性能飙升 3.12 倍,RISC-V 架构赋能边缘设备深度神经网络硬件加速
为了将矩阵数据传输到 CFU 进行计算,LW(加载字)指令的第一个操作数(rs1)将四个 8 位元素合并成一个 32 位的实体。通过两条指令提供输入和权重矩阵的维度:CMIS(CFU 矩阵输入形状)用于输入矩阵的行数(rs1)和列数(rs2),CMWS(CFU 矩阵权重形状)用于权重矩阵的行数(rs1)和列数(rs2)。最先进的人工智能(AI)模型的最佳例子是像 GPT-4 和 Stable Di
最近在 Transformer 神经网络架构方面的进展受到其巨大的计算需求的限制,这在边缘计算环境中带来了重大挑战。在这些网络连接受限的环境中,需要在资源受限的嵌入式处理器上进行本地数据处理。
我们设计了一个硬件自定义功能单元(CFU),用于加速边缘计算环境中的神经网络计算。我们的电路作为嵌入式处理器的协处理器,并实现了与第五代精简指令集计算机(RISC-V)开放标准指令集架构(ISA)兼容的新自定义指令。
我们实现了一个具有本地缓存的可编程处理单元(PE)的脉动阵列,以将密集矩阵乘法的计算从嵌入式处理器卸载下来。通过仿真,我们在具有三个编码器层和 256 维度的Transformer 模型的矩阵乘累加操作中实现了高达三倍的处理速度提升。
我们的设计为无缝集成硬件加速提供了一种途径,以利用开放标准 ISA 的优势来增强嵌入式处理器中的推理计算。通过定义与 RISC-V 处理器核心的接口,我们的硬件可以作为知识产权(IP)模块导入到可编程或特定应用的设计流程中。
在软件方面,将密集矩阵乘法指令替换为我们的自定义指令,而其余的指令编译和汇编步骤可以继续利用将 Python ONNX 模型转换为 RISC-V 指令的开源软件工具。

unsetunset本文目录unsetunset
-
本文目录
-
1. 引言
-
2. 相关工作
-
-
A. Transformer 的软件级优化
-
B. Transformer 的硬件级优化
-
-
3. 方法论
-
-
A. 硬件仿真工具
-
B. CFU 硬件设计
-
C. 自定义指令集
-
D. Transformer 神经网络上的性能
-
-
4. 结果
-
5. 结论
-
参考文献

unsetunset1. 引言unsetunset
最先进的人工智能(AI)模型的最佳例子是像 GPT-4 和 Stable Diffusion 3(SD3)这样的基础模型,它们在性能上远远超过了其他算法,从而推动了新的生成性应用的发展。
-
尽管这些模型的性能令人印象深刻,但它们并不适合在计算能力、能源和连接性预算受限的边缘计算环境中使用。
-
为了利用模型稀疏性来减少内存占用,引入了诸如权重剪枝和模型量化等算法技术。然而,采用加载存储架构的嵌入式处理器并没有针对这种模型稀疏性进行优化,以加速计算。
-
此外,还提出了各种硬件方法,通常是具有新颖硬件和指令集架构的专用处理器,如图形处理单元(GPU)或神经形态处理器。尽管这些专用硬件解决方案在性能上是有效的,但将它们重新设计用于边缘计算环境需要大量的投资。
我们的方法利用了 RISC-V 开放标准 ISA 的优势,通过一个小型加速器——自定义功能单元(CFU),与 RISC-V 中央处理单元(CPU)协同工作。我们的自定义硬件只执行神经网络中特定的速率限制操作,即矩阵乘法和累加,比 CPU 更高效。通过将这些计算从 CPU 卸载到 CFU,我们显著提高了模型推理的速度。与部署 RISC-V 解决方案相比,所需的重新设计要少得多。
只需要将矩阵乘法的代码部分重新定位到新指令,而 CFU 可以无缝集成到 RISC-V 软件定义的 FPGA 上的 CPU 核心中。我们在 Transformer 神经网络上评估了我们的设计优势,该网络已被广泛应用于多种多模态数据,包括文本生成、总结、文本到视频和图像到文本等任务。
unsetunset2. 相关工作unsetunset
A. Transformer 的软件级优化
许多研究表明,扩大 Transformer 模型的规模可以显著提高其性能水平,这一事实由 GPT-4 和 BERT 等模型的成功所证明。然而,这些大型模型的主要障碍是可用硬件的内存和计算限制。例如,像 GPT-3 175B 这样的模型在预训练期间耗费了数千个 petaflop/s 天的计算工作量。
为了解决 Transformer 模型的计算需求,提出了许多软件级优化技术。后训练量化(PTQ)可以在不重新训练的情况下缩小大型模型的规模。与量化感知训练(QAT)相比,这种方法具有更高的压缩效率。量化通过模型压缩和延迟降低带来改进。TensorFlow Lite 采用了一种量化方案,在推理期间使用整数运算,而在训练期间使用浮点运算。权重和激活被量化为 8 位整数,某些参数(如偏置向量)被量化为 32 位整数。LLM.int8()过程使用向量量化来量化大多数特征,并使用 16 位精度的混合精度分解来处理异常值。结果模型可以直接使用,而不会出现性能下降。
神经网络可以通过在前向传播过程中将实值权重和激活转换为+1 或-1 来二值化,这种网络被称为二值化神经网络(BNNs)。BNNs 可以在 MNIST、CIFAR-10 和 SVHN 数据集上实现接近最先进的结果,同时通过位运算显著降低功耗和内存消耗。BinaryConnect 方法应用了类似的二值化技术,但在前向和后向传播过程中只限制权重为+1 或-1。该方法用简单的加法和减法替换了众多的乘累加运算,显著提高了计算效率。这种方法的一个关键方面是在参数更新阶段保持高精度权重,以便有效地进行随机梯度下降(SGD)。
B. Transformer 的硬件级优化
通用处理器被优化为处理各种复杂且适应性强的计算任务。然而,它们通常在性能上不如针对高度并行 AI 任务的定制硬件加速器,这些任务具有独特的计算和数据依赖模式。神经处理单元(NPU)和张量处理单元(TPU)等硬件加速器被设计为更高效地执行这些任务。
NPU 旨在加速通常由 CPU 处理的特定小代码区域。这是通过一种名为“鹦鹉变换”的创新算法转换实现的,该转换将特定代码区域转换为神经网络,以利用这些网络的固有并行性进行硬件加速。另一方面,TPU 专注于加速矩阵处理。每个 TPU 芯片包含数千个相互连接的乘累加器,基于脉动阵列架构。然而,这些加速器针对的是一组具有相似计算特征的神经网络,因此是特定于应用的。
为了灵活支持不同的神经网络技术,一种名为 Cambricon 的指令集架构(ISA)将神经网络的高级功能组件分解为对应于低级计算操作的较短指令。Cambricon 建议了四种类型的指令:计算、逻辑、控制和数据传输。基于 Cambricon 的加速器可以容纳 10 个代表性基准测试,并且比 x86-CPU 和 GPU 分别快约 91.72 倍和 3.09 倍。
unsetunset3. 方法论unsetunset
A. 硬件仿真工具
自定义功能单元(CFU)是利用谷歌发布的 CFU-Playground 框架(https://google.github.io/CFU-Playground/)开发的,该框架便于设计用于提升基于 FPGA(现场可编程门阵列,一种可以通过软件重新配置硬件功能的芯片)的软 CPU 的机器学习处理器。

它借助 LiteX 框架来构建基于 FPGA 的片上系统(SoC,System on Chip,即将计算机或其他电子系统的大部分或全部组件集成到单一芯片上的集成电路)。
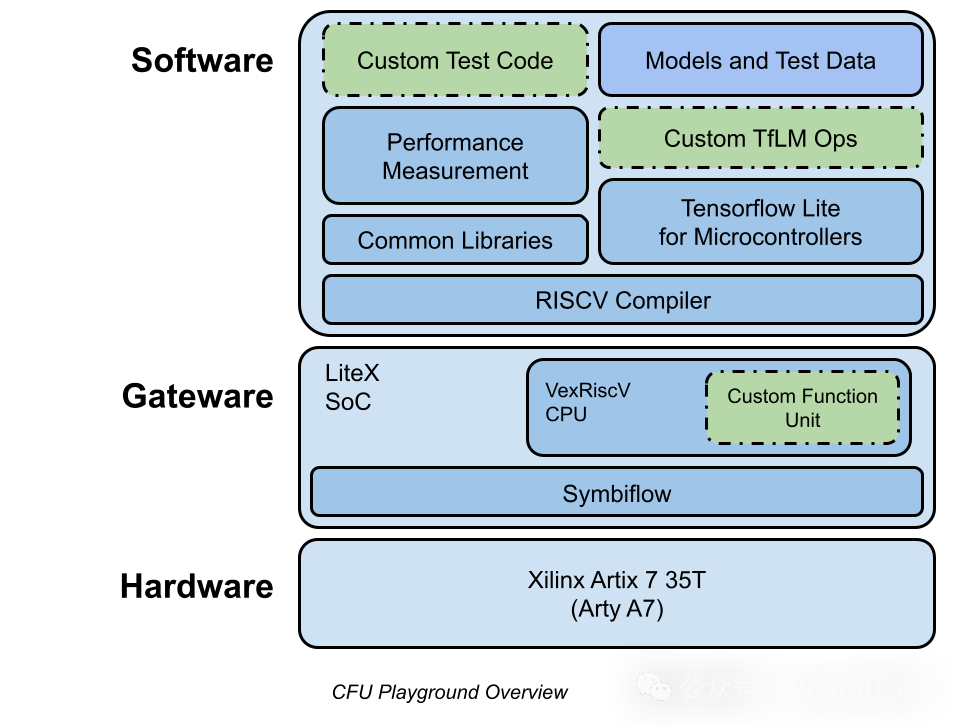
B. CFU 硬件设计
CFU 采用了脉动阵列架构,由一个 4×4 的处理单元(PE,Processing Elements,用于执行计算任务的基本单元)网格组成,如图 1 所示。
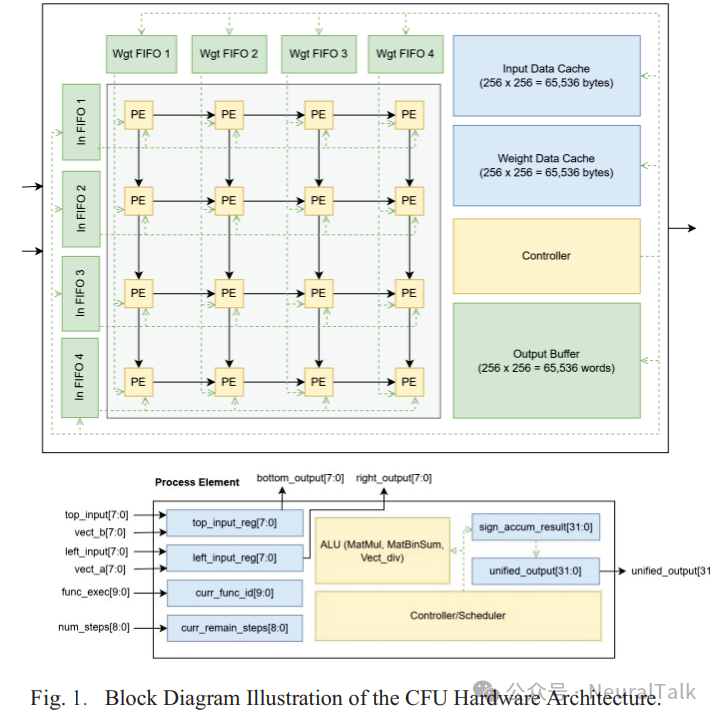
网格中的每个 PE 同时运行,处理不同的数据元素。这些数据元素要么从先进先出(FIFO,First-in-First-out,一种数据存储和访问方式,先进入的数据先被取出)模块中同步获取,要么从相邻的 PE 获取。有八个 FIFO 模块,其中四个模块用于输入数据,另外四个用于权重数据。每个模块包含一个队列,能够容纳多达 256 字节的正在用于计算的数据。
FIFO 模块从 CFU 的输入和权重数据缓存中获取数据。这些缓存作为输入和权重数据的快速可访问的片上存储器,最大存储容量分别为 65536 字节。每当执行加载指令时,缓存每次从 CPU 接收两个 32 位的数据。一个大小为 65536 字的统一缓冲区可用于存储计算的输出结果。在计算完成后,该缓冲区会在一个时间步内从所有 PE 收集最终输出。该模块有四个指定的输入端口(128 位宽),每个端口负责将一行中的四个 PE 的数据传输到缓冲区。每个 PE 输出 1 个字(即 32 位)的数据作为最终结果。
在将数据加载到 FIFO 模块完成后,PE 从 CFU 控制器接收指令。PE 开始执行乘法和累加的算术计算任务,通过持续从 FIFO 模块获取数据,同时将当前数据传递给相邻的 PE。在每个 PE 中,要执行的指令和累加的次数分别存储在 curr_func_id 和 curr_remain_steps 寄存器中。PE 的 ALU(算术逻辑单元,是处理器中执行基本算术和逻辑运算的核心部件)是计算的核心。为了便于 ALU 的操作,一系列寄存器被用来加载计算数据和存储随时间变化的中间累加结果。
在每个计算步骤中,新的数据项被加载到 left_input_reg 和 top_input_reg 寄存器中,这反过来又会使 curr_remain_steps 寄存器递减。这个计算过程持续迭代进行,直到 curr_remain_steps 寄存器达到零。最终输出被移动到 unified_output 寄存器中,然后被传回中央统一缓冲区。系统在 PE 之间维持这种迭代的数据加载、处理和传递过程,在协调的控制下,直到整个矩阵被完全处理。
这种设计适用于快速且并行的矩阵计算。
C. 自定义指令集
为 CFU 分配了多个自定义的 R 型指令(图 2 展示了 32 位 RISC-V 的 R 型指令格式),以扩展原始的 32 位 RISC-V ISA(指令集架构)。

当 CPU 遇到这些操作码中的一个时,它会将来自两个数据寄存器的数据转发到 CFU。CFU 处理完这些数据后,CPU 检索结果并将其存储在第三个寄存器中。这个架构的一个关键方面是 CFU 没有直接内存访问权限。因此,CPU 必须处理 CFU 和内存之间的所有数据传输。
为了将矩阵数据传输到 CFU 进行计算,LW(加载字)指令的第一个操作数(rs1)将四个 8 位元素合并成一个 32 位的实体。同样,第二个操作数(rs2)适合矩阵中的接下来的四个元素。调用矩阵乘法的自定义指令序列如下:
-
使用 CRST(CFU 重置)指令重置 CFU,以清除所有内部寄存器和缓冲区。
-
通过两条指令提供输入和权重矩阵的维度:CMIS(CFU 矩阵输入形状)用于输入矩阵的行数(rs1)和列数(rs2),CMWS(CFU 矩阵权重形状)用于权重矩阵的行数(rs1)和列数(rs2)。
-
使用 CMILW(CFU 矩阵输入加载字)指令将输入矩阵加载到 CFU。每条指令将两个 32 位值(rs1 和 rs2)传输到输入数据缓存,总共对应八个元素。
-
加载权重矩阵的过程类似,使用 CMWLW(CFU 矩阵权重加载字)指令。
-
使用 CMMUL(CFU 矩阵乘法)指令启动矩阵乘法。计算过程以四个为一批进行。在每次迭代中,计算涉及输入矩阵的四行与权重矩阵的点积。
-
矩阵乘法的最终结果存储在统一缓冲区中,通过 CMGW(CFU 矩阵获取字)指令将结果传输回用户程序。每条指令传输一个 32 位字,对应输出矩阵中的一个元素。对于形状为(n,m)的输出矩阵,需要 n×m 个时间步。
D. Transformer 神经网络上的性能
构建了六个基于 BERT 架构的 Transformer 模型用于评估,这些模型在编码器块的数量、隐藏大小等方面有所不同。
每个模型设计为处理一批输入序列,序列长度为 40 个标记。输入序列被转换成维度为 h 的文本嵌入向量(h 是隐藏层的维度)。这些嵌入向量被输入到一系列数量不同的编码器块中(编码器块的数量从 3 到 5 不等)。最后一步是从最后一个编码器块的输出中提取每个序列的第一个标记向量进行池化操作。然后,这个池化的输出通过一个使用双曲正切(tanh)激活函数的前馈层进行处理。
模型参数是随机初始化的,并且没有进行训练,因为本项目的主要关注点是分析和优化推理速度。评估模型被量化为 8 位整数权重,并以 TensorFlow Lite(tflite)格式存储。量化过程对于在支持 32 位 RISC-V 基础整数 ISA(指令集架构)以及“M”扩展(用于整数乘法和除法)的 FPGA SoC 上运行这些模型至关重要。我们在 Renode FPGA 模拟器上模拟了形状为(1,40)的输入数据在单次前向传递中每种操作类型的 Clock Ticks 数。我们在表 I 中报告了 CPU-only 和 CPU-CFU 模拟中速率限制指令的 Clock Ticks 数,每种模型变体都在两种环境中使用相同的神经网络架构和输入进行评估,以确保公平比较。
unsetunset4. 结果unsetunset
下表 II 表明 RISC-V CPU 指令在 Transformer 神经网络上的执行概况(1 个 Clock Ticks=1024 个时钟周期),在具有三个编码器层的 Transformer 模型中,矩阵乘法(由三维权重矩阵的 BATCH_MATMUL 和二维权重矩阵的 FULLY_CONNECTED 表示)占总推理时间的 30%以上。
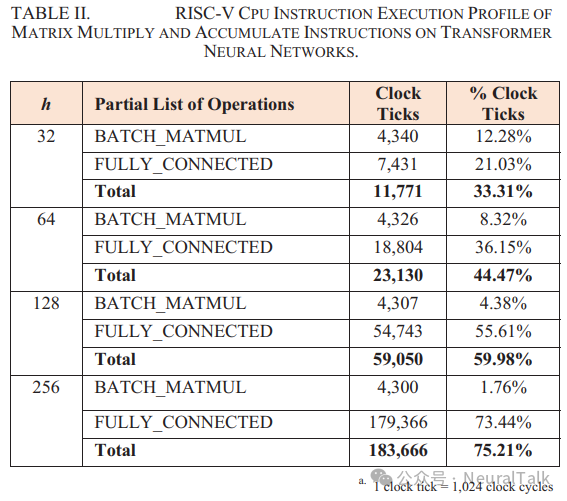
随着隐藏维度从 32 增加到 256,这两个操作所占的总计算时间比例从 1/3 增加到 1/2。因此,我们的CFU 被战略性地设计为优化模型推理过程中的关键操作——矩阵乘法。
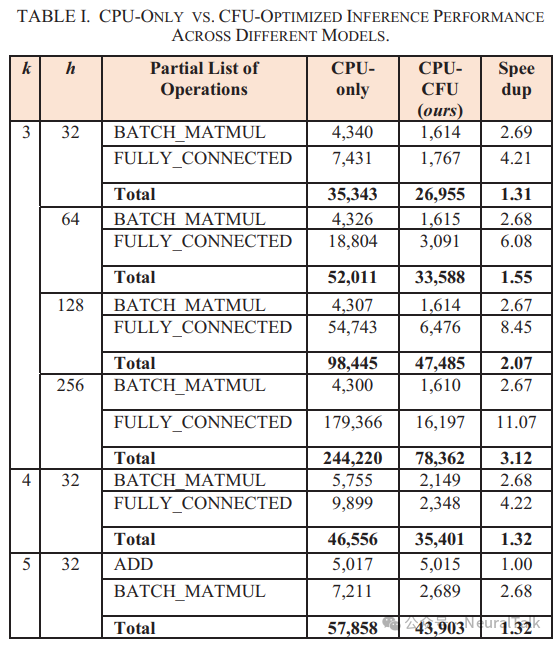
表 I 展示不同模型的 CPU-only 与 CFU 优化推理性能对比,显示了我们的 CFU 在 BATCH_MATMUL 和 FULLY_CONNECTED 操作上的改进性能。
其他类型的操作仍然由 CPU 执行,它们的 Clock Ticks 数包含在总数中。所有 Int8 量化的 Transformer 模型都从 CFU 加速中受益,推理时间减少。我们对具有三个编码器层和 256 个隐藏维度的宽 Transformer 模型实现了最大的改进,其中矩阵乘法和累加的 Clock Ticks 数从 244k 减少到 78k,模拟结果显示这些操作占总执行时间的 50%。因此,我们最好的性能结果实现了总速度提升 3.12 倍。
随着隐藏尺寸达到 128 或更高,速度提升变得更加显著,因为矩阵乘法和累加占据了更大的计算份额。例如,具有三个编码器层(h=256)的 Transformer 模型在这一关键操作上花费了 75.21%的计算时间。
因此,通过我们的 CFU,几乎实现了 3.12 倍的提升,这是因为巨大的 Clock Ticks 数减少:
-
批量矩阵乘法层从 4300 减少到 1610 个 Clock Ticks(大约快 2.64 倍)
-
全连接层从 179366 减少到 16197 个 Clock Ticks(大约快 9.69 倍)。
unsetunset5. 结论unsetunset
我们提出了一种新颖的硬件 CFU,用于加速边缘计算环境中的神经网络计算。CFU 由一个带有本地缓存的可编程处理单元(PE)脉动阵列提供支持,执行 8 位整数乘法和累加操作。该架构支持算术操作的并行和数据流执行,并允许相邻 PE 之间高效重用数据。
unsetunset参考文献unsetunset
-
J. Kaplan et al., "Scaling laws for neural language models," arXiv preprint arXiv:2001.08361, 2020.
-
T. Brown et al., "Language models are few-shot learners," Advances in neural information processing systems, vol. 3 3, pp. 1877-1901, 2020. 3. J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, "Bert: Pre-training of deep bidirectional transformers for language understanding," arXiv preprint arXiv:1810.04805, 2018.
-
B. Jacob et al., "Quantization and training of neural networks for efficient integer-arithmetic-only inference," in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 2704-2713.
-
T. Dettmers, M. Lewis, Y. Belkada, and L. Zettlemoyer, "Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale," Advances in Neural Information Processing Systems, vol. 35, pp. 30318-30332, 2022.
-
I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio, "Binarized neural networks," Advances in neural information processing systems, vol. 29, 2016.
-
M. Courbariaux, Y. Bengio, and J.-P. David, "Binaryconnect: Training deep neural networks with binary weights during propagations," Advances in neural information processing systems, vol. 28, 2015.
-
H. Esmaeilzadeh, A. Sampson, L. Ceze, and D. Burger, "Neural acceleration for general-purpose approximate programs," in 2012 45th annual IEEE/ACM international symposium on microarchitecture, 2012: IEEE, pp. 449-460.
-
N. Jouppi et al., "Tpu v4: An optically reconfigurable supercomputer for machine learning with hardware support for embeddings," in Proceedings of the 50th Annual International Symposium on Computer Architecture, 2023, pp. 1-14.
-
S. Liu et al., "Cambricon: An instruction set architecture for neural networks," ACM SIGARCH Computer Architecture News, vol. 44, no. 3, pp. 393-405, 2016.

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)