第六篇--Nature正刊 IF=48.5 | Delphi-2M:重新定义疾病预测和健康管理
Nature重磅研究:Delphi-2M模型革新疾病预测与健康管理 德国癌症研究中心等团队在《Nature》发表突破性研究,提出基于生成性变换器的Delphi-2M模型。该模型通过分析英国生物库和丹麦登记数据(覆盖230万+人群),能预测1000+种疾病的发展轨迹,并生成个性化20年健康预测。研究亮点包括: 首创时间依赖性建模,捕捉疾病间动态关联 跨人群验证显示卓越预测准确性(AUC值显著提升)
Nature正刊 IF=48.5| Delphi-2M:重新定义疾病预测和健康管理
引言
在人工智能,特别是在健康领域的最新进展中,出现了一种新的方法:利用大型语言模型(LLM)跟踪和预测个人一生中的疾病轨迹。这一方法在改善个性化医疗方面具有巨大潜力。最近,Nature期刊发表了一篇具有开创性的研究论文,标题为“A Transformer Model for Health Records”,介绍了Delphi-2M模型,该模型能够预测多种疾病的发生率,并通过分析英国生物库和丹麦登记数据,预测健康轨迹的进展。
基本信息
- 文章标题:Learning the natural history of human disease with generative transformers
- 期刊:Nature
- 影响因子:58.7
- 发表时间:2025年9月17日
- 研究单位:德国癌症研究中心、欧洲分子生物学实验室、诺和诺德基金会、哥本哈根大学
- 研究重点:健康轨迹建模、疾病预测和多病共存预示
- Github地址:https://github.com/gerstung-lab/delphi
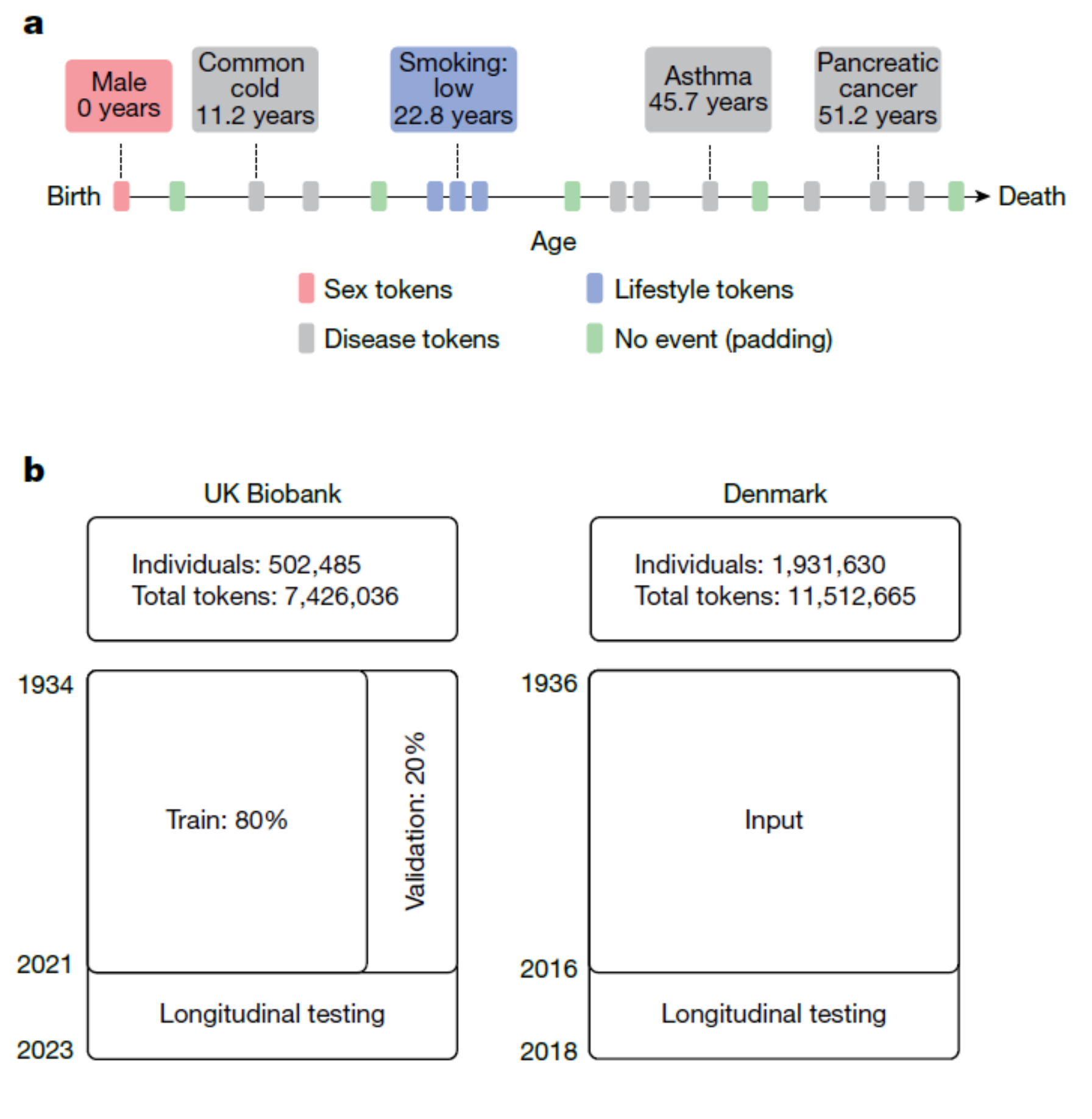
- 数据集:包括英国生物库(UK Biobank)和丹麦疾病登记数据。训练数据来源于402,799名参与者的数据,验证数据包括100,639名参与者的数据;此外,研究还进行了丹麦数据集的外部验证(共计1.93百万丹麦人数据)
创新点总结:
生成性变换器模型:提出了Delphi-2M,能够预测超过1000种疾病的进展,结合个人健康数据(如病史、生活方式等)进行多病共存建模。
时间依赖性建模:模型捕捉疾病之间的时间性依赖,能够预测个体未来健康状态,并为疾病预防和干预提供早期预测。
生成健康轨迹:Delphi-2M不仅预测疾病发生,还能生成个性化的健康轨迹,提供未来20年的健康路径预测。
跨人群验证:通过UK Biobank和丹麦疾病登记数据验证,展示了模型的广泛适应性。
可解释性与公平性:采用可解释AI方法,揭示疾病间的共病模式,同时评估模型的公平性和偏差,确保不同群体的应用效果。
一、研究背景与意义
随着慢性病和多病共存问题的加剧,传统的疾病预测和健康管理方法难以应对复杂的健康数据,特别是在长期健康变化的监测和个性化预防方面。现有的疾病预测模型通常只聚焦于单一疾病,忽略了疾病之间的相互影响及其时间性进展。
Delphi-2M模型采用生成性变换器(GPT)技术,能够整合健康记录、生活方式和人口统计数据,预测多种疾病的发生,并生成个性化的健康轨迹。这不仅提高了疾病预测的准确性,也为个体提供了长期的健康规划和预防措施。
该研究的意义在于,Delphi-2M能够全面预测多种疾病并理解疾病之间的相互关系,推动精准医疗的发展,实现个性化健康管理。通过捕捉疾病的时间性进展,模型为长期健康评估提供了新视角,并展示了在不同地区的广泛适用性,能够为全球公共卫生决策提供支持。
二、研究内容与方法
本研究的核心在于提出和训练Delphi-2M模型,这是一种基于生成性预训练变换器(GPT)的架构,用于预测人类疾病的多维进展。为了构建这一模型,研究者使用了来自UK Biobank和丹麦疾病登记的健康数据集,这些数据涵盖了大规模的人群和多种疾病事件。以下是研究内容与方法的主要步骤和技术细节:
【此处插入2张图片】
-
数据来源与处理
- UK Biobank**数据集包括来自502,485名个体的健康数据,共计7,426,036个token,其中80%的数据用于训练,20%用于验证。丹麦疾病登记数据集则包含1,931,630名个体的健康记录,数据总量为11,512,665个token。训练数据涵盖了多种疾病诊断信息、生活方式因素(如吸烟、饮酒)和人口统计学信息(如性别、体重指数等)。
- 数据处理时,研究者将每个个体的健康轨迹表示为时间序列,每个时间点的健康状态通过token进行编码,token包括疾病类型、性别、生活方式因素以及“无事件”填充数据。
-
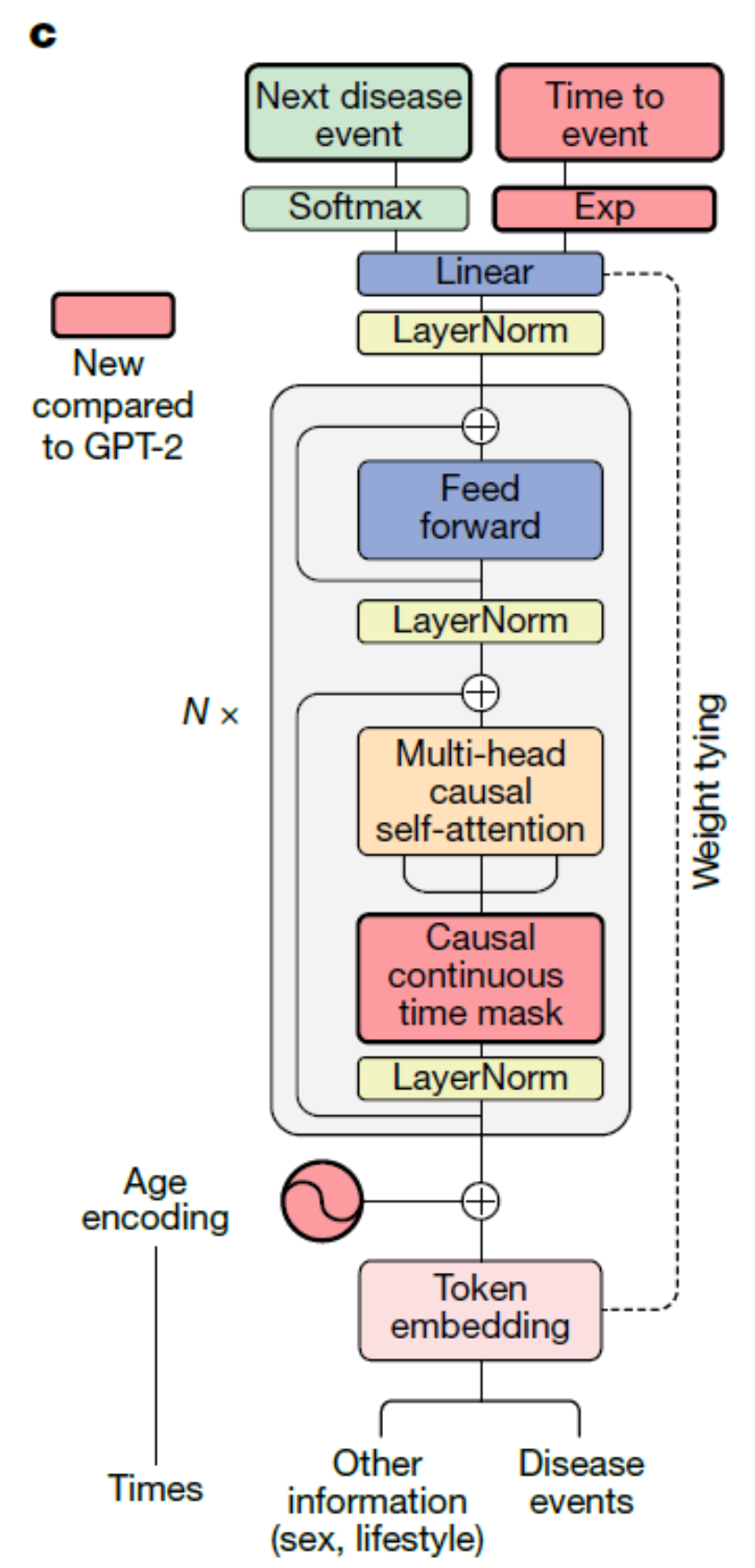
Delphi-2M模型架构
-
Delphi-2M在GPT-2的基础上进行了扩展,加入了针对健康数据的特定设计。例如,模型通过年龄编码将个体的健康轨迹与其年龄相关联,以便更好地捕捉疾病的时间性进展。此外,Delphi-2M还引入了因果连续时间掩码和多头因果自注意力机制,以便模型在预测时只关注历史数据,而不受未来数据的影响。
-
研究还对Delphi-2M与基本GPT模型(如NanoGPT-2M)的表现进行了比较。实验结果显示,Delphi-2M在捕捉年龄、性别和疾病信息的交叉熵上表现优异,能够有效减少训练过程中的误差。
-
-
模型优化与评估
- 研究者通过系统的超参数调优来优化Delphi-2M模型的结构,包括选择合适的模型大小和训练数据的比例。在训练过程中,通过调整模型参数并使用交叉熵损失函数,Delphi-2M成功实现了在不同年龄段的准确预测。图e显示了随着模型参数量的增加,验证损失逐渐降低,表明更大的模型能够更好地拟合训练数据。
- 在模型评估中,Delphi-2M表现出了较高的准确性,尤其是在预测疾病发生的时间(如下一个疾病事件的发生时间)。图g显示了Delphi-2M预测的预期天数与实际观测天数之间的良好拟合,表明模型能准确捕捉疾病进展的时序关系。

三、实验结果分析
1. Delphi-2M在疾病预测中的准确性与时序性
以下图表展示了Delphi-2M模型在疾病预测任务中的表现。通过疾病发生率(图a)和AUC(图b)两个指标,比较了Delphi-2M与其他模型在多个数据集上的效果。图表按疾病类型分为不同类别,包括败血症(A41)、糖尿病(E10)、抑郁症(F32)以及死亡预测任务(Death)。


-
疾病发生率预测:在多种疾病的预测中,Delphi-2M(紫色)在大多数任务中表现出色,特别是在急性心肌梗死(I21)、胰腺癌(C25)和乳腺癌(C50)等任务中,模型能够准确预测疾病发生的早期并捕捉到疾病的快速进展。相比于其他模型,Delphi-2M展示了更强的跨时间预测能力,特别是在疾病发生前的预测表现尤为突出。
-
AUC(分类准确性):在不同疾病类别的预测中,Delphi-2M展现出更高的AUC值,特别是在涉及多种疾病和死亡预测的任务中,Delphi-2M表现明显优于传统模型,如CLIP和BioMedCLIP。例如,在死亡预测任务中,Delphi-2M能够准确地预测死亡事件的发生时间,并显著提高了分类的准确性。
2. 模拟结果与真实数据的对比:Delphi-2M在疾病预测中的时效性与准确性
图a至图f展示了Delphi-2M模型在模拟疾病预测过程中与真实数据之间的对比。通过模拟健康数据轨迹并与实际观察结果进行比较,研究者评估了模型在长期模拟中的表现。
- 疾病发生率的模拟与真实数据对比(图a、图b):Delphi-2M模型在模拟疾病发生率时,能够很好地拟合实际观察到的健康轨迹,特别是在70至75岁期间的疾病发生率(图b)。通过模拟60岁以后发生的疾病率,模型展示了出色的时效性与准确性,能够捕捉到疾病发展的趋势,并与真实数据保持一致。
- 预测准确性的比较(图c):Delphi-2M与仅使用年龄和性别作为预测因子的模型相比,表现出更高的预测准确性。随着模拟年限的增加,Delphi-2M在正确预测疾病事件上的比例逐渐提高,证明其在多年的疾病进展预测中具备较强的泛化能力。
- 多因素对疾病预测的影响(图d、图e):在模拟吸烟、饮酒和BMI等生活方式因素后,Delphi-2M能够有效地捕捉这些因素与疾病发生的关系,并与真实数据中的健康变化(如吸烟、BMI变化对疾病发生率的影响)保持一致。尤其在模拟的高低风险组对比中,模型的预测与实际观测结果接近,展示了其在复杂因素下的强大建模能力。
- AUC与训练数据的关系(图f):通过对比使用UK Biobank数据和模拟数据进行训练后,Delphi-2M模型的AUC值在模拟数据上验证时较高,表明模型不仅能从真实数据中学习,还能有效地将这些学习应用于模拟数据中,从而提高了模型的泛化能力。
3. 关键因素对疾病预测的影响:特征重要性与生存率变化
图a至图d展示了Delphi-2M模型在不同疾病的特征重要性评估以及疾病发生后死亡率的变化。通过分析不同疾病类型和相关特征的影响,研究者进一步揭示了模型在预测过程中所依据的关键因素。


- 相对风险与基线率(图b):通过分析相对风险(relative rate),研究揭示了各个疾病的相对危险度,进一步分析了特定疾病(如胰腺癌、糖尿病)与其基线发病率的关系。Delphi-2M能够有效区分高风险与低风险疾病,为后续的疾病筛查和个性化治疗提供支持。
- 特征重要性评估(图c):通过SHAP值(图c),Delphi-2M能够清晰地显示出不同特征对疾病预测的影响。图c展示了疾病相关的ICD-10分类与预测的疾病发生率之间的关系。不同颜色的方块代表了不同类型的疾病,如新生物(Neoplasms)和循环系统疾病(Circulatory diseases),这些疾病类别的变化对疾病预测的贡献较大,且不同疾病类型的特征重要性差异明显。预测过程中,模型将更注重与疾病进展相关的时间性因素,如疾病发生的年龄段。
- 疾病发生后死亡率的变化(图d):图d显示了不同疾病在诊断后的死亡率变化,如胰腺癌(C25)和败血症(A41)。对于胰腺癌,模型预测在诊断后死亡率的变化呈现出较为平稳的趋势;而对于败血症,死亡率的增加则相对较快,这说明不同疾病的预后具有显著差异,且这些差异在模型的生存率预测中得到了有效反映。

4. 数据来源对疾病预测模型性能的影响

图a至图g展示了Delphi-2M模型在不同数据来源下的表现,强调了数据源在疾病预测中的作用。模型在UK Biobank和丹麦数据集上的AUC值高度一致,证明其在不同数据集中的泛化能力。尽管模型在80岁以上的死亡率预测上表现较弱,但在较低年龄段的疾病预测中能够有效捕捉死亡率和疾病发生的趋势。医院记录在疾病预测中占主导地位,尤其在死亡记录和心血管疾病方面,而自报告数据和初级保健数据则在长期疾病预测中提供了有力支持。不同疾病与数据源的关联性也有所不同,如新生物在医院记录中表现较好,而呼吸系统疾病则在初级保健数据中更为突出。通过SHAP值分析,发现Delphi-2M主要依赖医院记录和死亡记录,高质量的医院数据显著提高了预测的准确性。
四、优势与局限
优势
- 高准确性:Delphi-2M在多种疾病预测中表现出了高准确性,能够捕捉到疾病的时间依赖性和长期健康变化。
- 跨数据源泛化:模型在多个数据集(如UK Biobank和丹麦数据)上表现一致,展示了强大的跨数据源泛化能力。
- 多疾病预测:能同时预测1000多种疾病,并处理多病共存的复杂情形。
- 个性化健康预测:通过模拟个体的健康轨迹,为个性化医疗决策提供支持,具有高应用潜力。
局限
- 数据依赖性强:模型的表现高度依赖于高质量的健康数据,尤其是医院记录和死亡数据。
- 处理缺失数据的能力有限:在处理缺失数据时,模型的预测准确性可能降低。
- 局限于现有疾病编码:基于ICD-10编码的疾病分类可能限制了模型对一些新兴疾病或未充分分类疾病的预测能力。
- 长时间预测不够稳定:在模拟80岁以上人群的死亡率时,模型在数据不足的情况下表现不如预期。
参考文献
1.Attention is All You Need Vaswani et al., 2017: 这篇论文提出了Transformer模型,成为了后续生成模型(如GPT和BERT)的基础架构。Delphi-2M模型在此基础上进行扩展,应用了生成性预训练变换器(GPT)架构,用于多种疾病的预测和健康轨迹建模,是理解该模型架构的关键背景文献。
2.Language Models are Few-Shot Learners Brown et al., 2020:本文提出了GPT-3,展示了大规模语言模型在处理少量样本学习任务中的强大能力。Delphi-2M基于这一框架,结合了健康数据的生成性建模,推动了在医疗健康领域的应用,特别是在疾病预测任务中的表现。
3.Med-BERT: Pretrained Contextualized Embeddings on Large-Scale Structured Electronic Health Records for Disease Prediction Rasmy et al., 2021:Med-BERT是针对电子健康记录(EHR)的BERT变体,旨在通过大规模预训练模型提升疾病预测准确性。Delphi-2M借鉴了此类方法,并在多个疾病预测任务中进行了优化,尤其是在疾病时间性进展建模中。
4.TransformEHR: Transformer-Based Encoder-Decoder Generative Model to Enhance Prediction of Disease Outcomes Using Electronic Health Records Li et al., 2020:本文提出的TransformEHR模型利用变换器架构来增强疾病结局预测。Delphi-2M扩展了这一思想,将其应用于更广泛的疾病预测任务,并整合了多个数据来源,以提高模型的泛化能力和预测精度。
5.A Deep Learning Algorithm to Predict Risk of Pancreatic Cancer from Disease Trajectories Placido et al., 2023:这篇论文提出了一种基于深度学习的算法,能够根据疾病轨迹预测胰腺癌的风险。Delphi-2M采用类似的疾病轨迹建模方法,并通过跨疾病类别的联合学习进一步优化了疾病预测任务。
6.BEHRT: Transformer for Electronic Health Records Yang et al., 2023:BEHRT是专为电子健康记录设计的变换器模型,通过对健康数据的预训练,显著提升了多种疾病的预测能力。Delphi-2M在此模型基础上进一步优化了对多种疾病的预测,尤其是在模拟健康轨迹和跨疾病预测方面表现突出。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 34
34 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)