ViedoRAG论文解读
1. 信息完整性符号通道确保概念的精确表达感知通道保留丰富的上下文信息双通道互补,最大化信息保真度2. 检索精度多层次匹配:概念匹配 + 感知匹配交叉验证:提高结果可靠性语义推理:支持复杂查询理解3. 系统效率分层存储:优化存储和检索效率并行处理:两通道可并行执行智能缓存:减少重复计算4. 可扩展性模块化设计:易于扩展和维护增量学习:支持动态知识更新跨域适应:可适应不同视频类型。
VideoRAG:突破超长视频理解边界的检索增强生成框架
背景介绍:从文本RAG到视频RAG的技术跃迁
大型语言模型的知识边界困境
近年来,以GPT-4、Claude等为代表的大型语言模型(Large Language Models, LLM)在自然语言理解和生成方面取得了革命性突破。然而,这些模型面临着一个根本性的知识边界问题:
时间截止限制:模型的知识被"冻结"在预训练数据的时间截止点,无法获取最新信息。例如,一个在2023年训练的模型无法了解2024年发生的技术突破或世界事件。
覆盖范围局限:即使是最大规模的模型,其预训练数据也无法涵盖所有专业领域的深度知识,特别是企业内部文档、专业技术资料、个人化内容等私有信息。
动态更新困难:重新训练大型模型需要巨大的计算资源和时间成本,使得知识的实时更新变得不现实。
RAG技术:知识增强的创新范式
为了突破这些根本性限制,研究者提出了**检索增强生成(Retrieval-Augmented Generation, RAG)**技术。RAG的核心思想可以用一个简单的比喻来理解:
想象一个学者在回答问题时,不仅依靠自己的记忆,还会查阅图书馆中的相关资料。RAG就是让AI模型具备了这种"查阅资料"的能力。
RAG的工作原理:
- 知识库构建:将外部文档、数据库等信息源转化为可检索的知识库
- 相关性检索:根据用户查询,从知识库中检索最相关的信息片段
- 上下文增强:将检索到的信息作为上下文,与原始查询一起输入给LLM
- 增强生成:LLM基于增强后的上下文生成更准确、更新的回答
这种范式的优势在于:
- 实时性:可以随时更新知识库,无需重训模型
- 专业性:可以整合特定领域的专业知识
- 可控性:可以明确知道回答的信息来源
- 成本效益:避免了重新训练大模型的巨大成本
传统RAG技术的局限性:视频内容的挑战
虽然RAG技术在文本领域取得了巨大成功,但当面对视频这种信息密度极高的多模态内容时,传统RAG方法遇到了前所未有的挑战。这些挑战的根源在于视频与文本在信息结构上的根本性差异:
1. 信息密度的指数级差异
文本vs视频的信息量对比:
- 一页A4纸的文本大约包含500-800个单词
- 一分钟的1080p视频包含1800帧图像,每帧都是一个完整的视觉场景
- 如果用文字描述一分钟视频的所有细节,可能需要数千甚至上万字
这种信息密度差异带来的问题:
- 描述不完整性:将视频转换为文本描述时,必然会丢失大量视觉细节
- 存储成本激增:完整描述视频内容需要的文本量远超原始视频的存储需求
- 检索精度下降:基于不完整描述的检索无法准确定位用户真正需要的视频片段
2. 多模态信息的异构性挑战
视频是一种典型的异构多模态数据,同时包含:
视觉信息层:
- 静态元素:物体、人物、场景布局、颜色构成、光影效果
- 动态元素:运动轨迹、动作序列、表情变化、场景转换
- 空间关系:物体间的相对位置、深度信息、透视关系
音频信息层:
- 语音内容:说话人的具体话语、语调变化、情感表达
- 环境声音:背景音乐、自然声音、机械声音
- 声音特征:音量变化、频率特征、空间定位
文本信息层:
- 字幕文本:对话字幕、说明文字、翻译文本
- 图形文字:PPT内容、标识文字、图表数据
- 元数据:标题、标签、描述信息
时序信息层:
- 事件顺序:情节发展、因果关系、时间线
- 节奏变化:快慢节奏、停顿间隔、重复模式
- 同步关系:音画同步、多轨道协调
传统RAG方法基于"文本块(text chunks)"的处理范式,无法有效整合这些异构信息:
传统RAG处理流程:
视频 → 转录文本 → 文本分块 → 向量化 → 检索
↑
信息损失严重
3. 时序依赖关系的复杂性
视频中的知识往往具有强烈的时序依赖特性,这与文本的线性结构有本质区别:
短期时序依赖:
- 连续帧之间的运动连贯性
- 对话的上下文关联
- 动作的完整性(如一个完整的手势或操作步骤)
长期时序依赖:
- 跨越数分钟甚至数小时的情节发展
- 概念的逐步深入和递进关系
- 前后呼应的内容关联
非线性时序关系:
- 闪回、预告等非线性叙述
- 并行发生的多线程事件
- 周期性重复的模式
举个具体例子:在一个编程教学视频中,讲师可能在第10分钟提到一个概念,在第30分钟详细解释,在第50分钟通过实例演示,在第70分钟总结应用。传统RAG方法很难捕捉这种跨时间的概念演进关系。
4. 语义割裂问题
传统RAG的分块策略在视频内容上会导致严重的语义割裂:
场景割裂:一个完整的场景可能被分割到不同的文本块中
概念割裂:一个复杂概念的解释可能跨越多个视频片段
上下文割裂:问答对话的上下文关系被破坏
多模态割裂:视觉信息与音频信息被分离处理
这些问题的根本原因在于:传统RAG假设知识可以通过独立的文本片段有效表达,但视频中的知识往往是整体性的、关联性的、多维度的。
长视频处理的技术瓶颈
长视频处理的技术瓶颈:从分钟级到小时级的挑战
与此同时,现有的大型视觉模型在处理长视频时也面临着严峻挑战。这些模型通常设计用于处理短视频片段(几秒到几分钟),当面对跨越数小时甚至数天的超长视频序列时,技术挑战呈现指数级增长。这不仅仅是数据量的线性增加,而是涉及到计算复杂度、存储架构、检索效率等多个维度的系统性挑战。
1. 计算复杂度的爆炸式增长
数据量级的直观对比:
- 短视频(5分钟):约9,000帧图像 + 5分钟音频
- 中等视频(1小时):约108,000帧图像 + 1小时音频
- 长视频(10小时):约1,080,000帧图像 + 10小时音频
- 超长视频(100小时):约10,800,000帧图像 + 100小时音频
计算复杂度分析:
以视觉特征提取为例,假设使用主流的视觉编码器(如CLIP、ImageBind):
- 每帧图像的特征提取时间:约10-50ms
- 100小时视频的特征提取总时间:108,000秒 ≈ 30小时
- 这还不包括音频处理、文本转录、知识图谱构建等步骤
内存需求激增:
特征向量存储需求计算:
- 单帧视觉特征:512维 × 4字节 = 2KB
- 100小时视频视觉特征:10,800,000帧 × 2KB ≈ 21.6GB
- 加上音频特征、文本特征:总计可能超过100GB
2. 存储架构的系统性挑战
传统存储方案的局限性:
现有的视频处理系统通常采用平铺式存储(flat storage),即将所有特征向量存储在同一个向量数据库中。这种方案在处理超长视频时面临严重问题:
检索效率下降:
- 向量数据库的查询时间复杂度通常为O(log n)到O(n)
- 当n从104增长到107时,查询时间可能增长1000倍以上
- 实际测试:在包含1000万个向量的数据库中,单次查询可能需要数秒甚至数十秒
索引维护成本:
- 大规模向量数据库的索引构建时间可能长达数小时
- 增量更新的复杂度极高
- 内存占用可能达到数据本身的2-3倍
并发访问瓶颈:
- 多用户同时查询时,系统响应时间急剧恶化
- 资源竞争导致的死锁和超时问题
- 缓存策略的复杂性呈指数级增长
3. 语义一致性的跨时间维护
概念漂移问题:
在长视频中,同一个概念可能在不同时间点以不同的方式表达:
术语演进:
- 讲师可能先使用通俗术语,后来引入专业术语
- 同一概念在不同上下文中的表述差异
- 缩写、代称、指代关系的复杂变化
语义深化:
- 概念从简单介绍到深入分析的渐进过程
- 抽象概念通过具体实例的逐步阐释
- 理论与实践的多层次对应关系
上下文依赖:
- 代词指代的跨时间解析(“这个方法”、“刚才提到的”)
- 隐含前提的累积效应
- 话题转换的边界识别
举个具体例子:
时间轴示例(机器学习课程):
00:05 - "今天我们学习一种新的算法"
00:15 - "这种方法叫做神经网络"
01:30 - "NN的基本原理是..."
05:20 - "深度学习就是多层的神经网络"
10:45 - "CNN是专门处理图像的深度网络"
25:30 - "刚才的卷积神经网络..."
传统RAG方法很难建立这些跨时间的概念关联关系。
4. 检索精度与召回率的权衡困境
精确性vs完整性的矛盾:
在超长视频中,用户的查询可能对应多个相关片段,这些片段可能:
- 分布在视频的不同时间段
- 具有不同的重要性权重
- 存在层次化的逻辑关系
传统检索方法的问题:
Top-K检索的局限性:
- 固定的K值无法适应不同查询的复杂度
- 可能遗漏重要但相似度略低的片段
- 无法处理多粒度的检索需求
相似度计算的单一性:
- 仅基于向量相似度,忽略时序关系
- 无法区分核心内容与补充说明
- 缺乏对用户意图的深层理解
结果排序的简单化:
- 简单的相似度排序可能打乱逻辑顺序
- 忽略了内容的因果关系和依赖关系
- 无法提供结构化的知识呈现
5. 实时性要求与计算成本的平衡
用户体验的时延要求:
- 交互式查询:期望响应时间 < 2秒
- 实时问答:期望响应时间 < 5秒
- 深度分析:可接受响应时间 < 30秒
计算成本的现实约束:
- GPU资源的有限性和高昂成本
- 大规模向量计算的能耗问题
- 云服务的按需付费压力
6. 跨视频知识整合的复杂性
- 捕捉长距离时序依赖:无法有效建模跨越数小时的视频序列中的复杂时序关系
- 整合多视频知识:在需要整合多个相关视频的场景下(如系列讲座、多集纪录片分析、长期项目跟踪等),缺乏跨视频的语义关联能力
- 处理规模化内容:面对教育、媒体存档、企业培训等领域中动辄数百小时的视频内容时,计算和存储成本呈指数级增长
这些技术瓶颈的存在,使得传统的视频处理方法在面对超长视频时显得力不从心,极大地限制了AI系统在教育、媒体存档、企业知识管理等关键领域的应用潜力。VideoRAG正是在这样的背景下应运而生的创新解决方案。
核心问题:超长视频RAG的三重技术挑战
VideoRAG论文深入分析了超长视频检索增强生成面临的三个核心技术挑战,这些挑战相互交织,构成了一个复杂的技术难题体系。理解这些挑战是设计有效解决方案的前提。
挑战一:异构视频知识的高保真捕获
问题本质:如何在保持信息完整性的前提下,将视频中的多模态异构信息转换为可计算的知识表示?
1.1 多模态信息的同步性挑战
视频中的不同模态信息具有复杂的同步关系:
时间同步:
- 音画同步:语音内容与视觉画面的精确对应
- 字幕同步:文字信息与音频内容的时间对齐
- 动作同步:手势、表情与语言表达的协调
语义同步:
- 指代同步:语音中的"这个"、"那个"与视觉对象的对应
- 概念同步:抽象概念与具体视觉示例的关联
- 情感同步:语调变化与面部表情的一致性
技术难点:
# 传统方法的问题示例
def traditional_processing(video):
# 各模态独立处理,丢失同步信息
audio_features = extract_audio(video) # 时间戳:[0-300s]
visual_features = extract_visual(video) # 时间戳:[0-300s]
text_features = extract_text(video) # 时间戳:[0-300s]
# 简单拼接,无法捕获模态间的复杂关联
return concatenate([audio_features, visual_features, text_features])
1.2 信息密度的不均匀分布
视频中的信息密度在时间和空间维度上都存在显著的不均匀性:
时间维度的不均匀性:
- 高密度片段:概念解释、演示操作、重要结论
- 低密度片段:过渡段落、重复内容、停顿间隙
- 突发密度:关键信息的瞬间出现
空间维度的不均匀性:
- 视觉焦点区域:PPT内容、演示区域、重要物体
- 背景区域:装饰性元素、静态背景
- 动态关注区域:手势、表情、移动对象
模态重要性的动态变化:
时间轴示例(编程教学视频):
00:00-02:00 视觉主导:PPT展示课程大纲
02:00-05:00 音频主导:概念讲解,屏幕静态
05:00-15:00 多模态:代码演示+语音解释+手势指向
15:00-16:00 音频主导:总结回顾
1.3 语义层次的多级嵌套
视频知识具有复杂的层次结构,需要在不同抽象层次上进行理解:
微观层次(帧级):
- 单帧图像的对象识别
- 瞬时音频的语音识别
- 即时文本的内容提取
中观层次(片段级):
- 连续动作的完整识别
- 对话回合的语义理解
- 场景转换的边界检测
宏观层次(全局级):
- 整体主题的概念建模
- 知识结构的层次关系
- 跨时间的因果关联
挑战二:跨视频语义一致性的维护
问题本质:如何在处理多个相关视频时,建立统一的知识表示体系,确保概念的一致性和关联性?
2.1 概念表示的标准化难题
同一概念的多样化表达:
在不同视频中,同一个概念可能以完全不同的方式出现:
术语变异:
- 正式术语 vs 通俗表达:“神经网络” vs “人工神经元网络” vs “NN”
- 英文术语 vs 中文术语:“Machine Learning” vs “机器学习” vs “ML”
- 缩写形式 vs 完整形式:“AI” vs “Artificial Intelligence”
上下文依赖:
- 领域特定含义:在不同学科中"模型"的含义差异
- 时代背景影响:技术术语的历史演进
- 个人表达习惯:不同讲师的用词偏好
抽象层次差异:
概念层次示例(深度学习):
Level 1: "人工智能"(最抽象)
Level 2: "机器学习"
Level 3: "深度学习"
Level 4: "卷积神经网络"
Level 5: "ResNet架构"(最具体)
2.2 知识图谱的动态演进
实体关系的复杂性:
跨视频的知识整合需要处理实体间的复杂关系:
静态关系:
- 分类关系:“CNN是深度学习的一种”
- 组成关系:“神经网络由神经元组成”
- 属性关系:“ReLU是激活函数”
动态关系:
- 时序关系:“反向传播算法在1986年被提出”
- 因果关系:“梯度消失导致了ReLU的发明”
- 演进关系:“Transformer架构改进了RNN”
上下文关系:
- 应用场景:“CNN主要用于图像处理”
- 适用条件:“在数据量充足时,深度学习效果更好”
- 限制条件:“RNN在处理长序列时存在梯度消失问题”
2.3 跨视频实体对齐
实体识别的歧义性:
# 实体对齐的挑战示例
video_1_entities = [
{"name": "神经网络", "type": "概念", "context": "基础介绍"},
{"name": "李教授", "type": "人物", "context": "主讲人"}
]
video_2_entities = [
{"name": "NN", "type": "概念", "context": "高级应用"},
{"name": "Prof. Li", "type": "人物", "context": "客座讲师"}
]
# 需要识别:神经网络 == NN, 李教授 == Prof. Li
挑战三:大规模视频知识的高效检索
问题本质:如何在海量视频知识库中实现快速、准确、智能的信息检索?
3.1 检索粒度的多层次需求
用户查询的多样性:
用户的信息需求具有不同的粒度特征:
细粒度查询:
- “第15分钟讲师提到的那个公式是什么?”
- “演示中使用的具体参数设置”
- “某个特定错误的解决方法”
中粒度查询:
- “关于反向传播算法的完整解释”
- “CNN的基本原理和应用场景”
- “这个项目的整体架构设计”
粗粒度查询:
- “深度学习的发展历程”
- “机器学习的主要分支和应用”
- “人工智能的未来发展趋势”
3.2 语义理解的深度要求
查询意图的复杂性:
用户的真实需求往往隐藏在表面查询之下:
直接查询 vs 隐含需求:
用户查询:"这个算法的时间复杂度是多少?"
隐含需求:
- 算法的具体实现细节
- 在不同数据规模下的性能表现
- 与其他算法的性能对比
- 优化方法和改进空间
上下文相关的查询:
- 基于对话历史的连续查询
- 基于当前学习进度的个性化查询
- 基于特定应用场景的定向查询
3.3 实时性与准确性的平衡
响应时间的严格要求:
不同应用场景对响应时间有不同要求:
交互式学习:< 2秒
实时问答:< 5秒
深度分析:< 30秒
离线处理:< 5分钟
准确性的多维度评估:
- 相关性:检索结果与查询的匹配度
- 完整性:是否覆盖了查询的所有方面
- 时序性:是否保持了信息的逻辑顺序
- 新颖性:是否提供了有价值的新信息
这三重技术挑战相互关联、相互制约,构成了超长视频RAG系统设计的核心难题。VideoRAG通过创新的双通道架构,为这些挑战提供了系统性的解决方案。
VideoRAG的创新解决方案
为了系统性地应对这些挑战,本文提出了 VideoRAG 框架——一个专门针对超长视频内容设计的检索增强生成系统。VideoRAG的核心创新在于其双通道架构,它巧妙地将视频的多模态信息分解为两个互补的处理通道,既保证了信息的完整性,又实现了检索的高效性,从而释放RAG技术在超长视频理解领域的全部潜力。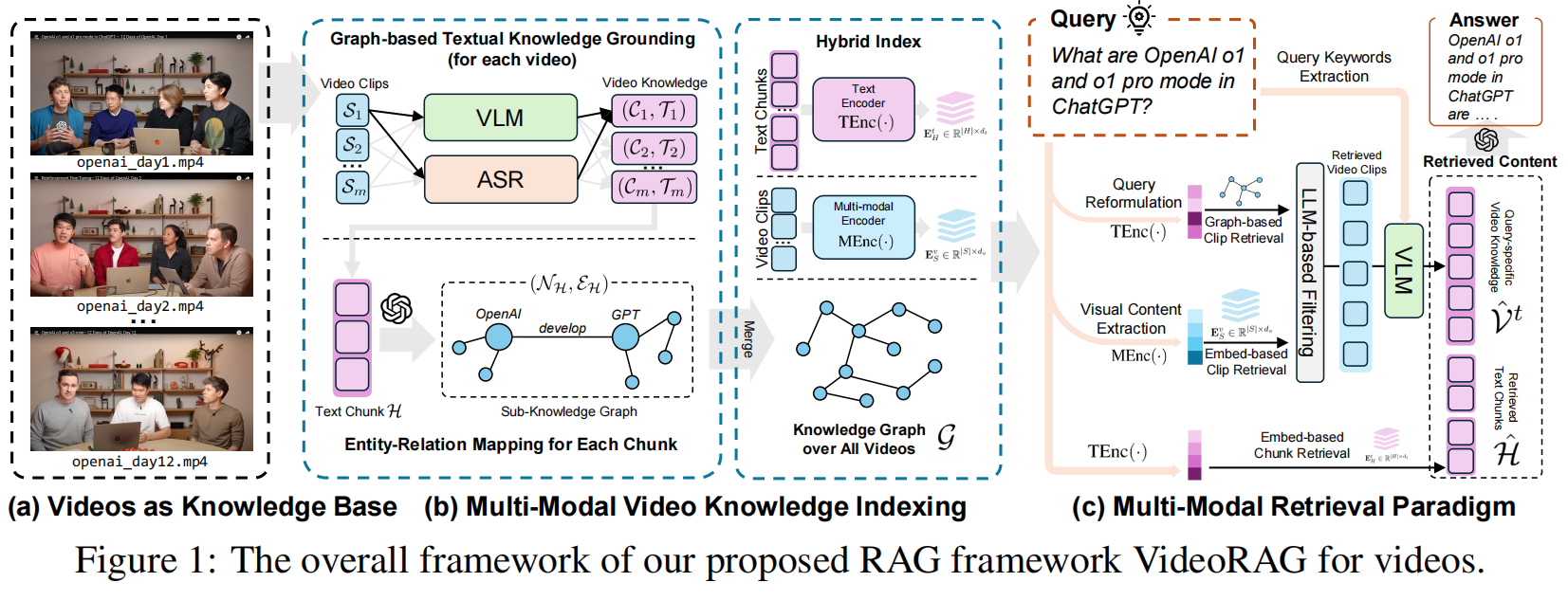
VideoRAG的创新解决方案:双通道架构的技术突破
面对上述三重技术挑战,VideoRAG提出了一个革命性的双通道架构(Dual-Channel Architecture),这一架构的核心思想是:将视频知识的表示和检索分解为两个互补且协同的处理通道,从而实现对复杂视频内容的高效理解和精准检索。
架构设计哲学:分而治之,协同增效
VideoRAG的双通道设计基于一个重要的认知科学发现:人类在理解复杂视频内容时,大脑会同时运行两套并行的信息处理机制:
通道一:图驱动的文本知识追踪(Graph-driven Text Knowledge Tracing)
- 核心功能:构建结构化的概念知识图谱
- 处理对象:语音转录、实体关系、概念层次
- 优势:精确的语义理解、高效的符号推理
通道二:分层多模态上下文编码(Layered Multi-modal Context Encoding)
- 核心功能:捕获丰富的感知层信息
- 处理对象:视觉场景、音频特征、时序动态
- 优势:完整的信息保真、直观的相似性匹配
通道一:图驱动的文本知识追踪
1.1 语音到知识的转换流水线
VideoRAG采用了一套精心设计的多阶段处理流水线,将原始视频转换为结构化知识:
# VideoRAG的知识提取流水线
def knowledge_extraction_pipeline(video_segment):
# 阶段1:高精度语音转录
transcript = whisper_asr(video_segment) # 使用Whisper ASR
# 阶段2:智能文本分块
chunks = intelligent_chunking(transcript,
chunk_size=500,
overlap=50,
semantic_boundary=True)
# 阶段3:实体和关系提取
entities_relations = []
for chunk in chunks:
# 使用LLM进行实体识别
entities = llm_extract_entities(chunk)
# 使用LLM进行关系识别
relations = llm_extract_relations(chunk, entities)
entities_relations.append((entities, relations))
# 阶段4:知识图谱构建
knowledge_graph = build_knowledge_graph(entities_relations)
return {
'text_chunks': chunks,
'knowledge_graph': knowledge_graph,
'entities': entities,
'relations': relations
}
1.2 知识图谱的智能构建机制
VideoRAG的知识图谱构建采用了增量式学习和冲突解决机制:
实体统一算法:
def entity_unification(new_entity, existing_entities):
"""
跨视频实体统一算法
"""
# 1. 字面匹配
exact_matches = find_exact_matches(new_entity, existing_entities)
if exact_matches:
return merge_entities(new_entity, exact_matches[0])
# 2. 语义相似度匹配
semantic_matches = find_semantic_matches(new_entity, existing_entities,
threshold=0.85)
if semantic_matches:
return merge_entities(new_entity, semantic_matches[0])
# 3. 上下文推理匹配
context_matches = find_context_matches(new_entity, existing_entities)
if context_matches:
return merge_entities(new_entity, context_matches[0])
# 4. 创建新实体
return create_new_entity(new_entity)
关系推理引擎:
def relation_inference_engine(knowledge_graph):
"""
基于现有关系推理新关系
"""
# 传递性推理:A->B, B->C => A->C
transitive_relations = infer_transitive_relations(knowledge_graph)
# 对称性推理:A-similar-B => B-similar-A
symmetric_relations = infer_symmetric_relations(knowledge_graph)
# 层次推理:A-is_a-B, B-is_a-C => A-is_a-C
hierarchical_relations = infer_hierarchical_relations(knowledge_graph)
return merge_relations([transitive_relations,
symmetric_relations,
hierarchical_relations])
通道二:分层多模态上下文编码
2.1 视觉特征的层次化提取
VideoRAG采用多尺度视觉编码策略,在不同时间粒度上提取视觉特征:
帧级特征提取:
def frame_level_encoding(video_frames):
"""
帧级视觉特征提取
"""
frame_features = []
for frame in video_frames:
# 使用ImageBind提取多模态特征
visual_feature = imagebind_encoder(frame)
# 场景理解
scene_info = scene_understanding(frame)
# 对象检测
objects = object_detection(frame)
frame_features.append({
'visual_embedding': visual_feature,
'scene_context': scene_info,
'objects': objects,
'timestamp': frame.timestamp
})
return frame_features
片段级特征聚合:
def segment_level_encoding(frame_features, segment_duration=30):
"""
片段级特征聚合
"""
segments = []
for i in range(0, len(frame_features), segment_duration * 30): # 30fps
segment_frames = frame_features[i:i + segment_duration * 30]
# 时序特征聚合
temporal_feature = temporal_aggregation(segment_frames)
# 场景一致性分析
scene_consistency = analyze_scene_consistency(segment_frames)
# 动作识别
actions = action_recognition(segment_frames)
segments.append({
'temporal_embedding': temporal_feature,
'scene_consistency': scene_consistency,
'actions': actions,
'start_time': segment_frames[0]['timestamp'],
'end_time': segment_frames[-1]['timestamp']
})
return segments
2.2 音频-视觉同步编码
VideoRAG特别注重音频和视觉信息的同步处理:
def audio_visual_sync_encoding(audio_features, visual_features):
"""
音频-视觉同步编码
"""
sync_features = []
for audio_seg, visual_seg in zip(audio_features, visual_features):
# 时间对齐检查
time_alignment = check_time_alignment(audio_seg, visual_seg)
if time_alignment > 0.9: # 高同步度
# 多模态融合
fused_feature = multimodal_fusion(audio_seg, visual_seg)
# 语义一致性检查
semantic_consistency = check_semantic_consistency(audio_seg, visual_seg)
sync_features.append({
'fused_embedding': fused_feature,
'audio_embedding': audio_seg['embedding'],
'visual_embedding': visual_seg['embedding'],
'sync_score': time_alignment,
'semantic_score': semantic_consistency
})
return sync_features
双通道协同机制:1+1>2的效果
VideoRAG的真正创新在于两个通道的智能协同机制:
3.1 查询理解的双通道分析
当用户提出查询时,系统会同时在两个通道中进行分析:
def dual_channel_query_analysis(user_query):
"""
双通道查询分析
"""
# 通道1:符号化查询理解
symbolic_analysis = {
'entities': extract_query_entities(user_query),
'relations': extract_query_relations(user_query),
'intent': classify_query_intent(user_query),
'constraints': extract_query_constraints(user_query)
}
# 通道2:感知化查询理解
perceptual_analysis = {
'visual_concepts': extract_visual_concepts(user_query),
'audio_concepts': extract_audio_concepts(user_query),
'temporal_concepts': extract_temporal_concepts(user_query),
'emotional_tone': analyze_emotional_tone(user_query)
}
# 双通道融合
unified_query = fuse_query_analysis(symbolic_analysis, perceptual_analysis)
return unified_query
3.2 检索结果的交叉验证
两个通道的检索结果会进行交叉验证和互补增强:
def cross_channel_validation(symbolic_results, perceptual_results):
"""
跨通道结果验证和融合
"""
validated_results = []
for sym_result in symbolic_results:
# 寻找感知通道的支持证据
supporting_evidence = find_supporting_evidence(sym_result, perceptual_results)
if supporting_evidence:
# 增强置信度
enhanced_result = enhance_confidence(sym_result, supporting_evidence)
validated_results.append(enhanced_result)
else:
# 降低置信度但保留
weakened_result = weaken_confidence(sym_result)
validated_results.append(weakened_result)
# 添加感知通道独有的发现
unique_perceptual = find_unique_perceptual_insights(perceptual_results, symbolic_results)
validated_results.extend(unique_perceptual)
return sort_by_confidence(validated_results)
技术优势总结
VideoRAG的双通道架构带来了显著的技术优势:
1. 信息完整性:
- 符号通道确保概念的精确表达
- 感知通道保留丰富的上下文信息
- 双通道互补,最大化信息保真度
2. 检索精度:
- 多层次匹配:概念匹配 + 感知匹配
- 交叉验证:提高结果可靠性
- 语义推理:支持复杂查询理解
3. 系统效率:
- 分层存储:优化存储和检索效率
- 并行处理:两通道可并行执行
- 智能缓存:减少重复计算
4. 可扩展性:
- 模块化设计:易于扩展和维护
- 增量学习:支持动态知识更新
- 跨域适应:可适应不同视频类型
这种双通道架构不仅解决了传统RAG在视频领域的技术瓶颈,更为超长视频的智能理解开辟了新的技术路径。
方法论:双通道架构的创新设计
VideoRAG的核心创新在于其双通道架构(Dual-Channel Architecture),这是一个专门为处理超长视频内容而设计的革命性框架。该架构包含两大关键组件:多模态视频知识索引框架 和 知识驱动的多模态检索范式。
架构设计哲学
双通道架构的设计哲学基于一个深刻的洞察:视频中的知识可以分解为两个互补的维度:
- 语义维度:通过语言可以表达的概念、关系和逻辑结构
- 感知维度:只能通过视觉和听觉感知的细节、氛围和非语言信息
传统方法试图将这两个维度强行统一,结果往往是顾此失彼。VideoRAG采用"分而治之"的策略,为每个维度设计专门的处理通道,最后在检索阶段进行智能融合。
1. 多模态视频知识索引框架
这个框架负责将非结构化的视频内容转化为结构化的、可检索的知识表示。它通过两个子组件协同工作:
1.1 基于图的文本知识构建(Graph-Driven Textual Knowledge Grounding)
核心思想:将视频中的语义信息提取并构建为知识图谱,实现跨视频的语义关联。
技术实现流程:
-
多模态内容转文本:
- 视觉转文本:使用先进的视觉语言模型(如MiniCPM-V)对视频关键帧进行场景描述生成(
segment_caption函数) - 音频转文本:采用Whisper ASR技术(
speech_to_text函数)将音频流转录为高质量的文字内容 - 文本整合:通过
merge_segment_information函数将视觉描述、音频转录和时间戳信息整合为统一的文本表示
- 视觉转文本:使用先进的视觉语言模型(如MiniCPM-V)对视频关键帧进行场景描述生成(
-
智能实体关系提取:
- LLM驱动提取:使用大型语言模型通过
extract_entities函数从整合后的文本中识别实体和关系 - 结构化表示:实体格式为
("entity"<分隔符><实体名><分隔符><实体类型><分隔符><实体描述>),关系格式为("relationship"<分隔符><源实体><分隔符><目标实体><分隔符><关系描述><分隔符><关系强度>) - 迭代式精化:通过
entity_extract_max_gleaning参数控制的多轮提取,确保实体识别的完整性
- LLM驱动提取:使用大型语言模型通过
-
跨视频知识图谱构建:
- 增量式构建:使用NetworkXStorage作为底层存储,通过
chunk_entity_relation_graph实现知识图谱的增量式构建 - 实体统一机制:通过
_merge_nodes_then_upsert函数处理跨视频的实体统一问题- 智能合并策略:当发现同名实体时,系统会聚合所有相关属性
- 类型选择:选择出现频率最高的实体类型作为统一类型
- 描述汇总:使用"廉价模型"(
cheap_model_func)对多个描述进行去重、排序和智能汇总 - 来源追踪:维护
source_id字段,记录实体在不同视频片段中的出现位置
- 关系合并机制:通过
_merge_edges_then_upsert函数处理关系的合并- 权重累积:将相同关系的权重进行累加,反映关系的重要程度
- 描述整合:对关系描述进行智能汇总,保持语义一致性
- 增量式构建:使用NetworkXStorage作为底层存储,通过
1.2 分层多模态上下文编码(Hierarchical Multimodal Context Encoding)
核心思想:为了弥补文本转换中可能丢失的视觉细节,直接对视频内容进行多模态编码,保留丰富的感知信息。
技术实现细节:
-
ImageBind多模态特征提取:
- 模型选择:采用ImageBind-Huge模型,这是一个能够处理图像、文本、音频、深度、热感和IMU数据等六种模态的统一编码器
- 视频编码流程:通过
encode_video_segments函数将视频路径转换为高维向量表示 - 批处理优化:视频片段被分批处理,平衡计算效率和内存使用
-
分层存储架构:
- 向量数据库:使用NanoVectorDBVideoSegmentStorage存储视频片段的特征向量
- 元数据关联:每个向量都与对应的视频片段元数据(时间戳、文件路径、描述等)关联
- 高效检索:支持基于向量相似度的快速检索
-
视觉特征保真度:
- 细节保留:直接编码保留了光影变化、物体细节、空间关系等难以用文字描述的视觉信息
- 时序连贯性:通过片段级编码保持视频的时序结构
- 跨模态对齐:ImageBind的统一嵌入空间确保了视觉和文本特征的语义对齐
2. 知识驱动的多模态检索范式
在用户查询时,该范式利用索引好的知识进行高效的多维度检索。
2.1 三层检索策略
第一层:朴素文本块检索
- 通过
chunks_vdb对用户查询进行基础的文本相似度检索 - 获取最相关的文本块作为基础上下文
第二层:知识图谱驱动的实体检索
- 查询精化:使用
_refine_entity_retrieval_query函数通过LLM重写用户查询,优化实体检索效果 - 实体匹配:在
entities_vdb中进行实体检索,找到与查询最相关的实体 - 图谱遍历:通过
_find_most_related_segments_from_entities函数,利用知识图谱的关系结构找到与检索实体相关的视频片段 - 语义扩展:不仅检索直接匹配的实体,还通过图谱关系发现间接相关的内容
第三层:视觉内容检索
- 视觉查询优化:使用
_refine_visual_retrieval_query函数重写查询,突出视觉相关的描述 - 向量检索:将优化后的查询通过
encode_string_query函数编码为ImageBind嵌入 - 相似度计算:在
video_segment_feature_vdb中进行向量相似度检索 - 视觉匹配:直接从视觉内容层面找到相关的视频片段
2.2 智能融合与过滤机制
多通道结果融合:
- 将实体检索结果(
entity_retrieved_segments)和视觉检索结果(visual_retrieved_segments)进行合并 - 形成综合的候选片段集合(
retrieved_segments)
LLM驱动的智能过滤:
- 使用大型语言模型的语义推理能力进行二次过滤
- 评估每个候选片段与用户查询的相关性
- 确保最终选出的片段与用户查询高度相关且逻辑连贯
上下文生成与响应:
- 为筛选后的视频片段生成详细的字幕描述(
caption_results) - 将文本检索内容(
retreived_chunk_context)和视频内容(video_data)整合为统一的上下文 - 通过系统提示(
sys_prompt)将所有信息提供给最终的LLM进行响应生成
架构优势总结
- 信息完整性:双通道设计确保了语义信息和感知信息的完整保留
- 检索精度:多层检索策略从不同维度定位相关内容,提高检索准确性
- 扩展性:模块化设计支持大规模视频库的高效处理
- 智能性:LLM驱动的查询优化和结果过滤提升了系统的智能化水平
- 一致性:跨视频的实体统一机制确保了知识的语义一致性
技术实现:从理论到实践的完整流程
VideoRAG的技术实现分为两个核心阶段:知识索引阶段(Knowledge Indexing Phase) 和 检索生成阶段(Retrieval-Generation Phase)。每个阶段都有其独特的技术挑战和创新解决方案。
阶段一:知识索引阶段
知识索引阶段是VideoRAG系统的基础,负责将原始视频内容转化为可检索的结构化知识。这个阶段的质量直接决定了后续检索的效果。
1.1 视频预处理与分段
智能分段策略:
- 时间窗口分段:将长视频按照固定时间窗口(如30秒)进行初步分割
- 场景感知分段:结合视觉特征变化检测场景切换点,实现语义连贯的分段
- 重叠处理:在相邻片段间设置重叠区域,避免重要信息在分段边界处丢失
元数据提取:
- 时间戳标记:为每个片段记录精确的开始和结束时间
- 文件路径管理:建立片段与源视频文件的映射关系
- 质量评估:对每个片段进行质量评估,过滤低质量内容
1.2 多模态内容转换
视觉信息提取:
# 核心函数:segment_caption
def segment_caption(video_path, start_time, end_time):
"""
使用MiniCPM-V等视觉语言模型对视频片段进行描述生成
- 关键帧采样:智能选择代表性帧
- 场景理解:生成详细的场景描述
- 对象识别:识别并描述视频中的主要对象
"""
音频信息提取:
# 核心函数:speech_to_text
def speech_to_text(audio_segment):
"""
使用Whisper ASR技术进行高质量语音转录
- 多语言支持:自动检测并转录多种语言
- 噪声处理:智能过滤背景噪声
- 时间对齐:保持转录文本与音频的时间同步
"""
信息融合:
# 核心函数:merge_segment_information
def merge_segment_information(visual_desc, audio_transcript, timestamp):
"""
将多模态信息整合为统一的文本表示
- 时序对齐:确保视觉和音频信息的时间一致性
- 语义融合:智能合并互补的信息源
- 结构化输出:生成标准化的片段描述
"""
1.3 知识图谱构建
实体关系提取:
# 核心函数:extract_entities
def extract_entities(merged_text, max_gleaning=3):
"""
使用LLM进行智能实体关系提取
- 迭代式提取:通过多轮gleaning提高提取完整性
- 结构化输出:生成标准格式的实体和关系
- 质量控制:通过置信度评估确保提取质量
"""
跨视频实体统一:
# 核心函数:_merge_nodes_then_upsert
def _merge_nodes_then_upsert(existing_entity, new_entity):
"""
智能实体合并机制
- 类型统一:基于频率选择最优实体类型
- 描述汇总:使用LLM进行描述的智能合并
- 来源追踪:维护实体在不同视频中的出现记录
"""
1.4 向量化存储
多层存储架构:
-
文本块存储(
chunks_vdb):- 存储分段后的文本内容
- 支持基于TF-IDF和语义相似度的检索
- 维护文本块与视频片段的映射关系
-
实体向量存储(
entities_vdb):- 存储实体的向量化表示
- 支持基于实体语义的快速检索
- 关联实体在知识图谱中的位置信息
-
视频特征存储(
video_segment_feature_vdb):- 存储ImageBind编码的视频特征向量
- 支持基于视觉相似度的检索
- 保持与原始视频片段的精确对应
-
知识图谱存储(
chunk_entity_relation_graph):- 使用NetworkX构建的图结构
- 支持复杂的图遍历和关系查询
- 实现实体间的语义关联发现
阶段二:检索生成阶段
检索生成阶段是VideoRAG系统的核心交互环节,它像一个智能的视频图书管理员,能够理解用户的复杂查询,从海量视频内容中精准定位相关信息,并生成高质量的回答。这个阶段的设计哲学是"多路并进,智能融合",通过多个独立但协同的检索通道,确保不遗漏任何有价值的信息。
2.1 查询理解与优化:让AI真正"听懂"你的问题
在传统的搜索系统中,用户输入什么,系统就搜索什么。但VideoRAG不同,它首先要"理解"用户真正想问的是什么。这就像一个经验丰富的图书管理员,当你问"那本关于人工智能的红色封面的书在哪里?“时,他不仅会搜索"红色封面”,还会理解你真正关心的是"人工智能"这个主题。
智能查询重写机制
VideoRAG采用了三种不同的查询重写策略,每种都针对特定的检索需求:
-
实体导向的查询重写(
_refine_entity_retrieval_query)这个过程就像把用户的问题翻译成"实体语言"。比如,当用户问"主要角色是谁?"时,系统会将其重写为"主要角色"这样的声明性语句,更适合在知识图谱中进行实体搜索。
工作原理:
- 实体识别:使用大型语言模型从查询中识别关键实体(人物、地点、概念等)
- 语义扩展:扩展查询的语义范围,包含同义词和相关概念
- 歧义消解:处理查询中的模糊表达,明确具体的搜索意图
-
视觉导向的查询重写(
_refine_visual_retrieval_query)这个功能专门处理包含视觉描述的查询。当用户问"电影开场时的天气如何?“时,系统会将其重写为"电影开场时具有特定天气条件的场景”,更适合在视觉特征空间中进行搜索。
核心能力:
- 视觉元素提取:识别查询中的颜色、动作、场景等视觉描述
- 场景重构:将抽象的视觉描述转化为具体的场景特征
- 多模态对齐:确保文本查询与视觉特征的语义对应
-
关键词提取(
_extract_keywords_query)这个过程提取查询中的核心关键词,用于后续的视频字幕生成。就像给视频片段贴上"标签",让系统知道应该重点关注哪些内容。
2.2 多层检索执行:三管齐下的智能搜索
VideoRAG的检索策略采用了"三层并行"的设计,每一层都有其独特的优势和适用场景。这就像同时派出三支不同专长的侦探队伍,从不同角度寻找线索。
第一层:基础文本检索 - 快速定位相关内容
这是最直接的检索方式,基于文本相似度进行搜索。
# 实际实现逻辑
results = await chunks_vdb.query(query, top_k=query_param.top_k)
chunks_ids = [r["id"] for r in results]
chunks = await text_chunks_db.get_by_ids(chunks_ids)
工作机制:
- 向量相似度计算:将用户查询转换为向量,与预存的文本块向量进行相似度计算
- 快速匹配:使用高效的向量数据库(NanoVectorDBStorage)进行毫秒级搜索
- 智能截断:根据
naive_max_token_for_text_unit参数控制返回内容的长度,确保不超出LLM的处理能力
第二层:知识图谱检索 - 发现深层关联
这是VideoRAG的核心创新之一,通过知识图谱发现实体间的深层关联。
# 核心实现流程
query_for_entity_retrieval = await _refine_entity_retrieval_query(query, query_param, global_config)
entity_results = await entities_vdb.query(query_for_entity_retrieval, top_k=query_param.top_k)
entity_retrieved_segments = await _find_most_related_segments_from_entities(
global_config["retrieval_topk_chunks"], node_datas, text_chunks_db, knowledge_graph_inst
)
智能机制:
- 实体匹配:在实体向量数据库中找到与查询最相关的实体
- 图遍历算法:通过知识图谱的关系链发现间接相关的内容
- 关系计数分析:计算实体与文本块的关联强度,选择最相关的视频片段
- 跨视频统一:利用实体统一机制,发现跨多个视频的相关内容
第三层:视觉内容检索 - 直击视觉本质
这一层直接在视觉特征空间中进行搜索,能够找到在文本描述中可能被遗漏的视觉信息。
# 视觉检索实现
query_for_visual_retrieval = await _refine_visual_retrieval_query(query, query_param, global_config)
segment_results = await video_segment_feature_vdb.query(query_for_visual_retrieval)
技术特点:
- ImageBind编码:使用先进的多模态模型将文本查询转换为视觉特征向量
- 视觉相似度计算:在高维视觉特征空间中进行精确匹配
- 场景级检索:能够理解和匹配复杂的视觉场景和动作
2.3 结果融合与过滤:智能决策的艺术
当三个检索通道都返回结果后,VideoRAG面临一个关键挑战:如何将这些来自不同源头的信息智能地融合在一起?这就像一个法官需要综合多方证据做出最终判决。
智能融合策略
# 结果合并逻辑
retrieved_segments = list(entity_retrieved_segments.union(visual_retrieved_segments))
retrieved_segments.sort(key=lambda x: (x.split("_")[0], int(x.split("_")[1])))
融合原则:
- 去重处理:自动移除重复的视频片段,避免信息冗余
- 时序排序:按照视频名称和片段索引进行排序,保持逻辑连贯性
- 权重平衡:不同检索通道的结果享有同等权重,确保信息的全面性
LLM驱动的智能过滤
这是VideoRAG的另一个创新点:使用大型语言模型作为"智能过滤器"。
# 过滤机制实现
async def _filter_single_segment(knowledge, segment_key_dp):
segment_key, caption = segment_key_dp
filter_prompt = PROMPTS["filtering_segment"].format(
caption=caption, knowledge=knowledge
)
result = await use_model_func(filter_prompt, **llm_kwargs)
return result, segment_key
过滤机制的工作原理:
- 相关性评估:LLM会阅读每个视频片段的粗略字幕,判断其是否与用户查询相关
- 并行处理:所有候选片段同时进行过滤,提高处理效率
- 智能决策:LLM返回"yes"或"no"的判断,只有相关的片段才会被保留
- 兜底机制:如果所有片段都被过滤掉,系统会保留所有原始检索结果,确保不会出现"无结果"的情况
2.4 上下文生成与回答:精雕细琢的最终呈现
经过前面的层层筛选,VideoRAG已经获得了最相关的视频片段和文本内容。现在需要将这些"原材料"加工成用户能够理解的高质量回答。
精细化字幕生成
对于筛选出的视频片段,VideoRAG会生成更加详细和准确的字幕:
# 详细字幕生成
keywords_for_caption = await _extract_keywords_query(query, query_param, global_config)
retreived_video_context = await retrieved_segment_caption(
remain_segments, keywords_for_caption, global_config
)
字幕生成的技术细节:
- 关键词引导:使用从查询中提取的关键词指导字幕生成,确保重点突出
- MiniCPM-V模型:采用先进的视觉语言模型生成高质量的视频描述
- 多帧采样:根据
fine_num_frames_per_segment参数从每个片段中采样多个关键帧 - 上下文感知:结合原始转录和视觉信息,生成更加准确和丰富的描述
综合上下文构建
VideoRAG将文本检索结果和视频信息整合成一个完整的上下文:
# 上下文整合
retreived_chunk_context = "-----New Chunk-----\n".join([c["content"] for c in maybe_trun_chunks])
sys_prompt = PROMPTS["videorag_response"].format(
context_data=retreived_chunk_context,
video_data=retreived_video_context,
user_question=query
)
上下文构建的关键要素:
- 信息分层:文本信息和视频信息分别组织,便于LLM理解和处理
- 逻辑排序:按照时间顺序和逻辑关系组织信息,确保连贯性
- 格式优化:使用特定的分隔符和格式,帮助LLM更好地解析信息
最终回答生成
# 最终回答生成
response = await use_model_func(sys_prompt, **llm_kwargs)
在这个最后阶段,VideoRAG使用精心设计的系统提示,将所有收集到的信息传递给大型语言模型。LLM会:
- 信息综合:将来自多个源头的信息整合成连贯的回答
- 逻辑推理:基于提供的证据进行逻辑推理和分析
- 语言优化:生成流畅、准确、易懂的自然语言回答
- 质量控制:确保回答的准确性、完整性和相关性
特殊处理:多项选择题
对于多项选择题,VideoRAG采用专门的处理流程:
# 多项选择题处理
sys_prompt = PROMPTS["videorag_response_for_multiple_choice_question"].format(
context_data=retreived_chunk_context,
video_data=retreived_video_context,
user_question=query
)
系统会返回JSON格式的结构化答案,包含:
- Answer:选择的答案标签(A、B、C、D等)
- Explanation:详细的解释说明,基于检索到的视频和文本证据
这种设计确保了VideoRAG不仅能够处理开放式问题,还能够在标准化测试场景中提供准确、可解释的答案。
技术创新点总结
-
多模态信息保真:通过双通道设计,既保留了语义信息的结构化优势,又保持了视觉信息的原始丰富性
-
跨视频知识统一:创新的实体合并机制实现了跨视频的语义一致性,构建了真正的全局知识图谱
-
智能查询优化:针对不同检索通道设计专门的查询优化策略,显著提升检索精度
-
分层检索架构:三层检索策略确保了从不同维度发现相关内容,提高了检索的召回率和准确率
-
LLM驱动决策:在关键节点引入大型语言模型的推理能力,提升了系统的智能化水平
实验结果
为了验证VideoRAG的有效性,研究者构建了一个名为 LongerVideos 的新基准数据集。该数据集包含超过160个视频,总时长超过134小时,涵盖讲座、纪录片和娱乐三大类别,远超现有数据集的规模和复杂度。
在LongerVideos上的综合评估表明:
- 性能优越:与现有的RAG替代方案和大型视觉模型相比,VideoRAG在处理超长视频内容方面表现出显著的性能优势。
- 组件有效性:消融实验证明,基于图的知识构建和多模态检索机制对提升模型性能至关重要。
- 案例研究:在一个关于OpenAI发布的12天系列讲座的具体案例中,VideoRAG成功地根据“评分者(graders)在强化学习微调中的作用”这一复杂问题,精准定位到了相关视频片段,并生成了比其他模型(如LightRAG)更深入、更具技术细节的回答,充分展示了其在真实场景中的应用潜力。
总而言之,VideoRAG框架通过其独特的双通道架构,成功地解决了超长视频理解中的关键挑战,为视频内容的知识检索和生成任务开辟了新的可能性。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 50
50 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)