SD模型微调之LoRA
知乎名为AItransformer,8年AI老兵,从事NLP、大语言模型、多模态大模型等相关算法的研发和落地,拥有丰富的算法经验,先后在百度、平安、小鹏汽车从事算法落地的工作,借助平台将个人的一些算法研究和经验分享出来,一起推动技术的进步!
论文地址:LoRA: Low-Rank Adaptation of Large Language Models
一、概念
LoRA(Low-Rank Adaptation of Large Language Models)是一种用于高效微调大规模预训练模型的技术,特别适用于参数量巨大的模型,如 GPT-3、BERT 或 Stable Diffusion 等。LoRA 提供了一种解决方案,使得在进行模型微调时,只需要微调非常少量的参数,同时保持与全量参数微调相近的性能表现。
1.1 核心原理
LoRA(Low-Rank Adaptation of Large Language Models) 的核心原理是通过低秩分解来减少大规模模型微调时需要更新的参数量,以此实现更高效的模型微调。它特别适用于像 GPT-3、BERT 或 Stable Diffusion 这样的预训练大模型,在微调这些模型时,LoRA 通过引入两个低秩矩阵来替代直接更新整个权重矩阵,从而显著降低了计算成本和存储需求。
核心思想:假设预训练模型中的权重矩阵 W 很大。LoRA 的基本思想是将它的更新部分 ΔW 分解为两个秩更小的矩阵 A 和 B 的乘积,从而减少需要更新的参数量,并且仅仅更新这两个矩阵。而不是更新整个 W 矩阵,保持预训练模型的原始性能。

1.2 优点
- 大幅减少参数更新量:通过对权重矩阵进行低秩分解,LoRA 只需要更新非常少的参数,而不是整个模型的参数。这大大降低了存储需求和计算成本。
- 保持模型的原始性能:LoRA 冻结SD模型的权重,因此微调后的模型依然可以利用预训练模型的知识。
- 模块化更新和可插拔设计:LoRA 的权重调整是通过 A 和 B 进行的,在推理时也可以轻松应用,不需要重新加载整个模型。LoRA 训练出的 A 和 B 矩阵是可以独立保存的。在推理时,你可以在不同任务之间快速切换,而不需要重新训练模型。
二、训练过程
LoRA 微调的训练过程可分为以下几个步骤:
(1)预训练模型加载
首先,加载一个预训练的 Stable Diffusion 模型。这个模型已经在大规模的文本图像数据集上进行了训练,具备强大的生成能力。LoRA 的目标是在该预训练模型上微调,只需调整极少的参数。
(2)选择微调的层
在 Stable Diffusion 模型中,LoRA 通常作用于模型中的线性层(主要在注意力模块的 Q、K、V 的三个权重矩阵W)。具体来说,LoRA 会对 U-Net 中的 cross-attention 机制、自注意力机制的线性层等进行调整。
LoRA 通过对这些线性层中的权重矩阵进行低秩分解(主要在注意力模块的 Q、K、V 权重),并引入两个低秩矩阵 A 和 B,通过这些矩阵来调整权重变化。
LoRA 主要作用于 U-Net 网络中的 注意力机制相关的线性层,特别是用于跨模态交互的 Cross-Attention(跨注意力)层 以及 Self-Attention(自注意力)层。
2.1 LoRA 优化的层
在 Stable Diffusion 的 U-Net 中,主要有两种注意力机制:自注意力机制(Self-Attention) 和 跨注意力机制(Cross-Attention)。LoRA 主要对这些注意力层中的 线性层 进行优化,特别是以下几个部分:
(1)Cross-Attention(跨注意力)层
Cross-Attention 是 U-Net 中的核心机制,它负责将图像的潜在特征(Latent Feature)与文本嵌入(Text Embedding)进行结合。通过跨注意力机制,模型可以从文本提示中获取信息,调整图像生成的内容。
在 Cross-Attention 中,LoRA 主要针对用于生成 Query (Q)、Key (K) 和 Value (V) 的线性变换层进行优化。
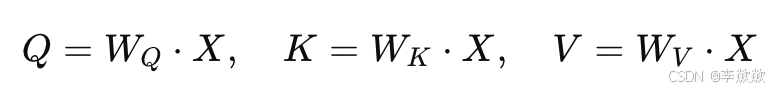
这些层分别处理输入特征和文本嵌入,并计算注意力权重。
(2)Self-Attention(自注意力)层
Self-Attention 是 U-Net 内部的图像特征交互机制,负责在图像的不同区域之间进行特征相互作用,从而捕捉到图像的全局依赖关系。
在 Self-Attention 中,LoRA 也对生成 Query (Q)、Key (K) 和 Value (V) 的线性层进行优化。
2.2 LoRA 如何优化这些层
LoRA 通过将注意力机制中的 线性层(例如,用于生成 Q、K、V 的线性变换层)进行低秩分解,从而减少参数更新量。具体的优化方式如下:
(1)原始线性层的操作
在注意力机制中,通常会对输入特征进行如下操作:
输入特征 X 会通过线性层进行映射,生成 Query (Q)、Key (K) 和 Value (V),具体公式为:

(2)LoRA 的低秩矩阵分解
与原始公式直接更新整个 、 、 矩阵相比,在 LoRA 中通过使用两个更小的矩阵 A 和 B 来表示这些矩阵的变化。
LoRA 通过引入 低秩分解 对权重矩阵进行调整: 、 、 被表示为预训练权重加上一个低秩矩阵的调整:

(3)优化的关键步骤

三、 推理过程中如何应用优化
在推理阶段,LoRA 的优化部分通过如下方式应用于模型:
- 应用权重更新:在推理过程中,LoRA 使用微调后的低秩矩阵 A 和 B,并将它们加到原始的权重矩阵中。例如,计算 Q 时:
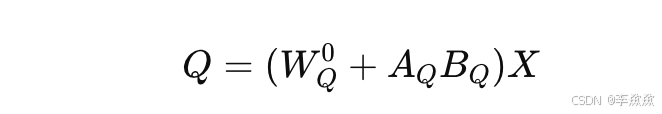
- 这个更新后的权重矩阵确保模型能够在保持原始生成能力的同时,生成包含定制内容的图像。
四、 为什么选择优化这些层
LoRA 选择优化 Attention 层中的线性层 有以下原因:
- Attention 层是核心:在 Stable Diffusion 的 U-Net 中,Attention 层(特别是 Cross-Attention 层)是将图像生成与文本提示结合的关键部分。对这些层进行优化,可以直接影响模型如何将文本信息传递给图像生成过程。
- 低秩分解的有效性:对于大型模型中的全连接层,低秩分解可以在不显著影响模型性能的情况下,显著减少参数更新量。Attention 层中的权重矩阵往往是高维的,因此通过 LoRA 对它们进行低秩分解能大幅降低训练成本。
- 减少计算开销:注意力机制中的线性层通常参数量大且计算密集,通过 LoRA 的低秩分解,可以在降低计算复杂度的同时保留模型的生成能力。
LoRA:只会对 部分 Cross-Attention 和 Self-Attention 层进行局部调整,调整层主要是哪些?
U-Net 中确实包含多个分辨率下的 Self-Attention 和 Cross-Attention 层,但 LoRA 的微调是有选择性的,并不会对每一个 Attention 层进行微调。LoRA 的设计初衷是通过低秩矩阵分解的方式只微调关键的 Attention 层。
LoRA 通常会优先选择在以下部分进行微调,而不会对整个 U-Net 中的所有层进行调整:
(1)瓶颈部分的 Attention 层
理由:瓶颈部分位于 编码器和解码器之间,是整个 U-Net 中分辨率最低的层级。这个部分的特征代表了全局的高层次信息和抽象概念。瓶颈部分的 Cross-Attention 层进行微调,因为这一部分的 Attention 负责将文本嵌入(来自 CLIP)与图像的潜在特征结合。由于这一部分影响整个生成过程的全局结构和语义,微调这里的 Cross-Attention 层可以最大化对文本提示的响应。
(2)解码器中的高分辨率层 Attention
理由:解码器的高分辨率层在解码器靠近输出的层中。这些层逐步将潜在特征映射回高分辨率图像,负责生成最终图像的细节,微调这些层的 Self-Attention 和 Cross-Attention 机制有助于确保图像的细节和纹理质量。LoRA 选择性地微调这些层以保持生成细节的精准度。
(3)部分中间层
理由:中间层出现在编码器部分和解码器部分的中间位置,即编码器将分辨率逐步降低时或解码器逐步上采样时的过渡层。在某些任务中,特别是需要全局一致性时,LoRA 可能会对部分中等分辨率层进行调整。这通常只针对某些关键的中间层,而不会全面覆盖所有中间层的 Attention 层。
其他的层不会进行改变。
DreamBooth会更改全部的Attention层。(3)低秩分解
对于每个需要微调的层,LoRA 将该层的权重矩阵 W 进行低秩分解:

(4)训练 LoRA 的低秩矩阵
在 LoRA 的训练过程中,我们仅训练 A 和 B 这两个低秩矩阵,而保持模型中原始的权重 不变。这种方法显著减少了需要更新的参数量,降低了训练开销。
具体流程:
- 图像和文本输入:使用包含图片和文本描述的数据对模型进行训练,类似于 Stable Diffusion 的预训练任务。
- 损失函数:LoRA 的损失函数与原始 Stable Diffusion 的损失函数类似,主要通过预测噪声残差来进行训练。损失函数通常是均方误差(MSE),公式如下:

- 只更新低秩矩阵:在反向传播时,LoRA 只更新 A 和 B,而保持预训练模型的其余部分不变。通过这样的方法,模型能够在少量参数更新的情况下学会新的任务。
更详细的过程:
- 前向传播(Forward Pass)
- 输入数据准备:输入包括图像和文本描述,这些输入会通过文本编码器(如 CLIP)和 Stable Diffusion 的 U-Net 进行特征提取。
权重替换:

生成 Q、K 和 V 矩阵:
对于输入的图像特征和文本嵌入,模型通过线性层生成 Q、K 和 V 矩阵:
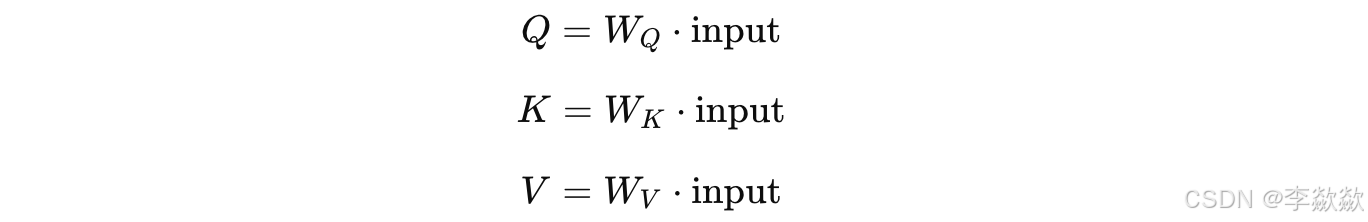
这里 、 和 表示 Attention 层的线性层权重。在 LoRA 微调时,这些权重扩展为:
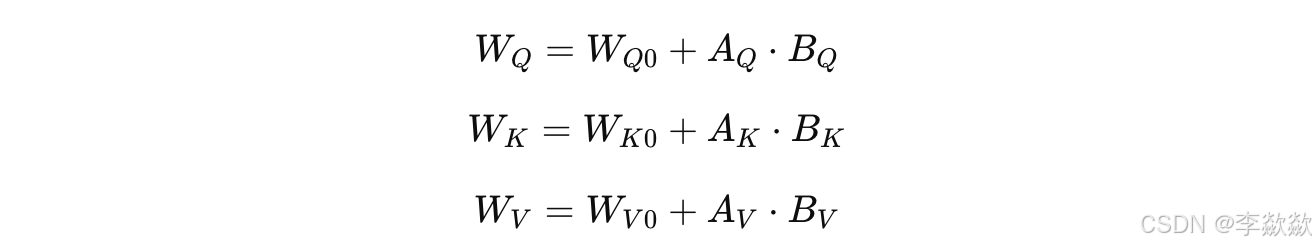
在前向传播时,使用这些新的 Q、K、V 权重来计算 Attention 输出。
计算注意力分数:
得到 Q 和 K 矩阵后,通过点积计算 Attention 分数,并使用 Softmax 进行归一化,以确定图像特征和文本特征的相关性:

其中, 是 Q、K 的维度,用于缩放以稳定梯度。这一步将重要特征赋予更高权重。
应用注意力分数到 Value 矩阵:
将注意力分数应用到 V 矩阵上,生成注意力聚合后的输出特征:
![]()
这一步的输出包含了从输入特征中提取的重要信息,带有新任务的特征细节。
注意力输出用于生成潜在噪声预测【TODO,待补充】
损失计算:
根据前向传播的输出,通过损失函数(通常为均方误差 MSE)计算预测噪声残差与目标的差异:

反向传播(Backward Pass)
计算损失的梯度:
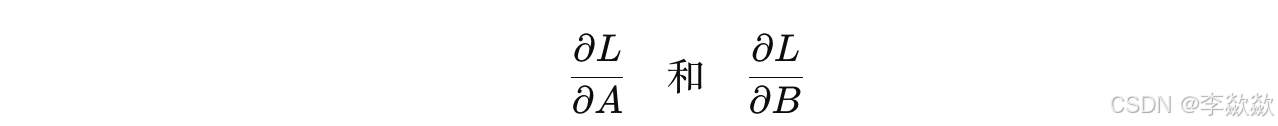
根据损失函数 L,计算损失相对于 A 和 B 的梯度:
锁定原始权重矩阵 :
在反向传播过程中,LoRA 只更新 A 和 B,而保持原始的权重矩阵 不变。这保证了预训练的知识不会被破坏,同时通过 A 和 B 的更新来适应新任务特征。
更新低秩矩阵 A 和 B:
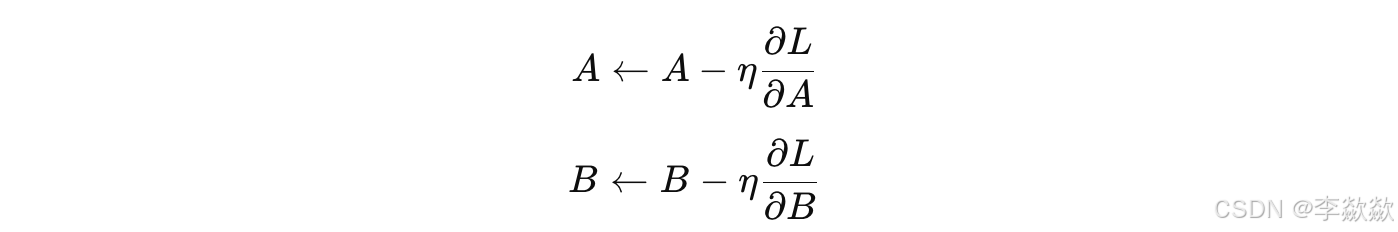
根据梯度,用优化算法(如 Adam)对 A 和 B 的参数进行更新:这里 η 是学习率,更新后的 A 和 B 让模型在不改变预训练权重的前提下适应新任务的特征。
转载于:
SD模型微调之LoRA_sd 的 lora-CSDN博客blog.csdn.net/haopinglianlian/article/details/144499730
个人介绍:知乎名为AItransformer,8年AI老兵,从事NLP、大语言模型、多模态大模型等相关算法的研发和落地,拥有丰富的算法经验,先后在百度、平安、小鹏汽车从事算法落地的工作,借助平台将个人的一些算法研究和经验分享出来,一起推动技术的进步!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)