Yolo姿态行人检测(onnxruntime后端、量化后续写)
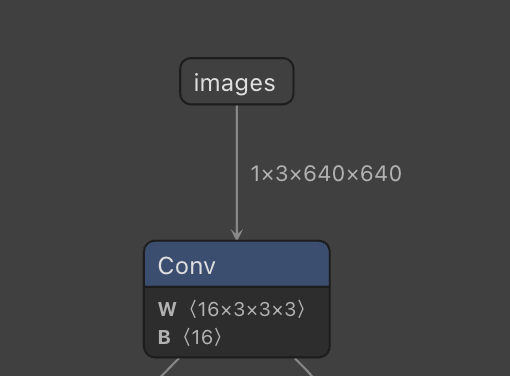
模型训练的时候输入的HW(高宽)就是固定的(很多模型都不支持动态输入),具体模型的tensor可以通过etron.app去查看,下面就是netron看到的模型输入[N,C,H,W],N表示批次,C表示颜色三通道。将boxs和关键点传入后处理函数,boxs的第5维向量是置信度(x, y, w, h, conf),前四维是框的坐标。剩下的51维是关键点,总计17个关键点,每三维为1个关键点。源码在我的
yolo11n的onnxruntime推理后端姿态检测以及行人检测实现。
本项目适用想CV入门的同学,yolo官方封装的Ultralytics包已经做好前后处理,不适合学习。
项目地址:GitHub - muggle-stack/Yolo_Pose: Yolo pose inference with onnxruntime
部署
git clone https://github.com/muggle-stack/Yolo_Pose.git概念
推理框架:Torch、Onnxruntime、Tvm等
前处理:记住基本所有的CV前处理都有需要:read、color、resize、crop\pad、normalize、transpose、add batch。
模型的输入 tensor 固定,因此需要对输入的图片进行前面所提到的这几点,具体以代码展开:
读入图片
if not cap.isOpened():
print("无法打开摄像头")
else:
while True:
start_time = time.time()
ret, frame = cap.read()
if not ret:
print("无法读取帧")
break调 color 通道(因为opencv默认读入图片的颜色通道格式是brg,因为模型训练以rgb的格式训练需要转换rgb)
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)resize 用opencv的resize方法去转。模型训练的时候输入的HW(高宽)就是固定的(很多模型都不支持动态输入),具体模型的tensor可以通过etron.app去查看,下面就是netron看到的模型输入[N,C,H,W],N表示批次,C表示颜色三通道。
frame_resized = cv2.resize(frame_rgb, input_size)我这里没做pad没发现精度有损失,你们也可以去做一下pad。
Normalize 把像素值变到模型训练时期待的数值分布。
frame_nomalized = frame_resized / 255.0Transpose 把HWC转置成CHW,保证数据跟卷积核实现一一对应,匹配底层算子。
input_tensor = frame_nomalized.transpose(2, 0, 1)[None, :, :, :].astype(np.float32)初始化onnxruntime后端:
我跑在 Spacemit 的K1上,所以直接在创建 session 的时候将EP设置为 SpaceMITExcutionProvider。当然跑在CPU上可以直接设置为CPUExcutionProvider。
providers = ['SpaceMITExcutionProvider']
# CPU上直接 providers = ['CPUExcutionProvider'],当然可以改其他后端如CUDAExcecutionProvider。
session_option = ort.SessionOptions()
session_option.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
session = ort.InferenceSession(model_path, sess_option=session_option, providers=providers)预处理以及创建会话以后,输出的形状是{1, 56, 8400)
将矩阵去掉第0个纬度并且转置矩阵(56, 8400)。不转置也行,不转置后处理需要改一下。
providers = ['SpaceMITExcutionProvider']
# CPU上直接 providers = ['CPUExcutionProvider'],当然可以改其他后端如CUDAExcecutionProvider。
session_option = ort.SessionOptions()
session_option.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
session = ort.InferenceSession(model_path, sess_option=session_option, providers=providers)后处理
将boxs和关键点传入后处理函数,boxs的第5维向量是置信度(x, y, w, h, conf),前四维是框的坐标。剩下的51维是关键点,总计17个关键点,每三维为1个关键点。分别是(x, y, conf)
for i in range(output_boxs.shape[0]): # [8400, 5]
conf = output_boxs[i][-1] # -1最后一个
if conf >= conf_thresh:
x_center = output_boxs[i][0] * scale_w
y_center = output_boxs[i][1] * scale_h
width = output_boxs[i][2] * scale_w
height = output_boxs[i][3] * scale_h
x1, y1 = int(x_center - width / 2), int(y_center - height / 2)
x2, y2 = int(x_center + width / 2), int(y_center + height / 2)
boxes.append([x1, y1, x2 - x1, y2 - y1])
confidences.append(conf)
cur_kps = keypoints[i].reshape(-1, 3)
cur_kps[:, 0] *= scale_w
cur_kps[:, 1] *= scale_h
kpts_list.append(cur_kps)17组关键点,在ultralytics官网可以找到https://docs.ultralytics.com/tasks/pose,提供10组颜色去连接关键点。
for i in range(output_boxs.shape[0]): # [8400, 5]
conf = output_boxs[i][-1] # -1最后一个
if conf >= conf_thresh:
x_center = output_boxs[i][0] * scale_w
y_center = output_boxs[i][1] * scale_h
width = output_boxs[i][2] * scale_w
height = output_boxs[i][3] * scale_h
x1, y1 = int(x_center - width / 2), int(y_center - height / 2)
x2, y2 = int(x_center + width / 2), int(y_center + height / 2)
boxes.append([x1, y1, x2 - x1, y2 - y1])
confidences.append(conf)
cur_kps = keypoints[i].reshape(-1, 3)
cur_kps[:, 0] *= scale_w
cur_kps[:, 1] *= scale_h
kpts_list.append(cur_kps)我的代码里面高于0.5的框都会被绘制,需要用nms去选择最优的框。
def nms(boxes, scores, iou_threshold=0.5):
indices = cv2.dnn.NMSBoxes(boxes, scores, score_threshold=0.5, nms_threshold=iou_threshold)
return indices.flatten() if len(indices) > 0 else []最后就是绘制行人框,将关键点按顺序连接
for i in indices:
box = boxes[i]
x1, y1, w, h = box
conf = confidences[i]
cv2.rectangle(original_image, (x1, y1), (x1 + w, y1 + h), (0, 255, 0), 2)
cv2.putText(original_image, f"person {conf:.2f}", (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 1)
connect_keypoints(original_image, kpts_list[i], skeleton, colors)
def connect_keypoints(image, keypoints, skeleton, colors):
for i, (start, end) in enumerate(skeleton):
if keypoints[start][2] > 0.5 and keypoints[end][2] > 0.5:
x1, y1 = int(keypoints[start][0]), int(keypoints[start][1])
x2, y2 = int(keypoints[end][0]), int(keypoints[end][1])
cv2.line(image, (x1, y1), (x2, y2), colors[i % len(colors)], 2)这样就能得到基于onnxruntime推理后端的行人检测和姿态检测啦。
源码在我的仓库都能找到,觉得有帮助的给个star呗,star数超过10,我将开源c++代码。
点个赞呗,点个赞呗,点个赞呗!!谢谢。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)