混合专家模型(MoE)
混合专家模型(MoE)是一种提升大语言模型性能的技术,通过多个子模型(专家)和路由机制动态选择最适合的专家处理输入。MoE用稀疏层替代传统密集层,仅激活部分参数,提升推理效率。路由机制通过softmax概率分配输入到专家,并引入负载均衡策略(如KeepTopK、容量限制)确保专家均衡训练。该技术也可应用于视觉模型,处理图像块时通过优先级评分优化资源分配。MoE在保持模型质量的同时显著降低计算开销,
本文内容来自视频A Visual Guide to Mixture of Experts (MoE) in LLMs
什么是混合专家模型
混合专家模型(Mixture of Experts, MoE)是一种使用不同的子模型(也就是“专家”)来提升大语言模型(LLM)质量的技术。
它主要由两部分组成:
(1)专家模型:每个专家模型都是一个前馈神经网络(Feed-Forward Neural Networks, FFNN);
(2)路由:决定某个token会被转发到哪一个专家模型;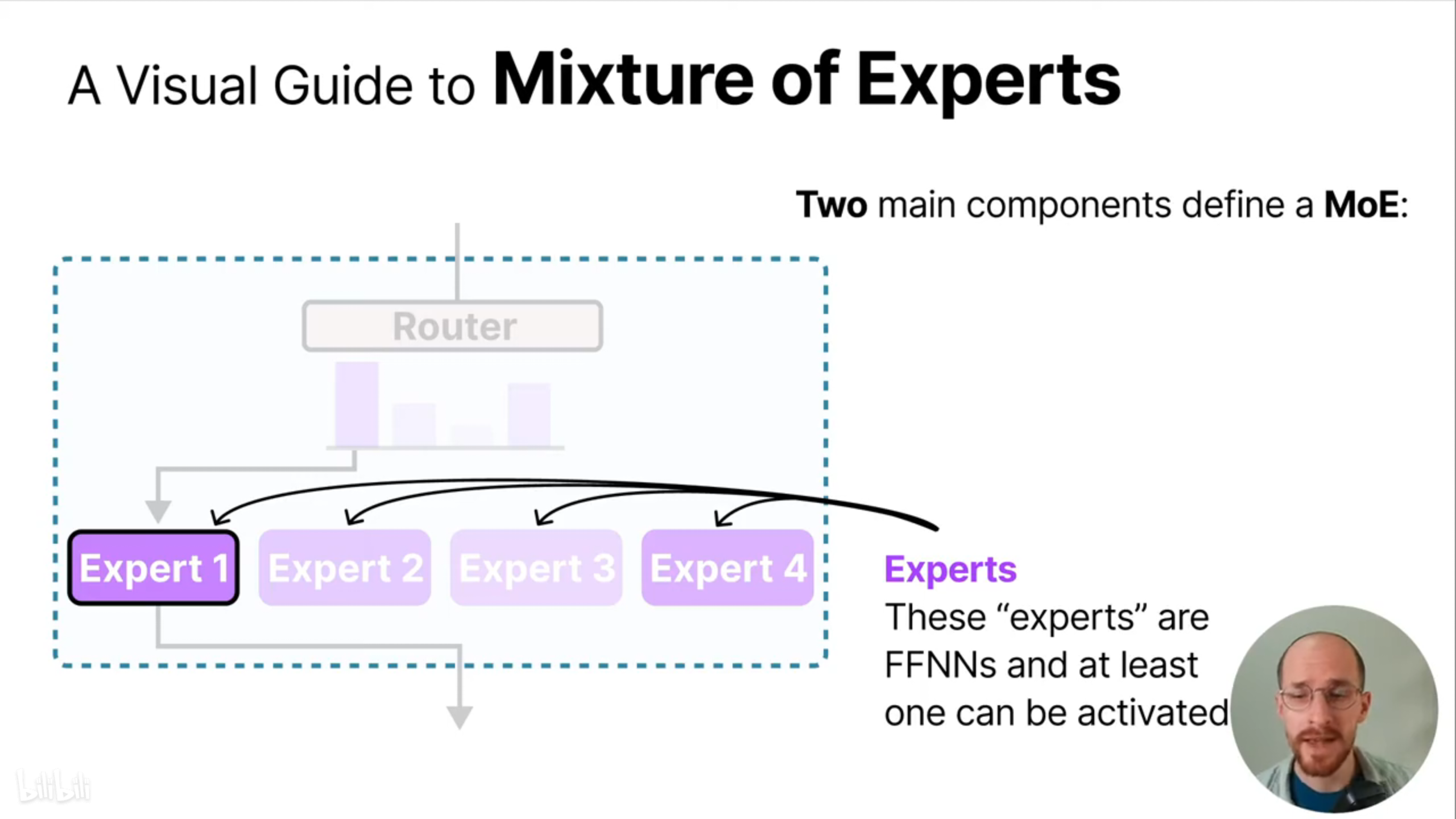
专家模型
混合专家模型主要用于取代密集层(Dense Layers)。在标准的仅有解码器Transformer架构中,前馈神经网络使用了掩码自注意力机制提取的上下文信息(使用掩码是为了在训练时防止未来的信息被利用),这里的前馈神经网络被称为密集层是因为所有的参数都被激活。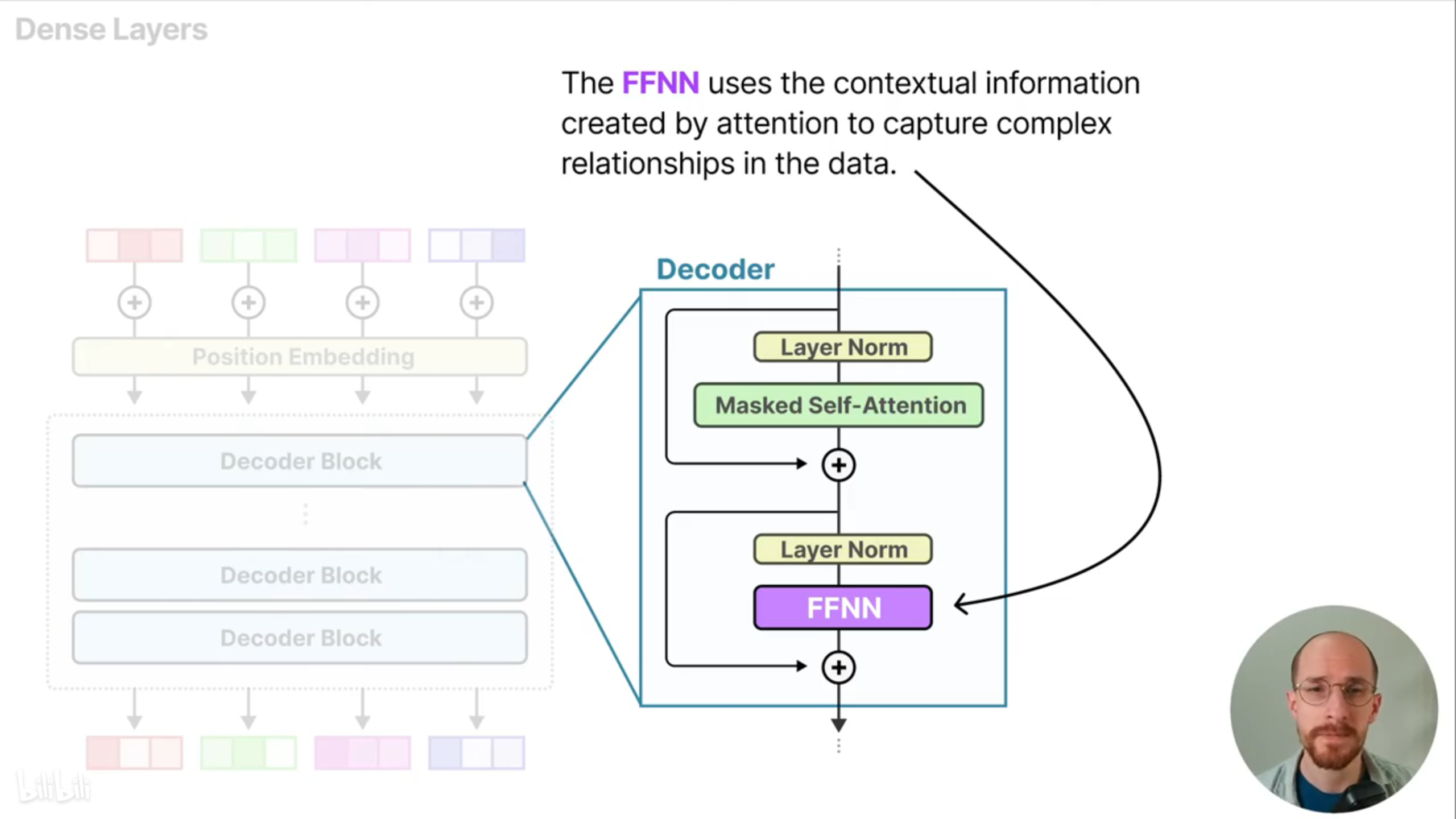
对于一个密集层,可以将其分割成不同的小模型(同样也是一个完整的前馈神经网络网络,称为“专家”),每次使用时只激活一部分的专家模型,这种结构可以称为稀疏层(Sparse Layers)。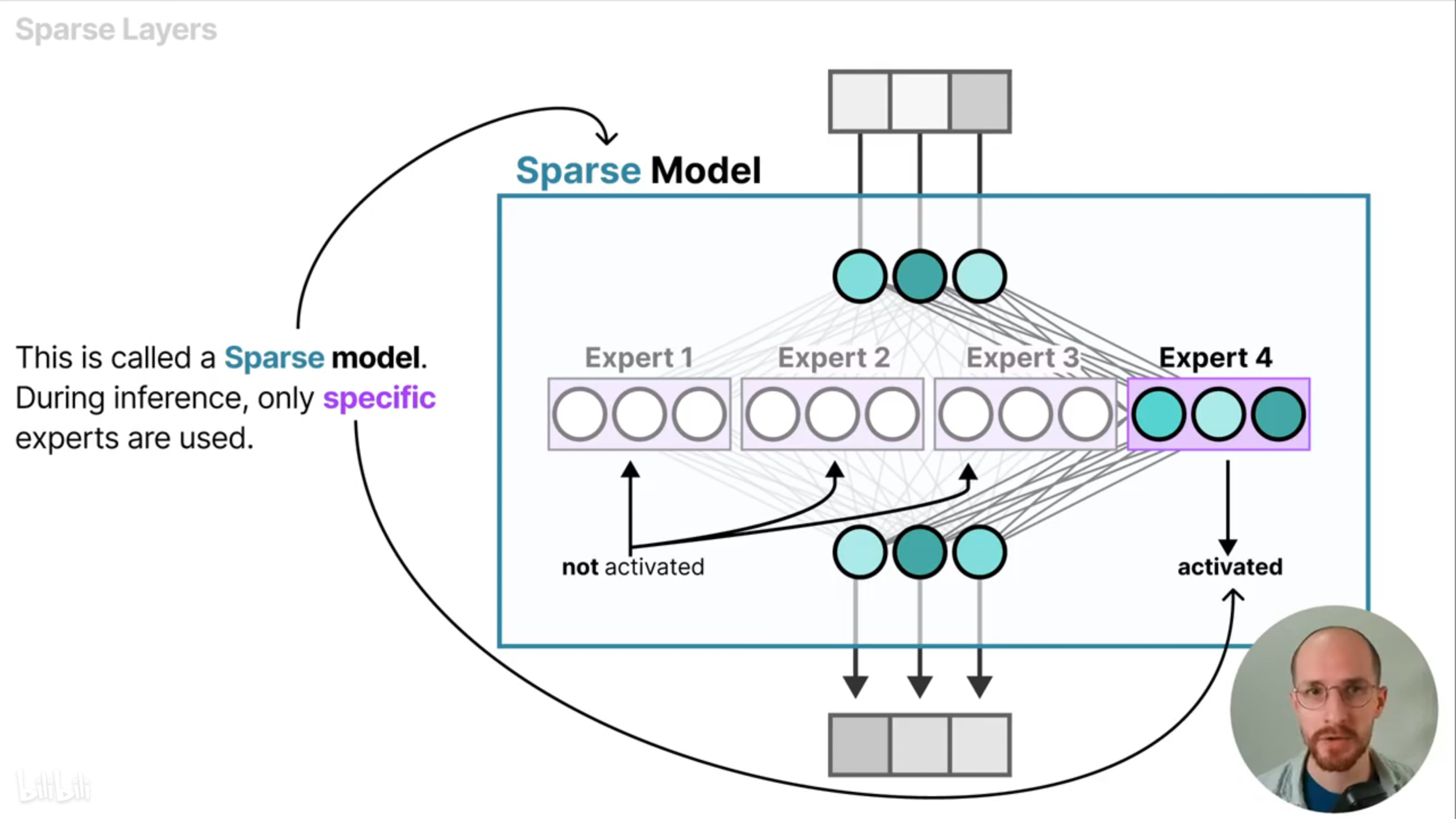
根据输入token的不同,MoE模型会选择最适合的专家,由于LLM通常有多个解码器块,所以给定token会经过不同的专家,形成不同的路径,使得LLM的功能更加强大。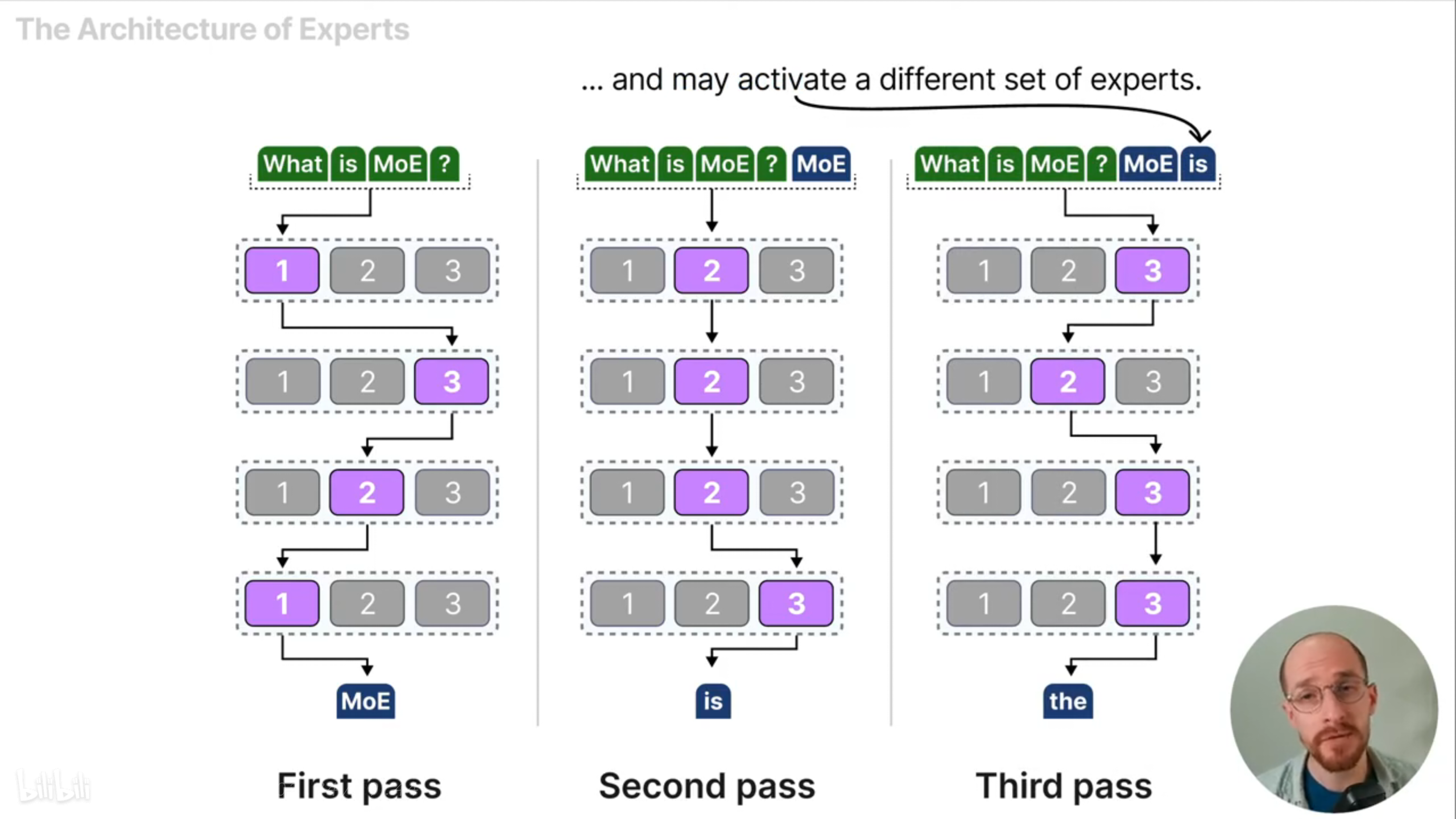
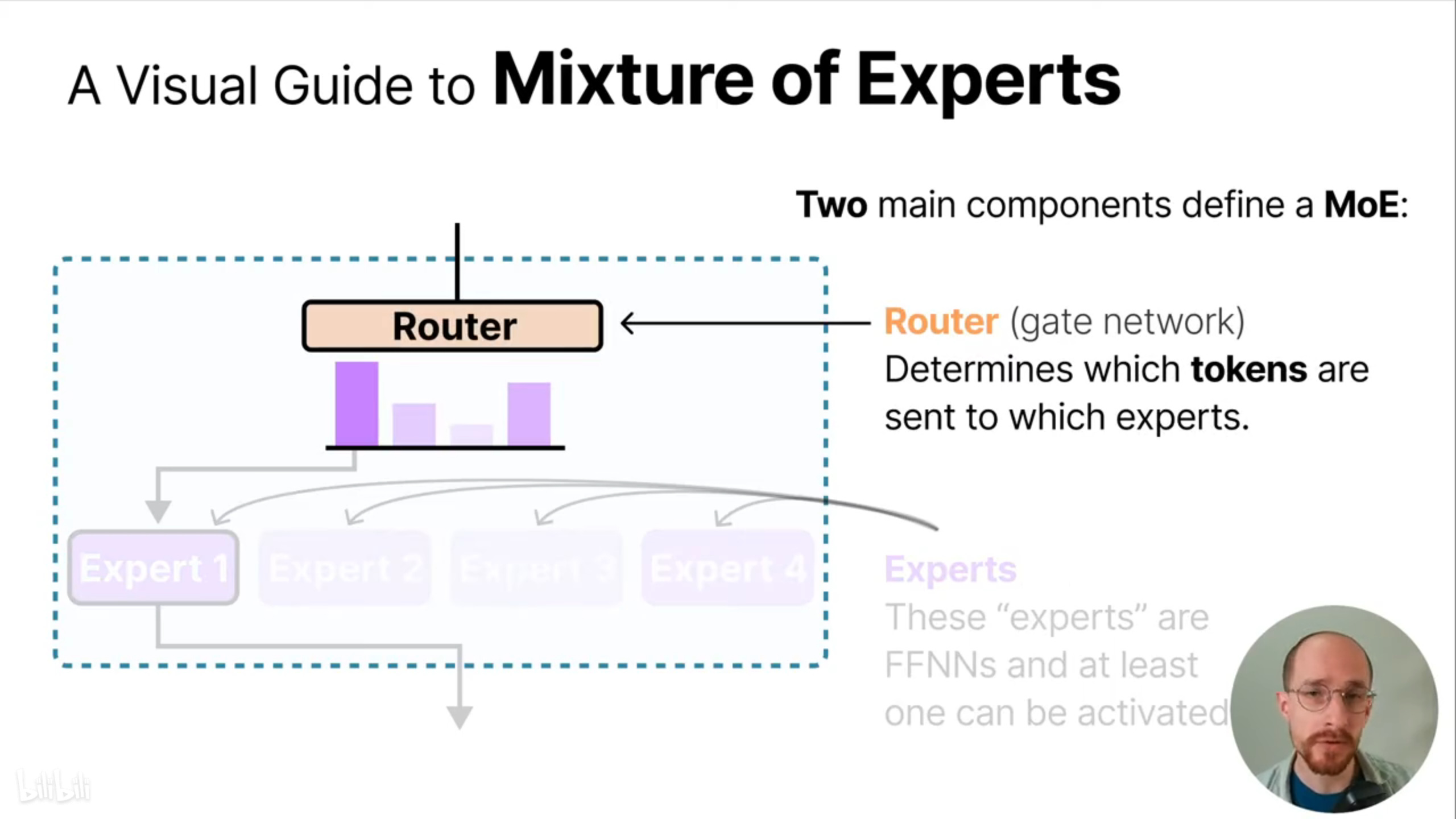
路由机制
路由主要解决如何选择最合适的专家模型的问题。路由主要包含一个前馈神经网络,对前馈神经网络的输出进行softmax得到选择不同专家的概率,MoE的最终输出为被选择专家模型输出的加权。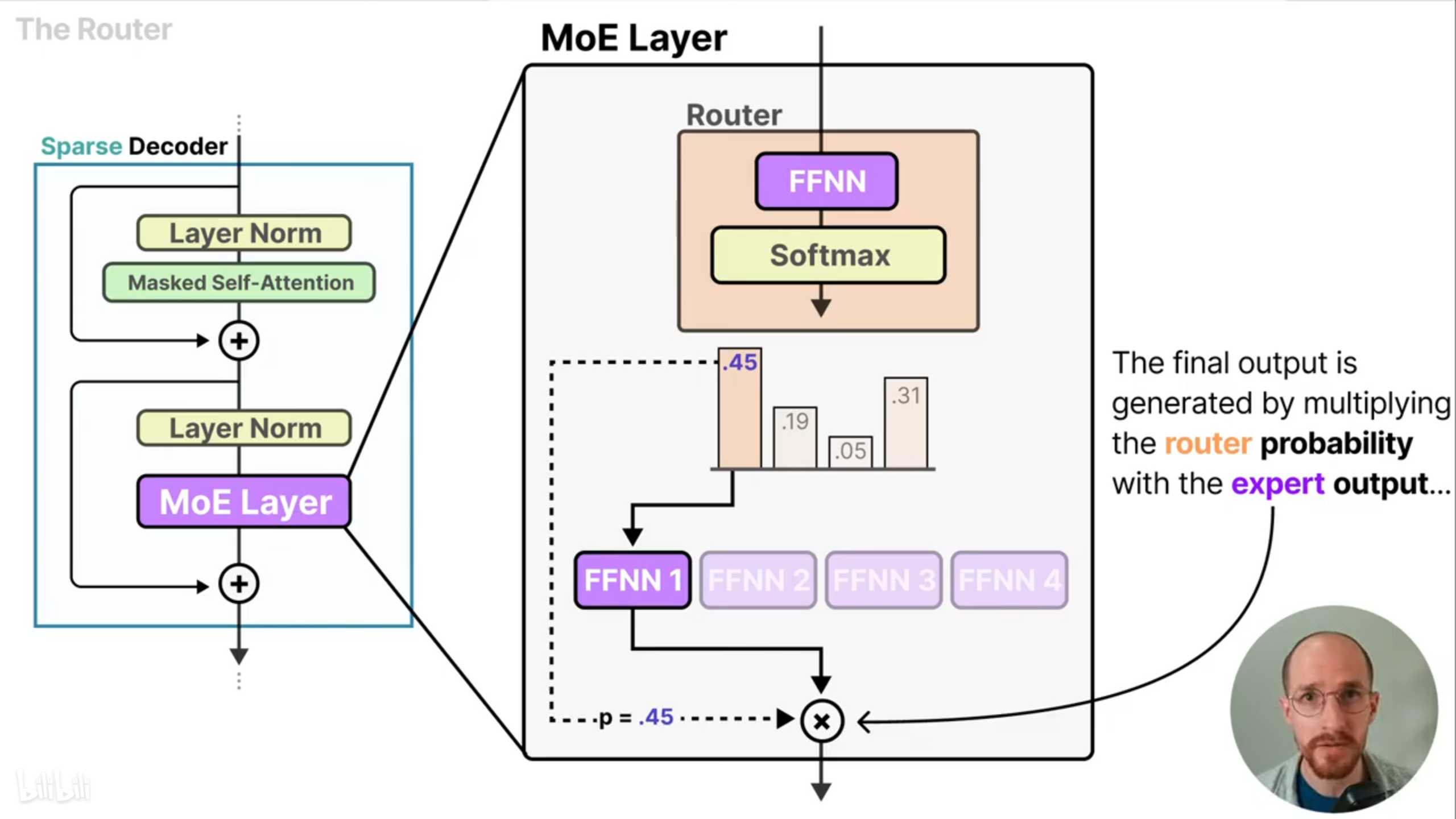
MoE
路由和专家模型一起构成了稀疏解码器中的MoE层,并取代了单一的前馈神经网络。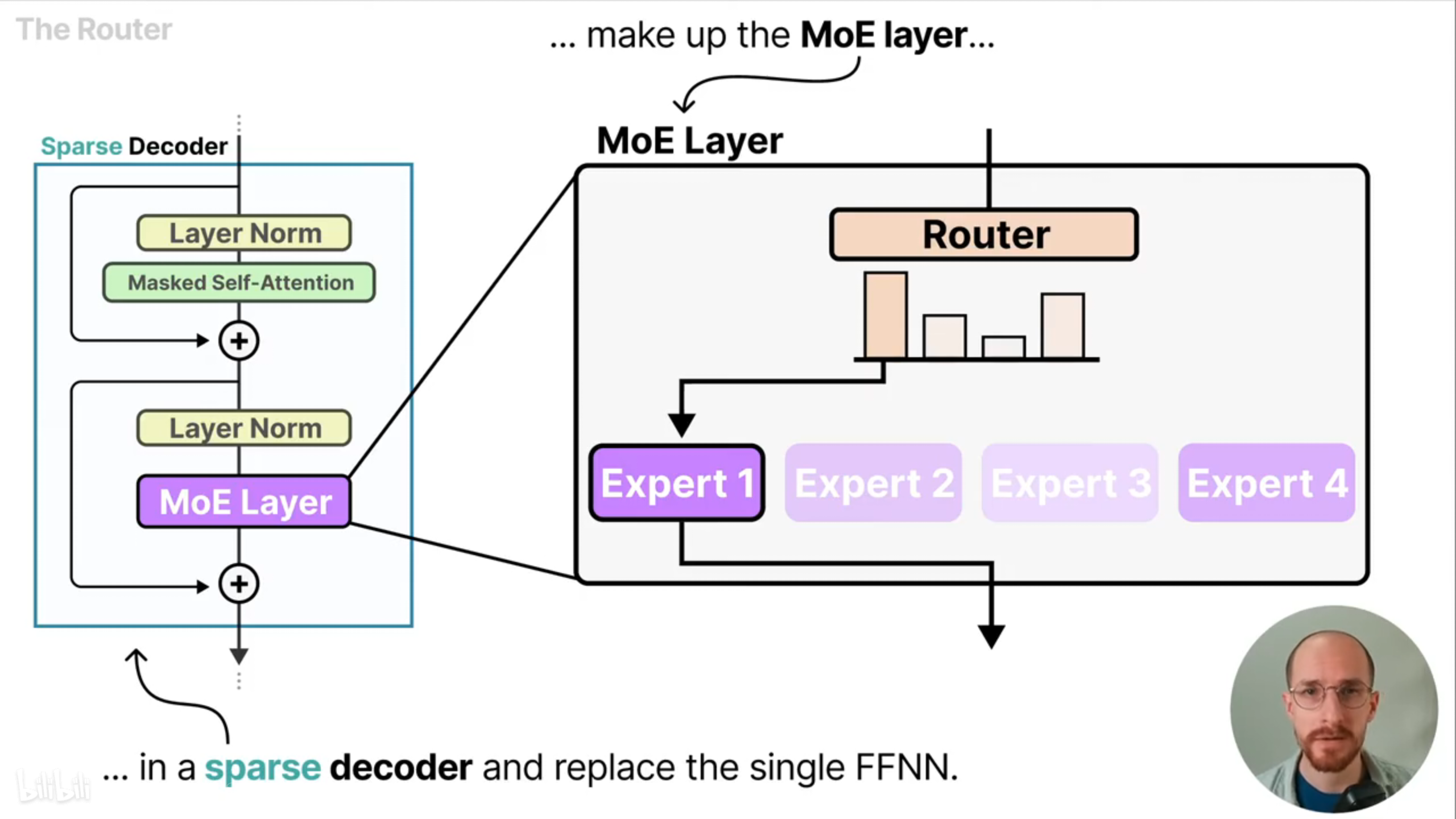
MoE模型仍需将所有参数加载到设备中,但在推理时只需要使用这些参数的一个子集(被激活的专家模型),使得推理速度可以快很多。比如Mixtral8×7B,加载的稀疏参数有46.7B,激活的参数只有12.8B。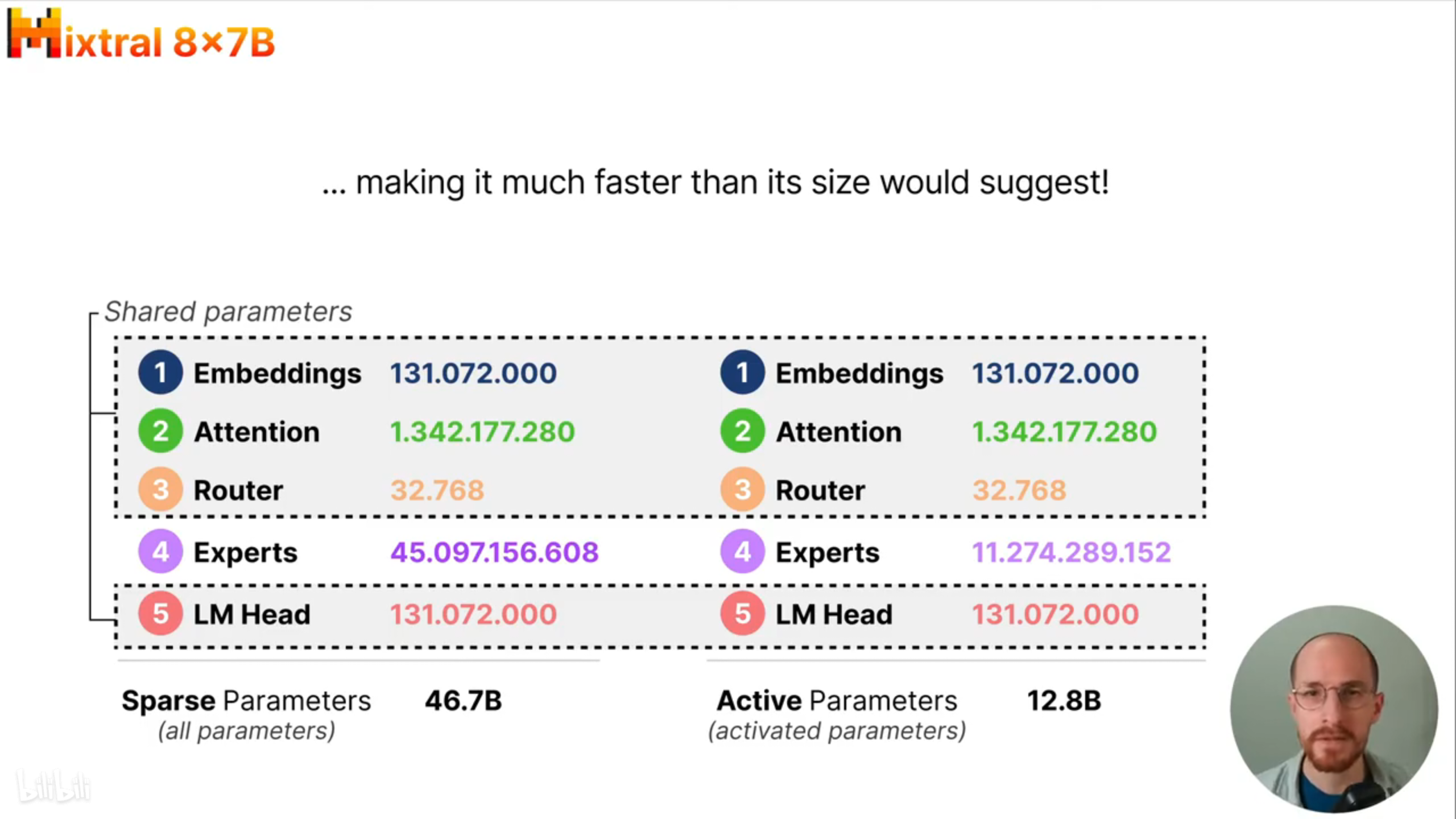
让我们来看看数据如何通过MoE层流动。输入矩阵X(维度为a×b,a是批次大小,b是token的维度)乘以路由权重矩阵W(维度为b×c,c是专家模型的数量),得到路由矩阵H(x)(维度为a×c)。对于每一个输入token,H(x)按行进行softmax得到选择特定专家的概率G(x)(维度为1×c),路由利用这个概率分布选择最适合的专家模型。最后将概率和选择的专家模型的输出相乘得到一个token的输出y。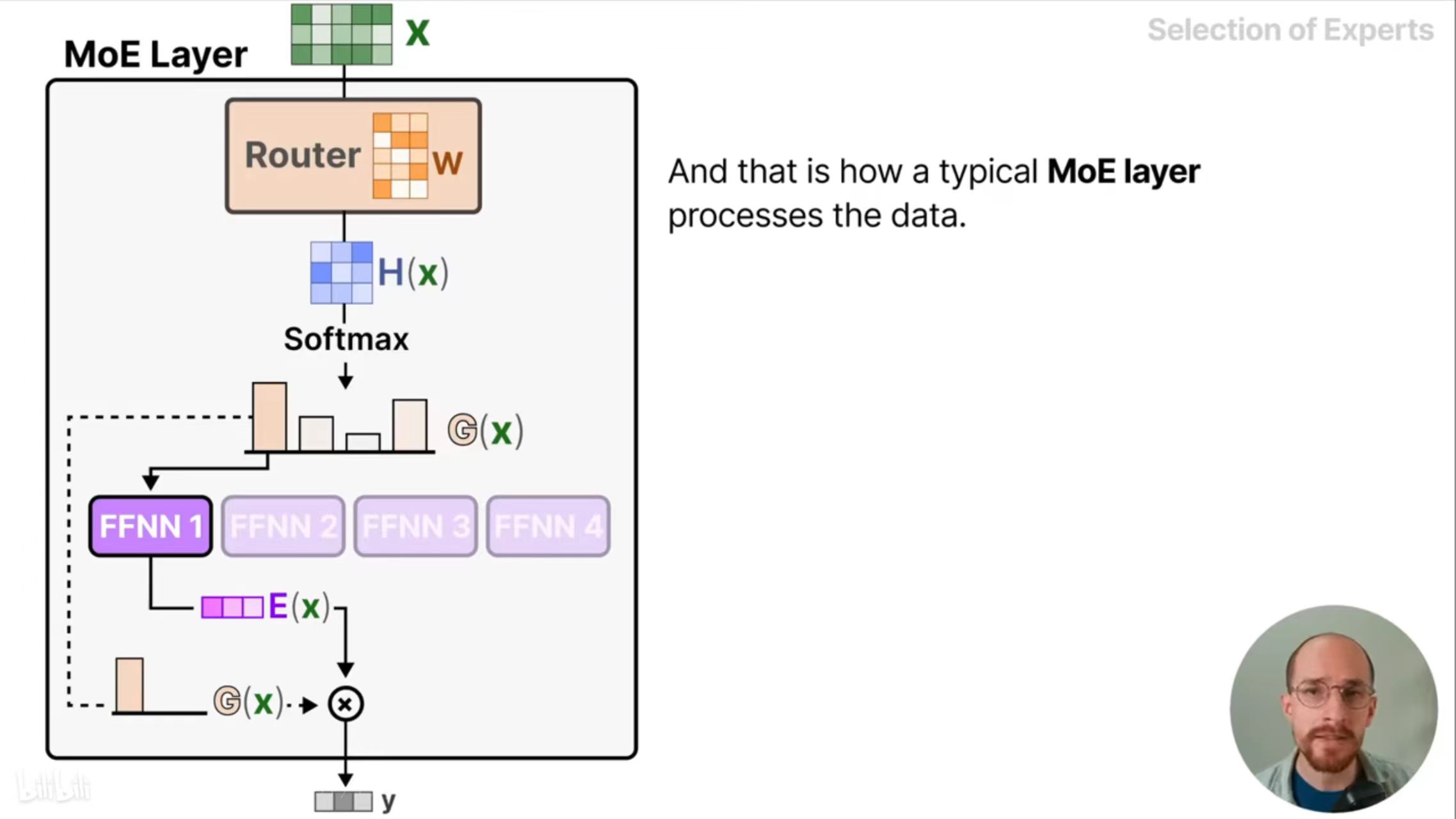
负载均衡与优化
在训练的时候,有些专家模型会比其他专家模型学得更快,导致它经常被选择,这会降低模型的整体能力。相反,我们希望不同的专家都能得到充分的训练,并且被选择的总体概率也是相近的,下面是一些常用的优化策略。
Keep TopK
引入可训练的高斯噪声可以防止路由总是选择同一组专家,因为高斯噪声会导致某些专家的概率变得很低,从而给予其他专家模型更多的训练机会。
另外,需要将除了前k个专家模型以外的权重设为负无穷,经过softmax函数后负无穷的地方会变成0,这可以使没有充分训练的专家赶上被频繁选择的专家。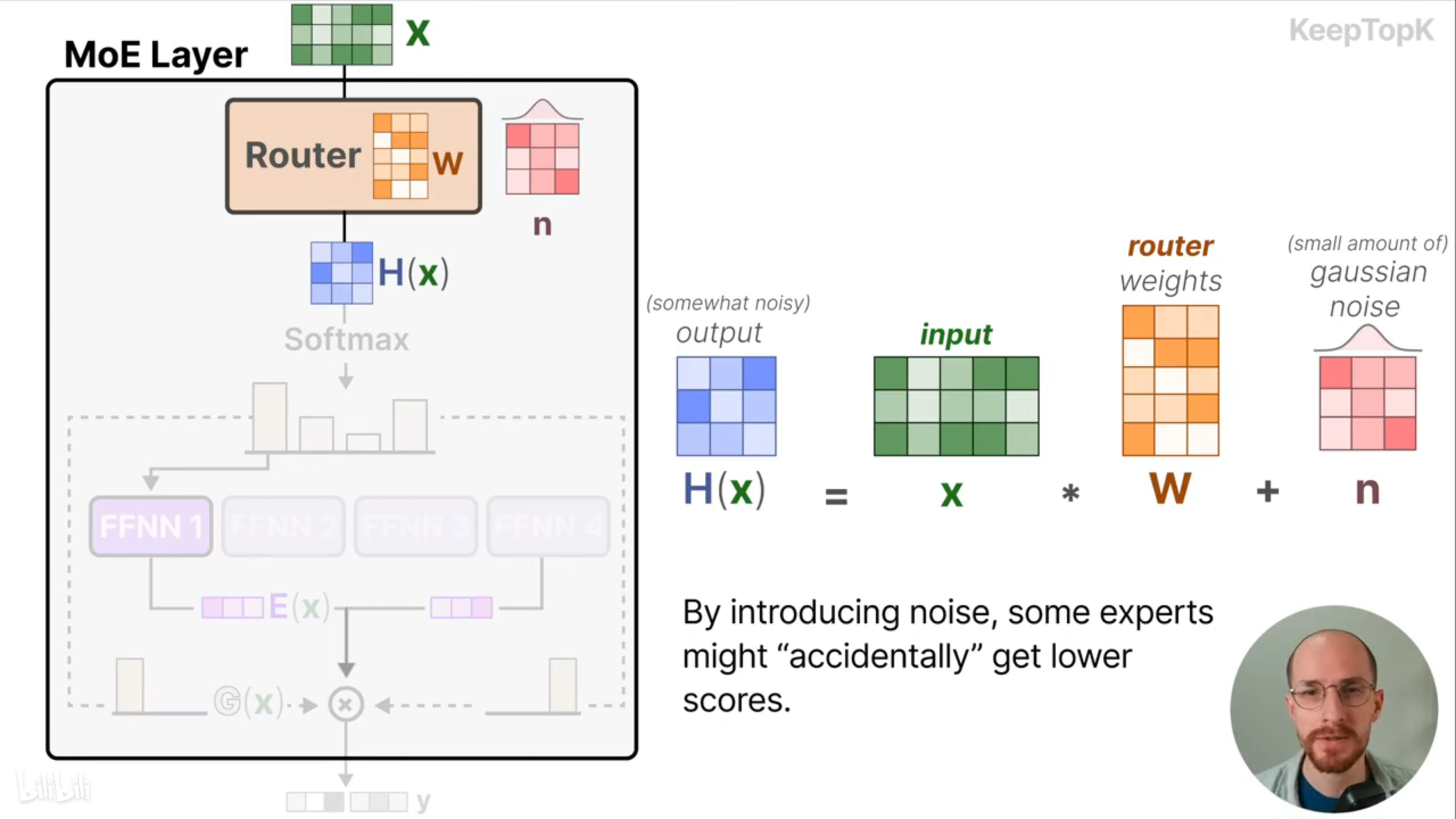
负载均衡损失函数
通过将每个专家关于一个批次token的路由概率得分相加,表示这个批次训练中每个专家被选择的可能性,也就是每个专家的重要性得分(importance score)。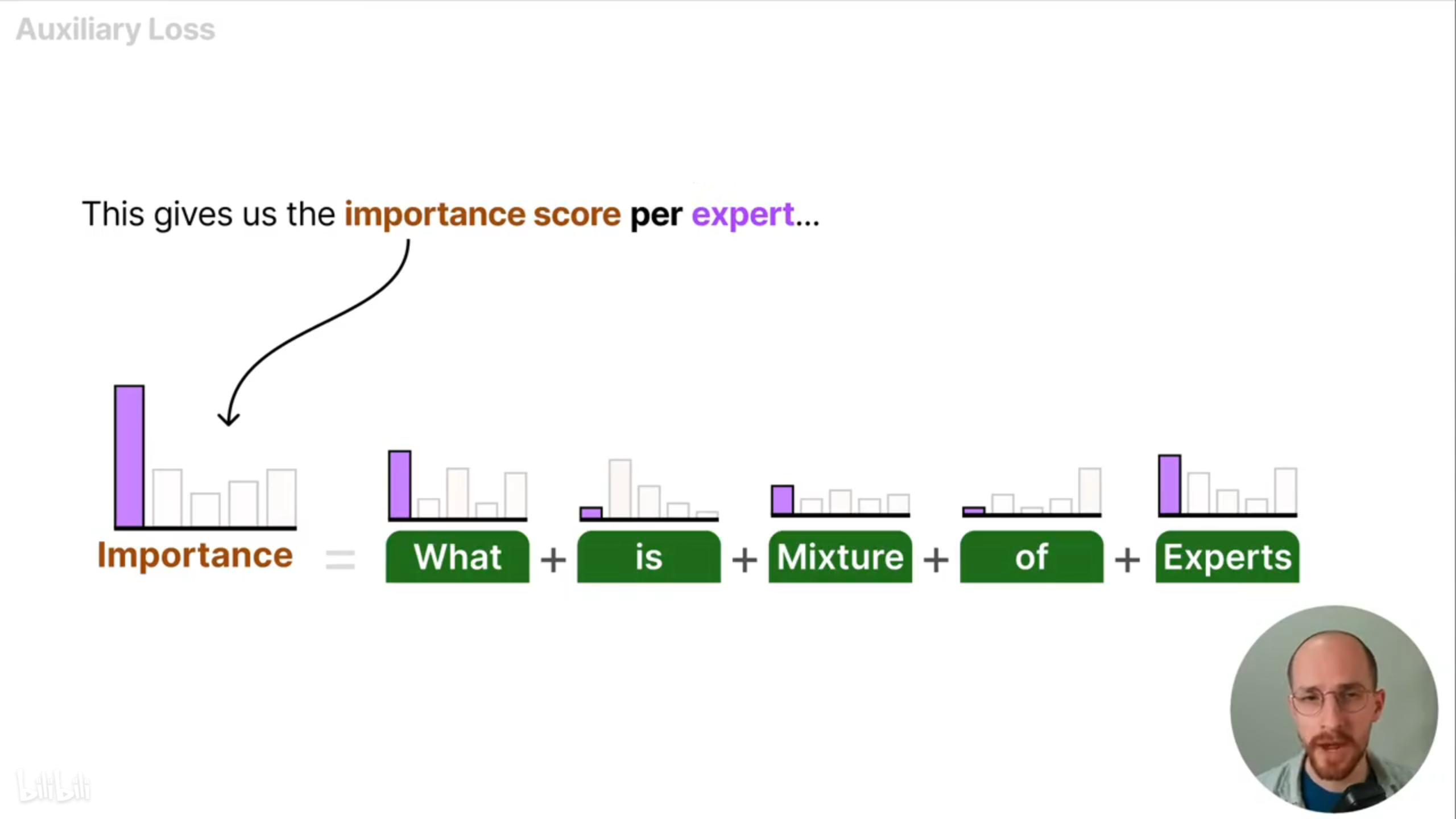
将重要性得分的标准差除以方差,得到变异系数(Coefficient of Variation, CV)。变异系数通常乘以一个常数缩放因子(超参数)作为负载均衡损失。从下图可以看出,重要性分布更均匀的情况下,变异系数得分更低。
负载均衡损失可以使训练过程更稳定,因为所有的专家都有相同的机会被训练。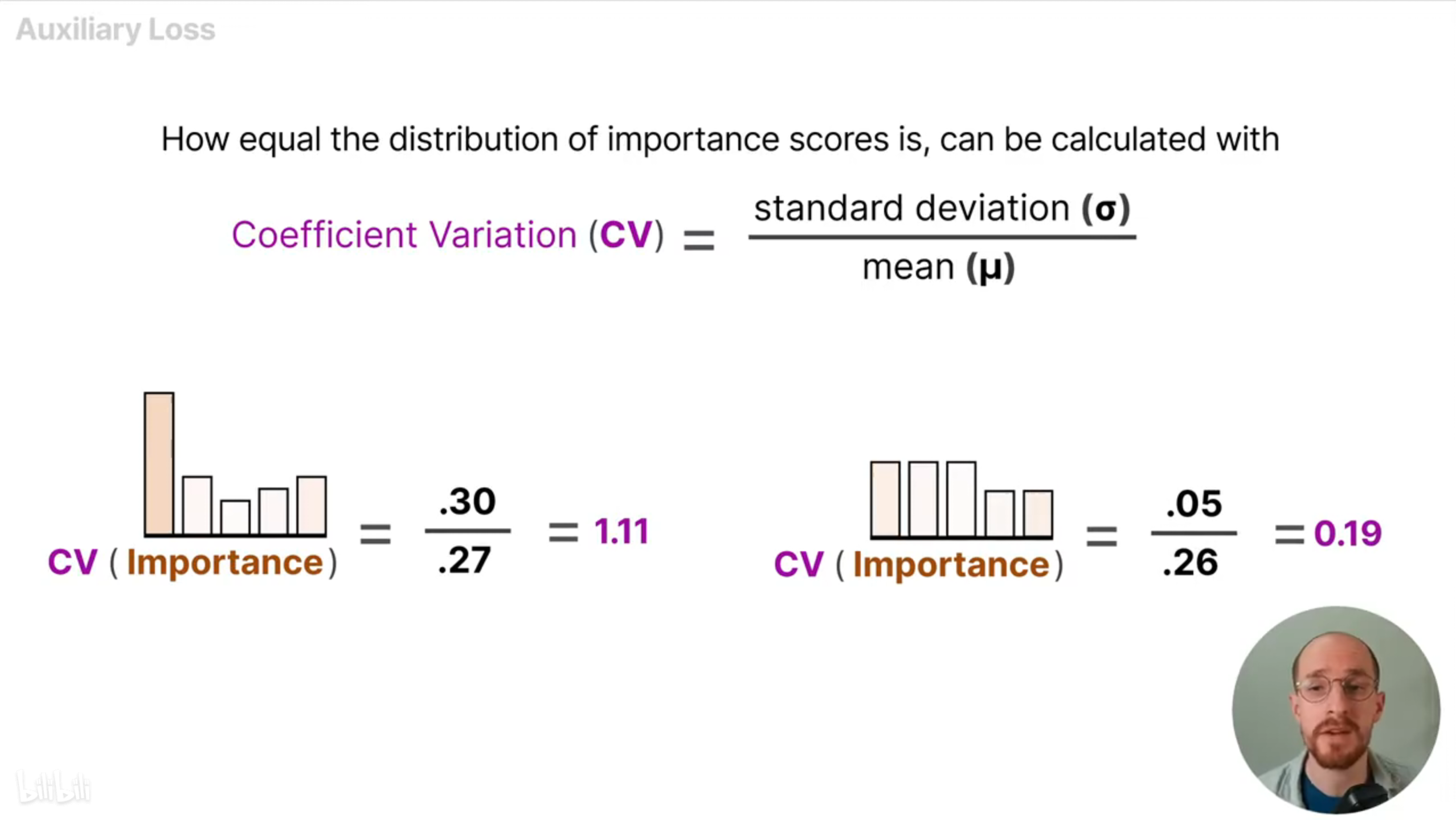
专家容量
专家的不平等不仅体现在被选中的专家上,还体现在被分配给每个专家的token上。比如专家四收到了一个token,而专家一收到剩下的所有token,这就导致专家四训练不足。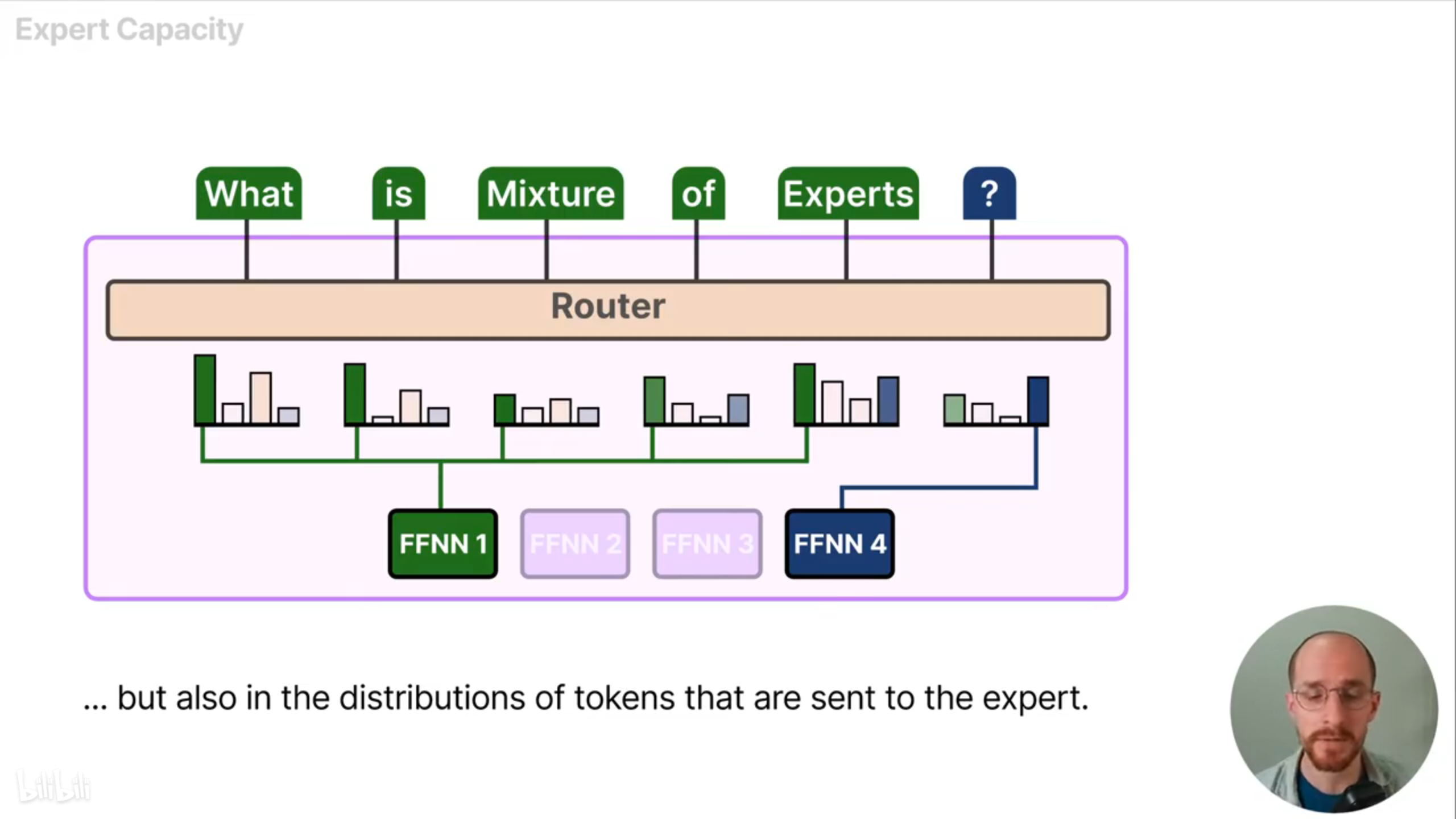
为了解决这个问题,可限制每个专家处理token的上限(称为专家容量),如果某个专家达到了容量上限,剩下的token会被路由到下一个最有可能的专家。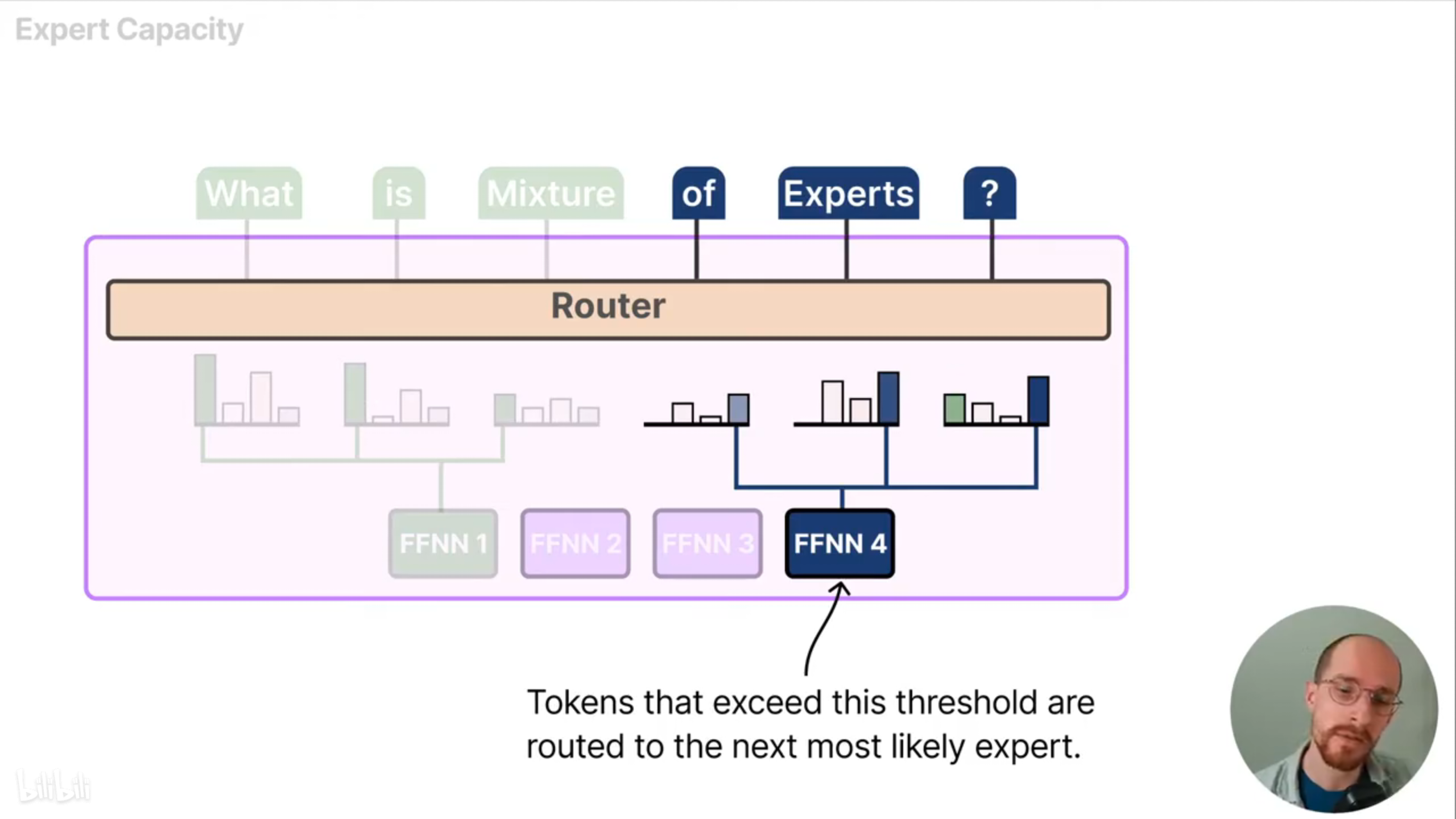
如果两个专家都达到了容量上限,新token会被直接发送到下一层,这被称为“token溢出”。因此,我们需要在token数量、专家容量和token溢出数量之间找到一个平衡。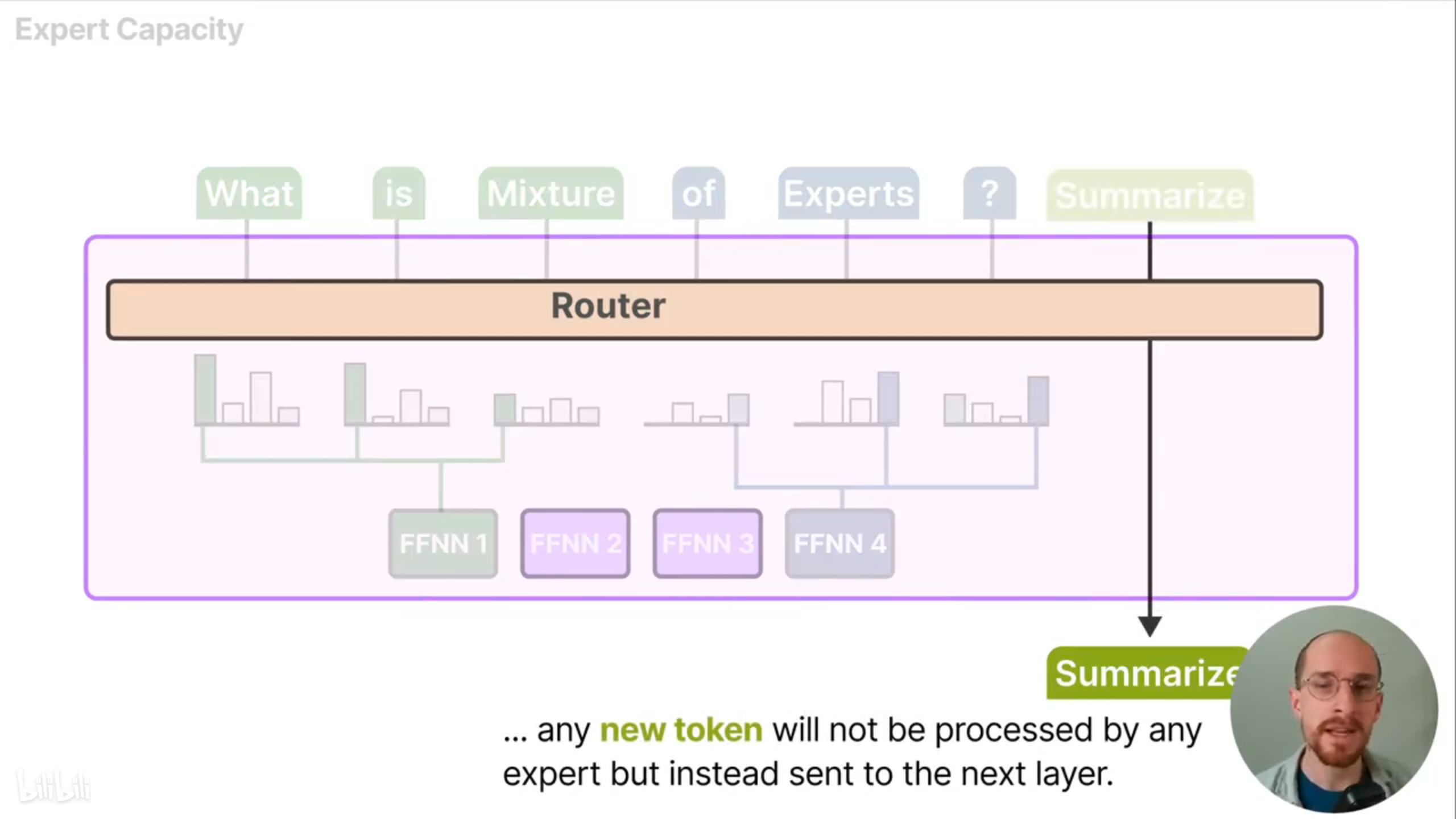
视觉模型中的混合专家模型
混合专家模型也可以使用到视觉模型中。首先了解下视觉transformer,为了执行与文本相同的token化过程,可将图片切分成不同的图像块,每块内容是一个token;然后将图像块展平成一个序列,经过线性投影并加入位置编码信息,得到嵌入向量。这个嵌入向量的维度与文本的token是类似的,因此视觉transformer的编码器和文本的是相同的,所以也可以很好地应用MoE模型。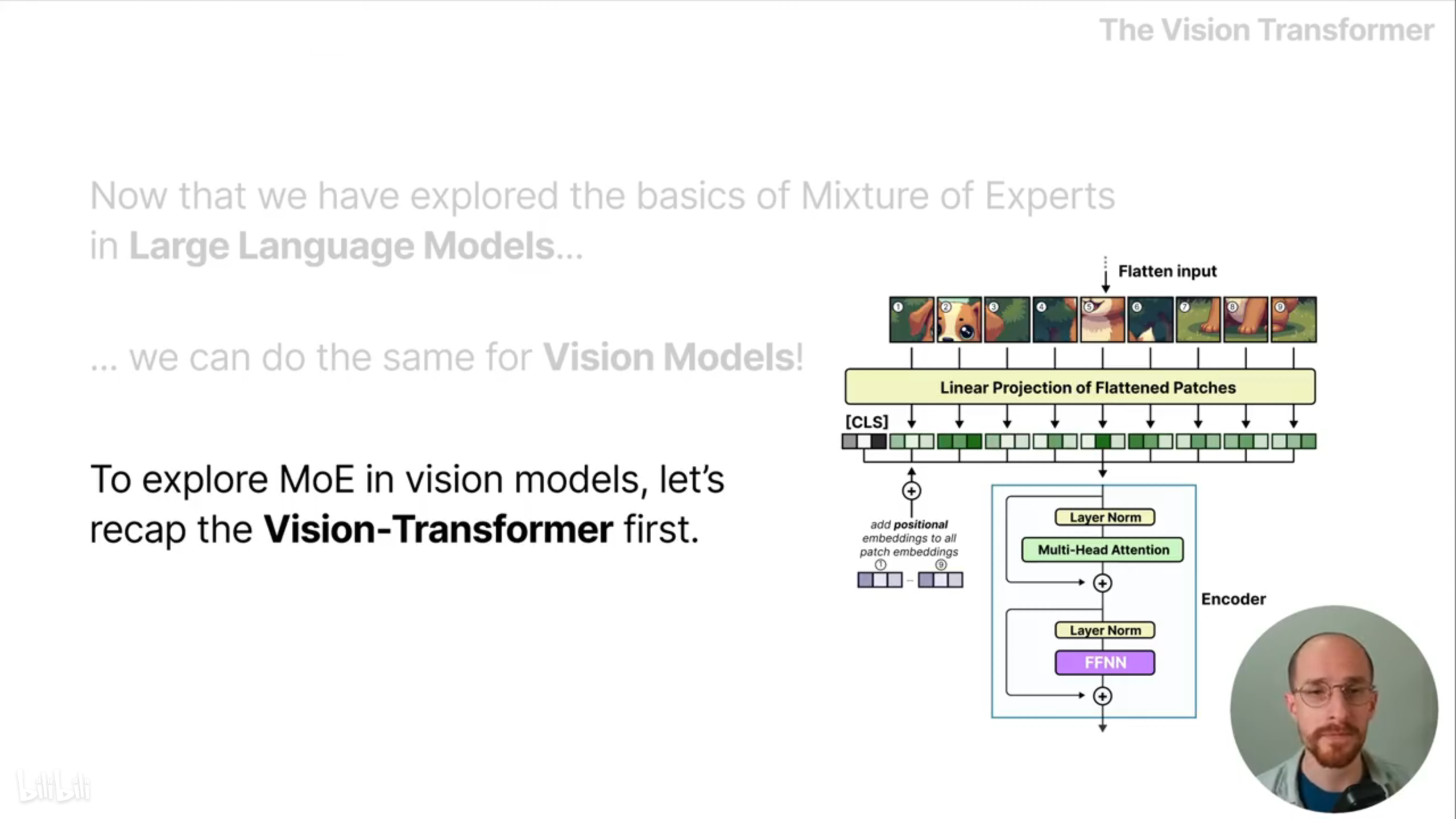
由于图像通常包含很多块,所以一般会给每个专家设置较低的容量来减少硬件限制,但是低容量会导致某些图像块被丢弃。
为解决这个问题,可使用优先级评分为不同块分配重要分数,最重要的块可以被优先处理,也就可以得到对原始图像更精准的表示。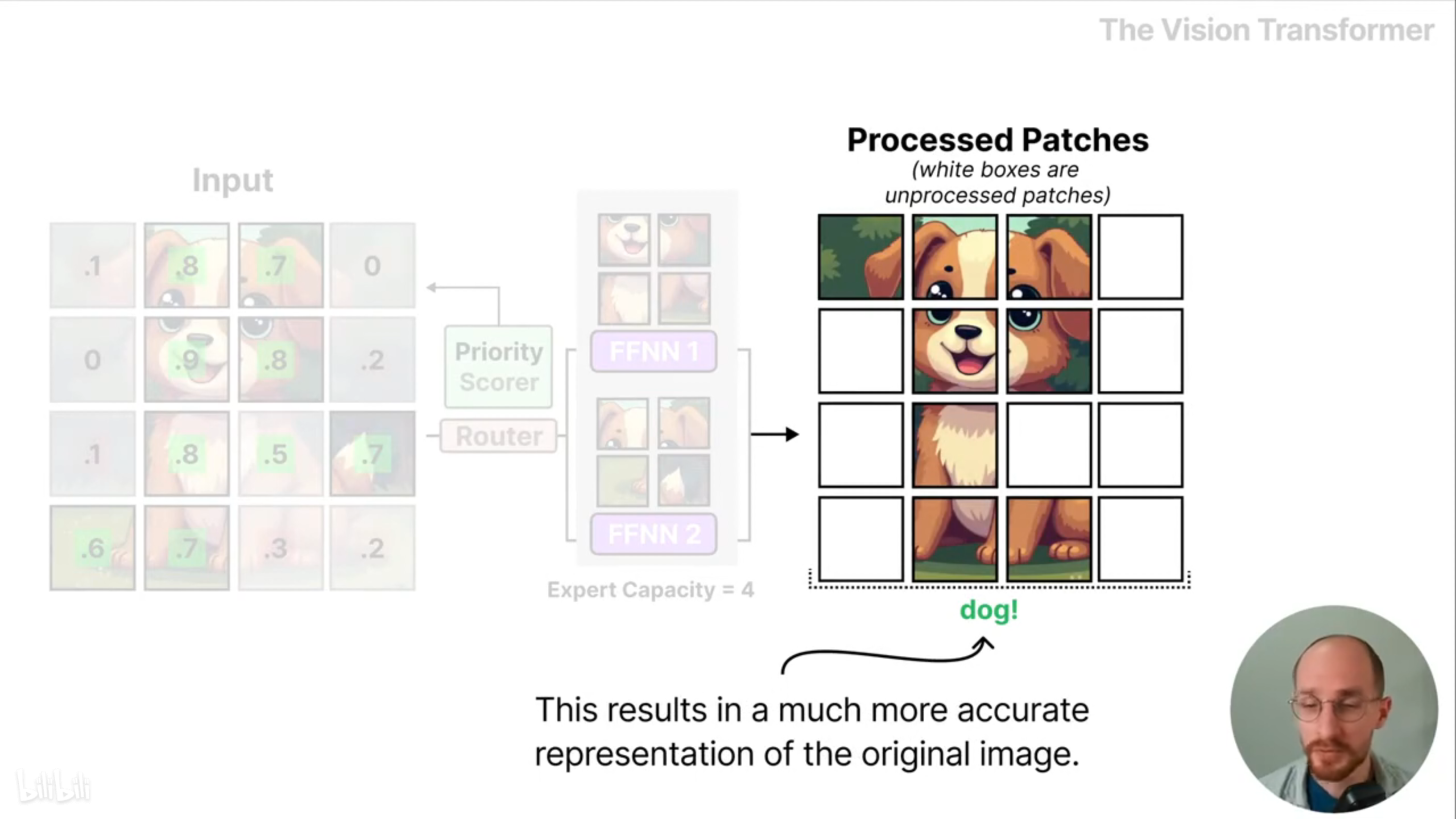
但是丢弃图像信息依旧不是一个好选择,为了利用所有的图像信息,软MoE将所有的图像块根据优先级分数加权混合,作为MoE的输入。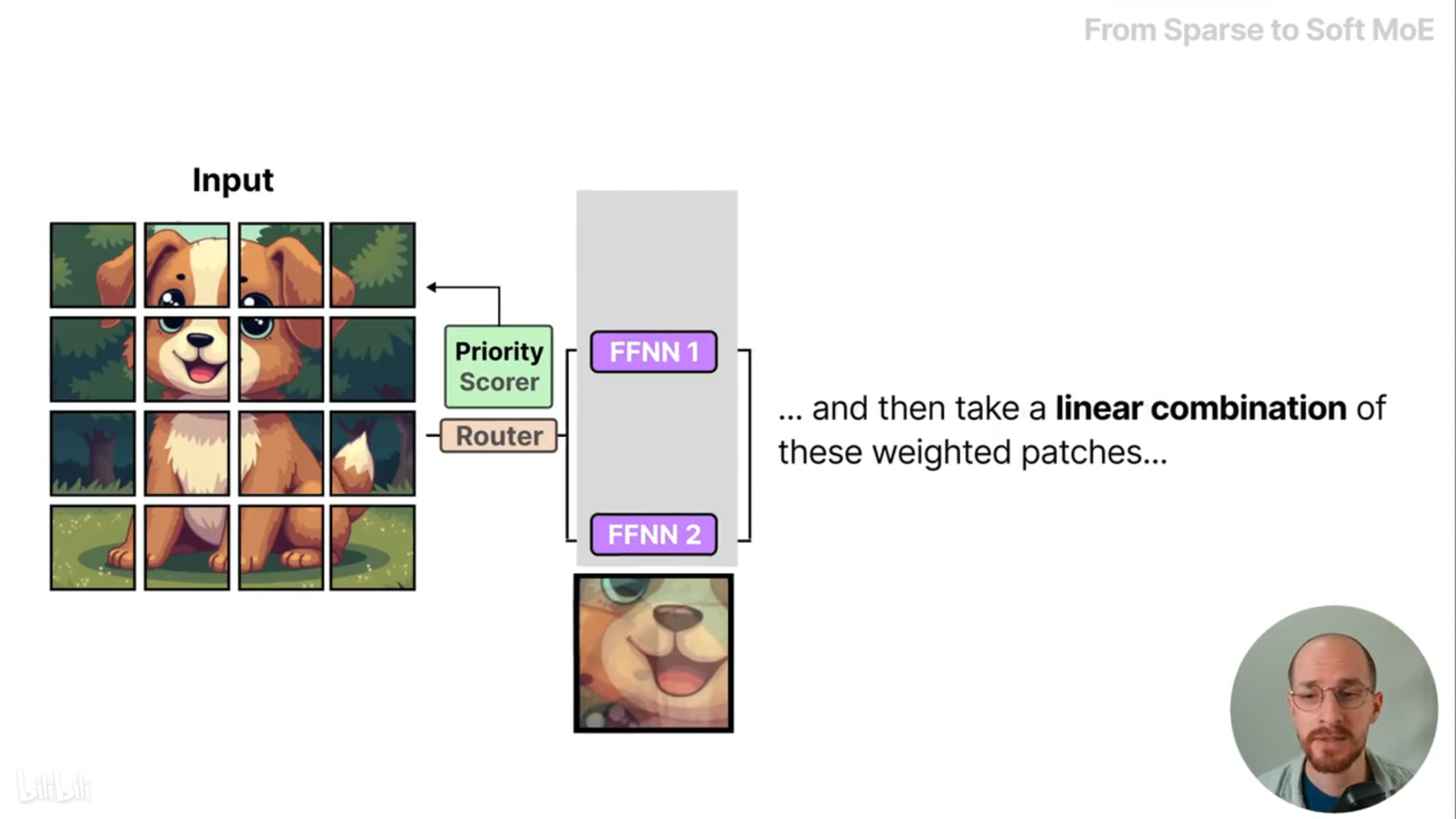
让我们来看看具体的数据流动。输入矩阵X(维度为a×b,a是批次大小,b是token的维度)乘以一个可学习的矩阵Φ(维度为b×c,c为专家容量*专家数量),得到矩阵R(维度为a×c),表示特定图像块和某个专家有多相关。对R进行列上的softmax,表示这个批次的所有图像块和某一专家有多相关,根据这个相关性,对整个批次的图像块进行加权混合,得到这个专家的一个输入x’(维度为1×b)。加权混合的输入x’会被路由到最适合的专家,然后经过专家模型得到输出y,随后,对R进行行上的softmax,表示某一图像块在不同专家的输入x’中的占比,根据这个占比,将所有专家的输出进行加权求和得到其中一个图像块的最终的输出y’。
这个架构在图像块级别影响输入,在专家级别影响输出。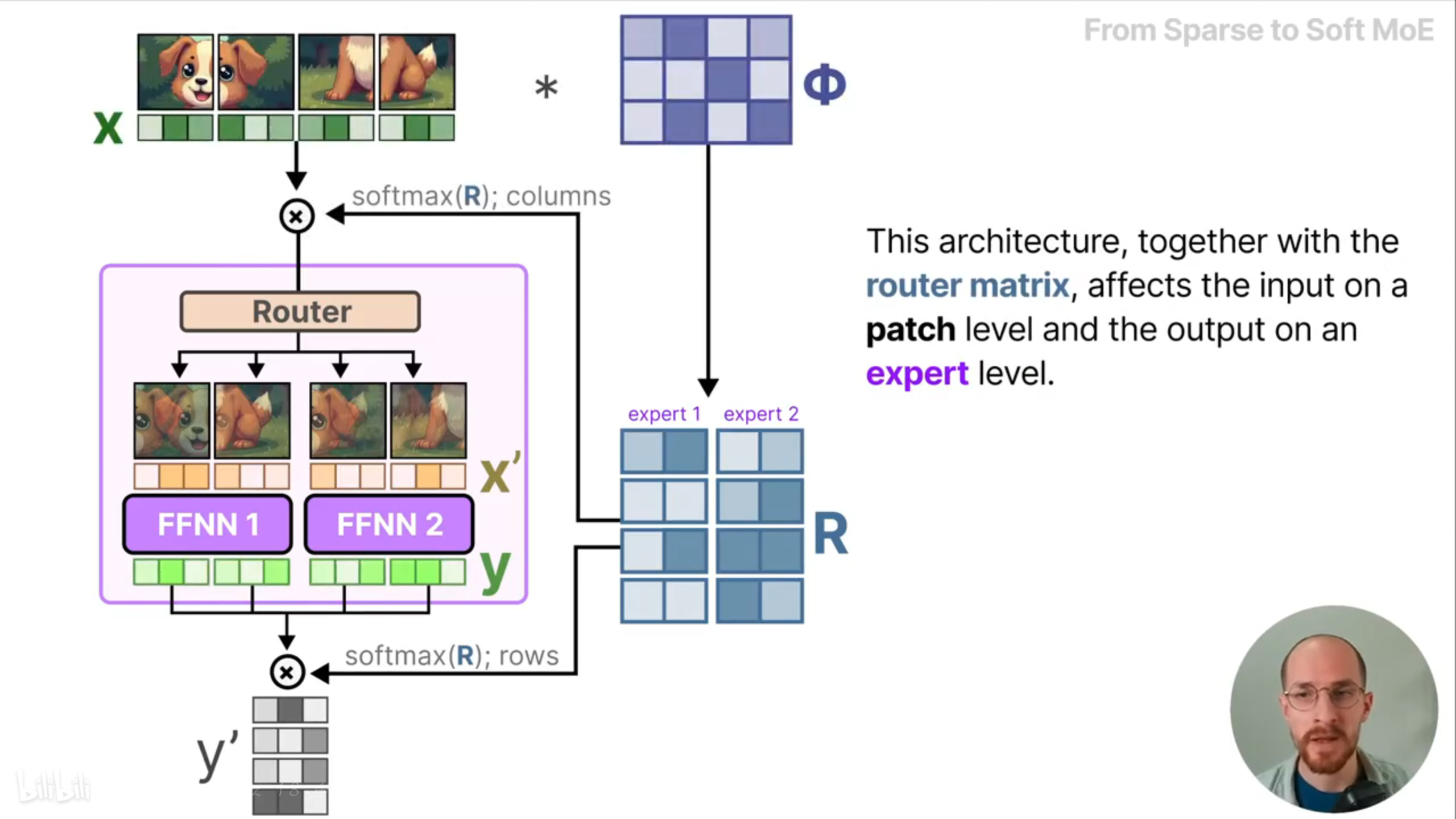
由于transformer可应用在视觉领域,类似MoE的技术也同样可以应用在视觉领域,因此,任何对LLM的改进都有可能对多模态模型有理论和实践上的影响。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)