FLUX.1 中国山水画 LoRA 的训练心得
这几天又尝试了一些风格类 LoRA 的训练,今天就来分享下制作中国山水画 LoRA 的心得,借鉴的画家是南宋四大家之一的刘松年。刘松年善画山水、人物,其艺术水平被誉为“院人中绝品”,与李唐、马远、夏圭并称“南宋四家”。
这几天又尝试了一些风格类 LoRA 的训练,今天就来分享下制作中国山水画 LoRA 的心得,借鉴的画家是南宋四大家之一的刘松年。刘松年善画山水、人物,其艺术水平被誉为“院人中绝品”,与李唐、马远、夏圭并称“南宋四家”。
图像数据集
之前的文章中的图像都是 512 像素的,本次则采用了不同像素图像的组合,如下图所示(图片来源于互联网),20 张图片含有多种长宽比的组合,像素都接近于 512 。因为 FLUX.1 比较擅长不同长宽的图像,所以这样的图像组合可以给模型更多的灵活性,方便我们后期生成各种长宽的图像。

对于图像的标注,本次我也依然采用了三种不同的组合来看看它们对风格类 LoRA 的影响。
- 无标注 - 即图片不使用任何的标注,仅在训练时添加触发词(trigger)
- 简单标注 - 触发词加简短的说明
- 复杂标注 - 触发词加详细的图片描述
简单标注
使用一个触发词加图片的基本描述,比如 liusongnian, painting, traditional chinese painting .,其中 liusongnian 为触发词。
这份完整版的Lora模型资料包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

复杂标注
本次还是使用 ComfyUI 里面的 Joy Caption节点来进行复杂标注的操作,它利用的是 Meta 的 Llama 模型来对图片进行描述,更加符合自然语言的表达。这个节点来自于 Comfyui_CXH_joy_caption 这款插件,链接里面有详细的中文安装指南和工作流文件。生成之后我对文字进行了简单的调整,以第一张图片为例,以下为标注内容。
liusongnian, a traditional Chinese painting depicting a serene landscape featuring a variety of
natural elements. In the foreground, a small bridge arches over a gently flowing stream, with rocks
and vegetation on either side. To the left, a group of people, including a man in a red robe and
a woman in a blue robe, are engaged in conversation near a tree. The man holds a staff,
while the woman gestures with her hands. The background showcases a mountainous terrain with dense
forests and tall, leafy trees. The sky is a light, hazy blue, and the mountains are rendered in
soft, textured shades of gray and brown. The people are dressed in traditional Chinese attire,
with the man wearing a robe and the woman in a simple, flowing garment.
The overall texture of the image is smooth and delicate, with fine, detailed brushstrokes that
create a sense of depth and realism. The illustration is likely from a historical period,
possibly the Ming dynasty, and showcases the traditional Chinese artistic style.
训练工具
本次仍旧使用了 FLUXTrainer 这个插件进行 LoRA 的训练,在 ComfyUI Manager 里面搜索名字安装后重启即可,工作流可以在这里下载 ComfyUI-FluxTrainer/examples,插件作者也经常会更新这个工作流的。具体的一些设置和操作可以参考本文开头提到的文章。
训练设置
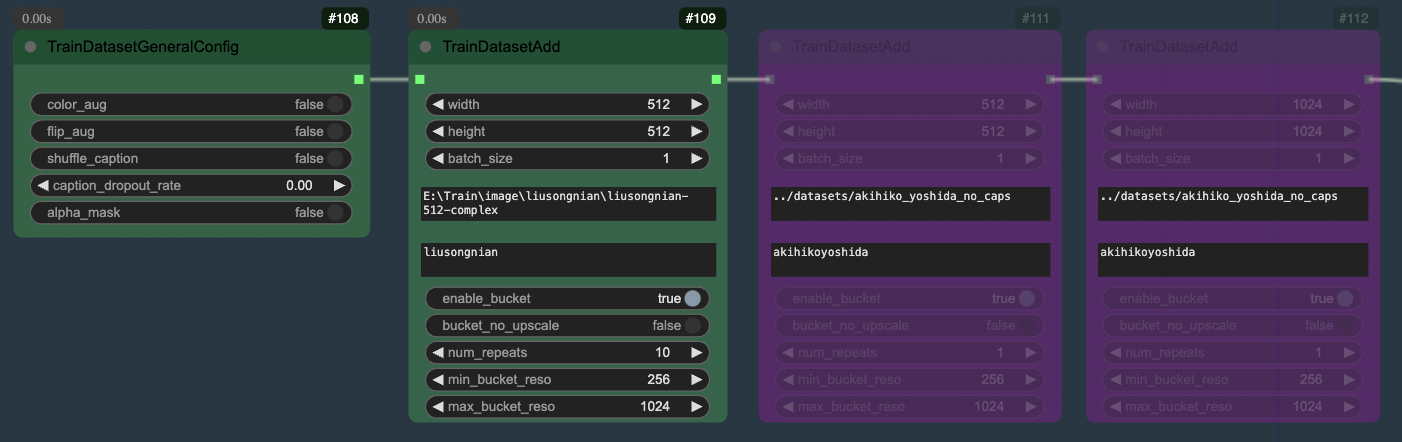
这次也依旧将图片都放置在同一个文件夹下,这里说明一下重复次数(num_repeats)和批次大小(batch_size),训练的步数公式如下,如果使用多个文件夹来同时训练不同分辨率的图像,计算公式会更加复杂。在这个工作流中 epoch(图片被完整训练一遍)是没有地方设置的,而是系统通过预先设置的总训练步数来推导出 epoch,对于习惯使用 epoch 来训练的,可能需要适应一下。
总的训练步数(max_train_steps) = 重复次数 * epoch * 图片的数量 / 批次大小
重复次数通常用于调整正则化图像和训练用图像的数量,或者调整不同分辨率图像的数量,使得它们的总数量能够更加平衡。在这次训练里,由于我只有一个文件夹的图像,理论上说只要将重复次数设置为 1 即可,但是从我个人的一些训练结果来看,有时添加重复次数感觉训练结果好那么一点,所以我也仍旧将重复次数设置为 10。
批次大小是指同时训练多少个数据。这取决于显存的大小和训练的分辨率。批次计算可以提高速度,但是过高的话也可能爆显存,我试了几个不同的批次,在我 16GB 显卡上面提升的速度很有限,所以我一般选择批次大小为 1 。
在设置里面我采用的是 Adafactor的优化器,使用这个优化器的时候,如果您不想自动调整学习率,你可以将 relative_step 设置为 false,并且将 max_grad_norm 设为 0,然后 lr_scheduler 采用 constant_with_warmup。network_dim 和 network_alpha 采用的是 16,网上有评论说采用 64 效果会更好,我暂时还没有测试,下一步可以试试看下效果,但是采用 64 的话,LoRA 的体积会增加。学习率为 0.0002,训练步数 2000,我也试过 0.0004 的学习率,但是发现 0.0002 的效果会更好,一般来说,更低的学习率需要更多的训练步数。
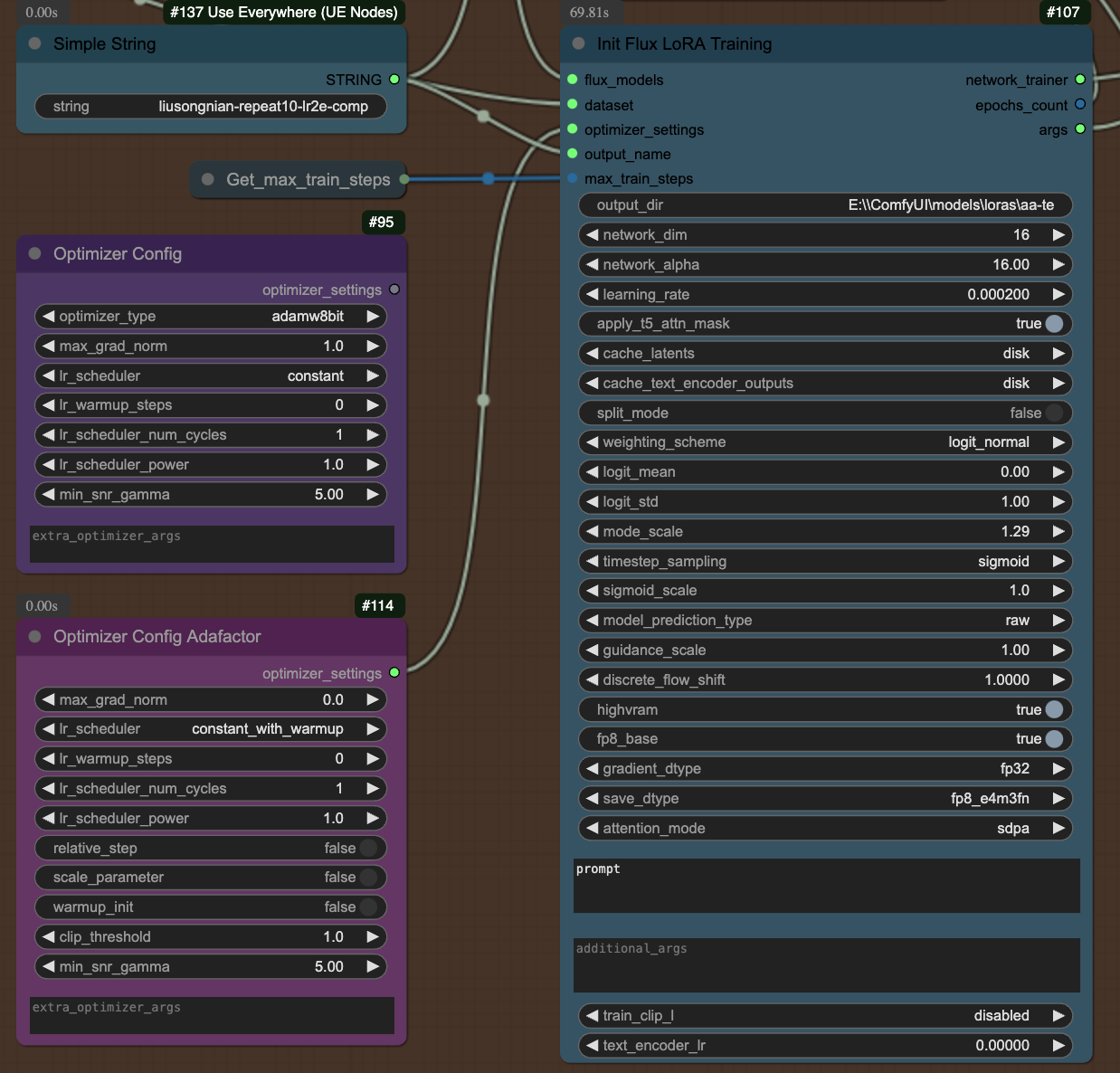
设置完毕之后就可以训练 LoRA 了,本次训练我总共跑了 9 遍,分别针对对不同的标注方式、学习率和批次大小。
模型测试
我们先来看一下在没有标注的情况下(学习率为 0.0002),分别在 500、1000、1500 和 2000 步下的效果,使用的提示词比较简单,前面两个含有一些国画常用的元素比如山水、石桥,第三个提示词中的生日(birthday)影响比较大,会伴随出现国画中所没有的蛋糕,第四个则完全是现代才有的赛车。
liusongnian, a painting depicting mountains and waters.
liusongnian, a painting depicting two figures standing on a fairy bridge.
liusongnian, a painting depicting a group of people celebrating birthday.
liusongnian, a painting depicting a racing car driving on the street.
如下图所示,可以看到在 500 步的时候,前面两个提示词中的山水、石桥元素能使画面更贴近国画的风格,但是离刘松年的风格还有些距离,赛车的画风则完全更贴近现代,第三个生日的图片则居于中间,既有传统风格也有一些现代的元素。然后随着步数的增加,基本上在 2000 步的时候能体现刘松年的风格了。
需要说明的是,图片中出现的印章和文字,如果放大看的话,应该是有变形甚至模糊的,这个主要是因为训练的图片里面含有大量的印章,如果只是体现画风的话,倒是可以在后续的训练中将这些印章去除再重新训练。

我们再来看一下同样在 2000 步数下(学习率为 0.0002),分别采用无标注、简单标注、复杂标注以及没有使用 LoRA 的效果。可以看到三个 LoRA 在对前面两个提示词的处理上都比较好。在第三个提示词上,红色的气球对简单标注 LoRA 的影响比较大,使得画面中出现了红色的圆圈,其他两个则相对能够处理好一些。在第四个提示词上,无标注 LoRA 的表现是最好的,既保留了赛车的轮廓又有了传统的元素,而其他两个则仍旧还是现代风格居多的。
总结下来,如果你想保持 LoRA 的灵活性,可以采用无标注的形式,这样子一些不在训练数据集里面的元素也能体现出 LoRA 的风格。但是如果你想专注于体现一些图像训练集里面的细节,有时候使用复杂标注则更好一些,当然你输入的提示词要符合这些细节。

前面提到训练图片是各种不同的长宽,下面也来看看这些效果,使用的是无标注 LoRA。
下图是 1024 * 1024 像素的。

再来看一下一个横屏下(1216 * 832)的效果。

效果总的都还可以,其中对第四个提示词,由于赛车这个元素不在训练图像里面,有时仍旧不能体现 LoRA 的风格。所以如果想尽可能体现这个 LoRA 的效果,需要挑选一些适合国风的提示词。当然如果你想体现反差,让传统和现代进行融合,采用一些现代才有的提示词也挺有意思的。
改善的空间
这个 LoRA 还有一些改善的空间,个人认为可以从下面这些方面进行完善。
- 训练集采用的是只有 20 张参考图,并且像素相对来说不是太高,使得训练的 LoRA 在一些细节上可能存在模糊。如果有可能的话,在得到高清图像的基础上可以进行更近一步的训练。
- 图像中出现的红色印章可能会影响画面,可以考虑在训练图像中进行去除。或者训练一个专门针对印章的 LoRA。文字的效果也是同理。
- 可以尝试采用更低的学习率以及更多的训练步数,进一步精细微调 LoRA。
我已经将三个(无标注、简单标注、复杂标注)的 LoRA 上传到网盘了,大家有兴趣体验的话,可以关注我的同名公众号(秋天的小伊)发送 liusongnian 来得到下载链接。体验下来,如果觉得有一些问题的,也欢迎在评论区留言哈。
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的AIGC全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

好了,本次分享就到这了。如果觉得本文对你有所帮助的话,麻烦点个赞哦。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献248条内容
已为社区贡献248条内容

所有评论(0)