【GNN】第五章:传统图机器学习算法:Deepwalk、Node2Vec、PageRank
摘要:本文介绍了三种传统图机器学习算法——DeepWalk、Node2Vec和PageRank,用于将图数据嵌入低维向量空间。DeepWalk通过随机游走生成节点序列,类似NLP的滑窗操作,再使用Word2Vec训练得到节点嵌入向量。Node2Vec在DeepWalk基础上引入有偏随机游走策略,通过调整参数p和q控制游走方向,能捕捉节点不同特性。PageRank则用于计算节点重要性排名。文章还演示
【GNN】第五章:传统图机器学习算法:Deepwalk、Node2Vec、PageRank
这些算法都是用来进行图数据信息嵌入的,就是把图数据中的节点、边、子图、整图等信息,嵌入或者说映射成一个低维的、稠密的向量。
一、DeepWalk
DeepWalk是深度学习思想用于图嵌入的开山之作。
论文名称:DeepWalk:Online Learning of Social Representations,发表于2014年的KDD学术会议上, 原作者还有这个论文的一个PPT。
论文下载地址:https://arxiv.org/pdf/1403.6652
1、完全随机游走
我们知道word2vec是通过滑窗操作,从文本语料中获取模型训练数据的。但是图数据和文本语料是天差地别的,那要向量化图数据中信息,滑窗肯定是不行的,于是人们想出了随机游走deepwalk的方法,来从图数据中获取训练模型的训练数据。
所以随机游走等同于滑窗操作。也所以随机游走也同滑窗思想一样简单易懂,就是在一个图数据中随机选中一个节点,然后人为规定随机游走几步、游走几次,就自动生成了一系列游走序列。那这些游走序列就等同于滑窗操作生成的训练文本,就可以直接送入CBOW或者Skip-gram训练了,进而获取图数据中的节点的嵌入向量。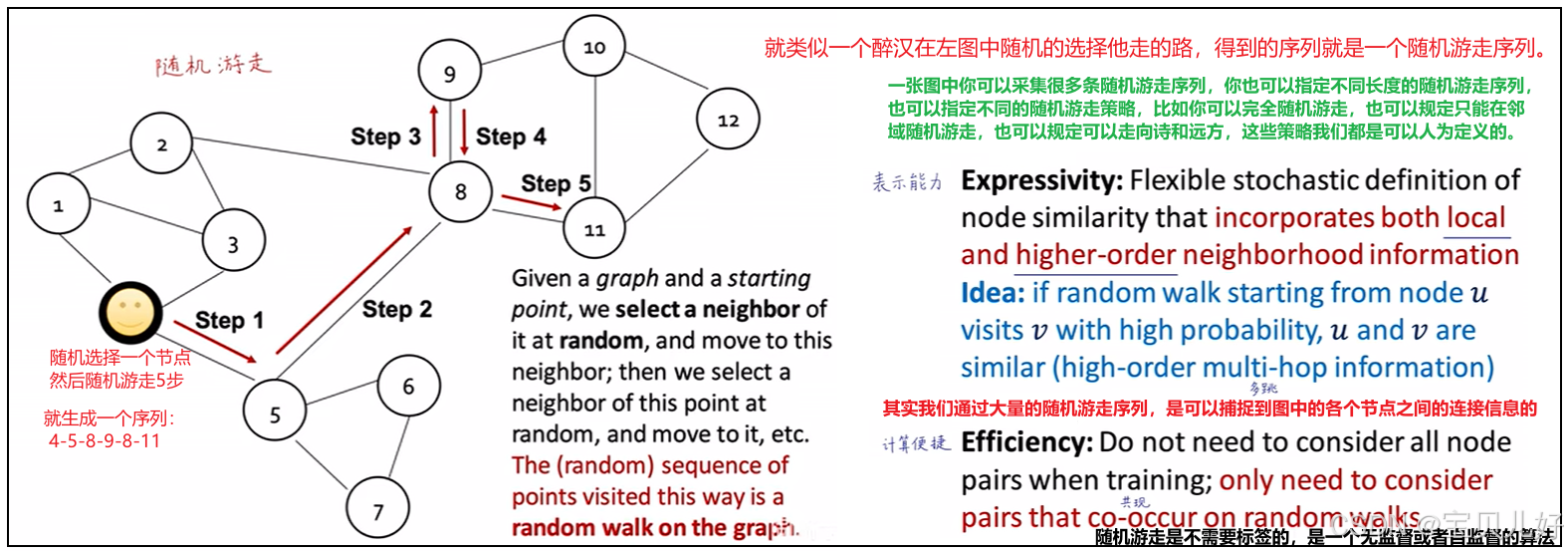
完全随机游走也叫均匀随机游走,通俗的类比就是,你假设有一个醉汉,这个醉汉在图中完全随机的选择他走的路,得到的序列就是一个随机游走序列。
下面我用一个例子来展示一下随机游走在图节点嵌入中的作用:
#1、导入西游记三元组文件
import pandas as pd
df = pd.read_csv(r'D:\pytorch-data\四大名著\西游记\triples.csv')
df[:5] 
#2、将三元组转化为图数据
import networkx as nx
G = nx.from_pandas_edgelist(df, 'head', 'tail')
#3、将图数据可视化
plt.rcParams['font.sans-serif'] = ['SimHei'] #显示正文
plt.rcParams['axes.unicode_minus'] = False #显示正负号
plt.figure(figsize=(20, 12))
pos = nx.spring_layout(G, seed=10)
nx.draw(G, pos, with_labels=True, node_size=20)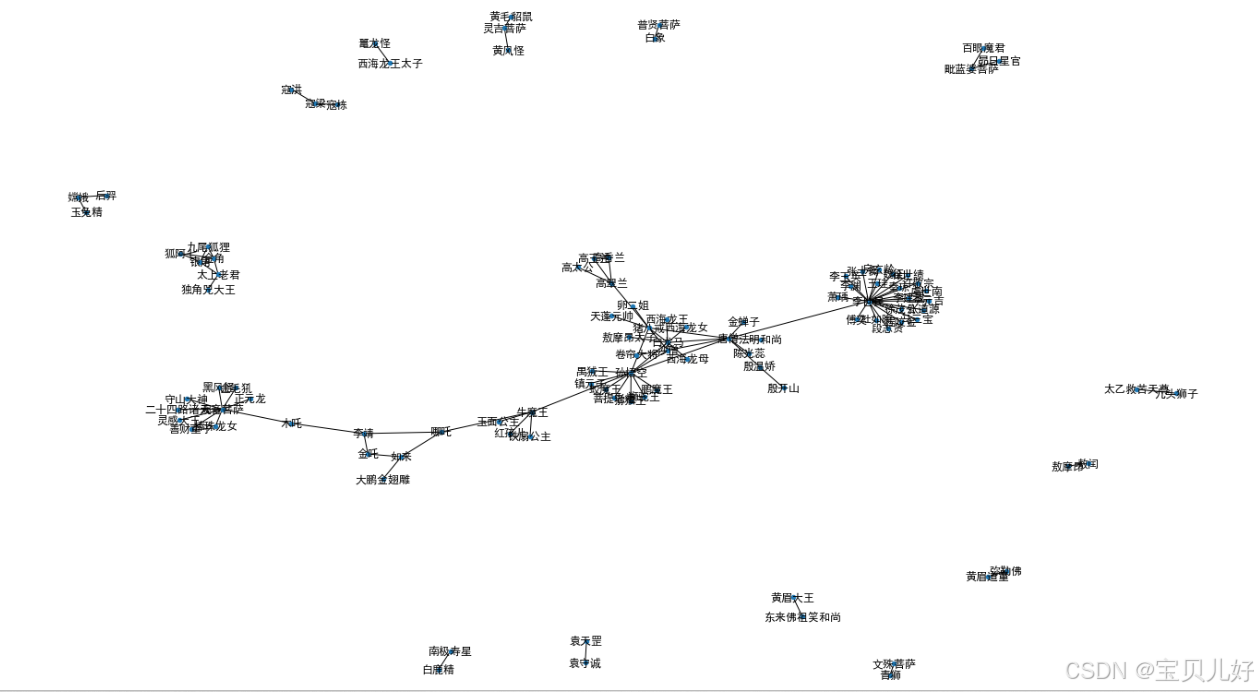
#4、写随机游走函数
def get_one_randomwalk(node, path_length): #输入一个要游走的起始点,和游走的步数
randomwalk_list = [node]
for i in range(path_length):
temp = list(G.neighbors(node))
if i > 0:
temp.remove(randomwalk_list[-2])
if len(temp) == 0:
break
next_node = random.choice(temp)
randomwalk_list.append(next_node)
node = next_node
return randomwalk_list
def get_randomwalks(G, path_length, path_num): #某个起始点要随机游走几次
all_nodes = list(G.nodes())
random_walks = []
for node in all_nodes:
for i in range(path_num):
sample = get_one_randomwalk(node, path_length)
random_walks.append(sample)
return random_walks
#5、获取随机游走序列
randomwalks = get_randomwalks(G, 5, 10)
len(randomwalks)
randomwalks
#6、用gensim库中的word2vec进行节点嵌入
from gensim.models import Word2Vec
model = Word2Vec(vector_size=16, #你想嵌入成多少维的向量
window=2, #窗口宽度,就是左边看2个词,右边看2个词
sg=1, #skip-gram用中心才来预测周围词。sg=0是CBOW:用周围词来预测中心词
hs=0, #不加分层softmax
negative=10, #负采样
alpha=0.03, #初始学习率
min_alpha=0.0007, #最小学习率
seed=0)
model.build_vocab(randomwalks, progress_per=2)
model.train(randomwalks, total_examples=model.corpus_count, epochs=100, report_delay=1)
#导出向量
nodes = list(G.nodes())
node_vec_dic = {}
for i in nodes:
vect = list(model.wv.get_vector(i))
node_vec_dic[i] = vect
node_vec_df = pd.DataFrame(node_vec_dic).T
node_vec_df[:5]
#7、PCA降维看看嵌入的效果
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca_2d = pca.fit_transform(node_vec_df)
pca_2d.shape
_ = plt.figure(figsize=(25,16))
_ = plt.scatter(pca_2d[:,0], pca_2d[:,1], s=200)
for i, label in enumerate(nodes):
_ = plt.text(pca_2d[i,0], pca_2d[i,1], label)
plt.show()
#8、TSNE降维看看嵌入的效果
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, n_iter=500)
embed_tsne = tsne.fit_transform(node_vec_df)
embed_tsne.shape
_ = plt.figure(figsize=(25,16))
_ = plt.scatter(embed_tsne[:,0], embed_tsne[:,1], s=200)
for i, label in enumerate(nodes):
_ = plt.text(embed_tsne[i,0], embed_tsne[i,1], label)
plt.show()
通过这个例子我们可以看到,deepwalk是不需要标签的,是一个无监督或者自监督的算法。通过大量的随机游走序列,我们是可以捕捉到图中的各个节点之间的连接信息的。
在原作者的PPT中还有如何构造损失函数、随机梯度下降、采集负样本等相关的数学公式和数学推导,这些我就不截图了,因为我个人感觉写一些代码,指定一些规则,随机游走序列就生成了,没必要数学证明吧。
2、有偏随机游走Biased Walks
从上面的例子中,我们可以直观的看到,随机游走就是从图数据中获取、可以直接喂入模型的训练数据的策略或者方法。
一张图中你可以采集很多条随机游走序列,你也可以指定不同长度的随机游走序列,也可以指定不同的随机游走策略,比如你可以完全随机游走,也可以规定只能在邻域随机游走,也可以规定可以走向诗和远方,这些策略我们都是可以人为定义的。
Node2Vec算法中的随机游走策略就是有偏的随机游走,有的也叫二阶随机游走,它有深度搜索和宽度搜索,就是我说的邻域游走和远方游走。但是不管怎样,它都是从图数据中生成训练数据的一种策略而已。下图是作者PPT中的截图: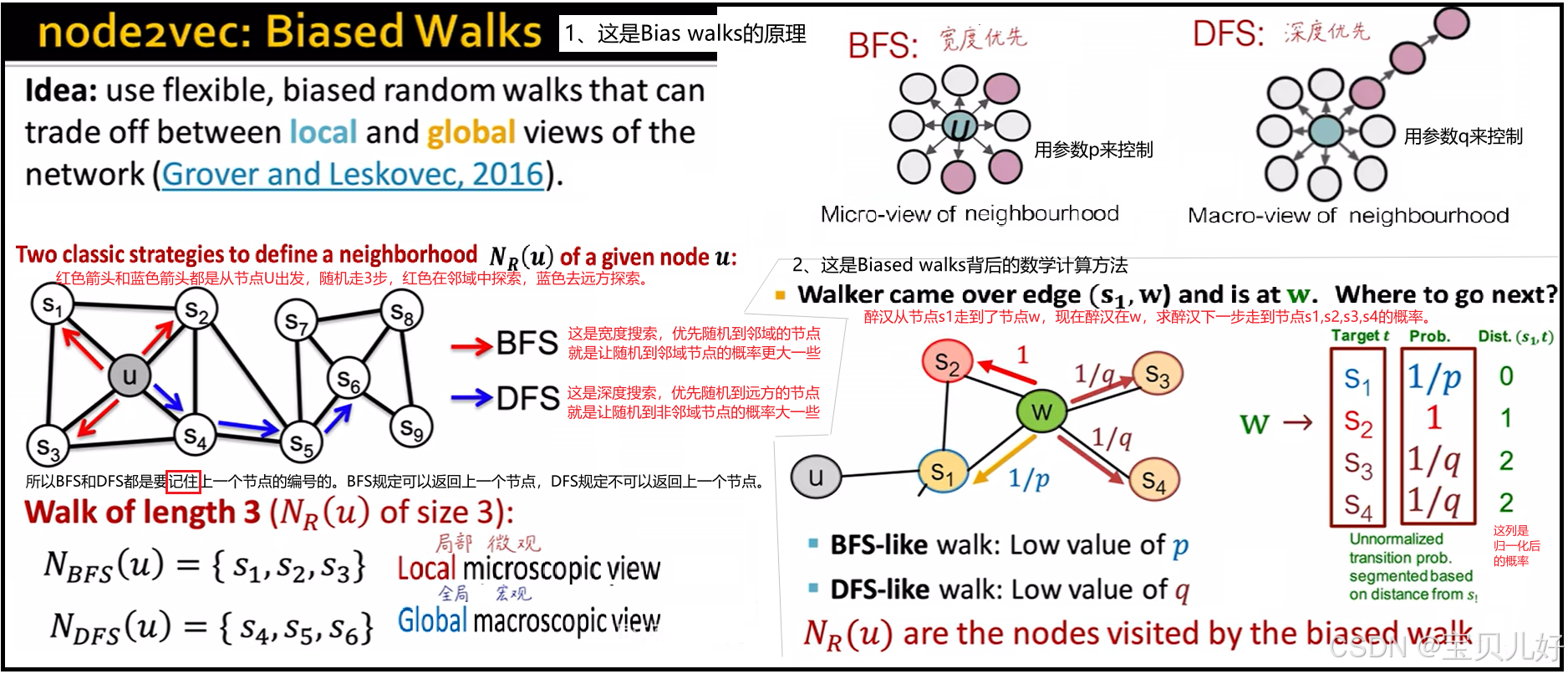
原作者PPT中说:不同p、q组合,可以实现不同的搜索,进而达到不同的效果。比如,p大q小,就是优先探索远方,而优先探索远方得到的数据序列,其生成的节点嵌入更容易反映同质社群这个属性。p小q大,是优先探索近邻,而优先探索近邻得到的数据序列更多反映的是局部微观区域,所以这些序列生成的节点嵌入就更容易反映节点的功能角色信息,比如是否是中枢节点、桥接节点、边缘节点等这些信息。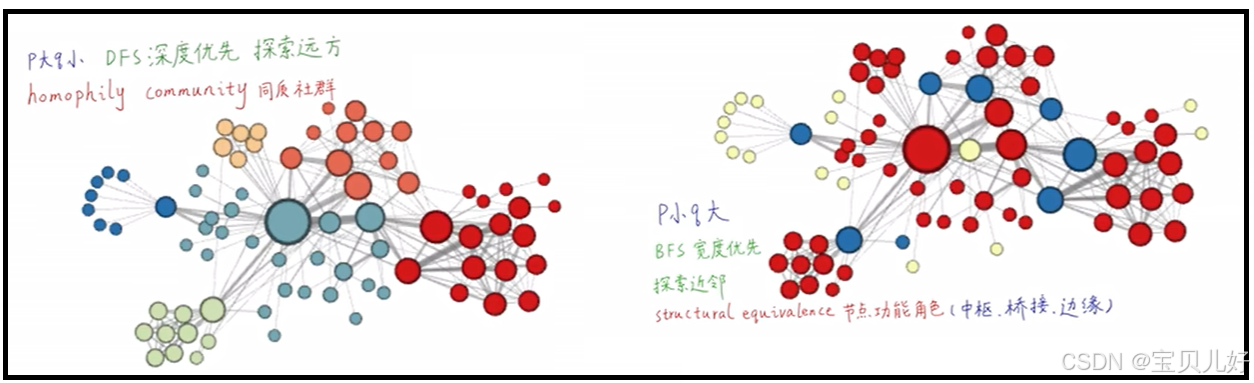
上图效果看似非常好,但是在实际操作中,p和q是很难调的,所以我们也是很难能达到这个效果的。
除了上述node2vec中打包的有偏游走策略,还有比如下图所示的这些游走策略,以及你选择的标准:
3、匿名游走
均匀随机游走和有偏随机游走都是"窗口"的思想,所以一般都是用来进行图节点嵌入的。如果我们想对整图进行嵌入呢?一般有下面几种解决方案:
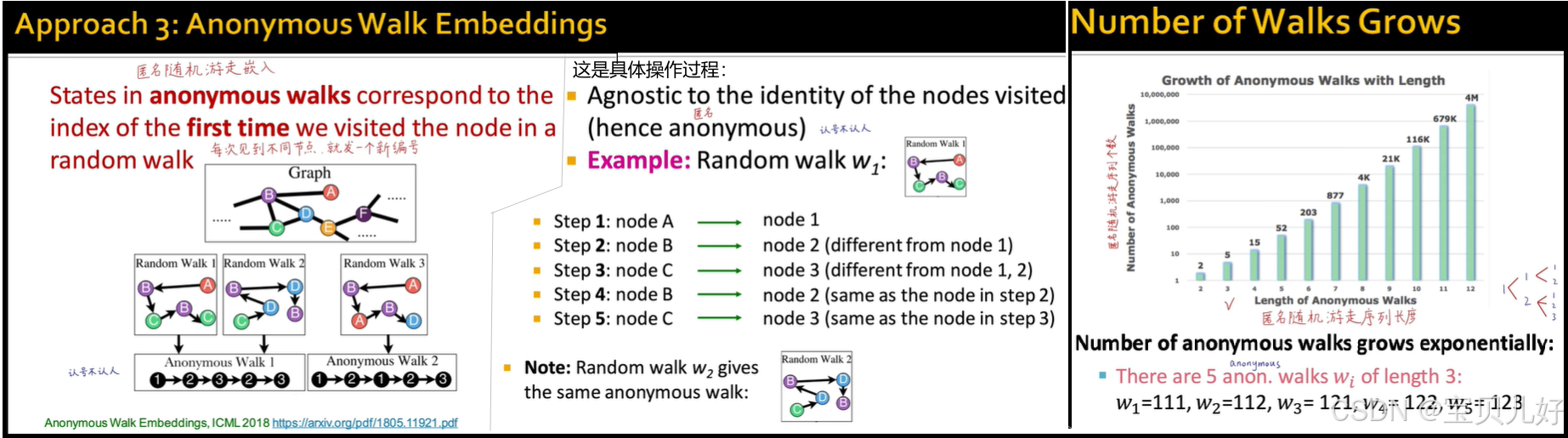
方法3就是匿名游走。匿名游走的个数,随步数呈几何级数增长。比如3个节点有5种匿名随机游走,4个节点有15种匿名随机游走。 以3个节点为例,我们把每种匿名随机游走的可能路径个数当作那个维度上的向量值,这样就生成了一个5维的向量,这个5维向量就可以用来表示整图。
匿名游走的论文链接是:https://arxiv.org/pdf/1805.11921 ,感兴趣的同学翻翻原论文吧。
二、Node2Vec
node2vec论文下载地址: https://arxiv.org/pdf/1607.00653
node2vec的前身是Word2Vec。Word2Vec是NLP领域中的把词嵌入成向量的算法。node2vec就是借鉴Word2Vec,二者无太多区别。前面我浩浩荡荡写了三万多字的Word2vec:【GNN】第四章:表示学习算法Word2Vec、CBOW、Skip-gram、hierarchical softmax、负采样_gcn-CSDN博客 就是为本篇的Node2vec打基础的。所以对word2vec有深刻理解了,node2vec就轻车熟路了。
Node2Vec算法是通过随机游走Deepwalk的方法,构造无监督或者说是自监督学习任务,来实现图数据嵌入的。所以也叫图表示学习算法,Node Embedding。也所以Node2Vec算法中实际上是打包了bias deepwalk算法的。所以这里我就通过例子来展示一下即可:
#1、导入西游记三元组文件
import pandas as pd
df = pd.read_csv(r'D:\pytorch-data\四大名著\西游记\triples.csv')
#2、将三元组转化为图数据
import networkx as nx
G = nx.from_pandas_edgelist(df, 'head', 'tail')
#3、构建Node2Vec模型
from node2vec import Node2Vec
node2vec = Node2Vec(G, dimensions=16, #嵌入的维度
p=2, q=0.5, #回家参数、外出参数
walk_length=5, #随机游走最大长度
num_walks=10, #每个节点作为起始节点生成的随机游走个数
workers=2) #并行线程数
#论文中给出的经验参数组合:
#p=1, q=0.5, n_clusters=6 DFS深度优先搜索,挖掘同质社群
#p=1, q=2, n_clusters=3 BFS宽度优先搜索,挖掘节点的结构功能。
#4、训练模型,生成节点的嵌入向量
model = node2vec.fit(window=3, #skip-gram窗口大小
min_count=1, #忽略出现次数低于此阈值的节点(词)
batch_words=4) #每个线程处理的数据量
#5、导出向量
nodes = list(G.nodes())
node_vec_dic = {}
for i in nodes:
vect = list(model.wv.get_vector(i))
node_vec_dic[i] = vect
node_vec_df = pd.DataFrame(node_vec_dic).T
node_vec_df[:5]#6、PCA降维看看嵌入的效果
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca_2d = pca.fit_transform(node_vec_df)
pca_2d.shape
_ = plt.figure(figsize=(25,16))
_ = plt.scatter(pca_2d[:,0], pca_2d[:,1], s=200)
for i, label in enumerate(nodes):
_ = plt.text(pca_2d[i,0], pca_2d[i,1], label)
plt.show()
#7、TSNE降维看看嵌入的效果
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, n_iter=500)
embed_tsne = tsne.fit_transform(node_vec_df)
embed_tsne.shape
_ = plt.figure(figsize=(25,16))
_ = plt.scatter(embed_tsne[:,0], embed_tsne[:,1], s=200)
for i, label in enumerate(nodes):
_ = plt.text(embed_tsne[i,0], embed_tsne[i,1], label)
plt.show()#8、社群检测
from networkx.algorithms import community
cluster = community.label_propagation_communities(G)
len(cluster)
cluster
dic = {}
for index, name in enumerate(list(cluster)):
for i in name:
dic[i] = index
color = []
for i in list(G.nodes):
color.append(dic[i])
plt.figure(figsize=(16,8))
nx.draw(G, node_size=50, node_color=color)
三、PageRank
这个算法已经非常过时了,本来是想调包走一遍就过了,但是当我完这个算法后,还是忍不住想把它记录下来。
PageRank是谷歌的发家算法,也是曾经改变世界的一个算法。在1997年之前,各家搜索引擎都很不理想,搜索到的网页只有20%的相关度,也所以那时的互联网也不温不火,直到1997年谷歌的第一代搜索引擎算法PageRank诞生,直接把搜索引擎的相关度**从20%提升到80%**,由此引爆互联网,我们开始大踏步迈入互联网时代,谷歌也借此一举超过雅虎、微软,成为了当时的传奇...搜索有多重要,看看国内的百度就知道了...
崇拜一下:pagerank的论文名称是《The PageRank Citation Ranking:Bring Order to the Web》,论文链接:http://ilpubs.stanford.edu:8090/422/1/1999-66.pdf 该论文被称为改变世界的十大IT论文、是线性代数的经典应用的典范、是搜索引擎、信息检索、图机器学习、图数据挖掘等领域的必读论文。我们先科普一下改变世界的十大IT论文:图灵机、香农信息论、维纳控制论、比特币白皮书、pagerank、AlexNet、ResNet、Alpha Go、Transformer、AlphaFold2。虽然我不是全部都看过,但从名字上就不明觉厉了,图灵香农都是神级人物啊...至于线性代数的典范,可能你要去学点泛函分析啥的,才能深刻领悟线代吧...
科普一下:PageRank这个算法其实就是计算互联网中的所有网页的重要性的算法。它把互联网中的每个网页看作一个节点,网页中的链接看成节点和节点之间的边,由此,互联网就是一个巨大的图。pagerank是计算图中的每个节点的重要性,具体的就是根据图中的节点的链接信息,给图中的每一个节点都算一个重要度,然后根据节点的重要度进行搜索推荐。
引申一下:pagerank算法还有两个变种:personalized pagerank(PPR)和 Random Walk with Restarts, 这两个变种是用来计算两个节点相似度问题的。而节点相似度也可以用在推荐系统中。
1、PageRank算法的思路
pagerank把互联网抽象成图数据,节点表示网页,节点和节点之间的链接就是边。
边是带方向的,分in-coming links 和 out-going links。其中in-coming links比较重要,表示别的节点引用我这个网页的重要性高于我引用别的网页。此外,来自重要页面的引用比非重要页面的引用权重更高。我们要根据这两个约束条件,来计算节点的重要性。

那如何用数学来表示并计算呢?从简单到复杂!,对,我先弄一个极简的图看看怎么算:
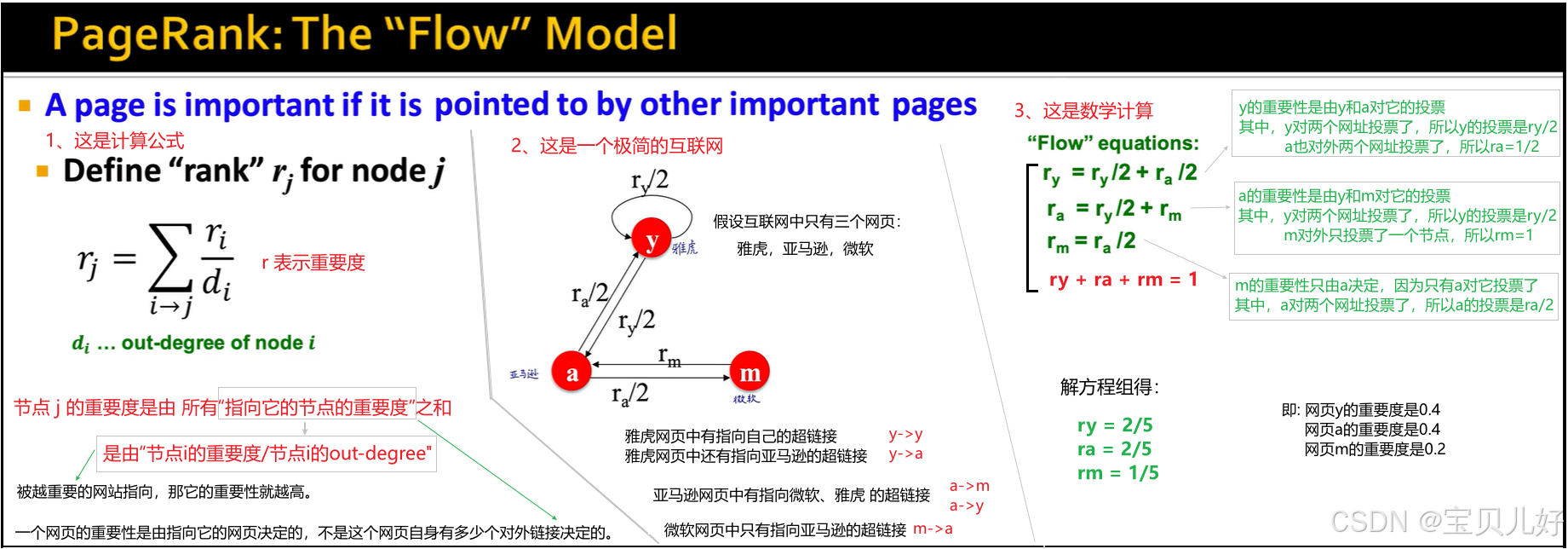
从上图的极简场景来看,这样计算是非常make sense的。一是,每个节点的重要性只与有多少网页指向它有关,而非它有多少个链接指向别人,这样就可以有效防止某些网址为刷高重要性分数而恶意放大量的链接。就是你的网页上即使有大量的对外链接,也不会被算出很高的重要性分值,只有有其他重要性网址指向你,你的重要性才高!二是,对于所有指向它的网址,那个网址的重要性越高,那这个网址对它的重要性的贡献就越大!这是非常合理的,也非常符合常识的。
从上图的极简情形看,这样计算似乎还不错,那我们把它推广到一般情形。而推广到一般的过程中是要遇到很多问题的,所以这里我就按问题来讲解。
问题1:如何更快更省力的求解方程组?
上图的方程组,我们一般是把方程的右边都化为0,生成这个方程组的增广矩阵,然后用高斯消元法解方程组的。但是这种解法太低效,那我们回头再研究研究这个方程组:
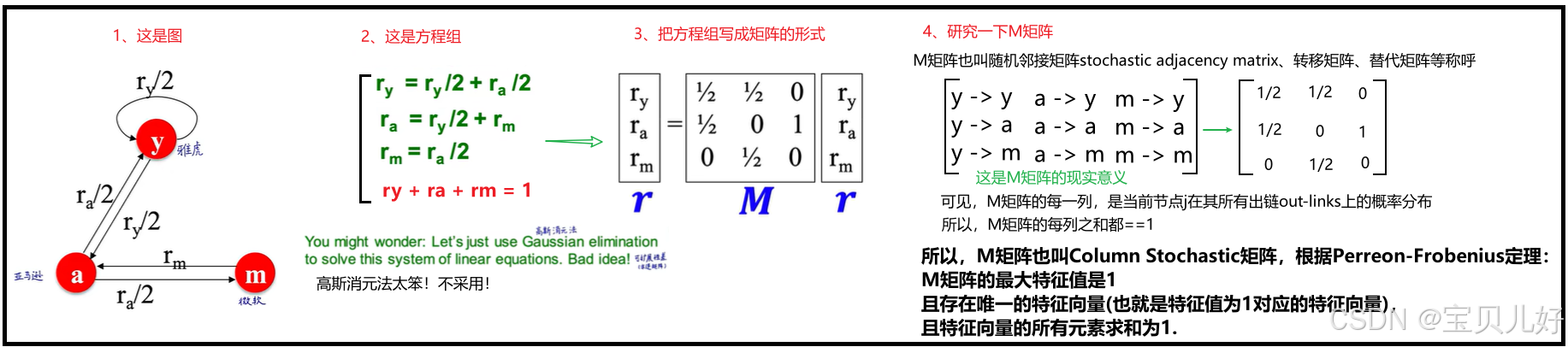
大概意思就是M矩阵只有一个特征值,就是1,那特征值1对应的特征向量就是方程组的解。或者我们可以肯定方程组肯定是有解的,而且所有解的和是1。那到底该怎么求这个特征向量呢?即使我们已经知道M的特征值是1,我们也不能用(E-M)x=0解特征向量吧,是不是又转回来解方程了?!看看pagerank是如何解的:

事实上,我只要迭代20次,答案就基本和我手动计算的结果相近了。这个不断左乘M矩阵的方法真是好,一是计算高效,计算机最擅长矩阵乘法了;二是可扩展性也好,当有新的节点加入或者退出图时,只需要重新迭代一下即可。
这里很多同学会问,为啥不断左乘M就可求解?上图是斯坦福CS224W《图机器学习》课程(2021)by Jure Leskovec PageRank部分的学习笔记的截图,其实我也没有找到数学推导,查阅了一些资料,据说是巴纳赫不动点定理啥的,总之和线性代数密不可分,这块我是没研究透,以后再补充吧。
问题2:幂迭代法是不是永远有效?就是会不会总是收敛的?收敛后的向量是不是我们要的解?不同的初始化对收敛有没有影响?
此处我把CS224W的ppt贴出来,大家自己看吧:
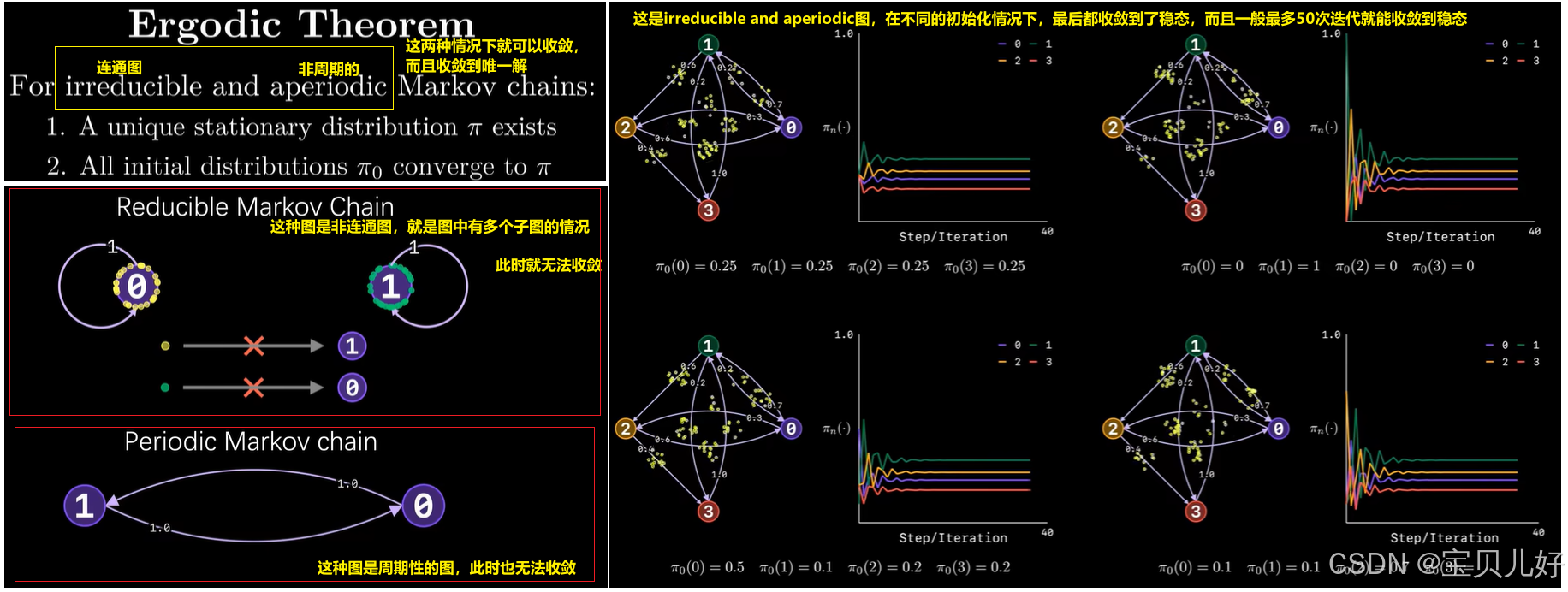
问题3:Dead Ends
Dead Ends就是上图中的Reducible的情况,就是一些页面是死胡同(没有外链),这样的页面就会导致importance "leak out",结果不收敛。从M矩阵的角度看就是:M矩阵的列的和不再是1,而是全0的情况,此时不断左乘M也不会收敛。此时的解决方法是:人为添加对外链接!

问题4:Spider Traps
又叫蜘蛛陷阱,就是某些网页故意设计成只有入链以及指向自己的出链,即自环,以此来提升网页的重要性。
从M矩阵的角度看,它不是列的和不为1,而是只有一个自身位置上的1。从数学上看,这种情况并不是一个问题,因为这种情况我们依然可以迭代出一个PageRank结果,但这个结果不是我们想要的,因为蜘蛛陷阱吸收了所有importance,只有这个网页的重要性是1,其他网页的重要性都是是0。这不是我们想看到的结果。

这样一来,进入蜘蛛陷阱后,也将会在几个时间步内传送出去。
2、调包实现PageRank
#1、导入西游记三元组文件
import pandas as pd
df = pd.read_csv(r'D:\pytorch-data\四大名著\西游记\triples.csv')
#2、将三元组转化为图数据
import networkx as nx
G = nx.from_pandas_edgelist(df, 'head', 'tail')
#3、可视化看看这个图
plt.rcParams['font.sans-serif'] = ['SimHei'] #显示正文
plt.rcParams['axes.unicode_minus'] = False #显示正负号
plt.figure(figsize=(20, 12))
pos = nx.spring_layout(G, seed=10)
nx.draw(G, pos, with_labels=True, node_size=20)
#4、调包networkx中的pagerank算法
pagerank = nx.pagerank(G, max_iter=500, alpha=0.8)
node_importance = sorted(pagerank.items(), key=lambda x:x[1], reverse=True)
node_importance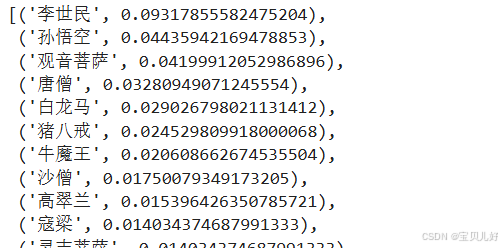
四、小结
1、基于随机游走的图信息嵌入算法都可以通过矩阵分解得到
2、基于随机游走的图信息嵌入算法的优缺点
(1)无法立刻泛化到新加入的节点。就是一个图中加入了一个新节点,那么就得重新游走,重新训练模型,之前的都不能用了。
(2)无法获取整体信息。因为随机游走还是类似NLP中的滑窗的效果,就是不管你的窗口有多大,你还只是一个窗口而已,你也是看不到全局信息的。除非你用匿名游走,或者直接上深度图神经网络来学习。
(3)只使用到图中的节点的连接信息,而没有利用图中的节点自身的属性信息、社群信息等。要充分利用这些信息,就只能上深度图神经网络了,所以下一章节我们就开启本系列的核心部分:深度图神经网络。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)