大模型面试被问:大模型显存计算公式与优化
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
随着DeepSeek爆火,面试中也越来越高频出现,因此训练营也更新了DeepSeek系列技术的深入拆解。包括MLA、MTP、专家负载均衡、FP8混合精度训练,Dual-Pipe等关键技术,力求做到全网最硬核的解析~
AI 算法在服务器中运行时,一个常见问题“单张 GPU 能承载多少模型参数?”,该问题跟模型结构、引擎框架、驱动版本、GPU 硬件相关。
本文围绕大模型的训练/推理场景,介绍 Transformer 类模型的显存计算公式,帮助读者能更好的了解全局显存的组成以及如何优化显存。
文中涉及的主要问题:
- 如何有效估算一个模型加载后的显存值?
- 计算值与实际 GPU 中的最大值的差距可以有多大?
- 大模型切分策略是如何降低显存的?计算公式怎么构建?
- 优化显存的方法和常见的优化思路?
01模型显存内容分析
在模型训练/推理时,显存(显卡的全局内存)分配一部分是给 AI 框架,另一部分给了系统(底层驱动)。
总的显存消耗量可以通过 API 查询,比如在 NVIDIA-GPU 上通过 nvidia-smi 指令能够打印出各个进程的显存消耗量。
+---------------------------------------------------------------------------------------+| Processes: || GPU GI CI PID Type Process name GPU Memory || ID ID Usage ||=======================================================================================|| 1 N/A N/A 67321 C .../anaconda3/envs/py/bin/python 23646MiB || 1 N/A N/A 71612 C .../anaconda3/envs/py/bin/python 848MiB || 2 N/A N/A 67321 C .../anaconda3/envs/py/bin/python 25776MiB |+---------------------------------------------------------------------------------------+
其中系统层的显存消耗一般由驱动控制,用户不可控;框架侧的显存消耗用户可控,也是本文分析的重点。以 PyTorch 框架为例通过显存可视化工具,看一下训练过程中显存的消耗。
如下图是一个模型训练过程中已用显存的数值随时间的变化:
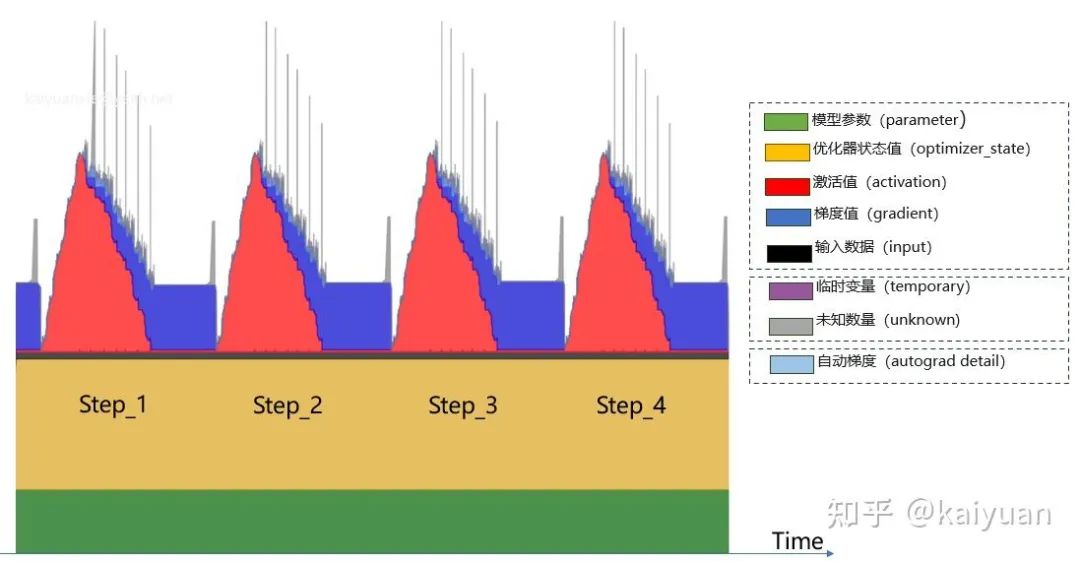
注意:数据是具体的消耗值,不等于 cudaMalloc 创建的显存值。
显存消耗的内容包括:
- 模型参数(parameter)
- 优化器状态值(optimizer_state)
- 激活值(activation)
- 梯度值(gradient)
- 输出数据(input)
- 临时变量(temporary)
- 自动梯度(autograd_detail)
- 未知数量(unknown)
从用户侧可以将这些数据进行一个分类:
- 可估算值: 模型参数(parameter)、优化器状态值(optimizer_state)、激活值(activation)、梯度值(gradient)、输出数据(input)
- 未命名数据: 临时变量(temporary)、未知数据(unknown)
- 其他(框架): 自动梯度(autograd_detail)
其中“未命名数据”来源可能是用户创建的一些临时变量,这些变量未参与图的计算过程,所以未被统计;或者是一些未被框架跟踪(tracing)到的数据。“自动梯度数据"是在反向传播求解梯度时产生的一些变量;
我们在显存计算时会发现“为什么有时显存估算值和实际测量值相差较大?”
其中一个可能的原因是:未知的数据太大。即显存中可估算值占比相对较小,其它不可估算值的数据占比较大,导致计算值和实际值差距较大( 误差可超过 30%),比如估算得到的显存消耗为 50GB,而实际测试达到了 75GB。
如下图是运行一个 LLM 模型采集的一些过程数据,可以看到 unknown 占比有时能达到 30%。
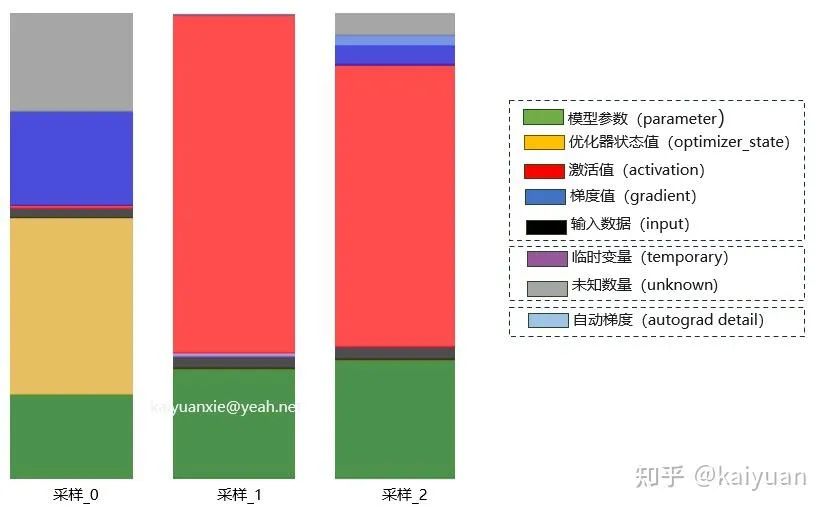
不同时刻显存的占比变化
02计算公式
2.1 训练场景
训练显存消耗(可估算部分)主要包括:模型参数(Model)+ 优化器状态(Optimizer status)+梯度值(Gradient)+激活值(Activation)。
根据数值的变化,可将显存消耗分为静态/动态值。训练过程中,模型参数、优化器状态一般不会变化,这两部分归属于静态值;激活值、梯度值会随着计算过程发生变化,将它们归类到动态值。
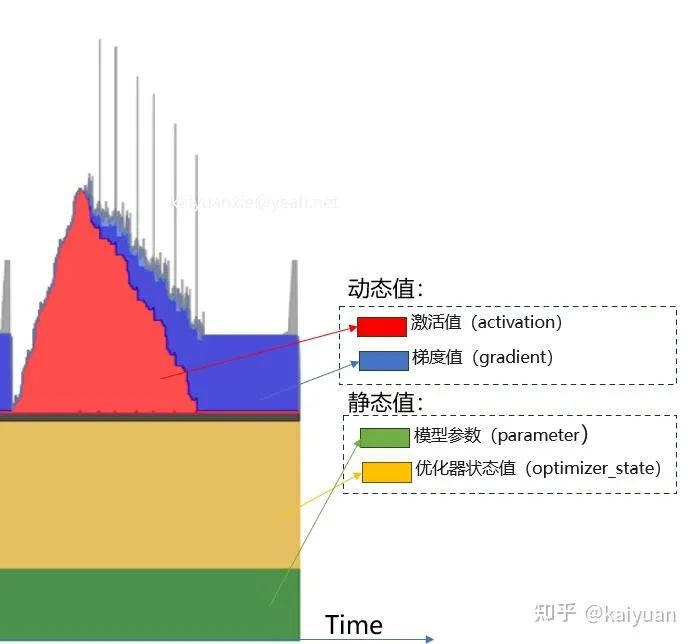
下面主要来看一下这四种类型值的估算方法:
2.1.1 模型显存(Model Memory)
模型自身所占用的显存大小与参数量、参数类型相关。常见类型 fp32、fp16/bf16、还有 int8、fp8 等。

关于模型保存的大小估算方法: 存储 checkpoint(ckpt)时仅考虑模型本身,只要将显存上模型内容存储到磁盘中。
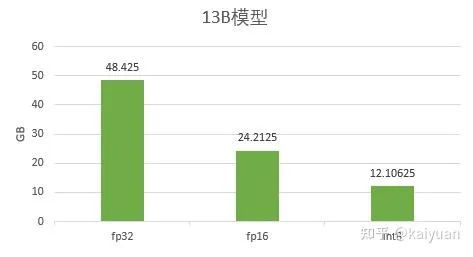
举例:以 1B(billion)模型为例,若采用 fp32 类型将其存储在磁盘上,其大小为:

1B 模型需要 3.725GB 存储空间,进一步近似认为 1B≈4GB,可方便作存储的估算推导,如 LLama13b,大约需要 52GB 存储空间。
注意:混合精度(Mixed-precision)最后存储的类型也是 fp32,公式也适合混合精度。
2.1.2 优化器状态(Optimizer status)
在 LLM 中常见的优化器是 Adam,优化器中每个参数需要一个 Momentum 和一个 Variance 状态参数,在混合精度训练中 Adam 还有一份模型参数副本。
Adam 参数器状态值计算公式(单位 GB):
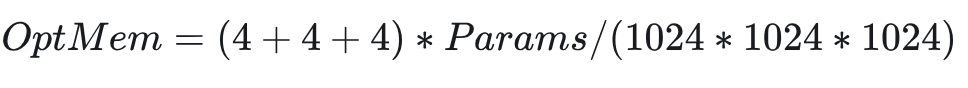
其中(4+4+4)的内容:
- 模型副本 4 Bytes
- Momentum 参数 4 Bytes
- Variance 参数 4 Bytes
- 如果是 8 位优化器,则计算变为:
- 模型副本 4 Bytes
- Momentum 参数 1Byte
- Variance 参数 1Byte
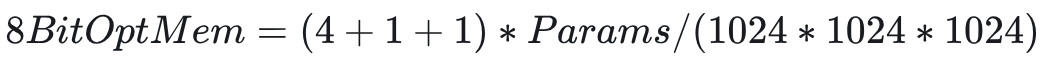
2.1.3 梯度值(Gradient)
梯度值与模型数据类型保持一致,计算如下(单位 GB):
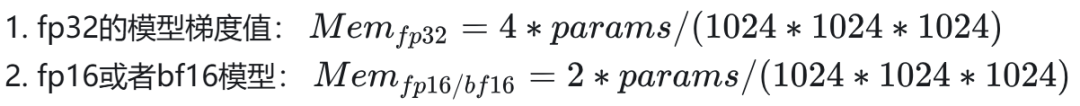
2.1.4 激活值(Activation)
激活值的大小跟模型参数、重计算、并行策略等相关,这里我们参考 Megtron 论文里面给的计算公式,来求解激活值所占用的显存大小。

2.2 训练的并行计算公式
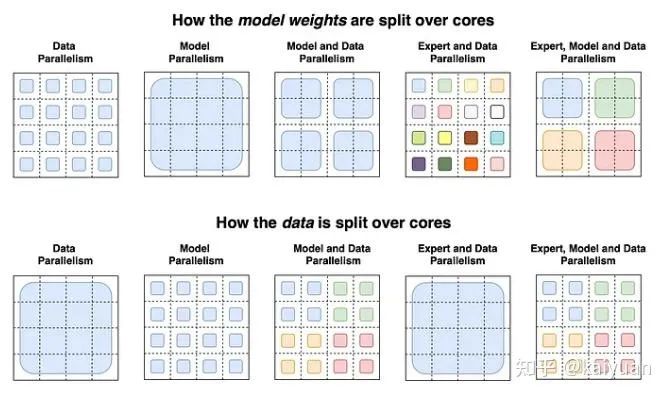
目前,单卡的物理显存基本不能满足大模型的训练需求,一般会采用模型并行方式来降低单卡显存消耗。
常见的几种方法:TP/SP/PP/Zero/重计算,这些方法出现在 DeepSpeed、Megtron 等并行框架中,目标都是让 GPU 能够装下更大的模型。
其中:
- TP(TensorParallel): tensor 并行;
- SP(SequenceParallel): 序列并行;
- PP(PipelineParallel): pipeline 并行;
- Zero: 参数服务器,分为 Zero1/2/3,最早出现在 deepspeed 中
当没有并行策略时,仅模型本身的显存需求(单卡)计算如下:
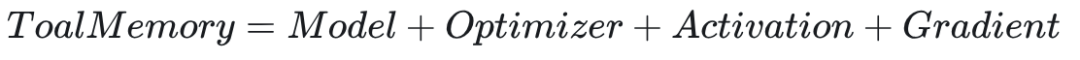
经过并行策略的调整,显存需求可变为(举例,PP/TP/zero1):
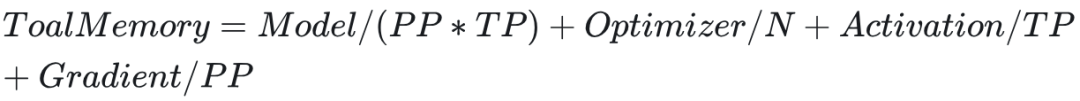
2.3.1 3D 并行
3D 并行主要是 TP(SP)/PP/DP,其中 DP 为数据并行主要用于提升 bs(batch size),DP 不降低单卡的显存消耗,但 TP(SP)/PP/DP 存在一个耦合关系,DP 的设置一般满足:
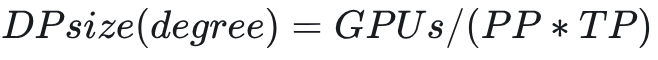
而 TP(SP)/PP 可降低模型、激活值、梯度的显存占用大小。
3D 并行对显存计算的影响计算:
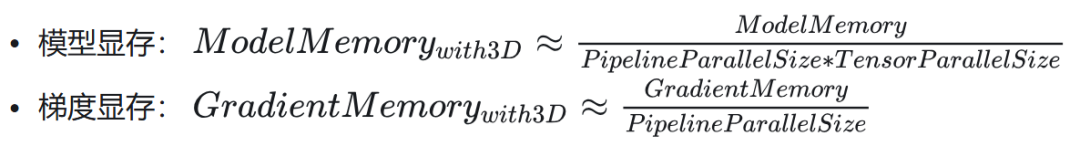
注意:梯度显存没有除以 TP,主要是考虑到反向计算时需要 AllGather 出完整 gradient。
3D 对激活值显存的消耗改变需要结合重计算公式进一步分析。另一个问题,当前比较流行的 MoE 方式也会改变模型的参数分布进而改变计算。
但认为 MoE 构造的是多个小模型,改变的是模型的结构,这里计算暂不展开。
考虑MoE时参数的变化
2.3.2 重计算(Recomputation)
一般而言,我们会把前向计算中的中间数据保存下来用于反向计算,从而避免反复计算。
而重计算是指为了降低显存消耗先丢弃一些前向计算结果,在反向传播时再重新计算得到。
结合论文[Reducing Activation Recomputation in Large Transformer Models]里面给的计算公式,激活值所占用的显存的计算公式如下:

单位 GB,参数说明:
- s 序列长度(sequence length),tokens 的量
- b 微批量大小(microbatch size)
- h 隐藏层大小(hidden dimension size)
- a attention 的头数 (number of attention heads)
- t tensor 并行数值(tensor parallel size)
- L transformer 模型的层数
- λ 比例系数,当为 fp16 时,值等于 1 /(1024 * 1024 * 1024)
假设我们选用 Tensor 和序列并行、不开重计算,则单卡的公式变为:
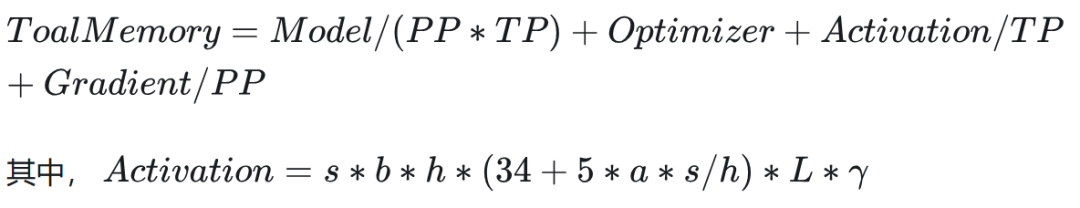
2.3.4 Zero 方法
Zero 方法对显存的优化和原理参考其论文[https://arxiv.org/abs/1910.02054],其中包含了三种策略,对显存降低的效果不一样。
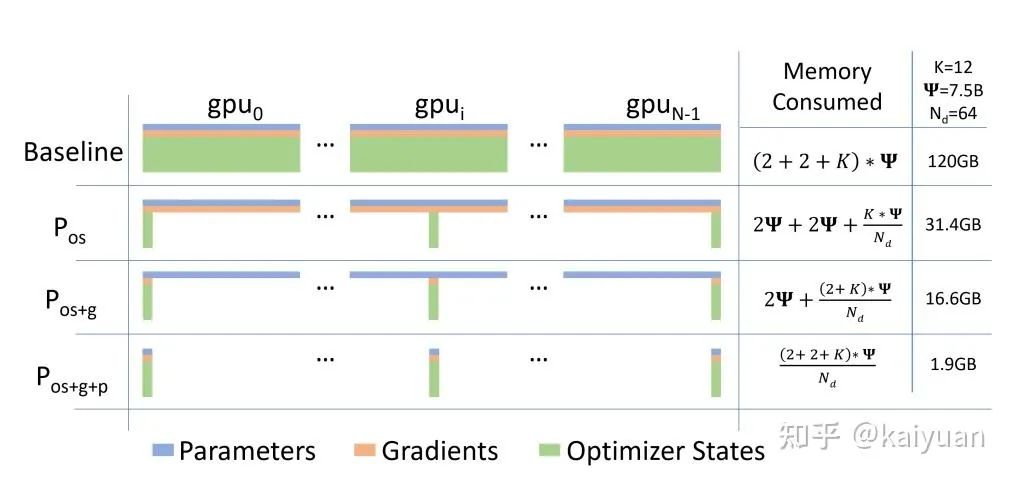
zero策略下显存消耗的计算变化
假设不考虑 3D 并行和重计算,开启 Zero 的计算公式为:

其中 N 是 GPU 的数量;LiveParams 是 Zero3 引入的参数,这些参数用于控制模型中哪些参数需要加载在 GPU 中,本身的显存占用不可忽视。
2.3.5 训练的综合计算列举
当条件确定好后,我们可将上述的公式综合起来求解总的显存消耗。通过一个具体的示例来说明。
假设相关的运算条件:
- 采用混合精度训练
- 开启 TP/SP/PP
- 不开重计算
- 开启 Zero2
混合精度的单层的数据配置一般如下图所示,需要注意的是 master weights 只要算一次,要么在优化器中计算要么在模型中计算,这里默认在优化器中考虑。
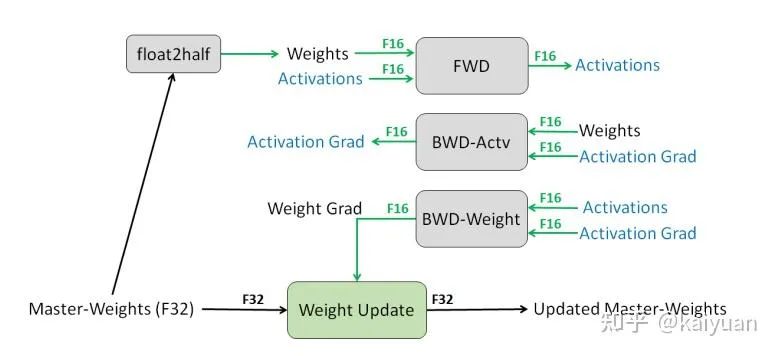
混合精度数值类型
计算公式如下(单位 GB):
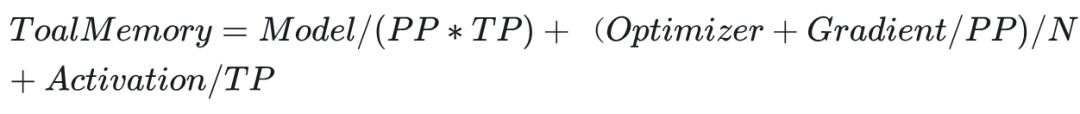
其中:

相关参数说明:
- params:模型参数
- N:GPU 数量
- PP:pipeline 并行数值
- TP:Tensor + 序列并行数值
- s 序列长度(sequence length),tokens 的量
- b 微批量大小(microbatch size)
- h 隐藏层大小(hidden dimension size)
- a attention 的头数(number of attention heads)
- t tensor 并行数值(tensor parallel size)
- L transformer 模型的层数
注意:公式计算得到是一个估算值,且只考虑了模型部分,实际运行中的总数还需要考虑框架、分布式通信库、环境变量、算法产生副本数据。
2.3 推理场景
推理的显存量组成成分比训练简单,有一个简单的估算公式:
总显存占用:
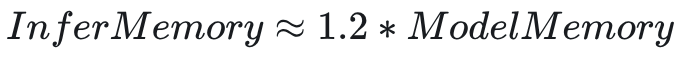
相关内容可参看这篇 blog:Transformer Inference Arithmetic | kipply’s blog。
总之,通过综合求解公式可以知道模型显存消耗主要部分,能帮助我们确定显存的优化的策略。
03
显存优化
由于大模型的参数成倍数的增长,远超出了单 GPU 物理显存所能承载的范围,大模型训练必然需要进行显存优化。
显存优化要么是优化算法本身,降低模型算法的显存消耗;要么是去扩大显存,通过一些置换方式获得“额外“空间,由于显存物理大小一定,我们获得额外空间的方式不外乎两种:
- 时间换空间;如,重计算
- 空间转移;如,多卡并行/offload
其中,时间换空间通常会消耗算力、带宽;空间转移主要是消耗 I/O 带宽,有一定的时延,可能会降低吞吐**。**
显存优化的过程一般是从模型算法本身到底层,可以参考的优化路径:
*多卡并行 -> 算子/数据类型 -> 消除框架副本 -> 显存管理 -> 底层 API*
1、*多卡并行***:**该手段相对来说是使用频率最高,且一般不会影响运算的精度,可以用 2 节中的计算公式为参考去设计新的 TP/PP/DP/Zero/重计算的相关参数来降低显存消耗。缺点:这些方式可能会增加额外的带宽消耗。
2、*算子优化***:**选取精度相同但显存消耗更低的算子/方案。缺点:一般情况下,算子优化的过程耗时较长。
3、*数据类型修改***:**用低精度替换高精度数据。比如用 fp16 代替 fp32,或者用更低的 int8/int4。缺点:该方式可能影响训练收敛性/推理性能。
**4、消除框架副本:**在 AI 框架(如 pytorch)中有些数据是一些由框架产生的中间副本,可以进行优化消除;缺点:游湖成本较大。
**5、显存管理:**通过显存管理的知识可知[PyTorch 显存管理],框架的显存管理会产生显存碎片,通过优化显存管理来优化碎片;缺点:目前可用的手段较少。
6、底层 API: 在 GPU 的驱动库中/CUDA 算子库中,不同 API 显存消耗不一样,我们可以用显存消耗更小算子去替换大显存消耗算子,比如FlashAttention;
有些默认的操作会产生额外系统显存,也可以考虑替换更高版本优化后的 API。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。


三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献603条内容
已为社区贡献603条内容

所有评论(0)