ICCV2023 | MIG | 通过动量积分梯度对视觉Transformer和卷积网络进行可转移对抗攻击
本文 “Transferable Adversarial Attack for Both Vision Transformers and Convolutional Networks via Momentum Integrated Gradients” 提出了动量积分梯度(MIG)攻击方法,利用积分梯度和动量迭代策略,有效攻击视觉 Transformer(ViTs)和卷积神经网络(CNNs),提升
Transferable Adversarial Attack for Both Vision Transformers and Convolutional Networks via Momentum Integrated Gradients
本文 “Transferable Adversarial Attack for Both Vision Transformers and Convolutional Networks via Momentum Integrated Gradients” 提出了动量积分梯度(MIG)攻击方法,利用积分梯度和动量迭代策略,有效攻击视觉 Transformer(ViTs)和卷积神经网络(CNNs),提升对抗样本的转移性,揭示了模型可解释性与对抗攻击鲁棒性的内在联系。
摘要-Abstract
Visual Transformers (ViTs) and Convolutional Neural Networks (CNNs) are the two primary backbone structures extensively used in various vision tasks. Generating transferable adversarial examples for ViTs is difficult due to ViTs’ superior robustness, while transferring adversarial examples across ViTs and CNNs is even harder, since their structures and mechanisms for processing images are fundamentally distinct. In this work, we propose a novel attack method named Momentum Integrated Gradients (MIG), which not only attacks ViTs with high success rate, but also exhibits impressive transferability across ViTs and CNNs. Specifically, we use integrated gradients rather than gradients to steer the generation of adversarial perturbations, inspired by the observation that integrated gradients of images demonstrate higher similarity across models in comparison to regular gradients. Then we acquire the accumulated gradients by combining the integrated gradients from previous iterations with the current ones in a momentum manner and use their sign to modify the perturbations iteratively. We conduct extensive experiments to demonstrate that adversarial examples obtained using MIG show stronger transferability, resulting in significant improvements over state-of-the-art methods for both CNN and ViT models.
视觉Transformer(ViTs)和卷积神经网络(CNNs)是广泛应用于各种视觉任务的两种主要骨干结构。由于ViTs具有卓越的鲁棒性,为其生成可迁移的对抗样本很困难,而在ViTs和CNNs之间迁移对抗样本则更具挑战性,因为它们处理图像的结构和机制存在根本差异。在这项工作中,我们提出了一种名为动量积分梯度(MIG)的新型攻击方法,它不仅能以高成功率攻击ViTs,还在ViTs和CNNs之间展现出出色的可迁移性。具体而言,受图像的积分梯度在不同模型间比常规梯度具有更高相似性这一观察结果的启发,我们使用积分梯度而非普通梯度来指导对抗扰动的生成。然后,我们以动量的方式将前几次迭代的积分梯度与当前的积分梯度相结合,得到累积梯度,并利用其符号迭代地修改扰动。 我们进行了大量实验,结果表明,使用MIG获得的对抗样本具有更强的可迁移性,与最先进的方法相比,在CNN和ViT模型上都实现了显著改进。
引言-Introduction
这部分内容主要介绍了研究背景、现有问题以及本文提出的方法和贡献,具体如下:
- 研究背景:视觉Transformer(ViTs)和卷积神经网络(CNNs)在视觉领域应用广泛。它们处理图像的机制不同,CNNs利用卷积滤波器捕捉局部特征,ViTs将图像视为图块序列并通过自注意力机制建模全局依赖关系。开发能攻击这两类模型的对抗样本很重要,有助于在实际应用前发现模型漏洞。
- 现有问题:在对抗攻击中,生成可迁移的对抗样本至关重要。然而,由于ViTs和CNNs的差异,之前针对CNNs设计的攻击方法对ViTs的迁移性有限。并且ViTs比CNNs更鲁棒,针对ViTs的对抗攻击研究较少,这给基于迁移的黑盒ViTs攻击带来阻碍。
- 本文方法:提出基于积分梯度和动量迭代策略的动量积分梯度(MIG)攻击方法。该方法使用积分梯度计算模型预测相对于输入的显著性分数,其符号用于指导扰动更新。同时采用动量迭代策略更新扰动,类似动量梯度下降算法,能加速扰动更新,跳出局部最优,提升对抗样本在不同模型间的迁移性。
- 主要贡献:一是提出MIG攻击方法,可高成功率攻击ViTs;二是MIG生成的对抗扰动在跨ViT和CNN模型时,迁移性优于当前最优方法;三是通过实验证明基于归因的迁移攻击对ViTs有效,揭示了模型可解释性与对抗攻击鲁棒性之间的内在联系。
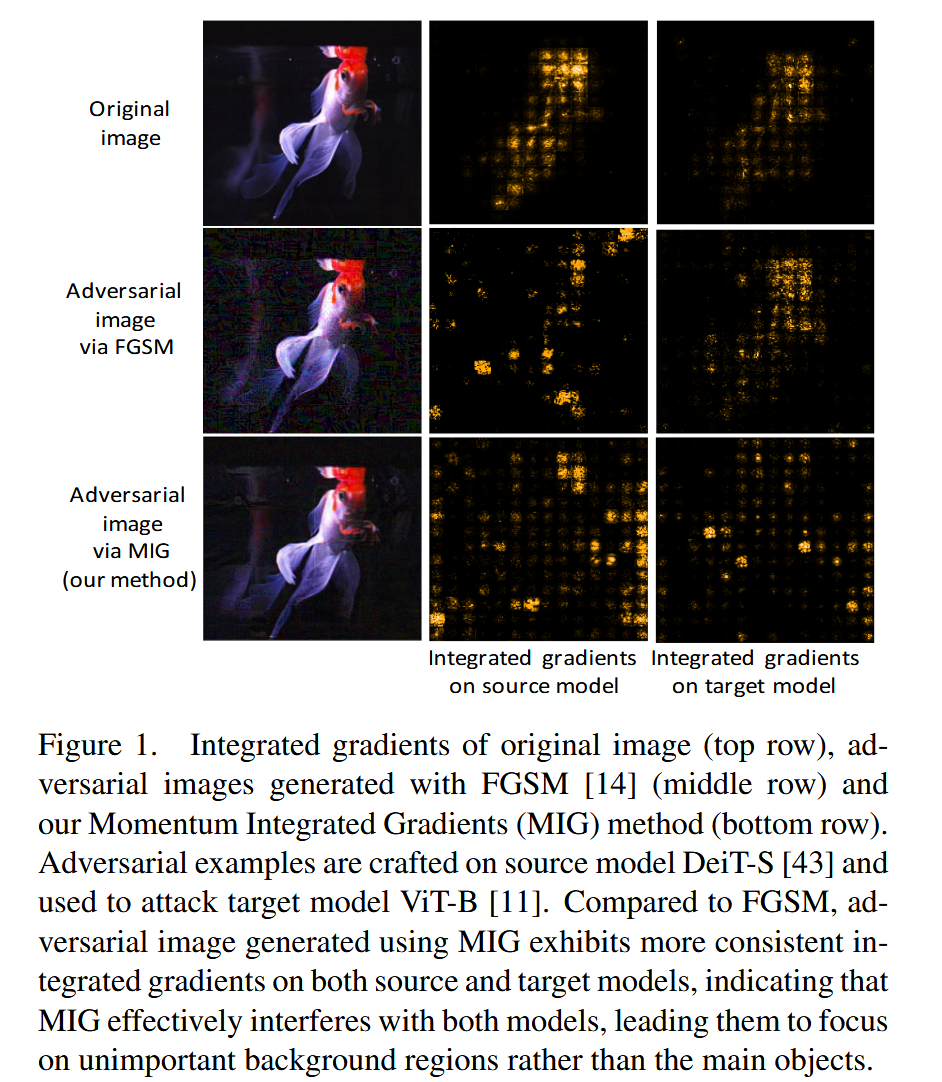
图1. 原始图像(第一行)、用快速梯度符号法(FGSM)生成的对抗图像(中间一行)以及用我们的动量积分梯度(MIG)方法生成的对抗图像(最后一行)的积分梯度。对抗样本在源模型DeiT-S上制作,并用于攻击目标模型ViT-B。与FGSM相比,使用MIG生成的对抗图像在源模型和目标模型上都表现出更一致的积分梯度,这表明MIG有效地干扰了这两个模型,使它们将注意力集中在不重要的背景区域而非主要物体上。
相关工作-Related Work
这部分内容主要回顾了与视觉Transformer(ViTs)的鲁棒性以及对抗攻击相关的研究工作,为后续提出的动量积分梯度(MIG)方法做铺垫,具体内容如下:
- Vision Transformer的鲁棒性:已有研究表明ViTs相比CNNs具有更强的对抗鲁棒性。如部分研究指出ViTs学习的特征含较少高频模式,对高频扰动不敏感,且自注意力机制有助于提升其鲁棒性。在基于迁移的攻击方面,现有攻击方法很难将对抗样本从CNNs有效迁移到ViTs,模型集成可在不牺牲干净准确率的情况下提升对黑盒攻击的鲁棒性 。
- 对抗攻击:根据攻击者对目标模型的信息获取程度,对抗攻击方法分为白盒攻击和黑盒攻击。白盒攻击中攻击者可完全访问目标模型,如FGSM和基于迭代梯度的方法;黑盒攻击更具挑战性,攻击者只能通过查询获取模型输出。黑盒攻击方法包括基于查询的攻击,以及利用对抗样本转移性的方法,如MI通过引入动量项和模型logits集成增强转移性,DIM通过对输入进行随机调整大小解决白盒模型过拟合问题,TIM使用一组图像计算梯度,SIM引入尺度不变性提升转移性等。但这些方法主要针对CNNs,对ViTs攻击效果不佳。近期有研究利用自集成和token细化来提高对ViTs的攻击转移性,而本文的MIG方法无需模型或输入集成,就能在CNNs和ViTs上都实现出色的转移性。
方法-Methodology
通过积分梯度捕获模型无关关键区域-Capture Model-agnostic Critical Regions via Integrated Gradients
该部分主要介绍了通过积分梯度(Integrated Gradients,IG)捕捉模型无关关键区域的原理和优势,为利用IG生成对抗样本提供理论依据,具体内容如下:
- 积分梯度的计算过程:积分梯度是一种用于解释神经网络预测的方法,它将神经网络的预测归因于其输入。假设 f : R n → [ 0 , 1 ] f: \mathbb{R}^{n} \to [0,1] f:Rn→[0,1] 表示一个深度网络,用于将输入图像分类到某一类别, b b b 为不包含有效信息的基线图像(通常为黑色图像)。从基线图像 b b b 到输入图像 x x x 的直线路径上计算各点的梯度,并对这些梯度进行累积,得到输入 x x x 和基线 b b b 沿第 i i i 维的积分梯度: I G i ( f , x , b ) = ( x i − b i ) × ∫ ξ = 0 1 ∂ f ( b + ξ × ( x − b ) ) ∂ x i d ξ I G_{i}(f, x, b)=\left(x_{i}-b_{i}\right) × \int_{\xi=0}^{1} \frac{\partial f(b+\xi \times(x-b))}{\partial x_{i}} d \xi IGi(f,x,b)=(xi−bi)×∫ξ=01∂xi∂f(b+ξ×(x−b))dξ ,用 I G ( f , x , b ) I G(f, x, b) IG(f,x,b) 表示所有维度的积分梯度。在实际计算中,通过沿着从基线图像到输入图像的直线路径上足够接近的点的梯度求和,来高效近似积分梯度: I G i ( f , x , b ) ≈ ( x i − b i ) × ∑ k = 1 s ∂ f ( b + k s × ( x − b ) ) ∂ x i × 1 s I G_{i}(f, x, b) \approx\left(x_{i}-b_{i}\right) × \sum_{k=1}^{s} \frac{\partial f\left(b+\frac{k}{s} \times(x-b)\right)}{\partial x_{i}} × \frac{1}{s} IGi(f,x,b)≈(xi−bi)×∑k=1s∂xi∂f(b+sk×(x−b))×s1 ,其中 s s s 为近似阶数(泰勒展开的阶数), s s s 越大近似越精确,但计算成本也越高,本文设置 s = 20 s = 20 s=20 以平衡精度和效率。
- 积分梯度提升对抗扰动转移性的原因:与直接梯度和原始注意力相比,积分梯度满足实现不变性这一良好属性。直观地说,如果两个网络对所有输入产生相同的输出,即使它们的实现方式不同,在功能上也是等效的。实现不变性意味着积分梯度在这样的网络之间是一致的,因为它们只取决于模型的输入和输出,不受实现细节的影响。当使用IG生成对抗扰动时,功能等效的两个模型应具有相同的输出,那么在源模型上有效的对抗扰动转移到目标模型时也应有效。虽然在实践中很难获得完全等效的模型,但该属性有助于定性解释IG带来的对抗转移性增强,并且在后面的消融实验进一步证实了其效用。
- 积分梯度用于生成对抗样本的启发:图2展示了不同模型对同一干净图像的积分梯度示例,不同模型的积分梯度虽有所不同,但都突出了显著区域,淡化了琐碎的背景区域。这一观察结果启发作者利用IG作为生成对抗样本的指导信号,因为它能标识出对模型预测至关重要的区域,通过对这些区域进行扰动,有望生成有效的对抗样本。

图2. 从左至右依次为一张原始图像以及来自ResNet-50、Inception-v4、DeiT-T和ViT-T的相应积分梯度。不同模型对同一图像的积分梯度分布相似。与卷积神经网络模型相比,视觉Transformer(ViTs)将图像作为图块序列进行处理,因此其积分梯度的分布也呈图块状。为了更清晰地展示,我们对原始图像添加五次随机高斯噪声,对得到的积分梯度进行平滑处理并取平均值。
利用动量加速扰动更新-Speed Up Perturbation Update via Momentum
该部分主要介绍了利用动量迭代策略加速扰动更新的原因和具体方法,通过引入动量策略改进基于积分梯度的攻击,以更高效地生成稳定且转移性更好的对抗样本,具体内容如下:
- 引入动量策略的原因:视觉模型通常参数众多,计算积分梯度的过程较为复杂。传统基于梯度的攻击方法(如FGSM等)仅利用当前梯度生成对抗样本,未考虑过去的步骤,容易陷入局部最优。而动量迭代策略类似于动量梯度下降算法,能通过积累历史梯度的信息,加速梯度下降过程,防止算法因模型特定噪声被困在次优区域,从而加快扰动更新速度,提高对抗样本在不同模型间的转移性,更高效地生成稳定的对抗样本。
- 动量迭代策略的具体计算方式:在基于积分梯度的攻击中应用动量策略,第 t t t 次迭代时累积的积分梯度 g t g_{t} gt 计算公式为: g t = μ ∗ g t − 1 + Δ t ∥ Δ t ∥ 1 g_{t}=\mu * g_{t - 1}+\frac{\Delta_{t}}{\left\| \Delta_{t}\right\| _{1}} gt=μ∗gt−1+∥Δt∥1Δt。其中, g t − 1 g_{t - 1} gt−1 是上一次迭代累积的积分梯度, Δ t \Delta_{t} Δt 是当前迭代的积分梯度,在相加前对其进行 L 1 L_{1} L1 范数归一化处理。动量因子(衰减因子) μ \mu μ 用于调节历史梯度的衰减速率,较小的 μ \mu μ 会使较旧的累积梯度更快衰减。通过这种方式,该策略能积累过往梯度的能量,在进入平坦区域时保持更新速度,避免算法停滞在较差的局部最优解,从而获得更稳定和最优的扰动,提升对抗样本在不同模型间的转移性。
动量积分梯度方法-Momentum Integrated Gradients Method
该部分详细介绍了动量积分梯度(MIG)方法的具体实现过程,包括其原理、生成对抗样本的迭代步骤以及与模型集成的相关内容,具体如下:
- MIG方法原理:MIG方法结合了积分梯度和动量迭代策略。通过积分梯度,在模型无关的归因空间中扰动对模型预测最关键的区域;利用动量迭代策略,积累先前梯度的能量,在进入平坦区域时保持速度,避免陷入局部最优解,从而得到稳定且最优的扰动。
- 生成对抗样本的迭代过程
- 初始化:给定干净输入图像 x x x 及其对应的真实标签 y y y,设置初始累积积分梯度 g 0 = 0 g_0 = 0 g0=0,初始图像 x 0 = x x_0 = x x0=x,步长 α = ϵ T \alpha = \frac{\epsilon}{T} α=Tϵ,其中 ϵ \epsilon ϵ 是对抗攻击的扰动预算, T T T 是迭代次数。
- 迭代计算:在第 t t t 次迭代中,首先计算模型输出关于当前输入 x t − 1 x_{t - 1} xt−1 的积分梯度 Δ t = I G ( f , x t − 1 , b ) \Delta_t = IG(f, x_{t - 1}, b) Δt=IG(f,xt−1,b)。接着,按照动量迭代方式更新累积梯度 g t = μ ∗ g t − 1 + Δ t ∥ Δ t ∥ 1 g_{t}=\mu * g_{t - 1}+\frac{\Delta_{t}}{\left\| \Delta_{t}\right\| _{1}} gt=μ∗gt−1+∥Δt∥1Δt。然后,使对抗图像 x t x_{t} xt 沿着 g t g_{t} gt 的符号方向移动,步长为 α \alpha α,即 x t = C l i p ϵ { x t − 1 + α ⋅ s i g n ( g t ) } x_{t}=Clip_{\epsilon}\{x_{t - 1}+\alpha \cdot sign(g_{t})\} xt=Clipϵ{xt−1+α⋅sign(gt)},其中 C l i p ϵ Clip_{\epsilon} Clipϵ 函数用于确保对抗图像的扰动在预算 ϵ \epsilon ϵ 范围内。
- 生成对抗样本:经过 T T T 次迭代后,得到最终的对抗图像 x a d v = x T x_{adv} = x_T xadv=xT 并返回。虽然文中给出的是无目标攻击的过程,但该方法很容易修改为有目标攻击版本。

MIG与模型集成-MIG with Model Ensemble
这部分主要探讨了MIG与模型集成的相关内容,研究了不同的集成策略及其对攻击转移性的影响,具体如下:
- 集成的必要性:MIG能在白盒模型上生成可转移的扰动,即便单模型已有良好的转移攻击能力,但由于CNNs和ViTs处理图像的方式不同,仅基于单个源模型生成的扰动可能受其特定架构限制。因此,通过模型集成有望克服这一局限,进一步提升对抗样本的转移性。
- 集成策略
- 扰动集成:分别使用两个源模型生成扰动,然后将它们结合起来,得到最终的扰动。
- logit集成:直接融合两个模型的logits,类似于之前研究中的做法。
- IG集成:计算两个模型的积分梯度并融合,形成新的IG用于更新扰动。
- 通用公式:这三种集成策略都可以用公式 z ( x ) = ∑ m = 1 M w m z m ( x ) z(x)=\sum_{m = 1}^{M} w_{m} z_{m}(x) z(x)=∑m=1Mwmzm(x) 来概括,其中 z m ( x ) z_{m}(x) zm(x) 代表第 m m m 个模型的扰动、logit或IG, w m w_{m} wm 是权重,需满足 w m ≥ 0 w_{m}≥0 wm≥0 且 ∑ m = 1 M w m = 1 \sum_{m = 1}^{M} w_{m}=1 ∑m=1Mwm=1,本研究设置 M = 2 M = 2 M=2,因为两个模型的集成已足够有效。
实验-Experiments
这部分主要通过一系列实验验证了MIG方法的有效性,具体内容如下:
-
数据集与评估指标:主要在ImageNet数据集上评估MIG性能。从ImageNet val分割集中随机抽取5000张图像,这些图像在用于生成对抗样本的白盒源模型上分类准确率为100%。通过计算攻击成功率(即成功欺骗目标黑盒模型的图像数量占总图像数量的比例)和平均攻击成功率(MASR,衡量攻击方法在多个目标模型上的整体性能)来评估对抗样本的转移性。
-
实验设置:分别以CNNs和ViTs作为源模型和目标模型,研究MIG对抗样本的转移性。源模型包括DeiT家族的三个视觉Transformer(DeiT-T、DeiT-S、DeiT-B)和三个CNNs(VGG-19 bn、MNAS、Inception-v4);目标模型包含三个CNNs(DenseNet-201、ResNet50-BiT-M、ConvNeXt)和五个ViT模型(ViT-S、ViT-B、ViT-L、Transformer iN Transformer、Swin-Transformer)。将MIG与FGSM、PGD等常用及先进攻击方法进行对比,设置扰动预算(\epsilon = 16/255),默认迭代次数(T = 25),动量因子(\mu = 1),使用Timm库中的预训练模型,在四个RTX 3090 GPU上进行实验。
-
实验结果
-
以ViTs为源模型:MIG显著提升了平均攻击成功率,比传统非集成方法(如FGSM、PGD)高出20%以上,也超越了基于集成的先进方法(如MI、PGD-RE、MI-RE)。且在向CNNs和ViTs模型转移时均有稳定提升,而以往攻击方法在两类模型上表现差异较大。
表1. 以DeiT系列模型为源模型时,MIG和其他攻击方法的攻击成功率(%)和平均攻击成功率(MASR,%)。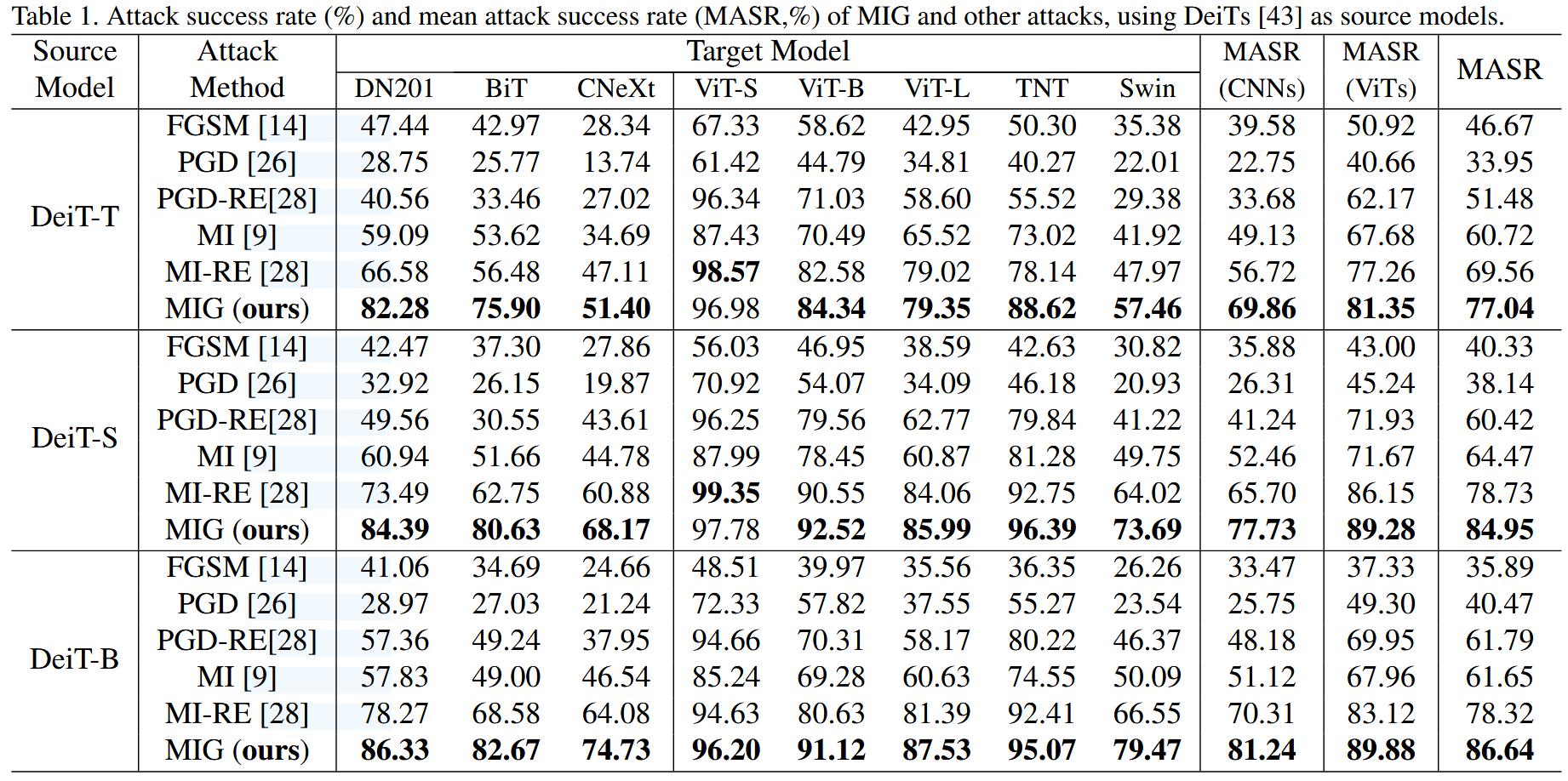
-
以CNNs为源模型:MIG同样性能提升显著。如以Inception-v4为源模型时,在CNNs上的MASR从FGSM的34.56%提升到87.05%,在ViTs上相比FGSM提升43.27%,大幅超越其他对比方法,表明其能有效攻击ViT模型,证明ViT模型并非对攻击完全免疫。
表2. 以卷积神经网络(CNNs)为源模型时,MIG和其他攻击方法的攻击成功率(%)和平均攻击成功率(MASR,%)。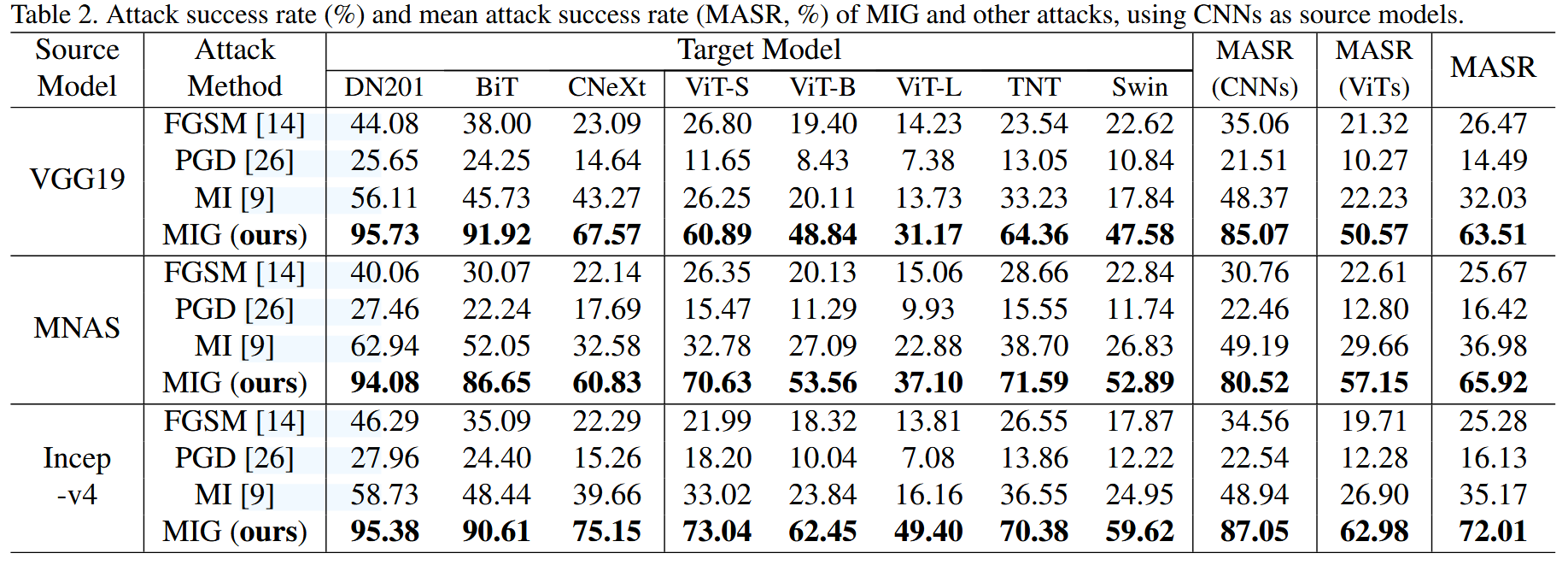
-
MIG与模型集成:研究不同模型集成策略对MIG的影响,发现logit集成和IG集成可显著提升对抗转移性,比用于集成的两个源模型的性能提升3.87%-25.63%,直接集成扰动效果较差;单类模型集成(尤其是两个CNN模型集成)对攻击ViT目标模型的性能提升有限,但仍比单个CNN模型设置的MASR提高约10%;一个ViT和一个CNN作为源模型时性能最佳。将MIG融入输入变换攻击方法(如DIM、TIM、SIM)后,攻击成功率提高了5%-23%,进一步验证了MIG的有效性。
表3. MIG在有无模型集成情况下的攻击成功率(%)和平均攻击成功率(MASR,%)。“Perturbation”(扰动)、“logit”(对数几率)和“IG”分别表示使用扰动集成、对数几率集成和积分梯度集成。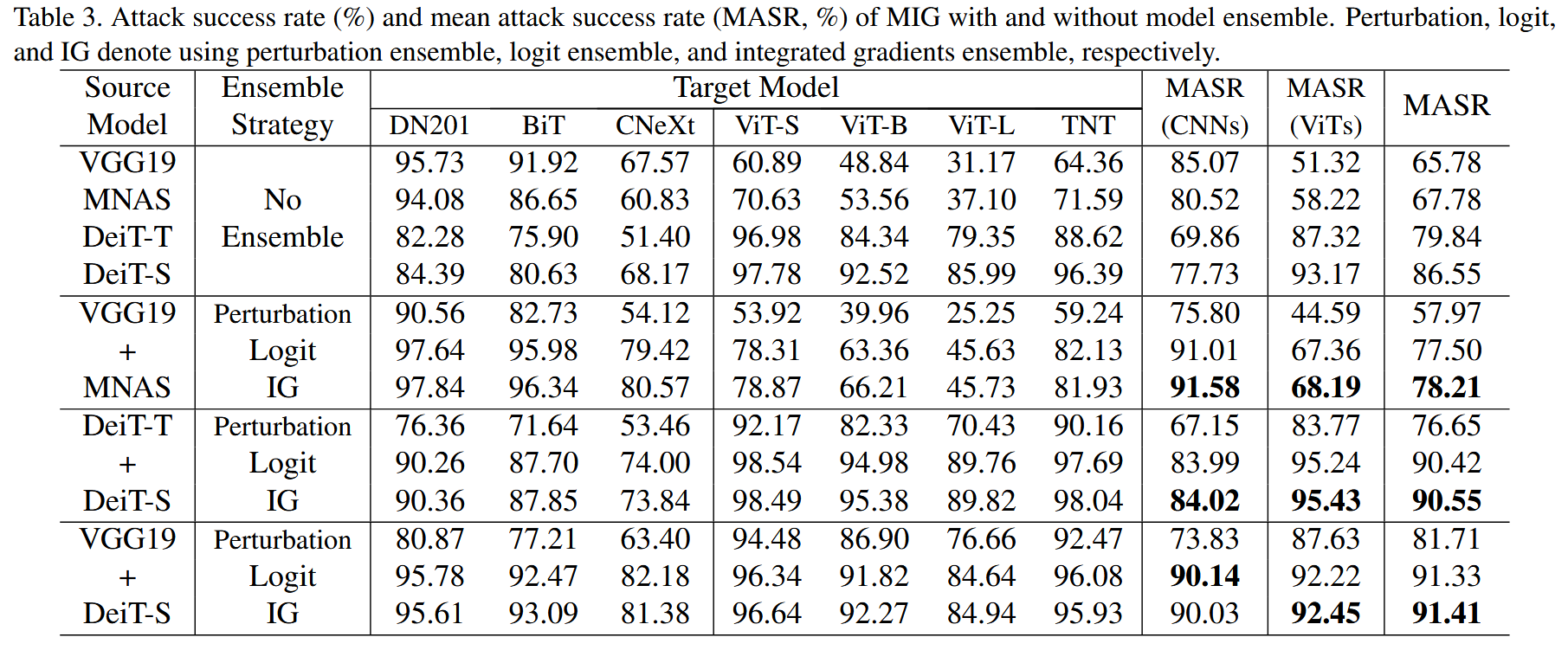
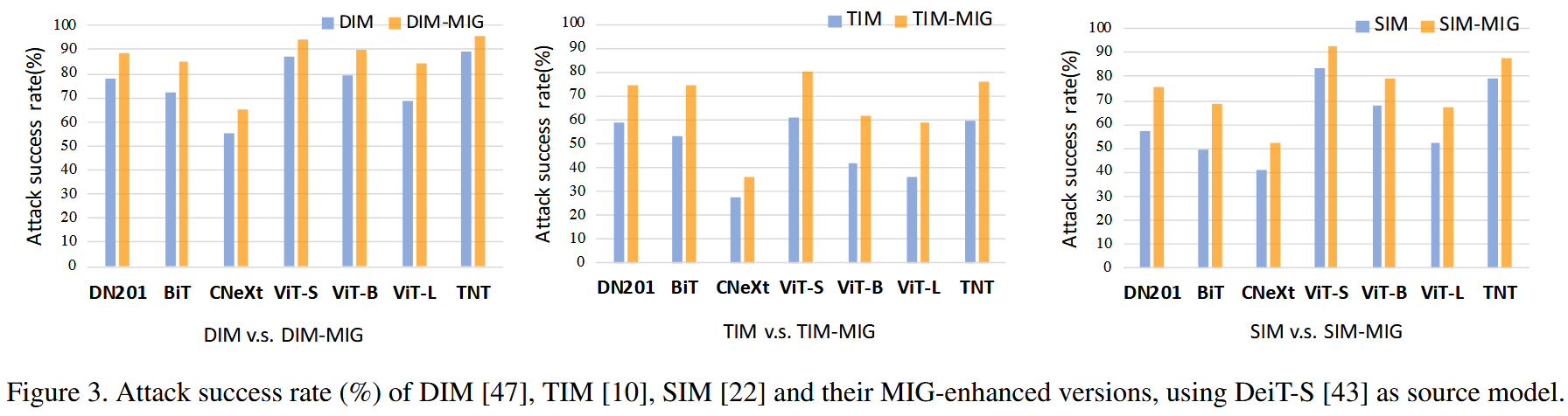
图3. 以DeiT-S 为源模型时,DIM 、TIM 、SIM 及其MIG增强版本的攻击成功率(%)。
-
-
消融实验:研究MIG中各关键组件(使用IG替换直接梯度、迭代更新对抗扰动、动量方式累积历史梯度)的贡献。以ViT-L为目标模型,DeiT-S、DeiT-B、MNAS、Inception-v4为源模型进行实验,结果表明使用IG和迭代策略可带来12%-30%的性能提升,动量更新策略进一步提升8.62%-24.14%,单独使用IG进行单步扰动生成效果不佳。
表4. 消融研究。将积分梯度(IG)、迭代更新和动量迭代更新视为MIG的关键组件,我们以ViT-L 为目标模型,分别研究这些组件的有效性。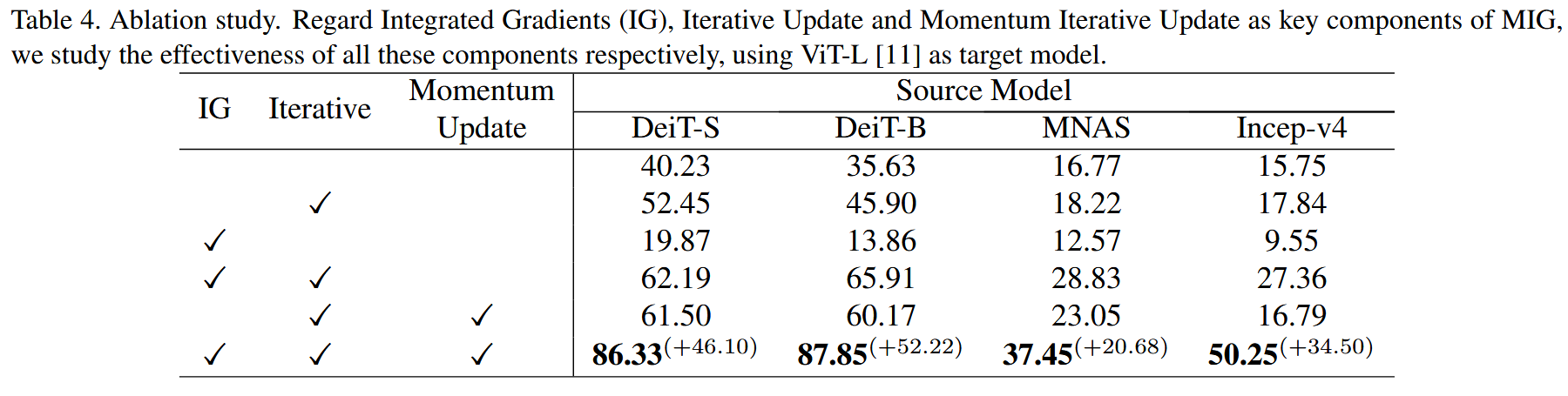
-
超参数选择:探究不同超参数(衰减因子 μ \mu μ、迭代次数 T T T、扰动预算 ϵ \epsilon ϵ)对MIG性能的影响。发现随着迭代次数和扰动预算增加,MIG性能提升,在 T = 25 T = 25 T=25、 ϵ = 16 / 255 \epsilon = 16/255 ϵ=16/255 时趋于稳定;动量衰减因子 μ = 1 \mu = 1 μ=1 时性能最优,且不同规模的目标模型(ViT-S到ViT-L)在相同超参数设置下能达到最佳性能。
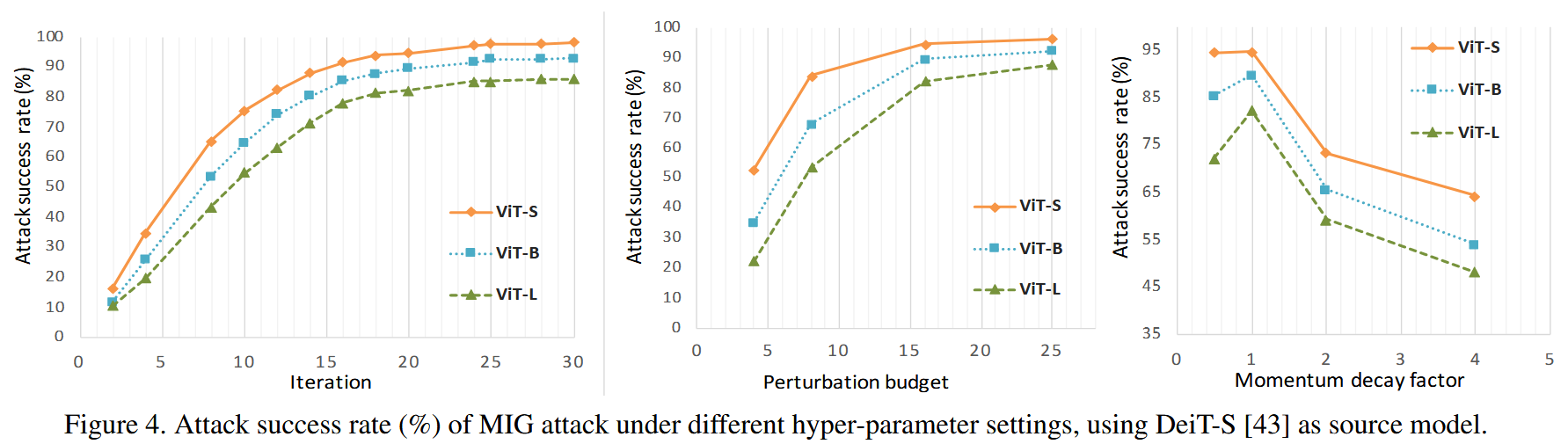
图4. 以DeiT-S为源模型时,MIG攻击在不同超参数设置下的攻击成功率(%)。
结论-Conclusion
这部分内容总结了研究成果,强调了研究的重要意义和价值,具体如下:
- 研究成果总结:视觉Transformer(ViTs)在图像分类任务中比传统卷积神经网络(CNNs)展现出更强的韧性。本文提出的动量积分梯度(MIG)攻击方法,利用积分梯度(IG)指示ViTs中识别全局依赖和语义相关区域的优势,对这些区域进行扰动,并结合动量迭代方法提升攻击质量。该方法在针对ViTs的攻击、跨ViT-CNN模型的攻击转移以及模型集成攻击场景下,均取得了当前最优的转移攻击成功率。
- 研究意义阐述:MIG方法不仅在攻击性能上表现卓越,还为研究ViTs的潜在漏洞提供了直观思路。这表明,即使ViTs具有较高的鲁棒性,但通过有效识别和扰动对其预测关键的区域,仍能实现稳定且有效的攻击。此研究揭示了ViTs在面对对抗攻击时并非坚不可摧,为后续进一步研究模型的对抗鲁棒性提供了新的方向和参考,有助于推动相关领域在提升模型安全性和可靠性方面的发展。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)