大模型TP、SP、EP切分
文章摘要:本文对比了传统Dense大模型和MoE大模型在并行计算方式上的差异。传统模型采用TP切分,Attention和FNN部分都需进行前向和反向各一次AR计算。而加入SP并行后,计算模式发生变化:前向的g{}变为AG,反向的g{}变为RS。文中以FNN部分为例说明计算模式转变,指出Attention部分也可采用类似处理方式。这反映了模型并行计算策略的演进过程。
传统Dense大模型, FNN部分也是按TP切分。现在 MoE大模型FNN已经是用EP切分了。
1. TP切分
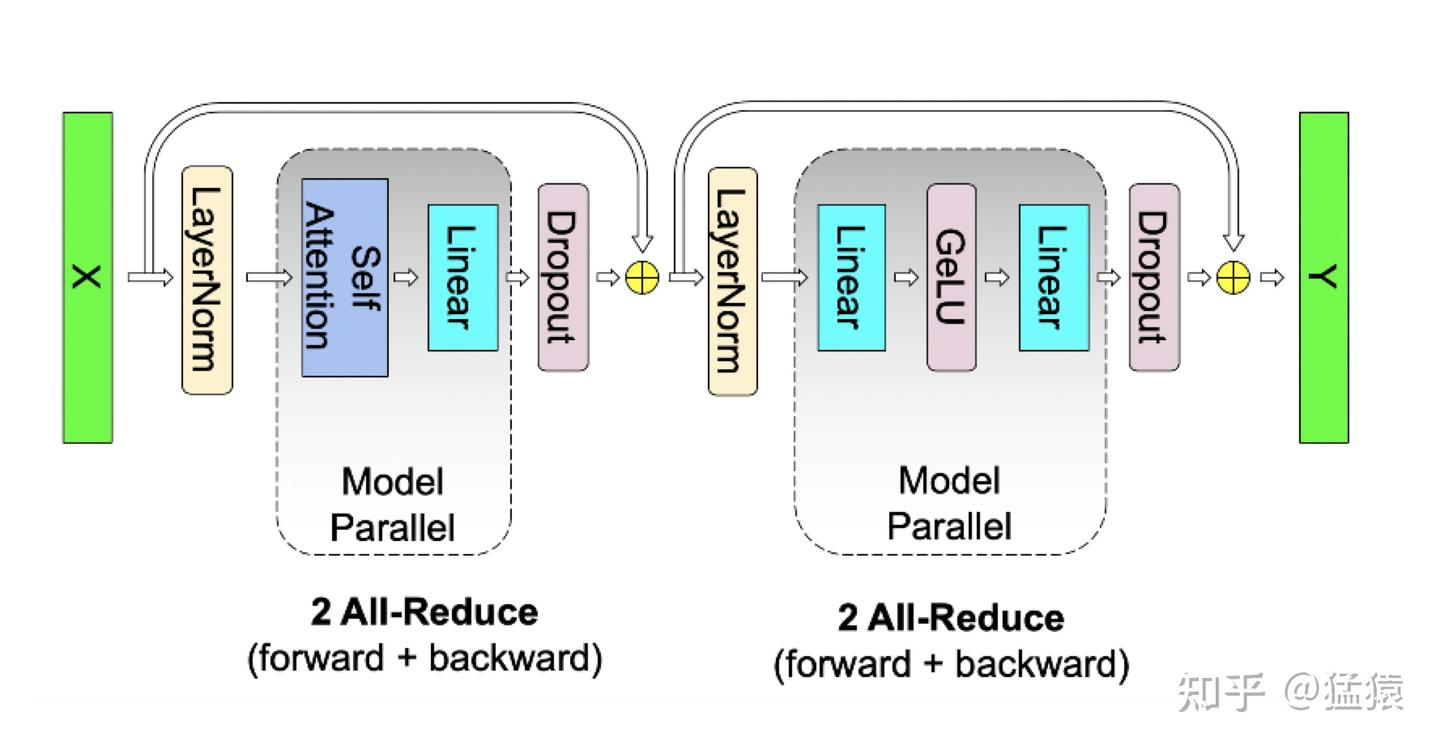 原始TP版本,Attention部分前向一次AR,反向梯度计算一次AR; FNN部分也是前向一次AR,反向一次AR。
原始TP版本,Attention部分前向一次AR,反向梯度计算一次AR; FNN部分也是前向一次AR,反向一次AR。
改进版本AR被拆分成RS+AG,重点说下Attention部分的
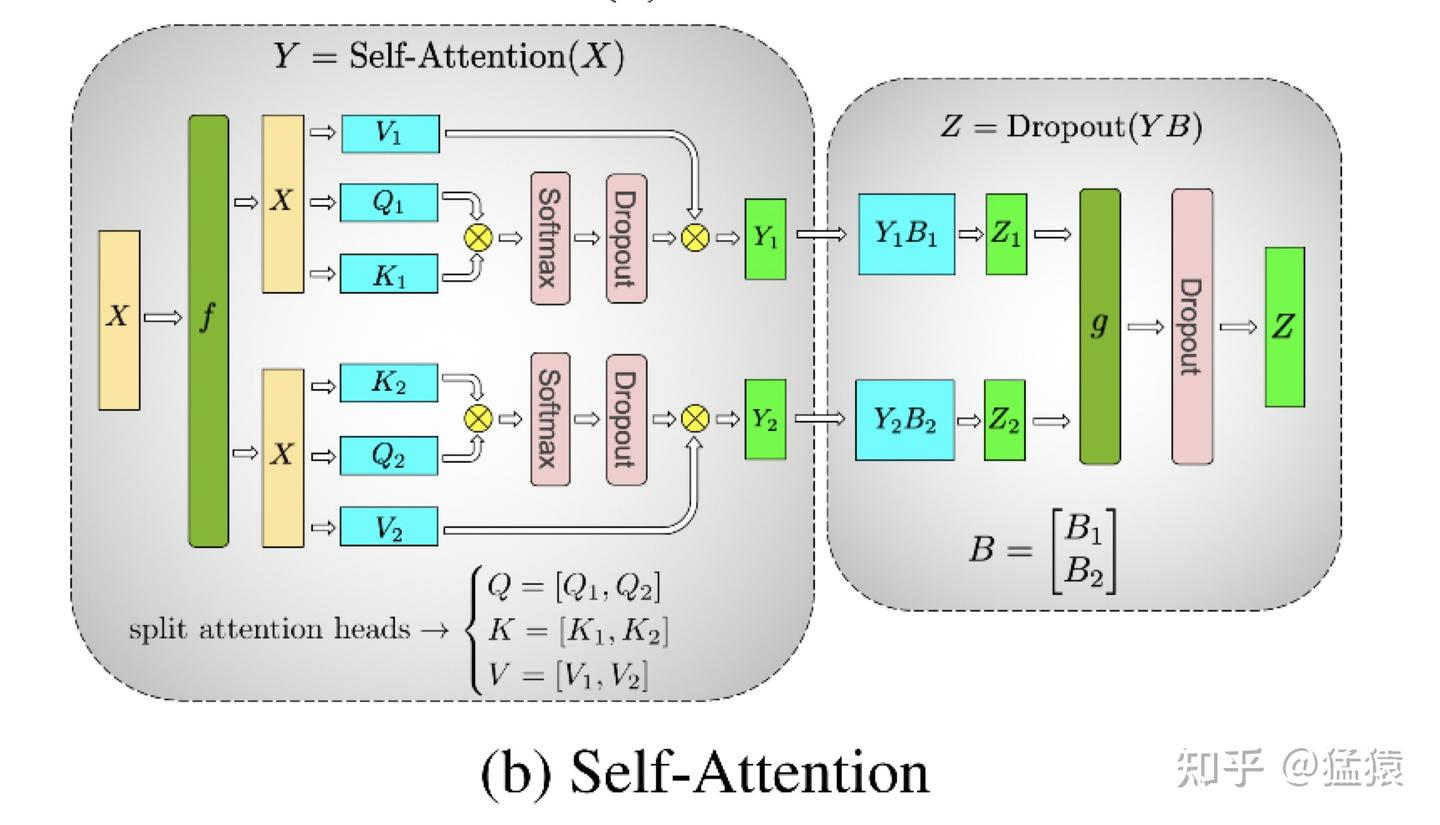
左侧方框是self-attention()函数,每张GPU卡的输入都是(B, S,D) 全量数据,输出Y按列切,原理是multi-head的head数,详细可以见《Attention Is All You Need》的论文。右侧方框是linear()函数,对应论文里的公式
linear部分的B矩阵按行切分, 也就是以上公式中的Wo按行切分,切分之后的和
(即
和
)结果需要再做一次reduce。前向
,g{}是AR; 反向
, f{} 是一次AR。
总结:TP切分,如果有两轮网络叠加,前一轮一般按列切,后一轮按行切,最后的结果,如果需要完整数据,通过reduce 合并; 只需要部分数据, 通过reduce-scatter合并。(Self-attention和MLP部分都是一个原理)
2. SP并行
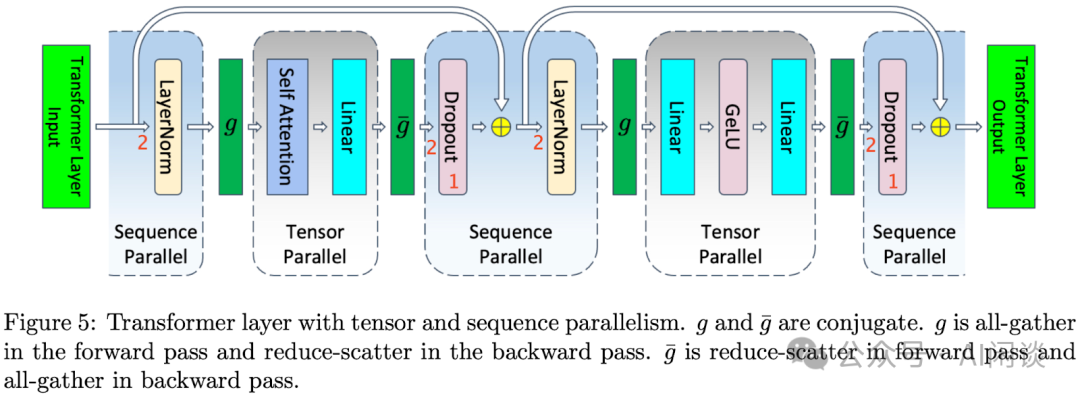
加入SP之后,前向 g{} 是AG,Attention之后的g' {} 从AR变成了RS,Dropout()前的输入是按Seq维度的切分输入(B, S/h, D)。这里是算子融合的方法,通信优化里常用的方法,感兴趣可以再专题展开。
反向g{} 是RS, Attention之后的g'{} 从无变成了AG。
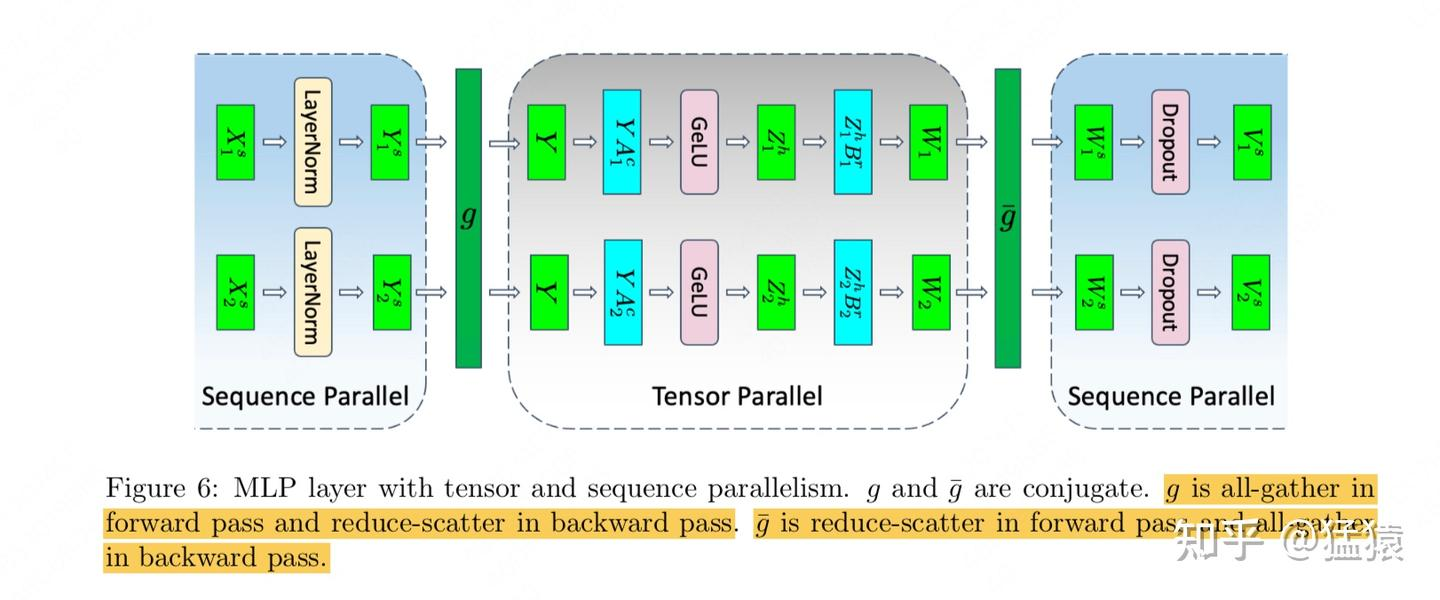 上图是FNN部分的图,如果改成Attention部分也是类似。
上图是FNN部分的图,如果改成Attention部分也是类似。
3. EP切分
MoE模型,FNN部分会替换成Expert部分, 前面g{}不需要做AG, 改成ALL2ALL,出向的g'也改成All2ALL。这样可以避免SP之后的相同数据同时做ALL2ALL。
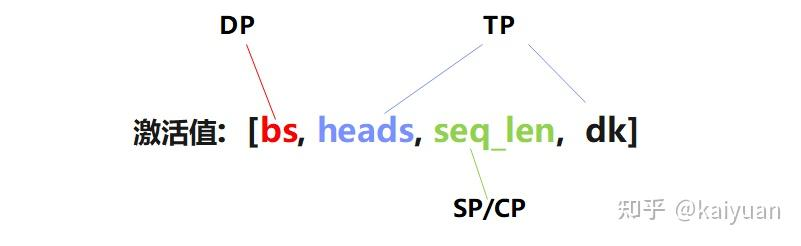
4.激活值总结

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)