效率神器!Graph Maker 让文本变知识图谱,复杂流程变三步!
摘要:GraphMaker是一个基于Python的开源库,能够利用大语言模型(如Llama3、Mistral等)从文本语料中自动构建知识图谱。它通过预定义本体(Ontology)来规范实体和关系类型,解决了传统方法在处理非结构化数据时的局限性。该工具支持文本分块处理、子图合并和Neo4j数据库存储,特别适用于Graph-RAG等应用场景。虽然存在实体识别一致性、隐含关系提取等挑战,但通过优化提示词
本文将介绍一个 Python 库 —— Graph Maker,它可以根据指定的本体(Ontology),从一组文本语料中自动生成知识图谱。
Graph Maker 使用的是开源大语言模型(LLM),如 Llama 3,Mistral, Mixtral,Gemma。这些模型被用于从文本中提取出知识图谱(KG)。
为什么要使用图谱?
💡 如果你已经对知识图谱的原理十分熟悉,可以跳过本节。
下面是一张能够简洁概括知识图谱理念的插图:
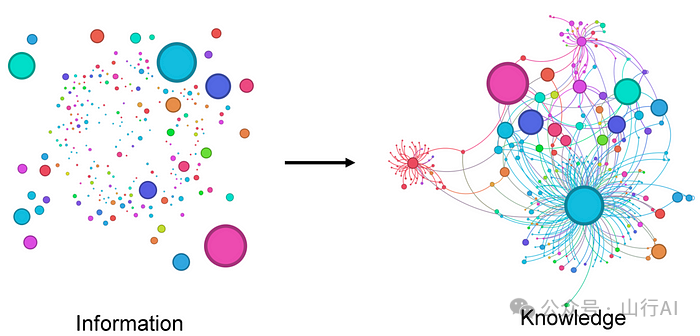
来源:https://arxiv.org/abs/2403.11996
构建知识图谱(KG),需要两类关键信息:
1.知识库(Knowledge Base):这可以是一个文本语料库、代码库、一组文章等。2.本体(Ontology):也就是我们关心的实体类别,以及它们之间的关系类型。 我在这里对“本体”的定义可能有些简化,但对于我们的目的来说足够用了。
示例本体如下:
实体(Entities): Person,Place
关系(Relationships):
Person — related to → Person(人物关联人物)
Person — lives in → Place(人物居住在某地)
Person — visits → Place(人物访问某地)
如果我们拥有上述两类信息,就可以从一篇提到人物与地点的文本中构建一个知识图谱。但假设我们的知识库是一项关于处方药及其相互作用的临床研究,那么我们可能会采用不同的本体,例如实体Compounds(药物成分)、Usage(用法)、Effects(效果)、Reactions(反应)等 ;关系:药物如何影响身体、可能的副作用等。
虽然这种方法在生成知识图谱方面不如传统方法那样严谨,但它也有其优点,它比传统方法更容易处理非结构化数据,可以更快速地生成知识图谱。从某种意义上讲,它生成的知识图谱本身也是“非结构化”的,但这些图谱构建起来更容易,所包含的信息更丰富。因此,这种方式非常适用于像 GRAG(Graph Retrieval Augmented Generation) 这样的应用场景。
为什么要选择 Graph Maker?
接下来,我列出一些在上一篇文章中收到的反馈中提到的问题和观察,这将有助于我们理解使用大语言模型构建知识图谱时面临的挑战。我们以《魔戒》(The Lord of the Rings)系列书籍在 Wikipedia 上的简介为例,毕竟——谁能不爱魔戒呢?
有意义的实体识别(Meaningful Entities)
当没有人为干预时,LLM 所提取的实体在类别上可能过于分散或随意。它往往会错误地把抽象概念当作实体来提取。
举个例子,文本原句:“Bilbo Baggins celebrates his birthday and leaves the Ring to Frodo”(比尔博·巴金斯庆祝他的生日,并将魔戒留给佛罗多)。
LLM 的提取结果可能是:“Bilbo Baggins celebrates his birthday”(比尔博庆祝生日)或 “Celebrates his birthday”(庆祝生日),并将其标记为一个“动作(Action)”。
但如果将 “Birthday(生日)” 提取为一个“事件(Event)”,可能会更有意义。
实体的一致性(Consistent Entities)
LLM 还可能在不同语境下将同一个实体识别为不同的实体。例如:
“Sauron”(索伦),“the Dark Lord Sauron”(黑暗魔君索伦),“the Dark Lord”(黑暗魔君),这三者本质上是同一个实体,不应该被提取为三个不同的实体。即使被提取为不同的实体,它们之间也应当通过“等价关系(equivalence relationship)”相连。
解析鲁棒性(Resilience in Parsing)
LLM 的输出天生具有不确定性。当我们需要从一份大型文档中提取知识图谱时,通常要 将语料拆分成小段文本,为每段文本生成子图,将多个子图合并为一个完整图谱。这就要求 LLM 在处理每段文本时,始终按照指定的 JSON schema 输出结果。一旦有某一段缺失或格式不正确,就可能影响整个图谱的连通性。
虽然现在的 LLM 在输出结构化 JSON 上已有显著提升,但依然远未达到完美。特别是当使用上下文窗口较小的模型时,生成的响应很容易出现不完整或缺漏。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

实体分类(Categorisation of the Entities)
LLM 在识别实体时可能会严重误判,特别是在上下文较为专业、术语特殊,实体不是标准英文命名,涉及领域知识较深的内容时。虽然命名实体识别模型(NER)在这方面表现更稳定,但它们也受限于自身的训练数据,且不能理解实体之间的关系。
要让 LLM 在分类时保持一致性,更多依赖的是“提示词工程(prompt engineering)”的技巧与艺术。
隐含关系(Implied Relations)
实体之间的关系有时是明确表达的,有时则是由上下文推断出来的。举个例子:
原文:
“Bilbo Baggins celebrates his birthday and leaves the Ring to Frodo”
(比尔博·巴金斯庆祝生日,并将魔戒留给佛罗多)
这段话隐含的关系包括:
•Bilbo Baggins → Owner → Ring(比尔博 是 魔戒 的拥有者)•Bilbo Baggins → heir → Frodo(比尔博 将 魔戒 传承给 佛罗多)•Frodo → Owner → Ring(佛罗多 成为 魔戒 的新主人)
我认为未来某个时刻,LLMs 在关系抽取方面会超过任何传统方法。但就目前而言,这仍是一个尚待解决的挑战,依赖于巧妙的提示词设计(prompt engineering)来引导模型正确理解和提取这些隐含关系。
Graph Maker 简介
我在这里分享的 Graph Maker 库,在严谨性与易用性之间取得了平衡,也就是说,它在结构化与非结构化之间找到了中间地带。在大多数前面提到的挑战中,它的表现都显著优于旧方案。
与“让 LLM 自行发现本体”不同,Graph Maker 的策略是引导(coerce)LLM 使用用户预定义的本体(ontology)
我们只需一条简单的 pip 命令即可安装该库:
pip install knowledge-graph-maker📦 knowledge-graph-maker - Create a knowledge graph out of any text using a given ontology 来自 PyPI 的开源包
它是如何工作的?——只需 5 个简单步骤
这些步骤已经被编写在本文末尾分享的 Jupyter Notebook 中。
1. 定义图谱的本体(Ontology)
该库支持以下形式的本体定义,底层采用的是 Pydantic 模型。
ontology =Ontology(# 要提取的实体标签,可以是字符串或字典对象,如下所示:labels=[{"Person":"不要添加任何形容词,仅使用人名。注意人物可能以代词或名字出现"},{"Object":"不要在对象名称前加定冠词 'the'"},{"Event":"事件应为涉及多人的事件,不包含 'gives'、'leaves'、'works' 等动词"},"Place","Document","Organisation","Action",{"Miscellaneous":"无法归入上述类别的其他重要概念"},],# 与应用场景相关的重要关系类型# 实际上是提示模型关注特定关系,不能保证仅提取这些关系,但多数模型表现良好relationships=["Relation between any pair of Entities",],)
我已经对提示词进行了调优,使其输出尽量符合所定义的本体结构。实际效果非常不错,虽然尚不能做到 100% 准确。图谱构建的准确性仍然依赖于多个因素,包括所选的语言模型,应用场景,所设定的本体,语料本身的质量。
2. 将文本分块(Split the text into chunks)
我们可以使用任意大的文本语料库来构建大型知识图谱,
但 LLM 当前仍然存在上下文窗口限制,因此我们需要适当地将文本进行分块,并逐块构建图谱。应使用的分块大小取决于所选模型的上下文窗口大小。
本项目中使用的提示词大约消耗 500 个 token,剩余的上下文可以分配给输入文本和输出图谱。
✅ 经验提示:
使用 200 到 500 tokens 的小块通常能生成更详细的图谱。
3. 将这些文本块转换为 Document 对象
Document 是一个 Pydantic 模型,其结构如下:
## Pydantic Document 模型classDocument(BaseModel):text: strmetadata: dict
我们在此添加的 metadata 元信息,会绑定到该文档中提取的每一条关系上。例如,我们可以在 metadata 中加入关系出现的上下文信息,如页码(page number),章节名(chapter),文章名(article name)。通常,同一对实体在多个文档中会出现多种关系,元信息可以帮助我们为这些关系提供上下文语义支持。
4. 运行 Graph Maker
Graph Maker 会直接接收一个 Document 列表,并逐个处理生成子图。最终输出是所有文档组成的完整图谱。
以下是一个简单示例:
from knowledge_graph_maker importGraphMaker,Ontology,GroqClient## 选择一个 Groq 支持的模型model ="mixtral-8x7b-32768"# model = "llama3–8b-8192"# model = "llama3–70b-8192"# model = "gemma-7b-it" # 这个模型可能是最快的,但略显不准确## 初始化 Groq Clientllm =GroqClient(model=model, temperature=0.1, top_p=0.5)graph_maker =GraphMaker(ontology=ontology, llm_client=llm, verbose=False)## 创建图谱graph = graph_maker.from_documents(docs)print("Total number of Edges", len(graph))# 输出:Total number of Edges 1503
Graph Maker 会将每个文档送入 LLM,解析其响应内容并构建最终图谱。最终输出的是一组边(Edge)对象的列表,每条边都是如下的 Pydantic 模型:
classNode(BaseModel):label: strname: strclassEdge(BaseModel):node_1:Nodenode_2:Noderelationship: strmetadata: dict ={}order:Union[int,None]=None
我已经调优了提示词,使其生成的 JSON 基本保持一致。如果返回的 JSON 无法正常解析,Graph Maker 会尝试手动将 JSON 字符串拆分为多段边结构,并尽可能地恢复有用信息。
5. 保存到 Neo4j(Save to Neo4j)
我们可以将图谱保存到 Neo4j 图数据库,用途包括但不限于 构建 RAG 应用(检索增强生成),运行 网络算法(如图遍历、中心性分析等),或仅用于通过 Neo4j Bloom[1] 可视化图谱。
以下是保存到 Neo4j 的示例代码:
from knowledge_graph_maker importNeo4jGraphModelcreate_indices =Falseneo4j_graph =Neo4jGraphModel(edges=graph, create_indices=create_indices)neo4j_graph.save()
每一条图谱中的边(Edge)都会作为一个事务(transaction)被写入数据库。第一次运行代码时,请将 create_indices 设置为 True,这将为图数据库设置节点的唯一约束(Uniqueness Constraints),做好图结构初始化准备。
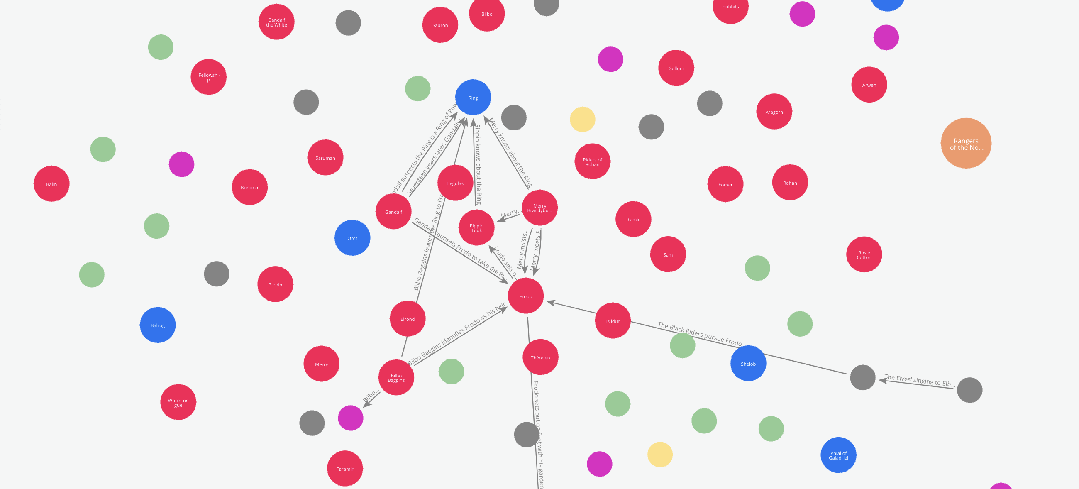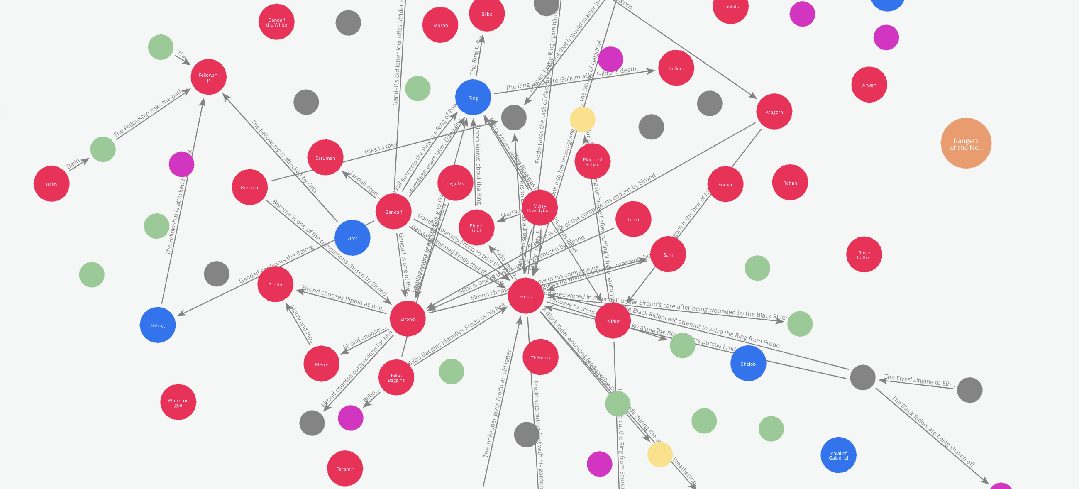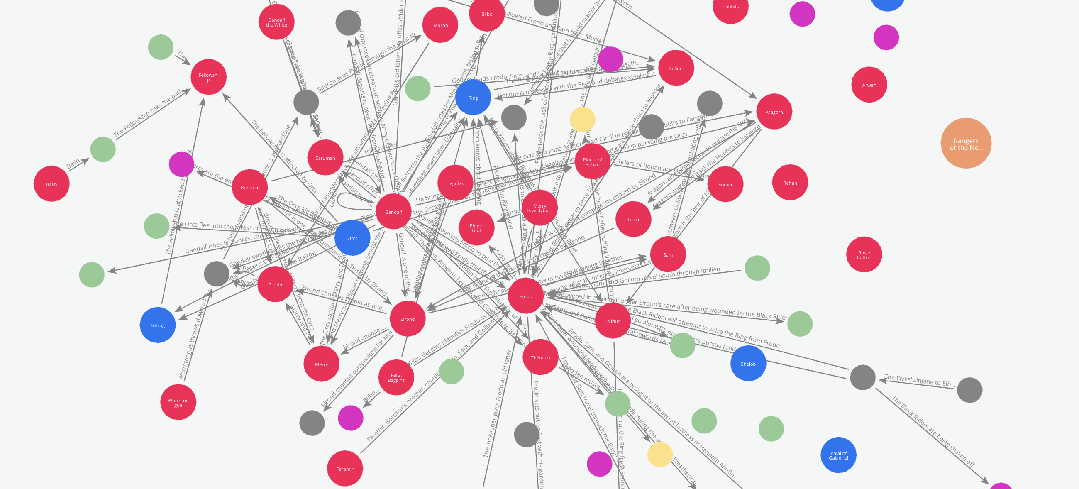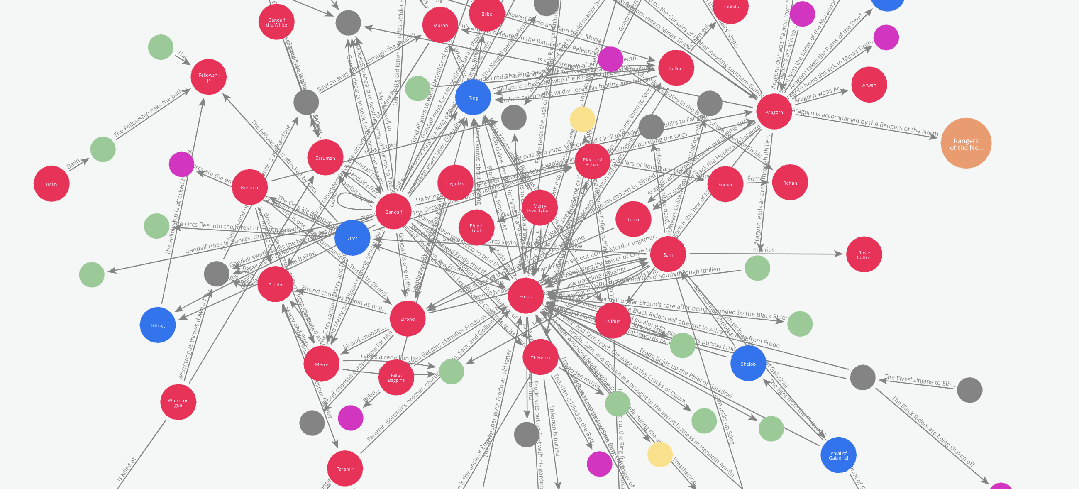
5.1 图谱可视化 —— 只是为了好玩也值了
在上一篇文章中,我们使用 networkx 和 pyvis 库对图谱进行了可视化。而在本例中,由于我们已经将图谱保存到了 Neo4j,我们可以直接使用 Neo4j Bloom 进行图谱可视化。
为了避免重复之前的内容,这次我们来做一个不同风格的可视化:
假设我们想要观察书中人物关系随剧情发展而变化的过程。
我们可以通过以下方式实现:
在 Graph Maker 处理整本书的过程中,动态记录边的添加顺序,从而追踪人物关系的演化。
为实现这一目标,Edge 模型中有一个名为 order 的属性。这个属性可以为图谱添加一个时间序列或事件顺序的维度。
在我们的示例中,Graph Maker 会自动为每个被处理的文本块赋予一个序号(即该块在文档列表中的位置),
并将该序号添加到它提取的每一条边中。因此,如果我们想观察人物关系的演化,只需根据 order 对图谱进行切片即可。
下面是一段这些图谱切片的动画演示:
图谱与 RAG(Graph and RAG)
这种类型的知识图谱最理想的应用场景大概就是 RAG(检索增强生成) 了。已经有无数文章在讨论如何将图谱集成进 RAG 应用中。
本质上,图谱为知识检索提供了丰富多样的方式。 根据我们对图谱结构和应用目标的设计,有些技术甚至比单纯的语义搜索更强大。
在最基础的层面,我们可以将嵌入向量(embedding vectors) 添加到节点和关系中,然后通过向量索引进行语义检索。但我认为,图谱在 RAG 应用中的真正力量,体现在将 Cypher 查询、网络算法和语义搜索混合使用时的能力。
源代码仓库(The Code)
以下是 GitHub 仓库链接,欢迎你下载试用👇:
📦 GitHub - rahulnyk/graph_maker[2]
Contribute to rahulnyk/graph_maker development by creating an account on GitHub.
仓库中包含了一个 Python 示例 Notebook,可以帮助你快速上手。
⚠️ 请注意:在使用之前,你需要在 .env 文件中添加你的 GROQ 凭证(API Key)。
如果你也愿意为这个开源项目做出贡献,欢迎参与,让它成为你的一部分。
大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献752条内容
已为社区贡献752条内容

所有评论(0)