行为基础模型:面向下一代人形机器人的全身控制系统(上)
25年6月来自香港理工、逐际动力、宁波数字孪生研究院、香港大学和瑞士 EPFL 的论文“Behavior Foundation Model: Towards Next-Generation Whole-Body Control System of Humanoid Robots”。人形机器人作为用于复杂运动控制、人机交互和通用物理智能的多功能平台,正备受关注。然而,由于复杂的动力学、欠驱动和多样化
25年6月来自香港理工、逐际动力、宁波数字孪生研究院、香港大学和瑞士 EPFL 的论文“Behavior Foundation Model: Towards Next-Generation Whole-Body Control System of Humanoid Robots”。
人形机器人作为用于复杂运动控制、人机交互和通用物理智能的多功能平台,正备受关注。然而,由于复杂的动力学、欠驱动和多样化的任务要求,实现人形机器人高效的全身控制 (WBC) 仍然是一项根本性挑战。虽然基于学习的控制器已显示出处理复杂任务的潜力,但它们依赖于针对新场景的劳动密集型且昂贵的再训练,限制了其在现实世界中的适用性。为了解决这些限制,行为基础模型 (BFM) 作为一种新范式应运而生,它利用大规模预训练来学习可重用的原始技能和行为先验,从而实现零样本或快速适应各种下游任务。本文全面概述用于人形 WBC 的 BFM,并追踪了它们在各种预训练流程中的开发。此外,讨论现实世界的应用、当前的局限性、紧迫的挑战和未来的机遇,将 BFM 定位为实现可扩展和通用人形机器人智能的关键方法。
人形机器人因其类人形态和高自由度 (DoF) 而日益被开发并应用于各种现实场景。这些特性使其能够在最初为人类设计的环境中无缝运行,灵活地执行运动、操控和交互任务。然而,人形机器人必须在复杂条件下协调全身运动,例如驱动不足、频繁的接触变化以及任务目标的动态变化,同时保持平衡和安全。这对充分发挥人形机器人的潜力提出了重大挑战。
传统的基于模型控制器
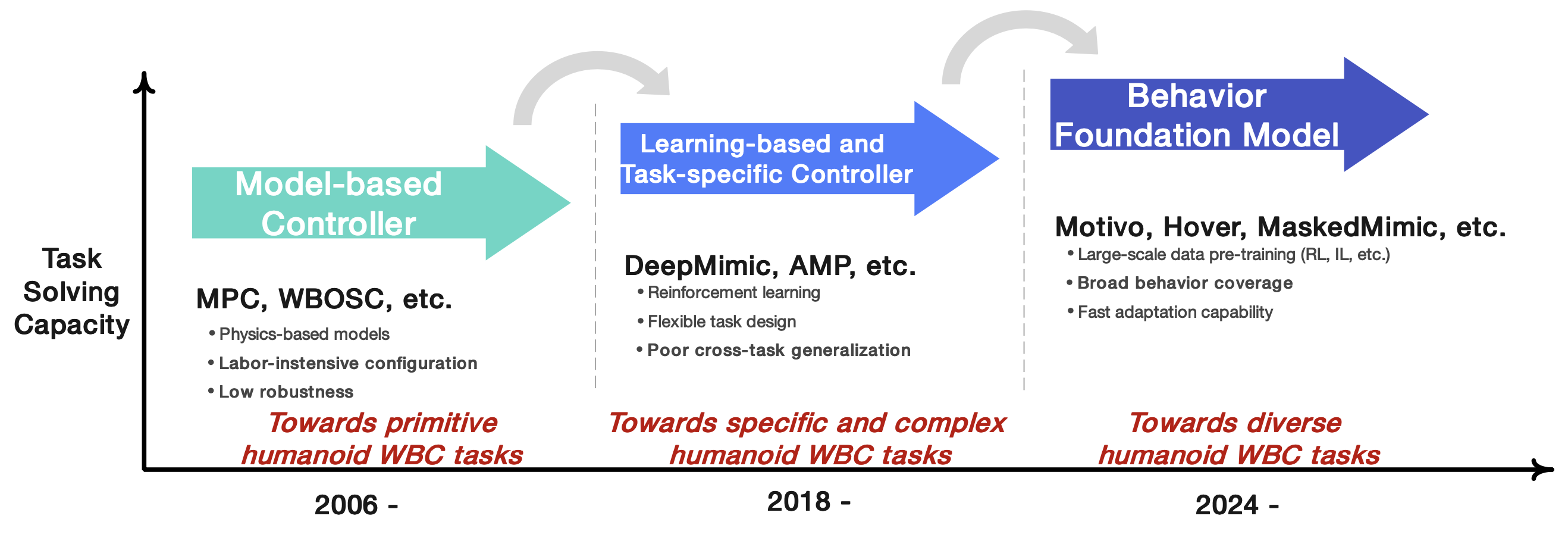
传统的 WBC 方法一直是早期人形机器人运动和操控的基石 [1, 2]。这些方法严重依赖基于物理的模型,通常采用预测-反应式层次结构:高级规划器(如质心模型预测控制 (MPC) [3, 4])生成参考轨迹,而低级任务空间全身控制器解决最优控制问题 (OCP) [5],以在动态约束下跟踪这些目标。例如,操作空间控制 [6] 和分层任务控制 [7] 建立了理论基础,而 [8] 则推进了分层二次多项式规划 (QP) 求解器,并实现了平衡、行走和操作等多任务场景的实时性能。此类框架已广泛应用于人形机器人,如 Atlas [9]、HRP-2 [10] 和 DLR 的扭矩控制机器人 [11],实现了鲁棒的运动和多接触交互。
尽管取得了成功,传统的 WBC 系统仍面临着严重的局限性:(i)针对复杂行为(例如,不平坦的地形或动态转换)的任务设计、增益调整和启发式调整仍然劳动密集且脆弱,(ii)实时 MPC 难以处理高维系统,通常需要进行简化,而这会牺牲动态保真度 [12],(iii)缺乏执行高动态技能(例如,后空翻或快速接触切换)或适应不可预见干扰的灵活性 [13],以及(iv)鲁棒性弱,因为即使是很小的推力也可能使带有基于模型步行控制器的机器人翻倒。这些挑战对于人形机器人来说尤其重要,因为其任务通常需要丰富的协调、接触推理和态势觉察[14,15]。因此,最近的研究越来越多地转向数据驱动的方法,旨在从演示或强化学习中学习运动技能、协调策略和行为先验[16,17]。
基于学习和特定任务的控制器
基于学习的方法,尤其是强化学习 (RL) 和模仿学习 (IL),已成为传统 WBC 方法的有前途的替代方案,使机器人能够通过环境交互或人类演示获得复杂的技能 [18–23]。例如,[16] 提出了一个名为 DeepMimic 的框架,该框架将深度强化学习与动作捕捉数据相结合,使物理模拟角色能够学习动态技能,同时保持自然的运动质量。[24] 通过引入对抗性运动先验 (AMP) 进一步扩展了 DeepMimic,从而在保持物理真实感的同时,实现了更具风格化和多样性的角色控制。相比之下,[25] 提出 HoST,这是一个基于强化学习的框架,用于从零开始学习类人机器人的站立控制,并在不同的实验室和室外环境中实现自适应且稳定的站立动作,突显强化学习在特定任务中卓越的学习能力和鲁棒性。
对于基于 IL 的方法,[26] 提出 TRILL,它将虚拟现实 (VR) 遥操作与 WBC 相结合,用于类人机器人的移动操控,在现实世界的双手任务中表现出 85% 的成功率 [27]。此外,[28] 开发一个富有表现力的 WBC 框架,将上半身 IL(用于风格化运动)与稳健的下半身运动分离,使类人机器人能够在执行各种动作时动态调整步态。这种方法克服了由于人与机器人形态不匹配而导致的全身模仿不稳定性。虽然基于学习的方法在各种类人 WBC 任务中表现出显著的成功,但它们面临着限制其更广泛适用性的根本性挑战。
基于 RL 的方法存在样本效率低下的问题,通常需要数百万次环境交互才能收敛,同时对奖励函数设计高度敏感——形状不良的奖励可能导致非预期行为或局部最优 [29]。此外,模拟-到-现实 (Sim2Real) 之间的差距,加剧了这些限制,因为在模拟中训练的策略在面对现实世界的动态、传感器噪声和硬件缺陷时常常会退化 [30–33]。
相比之下,基于 IL 的方法样本效率更高,但对数据收集构成了重大挑战,并且学习的策略通常会继承演示者的偏见和局限性 [34–38]。此外,这两种范式都难以实现泛化,其中学习到的策略通常只擅长于狭窄的任务,并且无法在没有大量再训练的情况下适应新场景。这些挑战共同强调了将学习的灵活性与结构化先验相结合的方法的必要性,以实现鲁棒性和泛化性——行为基础模型旨在弥合这一差距。
行为基础模型
“行为基础模型 (BFM)”这一术语首次出现在 [39] 中,该模型提出了一个基于继承者度量的框架,用于训练能够从极简演示中即时模仿各种行为的通才策略。该模型表明,在无监督交互数据上预训练的 BFM,有望通过前向-后向状态特征匹配来解决模仿任务,从而消除特定任务的强化学习微调,同时通过统一的表示支持多种 IL 范式,例如行为克隆、奖励推理和分布匹配。后续研究 [40– 44] 将 BFM 确立为一类能够在无奖励转换上进行无监督训练的强化学习智体,同时无需额外的学习或规划,即可在测试时为广泛的奖励函数类别提供近似最优策略。
本文将 BFM 的定义扩展为一类专门的基础模型 [45],旨在控制动态环境中的智体行为。 BFM 植根于通用基础模型(例如 GPT- 4 [46]、CLIP [47] 和 SAM [48])的原理,这些模型利用基于大规模静态数据的广泛自监督预训练,通常使用大量行为数据(例如轨迹、人类演示或智体与环境的交互)进行训练,从而对一系列全面的行为进行编码,而不是狭隘地专注于单任务场景。此特性确保模型能够轻松地跨不同任务、情境或环境进行泛化,展现出多功能且自适应的行为生成能力。视觉-语言-动作 (VLA) 模型 [47, 49–51] 的最新进展专注于整合视觉、语言和动作来处理多模态任务,并在动态环境中表现出色,能够基于视觉和语言输入生成上下文觉察的响应。相比之下,BFM 主要用于直接控制智体行为,例如运动、操纵和交互。此外,大多数现有的 VLA 模型适用于相对稳定的平台,例如机械臂或轮式人形机器人 [52],而 BFM 则是为了处理类人机器人复杂的 WBC 而开发的。
BFM 如图所示:
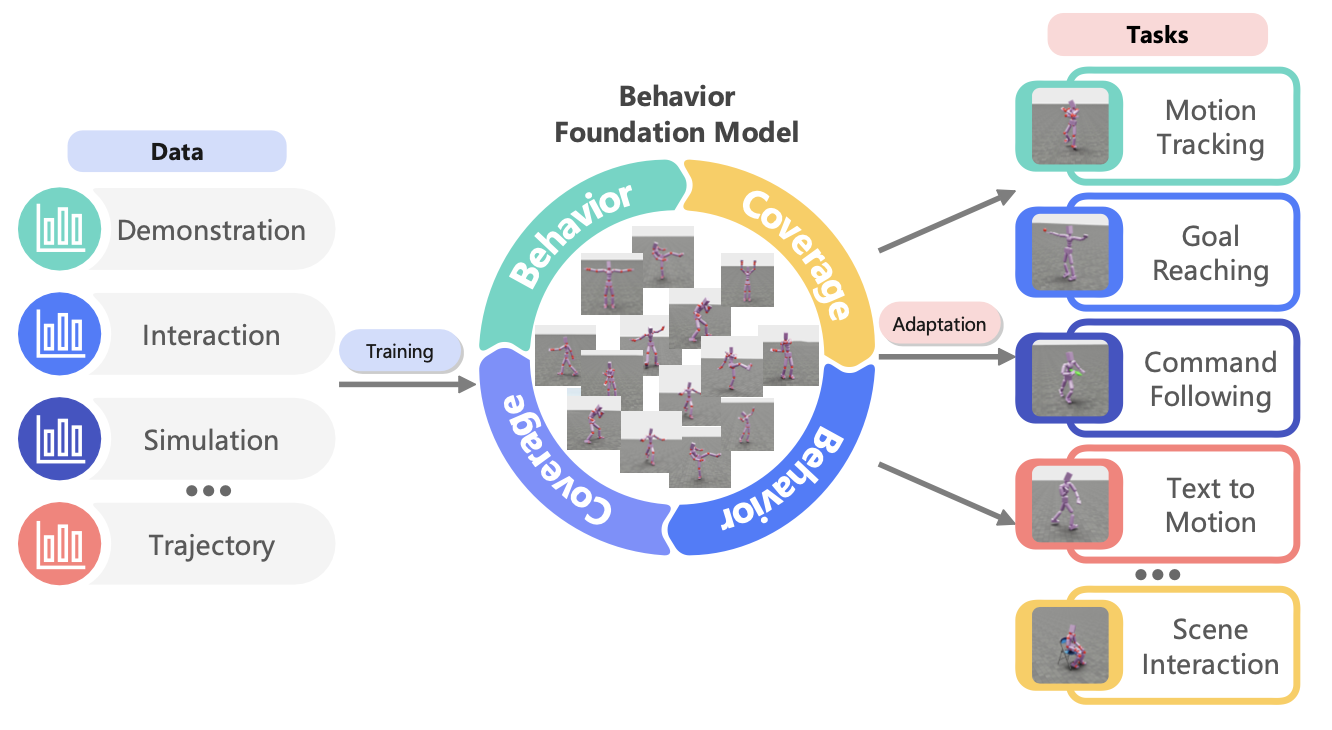
人形机器人全身控制
人形机器人有望在动态且不可预测的非结构化环境中运行,与灵活性较低的机器人平台相比,这需要高度通用、鲁棒、可重构、灵巧且移动的控制系统 [53]。为此,提出了人形机器人全身控制 (WBC),用于协调多个机器人附肢的运动,以同时可靠地执行多项任务。它将整个机器人身体视为一个单一的集成系统,使用一套统一的控制算法来管理运动、操纵以及与环境的交互 [54]。如图所示,人形机器人全身控制 (WBC) 已从传统的基于模型方法发展到基于灵活学习的方法,并朝着能够解决各种场景中广泛任务的通用型机器人方向发展 [28, 52, 53, 55–57]。顺应这一趋势,BFM 已成为一种有前途的方法,通过对各种运动数据进行大规模预训练来实现通用的 WBC。
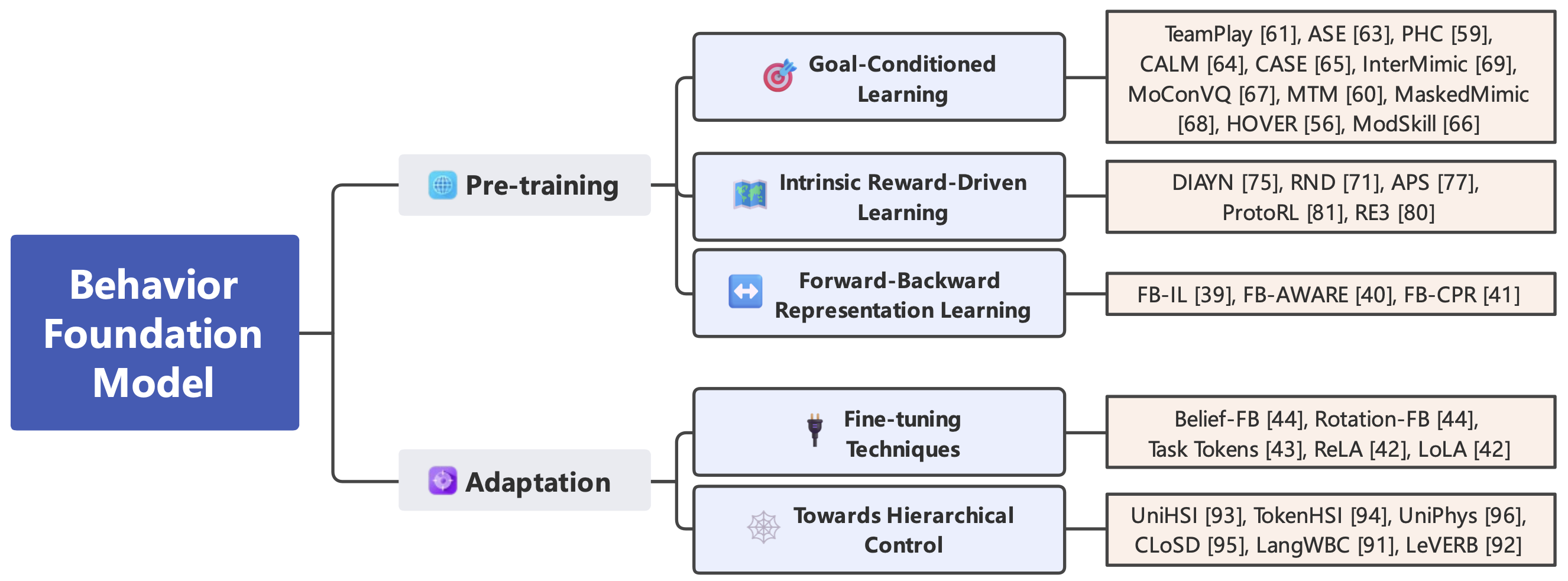
预训练
BFM 的预训练旨在从大规模数据源中学习可复用的原始技能和行为先验,为高效的下游自适应奠定基础。目前的方法大致可分为三类(如图所示):目标条件学习、内在奖励驱动学习和前向-后向框架。
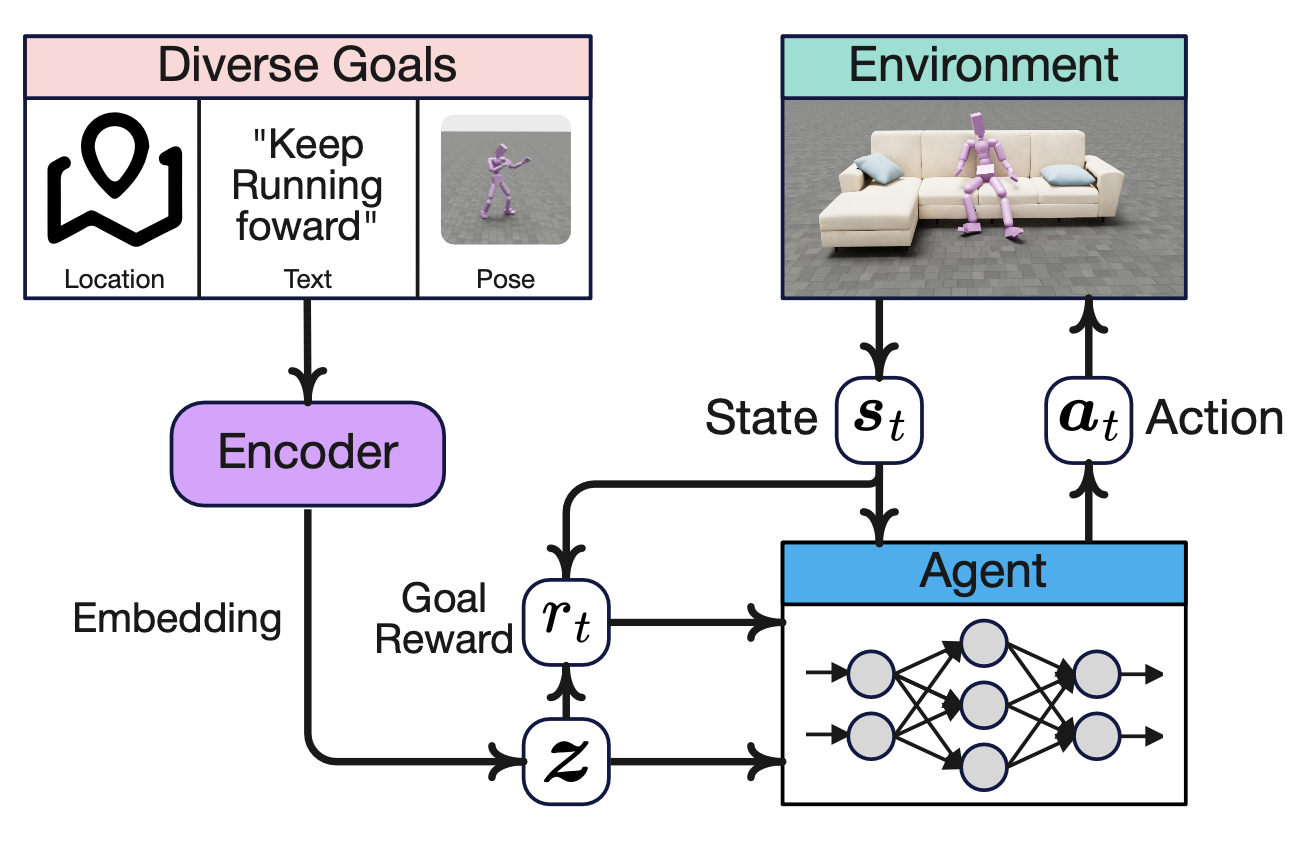
目标条件学习
如图所示,目标条件学习是强化学习中的一个框架,其中智体的行为以特定的目标或目的为条件,通常作为输入提供。在传统的强化学习中,智体从原始的状态-动作对中学习,没有明确的任务特定指导;而与传统的强化学习不同,目标条件学习将目标融入智体的策略中,使其能够调整其动作以实现该特定目标。目标可以以多种形式指定,例如目标状态、目标函数或外部任务描述 [59, 60]。这种方法允许智体通过学习能够有效处理不同目标的共享策略来泛化不同的目标。目标条件学习的关键优势在于它能够学习更灵活、可迁移的策略,从而应用于广泛的任务,因为它在训练过程中直接融入任务的目标,而无需针对每个特定任务进行重新训练。这使得它在智体需要解决多个任务或与不断变化的环境交互的环境中尤为有用。
来自运动追踪的技能学习。在众多目标条件学习方法中,基于跟踪的学习代表了一种特殊形式,其中目标行为由密集的参考监督或指导明确定义,通常源自动作捕捉数据或专家演示。在每个时间步,智体通常被训练来跟踪给定参考动作的关节角度或下一时间步的运动姿态 [16]。基于跟踪学习背后的主要动机是,学习跟踪单个姿态比直接模仿整个动作(尤其是复杂动作)更容易实现且更具通用性。例如,[61] 通过类似 DeepMimic [16] 的方法训练智体模仿大量足球动作捕捉数据,旨在实现对足球比赛行为的完整覆盖。然后,利用智体采样大量的状态-动作对来训练神经概率运动原语 (NPMP) 模型 [62],并导出低级潜条件控制器。最后,控制器将通过针对特定训练(例如,跟随、运球、射门和射门至目标)的奖励函数进行强化学习,从而应用于进一步的训练学习。在这里,学习的低级控制器可以被视为 BFM,因为它基于动作捕捉数据学习逼真的类人动作,并且可以快速适应各种高级训练学习。
类似地,[63] 引入了对抗技能嵌入 (ASE),这是一个通过将对抗性 IL 与无监督强化学习相结合来学习可复用运动技能潜空间的框架。ASE 经过非结构化运动数据的训练,可以生成一个潜变量为条件的低级控制器,该控制器能够生成各种物理上合理的行为,可作为下游任务的通用运动先验。在 ASE 的基础上,[64] 提出条件对抗潜变量模型 (CALM),该模型结合了条件判别器,能够通过潜操作对生成的动作进行细粒度控制。[65] 通过 CASE 进一步扩展了这一思路,引入了技能调节的 IL,并结合焦点技能采样和骨骼残余力等训练技术来增强敏捷性和动作多样性。
虽然上述方法能够从大型行为数据集中高效地获取技能,但 [55] 提出 HugWBC,探索在不依赖预收集动作数据的情况下学习多种运动技能。该框架通过结构化的 RL 流程自动生成自适应行为,其中通用命令空间在训练过程中动态地生成可行的速度、步态和姿势目标。通过将WBC重新表述为一个自监督的命令跟踪问题,该研究为开发通用类人控制器开辟了新的方向,这些控制器能够通过环境交互而非数据模仿来学习鲁棒的技能。
ModSkill [66] 超越身体层面的技能学习,引入了一个模块化框架,将全身运动解耦为针对各个身体部位的特定技能。这种模块化设计能够实现高效且可扩展的学习,因为每个身体部位都由一个由特定部位技能嵌入驱动的低级控制器独立控制。ModSkill 专注于身体部位层面技能的能力使其成为一个强大的系统,可用于控制复杂运动,并在不同任务中调整学习的行为。通过利用技能模块化注意层,ModSkill 增强运动技能在各种任务(例如伸手或击打)中的泛化能力,从而进一步提高特定任务的适应性。
从原始技能到高级目标执行。BFM 在学习各种原始技能方面的成功推动了更高级 BFM 的发展,这些 BFM 能够解释和执行高级目标,包括语言指令和多任务目标。一个值得注意的例子是 MoConVQ [67],它引入一个统一的运动控制框架,该框架基于通过矢量量化变分自编码器 (VQ-VAE) 学习的离散潜码。该模型通过提供紧凑的模块化表示,支持广泛的下游任务,包括运动追踪、交互式控制和文本转运动生成。MoConVQ 还与大语言模型 (LLM) 集成,使模拟智体能够通过上下文语言提示进行引导,从而连接符号推理和物理控制。
同时,MaskedMimic [68] 将基于物理的角色控制作为通用的运动修复问题来解决,它可以根据部分描述(例如被掩码的关键帧、目标或文本指令)生成全身运动。 Masked-Mimic 的训练过程分为两个阶段:首先,完全约束的运动跟踪控制器学习模仿不同的参考运动;然后,基于部分约束的 VAE 策略通过掩码目标条件反射提炼这些知识。因此,MaskedMimic 可以动态适应复杂场景,支持从 VR 控制到复杂的人机交互 (HOI) 等各种应用。此外,InterMimic [69] 专注于 HOI 场景,设计一个两阶段的师生框架,将不完善的动作捕捉交互数据蒸馏为鲁棒的基于物理的控制器。教师策略在噪声数据子集上进行训练,并通过模拟进行细化,然后通过基于 RL 的微调蒸馏为学生策略。这种课程策略能够在具有高物理保真度的各种交互中进行泛化。
对于现实世界的机器人应用,HOVER [56] 引入一个多模态策略蒸馏框架,允许类人机器人使用从预言机中提炼出单一统一的策略,在运动、操控和导航等任务之间无缝切换。这消除了对特定任务控制器的需求,展示了现实世界环境中的通用控制能力,类似于 MaskedMimic 对虚拟角色的多功能性。
所有上述方法都遵循 BFM 的理念,这体现在两个方面:(i) 它们能够从不同的数据源学习广泛的行为覆盖范围;(ii) 它们能够快速适应下游任务。这些模型在大规模数据集上进行训练,可以泛化到各种运动技能,例如运动、HOI 和特定任务的行为,而不局限于单一任务。例如,InterMimic 能够处理各种 HOT 任务,而 MoConVQ 则能够适应不同的任务,例如目标达成和基于文本条件的动作生成。此外,这些模型能够快速适应新任务,且只需极少的再训练,展现出它们能够将学习的行为应用于全新且未见过场景的能力。因此,广泛的行为覆盖范围与强大的适应能力共同将这些方法称为 BFM。
内在奖励驱动学习
在基于追踪的学习中,智体始终被赋予明确的目标(例如,关节角度或速度),并通过明确指定的奖励函数进行训练,以实现目标技能习得。相比之下,内在奖励驱动学习则提供了一种独特的方法,其中智体被激励去探索环境,而不依赖于明确的特定任务奖励。相反,智体受内在奖励的引导,这些内在奖励是自生成的信号,鼓励探索、技能习得或新奇事物检测。目前已开发出多种内在奖励驱动学习策略,包括好奇心驱动的探索[70–73]、技能发现[74–77]和最大化数据覆盖率[78–81],每种策略都鼓励智体探索环境的不同方面。

这些无监督强化学习智体被称为 BFM,基于以下两个关键观察结果:(i) 它们能够有效地探索环境和动作空间,并在内在奖励的激励下发现可泛化的行为;(ii) 它们表现出有效学习和适应各种任务的能力,如 [81] 和 [83] 所示。然而,仅使用内在奖励训练的 BFM 面临着巨大的局限性。智体通常需要进行大量的训练才能在内在奖励的指导下实现广泛的行为覆盖率,同时会持续产生不可靠的运动先验(例如,不安全或不切实际的运动),尤其对于具有极其复杂动态的人形机器人而言 [39]。尽管这种范式很方便,但未来的研究可能会通过开发混合方法来应对这些根本挑战,将内在奖励的探索性优势与目标条件学习的任务相关效用保证相结合,从而为人形机器人实现可靠的 BFM。
前向-后向表示学习
BFM 的最新进展得益于一种名为前向-后向 (FB) 表示学习的框架 [84],该框架将策略学习与特定任务的目标分离开来,展示了一种和目标条件学习和内在奖励驱动学习截然不同的方法。通过学习通用的策略表示,它可以通过奖励推理或演示对齐快速适应新任务,而无需额外的环境交互或策略优化。
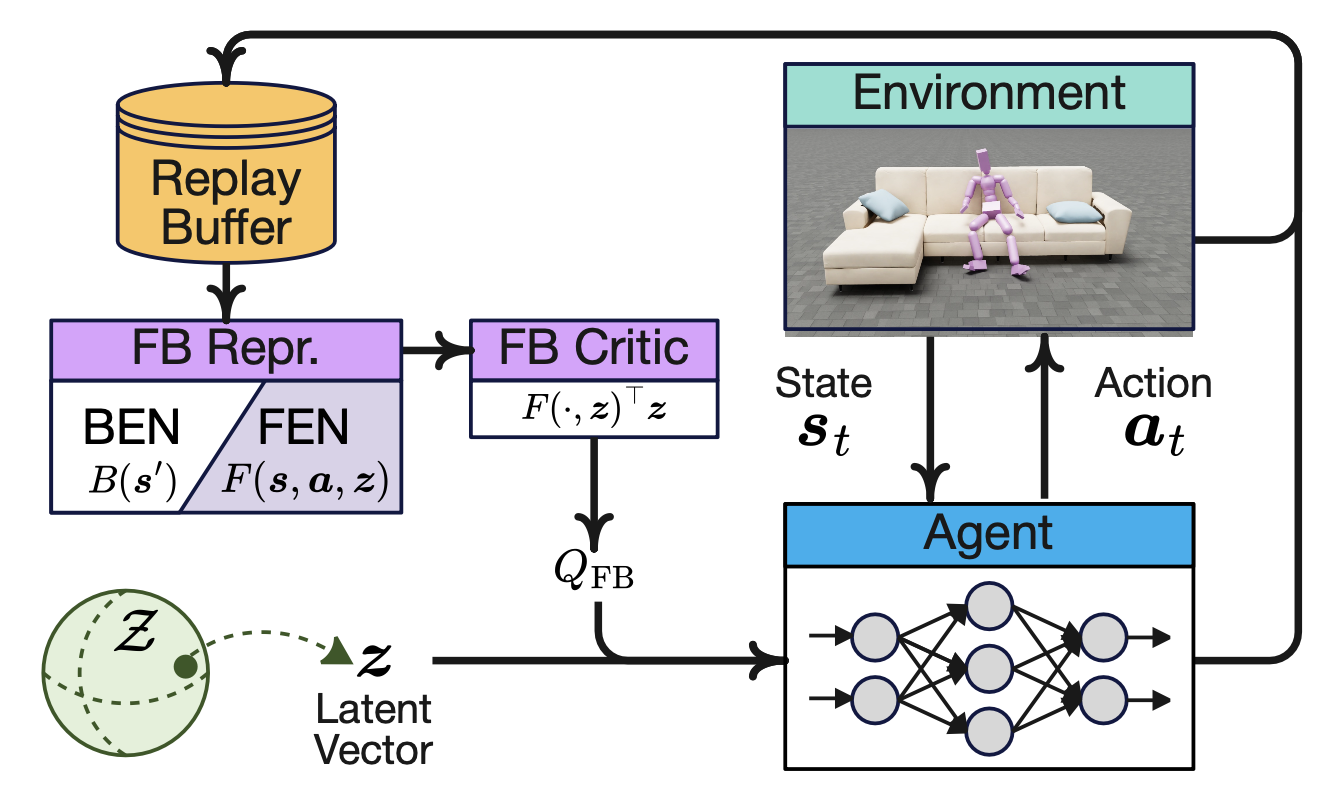
FB 表示学习的核心是学习后继者测度的有限秩近似,它是后继者表示的扩展 [85, 86]。它将折扣的状态访问分布描述为对状态的测度。对于任何奖励函数 r,π 的动作-价值函数 Qπ_r (s, a) 都会将动作价值函数解耦为两个独立项:(i) 后继测度,用于模拟环境中策略的演变;(ii) 奖励函数,用于捕捉与任务相关的信息。这种分解表明,学习 π 的后继者测度,无需进一步训练,即可对任何奖励的 Qπ_r 进行零样本评估。
为了学习一组策略,[87] 建议,前向嵌入 Fπ 和策略 π 都可以由相同的任务编码向量 z 参数化。然后,训练前向-后向嵌入网络最小化时间差分 (TD) 损失,该损失由贝尔曼残差得出。
一旦 FB 模型训练完成,它就可以用于以零样本方式解决各种任务,而无需执行额外特定任务的学习、规划或微调。
[39] 首次从字面上引入了“BFM”一词,并提出基于 BFM 的快速 IL——FB-IL,它支持多种 IL 原则,例如行为克隆、特征匹配和基于目标的约简,而无需为每个新任务编写单独的 RL 例程。[40] 通过结合自回归特征进一步增强了 FB 框架,以便在 BFM 中实现更精确的任务编码和更好的任务表示。标准 FB 方法使用线性任务投影,这会模糊奖励并降低空间精度,而自回归特征可以提高表达能力和性能,特别是对于需要空间精度或泛化能力的任务。此外,[40] 引入优势加权回归 (AWR) 来应对从复杂数据集进行离线学习的挑战。改进的 FB 方法 FB-AWARE 将自回归特征与优势加权相结合,在新环境中表现良好,甚至在 D4RL 等基准测试中与标准离线 RL 智体的性能相匹配。 FB 框架通过学习后继者测度表征并将预训练策略应用于新任务,提供一种通用且灵活的 BFM 训练方法。然而,该方法存在一些局限性:(i) 当潜维度 d 有限时,它依赖于低秩动态假设,导致策略选择的归纳偏差有限;(ii) 训练数据集覆盖率低,导致离线学习无法可靠地优化策略,通常会陷入少数次优行为,导致下游任务性能不佳。这些局限性极大地阻碍 FB 框架在人形机器人上的应用。为了解决这些局限性,[41] 提出条件策略正则化的 FB(FB-CPR),并引入了 Motivo,这是第一个真正意义上用于人形 WBC 的 BFM,它能够以零样本方式解决各种任务,包括运动跟踪、目标达成和奖励优化。
FB-CPR 并非一种严格的无监督方法,因为它利用未标记的演示数据来辅助运动先验学习。通过将无监督强化学习与来自未标记数据的类人行为先验相结合,FB-CPR 增强策略多样性和数据集覆盖率,使智体能够学习丰富的行为潜空间(例如行走、跳跃、倒立),并在各种任务中实现稳健的零样本性能。实验结果表明,Motivo 在运动追踪任务中的成功率达到 83%,在奖励优化任务中达到了 61% 的最高性能,其计算效率超越了 DIFFUSER,每 300 步仅需 12 秒。此外,它在运动多样性方面也优于 ASE 和 CALM,得分为 4.70(±0.66),这反映出其能够捕捉更广泛的行为。
。。。。。。待续。。。。。。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献215条内容
已为社区贡献215条内容

所有评论(0)