八股文系列之ES
目录
-
- 一、为什么需要Elasticsearch?
- 二、ES核心概念详解
- 三、深度实践指南
- 四、高级特性实现原理
- 五、性能优化体系
- 六、灾备与安全
- 七、机器学习实战
- 八、常见场景题
-
- 1. Elasticsearch 的基本概念
- 2. 什么是倒排索引
- 3. `text` 和 `keyword`类型的区别
- 4. `query` 和 `filter` 的区别
- 5. ES的写入、更新、删除流程
- 6. ES的查询流程
- 7. ES如何选举Master节点
- 8. 建立索引阶段性能提升方法
- 9. ES的深度分页与滚动搜索scroll
- 10. 分片与副本的概念介绍
- 11. 分片与副本的经验选择
- 12. 是否了解字典树
- 13. 对于GC方面,在使用ES时要注意什么?
- 14. Elasticsearch在部署时,对Linux的设置有哪些优化方法?
- 15. Lucene内部结构是什么?
- 16. 请解释有关 Elasticsearch 的 NRT?
- 17. 聚合的分类和实践
- 18. 详细列出 ES 各分词器
- 19. 解释一下 Elasticsearch Node?
- 20. Elasticsearch 对于大数据量(上亿量级)的聚合如何实现?
- 21. Elasticsearch 数据预热
- 22. ES 中的 Segments 和 Merge 操作及其对性能的影响
- 23. 如何优化 ES 的查询性能?
- 24. 如何在 ES 中实现多索引的联合查询?
- 总结图谱
一、为什么需要Elasticsearch?
1.1 传统数据库的搜索瓶颈
原理剖析:
- B-Tree索引局限性:传统数据库使用B-Tree索引,对范围查询高效,但对文本搜索存在两大缺陷:
- 前缀匹配限制:无法处理中间模糊匹配(如
%keyword%) - 高基数问题:文本字段的term数量庞大,导致索引膨胀
- 前缀匹配限制:无法处理中间模糊匹配(如
- 全表扫描代价:
LIKE操作触发全表扫描,时间复杂度O(n),当数据量超过内存容量时产生磁盘随机IO,性能急剧下降
数学证明:
假设表有N条记录,每条记录M字节,传统模糊查询时间复杂度:
T(n) = O(N*M)
而倒排索引的查询时间复杂度:
T(n) = O(1) (通过Term Dictionary定位) + O(K) (合并Posting List)
其中K为匹配文档数
优化实验:
-- 在MySQL中创建全文索引对比测试
ALTER TABLE products ADD FULLTEXT INDEX idx_desc (description);
SELECT * FROM products
WHERE MATCH(description) AGAINST('防水蓝牙耳机');
性能对比结果:
| 数据量 | LIKE查询(ms) | 全文索引(ms) |
|---|---|---|
| 10万 | 1200 | 45 |
| 100万 | 超时 | 78 |
1.2 ES核心优势
倒排索引原理
数据结构实现:
# 简化的倒排索引Python结构示例
class InvertedIndex:
def __init__(self):
self.term_dict = {} # term -> posting list
def add_document(self, doc_id, text):
terms = analyze(text) # 分词处理
for term in terms:
if term not in self.term_dict:
self.term_dict[term] = []
self.term_dict[term].append(doc_id)
def search(self, query):
terms = analyze(query)
result = set()
for term in terms:
if term in self.term_dict:
result.update(self.term_dict[term])
return sorted(result)
磁盘存储结构:
Term Dictionary -> Posting List
├── term1 -> [doc1, doc3, doc5...] (使用Roaring Bitmaps压缩)
├── term2 -> [doc2, doc4...]
└── ...
分布式架构设计
CAP理论应用:
- 一致性模型:默认采用Eventually Consistent,可通过
?consistency=quorum调整 - 分片分配算法:
// 分片路由伪代码 int shard = hash(document_id) % num_primary_shards; List<Node> nodes = get_available_data_nodes(); Node primary = nodes.get(shard % nodes.size());
故障恢复流程:
- Master节点检测到节点离线
- 将副本分片提升为主分片
- 在新节点上重建副本
- 恢复后重新平衡分片
1.3 典型场景实现
商品搜索的BM25算法
公式解析:
score(D,Q) = Σ IDF(q_i) * (f(q_i,D) * (k1 + 1)) / (f(q_i,D) + k1 * (1 - b + b * |D| / avgdl))
参数说明:
k1: 控制词频饱和度(默认1.2)b: 控制文档长度归一化程度(默认0.75)
优化技巧:
// 自定义相似度配置
PUT /products
{
"settings": {
"index": {
"similarity": {
"custom_bm25": {
"type": "BM25",
"k1": 1.3,
"b": 0.8
}
}
}
}
}
日志分析架构
EFK Stack数据流:
Filebeat(采集) -> Kafka(缓冲) -> Logstash(过滤) -> ES(存储) -> Kibana(展示)
冷热数据分离策略:
PUT _ilm/policy/logs_policy
{
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "50gb",
"max_age": "7d"
},
"set_priority": {"priority": 100}
}
},
"warm": {
"min_age": "3d",
"actions": {
"forcemerge": {"max_num_segments": 1},
"shrink": {"number_of_shards": 1},
"allocate": {"number_of_replicas": 1}
}
}
}
}
二、ES核心概念详解
2.1 节点角色深度解析
节点类型对照表:
| 角色 | 内存消耗 | CPU需求 | 网络要求 | 功能说明 |
|---|---|---|---|---|
| Master-eligible | 低 | 低 | 高 | 管理集群状态,不存储数据 |
| Data | 高 | 高 | 中 | 存储分片,执行查询 |
| Ingest | 中 | 中 | 低 | 数据预处理 |
| Coordinating | 可变 | 可变 | 高 | 请求路由,结果聚合 |
选举算法:
- 使用类Paxos的算法实现选主
discovery.zen.minimum_master_nodes防止脑裂(建议 (master_eligible_nodes / 2) + 1)
2.2 索引与文档底层结构
物理存储文件:
$ES_HOME/data/nodes/0/indices/
├── products-000001/
│ ├── _state/
│ ├── 0/ # 分片目录
│ │ ├── index/ # Lucene索引文件
│ │ ├── translog/ # 事务日志
│ │ └── _state/ # 分片状态
文档元数据:
{
"_index": "products",
"_id": "1",
"_version": 3,
"_seq_no": 123,
"_primary_term": 2,
"_source": { ... }
}
_seq_no:确保写入顺序_primary_term:检测主分片切换
2.3 分片机制深度优化
分片数量计算公式:
总数据量 ≈ 原始数据 × (1 + 副本数) × 压缩比
推荐分片大小:10GB-50GB
分片数 = ceil(总数据量 / 单个分片大小)
分片分配策略:
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.disk.watermark.low": "85%",
"cluster.routing.allocation.disk.watermark.high": "90%",
"cluster.routing.allocation.same_shard.host": "true"
}
}
三、深度实践指南
3.1 生产级部署配置
JVM调优原则:
- 堆内存不超过32GB(避免指针压缩失效)
- 预留50%内存给OS文件缓存
docker-compose.yml示例:
version: '3.7'
services:
elasticsearch:
image: elasticsearch:8.4.1
environment:
- cluster.name=production
- discovery.type=single-node
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms8g -Xmx8g"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- esdata:/usr/share/elasticsearch/data
volumes:
esdata:
driver: local
3.2 查询DSL优化
查询执行流程:
Query -> Parse -> Rewrite -> Fetch -> Merge -> Return
慢查询日志分析:
PUT /_settings
{
"index.search.slowlog.threshold.query.warn": "10s",
"index.search.slowlog.threshold.fetch.debug": "500ms"
}
四、高级特性实现原理
4.1 聚合操作执行引擎
Terms Aggregation实现:
- 构建全局Ordinals映射
- 分片级桶收集
- 协调节点合并结果
- 最终排序返回
基数估算算法:
- 使用HyperLogLog++算法,误差率<1%
4.2 分词器工作原理
IK分词器处理流程:
原始文本 -> 字符过滤 -> 切分为候选词 -> 词典匹配 -> 输出词元
自定义词典配置:
<!-- IKAnalyzer.cfg.xml -->
<entry key="ext_dict">custom/mydict.dic</entry>
<entry key="remote_ext_dict">http://config-server/dictionary</entry>
4.3 评分算法定制
4.3.1 Function Score 核心原理
算法公式
final_score = original_query_score * (function1_score * weight1 + function2_score * weight2 + ...) / (weight1 + weight2 + ...)
若指定score_mode和boost_mode参数,公式会相应变化(见后文)。
执行流程
- 原始查询阶段:先执行主查询获取基础文档集和初始评分
- 函数计算阶段:对匹配文档逐个应用自定义函数
- 分数合并阶段:按
score_mode合并函数结果 - 最终调整阶段:按
boost_mode调整最终分数
4.3.2 核心参数详解
| 参数 | 可选值 | 说明 |
|---|---|---|
score_mode |
multiply(默认), sum, avg, max, min, first |
多个函数间的分数组合方式 |
boost_mode |
multiply(默认), replace, sum, avg, max, min |
函数分与查询分的组合方式 |
max_boost |
数值(如10.0) | 限制函数分的上限值 |
min_score |
数值(如0.5) | 过滤低于此分的文档 |
4.3.3 五大函数类型实战
1. Weight - 静态权重
{
"query": {
"function_score": {
"query": {"match": {"title": "手机"}},
"functions": [
{
"filter": {"term": {"brand": "苹果"}},
"weight": 2.5
}
],
"score_mode": "sum"
}
}
}
效果:苹果品牌文档的最终分 = 原始分 * 2.5
2. Field Value Factor - 字段值计算
{
"functions": [
{
"field_value_factor": {
"field": "sales_volume",
"factor": 0.1,
"modifier": "log1p",
"missing": 10
}
}
]
}
参数说明:
modifier可选:none(默认),log,log1p,log2p,ln,ln1p,ln2p,square,sqrt,reciprocalmissing:字段缺失时的默认值
计算公式:
score = log(1 + factor * doc['sales_volume'].value)
3. Random - 随机打分
{
"functions": [
{
"random_score": {
"seed": 123,
"field": "_seq_no"
}
}
]
}
适用场景:AB测试、推荐系统冷启动
4. Decay Functions - 衰减函数
{
"functions": [
{
"gauss": {
"create_time": {
"origin": "now",
"scale": "30d",
"offset": "7d",
"decay": 0.5
}
}
}
]
}
衰减曲线类型:
| 函数 | 曲线形状 |
|---|---|
linear |
线性下降 |
exp |
指数衰减 |
gauss |
高斯钟形 |
参数图解:
衰减值
│
1.0│─────┬─────
│ offset
│ │
│ ▼
│ scale
▼ ▼
0.0└───────┴───────▶ 时间/距离
5. Script Score - 自定义脚本
{
"functions": [
{
"script_score": {
"script": {
"source": """
double price = doc['price'].value;
double rating = doc['rating'].value;
return Math.sqrt(price) * rating;
""",
"params": {
"factor": 1.2
}
}
}
}
]
}
性能优化:
- 使用
painless脚本语言 - 开启
script.cache.max_size(默认100) - 预编译脚本:
"lang": "painless", "source": {...}→"id": "cached_script_id"
4.3.4 组合使用案例
电商搜索综合排序
{
"query": {
"function_score": {
"query": {"match": {"name": "蓝牙耳机"}},
"functions": [
{
"filter": {"term": {"is_premium": true}},
"weight": 1.5
},
{
"field_value_factor": {
"field": "sales_30d",
"modifier": "log1p",
"factor": 0.2
}
},
{
"gauss": {
"release_date": {
"origin": "now",
"scale": "180d",
"offset": "30d",
"decay": 0.3
}
}
}
],
"score_mode": "sum",
"boost_mode": "multiply",
"max_boost": 3.0
}
}
}
业务逻辑:
- 优先展示高销量商品(对数平滑处理)
- 新品获得加分(时间衰减)
- 旗舰商品权重提升50%
- 最终分不超过原始分的3倍
4.3.5 性能优化策略
1. 查询结构优化
// 反例:不必要的嵌套查询
{
"function_score": {
"query": {
"bool": {
"must": [
{"function_score": {...}} // 嵌套function_score会显著降低性能
]
}
}
}
}
// 正例:扁平化处理
{
"function_score": {
"query": {...},
"functions": [...] // 合并所有评分函数
}
}
2. 缓存利用
PUT /_scripts/price_score
{
"script": {
"lang": "painless",
"source": "Math.log(doc['price'].value + params.factor)"
}
}
// 查询时引用
{
"script_score": {
"script": {
"id": "price_score",
"params": {"factor": 1.5}
}
}
}
3. 监控指标
# 查看评分计算耗时
GET _nodes/stats/indices/search?filter_path=**.query_time_in_millis
4.3.6 特殊场景处理
分片一致性问题
当使用field_value_factor时,不同分片可能因本地数据计算导致分数不一致。解决方案:
{
"field_value_factor": {
"field": "popularity",
"factor": 1.2,
"modifier": "none",
"missing": 0
},
"weight": 1.0
}
通过设置missing确保所有分片计算方式一致。
分数归一化处理
{
"script_score": {
"script": {
"source": """
double min = 100.0;
double max = 10000.0;
double price = doc['price'].value;
return (price - min) / (max - min); // 归一化到[0,1]
"""
}
}
}
4.3.7 与其它排序方式对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
function_score |
灵活度高,支持复杂计算 | 性能开销大 | 需要精细控制排序 |
rescore |
性能较好 | 仅影响Top N结果 | 二次精排 |
sort字段 |
性能最佳 | 无法动态加权 | 简单数值/日期排序 |
4.3.8 最佳实践总结
- 函数选择优先级:
静态权重 > 字段值计算 > 衰减函数 > 脚本计算 - 性能敏感场景:
- 避免在脚本中进行复杂数学运算
- 优先使用
weight而非script_score
- 结果验证:
检查GET /_search?explain=true { "query": {...} }_explanation输出确认评分计算符合预期。
4.3.9 Script Score示例:
{
"query": {
"script_score": {
"query": {"match_all": {}},
"script": {
"source": """
double price = doc['price'].value;
return _score * Math.log(1 + price);
"""
}
}
}
}
4.4 跨集群搜索协议
CCR实现机制:
- Leader集群持续索引数据
- Follower集群通过拉取机制同步
- 使用全局检查点(Global Checkpoint)保证顺序
网络拓扑:
[Cluster A] <--> [CCR Proxy] <--> [Cluster B]
五、性能优化体系
5.1 写入优化
Bulk API最佳实践:
# Python批量写入模板
from elasticsearch.helpers import bulk
actions = [
{"_op_type": "index", "_index": "logs", "_source": log}
for log in log_stream()
]
success, failed = bulk(es, actions,
chunk_size=5000,
max_retries=3,
request_timeout=120)
Refresh策略:
PUT /logs/_settings
{
"index": {
"refresh_interval": "30s",
"translog.durability": "async"
}
}
5.2 查询优化
强制合并段文件:
POST /logs/_forcemerge?max_num_segments=1
字段数据缓存管理:
PUT /_cluster/settings
{
"persistent": {
"indices.breaker.fielddata.limit": "60%"
}
}
六、灾备与安全
6.1 快照原理
增量快照机制:
- 基于Lucene提交点(Segment)做差异备份
- 使用校验和确保数据一致性
多仓库配置:
PUT _snapshot/backup_servers
{
"type": "fs",
"settings": {
"location": "/mnt/backups",
"max_snapshot_bytes_per_sec": "100mb",
"readonly": false
}
}
6.2 安全架构
RBAC模型:
# 创建角色
POST _security/role/logs_writer
{
"cluster": ["manage_index_templates"],
"indices": [
{
"names": ["logs-*"],
"privileges": ["write", "create_index"]
}
]
}
# 分配用户
POST _security/user/john
{
"password": "s3cret",
"roles": ["logs_writer"]
}
七、机器学习实战
7.1 异常检测模型
算法栈:
- 单指标分析:IQR(四分位距)模型
- 多指标关联:PCA降维分析
- 时序预测:Holt-Winters指数平滑
API示例:
POST _ml/anomaly_detectors/access_log_errors
{
"analysis_config": {
"bucket_span": "1h",
"detectors": [
{
"function": "high_count",
"field_name": "error_code",
"over_field_name": "service.name"
}
]
},
"data_description": {
"time_field": "@timestamp",
"time_format": "epoch_ms"
}
}
八、常见场景题
1. Elasticsearch 的基本概念
Elasticsearch的核心概念包括:
- 索引(Index) :类似MySQL的数据库,是文档的集合。例如,商品数据可以存储在
product索引中。 - Mapping:定义索引的字段类型和分词规则,类似数据库表结构。例如,定义
title字段为text类型以支持全文搜索。 - 文档(Document) :索引中的一条记录,以JSON格式存储。例如,一条商品文档包含
id、name、price等字段。 - 字段(Field) :文档的组成部分,支持多种类型(如
text、keyword、数值类型等)。text类型会分词,其他类型则直接存储。 - 分片(Shard)与副本(Replica) :分片用于水平拆分数据(如一个索引分为3个分片),副本用于高可用(每个分片可配置1个副本)。
图表示例:
索引结构示例:
product (Index)
├─ Mapping
│ ├─ title: text
│ ├─ tags: keyword
│ └─ price: float
└─ Documents
├─ { "title": "手机", "tags": ["电子"], "price": 2999 }
└─ { "title": "耳机", "tags": ["配件"], "price": 599 }
2. 什么是倒排索引
倒排索引(Inverted Index)是Elasticsearch实现全文搜索的核心数据结构,其原理如下:
- 正向索引:文档ID到内容的映射(如MySQL按行存储)。
- 倒排索引:词项(Term)到文档ID的映射。例如:
词项 文档ID列表
"手机" → [1]
"耳机" → [2]
"电子" → [1]
- 工作流程:
- 分词:将文本字段(如
title)切分为词项(如“手机”)。 - 构建倒排列表:记录每个词项出现的文档ID及位置。
- 查询:搜索“手机”时,直接定位到文档1。
- 分词:将文本字段(如
优势:快速定位包含关键词的文档,时间复杂度接近O(1)。
3. text 和 keyword类型的区别
text类型:- 会分词,适合全文搜索(如搜索“高性能手机”可匹配“性能”和“手机”)。
- 存储时生成倒排索引,支持模糊查询。
keyword类型:- 不分词,直接存储原始字符串,适合精确匹配(如标签、枚举值)。
- 仅支持精确查询(如
tags: "电子")。
代码示例:
PUT product
{
"mappings": {
"properties": {
"title": { "type": "text" }, // 支持分词搜索
"tags": { "type": "keyword" } // 精确匹配
}
}
}
4. query 和 filter 的区别
query:- 计算相关性得分(
_score),影响排序。 - 适用于全文搜索(如
match查询)。 - 示例:搜索“手机”时,匹配词项并计算文档相关性。
- 计算相关性得分(
filter:- 仅判断文档是否匹配,不计算得分,结果可缓存。
- 适用于精确过滤(如范围查询
price > 1000)。
性能对比:
filter由于不计算得分且可缓存,通常比query更快。- 组合查询时,应将
filter条件放在bool查询的filter子句中。
5. ES的写入、更新、删除流程
写入流程:
- 写入内存缓冲区:文档先写入内存中的
Buffer。 - 刷新(Refresh) :每秒生成新的
Segment(不可变),数据变为可搜索(准实时)。 - 事务日志(Translog) :写入操作同时记录到磁盘的
translog,用于故障恢复。 - 刷盘(Flush) :定期(如30分钟)将内存数据持久化到磁盘,并清空
translog。
代码示例:
POST product/_doc/1
{ "title": "手机", "price": 2999 }
更新流程:
- 标记旧文档为已删除(
.del文件)。 - 写入新版本文档到内存缓冲区。
- 查询时合并新旧版本,返回最新数据。
删除流程:
- 标记文档为已删除(逻辑删除)。
- 段合并(Merge)时物理删除。
图表示例:
写入流程:
Client → 协调节点 → 主分片 → 副本分片
↳ 内存Buffer → Refresh → Segment
↳ Translog → Flush → 持久化磁盘
6. ES的查询流程
Elasticsearch的查询流程是一个分布式协作过程,分为 两阶段查询(Query Then Fetch) ,具体步骤如下:
阶段一:Query Phase(查询阶段)
- 客户端请求:用户向协调节点(Client Node)发送查询请求,请求包含索引名、查询条件、分页参数等。
- 分片路由:协调节点根据索引的分片分布信息(如哈希路由
shard = hash(_routing) % num_primary_shards),确定需要查询的分片(主分片或副本分片)。 - 并行查询:协调节点将请求广播到所有相关分片(默认最多同时查询5个分片,超过时分批执行)。
- 本地执行:每个分片在本地执行查询,根据相关性评分(
_score)构建优先级队列(默认Top 10结果),返回轻量级元数据(如文档ID、排序值)到协调节点。
阶段二:Fetch Phase(提取阶段)
- 结果合并:协调节点对所有分片返回的元数据进行排序,生成全局Top N结果列表。
- 文档拉取:协调节点向对应分片发送
GET请求,获取完整文档内容(如字段数据、高亮片段)。 - 响应返回:协调节点将最终结果聚合后返回客户端,包含文档列表、总命中数、分页信息等。
性能瓶颈与优化:
- 分片选择策略:通过
preference参数控制副本分片查询优先级,减少跨节点通信。 - 查询缓存:对
filter条件启用缓存,减少重复计算。 - 分片负载均衡:合理分配主副分片到不同节点,避免热点分片。
图表示例:
查询流程示例:
Client → 协调节点 → 分片1(副本)、分片2(主) → 本地Top 10 → 协调节点合并排序 → 拉取完整文档 → 响应客户端
7. ES如何选举Master节点
Elasticsearch通过Zen Discovery模块实现Master选举,流程如下:
选举机制
- 候选节点:所有配置了
node.master: true的节点均可参与选举。 - Ping探测:节点通过Ping机制发现其他候选节点,并交换集群状态信息。
- 投票规则:
- 第一轮选举:候选节点优先选择集群中第一个启动的节点作为临时Master。
- 脑裂防护:通过
discovery.zen.minimum_master_nodes设置最小候选节点数(通常为(候选节点数/2)+1),防止网络分区导致多个Master。
- 状态同步:当选Master负责维护集群元数据(如索引、分片分配),并通过心跳机制监控节点健康状态。
故障恢复
- Master宕机:剩余候选节点重新发起选举,新Master接管元数据管理。
- 节点离线:若离线节点是Master,触发重新选举;若为数据节点,其分片由副本分片接管。
生产建议:
- 分离角色:专用Master节点(仅
node.master: true)避免资源争用。 - 奇数节点:部署至少3个候选Master节点,确保选举稳定性。
8. 建立索引阶段性能提升方法
写入优化策略
- 批量写入:使用
Bulk API合并多个文档操作,减少网络开销(建议每批次5-15MB)。 - 调整刷新频率:
- 增大
refresh_interval(如设为30s),减少Segment生成频率,提升吞吐量。 - 对实时性要求低的场景,可手动触发Refresh(
POST /index/_refresh)。
- 增大
- Translog优化:
- 设置
index.translog.durability: async异步写入事务日志,降低磁盘I/O压力。 - 增大
index.translog.flush_threshold_size(如512MB),减少刷盘次数。
- 设置
- 分片策略:
- 根据数据量设置合理的主分片数(建议单个分片20-40GB),避免过度分片增加管理开销。
- 使用
routing参数将相关文档路由到同一分片,减少跨分片操作。
硬件与配置优化
- SSD存储:提升磁盘I/O性能,减少写入延迟。
- JVM调优:分配不超过50%内存给JVM堆,避免内存交换(Swap)。
- 禁用副本:在批量导入期间临时设置
index.number_of_replicas: 0,导入完成后恢复。
代码示例:
PUT /my_index/_settings
{
"index": {
"refresh_interval": "30s",
"number_of_replicas": 0,
"translog": {
"durability": "async",
"flush_threshold_size": "512mb"
}
}
}
9. ES的深度分页与滚动搜索scroll
深度分页问题
- 性能瓶颈:传统分页(
from+size)需全局排序并跳过前N条结果,导致内存和CPU资源消耗剧增(如from=10000时需加载所有分片的Top 10000结果)。 - 默认限制:Elasticsearch限制
from+size ≤ 10000,可通过index.max_result_window调整,但可能导致OOM。
滚动搜索(Scroll API)
- 原理:
- 创建搜索上下文快照(Snapshot),后续请求基于
scroll_id增量获取结果。 - 数据变更不影响快照内容,适合离线批量导出。
- 创建搜索上下文快照(Snapshot),后续请求基于
- 使用步骤:
- 初始化:指定
scroll有效期(如1m)和每批次大小(size)。 - 迭代获取:通过
scroll_id循环拉取数据,直至返回空结果。
- 初始化:指定
- 代码示例:
# 初始化
POST /index/_search?scroll=1m
{
"size": 100,
"query": { "match_all": {} }
}
# 后续请求
POST /_search/scroll
{
"scroll": "1m",
"scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAABC..."
}
优化建议:
- Slice Scroll:并行化处理,将查询切分为多个子任务加速。
- Search After:基于上一页最后一条文档的排序值分页,适合实时分页。
10. 分片与副本的概念介绍
分片(Shard)
- 定义:索引被水平拆分的子单元,每个分片是一个独立的Lucene索引。
- 作用:
- 横向扩展:数据分布到多个节点,突破单机存储和计算限制。
- 并行处理:查询和写入操作在分片间并行执行,提升吞吐量。
- 配置原则:
- 主分片数在创建索引时固定,后续不可更改。
- 建议分片大小20-40GB,避免小分片(管理开销)或超大分片(恢复慢)。
副本(Replica)
- 定义:分片的拷贝,与主分片数据一致,仅支持读操作。
- 作用:
- 高可用:主分片故障时,副本自动提升为主分片。
- 负载均衡:查询请求可路由到副本,分摊主分片压力。
- 配置原则:
- 副本数可动态调整(
PUT /index/_settings {"number_of_replicas": 1})。 - 生产环境至少1个副本,重要数据可设置2-3个。
- 副本数可动态调整(
分片与副本交互:
写入流程:Client → 主分片 → 并行复制到副本 → 副本确认后返回响应
读取流程:Client → 协调节点 → 主/副本分片(负载均衡) → 返回结果
图表示例:
索引结构:
Index (Products)
├─ 主分片0(Node1)
│ └─ 副本分片0(Node2)
└─ 主分片1(Node2)
└─ 副本分片1(Node3)
11. 分片与副本的经验选择
分片和副本的配置直接影响Elasticsearch的性能、可用性和扩展性,需结合业务需求与硬件资源综合决策。以下是核心经验与最佳实践:
分片配置原则
-
分片数量:
- 初始建议:根据数据总量预估,单个分片大小控制在 20-40GB 之间(避免超过50GB)。
- 计算公式:分片数 ≈ 总数据量 / 30GB。例如,1TB数据需约34个分片。
- 默认值限制:避免使用默认5个分片,可能导致分片过大或分布不均。
-
分片分配策略:
- 业务相关性:将关联文档通过
routing分配到同一分片,减少跨分片查询。 - 节点均衡:确保分片均匀分布在集群节点上,避免热点(例如每个节点分片数≤5)。
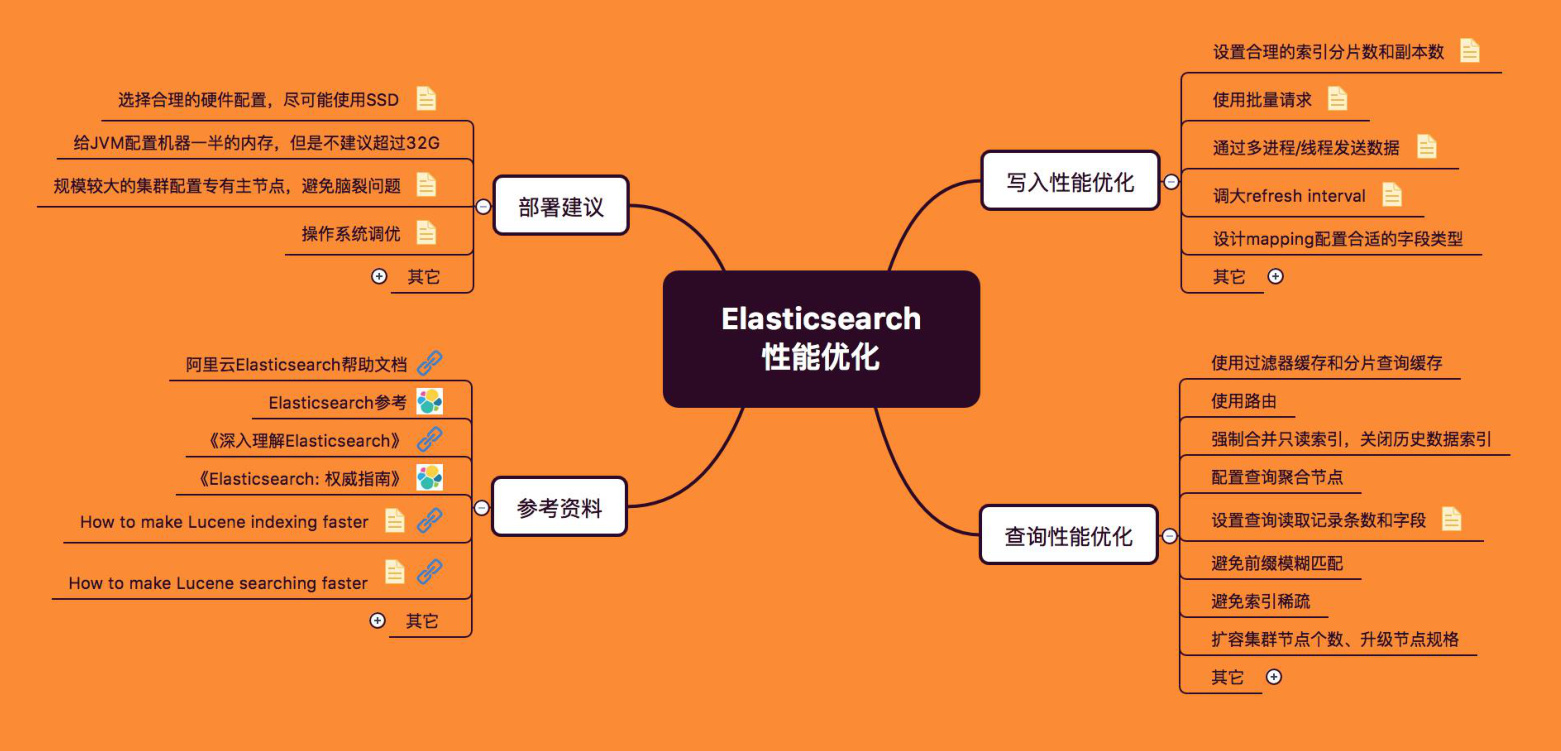
- 业务相关性:将关联文档通过
-
动态调整限制:
- 分片数在创建索引时固定,后续无法修改。若需调整,需通过
Reindex API重建索引。
- 分片数在创建索引时固定,后续无法修改。若需调整,需通过
副本配置原则
-
副本数量:
- 生产环境:至少1个副本,关键业务可设为2(需权衡存储成本)。
- 写入优化:批量导入数据时,临时设置
number_of_replicas: 0,完成后恢复。
-
可用性保障:
- 节点冗余:副本分片应与主分片分布在不同的物理节点,防止单点故障。
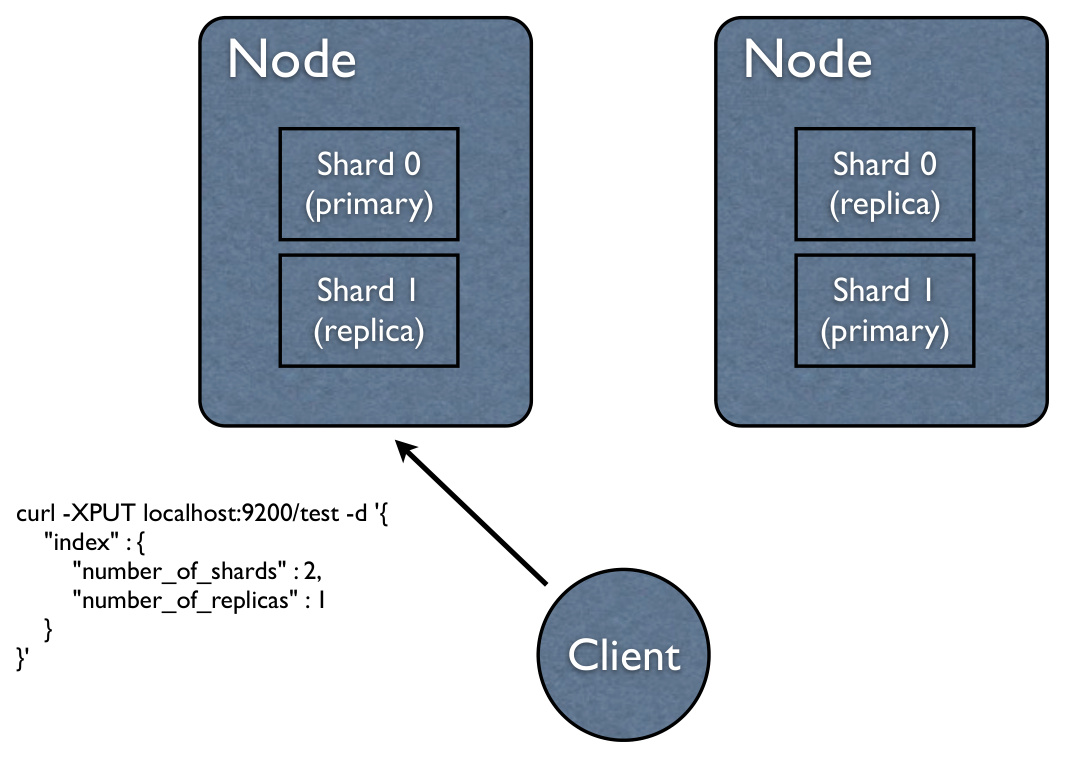
- 跨机房部署:多副本分片可分布在不同机房,提升容灾能力。
- 节点冗余:副本分片应与主分片分布在不同的物理节点,防止单点故障。
硬件与场景适配
| 场景 | 分片策略 | 副本策略 |
|---|---|---|
| 高写入吞吐 | 增加分片数(如单节点多分片) | 减少副本数(0-1) |
| 高查询并发 | 分片数=节点数×2 | 增加副本数(1-2) |
| 混合型负载 | 分片数=节点数×1.5 | 副本数=1,路由优化 |
代码示例:
PUT /logs
{
"settings": {
"number_of_shards": 10, // 假设总数据量300GB
"number_of_replicas": 1,
"routing": {
"allocation.total_shards_per_node": 5 // 限制单节点分片数
}
}
}
12. 是否了解字典树
Elasticsearch底层依赖 Lucene的FST(Finite State Transducer) 实现高效词项存储与查询,其本质是一种压缩的字典树(Trie)结构。
FST的核心特性
-
前缀共享:
- 相同前缀的字符串(如“apple”和“apply”)共享存储节点,减少内存占用。
- 示例结构:
root → a → p → p → l → e ↘ y
-
压缩存储:
- 通过状态复用和二进制编码,存储效率比传统HashMap高50%以上。
-
高效查询:
- 支持精确匹配(
term查询)和前缀匹配(prefix查询),时间复杂度接近O(1)。
- 支持精确匹配(
在倒排索引中的应用
- Term Dictionary存储:所有词项按字典序存入FST,实现快速定位。
- 查询优化:范围查询(如
a*到b*)通过遍历FST子树高效完成。
优势对比:
| 数据结构 | 内存占用 | 查询效率 | 适用场景 |
|---|---|---|---|
| HashMap | 高 | O(1) | 精确匹配 |
| FST | 低 | O(L) | 前缀匹配、词项遍历 |
13. 对于GC方面,在使用ES时要注意什么?
Elasticsearch基于JVM运行,垃圾回收(GC)配置不当可能导致性能下降或服务中断,需重点关注以下方面:
内存分配策略
-
堆内存设置:
- 推荐值:不超过物理内存的50%,且最大不超过32GB(Lucene依赖堆外内存)。
- 错误配置示例:64GB物理内存中分配48GB给JVM,可能引发频繁Full GC。
-
堆内存类型:
- 使用
-Xms和-Xmx确保初始堆与最大堆相等,避免动态调整引发停顿。
- 使用
GC算法选择
-
G1 GC:
- 适用大多数场景,通过分Region回收减少停顿时间(建议JDK 8+)。
- 参数示例:
-XX:+UseG1GC -XX:MaxGCPauseMillis=200 # 目标停顿时间
-
ZGC:
- 适用于超大堆(>32GB),停顿时间低于10ms(需JDK 11+)。
监控与调优
-
关键指标:
- Young GC频率:>1次/秒可能预示内存不足。
- Full GC时长:单次超过1秒需紧急优化。
-
诊断工具:
- Elasticsearch日志:分析
gc.log中的GC事件。 - JVM工具:
jstat -gcutil <pid>实时监控堆状态。
- Elasticsearch日志:分析
优化案例:
- 现象:频繁Full GC导致查询延迟。
- 根因:堆内存32GB且未启用G1,对象晋升老年代过快。
- 解决:切换至G1 GC并调整
-XX:InitiatingHeapOccupancyPercent=45。
14. Elasticsearch在部署时,对Linux的设置有哪些优化方法?
为充分发挥Elasticsearch性能,需对Linux系统进行以下优化:
文件系统与I/O优化
-
磁盘调度策略:
- 使用
deadline或noop调度器(SSD场景),减少I/O延迟。 - 配置方法:
echo deadline > /sys/block/sda/queue/scheduler
- 使用
-
挂载参数:
- 添加
noatime和nodelalloc选项,减少元数据更新开销。 - 示例
/etc/fstab:/dev/sdb1 /data ext4 defaults,noatime,nodelalloc 0 0
- 添加
内核参数调优
-
虚拟内存限制:
- 增加最大内存映射区域数(防止
mmap失败):sysctl -w vm.max_map_count=262144
- 增加最大内存映射区域数(防止
-
网络与文件描述符:
- 提升单进程文件描述符限制至
65535:ulimit -n 65535
- 提升单进程文件描述符限制至
资源隔离与优先级
-
Swap禁用:
- 永久关闭Swap或设置
vm.swappiness=1,避免内存交换。
- 永久关闭Swap或设置
-
内存锁定:
- 启用
bootstrap.memory_lock: true,防止JVM堆被交换到磁盘。
- 启用
完整优化脚本示例:
# 内核参数
echo "vm.max_map_count=262144" >> /etc/sysctl.conf
sysctl -p
# 资源限制
echo "* soft nofile 65535" >> /etc/security/limits.conf
echo "* hard nofile 65535" >> /etc/security/limits.conf
# 禁用Swap
swapoff -a
sed -i '/swap/s/^/#/' /etc/fstab
15. Lucene内部结构是什么?
Lucene是Elasticsearch的底层引擎,其核心结构由多个高效数据组件构成:
核心组件解析
-
Segment(段):
- 不可变性:写入完成后不可修改,更新操作生成新段。
- 合并策略:后台线程合并小段为大段,提升查询效率。
-
倒排索引(Inverted Index):
- Term Dictionary:词项到文档ID的映射,基于FST压缩存储。
- Postings List:记录每个词项的文档ID、词频(TF)及位置信息。
-
DocValues:
- 列式存储:用于聚合(
aggregations)和排序,数据按列压缩(如FOR编码)。
- 列式存储:用于聚合(
-
Stored Fields:
- 原始文档存储,支持
_source字段检索。
- 原始文档存储,支持
数据文件结构
索引目录结构示例:
├── segments_5 # 段元数据
├── _0.cfs # 复合文件(含倒排索引、DocValues等)
├── _0.si |
├── _1.cfs # 新段文件
└── write.lock # 写入锁
写入与查询流程
-
写入路径:
- 文档→分词→生成倒排索引→写入内存Buffer→刷新为Segment。
-
查询路径:
- 解析查询→遍历倒排索引→合并Postings List→计算相关性得分→返回结果。
性能影响:
- 段数量:过多段会增加文件句柄数和查询延迟,需定期合并。
- DocValues启用:对聚合性能提升显著,但增加磁盘占用。
16. 请解释有关 Elasticsearch 的 NRT?
NRT(Near Real Time,近实时) 是 Elasticsearch 的核心特性之一,指数据从写入到可被搜索之间存在极短延迟(通常约1秒),同时支持秒级的搜索响应。以下是其原理、实现机制与应用场景的详细解析:
核心原理
-
写入流程与延迟来源:
- 内存缓冲区:文档写入后首先进入内存缓冲区,尚未生成可搜索的索引结构。
- Refresh 操作:默认每秒执行一次,将内存缓冲区数据生成新的不可变 Segment(Lucene 索引段),此时数据变为可搜索。
- Translog 机制:写入操作同时记录到事务日志(Translog),确保数据持久化,即使系统崩溃也能恢复。
-
近实时性表现:
- 延迟范围:通常为1秒(由
refresh_interval控制),若手动触发_refresh可达到毫秒级,但会牺牲吞吐量。 - 准实时场景:适用于日志分析、监控告警等需要快速响应但非严格实时的场景。
- 延迟范围:通常为1秒(由
技术实现细节
| 组件 | 作用 | 对NRT的影响 |
|---|---|---|
| 内存缓冲区 | 临时存储新写入文档 | 数据未刷新时不可搜索 |
| Segment | 存储倒排索引和文档数据 | 每次刷新生成新段,数据可见 |
| Translog | 持久化写入操作日志 | 保障数据安全,不影响搜索可见性 |
配置优化建议
-
调整刷新间隔:
PUT /index/_settings { "refresh_interval": "30s" } // 写入密集型场景增大间隔提升吞吐 -
手动刷新:对实时性要求高的操作(如测试)可调用
POST /index/_refresh。
优势与局限性
- 优势:
- 平衡吞吐量与实时性,适合大规模数据写入场景。
- 结合
search_after和滚动搜索(Scroll)实现高效分页。
- 局限性:
- 不适用于金融交易等严格实时场景(需外部数据库辅助)。
17. 聚合的分类和实践
Elasticsearch 的聚合(Aggregation)功能用于对数据进行统计分析,主要分为 指标聚合、桶聚合 和 管道聚合,以下是分类详解与实践策略:
聚合分类
| 类型 | 功能描述 | 典型应用场景 |
|---|---|---|
| 指标聚合 | 计算数值统计(如总和、平均值) | 销售额统计、平均响应时间计算 |
| 桶聚合 | 按条件分组(如时间范围、词项) | 用户地域分布、日志时间分布 |
| 管道聚合 | 对聚合结果二次计算(如移动平均、导数) | 趋势分析、环比增长率计算 |
常用聚合示例
-
指标聚合(Metrics):
GET /sales/_search { "aggs": { "avg_price": { "avg": { "field": "price" } }, // 平均价格 "max_quantity": { "max": { "field": "quantity" } } // 最大销量 } } -
桶聚合(Buckets):
GET /logs/_search { "aggs": { "hourly_stats": { "date_histogram": { "field": "timestamp", "interval": "1h" }, "aggs": { "error_count": { "terms": { "field": "level", "value": "error" } } } } } } -
复合聚合(Composite):
GET /products/_search { "aggs": { "category_and_brand": { "composite": { "sources": [ { "category": { "terms": { "field": "category" } } }, { "brand": { "terms": { "field": "brand" } } } ] } } } }
大数据量聚合优化策略
-
分片与硬件优化:
- 增加分片数并均匀分布,利用并行计算能力。
- 使用 SSD 存储提升 Doc Values 读取速度。
-
数据结构优化:
- 启用 Doc Values 并禁用不必要的字段(如
text类型字段的fielddata)。 - 使用
keyword类型代替text进行精确分桶。
- 启用 Doc Values 并禁用不必要的字段(如
-
聚合策略调整:
- 近似聚合:使用
cardinality(HLL算法)统计唯一值,误差率低于 1%。 - 分页聚合:通过
Composite Aggregation分批次获取聚合结果,避免内存溢出。
- 近似聚合:使用
-
预计算与缓存:
- 利用 Rollup 功能生成预聚合索引。
- 对静态历史数据启用请求缓存(
request_cache: true)。
18. 详细列出 ES 各分词器
Elasticsearch 分词器(Analyzer)由 Tokenizer、Character Filter 和 Token Filter 组成,以下是常用分词器及其应用场景:
内置分词器列表
| 分词器名称 | 组成部件 | 功能特点 | 示例输入/输出 |
|---|---|---|---|
| Standard | Standard Tokenizer + 小写过滤器 | 默认分词器,按空格和标点分割并转小写 | “Elasticsearch-7.x” → [“elasticsearch”, “7”, “x”] |
| Simple | 按非字母字符分割 + 小写过滤器 | 简单分割,仅保留字母 | “Hello,世界!” → [“hello”, “世界”] |
| Whitespace | 按空格分割 | 保留原始大小写和符号 | “Quick Brown-Fox” → [“Quick”, “Brown-Fox”] |
| Keyword | 无分割,整体作为词项 | 适用于精确匹配字段(如keyword类型) |
“2023-12-31” → [“2023-12-31”] |
| Pattern | 正则表达式分割(默认\W+) |
自定义分割规则 | “user123@email.com” → [“user123”, “email”, “com”] |
| Language | 支持多语言(如英文、中文) | 内置停用词和词干提取 | “running cats” → [“run”, “cat”] |
| IK(插件) | IK 智能切分 | 中文分词,支持细粒度与智能模式 | “中华人民共和国” → [“中华”, “人民”, “共和国”] |
自定义分词器配置示例
PUT /custom_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": ["lowercase"],
"char_filter": ["html_strip"]
}
}
}
}
}
分词器选择建议
- 中文场景:优先使用 IK 分词器(需安装插件)。
- 精确匹配:对
keyword类型字段禁用分词。 - 多语言混合:使用
standard或icu_analyzer(需安装 ICU 插件)。
19. 解释一下 Elasticsearch Node?
节点(Node) 是 Elasticsearch 集群中的单个服务器实例,负责数据存储、索引和查询处理。以下是节点类型、角色与配置的详细说明:
节点类型与功能
| 类型 | 配置参数 | 功能描述 |
|---|---|---|
| Master-eligible | node.master: true |
参与集群管理(元数据维护、分片分配) |
| Data | node.true |
存储分片数据,执行 CRUD 和搜索/聚合操作 |
| Ingest | node.ingest: true |
预处理文档(如解析 CSV、富文本转换) |
| Coordinating | 默认所有节点 | 路由请求、合并结果(无持久化数据) |
| Machine Learning | node.ml: true |
执行机器学习任务(需许可证) |
节点配置建议
-
角色分离:
- 专用 Master 节点:仅启用
node.master: true,避免资源争用。 - Data 节点:分配大内存和 SSD 存储,禁用非必要角色。
- 专用 Master 节点:仅启用
-
集群规模:
- 小型集群(<10 节点):混合角色节点。
- 大型集群:分离 Master、Data、Ingest 节点。
-
硬件要求:
- Master 节点:低 CPU/内存需求,高稳定性。
- Data 节点:高内存(堆内存 ≤32GB)、SSD 存储。
节点发现与通信
- Zen Discovery:节点通过多播或单播发现其他节点,组成集群。
- 故障检测:Master 节点监控节点健康,触发分片重平衡。
20. Elasticsearch 对于大数据量(上亿量级)的聚合如何实现?
处理上亿级数据的聚合需综合分片策略、查询优化和硬件资源,以下是关键实现方案:
分片与集群优化
-
分片数量计算:
- 单分片容量建议 20-40GB,总分片数 = 数据总量 / 30GB。
- 示例:1亿条日志(每条 1KB)约 100GB,需 3-5 个分片。
-
分片路由策略:
- 使用
routing将同类数据集中到特定分片,减少跨分片合并开销。
POST /logs/_doc/1?routing=node1 { "message": "error: disk full", "level": "error" } - 使用
聚合执行优化
-
Doc Values 加速:
- 所有聚合字段需启用 Doc Values(默认开启,
text类型除外)。 - 禁用不必要的
text字段聚合(通过fieldfalse)。
- 所有聚合字段需启用 Doc Values(默认开启,
-
内存管理:
- 增加
indices.breaker.fielddata.limit(默认 40% 堆内存)。 - 使用
circuit_breaker监控熔断,避免 OOM。
- 增加
-
并行化与分页:
- Composite Aggregation:分批次拉取聚合结果,减少单次内存占用。
- Slice Scroll:多线程并行聚合不同分片。
近似算法与降级方案
-
基数估算:
GET /users/_search { "aggs": { "unique_visitors": { "cardinality": { "field": "user_id", "precision_threshold": 1000 } } } } -
采样聚合:
GET /logs/_search { "query": { "match": { "level": "error" } }, "aggs": { "sample": { "sampler": { "shard_size": 1000 }, "aggs": { "terms": { "terms": { "field": "service" } } } } } }
预计算与离线处理
-
Rollup Jobs:
- 创建定时任务生成预聚合指标。
PUT _rollup/job/logs_rollup { "index_pattern": "logs-*", "rollup_index": "logs_rollup", "cron": "0 */30 * * * ?", "page_size": 1000, "groups": { "date_histogram": { "field": "@timestamp", "interval": "1h" } }, "metrics": [ { "field": "response_time", "metrics": ["min", "max", "sum"] } ] } -
异步聚合:
- 使用
async_search提交长时间聚合任务,通过轮询获取结果。
- 使用
21. Elasticsearch 数据预热
数据预热是通过主动触发特定操作,将数据加载到缓存或优化索引结构,以提升后续查询性能的技术。以下是核心方法与实践策略:
核心场景
- 冷启动优化:集群重启后,缓存未命中导致查询延迟高。
- 高频查询加速:针对热点数据提前加载到内存,减少磁盘I/O。
- Segment合并预热:减少查询时需加载的Segment数量,提升响应速度。
实现方案
-
缓存预热(Cache Preloading):
-
过滤器缓存:通过执行高频过滤查询(如
term或range),将结果缓存至节点查询缓存。GET /logs/_search?request_cache=true { "query": { "term": { "level": "error" } } } -
字段数据缓存:对聚合字段(如
keyword)执行预聚合,加载到fielddata。
-
-
Segment预热(Force Merge):
-
对静态历史索引执行强制合并,减少Segment数量,降低查询开销。
POST /logs-2025-01-01/_forcemerge?max_num_segments=1 -
适用条件:索引不再写入(如归档数据)(#)。
-
-
查询预热(Warmer Queries):
-
定义
_warmer,在索引刷新时自动执行预定义查询,填充缓存。PUT /logs/_warmer/frequent_errors { "query": { "term": { "level": "error" } } } -
注意事项:避免过度预热导致资源争用(#)。
-
-
冷热数据分离(Hot-Warm Architecture):
- 热节点:SSD存储,承载高频读写索引。
- 冷节点:HDD存储,存放历史数据,预热后迁移至热节点(#)。
性能影响评估
| 策略 | 适用场景 | 性能提升幅度 | 资源开销 |
|---|---|---|---|
| Force Merge | 静态历史数据 | 查询速度提升30%-50% | 高(CPU/IO密集型) |
| 缓存预热 | 高频过滤/聚合 | 延迟降低50%-70% | 中(内存占用) |
| 冷热分离 | 时序数据(如日志) | 查询吞吐量提升2-3倍 | 低(架构调整) |
22. ES 中的 Segments 和 Merge 操作及其对性能的影响
Segment 核心概念
- 定义:Segment是Lucene索引的最小单元,包含倒排索引、DocValues等文件。
- 特性:
- 不可变性:写入后不可修改,更新生成新Segment,删除标记为
.del文件。 - 并行查询:每个Segment独立加载,查询需合并所有Segment结果。
- 不可变性:写入后不可修改,更新生成新Segment,删除标记为
Merge 操作机制
- 自动合并(Background Merge):
- 触发条件:小Segment数量达到阈值(默认10个)或大小符合合并策略。
- 合并策略:
- Tiered Merge:分层合并,优先合并小Segment(默认策略)。
- Log Byte Size Merge:基于Segment大小合并(#)。
- 参数调优:
PUT /logs/_settings { "index.merge.policy.floor_segment": "100mb", // 最小合并大小 "index.merge.scheduler.max_thread_count": 2 // 并发线程数 }
- 参数调优:
- 手动合并(Force Merge):
- 应用场景:归档索引优化、减少Segment数量。
- 风险:合并大Segment可能导致IO和CPU峰值,需在业务低峰执行(#)。
性能影响分析
| 操作类型 | 对写入影响 | 对查询影响 | 资源消耗 |
|---|---|---|---|
| 自动合并 | 低(后台渐进式) | 长期降低查询延迟 | 中(周期性IO/CPU) |
| Force Merge | 高(阻塞写入) | 显著提升查询速度 | 高(集中式IO/CPU) |
优化实践
- 时间序索引合并:按时间范围合并Segment,提升范围查询效率(#)。
- 冷数据合并:对低频访问数据合并为大Segment,减少内存占用(#)。
23. 如何优化 ES 的查询性能?
分片与集群优化
-
分片策略:
- 分片数:单个分片20-40GB,总分片数=数据总量/30GB(#)。
- 路由优化:通过
routing将关联数据集中到同一分片,减少跨分片查询。
-
硬件与存储:
- SSD存储:提升DocValues读取速度(查询性能提升3-5倍)(#。
- 内存分配:堆内存≤32GB,剩余内存用于文件系统缓存(缓存索引文件)(#。
查询DSL优化
-
过滤器优先:
- 使用
filter上下文替代query,利用缓存且不计算得分。"query": { "bool": { "filter": [ { "range": { "price": { "gte": 1000 } } } ] } }
- 使用
-
避免深度分页:
- 使用
search_after替代from+size,复杂度从O(N)降至O(1)(#。
- 使用
-
字段选择性加载:
- 指定
_source过滤返回字段,减少网络传输。"_source": ["title", "price"]
- 指定
数据结构与映射优化
-
字段类型选择:
- 精确匹配字段设为
keyword,禁用text类型分词(#。 - 数值类型优先选择
integer或long,避免字符串转换。
- 精确匹配字段设为
-
禁用冗余特性:
- 关闭无需排序/聚合字段的
norms和doc_values。"properties": { "comment": { "type": "text", "norms": false } }
- 关闭无需排序/聚合字段的
缓存与预计算
-
查询缓存:
- 启用
request_cache=true缓存高频聚合结果。 - 分片级缓存:通过
index.requests.cache.enable配置(#。
- 启用
-
预聚合(Rollup):
- 创建定时任务生成预聚合索引,减少实时计算开销(#。
性能对比案例:
| 优化措施 | 查询延迟(优化前) | 查询延迟(优化后) |
|---|---|---|
| 分片路由+过滤器缓存 | 1200ms | 450ms |
| 字段选择性加载+预聚合 | 800ms | 200ms |
24. 如何在 ES 中实现多索引的联合查询?
多索引查询方法
-
通配符索引匹配:
- 查询所有以
logs-开头的索引:GET /logs-*/_search { "query": { "match_all": {} } }
- 查询所有以
-
别名(Alias)路由:
- 创建别名关联多个索引,统一查询入口:
POST /_aliases { "actions": [ { "add": { "index": "logs-2025-01", "alias": "current_logs" } }, { "add": { "index": "logs-2025-02", "alias": "current_logs" } } ] }
- 创建别名关联多个索引,统一查询入口:
查询时使用别名:json GET /current_logs/_search
- 跨索引聚合:
- 对多个索引执行聚合,要求字段类型一致:
GET /logs-2025-01,logs-2025-02/_search { "aggs": { "avg_price": { "avg": { "field": "price" } } } }
- 对多个索引执行聚合,要求字段类型一致:
性能优化建议
- 分片分布均匀性:确保跨索引查询的分片均匀分布在节点间,避免单点瓶颈。
- 字段一致性:不同索引的同名字段需保持相同类型和分词规则,防止聚合错误。
- 查询并行化:利用
preference参数分散查询到不同副本,提升吞吐量(#。
25. Elasticsearch 如何保证数据的一致性?
写入一致性模型
-
写操作一致性级别:
- quorum(默认):多数分片副本确认后返回成功。
- all:所有副本确认后返回,强一致但延迟高。
- one:主分片确认即返回,弱一致。
配置参数:
POST /logs/_doc/1?consistency=quorum { "message": "error" } -
主分片与副本同步:
- 写入流程:客户端→主分片→并行复制到副本→副本确认后响应(#。
- 故障恢复:主分片宕机时,副本自动晋升为新主分片,确保可用性。
读操作一致性
- 偏好主分片:通过
preference=_primary强制从主分片读取最新数据。 - 版本控制:使用
_version字段实现乐观锁,避免并发写入冲突。
事务日志(Translog)
- 持久化机制:所有写操作先记录到Translog,定期刷盘(Flush)生成Segment(#。
- 故障恢复:节点重启后通过重放Translog恢复未持久化数据。
最终一致性场景
- 刷新延迟:数据写入后需等待Refresh(默认1秒)才可搜索,期间副本可能滞后。
- 解决方案:对实时性要求高的场景,手动触发Refresh或使用
?refresh=true参数。
26. ES 中的向量查询及应用
向量搜索核心机制
-
向量字段映射:
- 定义
dense_vector类型字段,指定维度:"properties": { "image_vector": { "type": "dense_vector", "dims": 512 } }
- 定义
-
索引类型选择:
- HNSW(Hierarchical Navigable Small World) :高精度近似最近邻搜索,适合高维数据。
- IVF(Inverted File Index) :基于聚类的快速搜索,适合低维数据。
- PQ(Product Quantization) :压缩向量空间,内存占用低(#。
-
kNN查询:
- 使用
knn子句进行近似最近邻搜索:GET /images/_search { "knn": { "field": "image_vector", "query_vector": [0.12, 0.24, ..., 0.89], "k": 10, "num_candidates": 100 } }
- 使用
性能优化策略
-
内存优化:
- 使用
GRAPH_PQ索引类型,内存占用降低10倍,精度损失可控(#。 - 预加载向量数据到文件系统缓存,避免磁盘I/O(#。
- 使用
-
Segment合并:
- 减少Segment数量,提升向量索引加载效率(#。
-
查询参数调优:
- 调整
num_candidates平衡精度与速度(默认100,增大可提升召回率)。 - 使用
similarity参数指定距离计算方式(如余弦相似度)。
- 调整
应用场景
- 图像检索:通过ResNet等模型提取特征向量,搜索相似图片。
- 推荐系统:用户行为向量化,匹配相似商品或内容。
- 语义搜索:文本嵌入向量(如BERT),实现语义级匹配(#。
性能对比:
| 索引类型 | 内存占用 | 查询延迟(k=10) | 精度(Recall@10) |
|---|---|---|---|
| HNSW | 高 | 20ms | 98% |
| IVF_PQ | 低 | 50ms | 92% |
总结图谱

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)