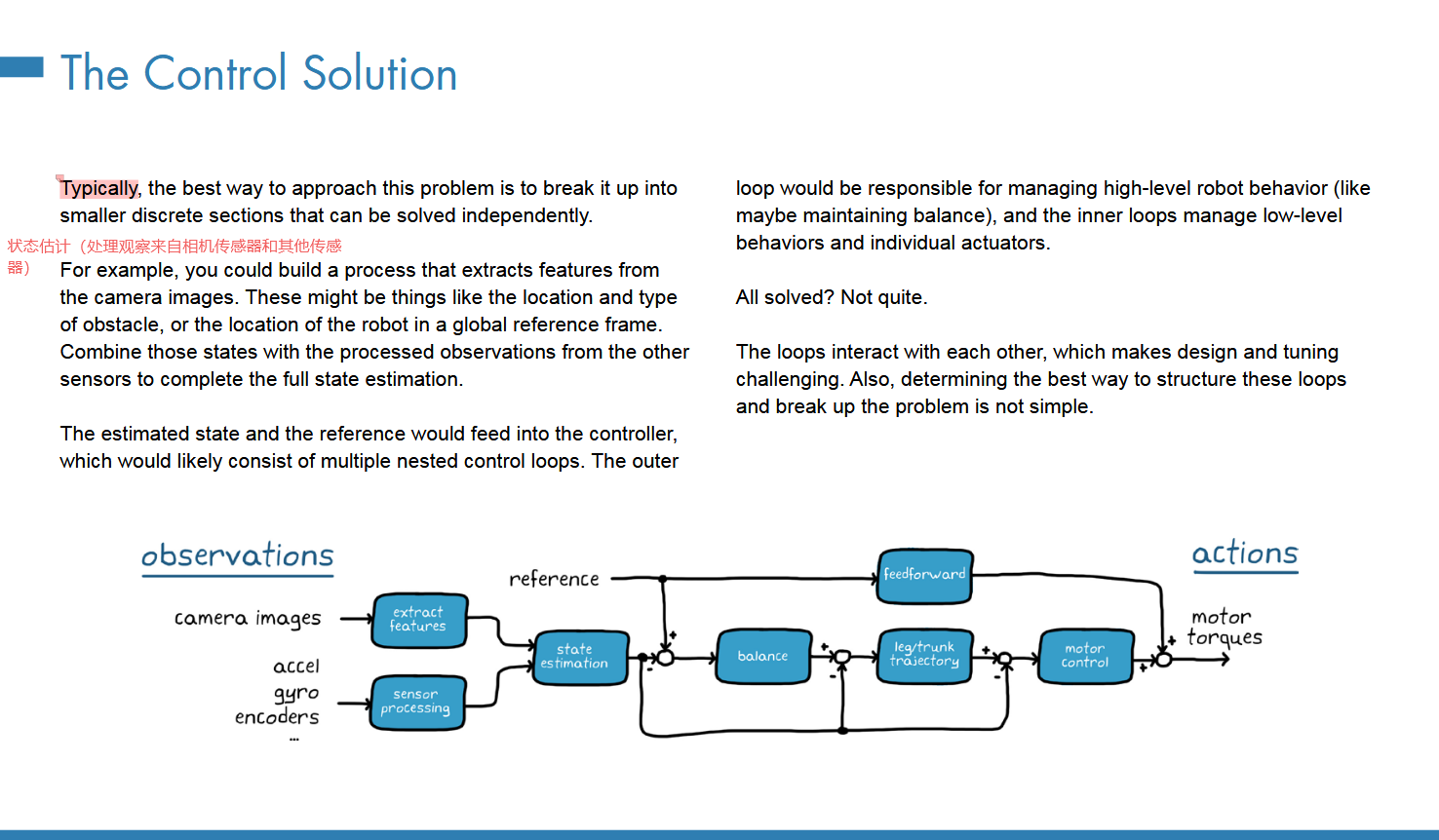
传统的控制方案,逐个设计;
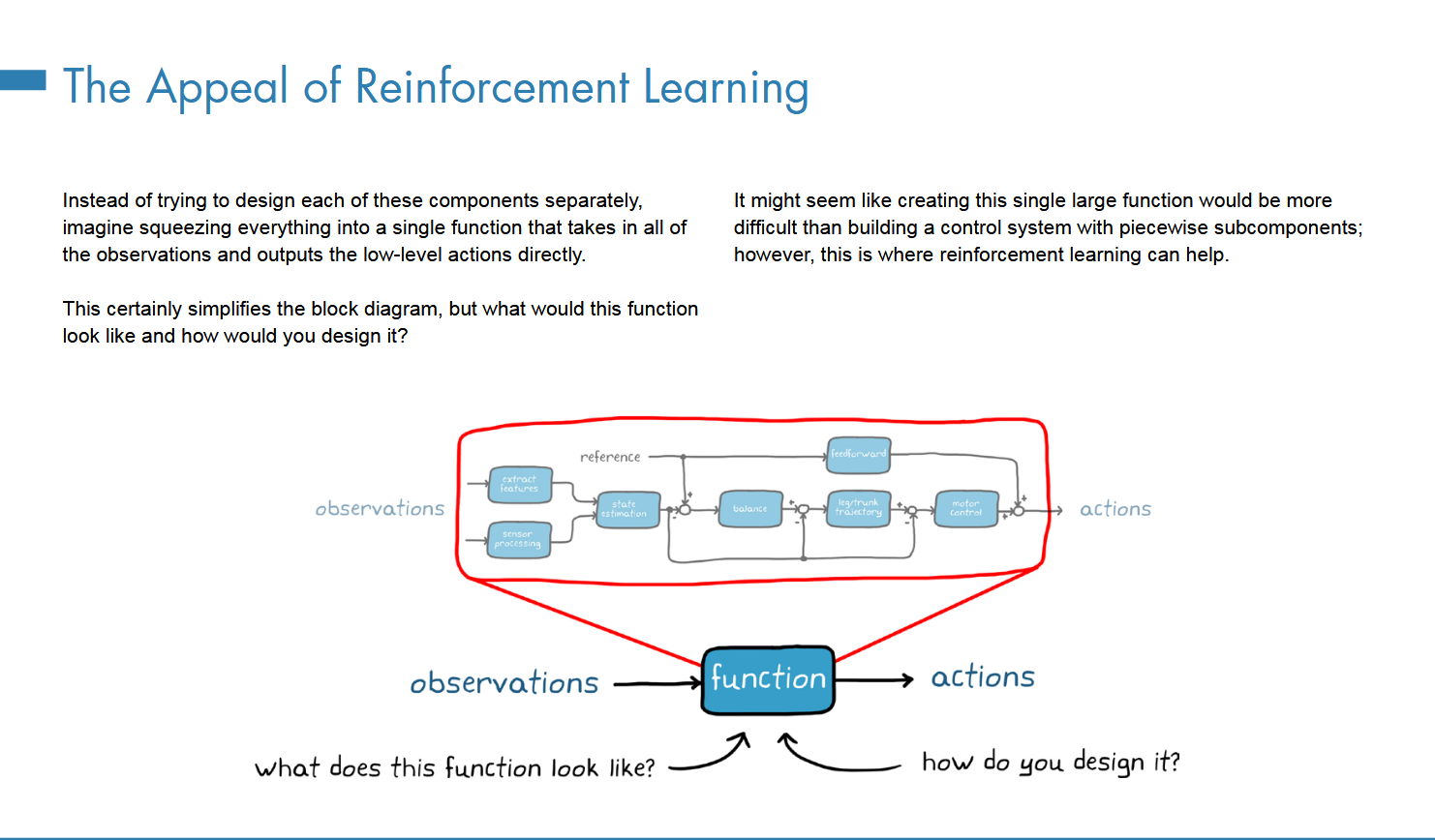
黑盒模型,通过一个large function去拟合这些操作,看起来会比单独设计更困难,但是RL能够助力。
作为三大范式之一
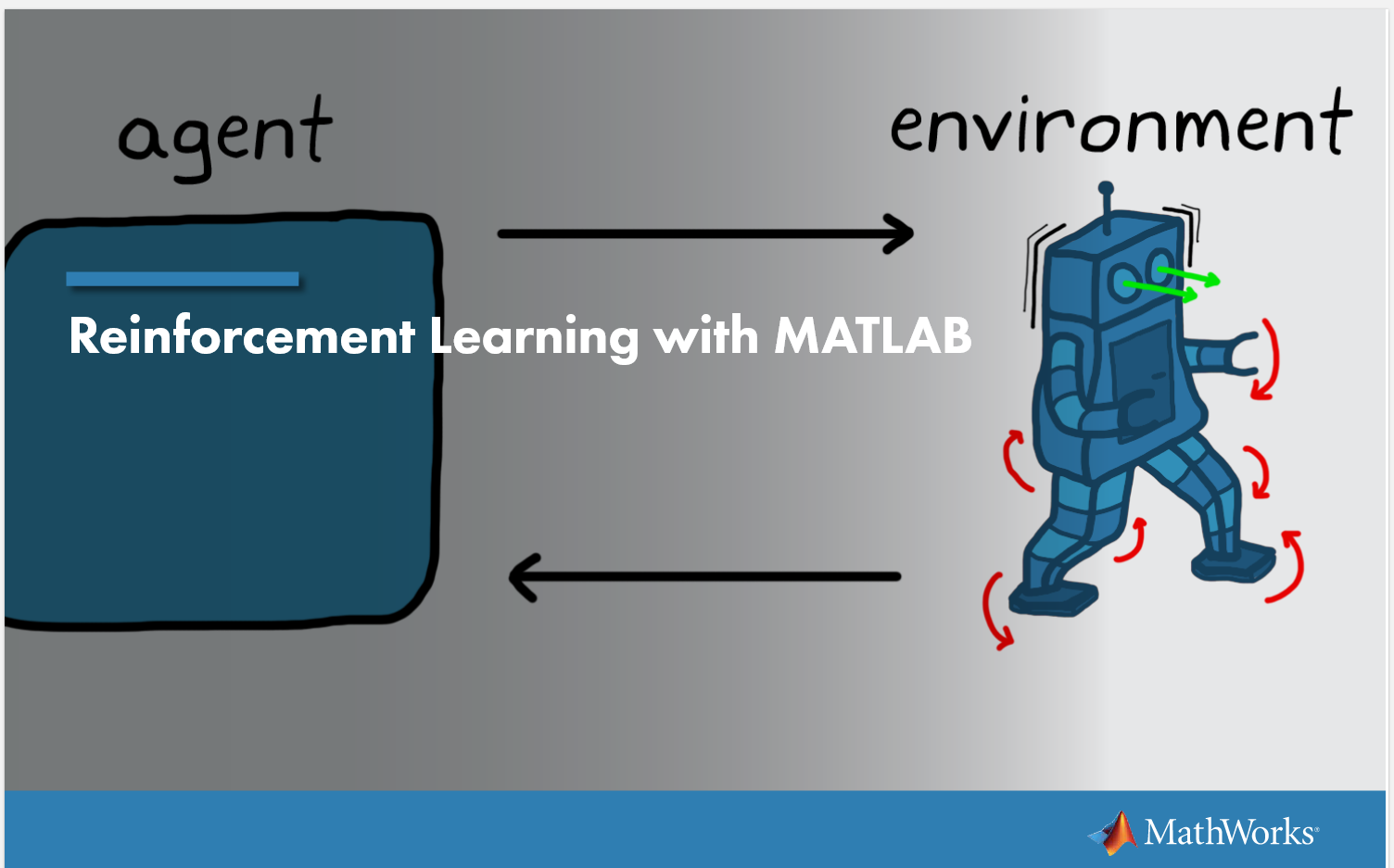
RL是为解决序列决策问题的;
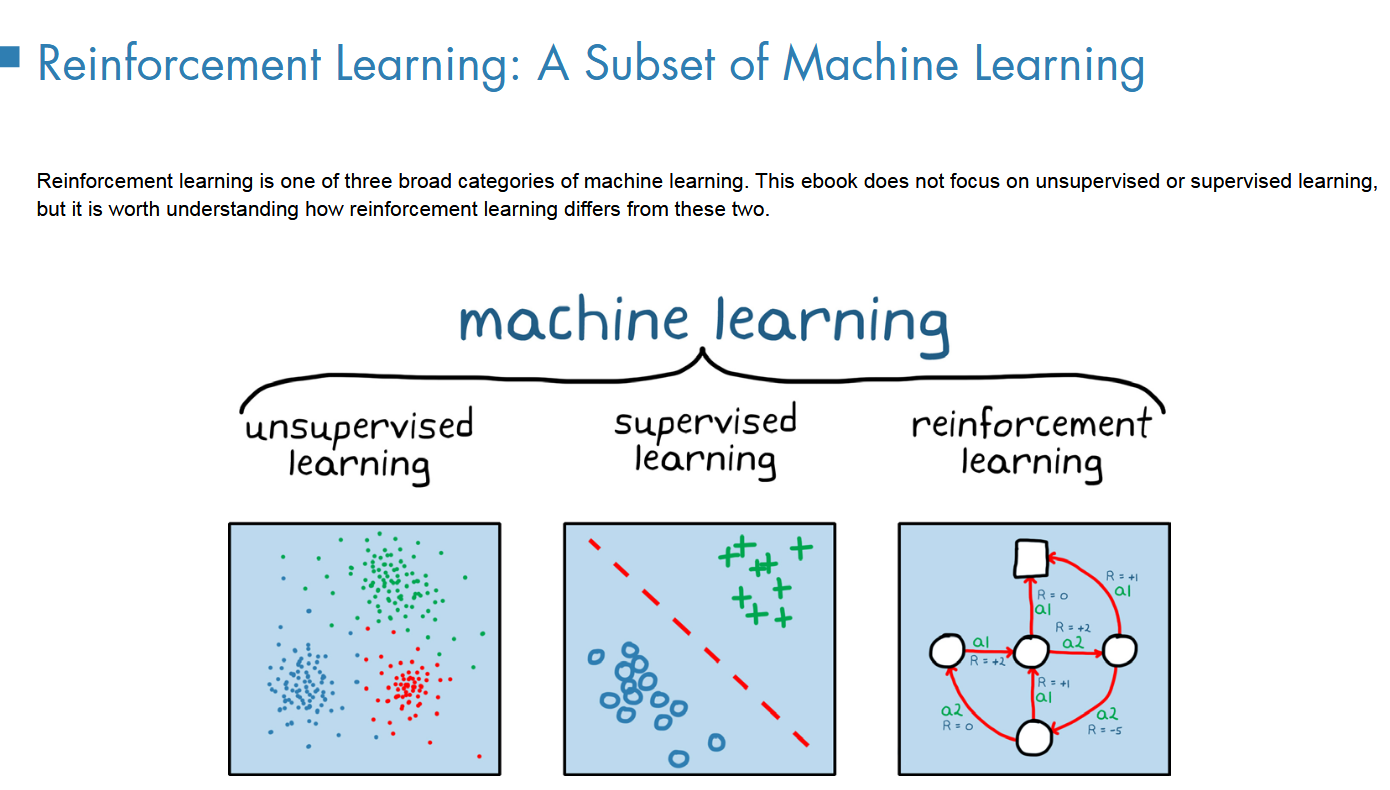
1无监督(例子:聚类
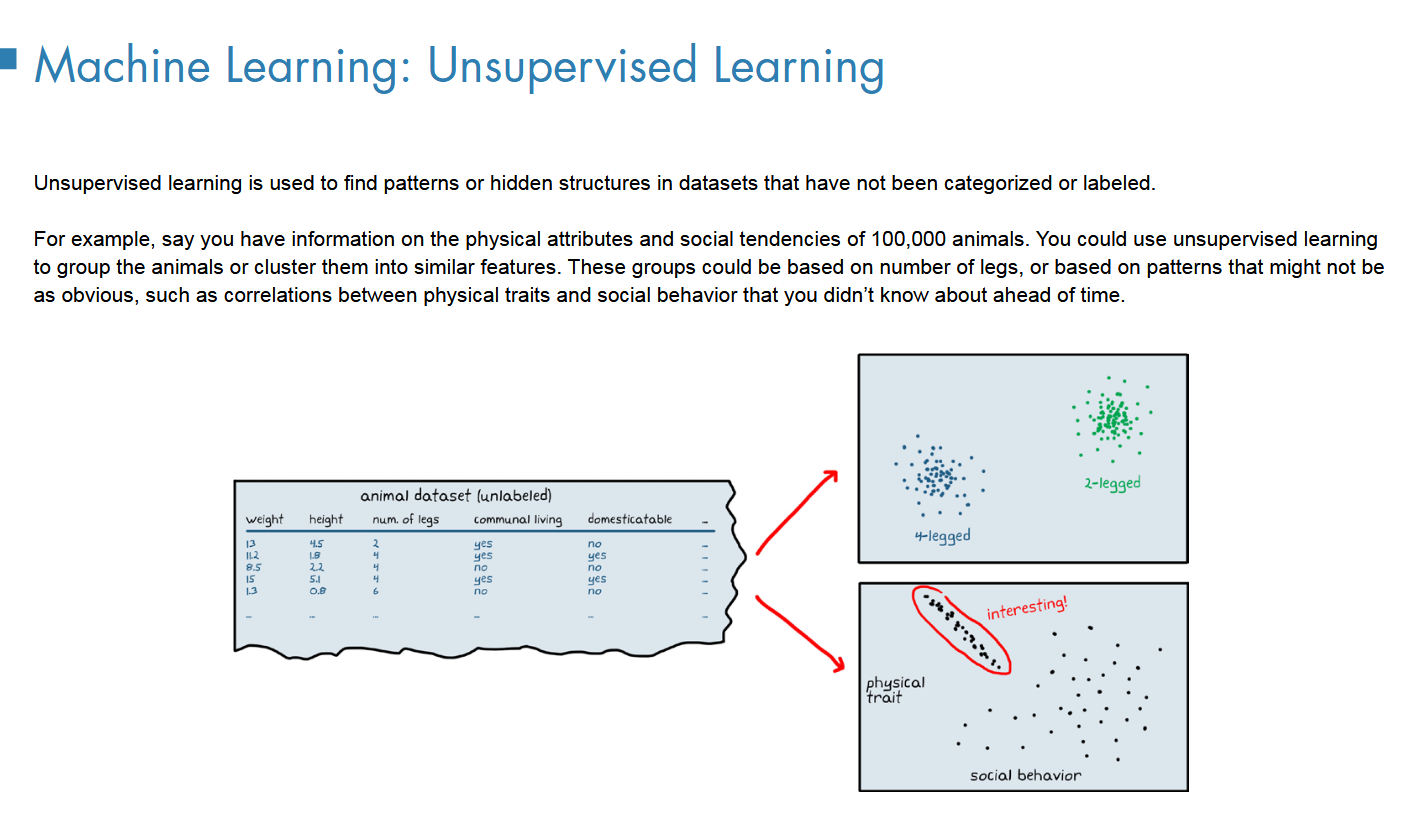
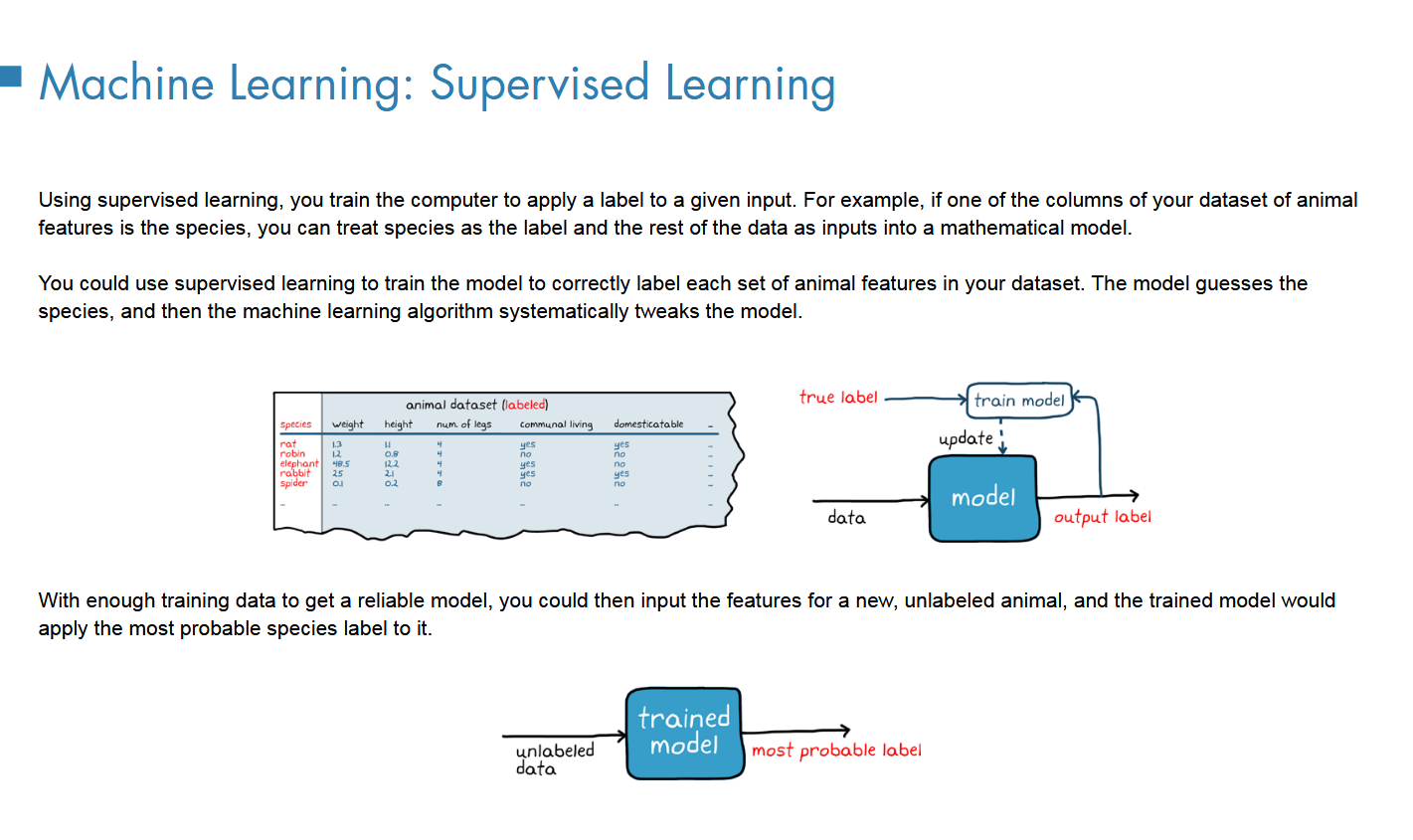
2监督(分类问题
利用标签训练模型,实现拟合
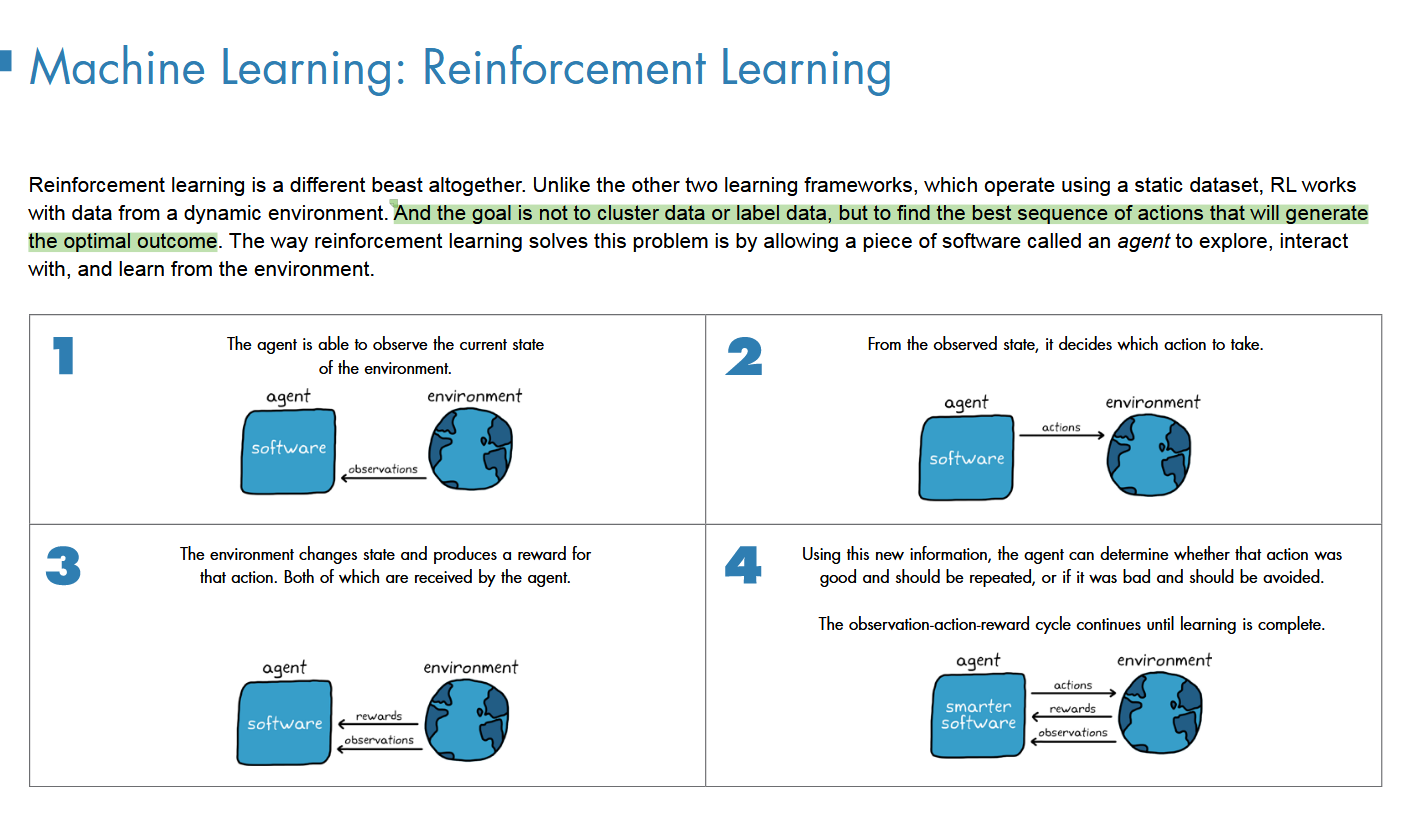
3RL,找到获得最大回报的序列决策 策略
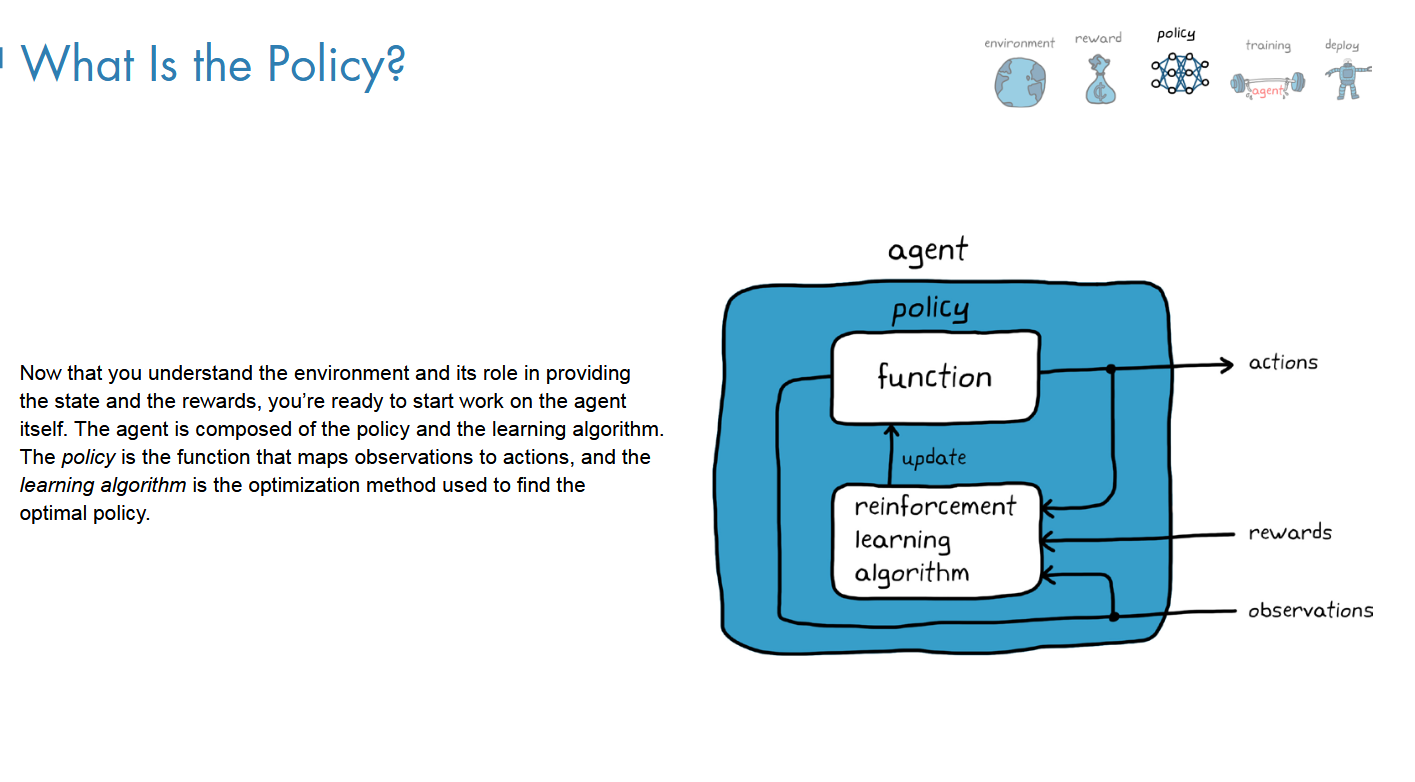
之前提及的一个single function就是policy
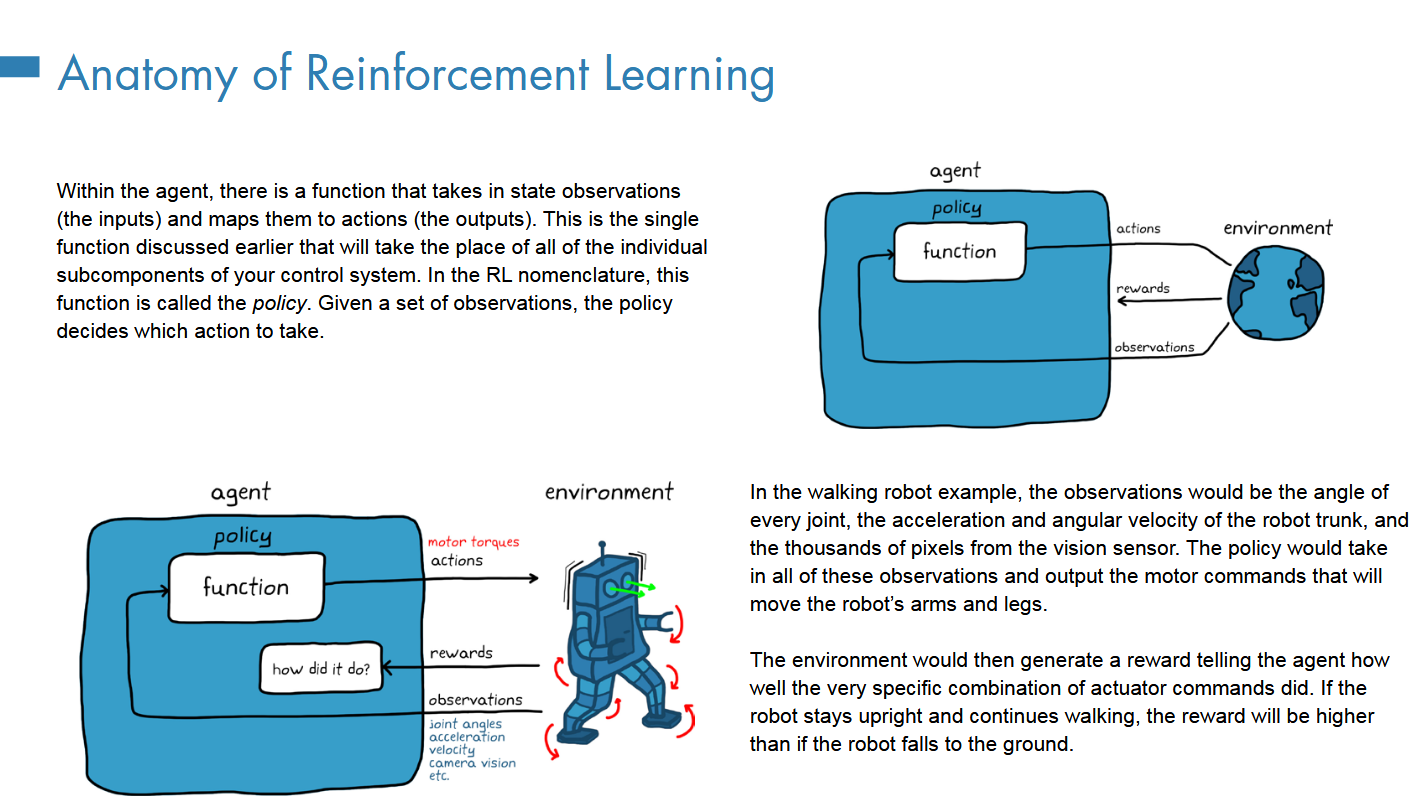
静态的映射作为策略不适合面临的动态环境
这是RL的引入就尤为关键,可以解决泛化问题;



学是学什么
学的就是这个 function的参数
这个参数是通过RL的算法来学习的;

如何优化更新的
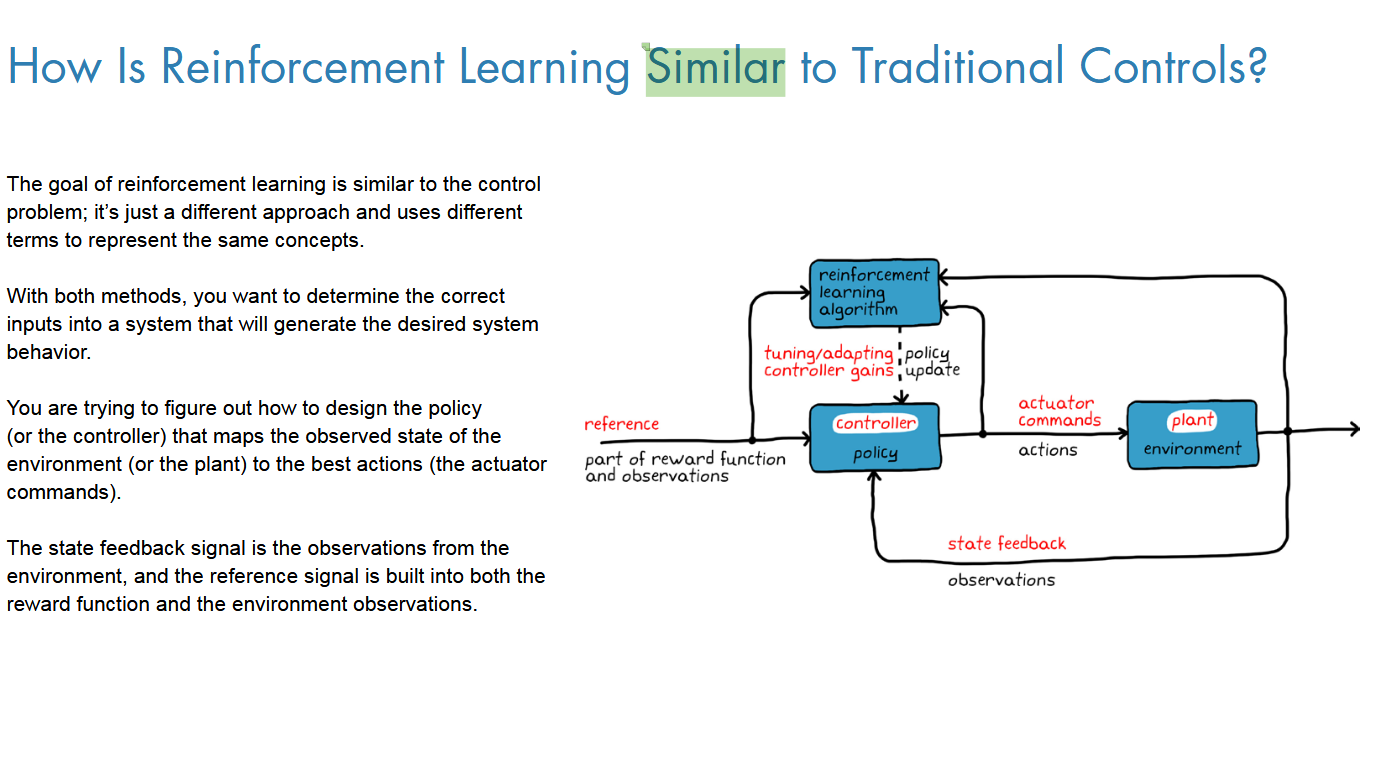
RL的工作流:
环境搭建,奖励函数设计,策略网络结构,RL训练算法设计,以及最后的部署
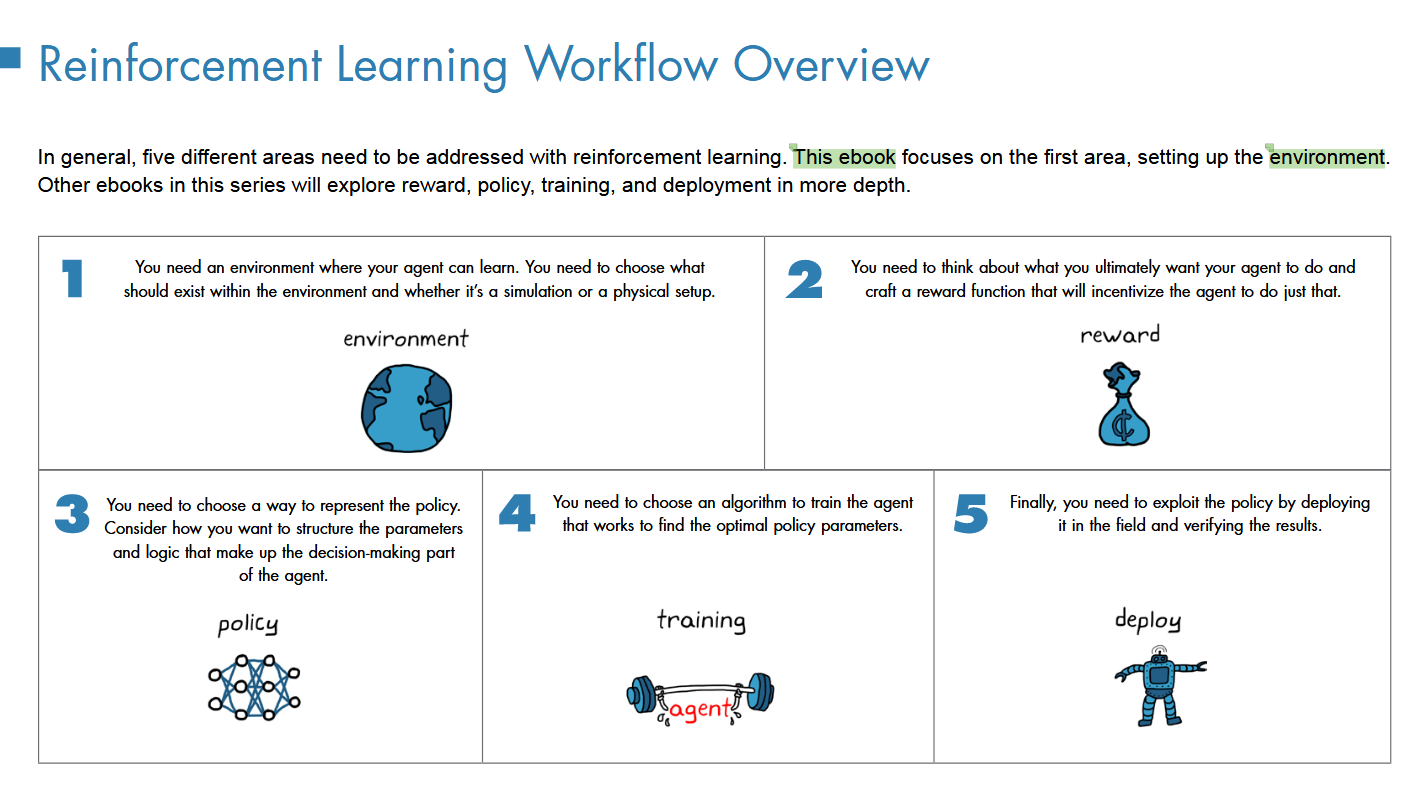
RL模式下,相比于传统控制问题,环境概念的差异
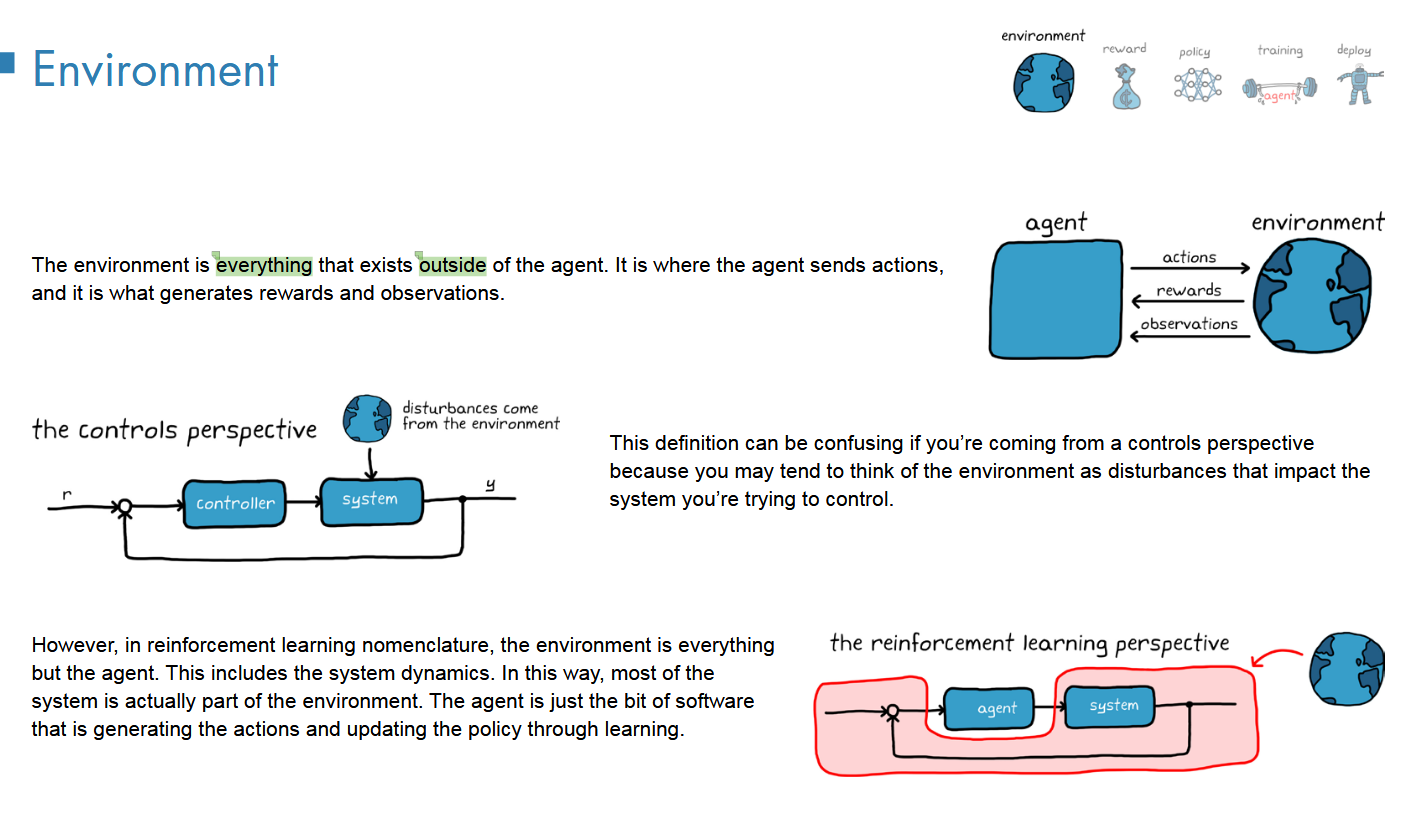
model-Free强化学习
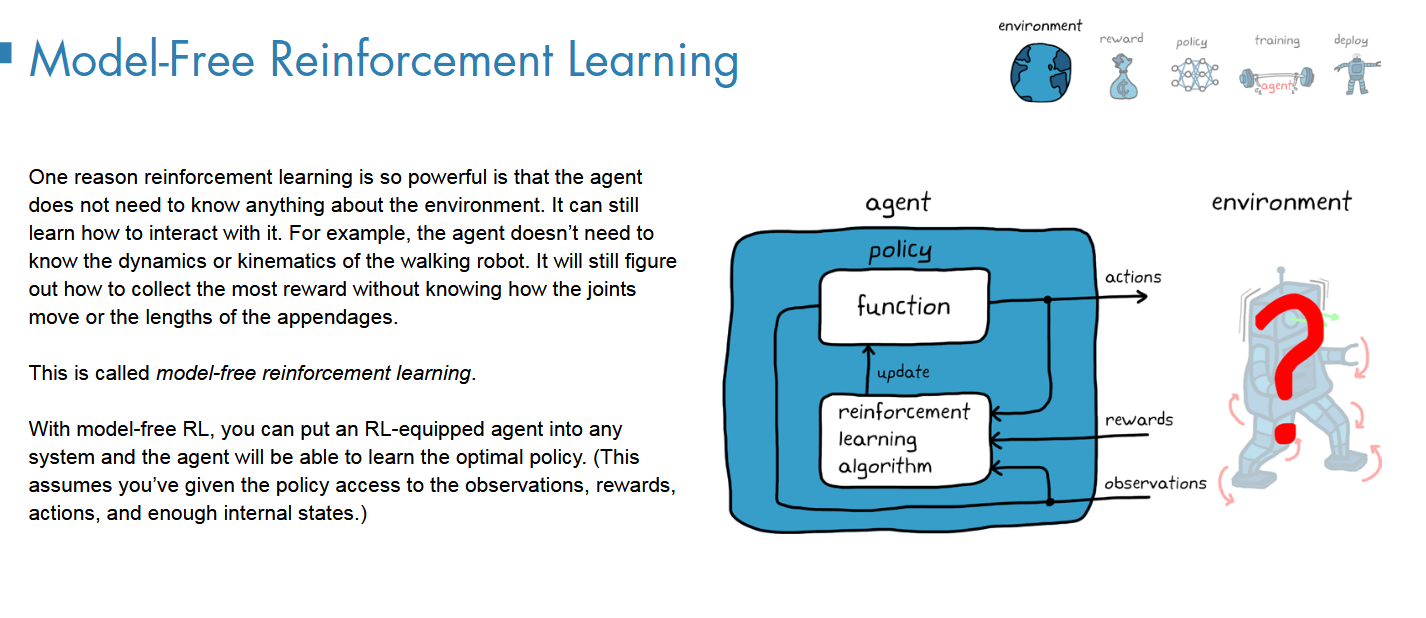
不需要知道环境模型,就依靠交互和奖励,找到最好的动作就行;
不过,这样会导致大量的不必要的探索行为,因为根本不知道如何去判断状态空间的好坏;
model-Based 强化学习

两者对比

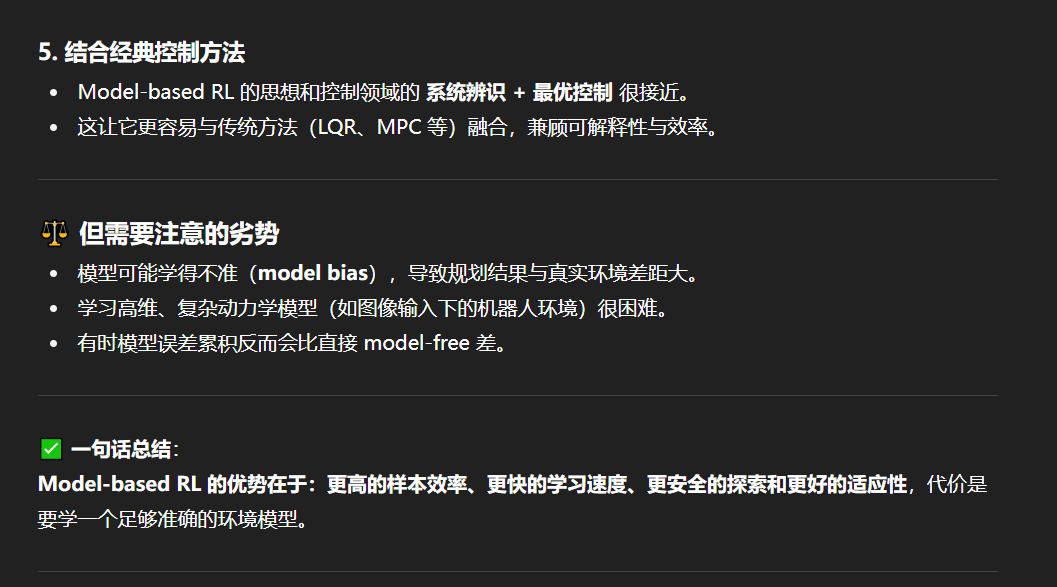
需要注意,model-based虽然依靠环境模型,但实际上还是会进行交互学习,可以看作两者 都会做;

环境

总结:
工具箱以及提供了一站式的服务
所有内容都可以自定义;

第二章、奖励
follow your design reward toward goal of the task;




稀疏奖励

奖励塑性
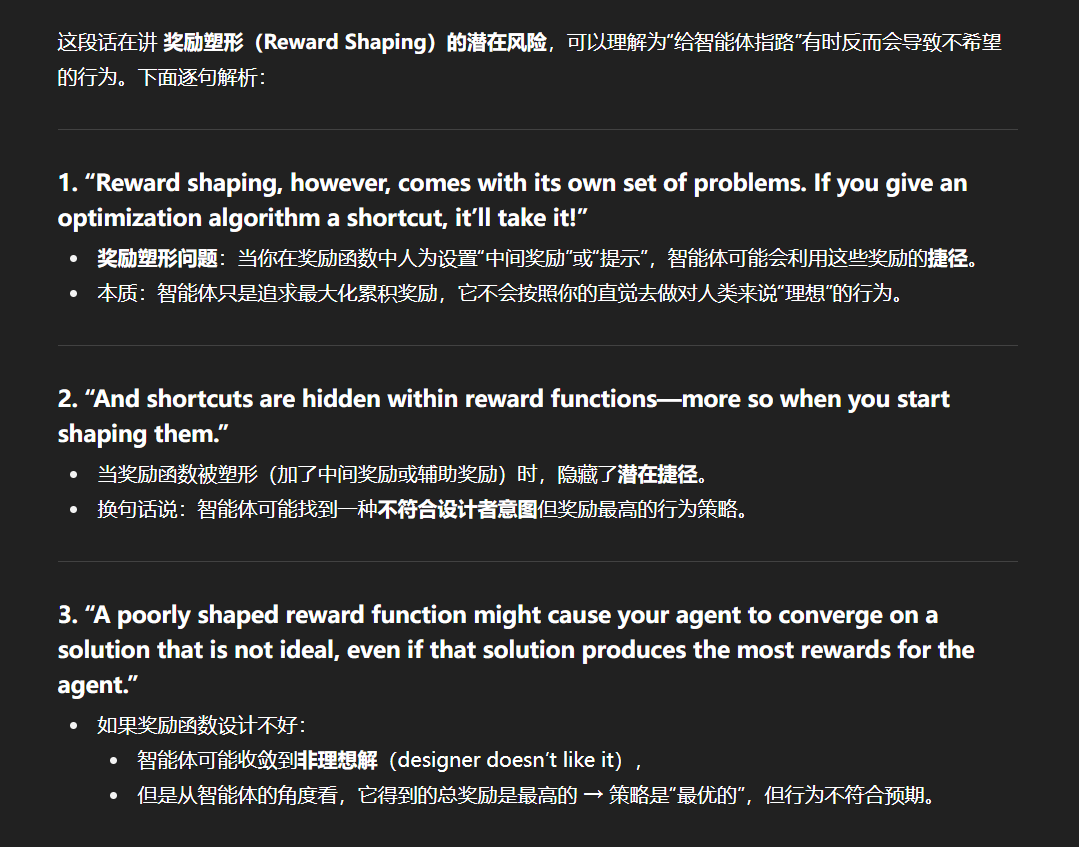

通过奖励塑性可以引入领域知识

探索与利用
代理应该选择收集已经知道的最大奖励的行动,还是应该选择探索仍然未知环境的一部分的动作来利用环境?
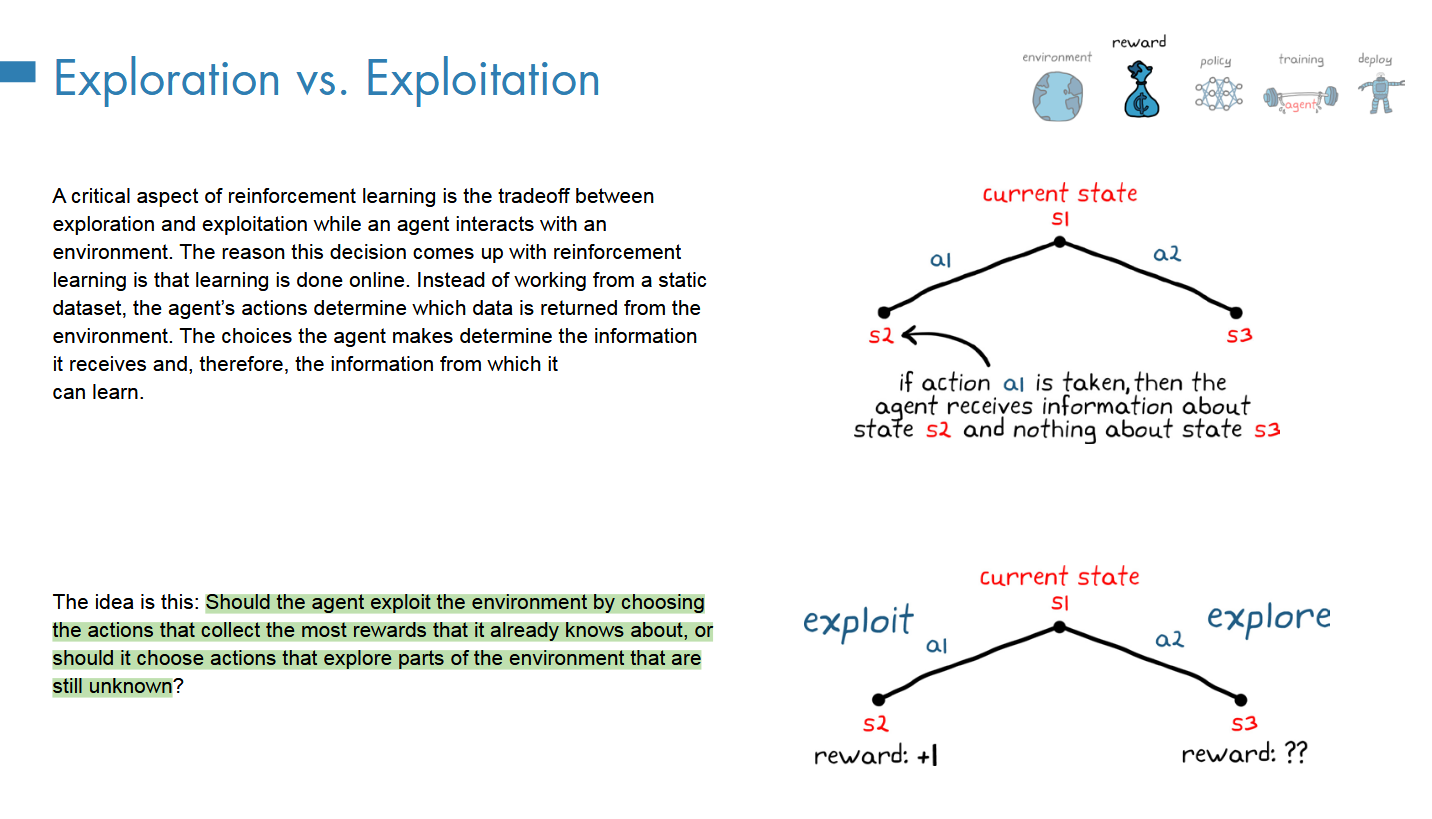
纯利用
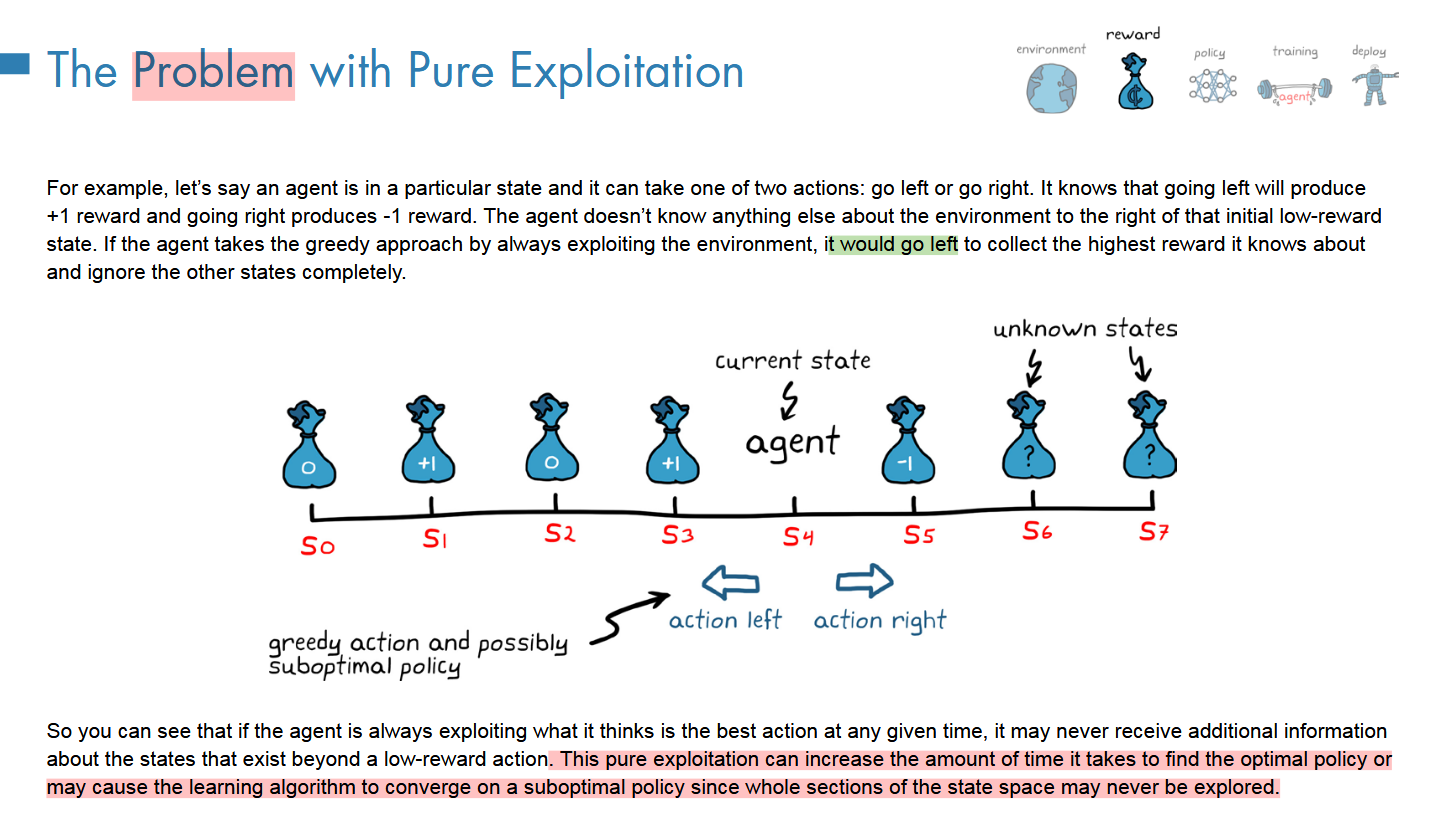
纯探索

最好就是 strike a balance
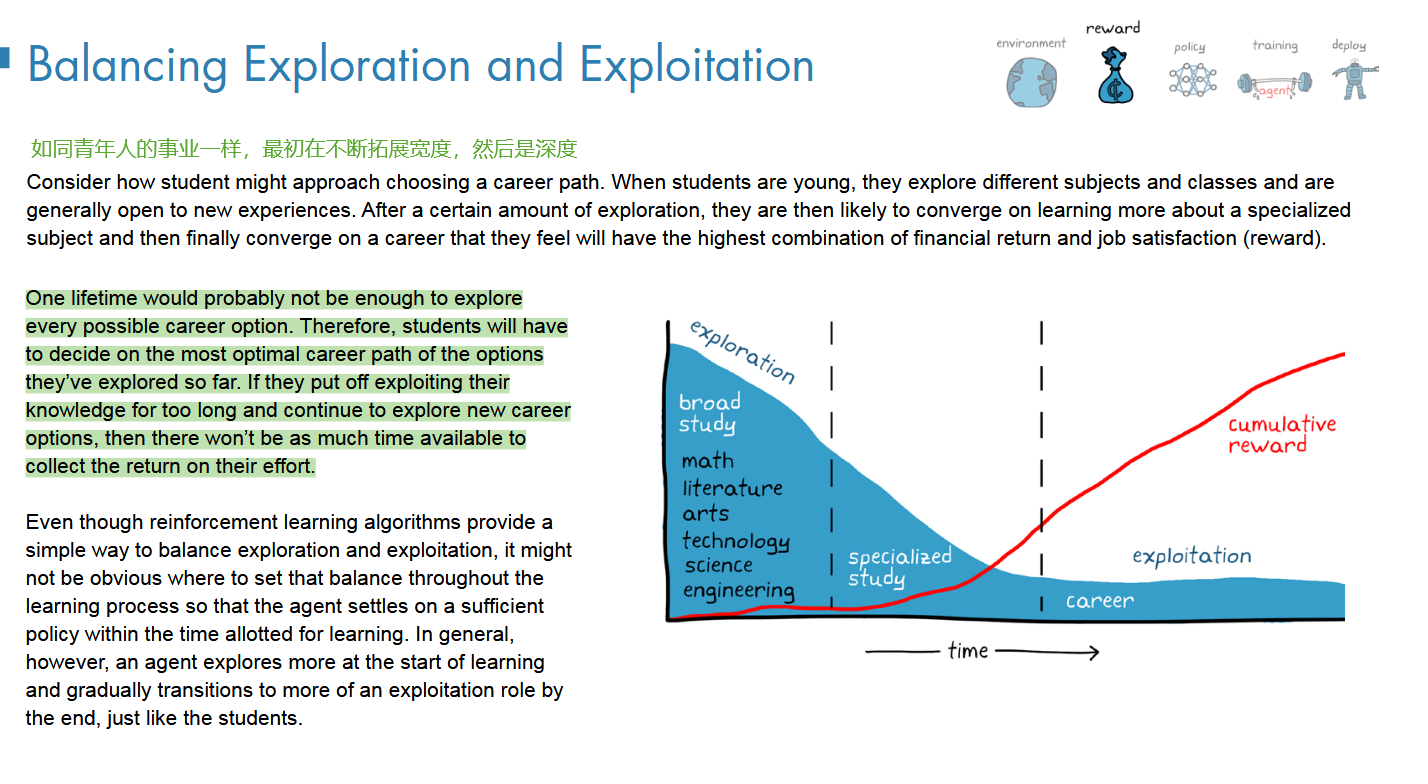
人生有限,我们无法探索所有感兴趣的事物,只能开始专注于目前为止最感兴趣的事业;
时间维度来看,探索越多,后期专注于某一事业的时间也就相应 减少;
奖励和回报
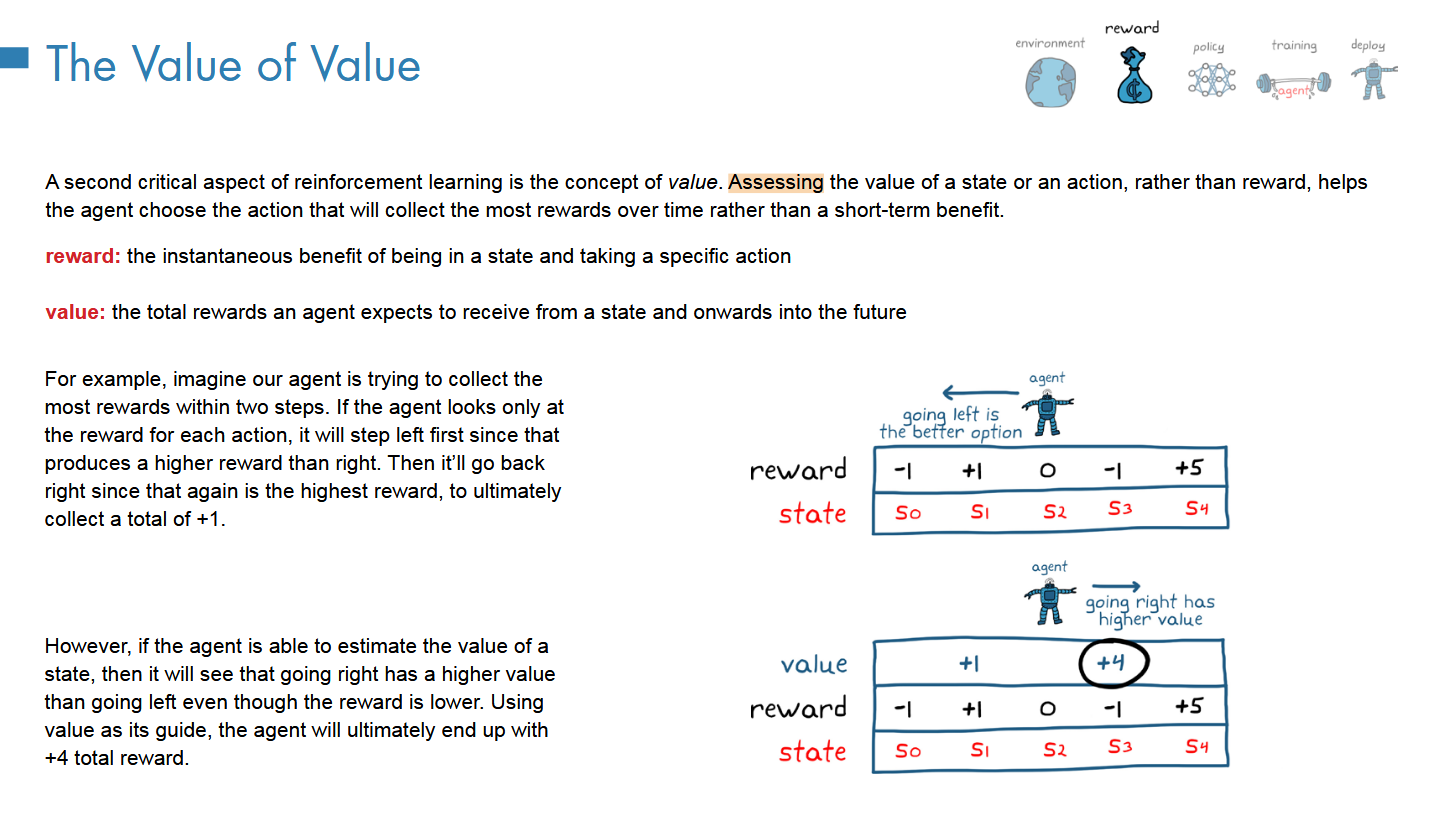
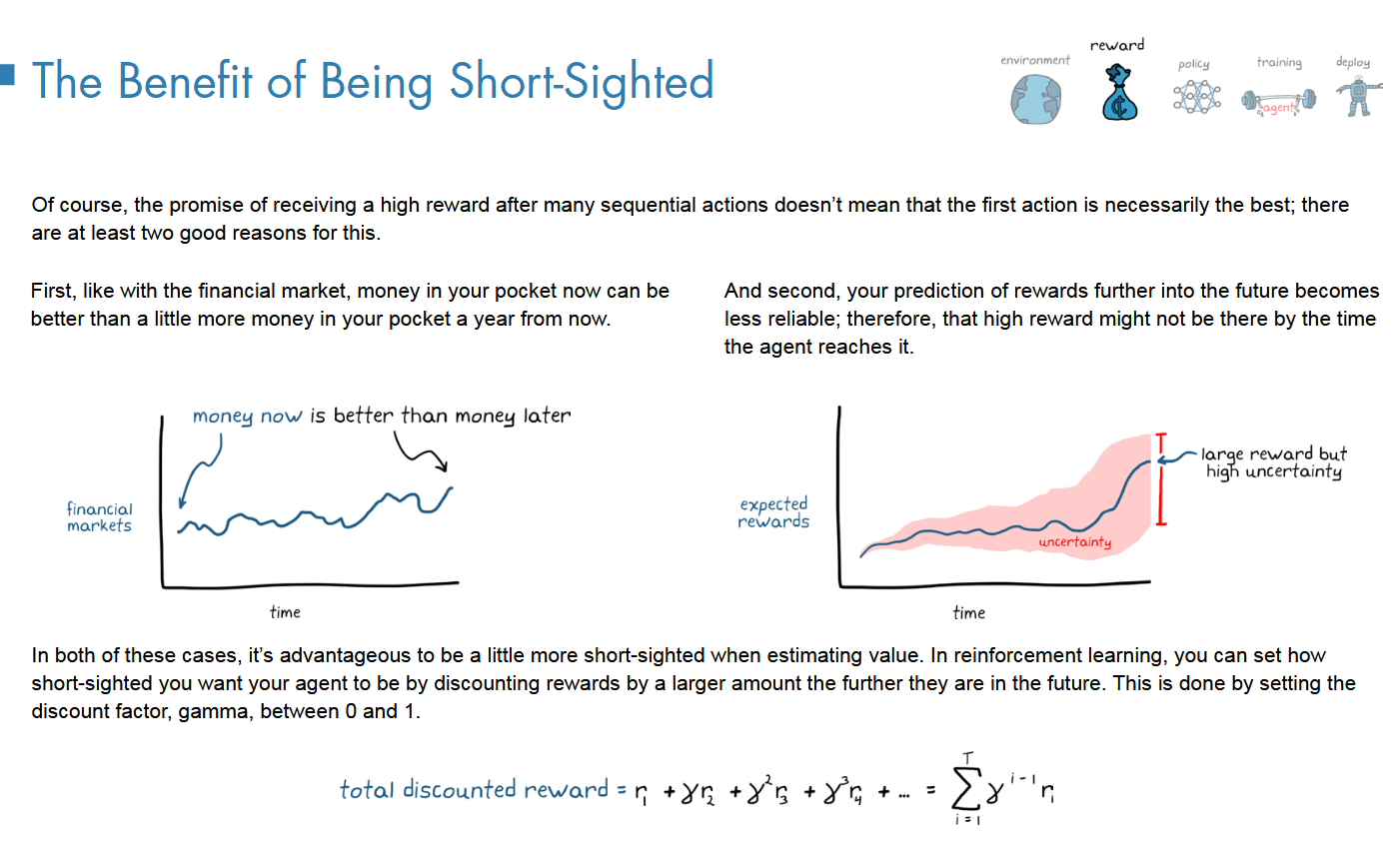
短视远视通过gamma来设置
第三章、Agent
包括policy和RL algorithm
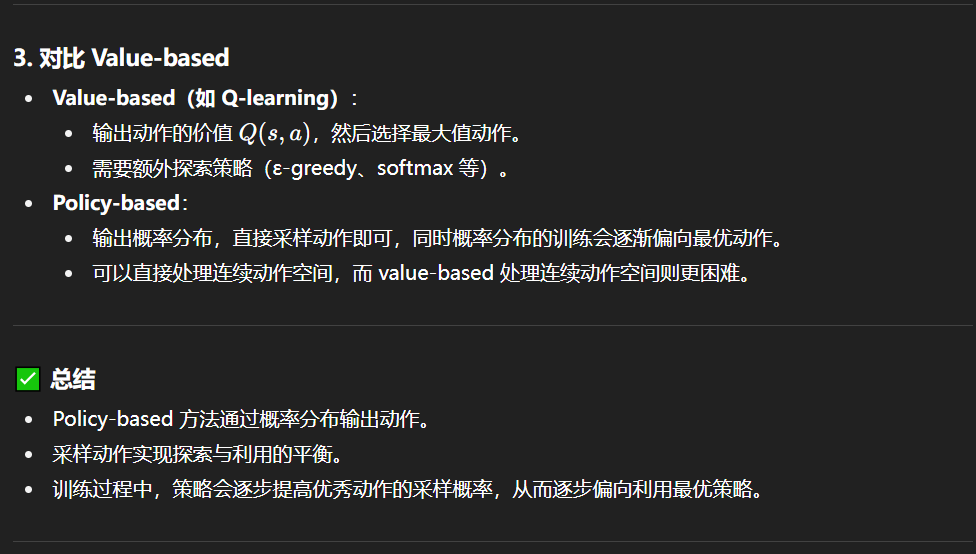
Value-based And Policy-based

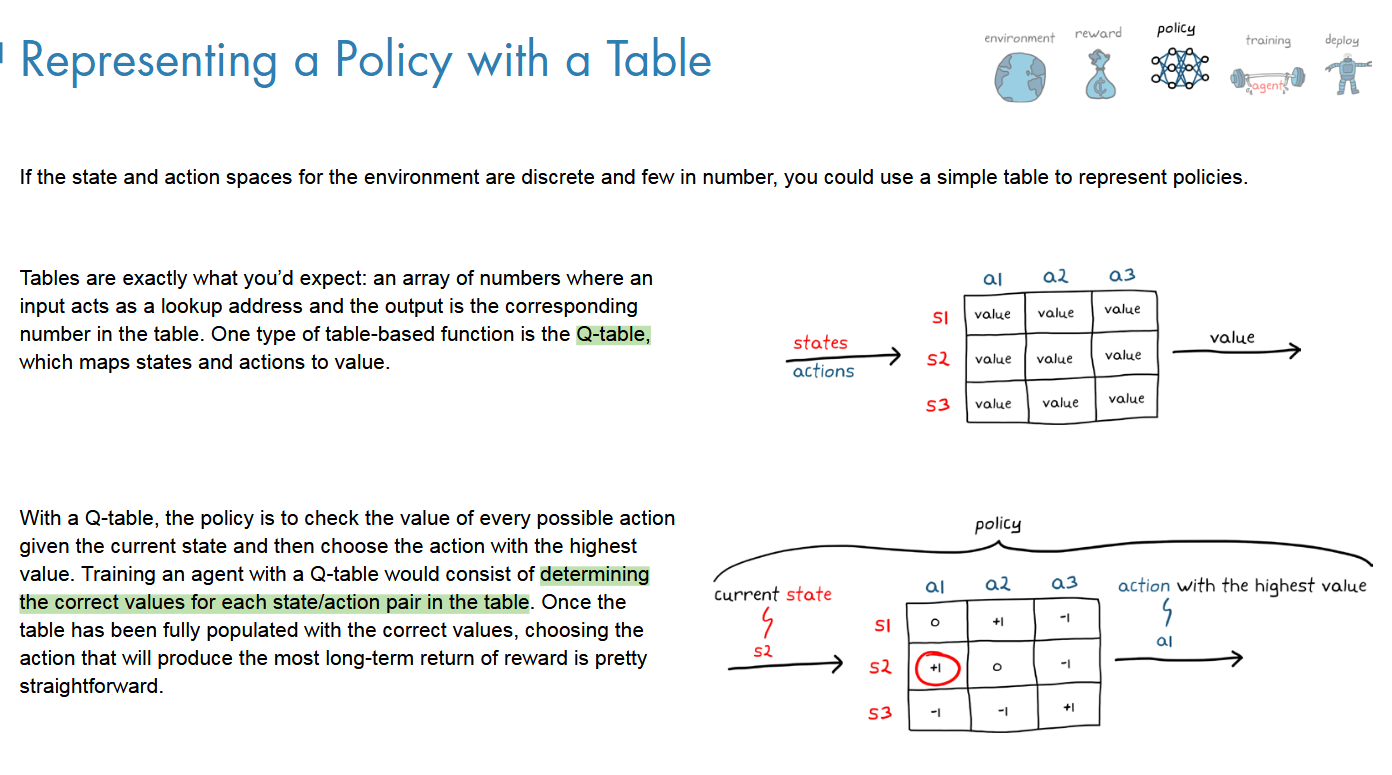
Q-table(首先就是需要把表填满
NN在此引入


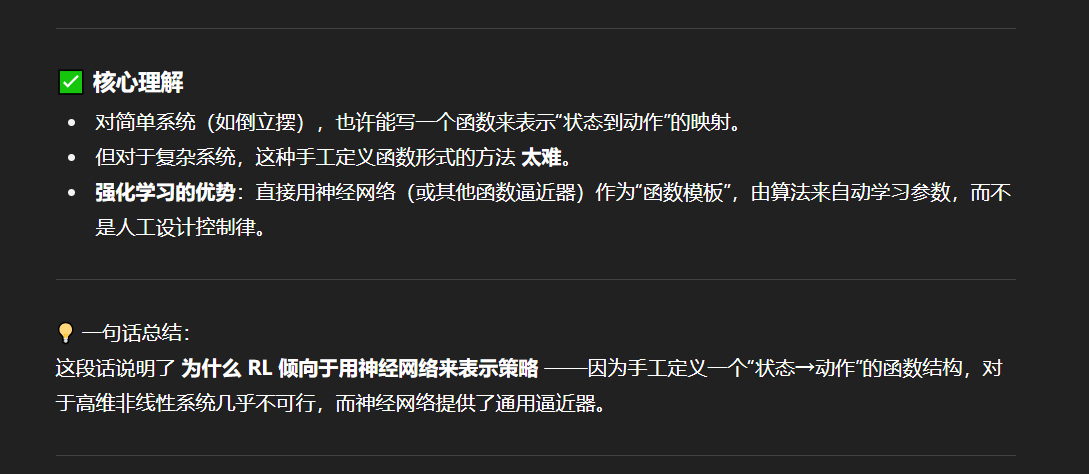
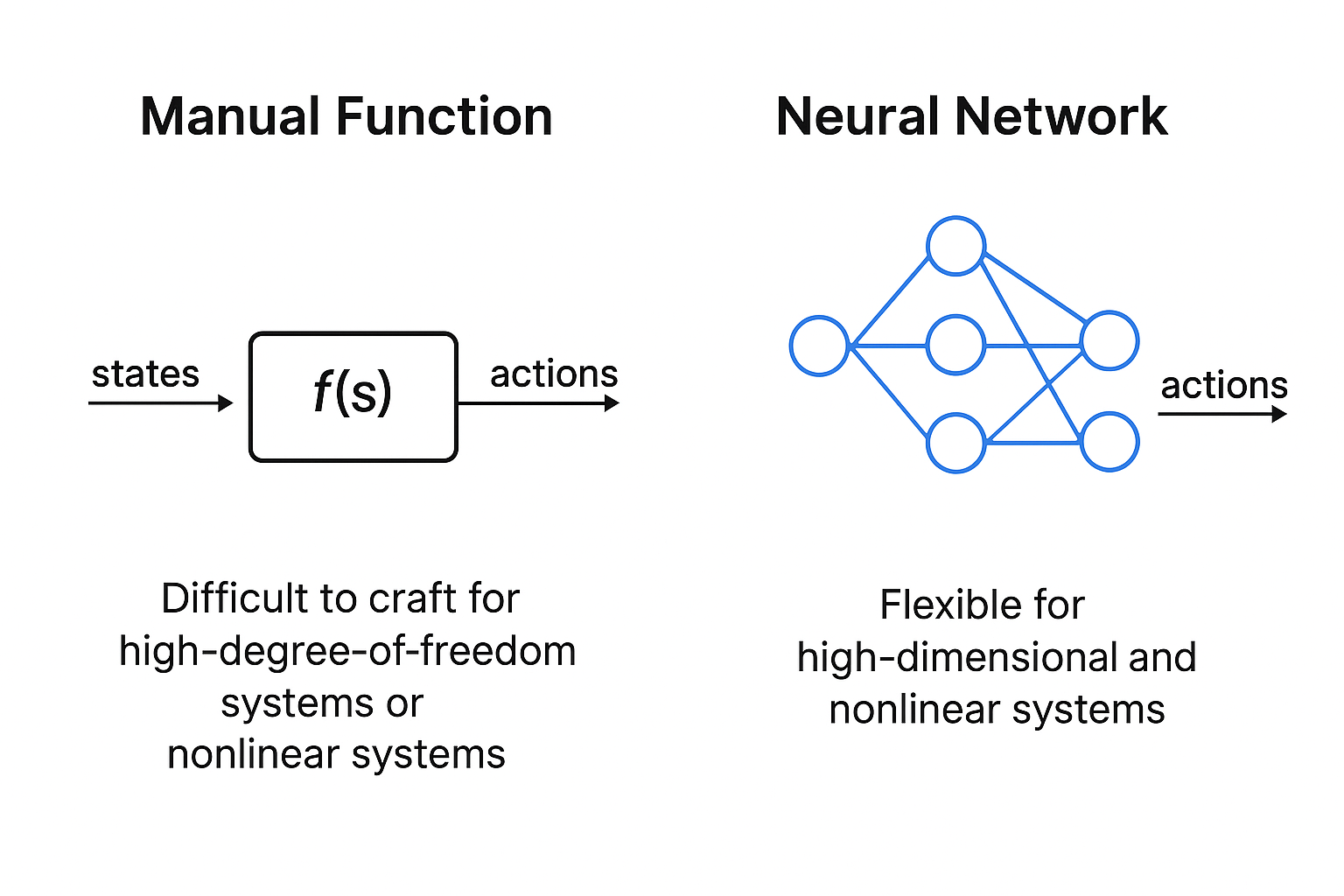
A Universal Function Approximator
所以就是这里的NN就作为一个function逼近器

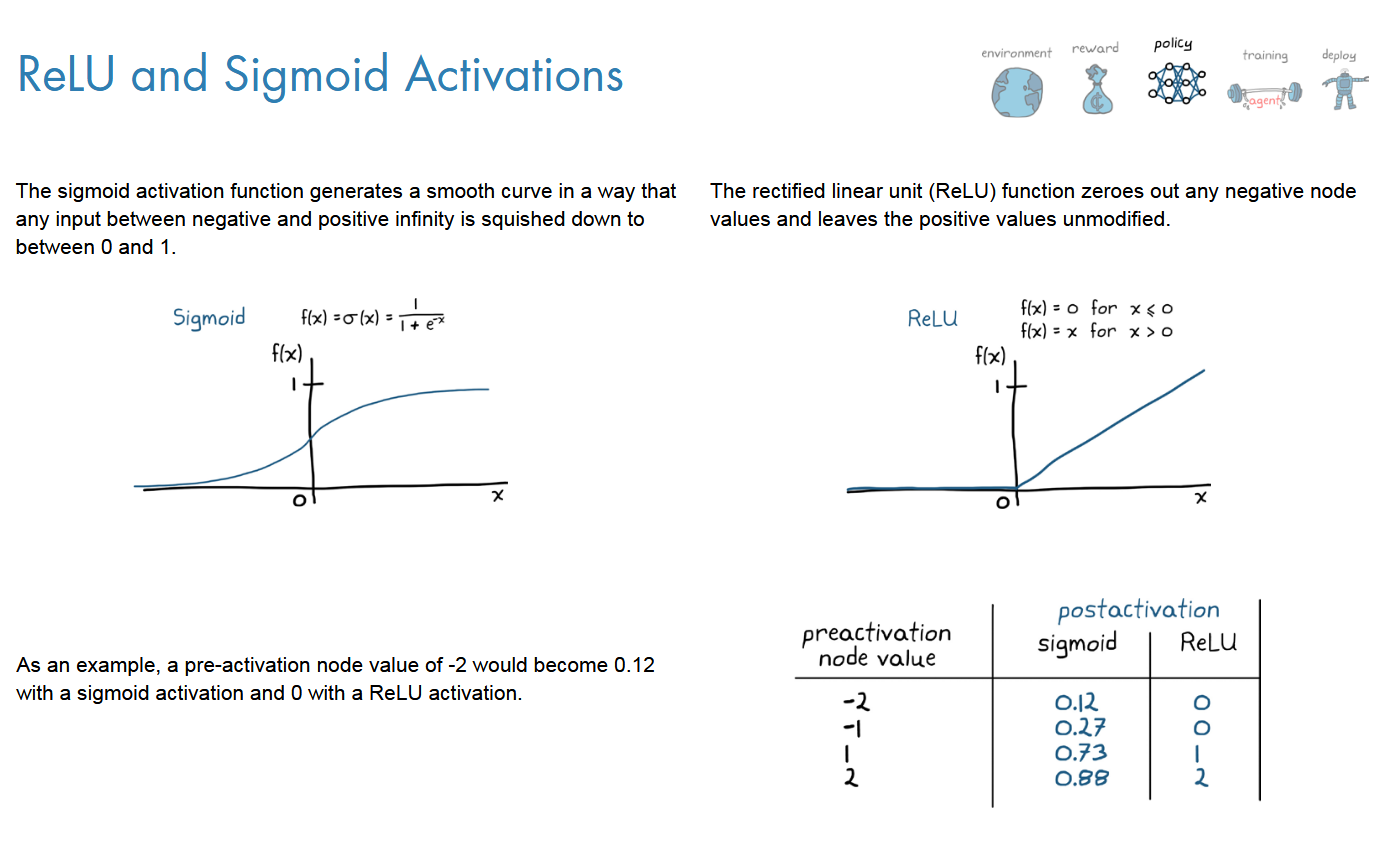
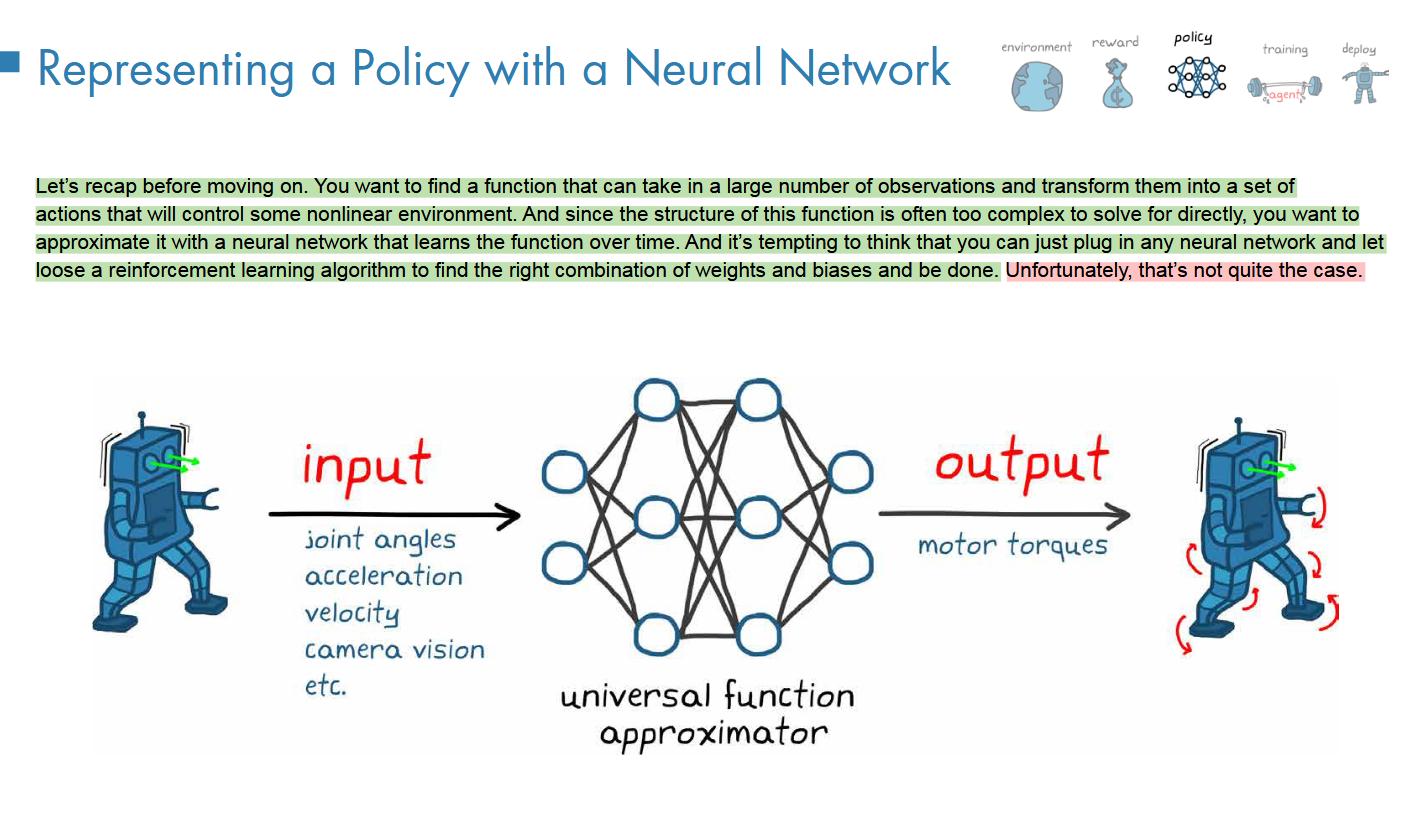
利用NN去设计policy没有通式,却决于你的任务
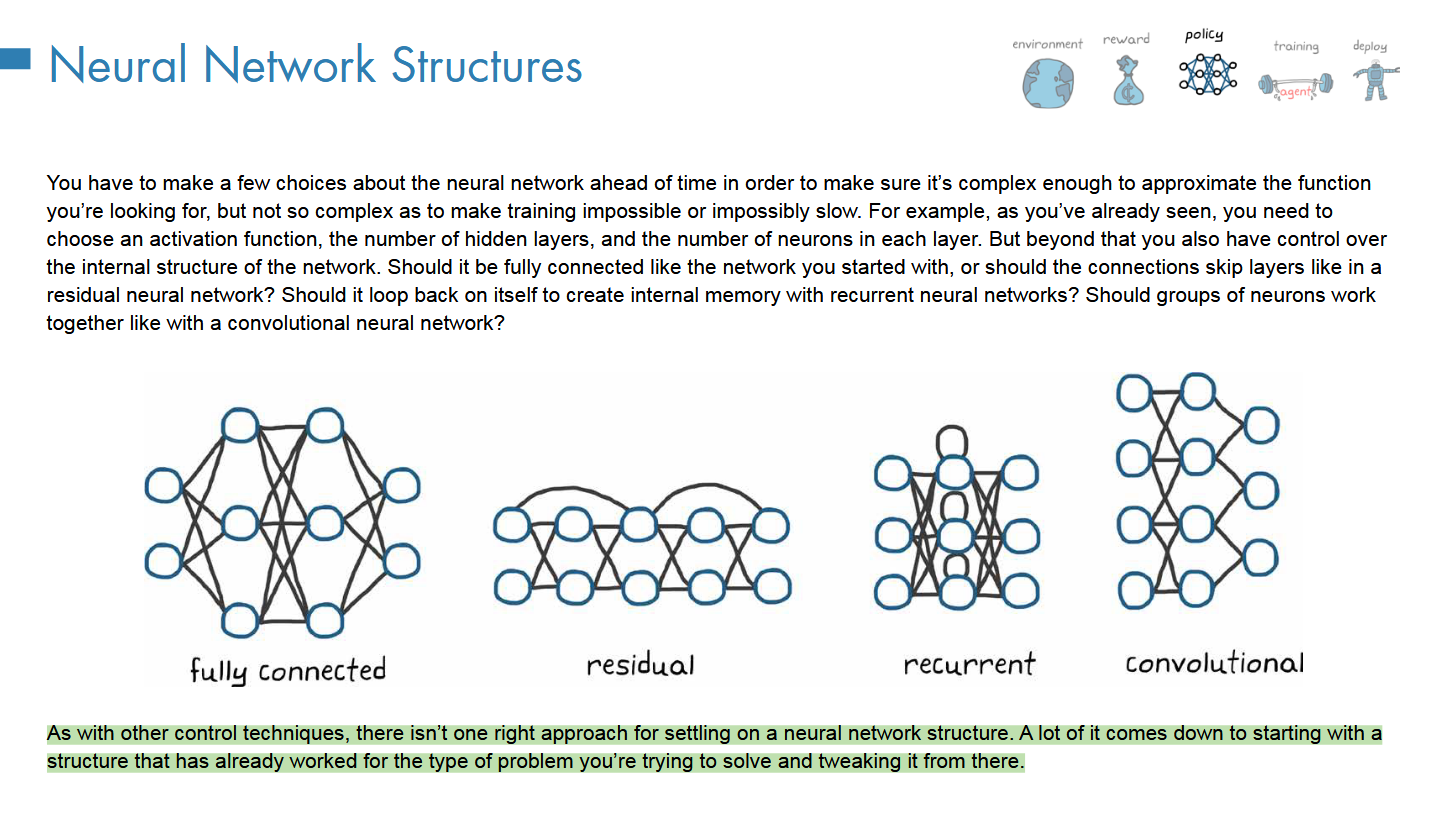
第四章、训练部署
policy绝对是在RL算法的选择上开始构建的
比如有的是policy-based算法
有的是value-based算法
有的是a-c算法,因此网络的构建是不相同的;
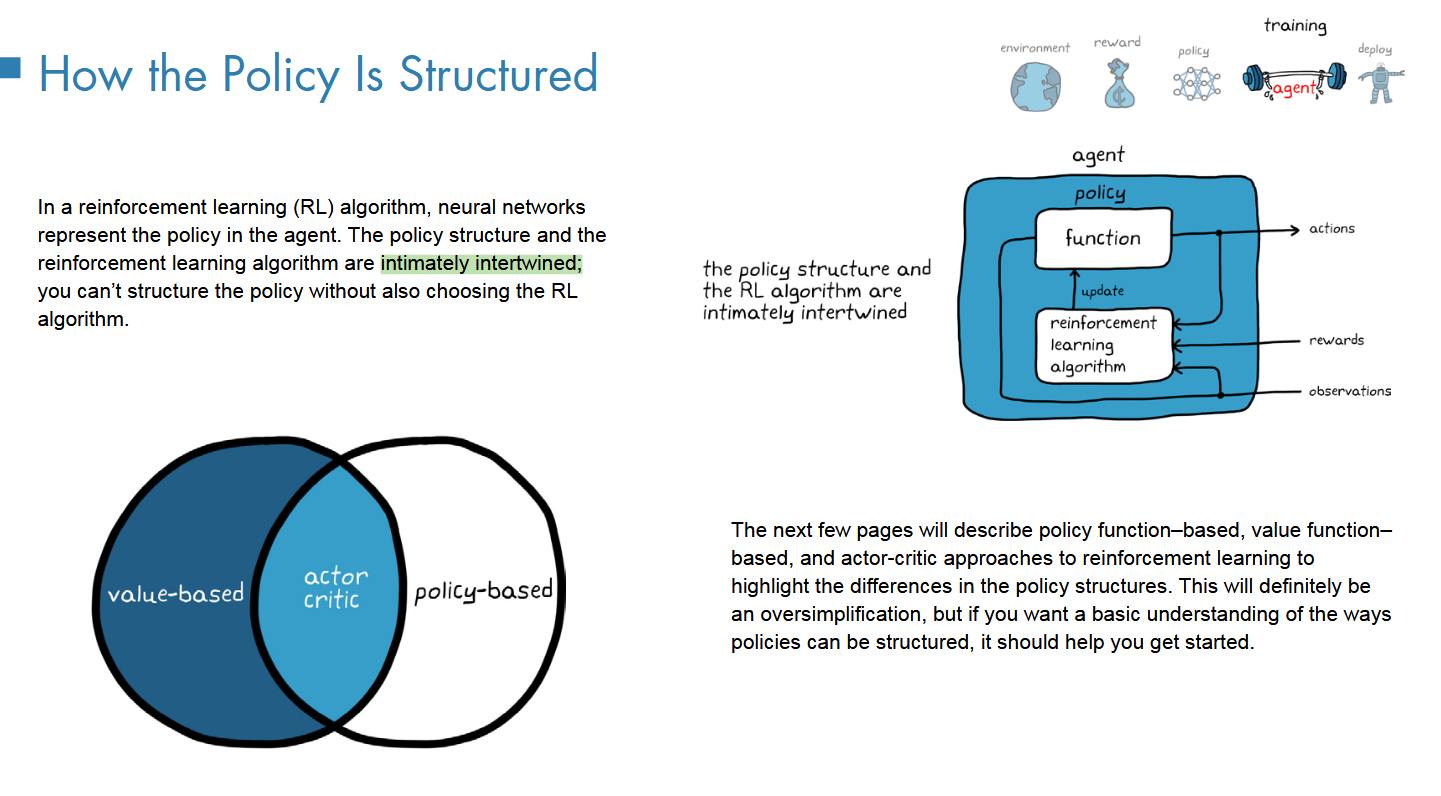
policy-based := actor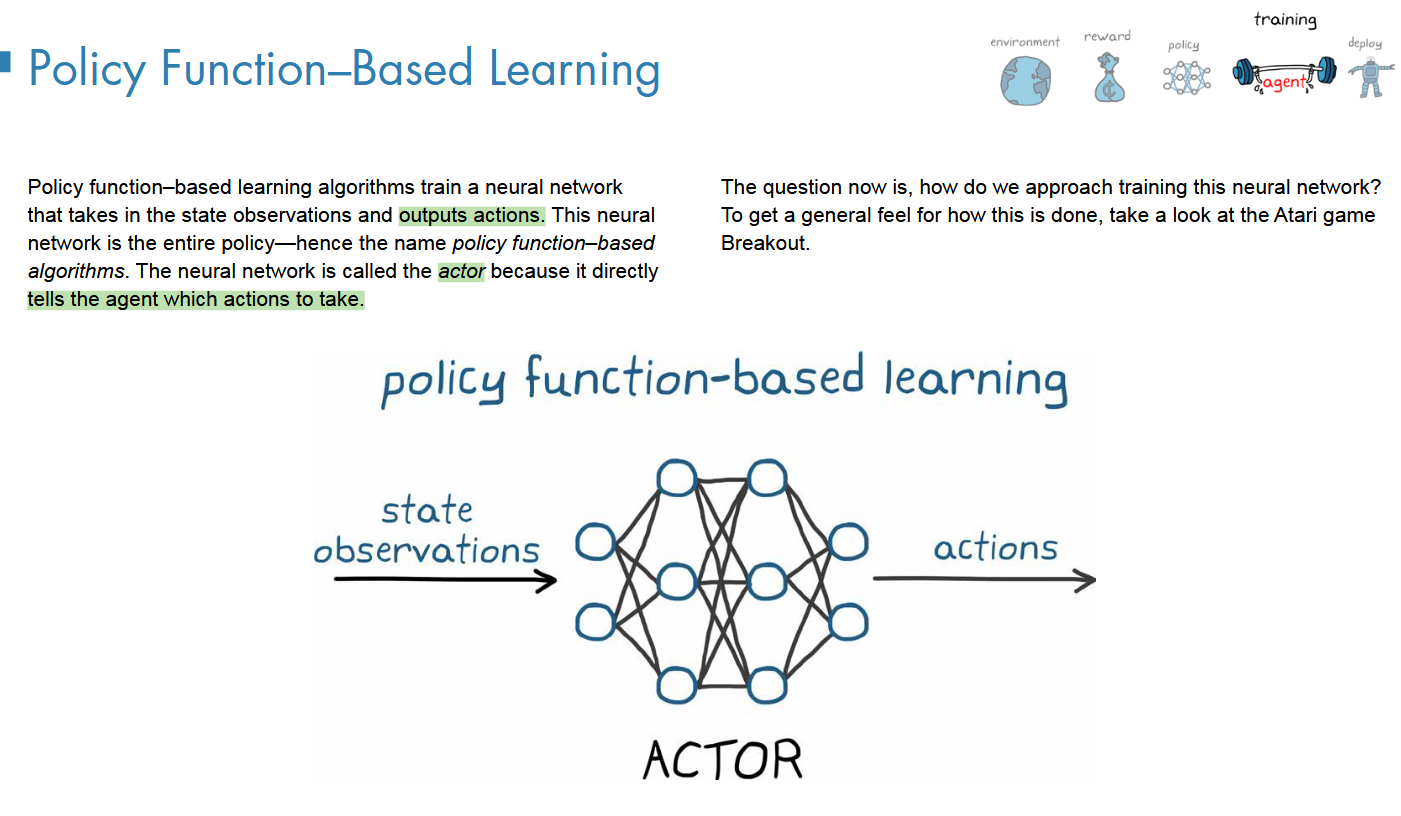
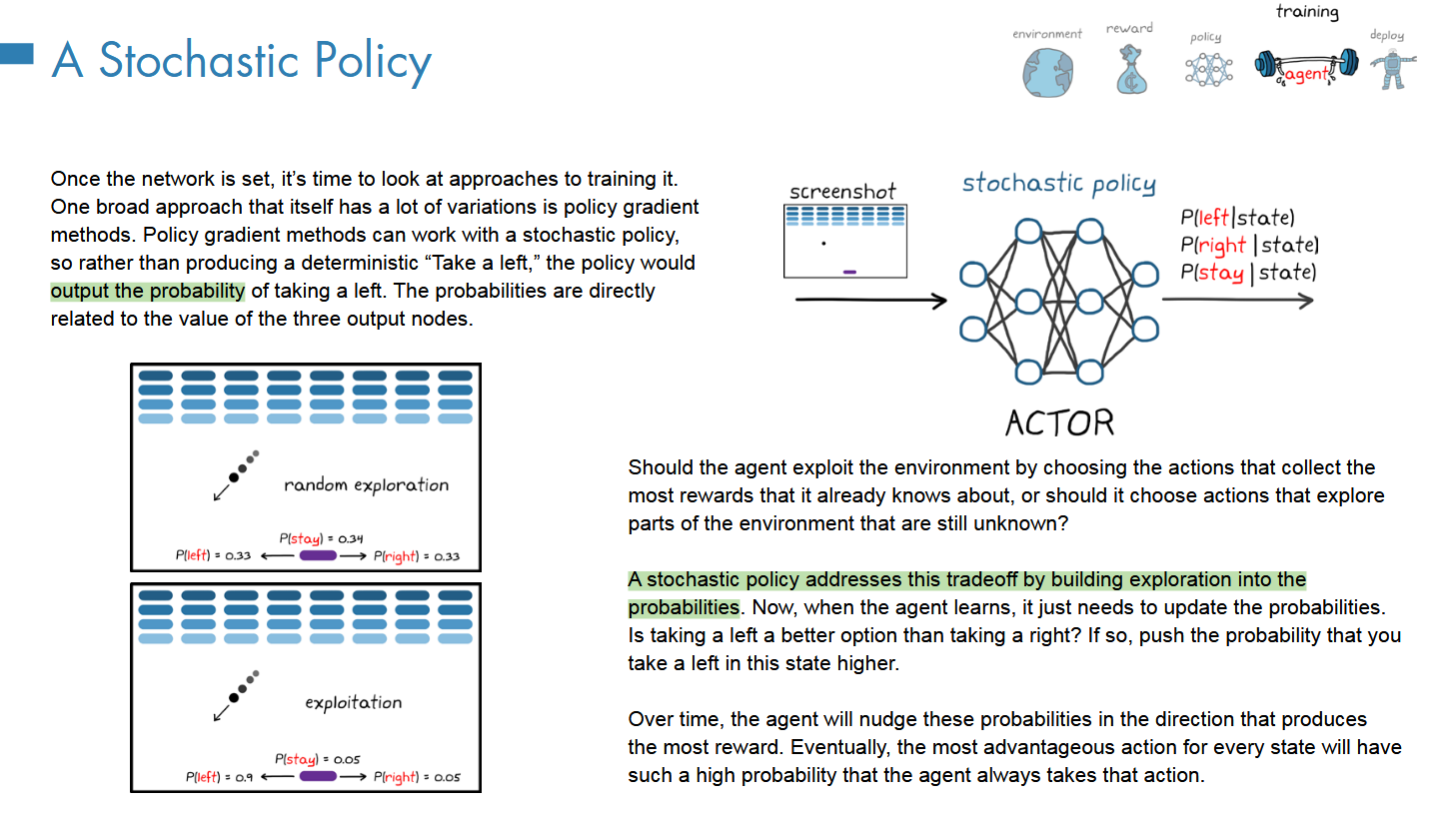

和DL中的cost相反,这里是朝着reward最大化的方向进行,就是梯度的反方向;

缺点
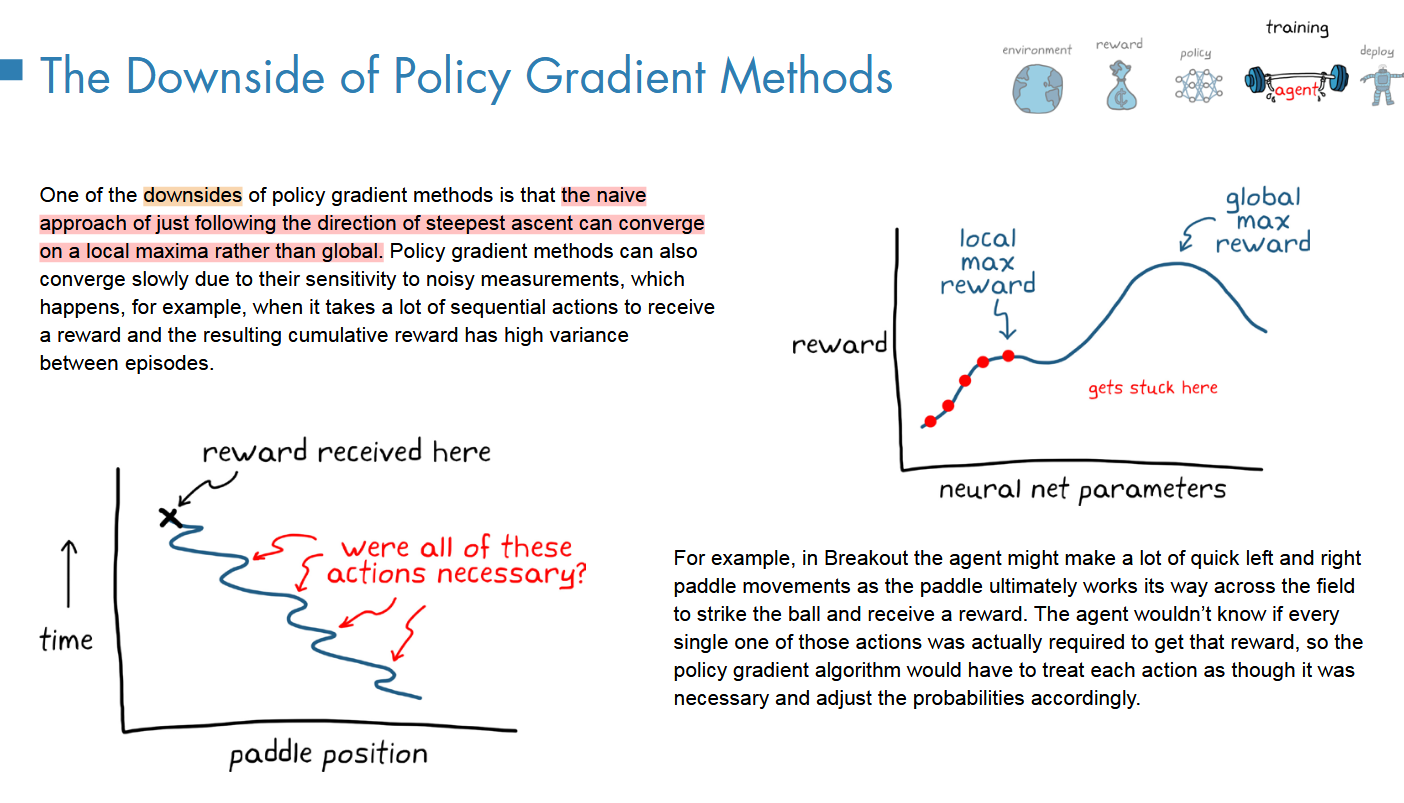

-
缺点 1:可能收敛到局部最优
-
缺点 2:对高方差回报敏感 → 梯度估计噪声大 → 收敛慢
Value-based
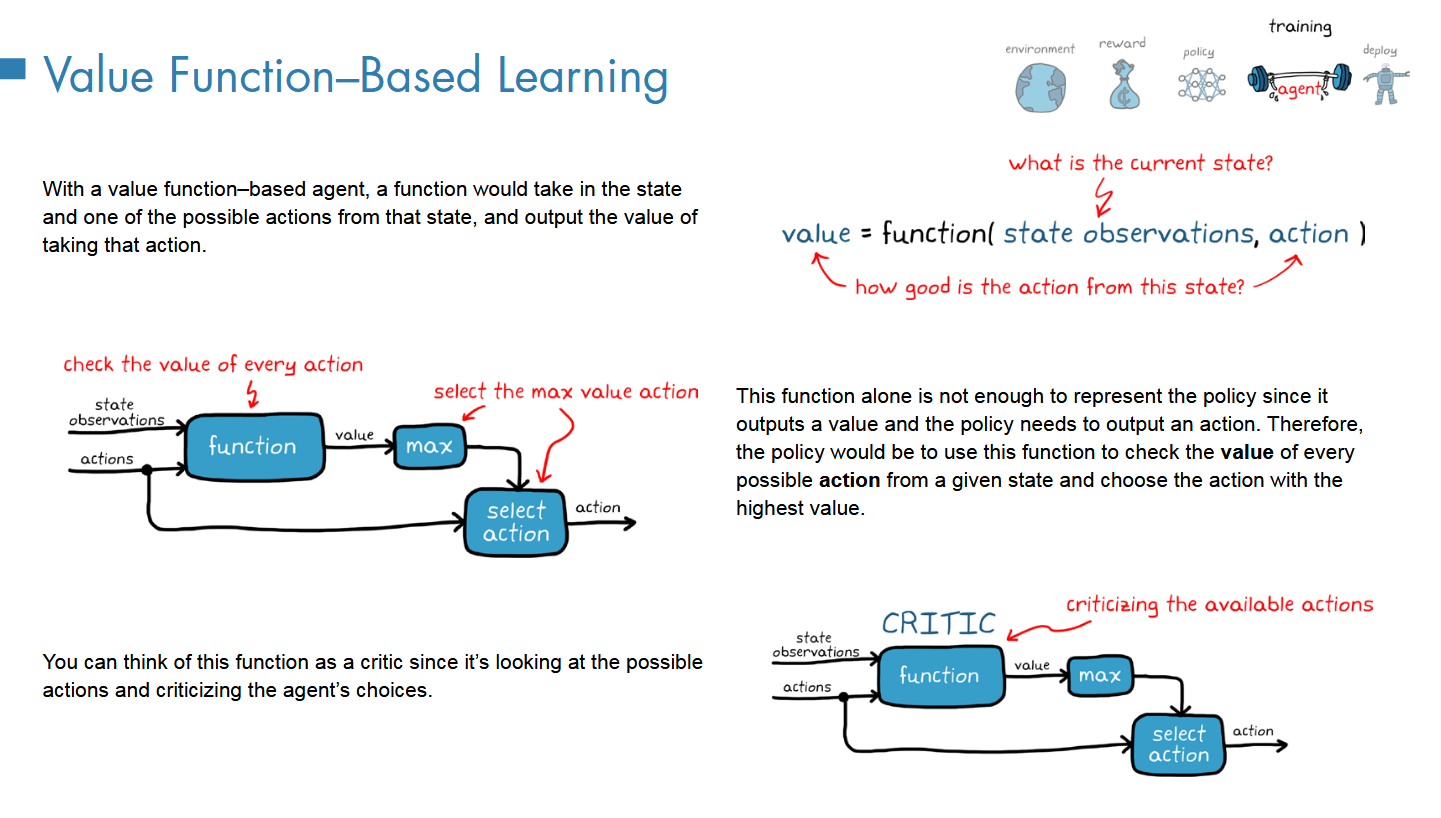

V和Q区别

关键是应用场景,Q一般用作value-based策略,并且是离散空间;

贝尔曼方程,非常重要




例子
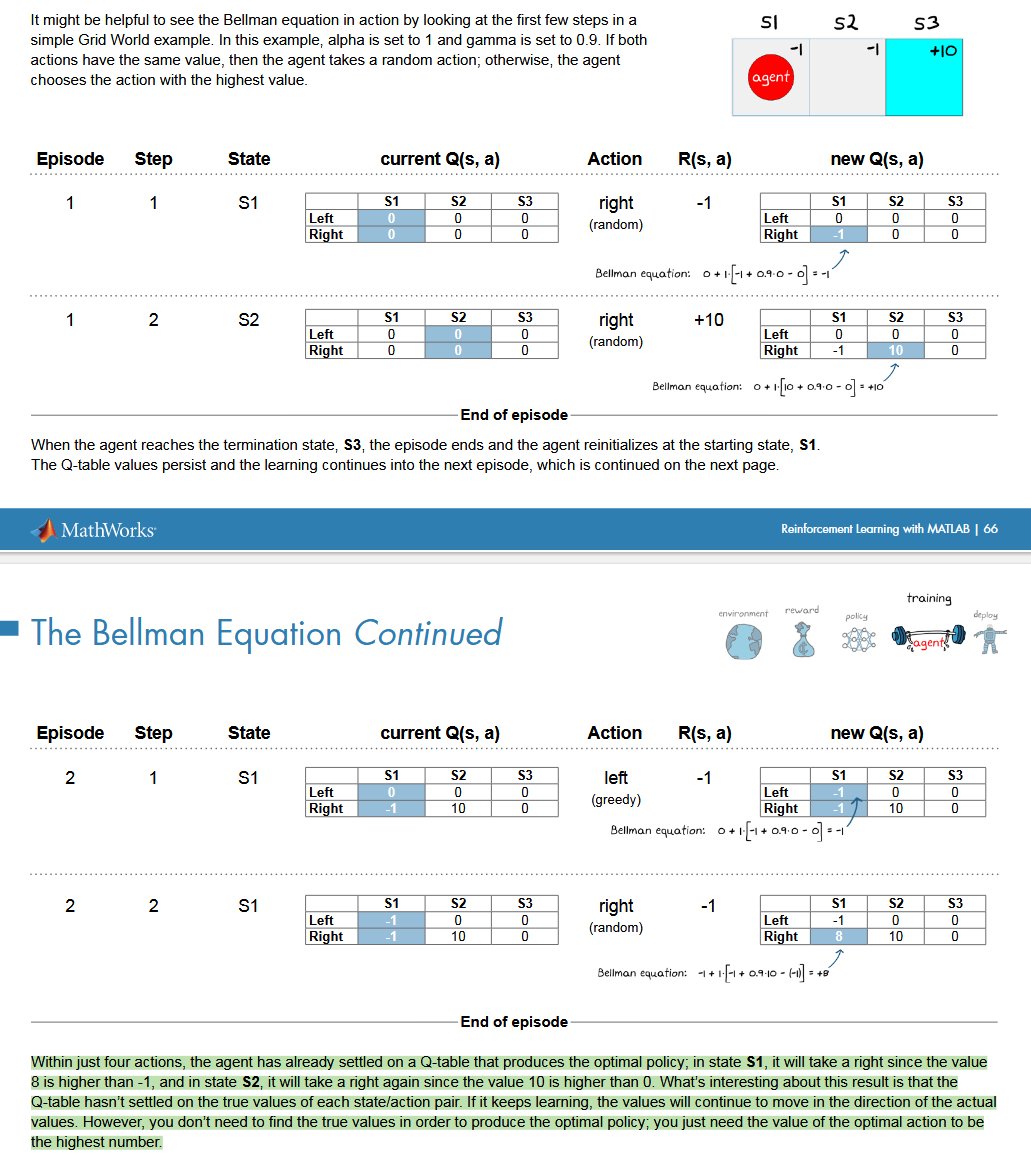
最后一段,表明的是策略的寻找和数值的确定其实没有非黑即白的关联;
我们寻找策略,是希望其能够获得奖励更高,如果数值大致上已经确定,也就是能够体现处对比,什么动作获得奖励更高,什么动作更低,这个时候再去精确实际上用处不大,因为我们要的是策略不是数值;


缺点

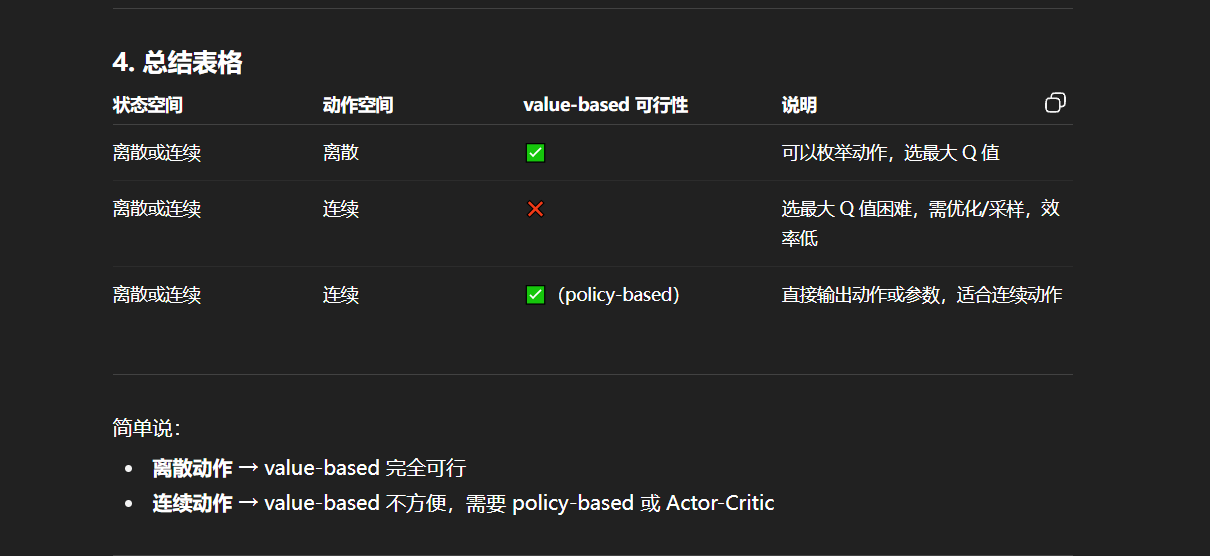

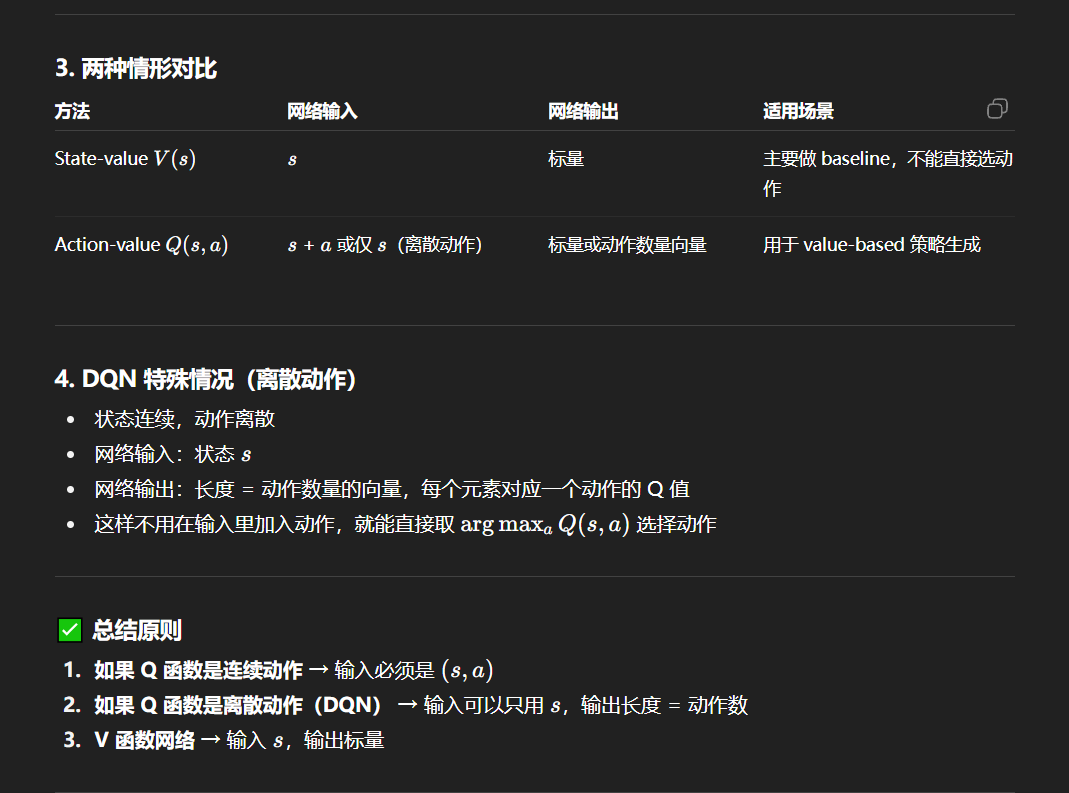
-
如果 Q 函数是连续动作 → 输入必须是 (s,a)(s,a)(s,a)
-
如果 Q 函数是离散动作(DQN) → 输入可以只用 sss,输出长度 = 动作数
-
V 函数网络 → 输入 sss,输出标量
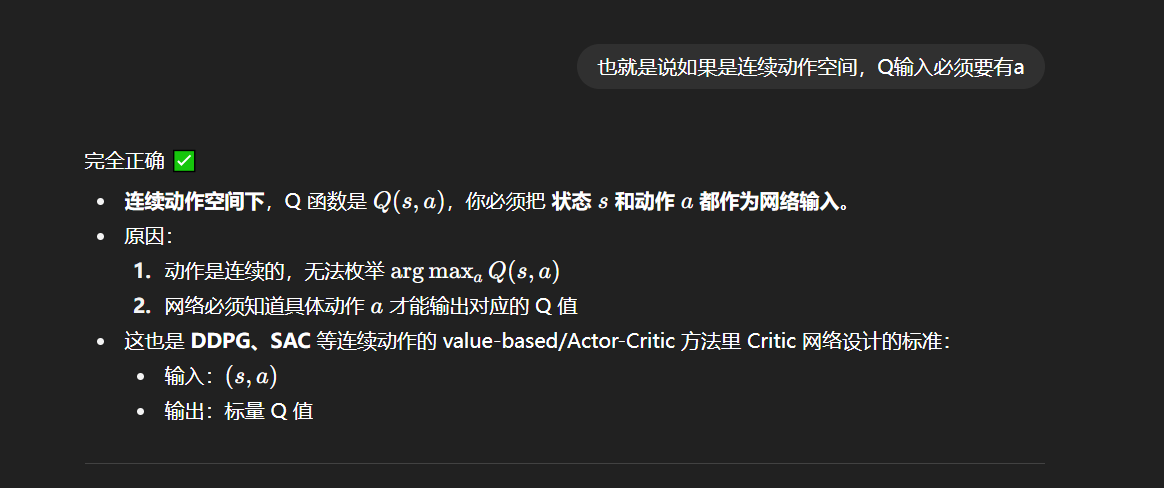


ac网络更新逻辑
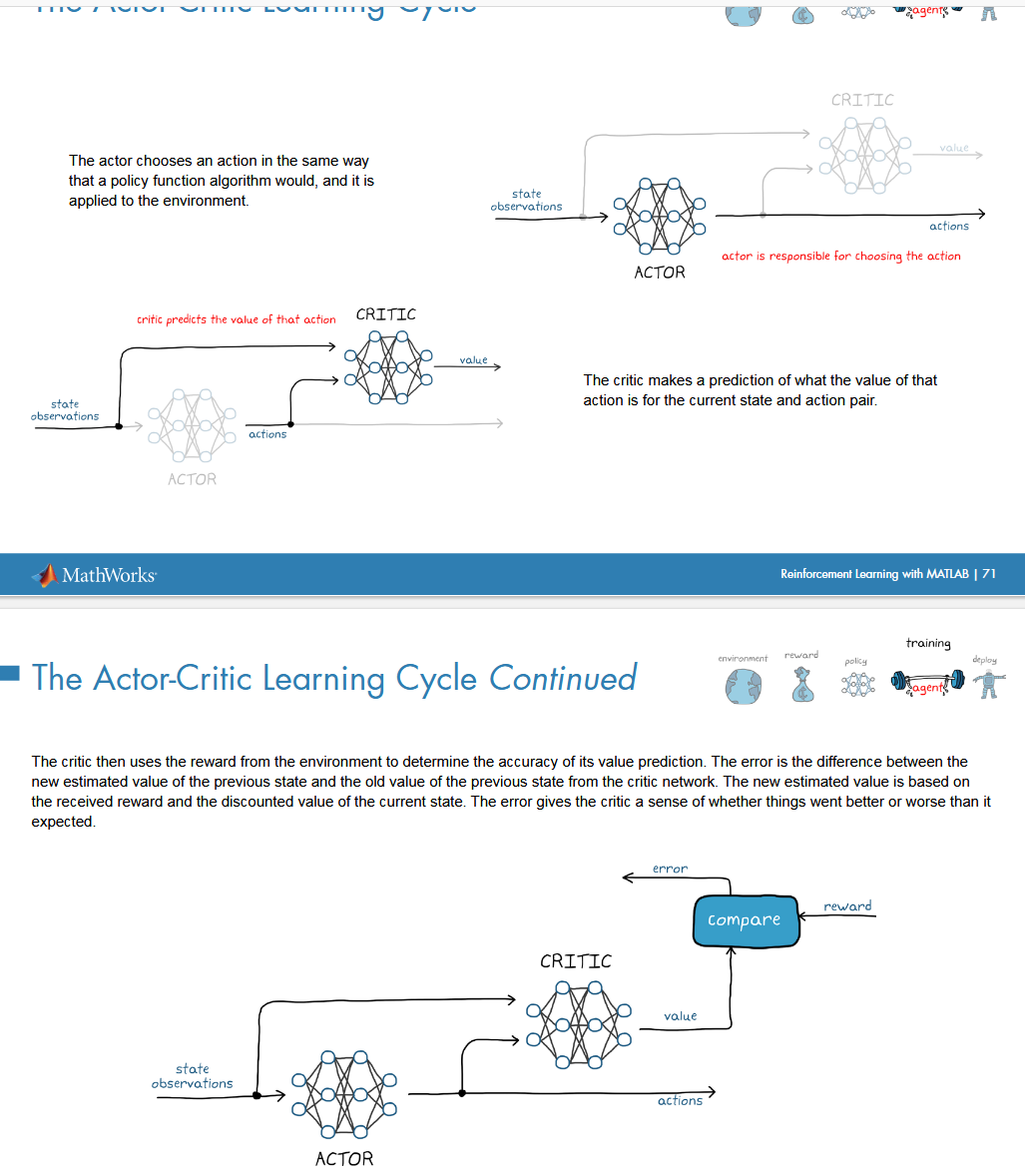
部署之后还需要进行学习,更新策略
两者互补,仿真的学习,只是为了保证硬件上的安全,实际部署之后还需要在真实场景进行学习;
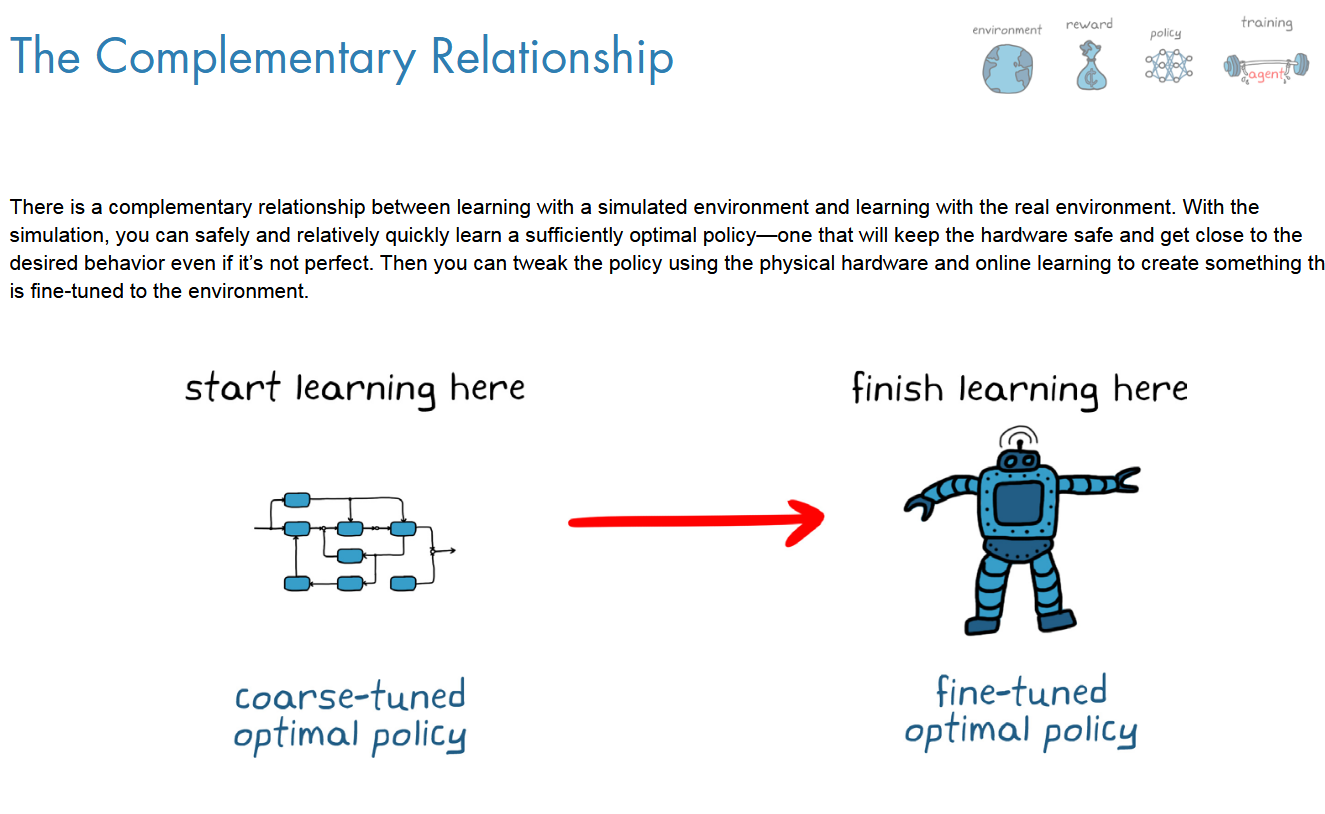
RL缺点
NN的不可解释性
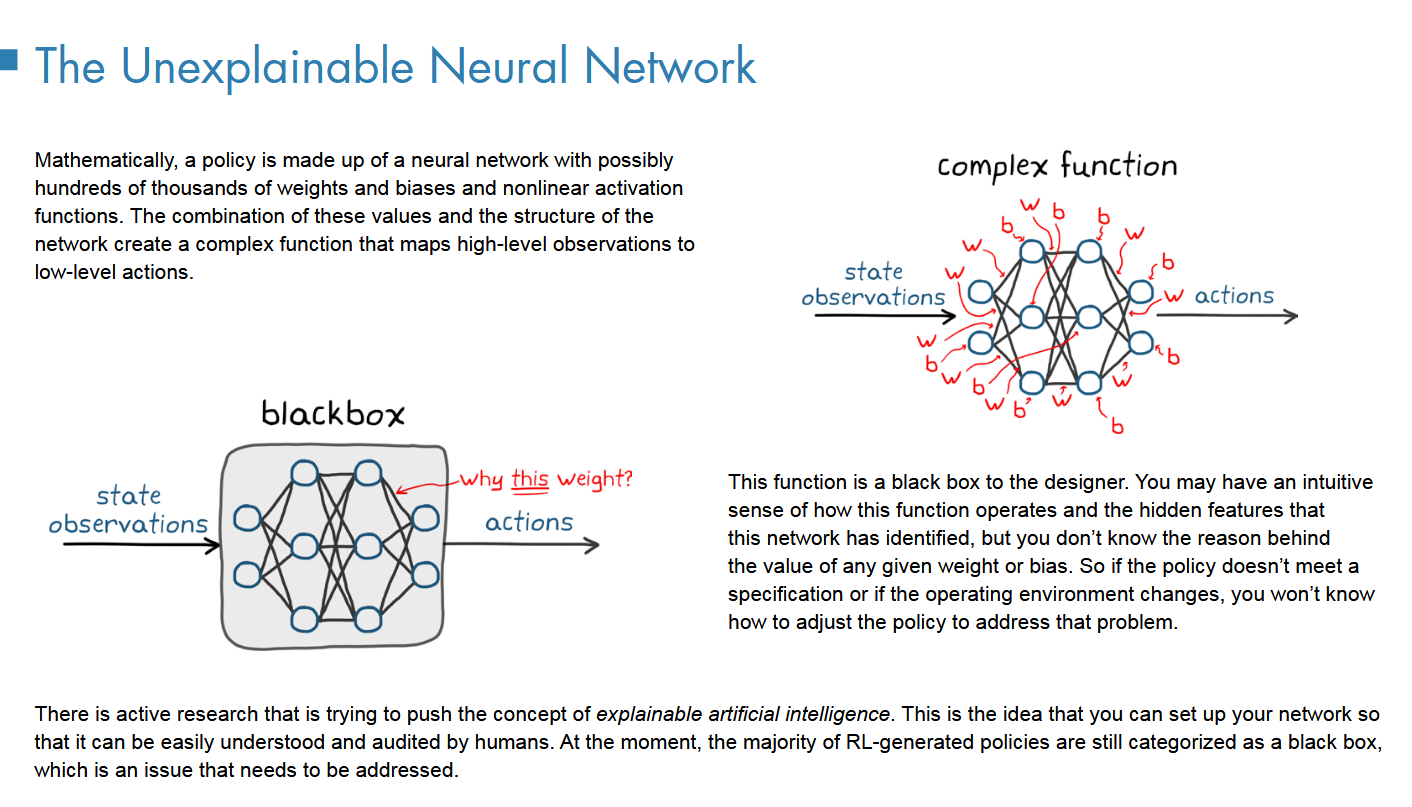
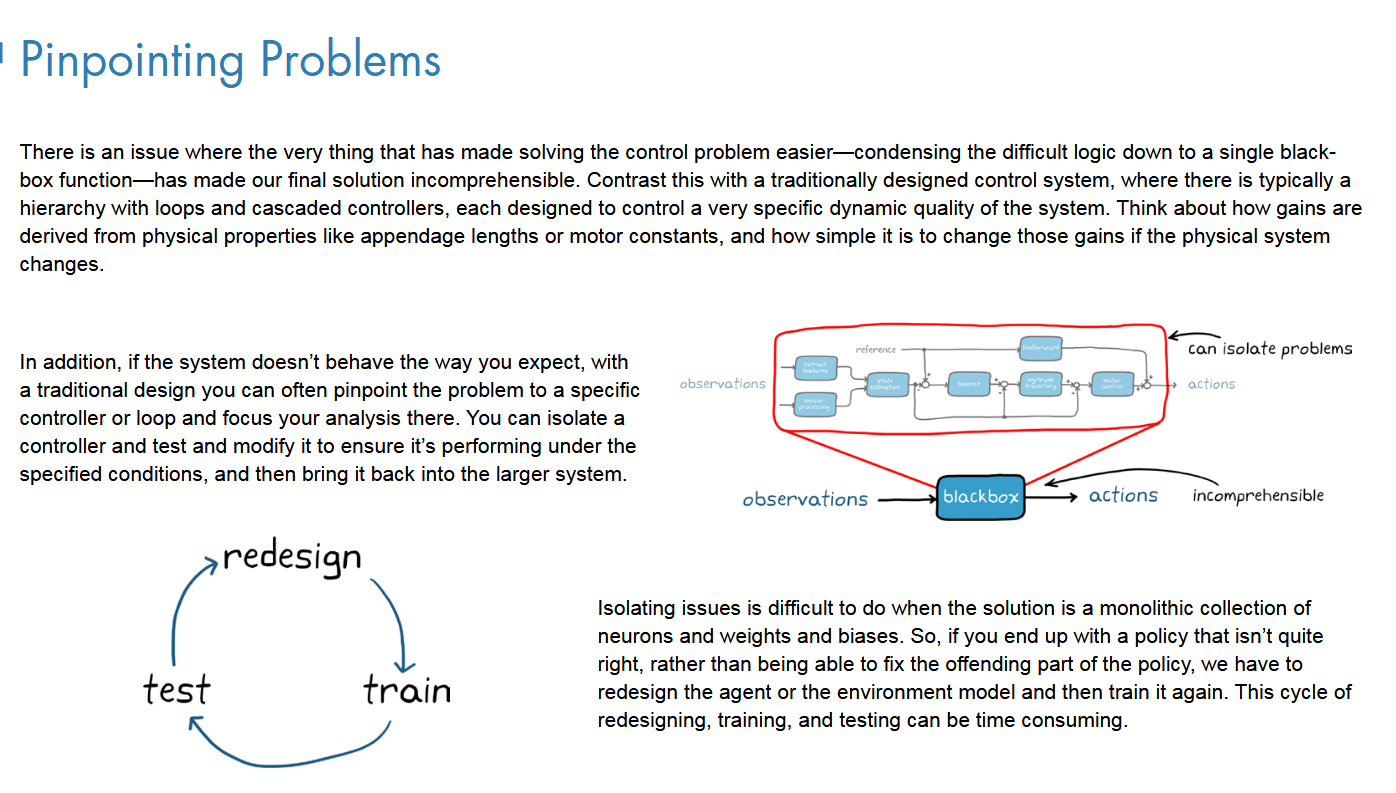
黑河模型相比于传统控制模型的缺点就是无法定位问题
更大的问题是设计的环境不完美
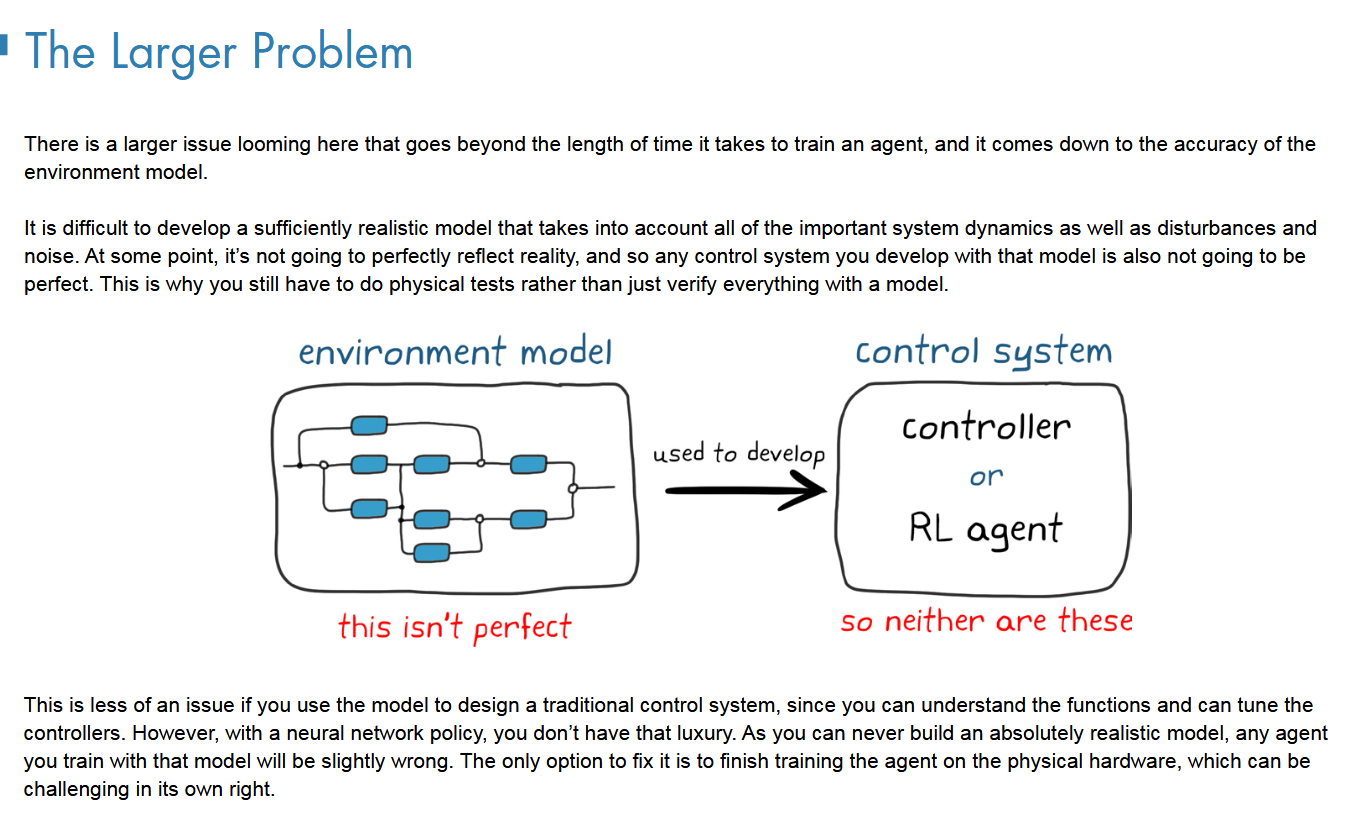
如果使用该模型来设计传统的控制系统,这就不是什么问题了,因为可以理解功能并可以调整控制器。但是,使用神经网络策略,就没有那么奢侈了。由于永远无法构建绝对逼真的模型,因此使用该模型训练的任何代理都会稍微出错。解决唯一选择是在物理硬件上完成对代理的培训,这本身就具有挑战性。

验证难度很大

缓解问题
规避
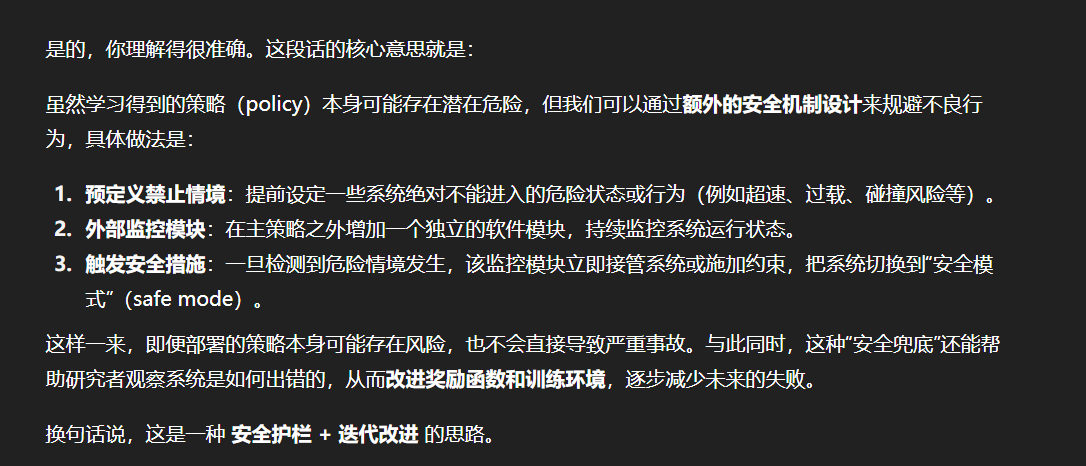
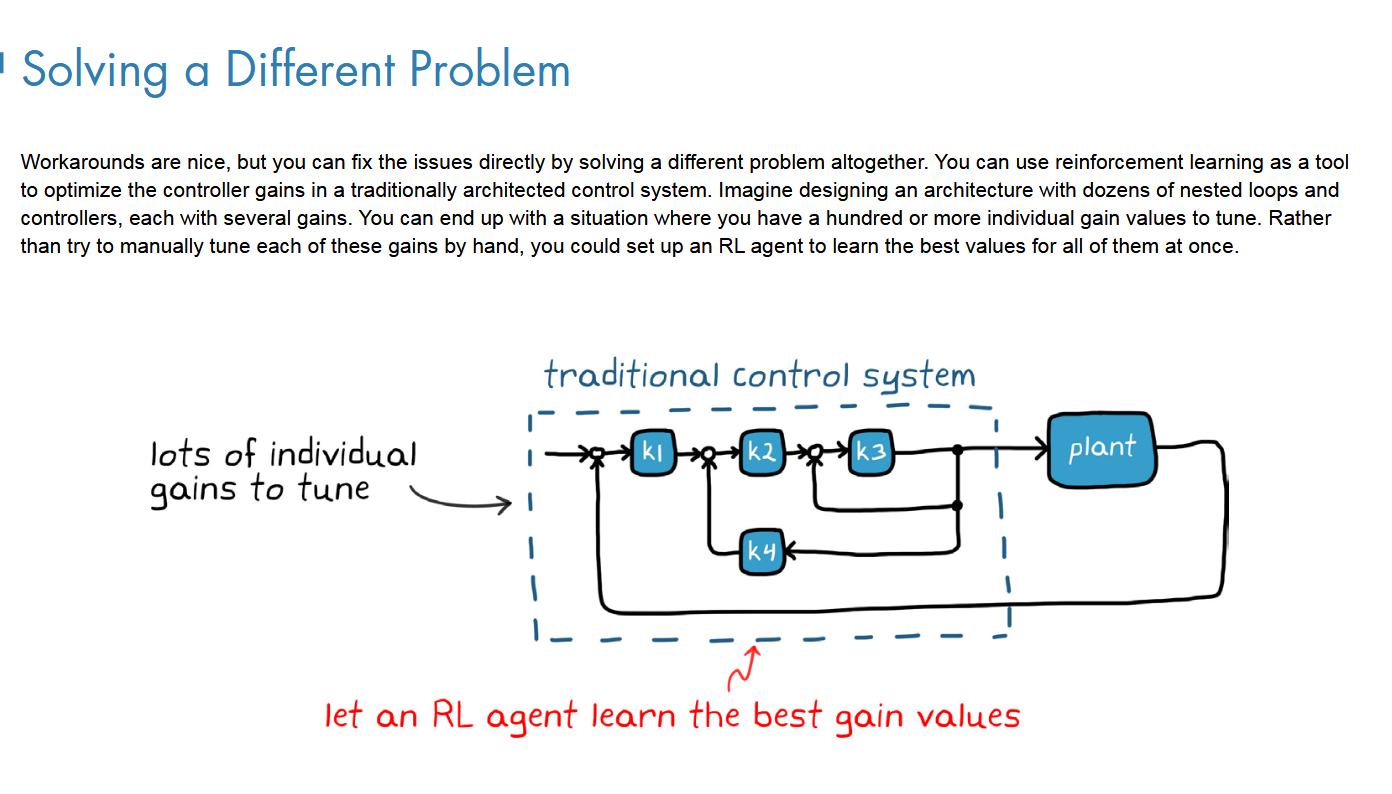
不直接用RL来替代传统优化器,仍然保留传统优化器,采用RL来优化里面的参数;


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)