文件存储数据
一.以Word形式存储
1.环境安装
安装python-docx库,使用命令:
pip install python-docx如果需要在Windows下调用Word应用程序本身,比如处理.doc格式或者加密,需要用到pywin32库
pip install pywin32但是使用python-docx是最主流的方式,虽然只使用于.docx格式的Word文件,但是python-docx支持跨平台使用,并且容易上手。
两种库的对比:
| 特性 | python-docx |
win32com.client |
|---|---|---|
| 跨平台性 | ✅ 支持 Windows/Linux/Mac | ❌ 仅支持 Windows |
| 文件格式 | 仅支持 .docx |
支持 .doc 和 .docx |
| 学习难度 | 简单,API 直观 | 较难,需了解 COM 对象 |
| 主要优势 | 轻量级,适合生成和修改内容 | 功能极强,可加密、转PDF、调用宏 |
| 适用场景 | 自动生成报告、简历、批量替换 | 办公自动化(OA)深度集成、文档加密 |
2.python-docx库的使用
前言:
python-docx将Word文档看成一个树形结构,主要有三个层级:
- Document(文档):代表整个.docx文件,是容器
- Paragraph(段落):表示文本中的文本块,注意:每次回车都会产生一个新段落
- Run(文本块):段落中具有相同样式的一段文本。比如一个段落里既有粗体又有斜体,它们就是不同的Run
1.基本使用:创建和保存文档
from docx import Document
#创建文件对象(创建一个新的空白文档)
doc = Document()
# print(doc)#<docx.document.Document object at 0x000001644C502270>
# print(type(doc))#<class 'docx.document.Document'>
#保存文档,填写文档的名称
doc.save('output.docx')2.基本使用:写入文本与标题
from docx import Document
#创建文件对象(创建一个新的空白文档)
doc = Document()
#---添加标题---
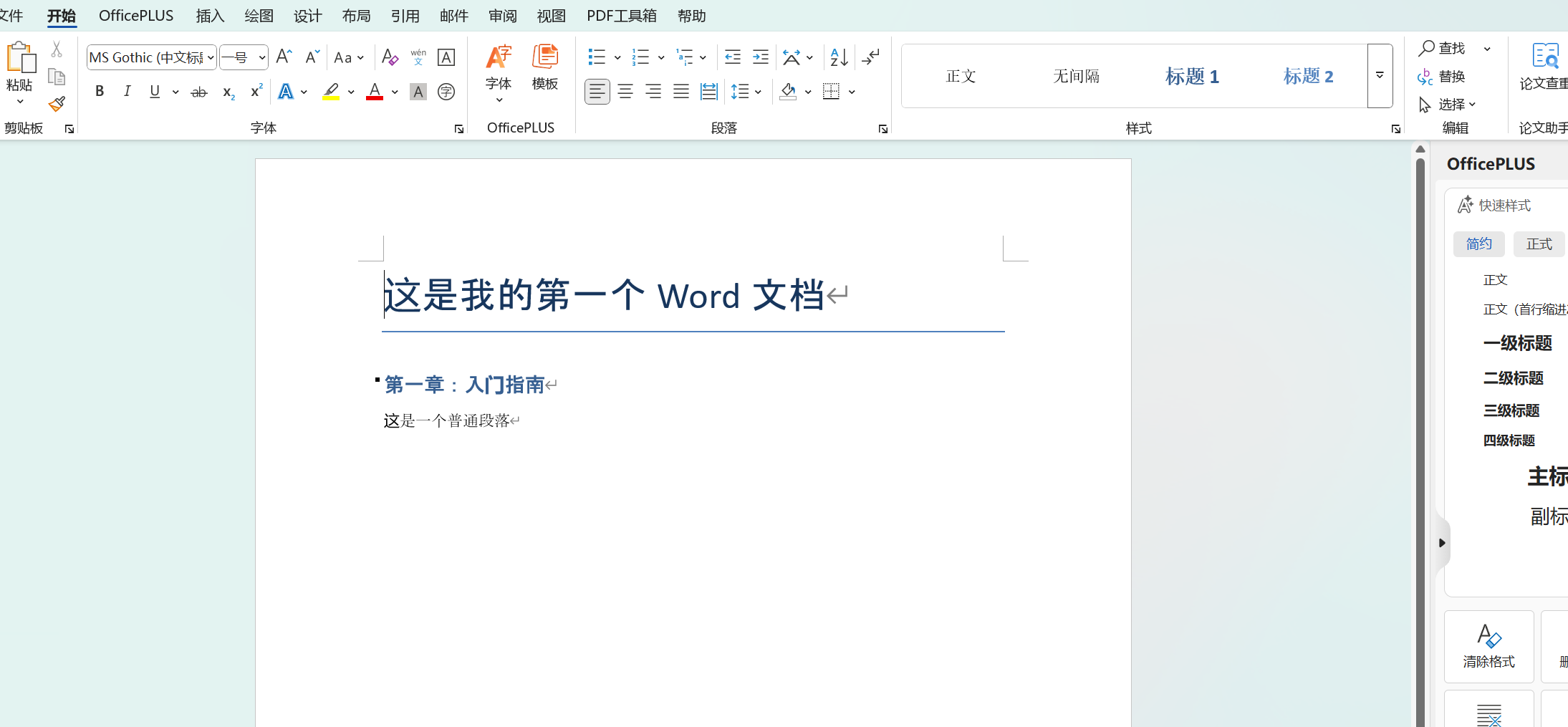
#level=0是文档标题,无缩进;level=1是标题1;以此类推...
doc.add_heading("这是我的第一个Word文档",level=0)
doc.add_heading("第一章:入门指南",level=1)
#---添加普通段落---
doc.add_paragraph("这是一个普通段落")
#保存文档,填写文档的名称
doc.save('output.docx')效果:
3.Paragraph类的.add_run方法
Paragraph类的.add_run()方法用于:
在一个段落(Paragraph)里添加一段具有独立样式的文本块(Run)
from docx import Document
from docx.shared import RGBColor
#打开一个.docx文件
doc = Document('output.docx')
#创建一个空的段落
paragraph = doc.add_paragraph()
#在该段落中添加多个Run
run1 = paragraph.add_run('普通文本')
run2 = paragraph.add_run('加粗文本')
run2.bold = True#设置加粗
run3 = paragraph.add_run('红色文本')
run3.font.color.rgb = RGBColor(255,0,0)
#注意:python-docx对文档的修改只存在于内存中,必须显式调用.save()才会将修改的内容存入磁盘
doc.save("output.docx")效果:

4.插入表格
1.最基础的:插入空表格
from docx import Document
#读入存在的docx文件
doc = Document('output.docx')
#添加一个3行2列的表格
table = doc.add_table(rows=3, cols=2)#创建的是空表格
doc.save('output.docx')效果:

2.填充表格内容
方法1:通过cell(row,col).text直接赋值(最常用)
from docx import Document
#读入存在的docx文件
doc = Document('output.docx')
#添加一个3行2列的表格
table = doc.add_table(rows=3, cols=2)
#填充表格内容
##设置表头
table.cell(0,0).text = "姓名"
table.cell(0,1).text = "年龄"
##设置数据行
table.cell(1,0).text = "张三"
table.cell(1,1).text = '25'
table.cell(2,0).text = "李四"
table.cell(2,1).text = '30'
doc.save('output.docx')效果:

方法2:遍历并批量填充
from docx import Document
doc = Document('output.docx')
data = [
['姓名', '年龄', '城市'],
['张三', '25', '北京'],
['李四', '30', '上海'],
['王五', '28', '广州']
]
# 先创建表格(行数 = len(data),列数 = len(data[0]))
table = doc.add_table(rows=len(data), cols=len(data[0]))
# 填充数据
for i, row_data in enumerate(data):
for j, cell_text in enumerate(row_data):
table.cell(i, j).text = cell_text
doc.save('output.docx')效果:

5.设置表格样式
📌 常用内置样式名(注意大小写!)
| 样式名称(英文) | 效果 |
|---|---|
'Table Grid' |
最常用!带完整边框的网格表 |
'Light Shading' |
表头浅灰底纹 |
'Colorful Grid' |
彩色边框(依赖 Office 主题) |
'Medium Shading 1' |
表头深色底纹 + 隔行变色 |
'Plain Table 1' ~ 'Plain Table 5' |
简洁无底纹,不同边框风格 |
💡 如何获取准确的样式名?
- 在 Word 中手动创建一个表格
- 应用你想要的样式
- 右键表格 → “表格属性” → “边框和底纹” → 查看“样式”名称
- 或直接使用上面列出的通用名称(跨版本兼容性好)
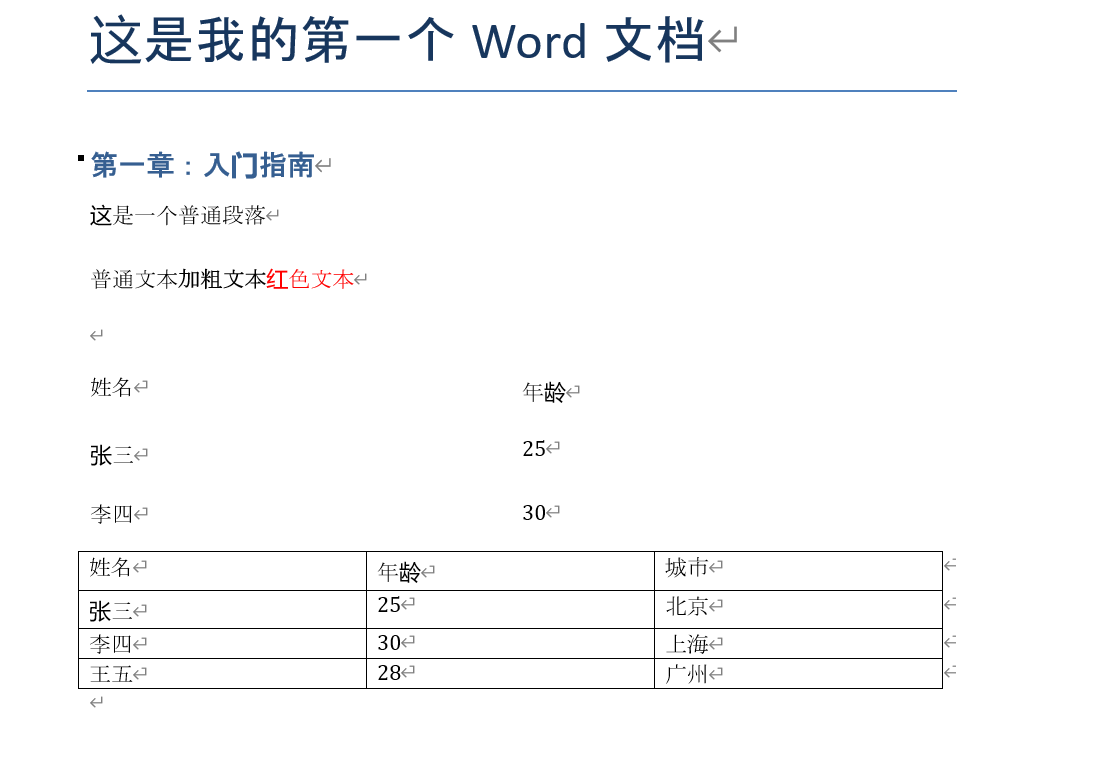
这里就只为第2个表格设置样式
from docx import Document
doc = Document('output.docx')
#遍历所有表格?可以!但我只想为第二个表格设置样式
if doc.tables:#确保文档中有表格
seconde_table = doc.tables[1]
seconde_table.style = 'Table Grid'#最常用的样式,带完整边框的网格表
doc.save('output.docx')#也可以换一个新的文件名,即把修改的内容存储到新的文件中,避免对原始文件进行修改效果:
6.插入图片
1.最基本的插入
from docx import Document
doc = Document('output.docx')
#插入图片(自动按原始比例进行缩放)
doc.add_picture('../../Picture/OIP-C.jpg')#这里的路径很容易搞错
doc.save('output.docx')注意:我的py文件是在“文件存储”这个文件夹下的子文件夹“Word文件”中的,而图片是存放在与文件存储这个文件夹的同级目录的“Picture”这个文件夹中的
使用“..”(表示上级目录)来表示图片的正确路径!!!
效果:

2.控制图片尺寸
可以指定插入图片的宽度(width)或高度(height),另一个维度会自动按比例缩放
如果同时指定宽高,图片会被拉伸(可能变形)
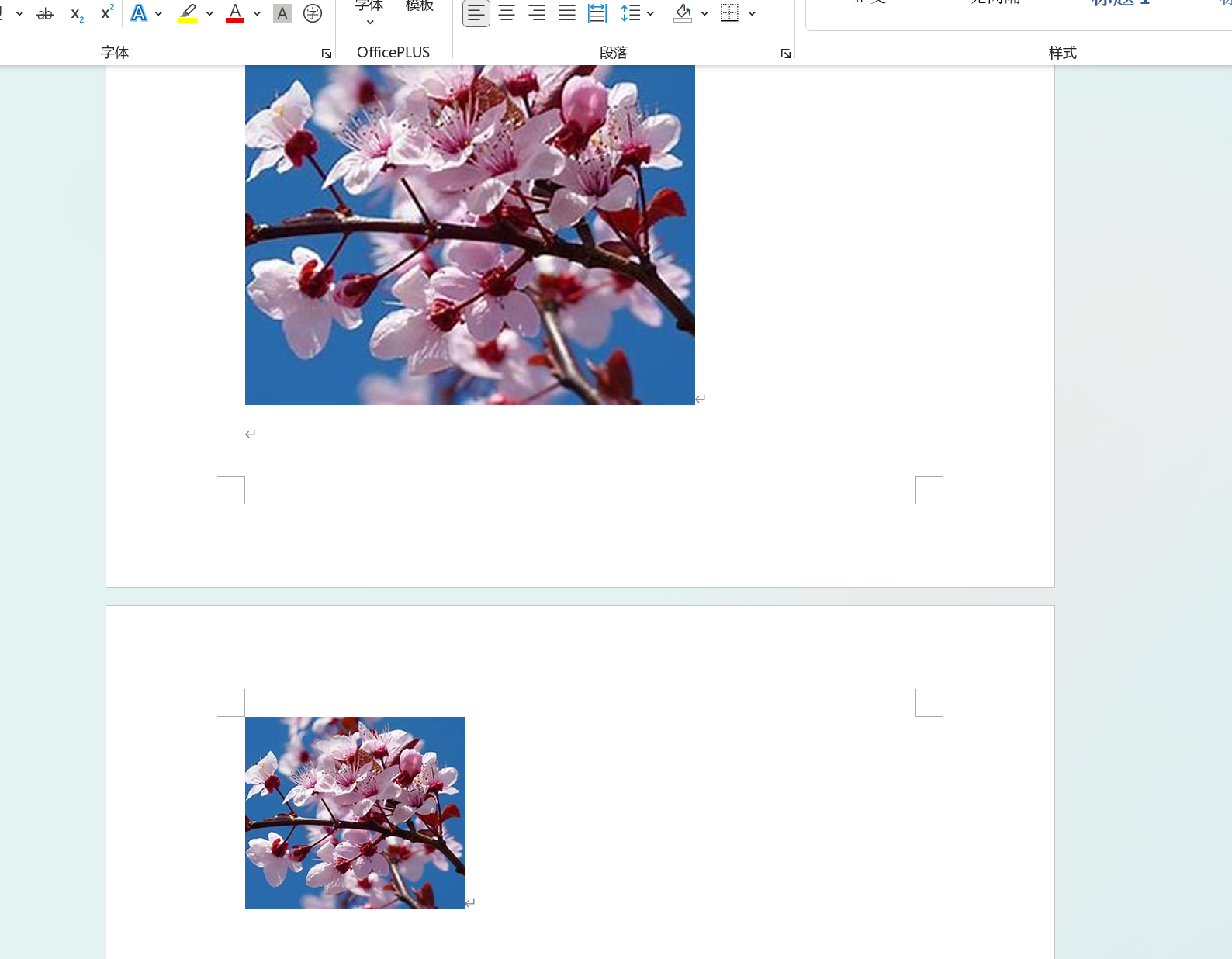
from docx import Document
from docx.shared import Cm#也可以导入Inches用英寸来设置
doc = Document('output.docx')
doc.add_picture("../../Picture/OIP-C.jpg", width=Cm(5))#设置图片宽度为5cm
doc.save('output.docx')效果:
3.将图片插入到特定位置
Document类的add_picture()方法默认在文档末尾添加一个独立段落来用于插入图片
如果希望图片出现在某段文字中间,需要:
- 先创建段落
- 在段落中通过add_run().add_picture()插入
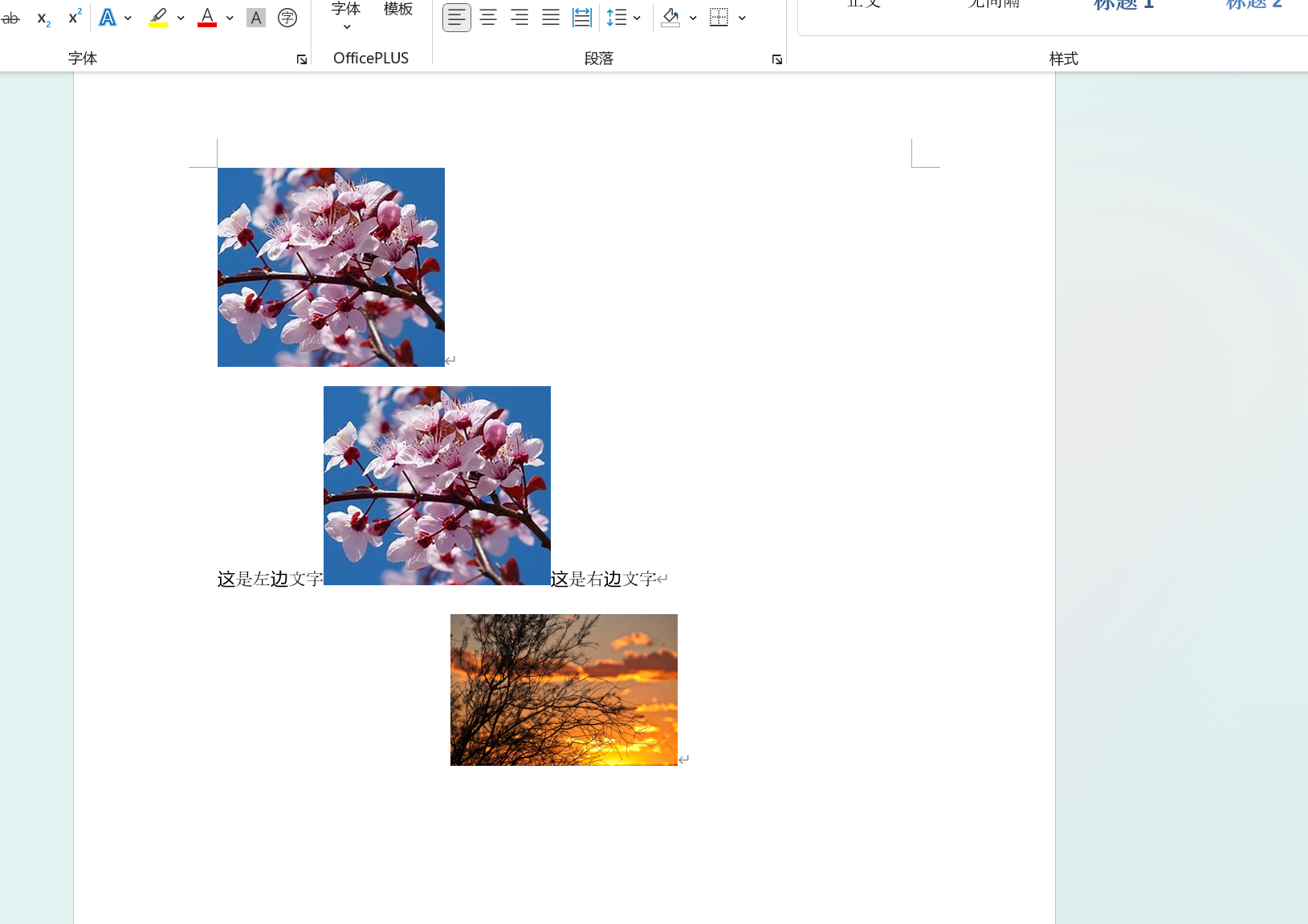
1.设置图片位于文字中间
from docx import Document
from docx.shared import Cm
doc = Document("output.docx")
p = doc.add_paragraph()#先创建一个空段落
# print(type(p))#<class 'docx.text.paragraph.Paragraph'>
# print(type(p.add_run()))#<class 'docx.text.run.Run'>
p.add_run("这是左边文字")
p.add_run().add_picture('../../Picture/OIP-C.jpg', width=Cm(5))#add_run()后要直接调用add_picture()
p.add_run("这是右边文字")
doc.save("output.docx")为什么add_run()后要直接调用add_picture()方法?
因为Run类的对象(由add_run()返回)本身是没有add_picture()方法的!
run = p.add_run()
run.add_picture(...) # ❌ 这样会报错!效果:

2.设置图片对齐方式
其他对齐选项:
- WD_ALIGN_PARAGRAPH.LEFT(默认)
- WD_ALIGN_PARAGRAPH.RIGHT
- WD_ALIGN_PARAGRAPH.CENTER
- WD_ALIGN_PARAGRAPH.JUSTIFY(设置段落对齐方式为两端对齐)
图片本身在一个段落当中,所以通过该段落设置对齐即可
from docx import Document
from docx.shared import Cm
from docx.enum.text import WD_ALIGN_PARAGRAPH
doc = Document("output.docx")
#插入图片并居中
p = doc.add_paragraph()
p.alignment = WD_ALIGN_PARAGRAPH.CENTER
p.add_run().add_picture('../../Picture/picture1.png', width=Cm(5))
doc.save('output.docx')效果:
4.插入图片的常见问题
❗ 常见问题
| 问题 | 解决方案 |
|---|---|
| 图片不显示 / 显示为红叉 | 路径错误,或保存后移动了图片文件(Word 嵌入图片,但调试时注意路径) |
| 图片太大超出页面 | 用 width=Cm(15) 限制宽度(A4 纸宽约 18cm) |
| 想环绕文字? | python-docx 不支持文字环绕(Word 的“嵌入型”以外的布局),图片只能独占一行或在行内 |
| 插入网络图片? | 需先下载到本地,再插入 |
5.插入网络图片
python-docx的add_picture()不支持直接传入URL,如果有网络图片需要插入,需先下载到本地
或者:
python-docx支持BytesIO对象!所以可以从内存中插入图片,无需保存到磁盘!
import requests
from docx import Document
from docx.shared import Cm
from docx.enum.text import WD_ALIGN_PARAGRAPH
from io import BytesIO#导入BytesIO类,用于在内存中创建一个类似文件的对象(file-like object),但不实际读写磁盘文件而是操作字节数据(bytes)
response = requests.get('https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png')
image_stream = BytesIO(response.content)
doc = Document('output.docx')
p = doc.add_paragraph()
p.add_run('百度logo:')
p.alignment = WD_ALIGN_PARAGRAPH.CENTER
p.add_run().add_picture(image_stream, width=Cm(10))
doc.save('output.docx')效果:

✅ 总结:from io import BytesIO 的作用
| 用途 | 说明 |
|---|---|
| 内存中模拟文件 | 创建一个像文件一样可读写的对象,但数据存在 RAM 中 |
| 避免临时文件 | 下载/生成图片后直接使用,无需写入磁盘再读取 |
与 python-docx 配合 |
让 add_picture() 支持从内存插入图片 |
| 提高性能 & 安全性 | 减少磁盘操作,适合 Web 服务、自动化脚本 |
7.设置文字样式与大小
在 python-docx 中,不能直接对段落(Paragraph)整体设置字体样式和大小,而是要通过 Run(文本运行)对象 来控制文字的格式。
需导入:
from docx.shared import Pt, RGBColor
from docx.enum.text import WD_COLOR_INDEX # 用于高亮🎨 常用文字样式设置
| 属性 | 说明 | 示例 |
|---|---|---|
run.bold |
加粗 | run.bold = True |
run.italic |
斜体 | run.italic = True |
run.underline |
下划线 | run.underline = True |
run.font.size |
字号 | run.font.size = Pt(12) |
run.font.color.rgb |
颜色 | RGBColor(0, 0, 255)(蓝) |
run.font.name |
西文字体 | 'Arial', 'Times New Roman' |
run.font.highlight_color |
高亮背景 | WD_COLOR_INDEX.YELLOW |
✅ 总结
| 目标 | 操作 |
|---|---|
| 设置文字样式 | 操作 Run 对象,不是 Paragraph |
| 设置字号 | run.font.size = Pt(14) |
| 设置中文字体 | 同时设置 font.name 和 eastAsia |
| 加粗/颜色等 | run.bold = True, run.font.color.rgb = RGBColor(...) |
二.以Excel形式存储
一.使用pandas
1.安装依赖
pip install pandas openpyxl其中openpyxl是写入.xlsx文件的引擎
2.读取Excel文件
import pandas as pd使用pd.read_excel()函数
import pandas as pd
df = pd.read_excel(
io, # Excel文件路径或文件对象
sheet_name=0, # 工作表名称或索引
header=0, # 指定作为列名的行
names=None, # 自定义列名
index_col=None, # 指定作为索引的列
usecols=None, # 指定要读取的列
dtype=None, # 指定列的数据类型
engine=None, # 指定解析引擎
converters=None, # 自定义列转换函数
skiprows=None, # 跳过的行数
nrows=None, # 读取的行数
na_values=None, # 指定缺失值
keep_default_na=True, # 是否使用默认缺失值识别
parse_dates=False, # 解析日期列
date_format=None, # 日期格式
thousands=None, # 千位分隔符
skipfooter=0, # 跳过末尾行数
storage_options=None # 存储选项(如云存储)
)代码示例:
不指定工作表的名称会默认读取第一个工作表:
import pandas as pd
excel_data = pd.read_excel("data1.xlsx")
print(excel_data)输出:
日期 收入
0 2025-11-11 121
1 2025-11-12 140
2 2025-11-13 123
3 2025-11-14 145
4 2025-11-15 111
5 2025-11-16 162
6 2025-11-17 25
7 2025-11-18 333
8 2025-11-19 214
9 2025-11-20 145
10 2025-11-21 399
11 2025-11-22 2
12 2025-11-23 136
13 2025-11-24 166
14 2025-11-25 186
15 2025-11-26 196
16 2025-11-27 206
17 2025-11-28 126
18 2025-11-29 216
19 2025-11-30 222
20 2025-12-01 0
21 2025-12-02 235
22 2025-12-03 1200
23 2025-12-04 32
24 2025-12-05 126
25 2025-12-06 122
26 2025-12-07 123
27 2025-12-08 146
28 2025-12-09 78
29 2025-12-10 0
30 2025-12-11 124
31 2025-12-12 789
32 2025-12-13 142
33 2025-12-14 174
34 2025-12-15 258
35 2025-12-16 173
36 2025-12-17 56
37 2025-12-18 359
38 2025-12-19 475
39 2025-12-20 128
指定读取工作表(第一个工作表的名称为“收入表”,第二个工作表的名称为“成绩表”)
import pandas as pd
excel_data = pd.read_excel("data1.xlsx", sheet_name="收入表")
print(excel_data)输出与上一段代码的输出结果一样
import pandas as pd
excel_data = pd.read_excel("data1.xlsx", sheet_name="成绩表")
print(excel_data)输出:
姓名 性别 语文 数学 英语
0 小王 男 100 139 105
1 小张 女 120 77 132
2 小明 男 76 100 103
3 小红 女 112 89 116
4 小刚 男 110 96 84
5 小飞 男 95 102 87
6 小强 男 91 56 109
7 小华 女 99 101 110
一次性读所有的工作表,返回一个字典:
import pandas as pd
dfs = pd.read_excel("data1.xlsx", sheet_name=None)
print(dfs)输出:
{'收入表': 日期 收入
0 2025-11-11 121
1 2025-11-12 140
2 2025-11-13 123
3 2025-11-14 145
4 2025-11-15 111
5 2025-11-16 162
6 2025-11-17 25
7 2025-11-18 333
8 2025-11-19 214
9 2025-11-20 145
10 2025-11-21 399
11 2025-11-22 2
12 2025-11-23 136
13 2025-11-24 166
14 2025-11-25 186
15 2025-11-26 196
16 2025-11-27 206
17 2025-11-28 126
18 2025-11-29 216
19 2025-11-30 222
20 2025-12-01 0
21 2025-12-02 235
22 2025-12-03 1200
23 2025-12-04 32
24 2025-12-05 126
25 2025-12-06 122
26 2025-12-07 123
27 2025-12-08 146
28 2025-12-09 78
29 2025-12-10 0
30 2025-12-11 124
31 2025-12-12 789
32 2025-12-13 142
33 2025-12-14 174
34 2025-12-15 258
35 2025-12-16 173
36 2025-12-17 56
37 2025-12-18 359
38 2025-12-19 475
39 2025-12-20 128, '成绩表': 姓名 性别 语文 数学 英语
0 小王 男 100 139 105
1 小张 女 120 77 132
2 小明 男 76 100 103
3 小红 女 112 89 116
4 小刚 男 110 96 84
5 小飞 男 95 102 87
6 小强 男 91 56 109
7 小华 女 99 101 110}
3.写入Excel文件
DataFrame.to_excel()import pandas as pd
excel_data = pd.read_excel("data1.xlsx", sheet_name="成绩表")
#计算总分
excel_data['总分'] = excel_data['语文'] + excel_data['数学'] + excel_data['英语']
print(excel_data)输出:
姓名 性别 语文 数学 英语 总分
0 小王 男 100 139 105 344
1 小张 女 120 77 132 329
2 小明 男 76 100 103 279
3 小红 女 112 89 116 317
4 小刚 男 110 96 84 290
5 小飞 男 95 102 87 284
6 小强 男 91 56 109 256
7 小华 女 99 101 110 310
#对总分进行排名(降序排),参数method的默认值为min,表示排名并列时取最小的那个排名
excel_data['排名'] = excel_data['总分'].rank(method='min', ascending=False).astype('int')#这里转换为int类型,默认是float类型
print(excel_data)输出:
姓名 性别 语文 数学 英语 总分 排名
0 小王 男 100 139 105 344 1
1 小张 女 120 77 132 329 2
2 小明 男 76 100 103 279 7
3 小红 女 112 89 116 317 3
4 小刚 男 110 96 84 290 5
5 小飞 男 95 102 87 284 6
6 小强 男 91 56 109 256 8
7 小华 女 99 101 110 310 4
#sort_values()函数会按指定的列排名并会根据排名重新排列DataFrame的行,返回一个新的DataFrame
excel_data_sorted = excel_data.sort_values(by=['总分'], ascending=False)
print(excel_data_sorted)输出:
姓名 性别 语文 数学 英语 总分
0 小王 男 100 139 105 344
1 小张 女 120 77 132 329
3 小红 女 112 89 116 317
7 小华 女 99 101 110 310
4 小刚 男 110 96 84 290
5 小飞 男 95 102 87 284
2 小明 男 76 100 103 279
6 小强 男 91 56 109 256
#保存为Excel文件
excel_data_sorted.to_excel('data2.xlsx')效果:
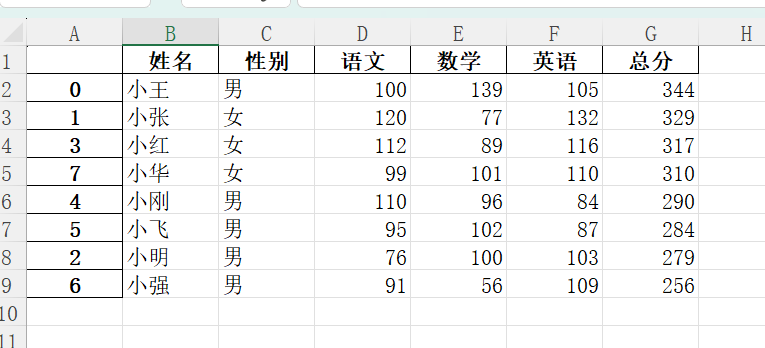
excel_data_sorted = excel_data.sort_values(by=['总分'], ascending=False).reset_index(drop=True)输出:
姓名 性别 语文 数学 英语 总分
0 小王 男 100 139 105 344
1 小张 女 120 77 132 329
2 小红 女 112 89 116 317
3 小华 女 99 101 110 310
4 小刚 男 110 96 84 290
5 小飞 男 95 102 87 284
6 小明 男 76 100 103 279
7 小强 男 91 56 109 256
excel_data_sorted = excel_data.sort_values(by=['总分'], ascending=False).reset_index(drop=True)
excel_data_sorted.index = excel_data_sorted.index + 1
print(excel_data_sorted)输出:
姓名 性别 语文 数学 英语 总分
1 小王 男 100 139 105 344
2 小张 女 120 77 132 329
4 小红 女 112 89 116 317
8 小华 女 99 101 110 310
5 小刚 男 110 96 84 290
6 小飞 男 95 102 87 284
3 小明 男 76 100 103 279
7 小强 男 91 56 109 256
excel_data_sorted = excel_data.sort_values(by=['总分'], ascending=False).reset_index(drop=True)
excel_data_sorted.index = excel_data_sorted.index + 1
# print(excel_data_sorted)
excel_data_sorted.to_excel('data2.xlsx')
效果:
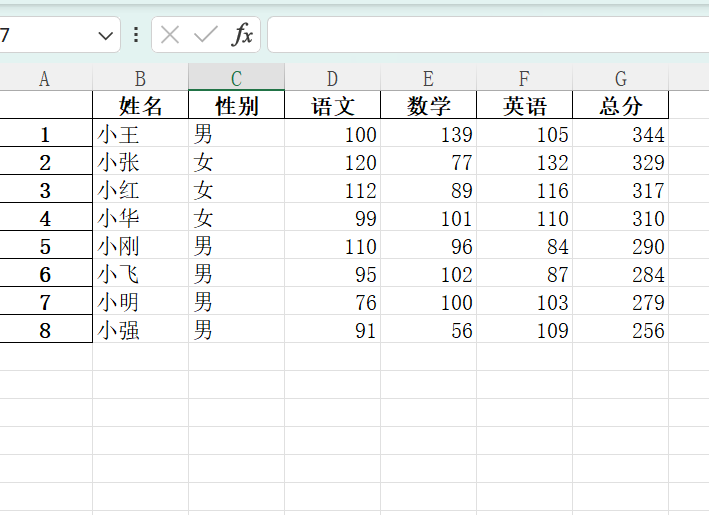
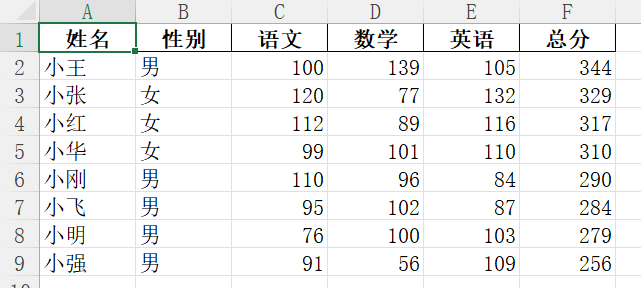
excel_data_sorted.to_excel('data2.xlsx',index=False)#参数index设置为False不将DataFrame的行索引index写入文件中效果:
4.将长文本写入Excel文件
将较长的文本数据保存到 Excel 文件时,需要注意以下几点:
- Excel 单元格对文本长度有限制(
.xlsx格式最大支持 32,767 个字符/单元格); - 超长文本可能被截断或显示异常;
- 需要确保写入方式能保留完整内容;
- 可能需要调整单元格格式(如自动换行、列宽)以便查看。
import pandas as pd
# 示例:包含长文本的数据
long_text = """
这是一段非常长的文本,可能包含多行内容、
中文、英文、标点符号,甚至代码片段。
在实际应用中,可能是文章、日志、评论、报告等。
只要不超过 32767 字符,Excel 就能完整存储。
"""
data = {
"ID": [1, 2],
"标题": ["报告A", "报告B"],
"内容": [
long_text * 2, # 模拟更长文本
"另一段长文本..." + "详细描述" * 100
]
}
df = pd.DataFrame(data)
print(df)输出:
ID 标题 内容
0 1 报告A \n这是一段非常长的文本,可能包含多行内容、\n中文、英文、标点符号,甚至代码片段。\n在实...
1 2 报告B 另一段长文本...详细描述详细描述详细描述详细描述详细描述详细描述详细描述详细描述详细描述详...
data = {
"ID": [1, 2],
"标题": ["报告A", "报告B"],
"内容": [
long_text * 2, # 模拟更长文本
"另一段长文本..." + "详细描述" * 100
]
}
df = pd.DataFrame(data)
# print(df)
df.to_excel('长文本示例.xlsx')效果:
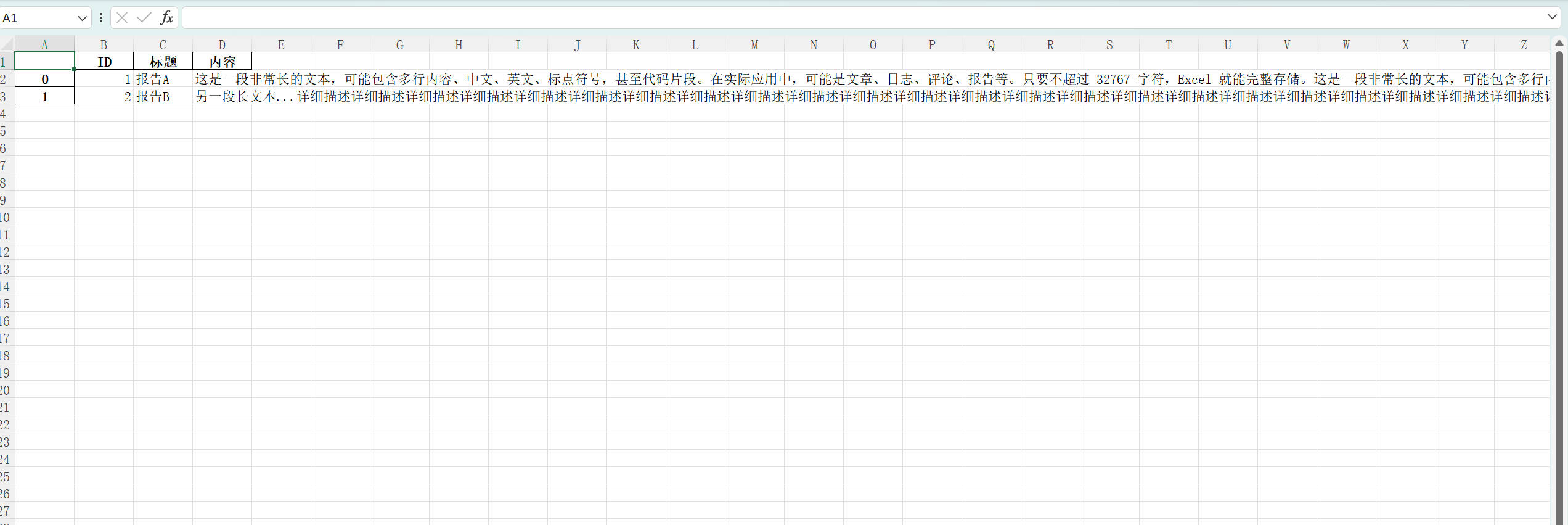
不把DataFrame的行索引写入Excel表格中:
df.to_excel('长文本示例.xlsx', index=False)效果:

5.修改样式
二.使用openpyxl
1.环境依赖
pip install openpyxl2.基础用法
(1).创建工作簿
from openpyxl import Workbook
#新建一个空的Excel工作簿对象
#调用Workbook()函数后会在内存中创建一个新的工作簿,这个工作簿默认带一张工作表,可以通过工作簿对象.active拿到这张工作表
wb = Workbook()
# print(wb)#<openpyxl.workbook.workbook.Workbook object at 0x000002216EB58D70>
# print(type(wb))#<class 'openpyxl.workbook.workbook.Workbook'>
#工作表对象
ws = wb.active
# print(ws)#<Worksheet "Sheet">
# print(type(ws))#<class 'openpyxl.worksheet.worksheet.Worksheet'>
#修改当前工作表的名称(改名后,在Excel底部的标签栏看到的就是“订单表”而不是默认的“sheet”)
ws.title = "订单表"(2).写入数据
headers = ["日期", "客户", "产品", "数量", "单价", "金额"]
data = [
["2025-12-01", "张三", "A001", 10, 5.5, 55],
["2025-12-02", "李四", "B002", 20, 3.0, 60],
["2025-12-03", "王五", "C003", 15, 4.0, 60],
]
#append是openpyxl工作表对象(WorkSheet)的一个方法,用于将可迭代对象里的元素按顺序一次性写到当前表的下一个空行,并且会自动换行
#返回None,不能链式调用
ws.append(headers)
for raw in data:
ws.append(raw)(3).设置样式(简单版)
#设置边框样式:单元格四周都是细线
from openpyxl.styles import Border, Side, Alignment
thin = Side(style='thin', color='000000')#细线,黑线
#color参数接收一个表示RGB十六进制的字符串,这个字符串一共6位,前2位表示红,中间2位表示绿,最后2位表示蓝
border = Border(left=thin, right=thin, top=thin, bottom=thin)#单元格四周都应用样式thin
#获取当前工作表ws中“已存在的数据”的最大行号和最大列号,用它们去遍历整个数据矩形区域
max_row = ws.max_row
max_col = ws.max_column
for row in ws.iter_rows(min_row=1, max_col=max_col, min_col=1, max_row=max_row):
print(row)返回:
(<Cell '订单表'.A1>, <Cell '订单表'.B1>, <Cell '订单表'.C1>, <Cell '订单表'.D1>, <Cell '订单表'.E1>, <Cell '订单表'.F1>)
(<Cell '订单表'.A2>, <Cell '订单表'.B2>, <Cell '订单表'.C2>, <Cell '订单表'.D2>, <Cell '订单表'.E2>, <Cell '订单表'.F2>)
(<Cell '订单表'.A3>, <Cell '订单表'.B3>, <Cell '订单表'.C3>, <Cell '订单表'.D3>, <Cell '订单表'.E3>, <Cell '订单表'.F3>)
(<Cell '订单表'.A4>, <Cell '订单表'.B4>, <Cell '订单表'.C4>, <Cell '订单表'.D4>, <Cell '订单表'.E4>, <Cell '订单表'.F4>)
确实反映了当前活动的工作表中有4行数据,也可以从每一个元组中看出有6列数据
max_row = ws.max_row
max_col = ws.max_column
for row in ws.iter_rows(min_row=1, max_col=max_col, min_col=1, max_row=max_row):
for cell in row:
print(cell)输出:
<Cell '订单表'.A1>
<Cell '订单表'.B1>
<Cell '订单表'.C1>
<Cell '订单表'.D1>
<Cell '订单表'.E1>
<Cell '订单表'.F1>
<Cell '订单表'.A2>
<Cell '订单表'.B2>
<Cell '订单表'.C2>
<Cell '订单表'.D2>
<Cell '订单表'.E2>
<Cell '订单表'.F2>
<Cell '订单表'.A3>
<Cell '订单表'.B3>
<Cell '订单表'.C3>
<Cell '订单表'.D3>
<Cell '订单表'.E3>
<Cell '订单表'.F3>
<Cell '订单表'.A4>
<Cell '订单表'.B4>
<Cell '订单表'.C4>
<Cell '订单表'.D4>
<Cell '订单表'.E4>
<Cell '订单表'.F4>
max_row = ws.max_row
max_col = ws.max_column
for row in ws.iter_rows(min_row=1, max_col=max_col, min_col=1, max_row=max_row):
for cell in row:
print(cell.value)输出:
日期
客户
产品
数量
单价
金额
2025-12-01
张三
A001
10
5.5
55
2025-12-02
李四
B002
20
3.0
60
2025-12-03
王五
C003
15
4.0
60
得到的cell对象:
在 for cell in row: 里,每个 cell 都是 openpyxl.cell.cell.Cell 类的实例,
最常用的属性/方法按“读值、写值、样式、位置”四类速查如下
来了解一个函数:get_column_letter()
#get_column_letter():把数字列号转换为Excel的字母
from openpyxl.utils import get_column_letter
print(get_column_letter(1))
print(get_column_letter(3))
print(get_column_letter(5))输出:
A
C
E
工作表对象的column_dimensions属性:
一个“dict-like”属性,用来一次性访问或设置整列的格式、宽度、隐藏状态等(按列字母索引的顺序)
如:
from openpyxl.utils import get_column_letter
# 1. 设置列宽
ws.column_dimensions['B'].width = 20 # B 列宽 20 字符
ws.column_dimensions['C'].width = 12
# 2. 批量设置
for col in range(1, 10):
letter = get_column_letter(col)
ws.column_dimensions[letter].width = 15
# 3. 隐藏列
ws.column_dimensions['D'].hidden = True
# 4. 设置“最佳匹配”
ws.column_dimensions['E'].bestFit = True
# 5. 设置列级别(分级显示)
ws.column_dimensions['F'].outline_level = 1所以,样式设置的代码如下:
#设置边框样式:单元格四周都是细线
from openpyxl.styles import Border, Side, Alignment
thin = Side(style='thin', color='000000')#细线,黑线
#color参数接收一个表示RGB十六进制的字符串,这个字符串一共6位,前2位表示红,中间2位表示绿,最后2位表示蓝
border = Border(left=thin, right=thin, top=thin, bottom=thin)#单元格四周都应用样式thin
#获取当前工作表ws中“已存在的数据”的最大行号和最大列号,用它们去遍历整个数据矩形区域
max_row = ws.max_row
max_col = ws.max_column
for row in ws.iter_rows(min_row=1, max_col=max_col, min_col=1, max_row=max_row):
for cell in row:
cell.border = border#设置为上面所设置好的边框样式
#让表头居中,更美观
if cell.row == 1:
cell.alignment = Alignment(horizontal='center', vertical='center')
from openpyxl.utils import get_column_letter
#设置列宽
for col_idx in range(1, max_col+1):
ws.column_dimensions[get_column_letter(col_idx)].width = 12
#设置行高,表头的行高高一点,其余行的行高默认
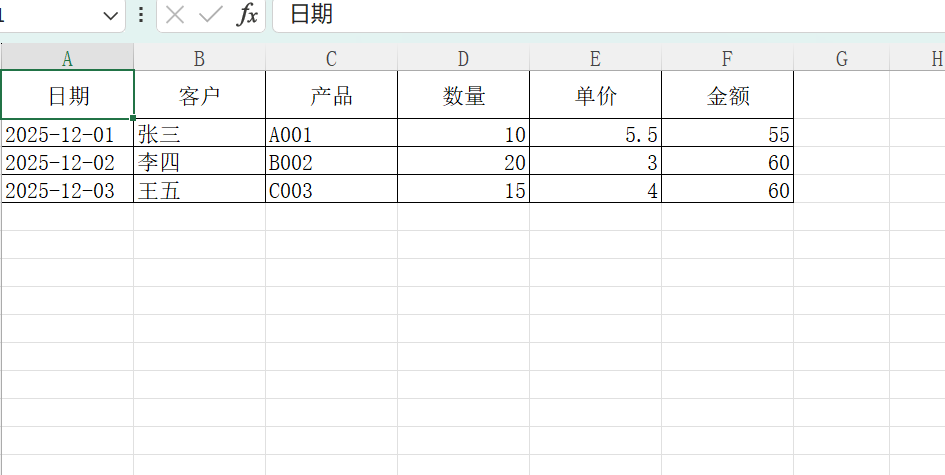
ws.row_dimensions[1].height = 24 #单位是磅(point)(4).保存文件
#保存文件
wb.save("dome.xlsx")
print("已生成 demo.xlsx")效果:
如果想让所有的单元格中的内容都居中显示,可以这样设置:
from openpyxl import Workbook
from openpyxl.styles import Border, Side, Alignment
from openpyxl.utils import get_column_letter
#创建新的Excel空白工作簿对象
wb = Workbook()
#拿到当前的工作表对象
ws = wb.active
#设置当前工作表的名称
ws.title = "订单表"
headers = ["日期", "客户", "产品", "数量", "单价", "金额"]
data = [
["2025-12-01", "张三", "A001", 10, 5.5, 55],
["2025-12-02", "李四", "B002", 20, 3.0, 60],
["2025-12-03", "王五", "C003", 15, 4.0, 60],
]
#写入数据
ws.append(headers)
for d in data:
ws.append(d)
#定义居中样式
center_align = Alignment(horizontal='center', vertical='center')
#定义边框样式
thin = Side(style='thin', color="000000")
border = Border(left=thin, right=thin, top=thin, bottom=thin)
#遍历所有已用区域,为这些区域(单元格)设置样式
max_row = ws.max_row
max_col = ws.max_column
for row in ws.iter_rows(min_row=1,max_row=max_row,min_col=1,max_col=max_col):
for cell in row:
cell.border = border
cell.alignment = center_align
#设置列宽
for col_idx in range(1, max_col+1):
ws.column_dimensions[get_column_letter(col_idx)].width = 12
#设置行高
ws.row_dimensions[1].height = 24
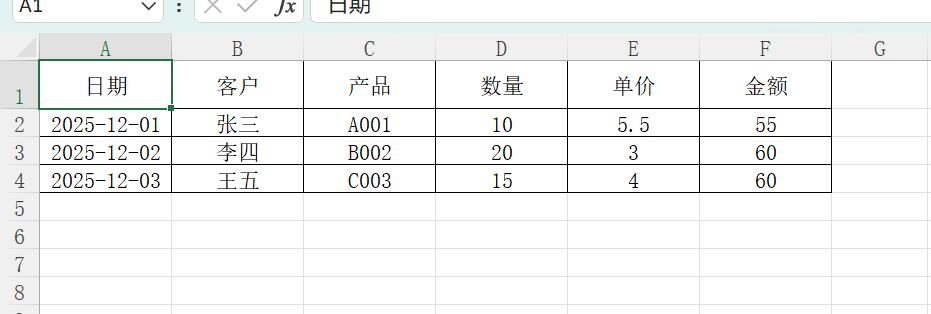
#保存文件
wb.save("demo.xlsx")效果:
(5).设置字体样式
需要导入,使用Font类:
from openpyxl.styles import Font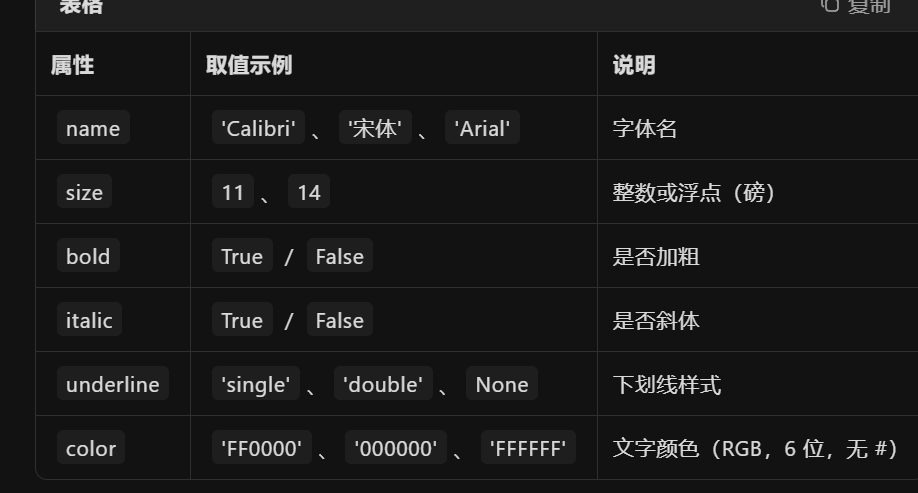
代码示例:
from openpyxl import Workbook
from openpyxl.styles import Border, Side, Alignment
from openpyxl.utils import get_column_letter
from openpyxl.styles import Font
#创建新的Excel空白工作簿对象
wb = Workbook()
#拿到当前的工作表对象
ws = wb.active
#设置当前工作表的名称
ws.title = "订单表"
headers = ["日期", "客户", "产品", "数量", "单价", "金额"]
data = [
["2025-12-01", "张三", "A001", 10, 5.5, 55],
["2025-12-02", "李四", "B002", 20, 3.0, 60],
["2025-12-03", "王五", "C003", 15, 4.0, 60],
]
#写入数据
ws.append(headers)
for d in data:
ws.append(d)
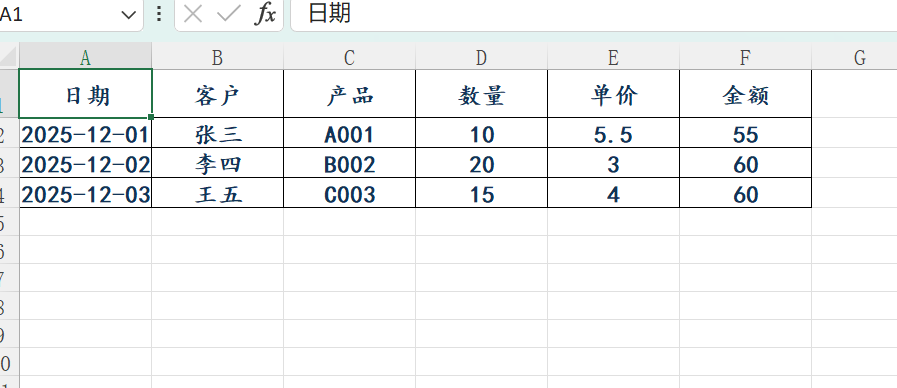
#定义字体样式
ft = Font(
name="楷体", #字体名称
size=12, #字号(单位:磅)
bold=True, #加粗
color='123456' #颜色
)
#定义居中样式
center_align = Alignment(horizontal='center', vertical='center')
#定义边框样式
thin = Side(style='thin', color="000000")
border = Border(left=thin, right=thin, top=thin, bottom=thin)
#遍历所有已用区域,为这些区域(单元格)设置样式
max_row = ws.max_row
max_col = ws.max_column
for row in ws.iter_rows(min_row=1,max_row=max_row,min_col=1,max_col=max_col):
for cell in row:
cell.border = border
cell.alignment = center_align
cell.font = ft
#设置列宽
for col_idx in range(1, max_col+1):
ws.column_dimensions[get_column_letter(col_idx)].width = 12
#设置行高
ws.row_dimensions[1].height = 24
#保存文件
wb.save("demo.xlsx")效果:
(6).对长文本的处理
什么样式都没设置的版本:
from openpyxl import Workbook
from openpyxl.styles import Side, Border, Alignment, Font
from openpyxl.utils import get_column_letter
#包含长文本的数据
long_text1 = """
这是一段非常长的文本,可能包含多行内容、
中文、英文、标点符号,甚至代码片段。
在实际应用中,可能是文章、日志、评论、报告等。
只要不超过 32767 字符,Excel 就能完整存储。
"""
long_text2 = """
你好,当你多年后再回头看这段时光会是什么感受呢?
这大学四年,好像高中那几年一样吧,但其实你写下这句话的时候就已经意识到了四年真的很短,真的很快
你的人生,有多少个四年呢
"""
wb = Workbook()
ws = wb.active
ws.title = "长文本示例"
ws.append([long_text1])#append方法只能作用于列表、元组、序列range对象、生成器、字典,不能对字符串
ws.append([long_text2])
wb.save("长文本.xlsx")效果:

设置样式:
from openpyxl import Workbook
from openpyxl.styles import Side, Border, Alignment, Font
from openpyxl.utils import get_column_letter
#包含长文本的数据
long_text1 = """
这是一段非常长的文本,可能包含多行内容、
中文、英文、标点符号,甚至代码片段。
在实际应用中,可能是文章、日志、评论、报告等。
只要不超过 32767 字符,Excel 就能完整存储。
"""
long_text2 = """
你好,当你多年后再回头看这段时光会是什么感受呢?
这大学四年,好像高中那几年一样吧,但其实你写下这句话的时候就已经意识到了四年真的很短,真的很快
你的人生,有多少个四年呢
"""
wb = Workbook()
ws = wb.active
ws.title = "长文本示例"
ws.append([long_text1])#append方法只能作用于列表、元组、序列range对象、生成器、字典,不能对字符串
ws.append([long_text2])
#wrap_text参数的作用:使单元格中的长文本按列宽自动换行显示(超出部分不再向右溢出,而是在单元格内部换行)
wrap_align = Alignment(wrap_text=True, vertical='top')
ft = Font(
name="微软雅黑",
size=12,
bold=True,
italic=True,#斜体
)
thick = Side(style='thick', color='00FF0000') # 00 不透明 + FF0000 红色
border = Border(left=thick, right=thick, top=thick, bottom=thick)
for row in ws.iter_rows(min_row=1,max_row=ws.max_row,min_col=1,max_col=ws.max_column):
for cell in row:
cell.border = border
cell.font = ft
cell.alignment = wrap_align
for row_idx in range(1, ws.max_row+1):
ws.row_dimensions[row_idx].height =160#合适的列宽和行高在现在Excel中尝试和操作才知道
for col_idx in range(1, ws.max_column+1):
ws.column_dimensions[get_column_letter(col_idx)].width = 40
wb.save("长文本.xlsx")效果:

(7).存储图片
import requests
from io import BytesIO
from openpyxl import Workbook
from openpyxl.utils import get_column_letter
from openpyxl.styles import Border, Side, Alignment
from openpyxl.drawing.image import Image
wb = Workbook()
ws = wb.active
ws.title = '图片示例'
response = requests.get(url='https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png')
response.raise_for_status()
image_stream = BytesIO(response.content)#内存文件句柄
img = Image(image_stream)
#调整图片的大小
img.width = 50
img.height = 50
#插入到工作表中
ws.add_image(img, 'D2') #左上角锚定在D2
wb.save("图片示例.xlsx")效果:

调整图片大小:
#调整图片的大小
img.width = 200
img.height = 200效果:


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)