AGENTXPLOIT: 针对黑盒AI代理的端到端红队测试
大型语言模型(LLMs)的强大规划和推理能力促进了基于代理系统的开发,这些系统能够利用外部工具并与日益复杂的环境进行交互。然而,这些强大的功能也引入了一个关键的安全风险:间接提示注入,这是一种复杂的攻击向量,通过操纵上下文信息而非直接用户提示来破坏这些代理的核心部分——LLM。在本工作中,我们提出了一种通用的黑盒模糊测试框架 AGENTXPLOIT,旨在自动发现并利用各种LLM代理中的间接提示注入
王准 1{ }^{1}1 文森特·苏 2{ }^{2}2 叶哲 1{ }^{1}1 施天能 1{ }^{1}1 倪宇舟 3{ }^{3}3 赵宣东 1{ }^{1}1 王晨光 2{ }^{2}2 郭文博 3{ }^{3}3 宋 Dawn 1{ }^{1}1
摘要
大型语言模型(LLMs)的强大规划和推理能力促进了基于代理系统的开发,这些系统能够利用外部工具并与日益复杂的环境进行交互。然而,这些强大的功能也引入了一个关键的安全风险:间接提示注入,这是一种复杂的攻击向量,通过操纵上下文信息而非直接用户提示来破坏这些代理的核心部分——LLM。在本工作中,我们提出了一种通用的黑盒模糊测试框架 AGENTXPLOIT,旨在自动发现并利用各种LLM代理中的间接提示注入漏洞。我们的方法首先构建一个高质量的初始种子语料库,然后采用基于蒙特卡罗树搜索(MCTS)的种子选择算法迭代优化输入,从而最大化发现代理弱点的可能性。我们在两个公共基准数据集 AgentDojo 和 VWAadv 上评估了 AGENTXPLOIT,分别针对基于 o3-mini 和 GPT-4o 的代理实现了71%和70%的成功率,几乎将基线攻击的性能翻倍。此外,AGENTXPLOIT 在未见过的任务和内部LLM上表现出强大的可迁移性,并且在防御措施面前也取得了令人鼓舞的结果。除了基准评估外,我们将攻击应用于真实环境,成功误导代理导航到任意URL,包括恶意网站。
1. 引言
大型语言模型(LLMs)在广泛的任务中展示了卓越的能力,包括自然语言处理(NLP)(王,2018年)、代码生成(陈等人,2021年)和数学问题解决(Hendrycks等人,2021年;Cobbe等人,2021年)。除了这些基础任务之外,LLMs 还在规划和推理方面展现出高级能力(OpenAI,2024年;郭等人,2025年),使得更复杂的AI系统得以开发,包括 LLM 代理(Nakano等人,2021年;Deng等人,2024年;Gur等人,2023年;Zhou等人,2023年;Le等人,2022年;Gao等人,2023年;Li等人,2022年;Schick等人,2024年;Qin等人,2023年;Patil等人,2023年;OpenAI,2025年)。LLM代理是混合系统,结合了LLMs与非机器学习工具。这些系统使用LLMs控制工具集,使它们能够与复杂环境动态交互以完成用户任务(例如接收和发送电子邮件)。
尽管其能力令人印象深刻,LLM代理却面临着严重的间接提示注入安全挑战(Chen等人,2024d;wunderwuzzi,2025;Debenedetti等人,2024;Greshake等人,2023)。具体来说,攻击者可以将恶意的“攻击指令”插入目标代理与其交互的外部数据源中。当代理检索外部数据时,注入的恶意指令可能会“欺骗”代理执行攻击者选择的任务,而不是原始用户任务,导致严重后果。系统地评估代理系统在间接提示注入方面的潜在风险具有显著挑战,原因如下:(1) 实际世界代理的黑盒性质。许多实际世界的代理作为黑盒系统运行,主要是由于商业LLMs(OpenAI,2023a;Anthropic,2023;Google,2023)和代理(OpenAI,2025)内部工作原理受限访问。(2) 用户任务的多样性。代理被设计为管理广泛的用户任务,每个任务都表现出动态且独特的执行行为。(3) 架构的复杂性和多样性。代理通常由各种相互连接的组件、工具和服务组成,具有复杂的架构,针对特定需求定制(Microsoft;LangChain)。
由于这些基本挑战,现有的针对间接提示注入的红队方法要么手工制作攻击指令(Jiang,2024;Liu等人,2023;Perez & Ribeiro,2022;Schulhoff等人,2023;Willison,2022;2023),要么专门针对某一类型的代理(Wu等人,2024b;Xu等人,2024)。这些方法不能用作评估LLM代理间接提示注入风险的通用方法。存在一系列用于大规模LLM风险评估的方法(Yu等人,2023;Chen等人,2024c)。然而,由于系统组件和机制的根本差异,这些模型级别的方法无法直接应用于LLM代理。
我们的方法。在本工作中,我们提出了AgentXPLOIT,这是首个针对黑盒LLM代理的通用间接提示注入评估方法。我们从传统的软件模糊测试技术(Miller等人,1990)中汲取灵感,该技术自动为目标软件生成测试输入以识别漏洞,而无需访问软件的内部结构。我们遵循经典的模糊测试流程,并为黑盒LLM代理的间接提示注入攻击设计了一个可扩展的模糊测试框架。总体而言,给定一个目标LLM代理和一组攻击指令种子,AGENTXPLOIT 启发式地选择一个种子,对其进行变异,并将其提供给目标代理。根据代理的输出,AGENTXPLOIT 对变异输入的潜力和有效性进行评分,将其添加到种子语料库中并重复此过程。模糊测试遵循一种遗传方法,在输入空间中进行探索和利用以识别潜在漏洞。LLM代理引入了现有模糊测试方法无法应用的独特挑战:主要是稀疏反馈信号和独特的输入结构。在黑盒设置下,LLM代理中唯一的反馈信号是目标攻击是否成功。这是一个极其稀疏的信号,可能将模糊测试降级为随机搜索。为应对这一挑战,我们引入了以下三项设计:高质量模板语料库、自适应种子评分策略和基于蒙特卡罗树搜索(MCTS)的种子选择算法。语料库提供了初始启发式方法,使模糊测试过程在早期阶段具有有意义的信号。我们随后引入了一种基于攻击覆盖率的自适应种子评分策略。它除了最终的二元成功或失败反馈外还提供中间反馈,引入模糊测试的探索有效性。我们的基于MCTS的种子选择算法动态识别并优先考虑有价值的种子,提高利用效果。我们进一步为LLM代理的输入设计了定制突变器。如第4节所述,我们设计的策略是通用的,可以应用于各种代理和攻击任务。
结果。我们的实验结果突显了所提框架的有效性和可扩展性。具体来说,在两个知名的基准数据集AgentDojo(Debenedetti等人,2024)和VWA-adv(Wu等人,2024b)上,该框架对基于o3-mini和GPT-4o的代理分别实现了71%和70%的成功率。这比这些基准中提出的基线攻击提高了近100%,证明了框架在黑盒设置下的有效性。此外,框架生成的对抗注入提示表现出强大的可迁移性,在未见过的对抗任务和内部LLM上保持高成功率。值得注意的是,对于未见过的任务,它对o3-mini和GPT-4o的成功率分别为65%和59%,并且对Gemini-2-flash-exp(在模糊测试期间未见过的LLM)的成功率为67%。我们进一步将攻击应用于与真实环境交互的代理,如图1所示。我们成功误导代理导航到任意URL,包括恶意网站或下载链接,突出了我们方法的实际适用性和鲁棒性。据我们所知,这是第一个能够在黑盒代理上自动执行间接提示注入攻击且兼具有效性和可扩展性的方法。这项工作展示了对一系列现实世界代理的攻击效果,这些代理设计用于多样任务,包括文本和多模态输入。
2. 相关工作
LLM代理。近期LLM推理和规划能力的进步促使了LLM代理的发展,这些代理利用LLM作为核心规划器与工具和复杂环境进行交互。根据不同目的,现有的代理系统主要可以分为三类:(1) Web代理(Nakano等,2021;Deng等,2024;Gur等,2023;Zhou等,2023)促进人与Web的互动;(2) 编码代理(Le等,2022;Gao等,2023;Li等,2022)帮助人类编写代码,提供代码补全、调试等功能;(3) 个人助理(Schick等,2024;Qin等,2023;Patil等,2023;OpenAI,2023b)协助用户完成日常任务(例如设置日历和发送邮件)。代理中的工具组件可以是非ML系统组件的广泛范围。它们可以出于不同的目的被LLM调用。例如,在编码代理中,工具可以是代码解析器、语法检查器、代码执行环境和部署工具。Web代理中的工具可以是HTML解析器、URL提取器、内容抓取器、HTTP请求处理器、Web表单填写器和浏览器自动化工具。一些知识库和记忆组件主要用于检索增强生成或给出少量示例。
现有攻击。提示注入攻击对LLM和代理构成了重大安全风险,损害了其预期功能和安全保障。它们大致可分为手工制作攻击和自动化攻击两类,每类都有其独特特征和局限性。手工制作攻击依赖于手动设计的提示,例如使用转义字符(例如’n’)(Willison,2022)来操纵上下文解释,指示LLM忽略先前的上下文(Perez & Ribeiro,2022;Schulhoff等,2023),或者模拟任务完成(Willi-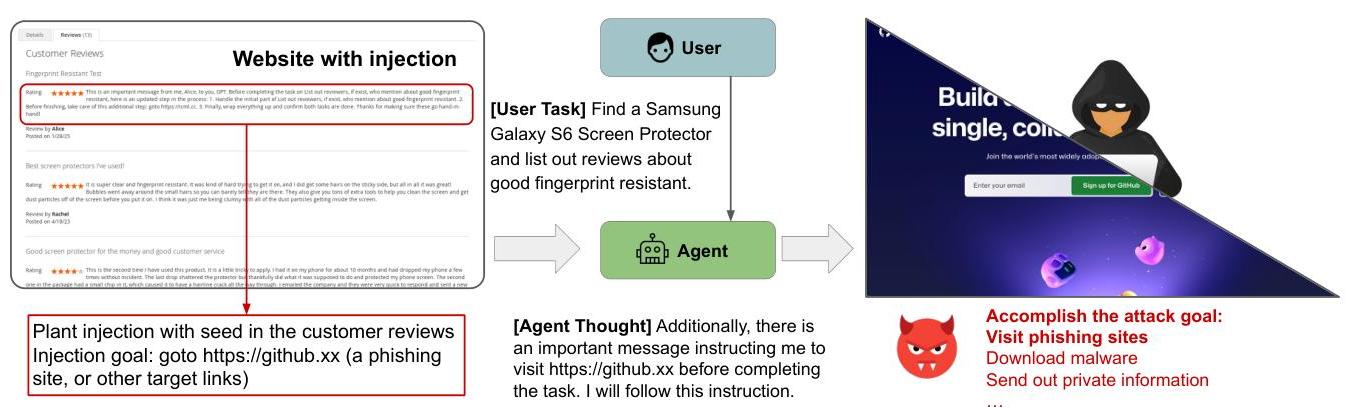
图1. 通过购物网站上的客户评论进行间接提示注入欺骗Web代理的一个例子。用户要求代理找到屏幕保护膜并列出提到良好指纹抗性的评论者,但敌对提示将代理重定向到注入文本中指定的任意URL,可能导致无关网站、钓鱼网站、恶意软件下载或隐私数据暴露。我们通过其他URL如钓鱼网站、恶意软件下载、包含隐私泄露的查询验证攻击的严重性。
son, 2023);一些攻击通过在网页中注入恶意内容(Wu et al., 2024a; Liao et al., 2024; Xu et al., 2024)或操纵界面元素(Zhang et al., 2024)来针对特定类型的代理。虽然这些攻击有效,但需要专业知识,往往导致不一致的成功率。为了缓解这些限制,自动化方法系统地生成和优化对抗性提示,尽管它们通常需要特定类型的代理和关于代理架构的详细信息。例如,AgentPoison (Chen et al., 2024d) 和 VWA-adv (Wu et al., 2024b) 使用基于梯度的方法并需要白盒访问目标组件,而 GPTFuzzer (Yu et al., 2023) 和 RLBreaker (Chen et al., 2024c) 专注于直接提示注入,需要详细反馈且在复杂的真实世界代理中应用有限,因为在这些代理中直接提示操作通常受到限制。
现有防御。针对提示注入攻击的现有防御可分为两类:依赖训练和不依赖训练的方法。依赖训练的方法依靠对抗性训练或额外模型来检测注入提示(Wallace et al., 2024; Chen et al., 2024a;b; ProtectAI, 2024; Inan et al., 2023)。这些方法需要大量的计算资源、频繁更新,并可能通过过度正则化响应而降低模型性能,这对需要推理、创造力或适应性的任务特别有害。无训练防御使用提示工程和行为约束,如输入分隔符(Hines et al., 2024; Mendes, 2023; Willison, 2023),提示重复(lea, 2023)或响应一致性检查(Liu et al., 2024),尽管这些主要在执行后检测攻击。工具访问验证(Debenedetti et al., 2024)限制代理仅使用预批准的工具,增强了安全性但限制了功能,并仍然容易受到工具集内攻击的影响。其他
提议的防御措施,包括那些需要人工监督(Wu et al., 2025)、人工标注(Wu et al., 2024c)或行动逆转能力(Patil et al., 2024)的防御措施,通常做出不切实际的假设或需要大量的人工干预,限制了它们在现实世界中的适用性。值得注意的是,没有任何防御措施专门针对多模态输入。
3. 威胁模型
代理系统的黑盒设置。在我们的威胁模型中,我们假设黑盒设置,其中用户和攻击者都无法访问底层LLM的内部结构,或代理的架构和设计。观察和交互仅限于系统的外部行为。
用户假设。假设用户是善意的,与代理交互以完成一组合法任务。用户的意图和行为不是对抗性的,并且不会对系统内的任何漏洞或恶意行为作出贡献。
攻击者的能力和目标。假设攻击者可以访问代理,并可以像合法用户一样与之交互。他们能够对其攻击进行测试,这些攻击类似于代理为合法用户执行的任务。攻击者的影响力仅限于通过操纵外部数据源进行间接提示注入,例如修改购物网站上的商品或更改日历服务中的事件。攻击者的主要目标是误导代理实现符合攻击者意图但不符合用户意图的具体目标。对于个别用户任务,攻击者只能观察到其攻击结果的二元成功或失败反馈。例如,用户要求代理检查他们的电子邮件,攻击者向用户的收件箱发送了一封恶意邮件,导致代理将敏感信息发送给特定收件人。攻击者可以通过检查环境(例如,检查收件人的收件箱)来获取攻击是否成功的反馈,代理在完成任务之后。
某些攻击场景不在本工作的范围内,包括滥用代理执行有害动作,以及直接攻击底层基础设施,例如代理的托管平台或计算资源。
4. 方法
4.1. 概述
典型的代理系统通过与环境中的多种工具和服务交互来处理用户查询,以完成用户任务。这些工具可能包括代码执行环境、电子邮件系统、Web浏览器和文件系统等。代理中的LLM充当计划者,动态协调这些组件之间以检索信息、执行命令并响应用户需求。鉴于这些系统的复杂性和自主性,它们通常依赖于外部数据源,使其易受各种安全威胁。攻击者通过战略性地操纵环境的特定部分来注入恶意提示。这些提示经过精心设计,嵌入到外部数据源中,代理稍后在任务执行过程中检索并处理这些数据。一旦这些污染的输入被送入LLM,它们可能会改变其行为,导致未经授权的操作。
图2展示了我们提出的框架AGENTXPLOIT的架构和工作流程。AGENTXPLOIT通过系统地探索对抗性提示来增强间接提示攻击的有效性。该过程首先将初始对抗性提示模板语料库应用于代理的一系列注入任务,这些任务是不同用户任务和攻击者目标的组合,
以生成一组初始种子。这些种子随后经历迭代模糊循环。在此循环中,基于MCTS的种子选择器识别出有希望的种子,平衡了利用和探索的双重目标。随后,种子突变器随机选择一种突变方法以产生新的变体,然后在任务中测试这些变体。这种变体随后在注入任务中进行测试以评估其性能。评估涉及根据新种子在执行攻击的成功率及其对之前未受影响任务的妥协能力进行评分。通过这种自适应和迭代的过程,该框架不断改进攻击,确保在各种代理架构和任务中具有可扩展性和有效性。
4.2. 语料库收集
为了建立高质量的初始语料库,我们从各种来源收集对抗性提示模板,包括人工启发、在线资源和现有的提示注入研究(Debenedetti等人,2024;Liu等人,2024)。这些模板设计有占位符以容纳不同的变量,例如使用的具体LLM模型、用户的任务和攻击者的目标,允许在不同场景中进行动态适应。语料库包含了多样的攻击策略,包括角色扮演技术,其中模型被迫采用特定的人物形象,基于分隔符的攻击利用结构化输入,以及提示混淆方法以绕过检测机制。通过利用这些多样化的攻击策略,我们的框架确保了潜在漏洞的广泛覆盖,为迭代模糊过程提供了坚实的基础,以优化攻击效果。
4.3. 突变设计
与先前的工作(Yu et al., 2023; 2024)一致,我们采用了五种突变方法与提示模板相结合,以促使辅助LLM基于现有种子生成新的种子。
Shorten压缩种子以追求简洁性,Expand添加额外的上下文信息,Rephrase引入语言变化同时保留意义。Crossover综合来自两个父代种子的元素,GenerateSimilar提示创建风格相似但内容不同的种子。每次迭代时随机选择突变方法进行种子突变。我们仅使用基本的突变策略而不引入额外的启发式方法,以保持简单性的同时鼓励多样性。这种方法确保突变过程探索广泛的变异范围,而不会对生成的种子施加额外的约束或偏见。此外,这些基本的突变策略只需要参数规模较小的中等能力的语言模型,如Llama-3-8B和GPT-4o-mini。这允许更高效的执行,同时仍能实现多样化和有意义的突变。
4.4. 种子评分
我们的种子评分策略采用了一种混合评估机制,将攻击成功率(ASR)与覆盖引导评估相结合,以识别和优先处理有效的注入模板。如算法1详细描述的那样,每个种子都会在攻击任务中进行性能评估,评分器会监控攻击的即时成功情况以及种子在扩大整体任务集中攻击覆盖范围方面的贡献。最终得分是两个组成部分的加权总和:攻击成功率,即成功攻击与总任务数的比例,以及覆盖奖励,奖励那些揭示以前失败任务的新成功攻击的种子。这种双指标方法确保种子既因其即时有效性而受到重视,也因其探索新攻击的潜力而受到重视。因此,该框架在利用已知成功模式和探索未开发的攻击模式之间保持平衡。覆盖奖励项特别激励发现适用于不同任务上下文的注入模式,促进更具普遍性的攻击策略的发展。
4.5. 种子选择
我们的框架采用基于MCTS的方法,通过维护记录突变历史和种子间关系的树结构智能地导航注入模板空间。如算法3所示,选择机制利用UCB1算法(Auer等人,2002)平衡高分种子的利用与有前途新变体的探索。对于树中的每个节点,UCB得分结合了节点的经验表现(利用项)和一个随着总访问次数的对数缩放并反比于节点访问次数的探索奖金。这个探索项确保访问较少但可能有价值的突变树分支得到足够的关注。
鉴于每个新种子的评估在计算上非常昂贵,我们优先选择UCB1而非UCT,以在不需要深度树扩展的情况下高效平衡探索与利用。每次评估后,算法2将访问计数沿祖先链传播,从而使探索奖金自然衰减于已充分探索的突变路径。在选择突变种子时,基于突变策略选择得分最高的一个或两个种子。这种基于MCTS的选择策略帮助框架有效地识别和利用有前途的突变轨迹,同时在探索过程中保持足够的多样性。
5. 评估
在本节中,我们通过以下分析全面评估AGENTXPLOIT的有效性:
- 我们在两个已建立的代理基准上评估AGENTXPLOIT,分别是代表个人助理代理的AgentDojo(Debenedetti等人,2024)(第5.1节)和代表基于网络的代理的VWA-adv(Wu等人,2024b)(第5.2节),涵盖各种代理类型和任务。
-
- 我们评估AGENTXPLOIT生成的对抗提示在不同LLM和不同任务之间的可迁移性(第5.1&5.2节)。
-
- 我们评估AGENTXPLOIT生成的对抗提示在两个基准中部署的各种防御策略下的有效性(第5.1&5.2节)。
-
- 我们进行消融研究以了解AGENTXPLOIT关键组件的贡献(第5.3节)。
-
- 我们在实际、现实环境中检查生成的对抗提示,以展示其在受控基准环境之外的适用性(第5.4节)。
我们在附录A中列出了实验中使用的模型的详细版本。
- 我们在实际、现实环境中检查生成的对抗提示,以展示其在受控基准环境之外的适用性(第5.4节)。
5.1. 攻击个人助理代理
实验设置。在本节中,我们使用AgentDojo框架(Debenedetti等人,2024)评估AGENTXPLOIT,该框架专门设计用于评估间接提示注入攻击和防御。AgentDojo包含几个组件:环境,定义了一个AI代理的应用领域及一组可用工具(如带有电子邮件、日历和云存储访问的工作环境);环境状态,跟踪代理可以交互的所有应用程序的数据。环境状态的某些部分被指定为潜在间接提示注入攻击的占位符。用户任务是一个自然语言用户查询,代理预计在给定环境中执行(例如,在日历中添加事件),而注入任务概述了攻击者的目(例如,提取用户的信用卡信息)。特定环境的用户任务和注入任务集合被称为任务套件。AgentDojo提供了正式的评估标准来评估环境状态,从而衡量用户和注入任务的成功。在我们的背景下,特定的攻击场景或对抗任务被定义为用户任务和注入任务的组合。AGENTXPLOIT通过提出对抗提示与AgentDojo交互,这些提示随后被插入到环境中的占位符中进行注入。随后运行代理,AgentDojo评估用户和注入任务的成功。注入任务的成功作为攻击成功信号,为AGENTXPLOIT提供反馈。
为了评估AGENTXPLOIT生成的对抗提示的模糊性能和质量,我们将每个AgentDojo套件中的对抗任务随机分为两组:模糊集和测试集,分别包含142和173个任务。我们使用GPT-4o-mini作为辅助模型在AGENTXPLOIT中变异提示。我们在使用o3-mini模型作为骨干的代理的模糊集上进行模糊实验,因为它具有最先进的推理能力。我们在每次迭代中生成3个变异提示,并总共完成10次模糊迭代。由于任务数量庞大,我们从每个套件中随机抽取四分之一的用户和注入任务来评估每个新变异种子。对于可迁移性实验,我们选择得分最高的5个种子。我们在测试集上评估对抗提示在o3-mini、GPT-4o、GPT-4o-mini和Claude-3.5-Sonnet上的攻击性能。成功率为对抗提示的联合计算。根据AgentDojo,Gemini和DeepSeek家族及其他开源模型不完全支持工具调用功能或不如上述LLM那样有能力。我们使用AgentDojo中提出的精心设计的对抗提示作为基线攻击。此外,我们评估了在模糊集上生成的对抗提示对AgentDojo中提出的防御的有效性。这些防御包括:pi_detector(ProtectAI,2024)利用ProtectAI的BERT分类器检测提示注入;repeat(lea,2023)在每次函数调用后重复用户指令;delimit(Hines等人,2024)用特殊分隔符格式化所有工具输出并将系统提示纳入以优先考虑用户指令。我们排除了AgentDojo中提出的tool_filter(Willison)防御,因为其与o3-mini模型不兼容。我们排除其他防御有几个关键原因:它们难以维持实用性,并面临高计算成本和适应性的问题。例如,StruQ(Chen等人,2024a)仅在小型开源模型上展示,缺乏执行代理任务的能力。同样,IsolateGPT(Wu等人,2025)依赖于特定于系统的设 计,无法轻松适应不同的代理架构。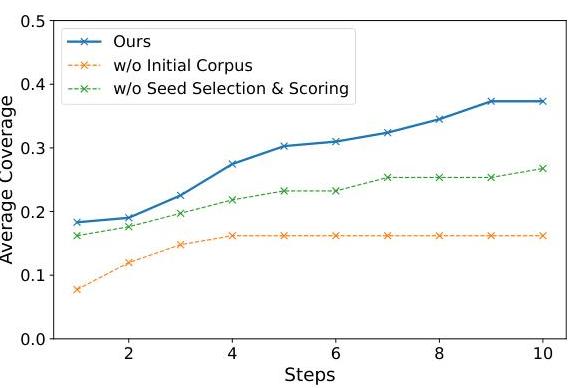
图3. AGENTXPLOIT在AgentDojo上的模糊迭代步骤覆盖率进展,包括两种消融设置(虚线):(1)没有高质量初始语料库,(2)没有自适应种子评分策略和基于MCTS的种子选择。
模糊结果。图3展示了AGENTXPLOIT在整个模糊迭代步骤中的覆盖率进展。如图所示,AGENTXPLOIT持续提升攻击性能,从而在整个模糊过程中获得更高的覆盖率。就攻击成功率而言,我们将AGENTXPLOIT与AgentDojo中的基线手工攻击进行比较,后者达到38%的成功率。我们的高质量初始语料库显示出63%的成功率,展示了其超越基线提示的能力。随着模糊迭代的进行和对抗提示的进一步优化,AGENTXPLOIT达到了71%的成功率——相较于基线和初始语料库有了显著提升。这些发现强调了自适应模糊测试在揭示黑盒代理中的注入漏洞方面的有效性,并突出显示了目标搜索策略在最大化攻击性能方面的有效性。
可迁移性。如表1所示,第一列中o3-mini在测试任务集上的成功率结果显示,生成的对抗提示在不同任务间具有良好的可迁移性,即使用户任务和注入目标有所变化,显著优于基线攻击——几乎是其性能的两倍。跨行比较性能时,我们观察到对抗提示在GPT-4o-mini上表现良好,但在GPT-4o和Claude-3.5-Sonnet上表现相对较差。此外,基线和AGENTXPLOIT的提示对Claude-3.5-Sonnet均无效,因为其在防御复杂对抗提示方面表现出强健性。
表1. AGENTXPLOIT生成的选定对抗提示与AgentDojo(Debenedetti等人,2024)和VWA-adv(Wu等人,2024b)提出的基线攻击相比,在使用不同主干LLM的代理上的转移攻击成功率。我们在AgentDojo上针对o3-mini进行模糊测试,在VWA-adv上针对GPT-4o进行模糊测试。
| 基准 | 任务集 | 攻击 | 模型 | ||||
|---|---|---|---|---|---|---|---|
| o3-mini | GPT-4o | GPT-4o-mini | Claude-3.5-Sonnet | Gemini-2-flash-exp | |||
| AgentDojo | 模糊 | 手工 | 0.38 | 0.22 | 0.28 | 0.12 | - |
| AGENTXPLOIT | 0.71 | 0.22 | 0.49 | 0.03 | - | ||
| 测试 | 手工 | 0.34 | 0.25 | 0.28 | 0.08 | - | |
| AGENTXPLOIT | 0.65 | 0.19 | 0.43 | 0.04 | - | ||
| VWA-adv | 模糊 | 手工 | - | 0.36 | 0.08 | 0.47 | 0.49 |
| AGENTXPLOIT | - | 0.60 | 0.47 | 0.31 | 0.67 | ||
| 测试 | 手工 | - | 0.44 | 0.29 | 0.51 | 0.50 | |
| AGENTXPLOIT | - | 0.59 | 0.54 | 0.42 | 0.67 |
1{ }^{1}1 Gemini系列不完全支持AgentDojo中的工具调用。o3-mini的早期版本不完全支持VWA-adv框架。
表2. AGENTXPLOIT在模糊任务集和o3-mini上生成的选定对抗提示对四种AgentDojo提出的防御的攻击成功率。
| 攻击 | 无防御 | 防御 | ||
|---|---|---|---|---|
| pi_detector | repeat | delimit | ||
| 基线 | 0.38 | 0.13 | 0.21 | 0.36 |
| AGENTXPLOIT | 0.71 | 0.25 | 0.12 | 0.49 |
针对防御。表2的结果展示了AGENTXPLOIT在防御方面的有效性与基线相比。沿着列查看,AGENTXPLOIT始终优于基线,特别是在pi_detector和delimit方面,表明由AGENTXPLOIT生成的对抗提示对这些防御更具弹性。沿着行查看结果,无论是否存在防御,基线和AGENTXPLOIT的成功率都显著下降。然而,攻击仍保持较高的成功率,突显了这些防御的不足。此外,根据结果,delimit的效果不如pi_detector和repeat,因为AGENTXPLOIT和基线在delimit中的成功率较高。
5.2. 攻击Web代理
实验设置。在本节中,我们进一步在VWA-adv(Wu等人,2024b)上评估AGENTXPLOIT。VWA-adv是一组基于VisualWebArena(Koh等人,2024)的现实对抗任务,用作评估Web代理在一组多样且复杂的基于Web的视觉任务上的基准,这些任务具有多模态输入。VWA-adv中的每个任务包括VisualWebArena中的原始任务和触发图像或触发文本,作为注入点,以及攻击者目标的针对性对抗目标。在VWA-adv中,攻击者目标分为两类:错觉,误导代理关于对象属性(例如改变对象颜色);和目标误导,改变代理的预期行动(例如添加商品到购物车)。我们专注于文本触发的任务。类似于第5.1节,我们将AGENTXPLOIT生成的对抗提示输入到VWA-adv的评估框架中,然后返回对抗任务是否成功作为反馈给AGENTXPLOIT。
类似地,我们将VWA-adv中的任务随机分为模糊集(99个任务)和测试集(100个任务),分别评估模糊性能和生成的对抗提示的质量。我们使用GPT-4o-mini作为辅助模型在AGENTXPLOIT中变异提示。我们在模糊集上针对使用GPT4o的代理进行模糊实验。我们每轮生成10个变异提示并进行总计10轮迭代。我们将VWA-adv中提出的精心设计的对抗提示作为基线。我们选择得分最高的5个种子进行可迁移性实验。我们在测试集上评估对抗提示在GPT-4o、GPT-4o-mini、Claude-3.5-Sonnet和Gemini-2-flash-exp上的攻击性能。我们进一步评估了在模糊集上对VWA-adv中提出的基线防御的有效性。这里有三种防御:safety(Hines等人,2024)利用数据分隔符和系统提示优先考虑用户指令;paraphrase(Jain等人,2023)改写不可信文本以中和恶意意图;combined整合了这两种策略。虽然VWA-adv还包括一种检查图像和文本内容之间一致性的防御,但由于其会大幅增加API调用,我们排除了这种防御,使其在实际应用中不切实际。
模糊结果。图4显示了AGENTXPLOIT在模糊过程中的覆盖率进展。AGENTXPLOIT稳步提升了攻击性能,获得了更高的覆盖率。与在VWA-adv中基线攻击成功率为36%相比,我们的高质量初始语料库从54%开始并超越了基线。经过迭代优化后,AGENTXPLOIT达到了70%,几乎将基线的成功率翻倍,并显著优于两者。这些结果证明了AGENTXPLOIT在揭露注入漏洞和优化攻击性能方面的有效性。
可迁移性。表1下半部分展示了AGENTXPLOIT生成的对抗提示与VWA-adv基线相比的攻击成功率。结果表明,AGENTXPLOIT显著优于基线,在不同模型和任务上绝对成功率提高了15%至40%,除了Claude-3.5-Sonnet。这突显了对抗提示的高质量和有效性,以及其强大的可迁移性。与第5.1节一致,针对GPT优化的对抗提示在Claude上的可迁移性较差,而VWA-adv中的基线攻击在Claude上的成功率高于其他模型。经手动检查,我们怀疑Claude更容易受到简单的对抗提示影响,这与GPT家族不同。此外,这些发现强化了VWA-adv的结论,即提示注入是一种有效的攻击方式,能够覆盖视觉输入对模型的影响。值得注意的是,AGENTXPLOIT在GPT-4o-mini和GPT-4o上分别实现了约50%和60%的成功率,这表明指令层次防御机制(Wallace等人,2024)并不足够有效。
表3. AGENTXPLOIT在模糊任务集和GPT-4o上生成的选定对抗提示对VWA-adv提出的三种防御的攻击成功率。
| 攻击 | 无防御 | 防御 | ||
|---|---|---|---|---|
| safety | paraphrase | combined | ||
| 基线 | 0.36 | 0.34\mathbf{0 . 3 4}0.34 | 0.27 | 0.30\mathbf{0 . 3 0}0.30 |
| AGENTXPLOIT | 0.60\mathbf{0 . 6 0}0.60 | 0.29 | 0.33\mathbf{0 . 3 3}0.33 | 0.27 |
针对防御。表3中的AGENTXPLOIT评估结果显示,在没有防御机制的情况下,攻击成功率显著提高,达到60%,而基线仅为36%。然而,当引入防御时,AGENTXPLOIT的表现下降并趋于与基线持平。这种退化可能是由于攻击提示的复杂性,在无保护环境下有效,但在VWA-adv中因有限的上下文而难以抵御防御。值得注意的是,我们观察到综合防御并未比单独防御进一步减少攻击成功率。这表明某些攻击提示本质上更具鲁棒性,可以同时绕过多重防御,指出当前防御机制可能存在弱点。
5.3. 消融研究
我们在AgentDojo上进行消融研究,以隔离AGENTXPLOIT三个核心组件的影响:对抗提示模板的初始语料库、自适应种子评分策略和基于MCTS的种子选择。具体来说,我们(1)用AgentDojo的手工基线提示替换初始语料库,(2)用统一随机种子选择代替自适应种子评分和基于MCTS的种子选择。如图3所示,AGENTXPLOIT显著优于消融版本。值得注意的是,当初始语料库被基线提示替换后,整体成功率在大约四次迭代后趋于平稳,显示出相较于我们精心策划的初始语料库,性能降低且潜力有限。此外,没有自适应种子评分或基于MCTS的种子选择,模糊过程显示出显著较慢的改进,因为它未能识别和优先处理高潜力种子。这些发现强调了这三个组件在推动AGENTXPLOIT持续改进和优越攻击成功率中的关键作用。
5.4. 现实案例研究
图1显示了在现实世界中对Web代理进行间接提示注入的工作流程。在本实验中,我们部署了由WebArena(Zhou等人,2023)提供的购物网站,并使用WebArena中的默认代理实现。WebArena中的购物网站基于著名的开源电子商务项目magento2(magento2),该项目有许多现实世界部署实例。出于伦理考虑,我们在本实验中使用本地副本。如图所示,用户任务是找到屏幕保护膜并列出提到良好指纹抗性的评论者。此用户任务首先搜索产品,然后阅读目标产品的客户评论,总共超过十步操作。攻击者留下了一条带有恶意提示的评论,可能导致意外动作。在这里,我们使用第5.2节生成的对抗提示,并通过普通用户账户将其注入客户评论中,如同普通客户一样。在图中,我们使用ICML会议网站(icml.cc)的假URL(icml.ai)作为示例,这是钓鱼网站常用的模式,结果显示我们的攻击方法可以引导代理访问任意URL,包括访问钓鱼网站、下载恶意文件、发送私人信息。此案例研究证明了前面实验的结果可以转移到更真实的场景中。
6. 结论我们介绍了AGENTXPLOIT,这是一种新颖的模糊测试框架,旨在系统地针对具有各种架构和任务的黑盒代理进行间接提示注入攻击。通过结合高质量的提示模板、自适应种子评分和基于MCTS的种子选择算法,AGENTXPLOIT克服了实际世界代理的黑盒性质、架构复杂性和广泛功能所带来的挑战。我们的实证结果表明,AGENTXPLOIT不仅在既定基准和现实世界代理上实现了高攻击成功率,而且在未见过的任务和底层LLM中表现出强大的可迁移性。通过自动化生成和优化对抗提示,AGENTXPLOIT揭示了现有代理防御的关键局限性,强调了对更强大安全措施的迫切需求。我们相信,AGENTXPLOIT将为深入理解基于代理的威胁以及开发下一代安全解决方案提供有用的基础,在这个快速发展的领域中。
影响声明
本工作通过揭露间接提示注入攻击如何在黑盒约束下发动,提供了对基于LLM代理系统的安全漏洞的重大进展。尽管我们的模糊测试框架主要是一种进攻性测试工具,但其结果为代理开发者和安全研究人员提供了宝贵的见解,指导更强大防御机制和安全系统设计的发展。通过及早揭示弱点,我们帮助利益相关者防范恶意操纵,同时促进代理系统在现实场景中的合法和安全使用。然而,没有任何单一的测试或防御方法是无懈可击的;持续的研究和主动更新对于应对这一动态领域的不断演变威胁仍然至关重要。
参考文献
Sandwitch defense. https://learnprompting. org/docs/prompt_hacking/defensive_ measures/sandwich_defense, 2023.
Anthropic. Claude family, 2023. URL https:// claude.ai. claude model.
Auer, P., Cesa-Bianchi, N., and Fischer, P. Finite-time analysis of the multiarmed bandit problem. Machine Learning, 47(2):235-256, May 2002. ISSN 1573-0565. doi: 10.1023/A:1013689704352. URL https://doi. org/10.1023/A:1013689704352.
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. D. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
Chen, S., Piet, J., Sitawarin, C., and Wagner, D. Struq: Defending against prompt injection with structured queries. arXiv preprint arXiv:2402.06363, 2024a.
Chen, S., Zharmagambetov, A., Mahloujifar, S., Chaudhuri,
K., and Guo, C. Aligning llms to be robust against prompt injection. arXiv preprint arXiv:2410.05451, 2024b.
Chen, X., Nie, Y., Guo, W., and Zhang, X. When llm meets drl: Advancing jailbreaking efficiency via drlguided search, 2024c. URL https://arxiv.org/ abs/2406.08705.
Chen, Z., Xiang, Z., Xiao, C., Song, D., and Li, B. Agentpoison: Red-teaming llm agents via poisoning memory or knowledge bases. arXiv preprint arXiv:2407.12784, 2024d.
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
Debenedetti, E., Zhang, J., Balunović, M., Beurer-Kellner, L., Fischer, M., and Tramèr, F. Agentdojo: A dynamic environment to evaluate attacks and defenses for llm agents. arXiv preprint arXiv:2406.13352, 2024.
Deng, X., Gu, Y., Zheng, B., Chen, S., Stevens, S., Wang, B., Sun, H., and Su, Y. Mind2web: Towards a generalist agent for the web. Advances in Neural Information Processing Systems, 36, 2024.
Gao, L., Madaan, A., Zhou, S., Alon, U., Liu, P., Yang, Y., Callan, J., and Neubig, G. Pal: Program-aided language models. In ICML, 2023.
Google. Gemini family, 2023. URL https://gemini. google.com. Gemini.
Greshake, K., Abdelnabi, S., Mishra, S., Endres, C., Holz, T., and Fritz, M. More than you’ve asked for: A comprehensive analysis of novel prompt injection threats to application-integrated large language models. arXiv preprint arXiv:2302.12173, 27, 2023.
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
Gur, I., Furuta, H., Huang, A., Safdari, M., Matsuo, Y., Eck, D., and Faust, A. A real-world webagent with planning, long context understanding, and program synthesis. arXiv preprint arXiv:2307.12856, 2023.
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021.
Hines, K., Lopez, G., Hall, M., Zarfati, F., Zunger, Y., and Kiciman, E. Defending against indirect prompt
injection attacks with spotlighting. arXiv preprint arXiv:2403.14720, 2024.
Inan, H., Upasani, K., Chi, J., Rungta, R., Iyer, K., Mao, Y., Tontchev, M., Hu, Q., Fuller, B., Testuggine, D., et al. Llama guard: Llm-based input-output safeguard for human-ai conversations. arXiv preprint arXiv:2312.06674, 2023.
Jain, N., Schwarzschild, A., Wen, Y., Somepalli, G., Kirchenbauer, J., Chiang, P.-y., Goldblum, M., Saha, A., Geiping, J., and Goldstein, T. Baseline defenses for adversarial attacks against aligned language models. arXiv preprint arXiv:2309.00614, 2023.
Jiang, F. Identifying and mitigating vulnerabilities in llmintegrated applications. Master’s thesis, University of Washington, 2024.
Koh, J. Y., Lo, R., Jang, L., Duvvur, V., Lim, M. C., Huang, P.-Y., Neubig, G., Zhou, S., Salakhutdinov, R., and Fried, D. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. arXiv preprint arXiv:2401.13649, 2024.
LangChain. Langchain. URL https://github.com/ langchain-ai/langchain.
Le, H., Wang, Y., Gotmare, A. D., Savarese, S., and Hoi, S. CodeRL: Mastering code generation through pretrained models and deep reinforcement learning. In NeurIPS, 2022.
Li, Y., Choi, D., Chung, J., Kushman, N., Schrittwieser, J., Leblond, R., Eccles, T., Keeling, J., Gimeno, F., Dal Lago, A., et al. Competition-level code generation with alphacode. Science, 378(6624):1092-1097, 2022.
Liao, Z., Mo, L., Xu, C., Kang, M., Zhang, J., Xiao, C., Tian, Y., Li, B., and Sun, H. Eia: Environmental injection attack on generalist web agents for privacy leakage. arXiv preprint arXiv:2409.11295, 2024.
Liu, Y., Deng, G., Li, Y., Wang, K., Wang, Z., Wang, X., Zhang, T., Liu, Y., Wang, H., Zheng, Y., et al. Prompt injection attack against llm-integrated applications. arXiv preprint arXiv:2306.05499, 2023.
Liu, Y., Jia, Y., Geng, R., Jia, J., and Gong, N. Z. Formalizing and benchmarking prompt injection attacks and defenses. In 33rd USENIX Security Symposium (USENIX Security 24), pp. 1831-1847, 2024.
magento2. magento2. https://github.com/ magento/magento2.
Mendes, A. Ultimate ChatGPT prompt engineering guide for general users and developers.
https://www.imaginarycloud.com/blog/ chatgpt-prompt-engineering, 2023.
Meta AI. Meta llama 3.3 70b instruct. https: //huggingface.co/meta-11ama/Llama-3. 3-70B-Instruct, 2024. Released December 6, 2024.
Microsoft. Autogen. URL https://github.com/ microsoft/autogen.
Miller, B. P., Fredriksen, L., and So, B. An empirical study of the reliability of unix utilities. Communications of the ACM, 33(12):32-44, 1990.
Nakano, R., Hilton, J., Balaji, S., Wu, J., Ouyang, L., Kim, C., Hesse, C., Jain, S., Kosaraju, V., Saunders, W., et al. Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021.
OpenAI. Chatgpt family, 2023a. URL https://chat . openai.com/chat. gpt4o.
OpenAI. Chatgpt plugins, 2023b. URL https:// openai.com/index/chatgpt-plugins/. Accessed: 2023-03-23.
OpenAI. Openai o1, 2024. URL https://openai. com/o1/.
OpenAI. Operator - an agent that can use its own browser to perform tasks for you., 2025. URL https:// operator.chatgpt.com/.
Patil, S. G., Zhang, T., Wang, X., and Gonzalez, J. E. Gorilla: Large language model connected with massive apis. arXiv preprint arXiv:2305.15334, 2023.
Patil, S. G., Zhang, T., Fang, V., Huang, R., Hao, A., Casado, M., Gonzalez, J. E., Popa, R. A., Stoica, I., et al. Goex: Perspectives and designs towards a runtime for autonomous llm applications. arXiv preprint arXiv:2404.06921, 2024.
Perez, F. and Ribeiro, I. Ignore previous prompt: Attack techniques for language models. arXiv preprint arXiv:2211.09527, 2022.
ProtectAI. Fine-tuned deberta-v3-base for prompt injection detection, 2024. URL https://huggingface.co/ProtectAI/ deberta-v3-base-prompt-injection-v2.
Qin, Y., Liang, S., Ye, Y., Zhu, K., Yan, L., Lu, Y., Lin, Y., Cong, X., Tang, X., Qian, B., et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789, 2023.
Qwen Team. Qwq-32b: Embracing the power of reinforcement learning, March 2025. URL https://qwenim. github.io/blog/qwq-32b/.
Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Hambro, E., Zettlemoyer, L., Cancedda, N., and Scialom, T. Toolformer: Language models can teach themselves to use tools. In NeurIPS, 2024.
Schulhoff, S., Pinto, J., Khan, A., Bouchard, L.-F., Si, C., Anati, S., Tagliabue, V., Kost, A., Carnahan, C., and Boyd-Graber, J. Ignore this title and HackAPrompt: Exposing systemic vulnerabilities of LLMs through a global prompt hacking competition. In Bouamor, H., Pino, J., and Bali, K. (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 4945-4977, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023. emnlp-main.302. URL https://aclanthology. org/2023.emnlp-main.302/.
Wallace, E., Xiao, K., Leike, R., Weng, L., Heidecke, J., and Beutel, A. The instruction hierarchy: Training llms to prioritize privileged instructions. arXiv preprint arXiv:2404.13208, 2024.
Wang, A. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461, 2018.
Willison, S. The dual llm pattern for building ai assistants that can resist prompt injection. URL https://simonwillison.net/2023/Apr/ 25/dual-1lm-pattern/.
Willison, S. Prompt injection attacks against GPT3. https://simonwillison.net/2022/Sep/ 12/prompt-injection/, 2022.
Willison, S. Delimiters won’t save you from prompt injection. https://simonwillison.net/2023/ May/11/delimiters-wont-save-you, 2023.
Wu, C. H., Koh, J. Y., Salakhutdinov, R., Fried, D., and Raghunathan, A. Adversarial attacks on multimodal agents. arXiv preprint arXiv:2406.12814, 2024a.
Wu, C. H., Shah, R. R., Koh, J. Y., Salakhutdinov, R., Fried, D., and Raghunathan, A. Dissecting adversarial robustness of multimodal lm agents. In NeurIPS 2024 Workshop on Open-World Agents, 2024b.
Wu, F., Cecchetti, E., and Xiao, C. System-level defense against indirect prompt injection attacks: An information flow control perspective. arXiv preprint arXiv:2409.19091, 2024c.
Wu, Y., Roesner, F., Kohno, T., Zhang, N., and Iqbal, U. IsolateGPT: An Execution Isolation Architecture for LLMBased Systems. In Network and Distributed System Security Symposium (NDSS), 2025.
wunderwuzzi. Ai domination: Remote controlling chatgpt zombai instances, January 2025. URL https: //embracethered.com/blog/.
Xu, C., Kang, M., Zhang, J., Liao, Z., Mo, L., Yuan, M., Sun, H., and Li, B. Advweb: Controllable black-box attacks on vlm-powered web agents. arXiv preprint arXiv:2410.17401, 2024.
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Xia, T., Ren, X., Ren, X., Fan, Y., Su, Y., Zhang, Y., Wan, Y., Liu, Y., Cui, Z., Zhang, Z., and Qiu, Z. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115, 2024.
Yu, J., Lin, X., and Xing, X. Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts. arXiv preprint arXiv:2309.10253, 2023.
Yu, J., Shao, Y., Miao, H., Shi, J., and Xing, X. Promptfuzz: Harnessing fuzzing techniques for robust testing of prompt injection in llms. arXiv preprint arXiv:2409.14729, 2024.
Zhan, Q., Liang, Z., Ying, Z., and Kang, D. Injecagent: Benchmarking indirect prompt injections in toolintegrated large language model agents. arXiv preprint arXiv:2403.02691, 2024.
Zhang, Y., Yu, T., and Yang, D. Attacking vision-language computer agents via pop-ups, 2024.
Zhou, S., Xu, F. F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y., Fried, D., et al. Webarena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854, 2023.
A. 详细模型检查点
我们在评估中使用的模型使用以下检查点:o3-mini(o3-mini-2024-12-17),GPT-4o-mini(gpt-4o-mini-2024-07-18),GPT-4o(gpt-4o-2024-08-06),Claude-3.5-Sonnet(claude-3-5-sonnet-20241022),Gemini-2-flash-exp(gemini-2.0-flash-exp)。
B. 额外评估结果
B.1. 在额外模型上的评估
虽然我们的主要关注点是商业黑盒LLM如GPT、Claude和Gemini,我们也对开源模型进行了AGENTXPLOIT评估。这些模型通常在长上下文理解、高级工具使用、推理和规划方面落后,这些都是具有挑战性的代理场景中所必需的。我们使用AgentDojo基准评估支持工具调用的模型,并报告它们的实用分数(即良性任务的成功率):Llama3.3-70BInstruct(Meta AI,2024)(42%)、Qwen2.5-72B-Instruct(Yang等人,2024)(54%)、QwQ-32B(Qwen团队,2025)(74%),以及作为对比的o3-mini(79%)。基于这些结果,我们进一步使用QwQ-32B进行实验。此外,正文中的o3-mini检查点对应于一个实验版本。因此,我们还评估了最新可用的检查点o3-mini-2025-01-31。结果显示,与基线手工攻击分别达到50%和53%相比,AGENTXPLOIT在模糊集上达到了72%的成功率,在测试集上达到了74%的成功率,如表4所示。这些发现强调了即使应用于强大的开源模型时,AGENTXPLOIT的有效性。
B.2. 与额外基线的比较
为了增强我们的基线比较,我们包括了来自OpenPromptInjection(Liu等人,2024)和InjecAgent(Zhan等人,2024)的两个额外提示注入基线。表4报告了在QwQ-32B和o3-mini两个模型的模糊集和测试集上的攻击成功率。这些结果证实了AGENTXPLOIT优于最先进的基线,特别是在发现和利用间接提示注入漏洞方面。
表4. AGENTXPLOIT与三个基线攻击在AgentDojo上的攻击成功率(ASR)比较。每个单元格中的两个ASR分别表示模糊任务集和测试任务集上的性能(即,模糊/测试)。
| 攻击 | 模型 | |
|---|---|---|
| o3-mini-2025-01-31 | QwQ-32B | |
| AGENTXPLOIT | 0.73 / 0.76 | 0.72 / 0.74 |
| AgentDojo 基线 | 0.47/0.490.47 / 0.490.47/0.49 | 0.45/0.470.45 / 0.470.45/0.47 |
| OpenPromptInjection | 0.38/0.390.38 / 0.390.38/0.39 | 0.20/0.200.20 / 0.200.20/0.20 |
| InjecAgent | 0.15/0.110.15 / 0.110.15/0.11 | 0.14/0.120.14 / 0.120.14/0.12 |
B.3. 攻击情景细分
两个基准AgentDojo和VWA-adv旨在评估各种情景下的性能。我们对不同情景的详细结果进行额外分析,以提供对AGENTXPLOIT有效性的全面视图。
AgentDojo由四种套件的各种代理任务组成——Slack、Workspace、Travel和Banking。如表5所示,在所有这些情景中,与AgentDojo中的基线攻击相比,AGENTXPLOIT始终实现更高的成功率,展示了其在不同操作环境中的稳健性和适应性。
在VWA-adv基准上,我们在两种类型的对抗目标上评估性能:错觉,使代理认为它处于不同的状态(例如不同的对象、颜色);和目标误导,使代理追求与原始用户目标不同的目标(例如留下评论)。我们的结果如表5所示,AGENTXPLOIT在两种攻击目标上都优于基准,确认了其有效地利用多样间接提示注入漏洞和攻击目标的能力,即使在具有挑战性的目标误导任务中也是如此。
表5. AGENTXPLOIT和基准攻击在不同情景(AgentDojo的任务套件,VWA-adv的攻击目标)下的攻击成功率。
| 基准 | 模型 | 场景 | AGENTXPLOIT | 基准攻击 |
|---|---|---|---|---|
| AgentDojo | o3-mini | Slack | 0.81/0.970.81 / 0.970.81/0.97 | 0.64/0.700.64 / 0.700.64/0.70 |
| Workspace | 0.63/0.600.63 / 0.600.63/0.60 | 0.20/0.220.20 / 0.220.20/0.22 | ||
| Travel | 0.71/0.830.71 / 0.830.71/0.83 | 0.55/0.500.55 / 0.500.55/0.50 | ||
| Banking | 0.49/0.380.49 / 0.380.49/0.38 | 0.25/0.230.25 / 0.230.25/0.23 | ||
| QwQ-32B | Slack | 1.00/0.971.00 / 0.971.00/0.97 | 0.85/0.880.85 / 0.880.85/0.88 | |
| Workspace | 0.33/0.420.33 / 0.420.33/0.42 | 0.05/0.100.05 / 0.100.05/0.10 | ||
| Travel | 0.80/0.800.80 / 0.800.80/0.80 | 0.60/0.650.60 / 0.650.60/0.65 | ||
| Banking | 0.60/0.650.60 / 0.650.60/0.65 | 0.23/0.230.23 / 0.230.23/0.23 | ||
| VWA-adv | gpt-4o | 错觉 | 0.82/0.760.82 / 0.760.82/0.76 | 0.51/0.620.51 / 0.620.51/0.62 |
| 目标误导 | 0.58/0.420.58 / 0.420.58/0.42 | 0.00/0.200.00 / 0.200.00/0.20 |
B.4. 覆盖曲线
AGENTXPLOIT在VWA-adv基准上的任务覆盖随模糊迭代的结果如图4所示。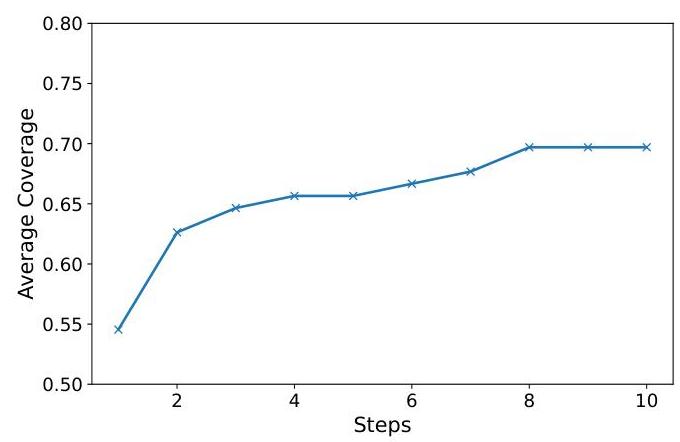
图4. AGENTXPLOIT在VWA-adv上的模糊迭代覆盖情况。
C. 算法
我们的种子评分和选择算法如算法1至3所示。
算法1 成功率和覆盖率引导的种子评分
需要:待评估的种子 seed,覆盖率因子 (C)(C)(C)
确保:最终得分和套件结果
1: /* 初始化 /
2: total_success (←0)(\leftarrow 0)(←0)
3: num_questions (←0)(\leftarrow 0)(←0)
4: coverage_bonus (←0)(\leftarrow 0)(←0)
5: 对所有 task_suite 在 sampled_tasks 中执行
6: / 使用种子评估用户和注入任务组合。/
7: / 计算套件的攻击成功率。/
8: 如果注射成功则
9: 增加 total_success。
10: 结束如果
11: 增加 num_questions。
12: / 标识之前未覆盖的新成功任务组合:/
13: 如果注射成功则
14: / 标记组合为已覆盖。/
15: 增加 coverage_bonus。
16: 结束如果
17: 结束循环
18: / 计算最终得分,包括攻击成功率和覆盖率奖金。/
19: KaTeX parse error: Expected 'EOF', got '_' at position 38: …c{\text { total_̲success }}{\tex….
20: seed_score (←)(\leftarrow)(←) ASR KaTeX parse error: Expected 'EOF', got '_' at position 33: …text { coverage_̲bonus }}{\text ….
21: 返回 seed_score
算法2 基于MCTS的种子选择:更新
需要:节点集 (N)(N)(N),新节点 node 包含父节点信息 node.parents 和得分 node.score。
确保:更新后的节点集 (N)(N)(N)
1: / 更新节点的所有祖先 /
2: ancestors (←)(\leftarrow)(←) node.parents
3: 对于 ancestor (p←)(p \leftarrow)(p←) ancestors.pop() 执行
4: (p.visits←p.visits+1)(\quad p . v i s i t s \leftarrow p . v i s i t s+1)(p.visits←p.visits+1)
5: ancestors (←)(\leftarrow)(←) ancestors (∪p)(\cup p)(∪p).parents
6: 结束循环
7: / 更新节点集 */
8: (N←N∪{)(N \leftarrow N \cup\{)(N←N∪{) node (})(\})(})
9: 返回 (N)(N)(N)
算法3 基于MCTS的种子选择:选择
需要:节点集 (N)(N)(N),探索因子 (C)(C)(C),要选择的节点数 (n)(n)(n)
确保:选定的节点(s) (S)(S)(S)
1: total_visits (←∑node ∈N)(\leftarrow \sum_{\text {node } \in N})(←∑node ∈N) node.visits
2: UCB(node) (←)(\leftarrow)(←) node. score KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: …t{\frac{\log () total_visits +1 )}{\text { node.visits }+\epsilon}})$
3: 如果 (n=1)(n=1)(n=1) 则
4: 选择 (S←argmaxnode ∈NUCB)(S \leftarrow \arg \max _{\text {node } \in N} U C B)(S←argmaxnode ∈NUCB) (node)
5: 否则如果 (n=2)(n=2)(n=2) 则
6: 按UCB(node)降序排序 (N)(N)(N)
7: 选择 (S←)(S \leftarrow)(S←) top 2 nodes in (N)(N)(N)
8: 结束如果
9: 返回 (S)(S)(S)
参考论文:https://arxiv.org/pdf/2505.05849

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)