MUSE-VL、TokenFlow、UniToken论文解读
MUSE-VL、TokenFlow、Unitoken语义+像素视觉编码的工作的论文解读
目录
这三个文章都是类似Show-o2的结构,通过双分支来获取高层语义和底层细节,并将两者特征和文本信息均输入进AutoRegressive Model中,从而实现多模态建模。这三个论文均是实现理解和生成统一建模的,其中MUSE-VL最早引入语义特征,生成和理解任务干扰严重,TokenFlow则通过双码本共享映射,再一步进行解耦,但仍需特定的理解和生成数据比例调节实现,UniToken认为双码本方法复杂度高,所以直接并行使用SigLIP和VQGAN并通过简单的Connector得到相应的特征并concat作为Unified特征。
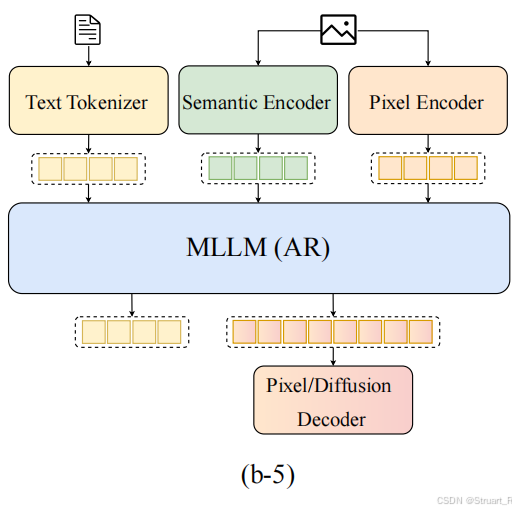
一、MUSE-VL
1、概述
MUSE-VL改进了EMU3和VILA-U的缺陷。
MUSE-VL是建立在EMU3等基于AR主干的LLM存在的问题来改进的,当时还没有考虑使用connector进行语义对齐,只是一味地通过大量训练实现对齐。而VILA-U一改EMU3中Visual Encoder采用VQGAN实现低层像素提取,而完全利用CLIP+RQ-VAE作为Visual Encoder实现高层语义提取。但是传统Visual Tokenizer仅能关注低级像素信息,导致视觉token与文本token难以对齐,在理解性能上显著落后与Und.-Only的专用模型如LLaVA-NeXT,VILA-U的方法虽然语义对齐很好,又缺乏良好文生图能力。
所以MUSE-VL中对于Image Encoder提出了双分支特征融合策略,通过语义编码器和像素编码器两个模块分别提取高层语义和低层像素信息,并量化融合特征。对于除Image Encoder部分几乎完全与EMU3的端到端自回归,采用NTP Loss一致。
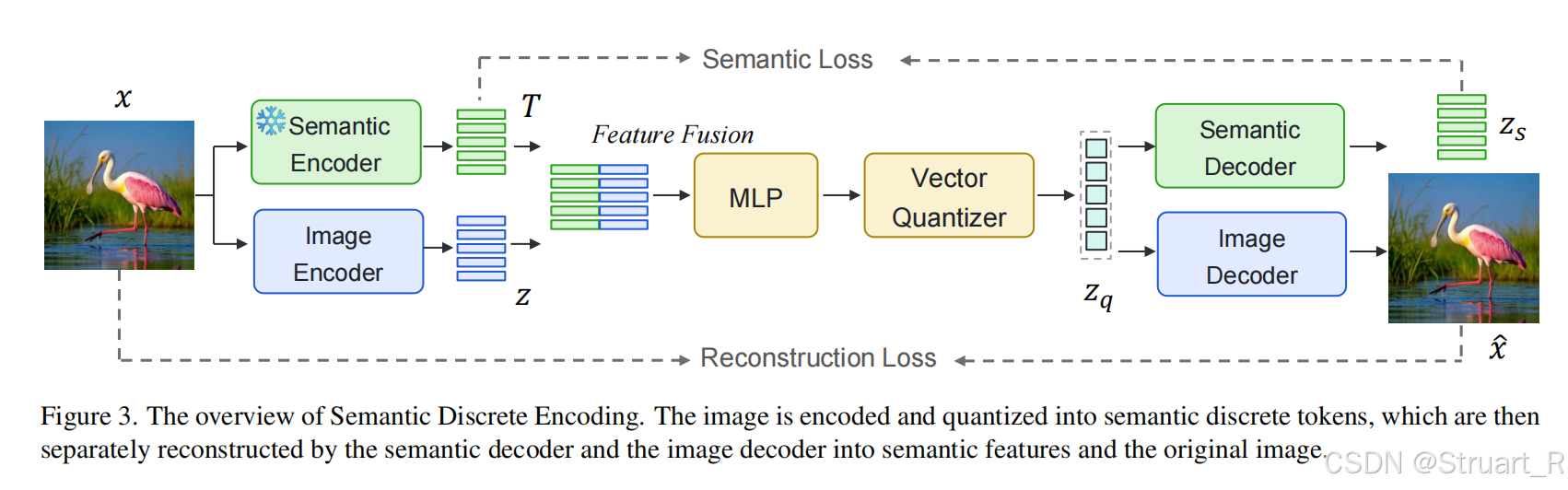
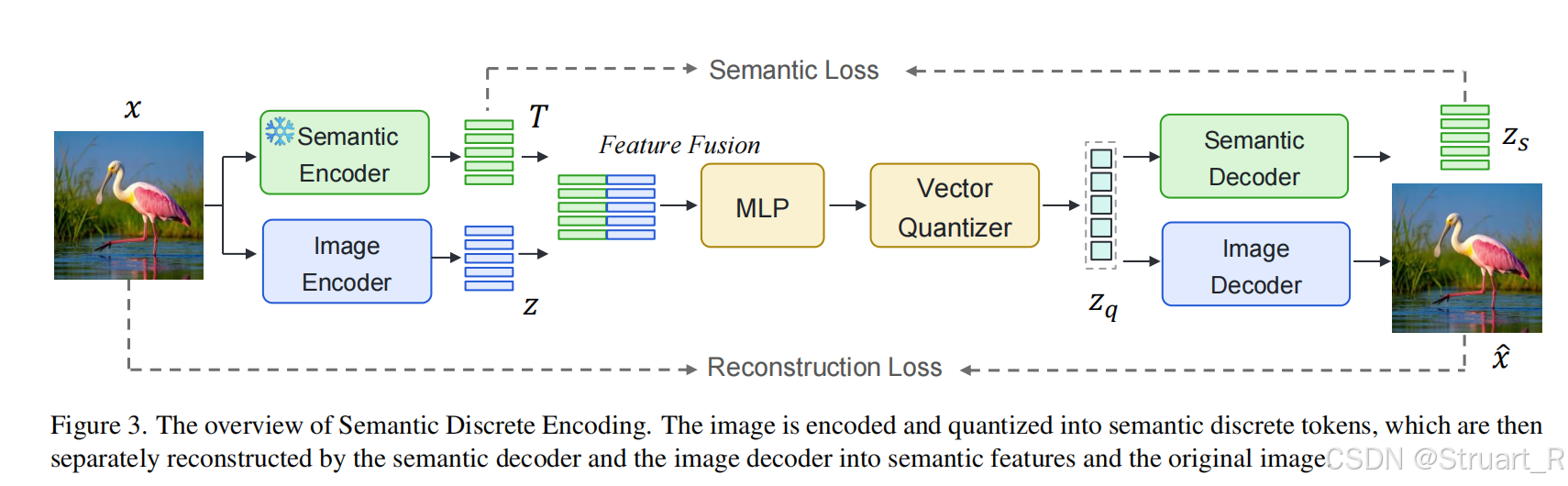
2、方法
Image Tokenizer(SDE)
MUSE-VL模型的Image Tokenizer通过Semantic和Pixel两个方向提取特征,并经过MLP(融合特征),VQ(连续特征转为离散特征)得到特征向量作为LLM的输入。
Semantic Encoder:采用SigLIP-SO400m-patch14-384 and SigLIP-Large-patch16-256两个不同的分辨率。
Semantic Decoder:类似于BEiT V2用于解码特征。(只是训练Tokenizer时出现)
Image Encoder & Decoder:VQGAN(应该与EMU3一致)
训练目标:语义+重建+VQ码本损失
(1)语义:编码语义特征与解码语义特征的余弦相似度损失
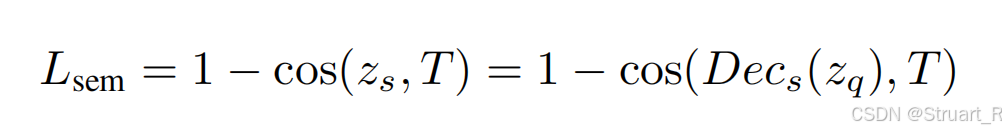
(2)重建:L2损失、LPIPS、GAN损失(因为用到了VQGAN)
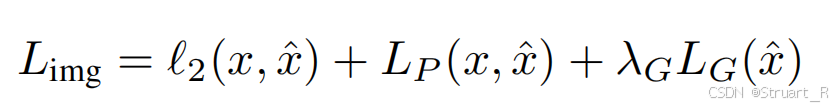
(3)VQ码本损失:这个很有趣了,以往都是只有前一半,表示强制码本向量
逼近编码器输出特征
,让码本学会编码器的输出特征分布,并且离散化。而后一半
,表示强制编码器输出
逼近量化结果
。这主要处理单边设计损失函数会出现灾难性崩塌,编码器逐渐倾向于放大输出
的范数,码本被迫追赶膨胀的特征
,导致量化误差爆炸。
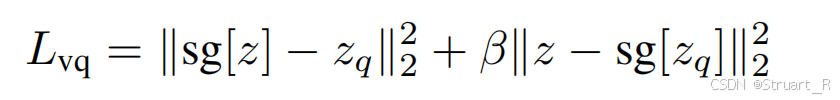
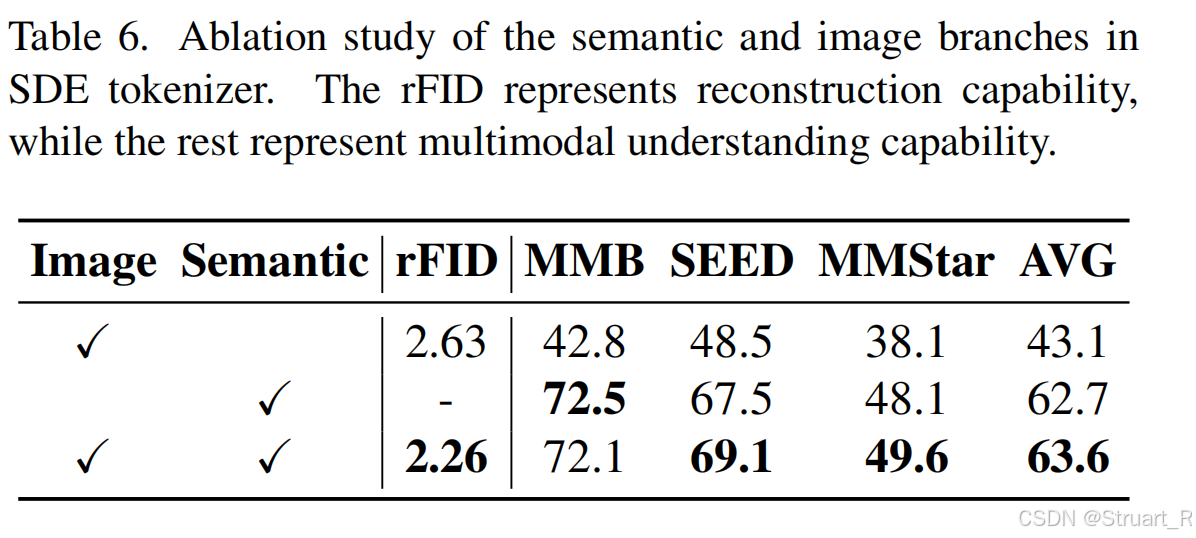
在后续实验中也对比了SDE这种双分支特征提取的架构合理性,仅测试Image Tokenizer的处理办法,虽然在重建能力上(rFID)SDE方法与RQ-VAE(VILA-U)效果不相上下,但是维度上缩小了4倍,这可以加快训练效率。
另外对比了双分支架构与单分支的效果
LLM
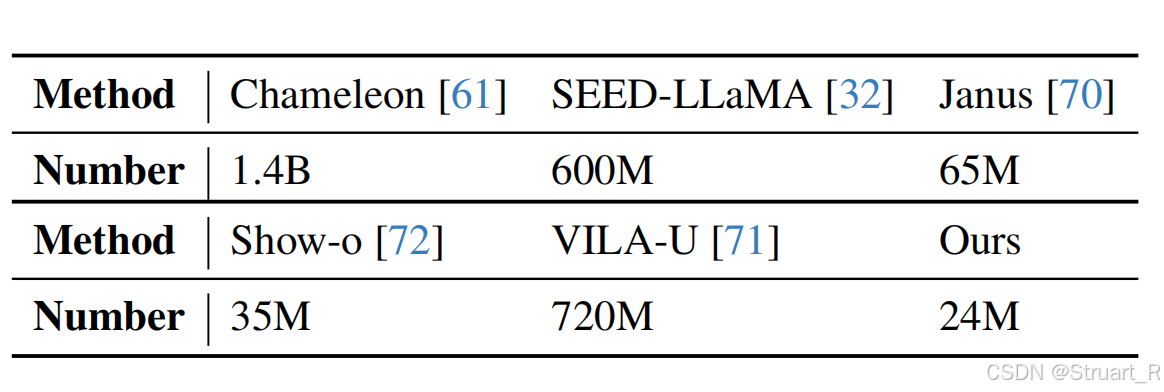
无需修改LLM结构,直接扩展LLM词嵌入层(添加了32768个Visual tokens),并通过<soi>和<eoi>表示视觉标记的起始符,主干结构采用 Qwen-2.5-7B, Qwen-2.5-32B, Yi-1.5-9B, Yi-1.5-34B四个模型进行实验,通过SDE这种双分支的方式无缝连接视觉和语言信息,不需要再通过大规模数据集训练来优化LLM,只需要少量的图文对(24M)即可
训练目标仍然用NTP loss(基于交叉熵损失)
3、实验
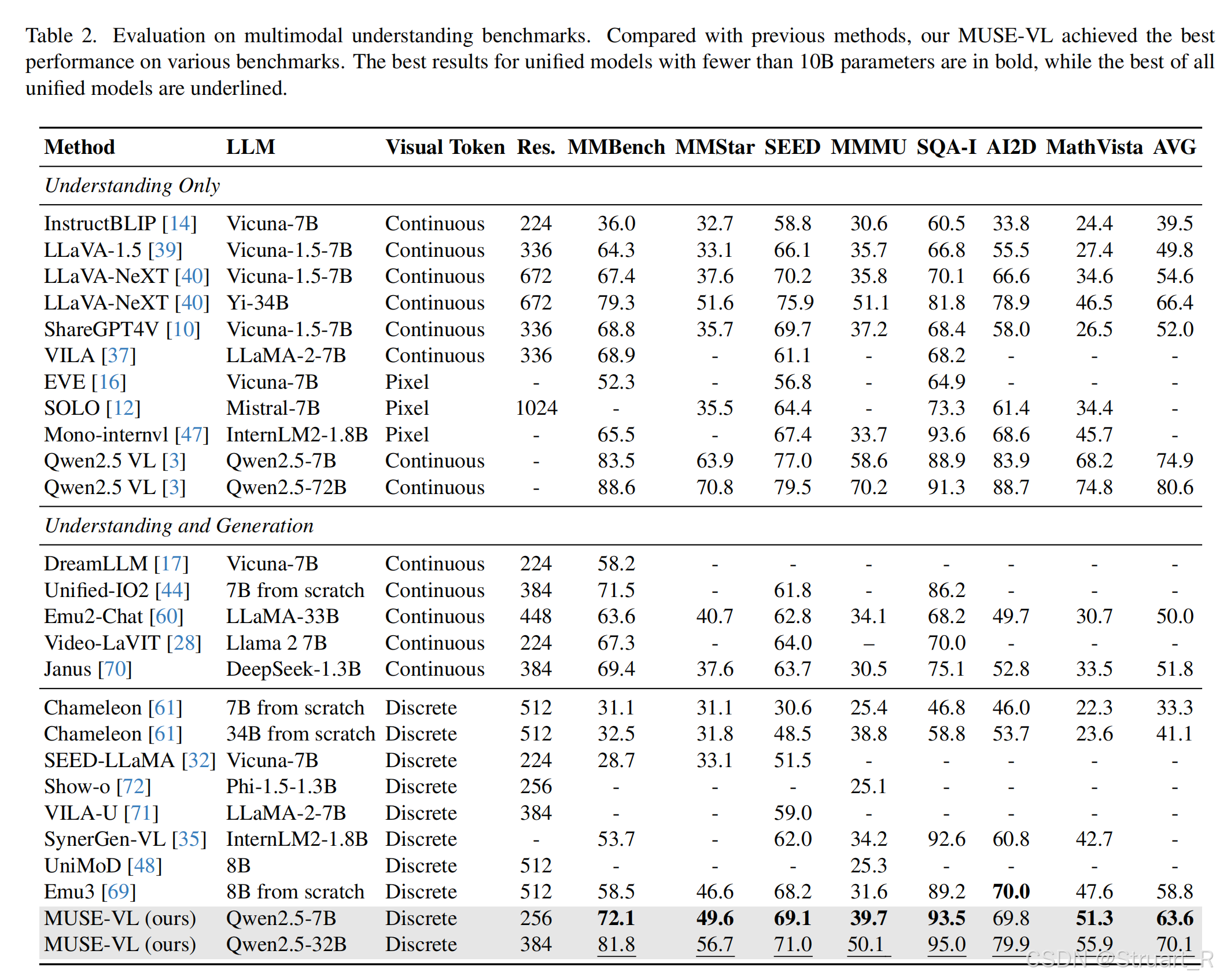
多模态理解
虽然有了文生图能力,并且超过了以往的统一模型的多模态理解能力,but无法超过初始的Und.-only 模型,这就是语言能力丧失,后续Show-o等模型在推理阶段分阶段训练并引入纯文本数据,优化了这个问题。
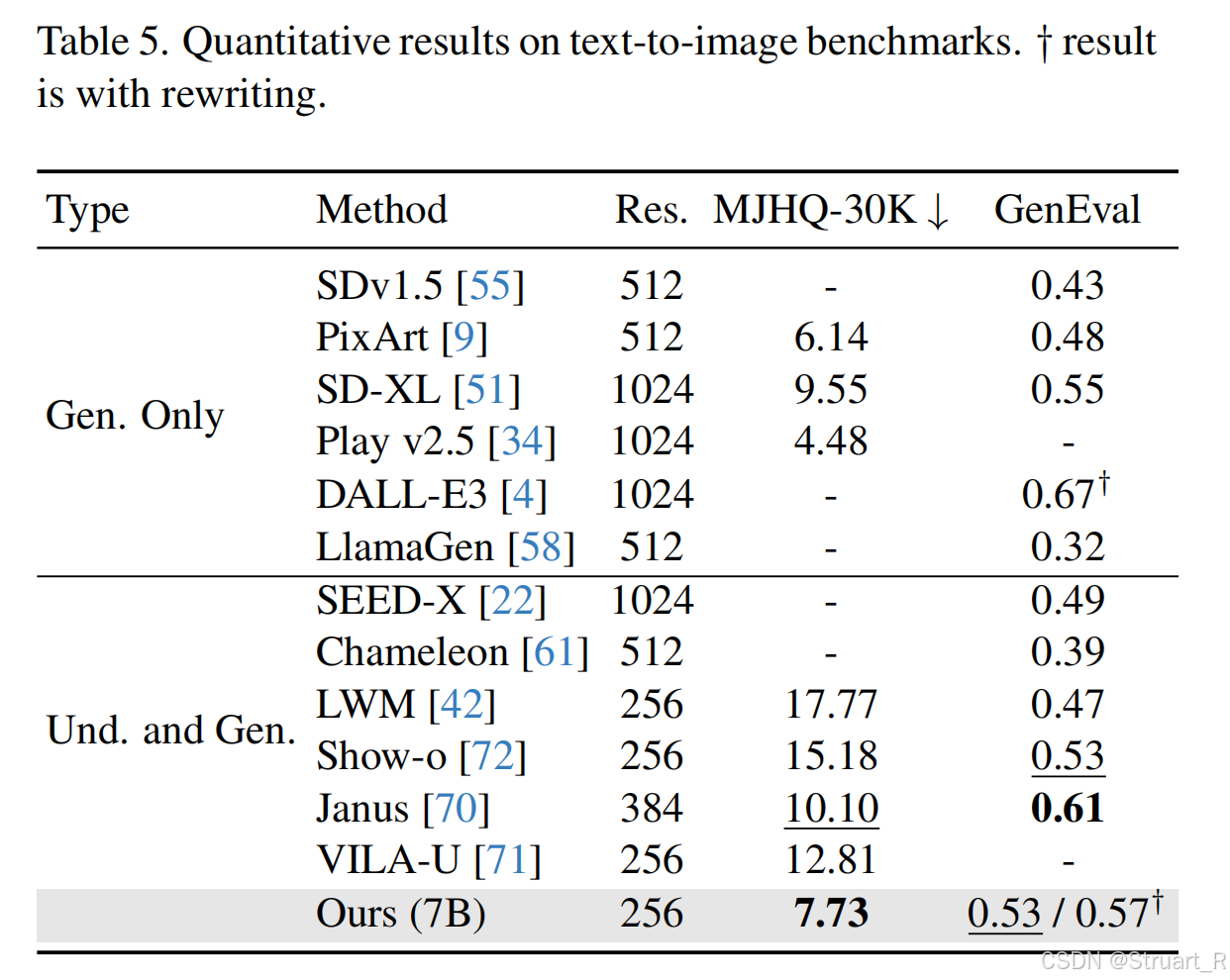
文生图能力
统一模型上效果很棒,Gen.-only不太行(符合早期模型假设,先对比统一,再优化单一能力方向)
二、TokenFlow
1、概述
TokenFlow相当于MUSE-VL的同时期工作,同样对比EMU3和LLaMaGen这些,这两个论文都是围绕改进Image Tokenizer实现视觉与语言统一建模的工作。
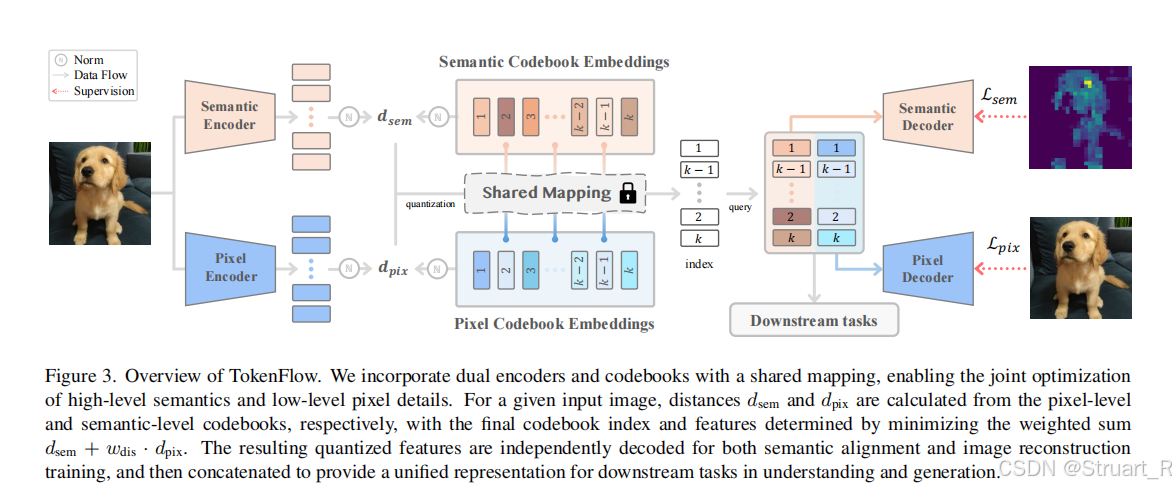
TokenFlow则通过双码本架构,显式解耦语义和像素特征学习(在量化过程继续解耦),并通过共享映射机制保持两者对齐,其实同样是解决了传统VQ方法作为图像提取器的语义缺失问题。
2、方法
Image Tokenizer
同样采用双编码器架构,语义编码器采用预训练的CLIP ViT模型作为教师模型,训练VQKD模型(从代码看应该是尝试了CLIP ViT-B/14-224,ViTamin-XL-256 ,SigLIP-SO400M-patch14-384),提取高维语义特征,像素编码器通过自己设定的一组下采样卷积提取特征
,并通过残差和注意力混合,提取全局信息和局部纹理细节的图像提取网络作为教师模型,蒸馏VQGAN模型。
量化通过双码本分别处理语义特征和像素特征,并共享统一的映射。这不代表码本完全一致,其中语义码本给了32维,像素码本给了8维,分别计算两者的码本损失距离,并根据两者的加和,基于融合距离取最近邻索引。最后将两者特征拼接作为LLM图像部分的输入。
训练目标:与MUSE-VL基本一致,同样是语义+像素+码本损失+多尺度一致性损失
其中像素和码本损失完全一致,语义损失利用图像的L2损失计算。多尺度一致性损失应该是为了保证纹理细节。
Text tokenizer
应该与MUSE-VL相近,均为BPE分词器
LLM
主干架构使用Vicuna-v1.5-13B ,Qwen-2.5-14B,Visual tokenizer的输出通过MLP对齐到LLM特征空间中,(MUSE-VL没有开源不知道有没有用MLP对齐),并于文本tokens拼接作为输入。
训练目标:只训练图像的交叉熵损失。
训练遵循LLaVA-1.5范式
推理策略
对不同尺度的处理中,观察到由于VAR采用传统的top-k-top-p采样策略时,导致图像崩溃和重复的局部模式。传统采样方法仅进行单步采样,时间更短,但高频纹理丢失,局部重复。TokenFlow则使用三轮采样,第一轮采用传统采样聚焦宽采样,保证创造性多样性,再逐渐缩小采样空间缩小尺度信息,聚焦信息,强制一致性。

这里细节讨论一下VAR的模型缺陷,就是那个提出Next-scale Prediction的VAR,VAR中在图像视为无序序列,所以推理过程是:文本输入->AR生成tokens概率分布->单步采样(取argmax)->获得离散token索引->decoder->生成图像。
而只通过取最大值,很容易导致生成结果缺乏多样性,存在模式崩溃,模式重复的情况。
TokenFlow则在Visual Tokenizer的解码输出采样部分使用三阶段采样平衡,先通过同样的采样方法过滤出不同的1200个候选,第二步从中再过滤100个精选,最后在确定一个token,通过逐步收敛防止随机失控,这也解决了自回归图像生成中多样性与质量权衡问题。
Top-k-Top-p采样原理(VAR工作)
Top-k采样
从LLM输出的token概率分布中筛选出概率最高的前K个候选tokens。
Top-p采样
选择几轮采样后,累积概率达到p的最小tokens集合,也就是最早超过p的token。
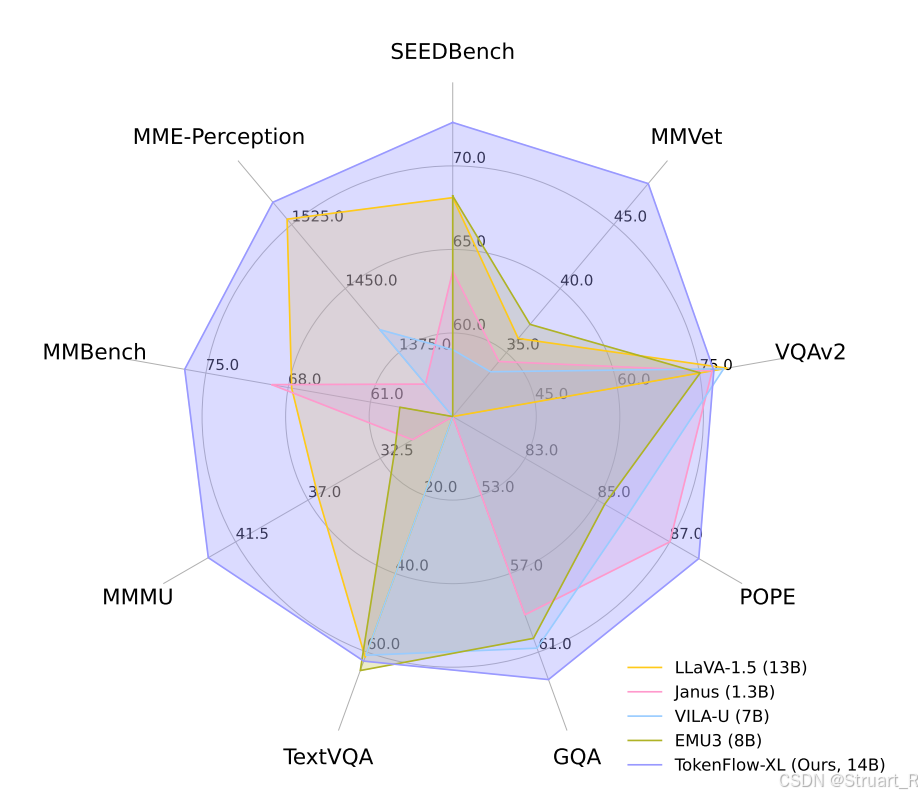
3、实验
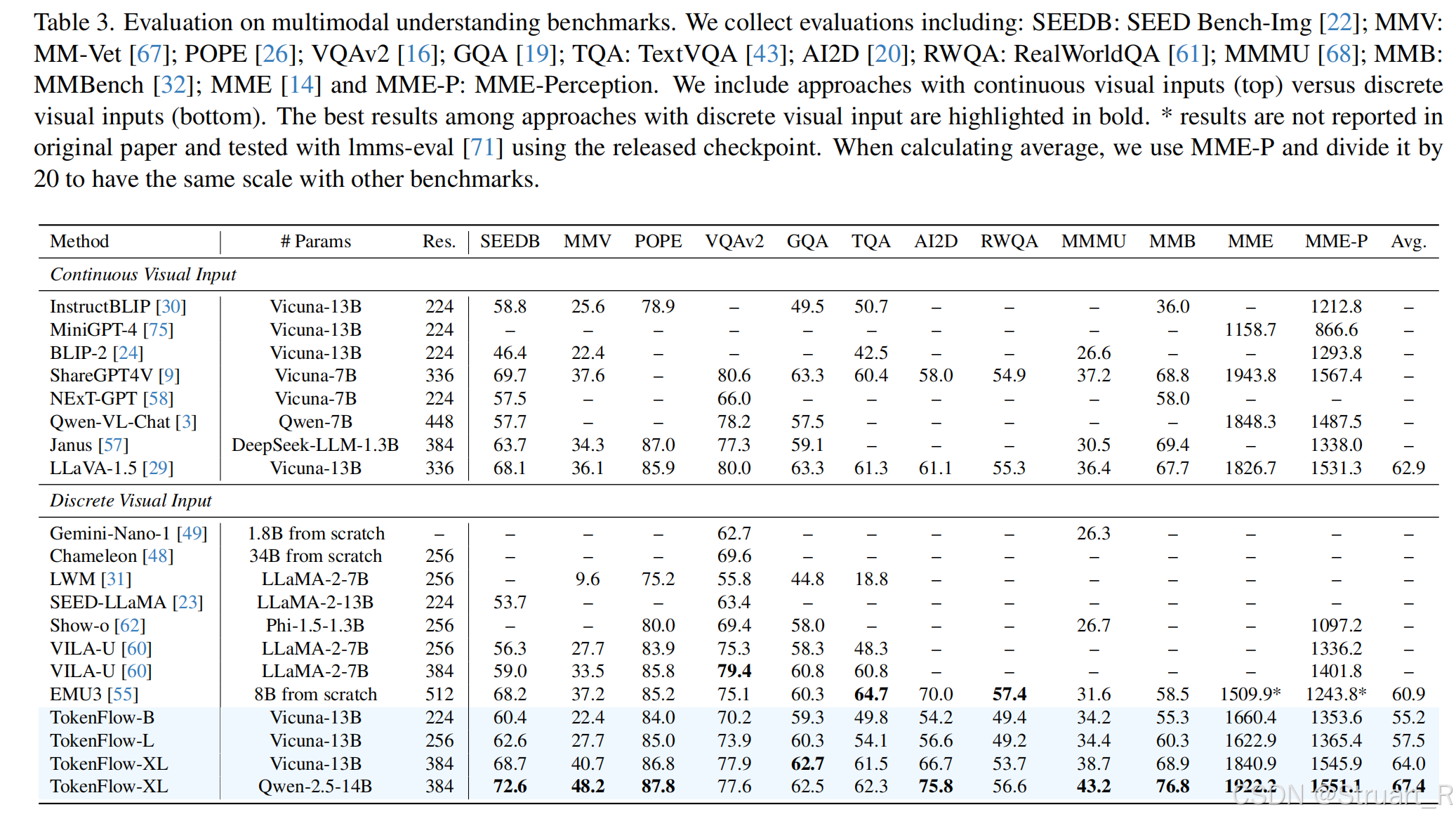
多模态理解对比,他这里突出超过了LLaVA-1.5可能是因为训练策略一致,但是更应该对比Qwen-2.5-14B吧
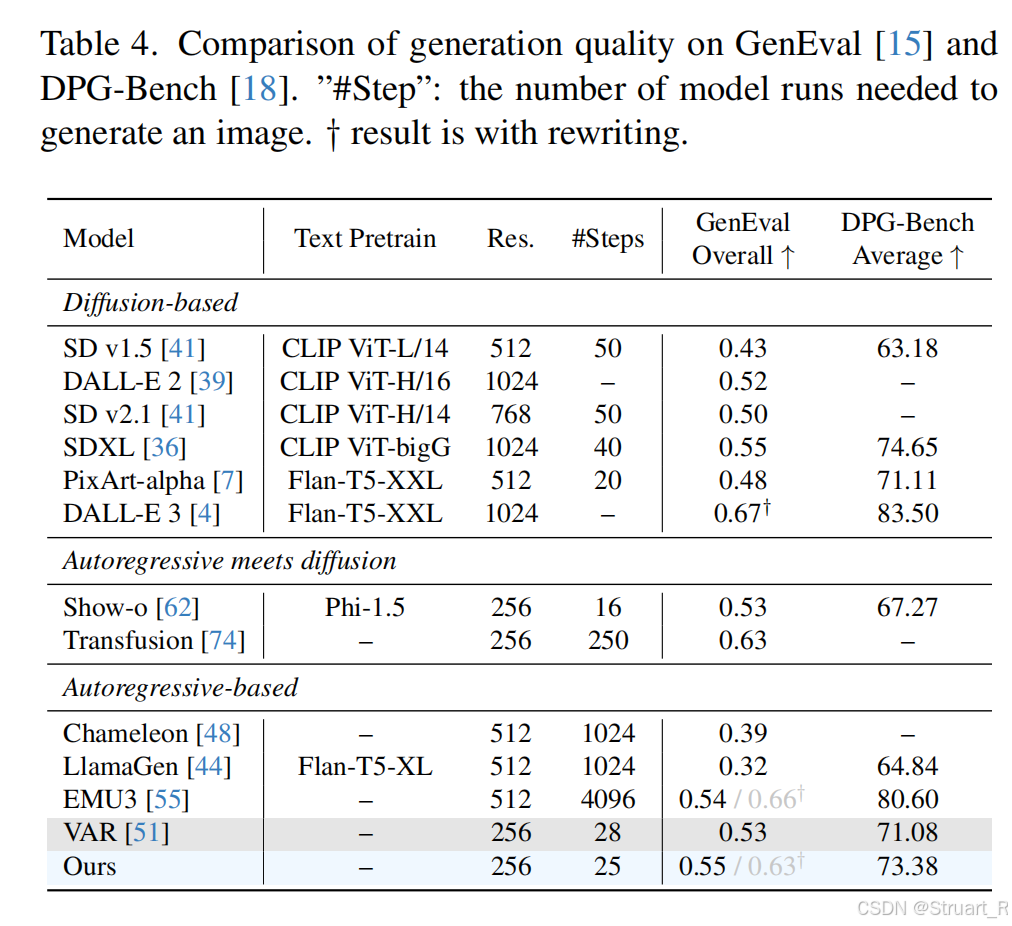
生成模型对比。这里自回归模型特殊的对比了VAR,表达自己的推理策略正确,但是相比于主流图像扩散模型还是有差距。
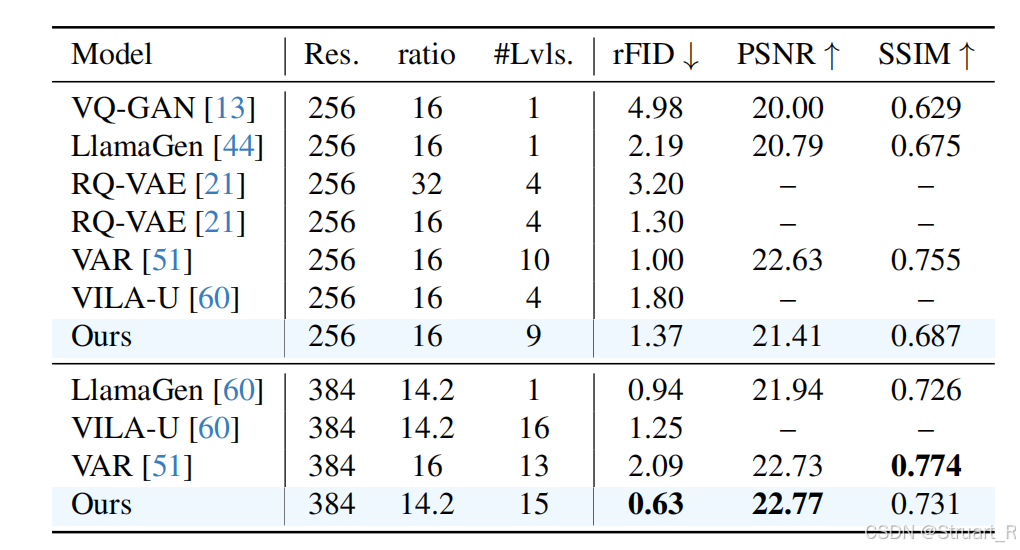
对比Image tokenizer的工作。
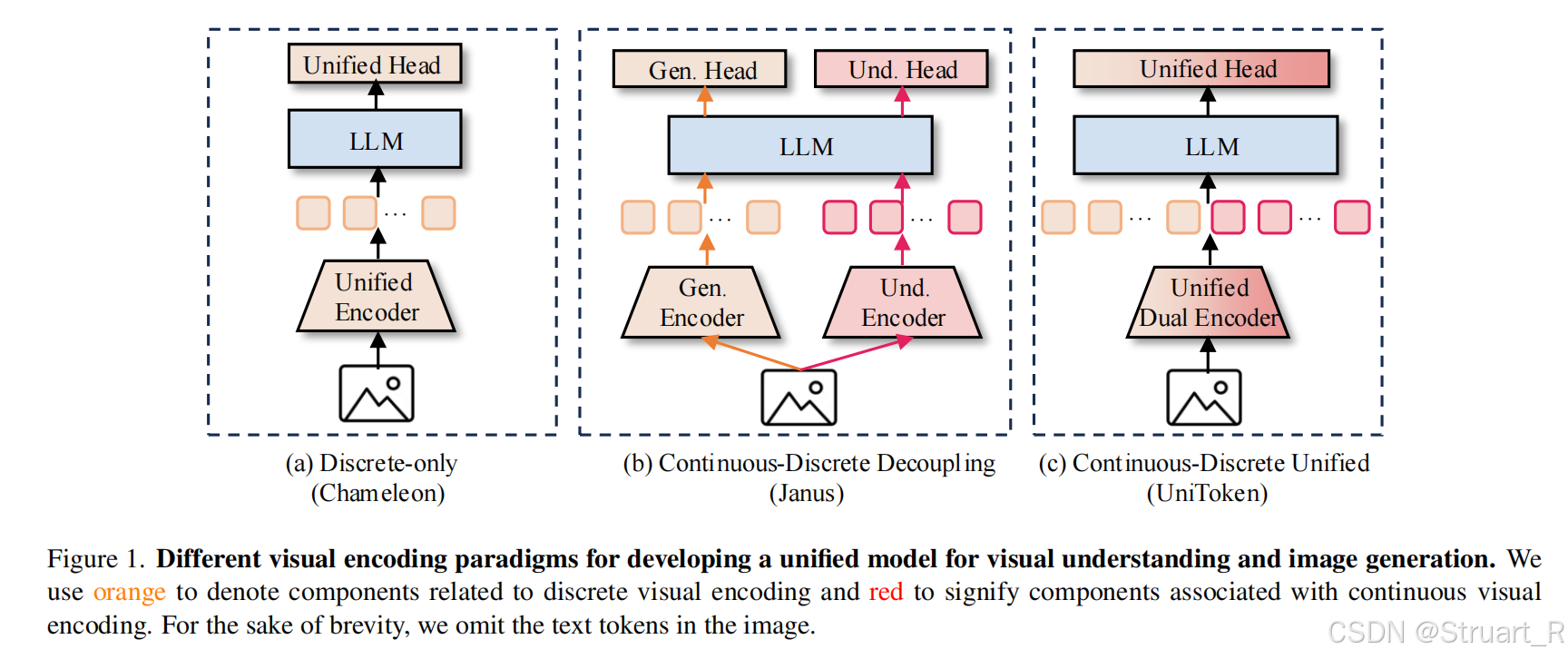
三、UniToken
1、概述
对比Janus这种生成理解分离的工作以及EMU3、Chameleon这种纯AR完全通过NTP loss训练的端到端任务。
解决的问题同样是视觉和语义割裂的问题,以及同样重要的理解和图像合成联合训练干扰的问题。同样也提到了以往的语义和视觉联合提取特征的方法,会导致参数量大幅增加,任务切换时也要重新加载模型权重。
当前的理解任务如果做离散编码仍然难以与连续视觉编码的MLLM匹敌,但是离散编码也可以应对更复杂的多模态任务,但是不是缺失信息,就是参数量大、任务加载慢。
不同于Janus的多任务解耦方法,UniToken为所有下游任务均提供一套完备的视觉信息。
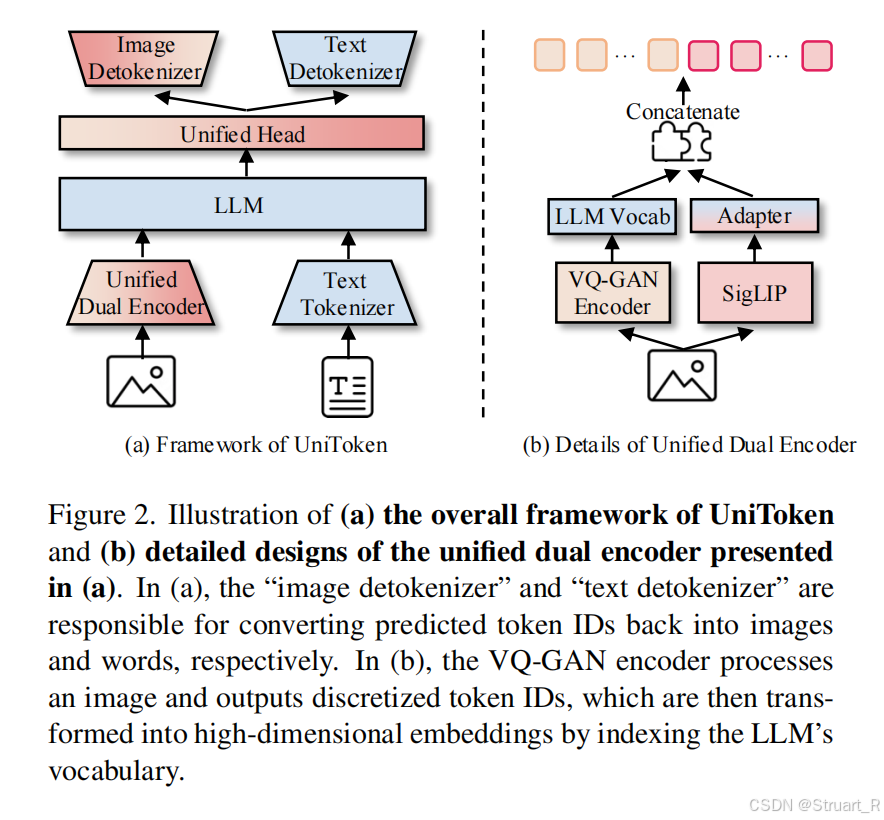
2、方法
Visual Encoder
双分支编码器与以往的方法相近,同样连续分支使用SigLIP VIT+Adapter提取语义特征,离散分支使用VQ-GAN提取像素特征(像素特征学的Chameleon),之后将两者拼接并用MLP对齐到LLM特征空间作为输入。
输入为:[BOS][BOI]{image_d}[SEP]{image_c}[EOI]{text}[EOS]
其中[BOS]和[EOS]代表整个序列开始和结束,[BOI]和[EOI]代表这个图像tokens的开始和结束,{image_d}和{image_c}分别代表离散和连续的图像tokens,并且用[SEP]将两者分开。对于图片的处理同样用了LLaVA1.5的方式,按图片宽高比把图片分成不同形状的patch(2x2,2x1,2x3等等),每一个patch单独输入得到图片tokens。
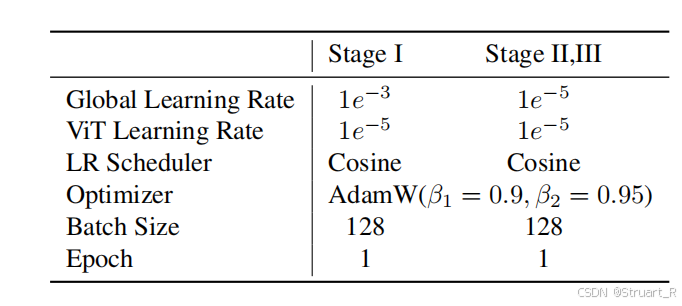
3、训练方法
Stage1:采用Chameleon作为基座,lumina-mGPT的预训练模型,固定LLM参数,只训练SigLIP和VIT,相当于上图Unified Dual Encoder中左支从Chameleon中继承,并且frozen参数。训练数据2.5M,包括ShareGPT4V(高语义密度)、LLaVA(多轮对话)、ALLaVA(学术场景)。
Stage2:全参数训练,采用下表格数据。

Stage3:沿用第二阶段训练策略,全参数训练,额外添加了高质量多模态对话数据(423K)和文生图数据(100K)
训练目标:NTP loss+CE loss,NTP loss保证大语言模型可以正常进行训练,CE loss分别计算文本答案tokens的交叉熵和图像tokens的交叉熵。
4、实验
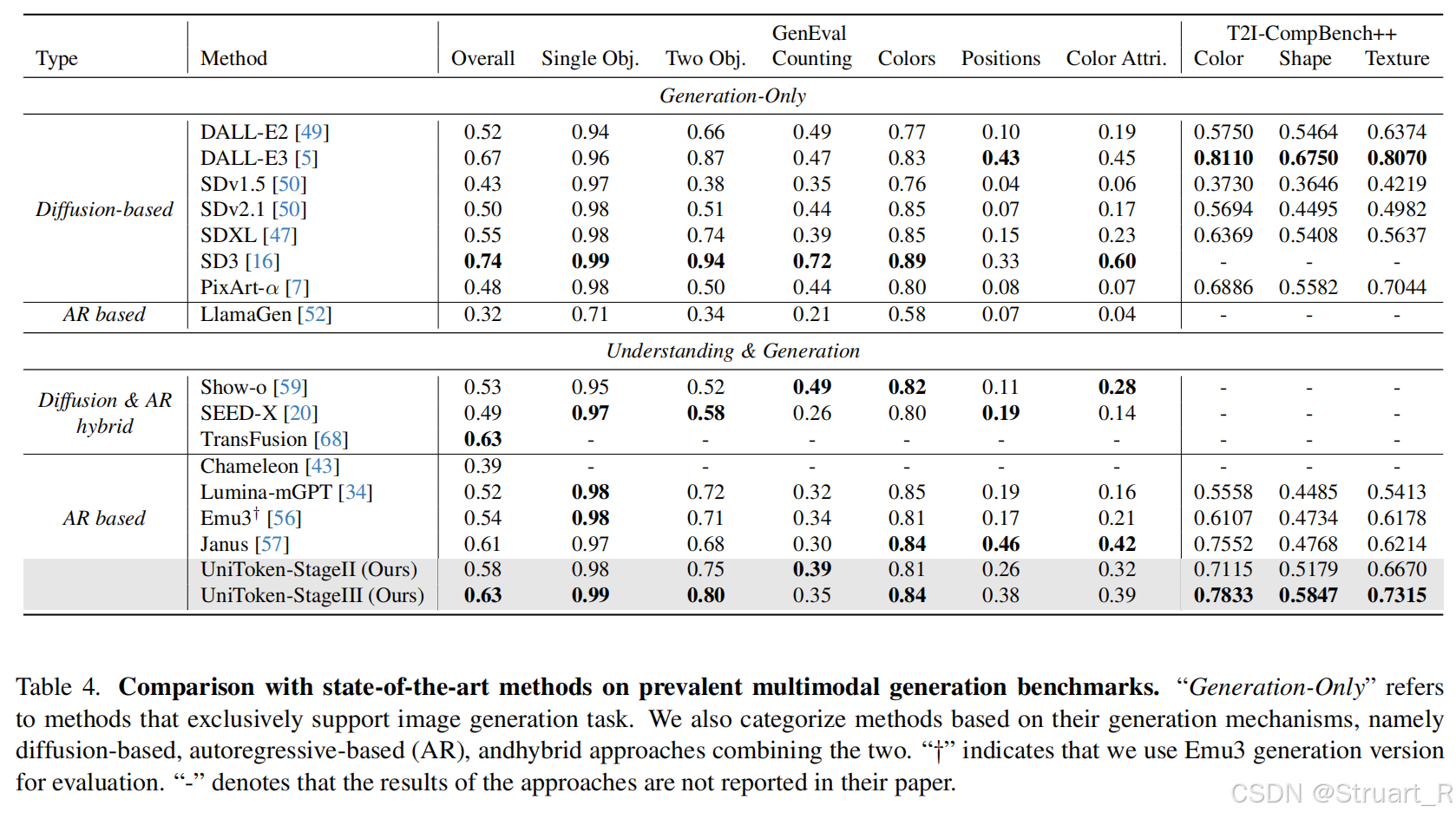
多模态理解能力远比生成能力提升的快。
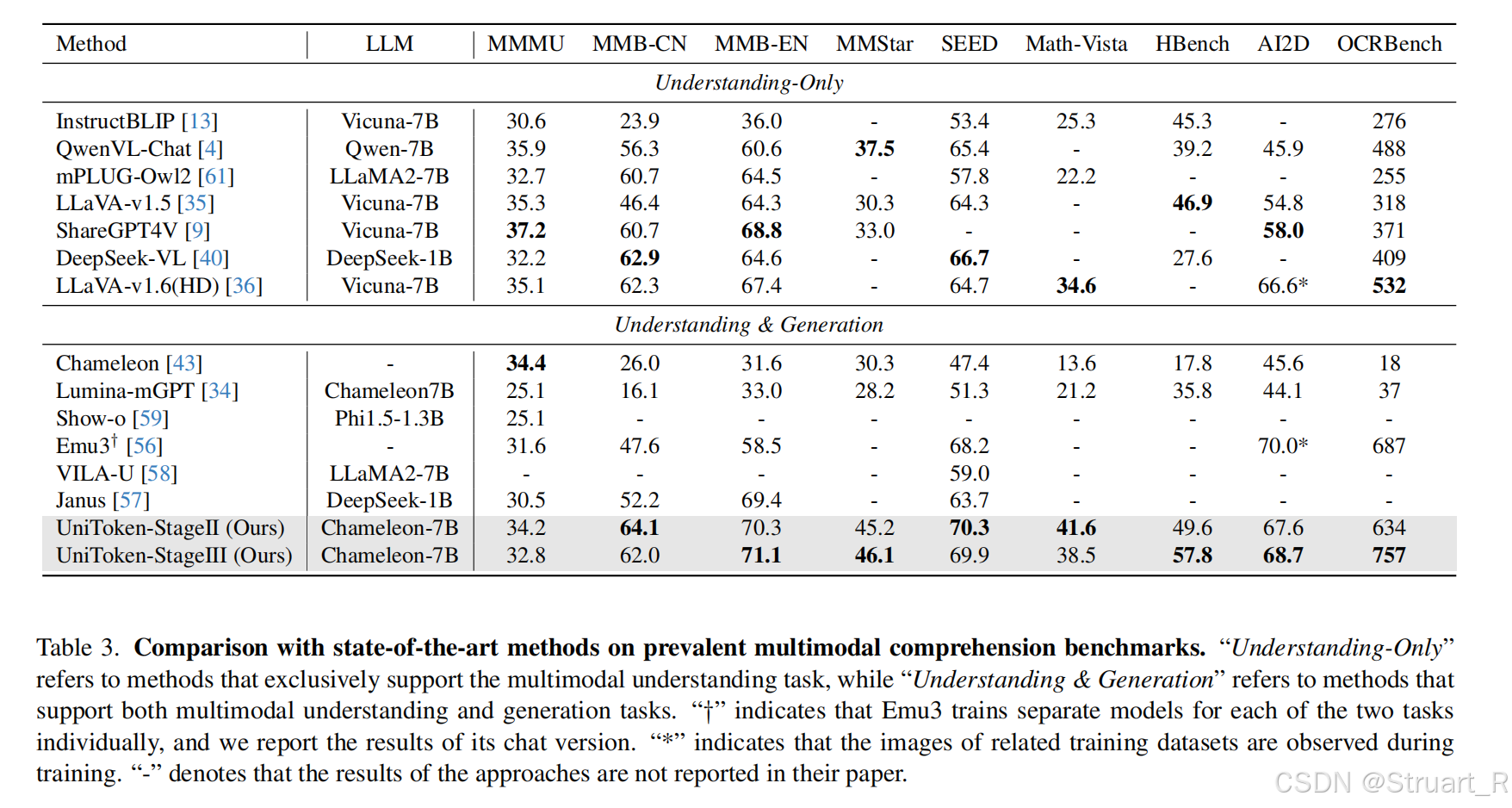
图像生成能力还是超不过DALLE-E 3,但是已经逐渐接近了。
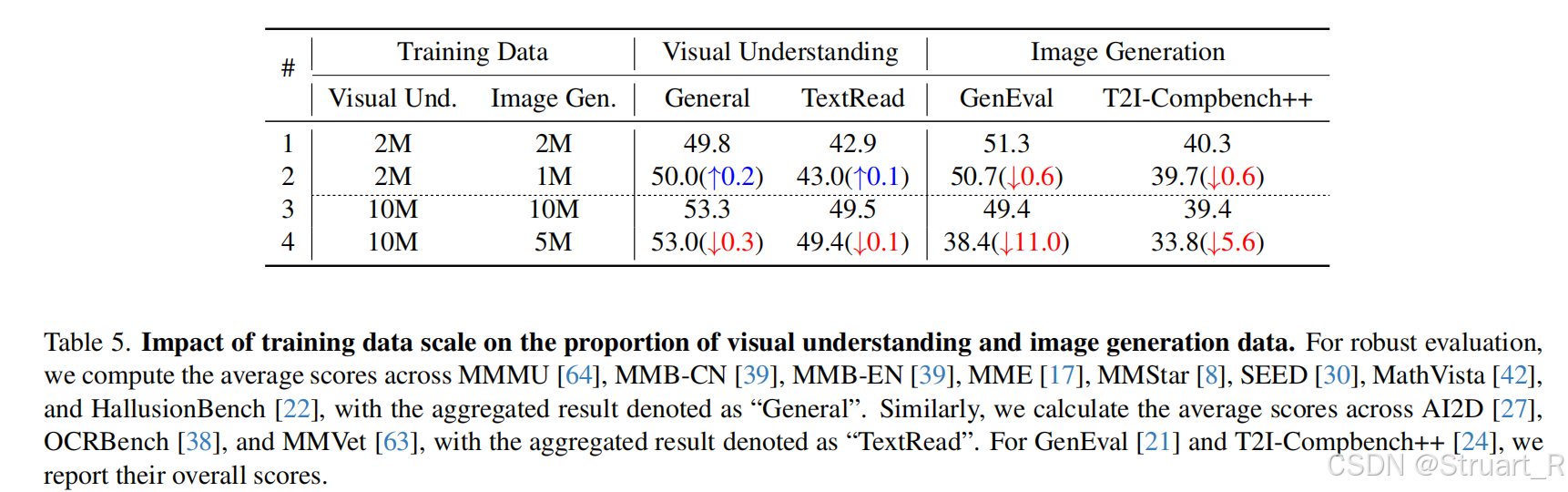
Und和Gen数据比例不同下的模型,同样证明了视觉理解数据的比例高于图像数据,或者说从理解数据中可以学到更多。
参考论文:
[2411.17762] MUSE-VL: Modeling Unified VLM through Semantic Discrete Encoding
[2412.03069] TokenFlow: Unified Image Tokenizer for Multimodal Understanding and Generation

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)