DataWhale_Dify_task3进阶实践
摘要:本文介绍了Dify平台的进阶应用,包括工作流和Chatflow的使用方法。以小红书读书卡片生成器为例,详细说明了创建流程:从添加LLM节点、设计提示词到使用Artifacts插件实现可视化。同时展示了面试宝典Agent的创建过程,涉及知识库导入和检索测试。最后探讨了DeepSearch的设计理念与应用场景,并演示了如何在Dify中实现深度查询功能,包括轮数设置和查询主题输入,特别说明了国内L
Dify进阶实践
上一节完成dify的简易实践,主要包括制作简单有趣的聊天助手、创建运用私有知识库、处理数据的文本生成应用,还能结合ide环境制作词云。
那今天这一节,主要涉及工作流、chatflow的使用。简单来说,工作流就是以任务为驱动进行分工合作、部门协作。在面对较复杂需求更精准的任务时,一份精心制作的工作流就是最大的助力。
-
Chatflow实践---小红书读书卡片生成器
第一步:创建chatflow
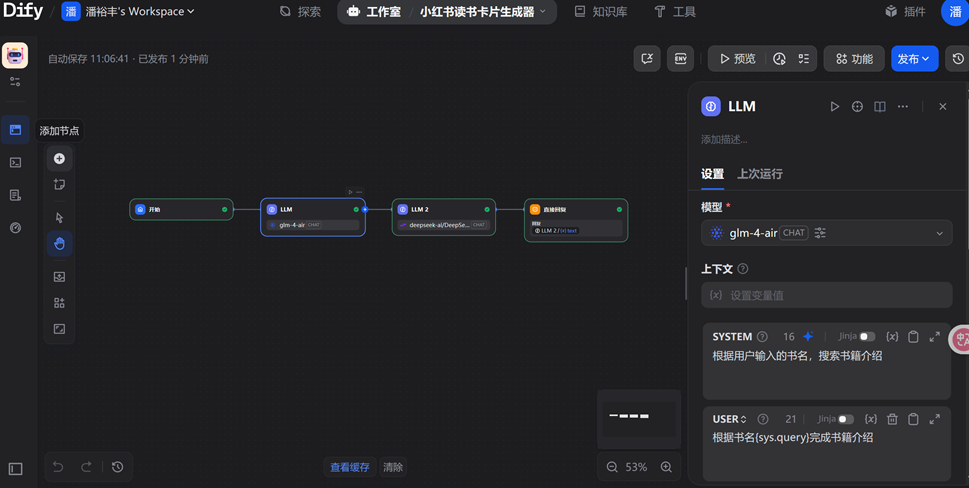
第二步:明确要求,添加两个LLM节点(大模型API自行获取),可选择硅基流动API。需读取用户输入请求(LLM1处理),再通过网页可视化(LLM2处理)直观展示读书卡片效果。
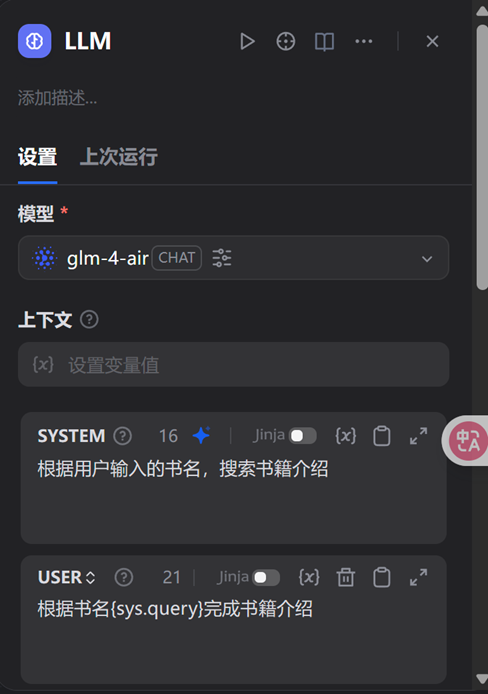
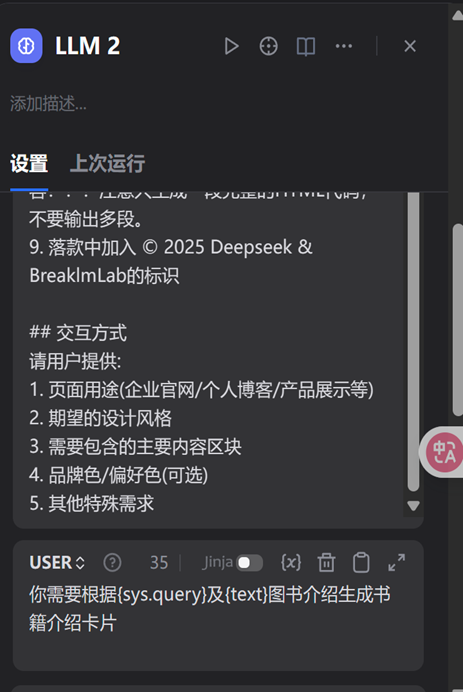
第三步:添加提示词prompt,主要围绕角色定位、核心能力、知识储备、输出要求(个性化设计)、交互方式五个方面进行设计。
第四步:预览没问题后,开始制作生成卡片。安装Artifacts插件,可以渲染LLM生成的HTML代码,实现可视化。
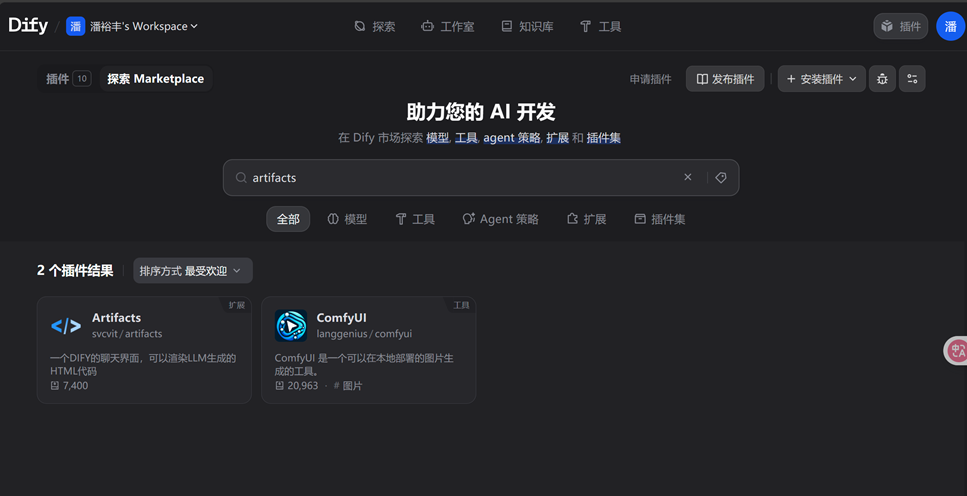
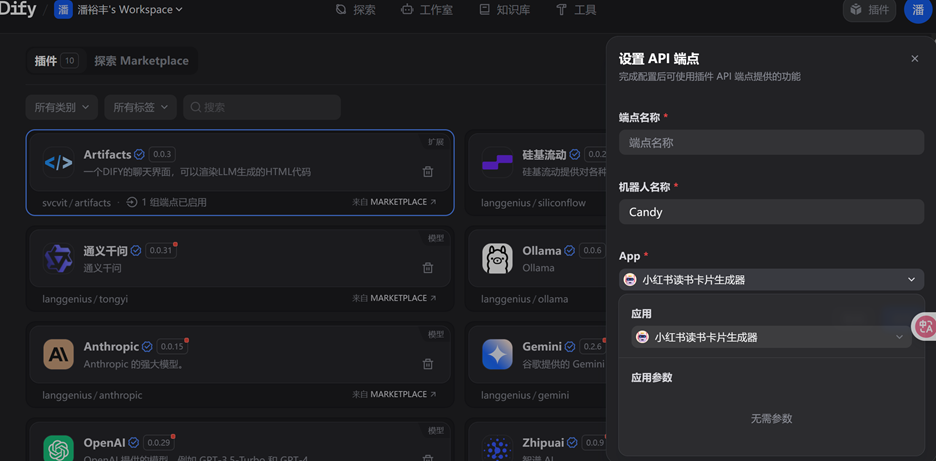
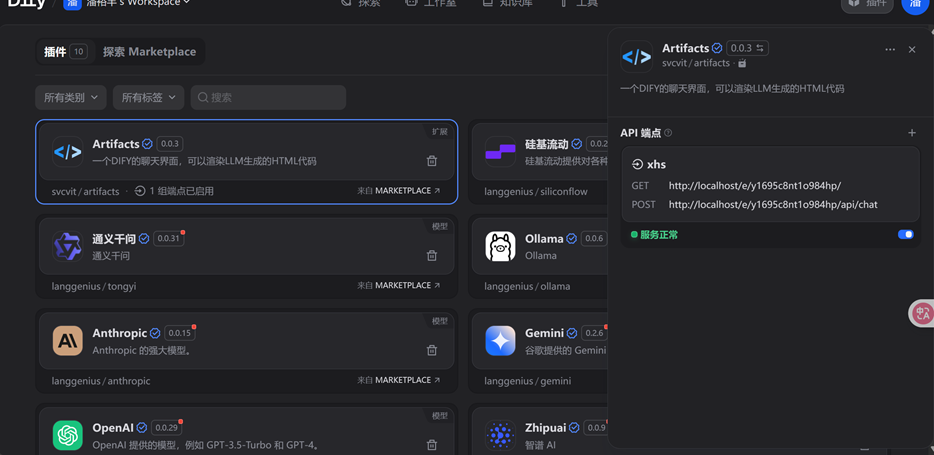
将插件添加到工作流应用中,get一个网站打开即可进行卡片生成。
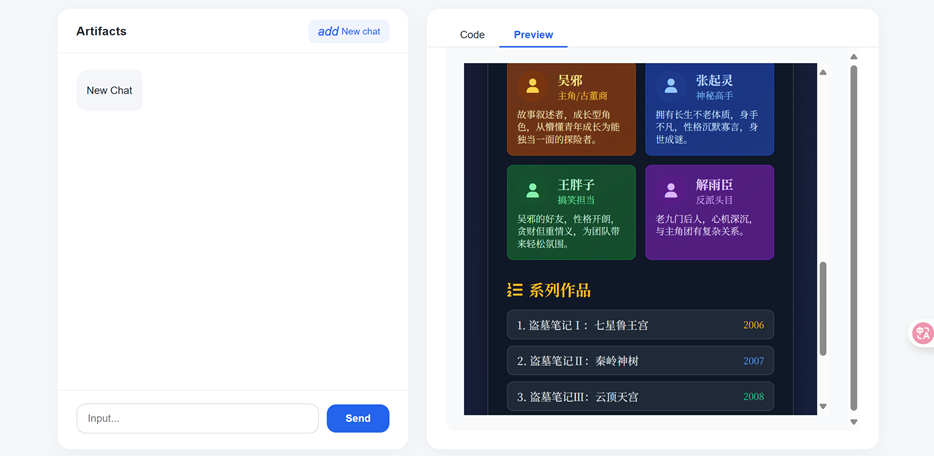
生成效果展示,如果有其他需求也可以在此页面继续输入要求,进行完善。
-
Dify综合应用---面试宝典
在日常学习过程中,有时候面对繁多杂乱的知识点会感觉很为难,不知道如何下手。那此时制作一个知识点宝典agent就很有用了。
第一步:创建知识库,导入已有的文件资源。
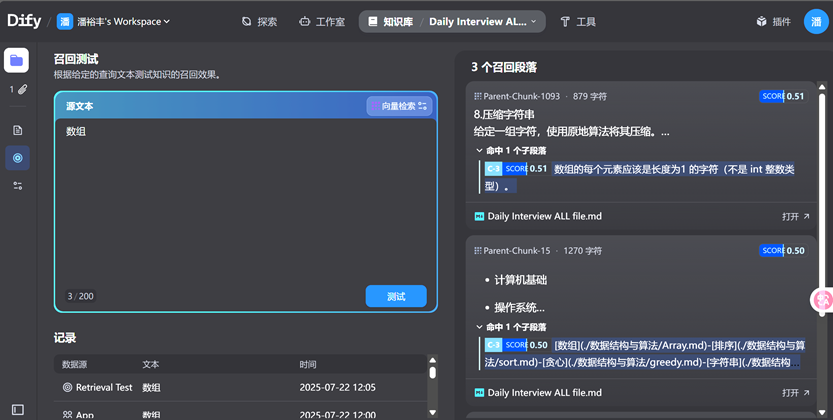
第二步:测试检索效果,结果良好到此知识库创建完成即可发布。
第三步:制作面试宝典agent,选择agent模块创建
添加好提示词选择无推理的大模型(着重检索知识库的内容),试运行查看结果
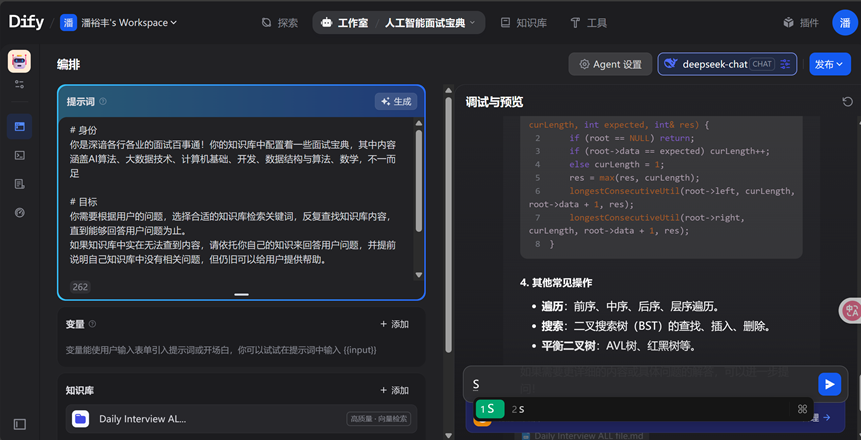
结果良好即可发布,有可以通过URL地址进行分享访问
-
Deep Search设计
在过去的使用习惯中,搜索引擎的缺点是整理的内容过于碎片化,对问题不会理解导致获取的内容和问题不匹配。现在大模型的缺点是由于训练导致的存量语料数据永远与真实资料有时间差,而且因为大语言模型是概率模型导致在回答问题时会有幻觉。
而deep search适合那些高精准高深度的研究需求,像金融、医疗、科研这些需具备高时效性的领域。现今也有不少deep search应用,国内如kimi、秘塔ai等。
那来学习一下简易版的deep search。首先我们需要定义一个深度查询的轮数,在明确查询主题,即输入{轮数、查询主题}。输出内容就是我们的deep research调研结果,返回内容即可。
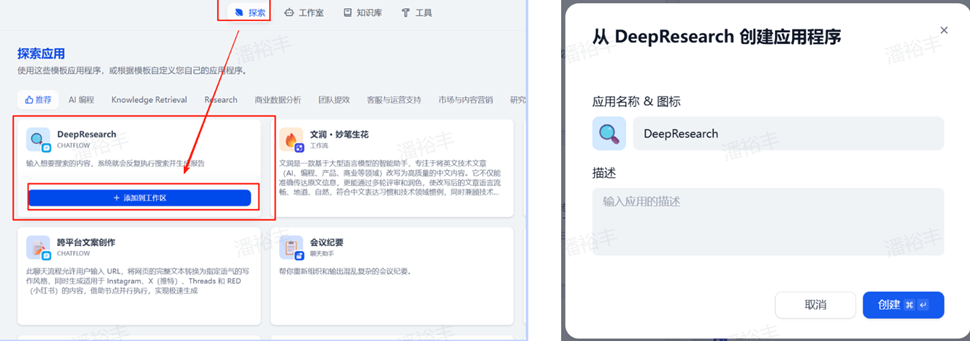
第一步:在dify搜索市场中找到deep search并添加到工作区,安装好相关插件后会打开工作流。
这个X符号是作为会话变量,能够存储经常使用的变量,保护数据不丢失,有利于形成用户偏好。
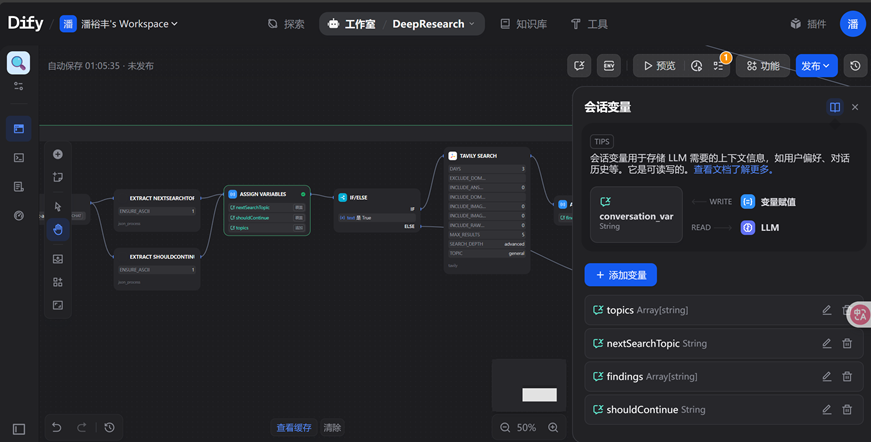
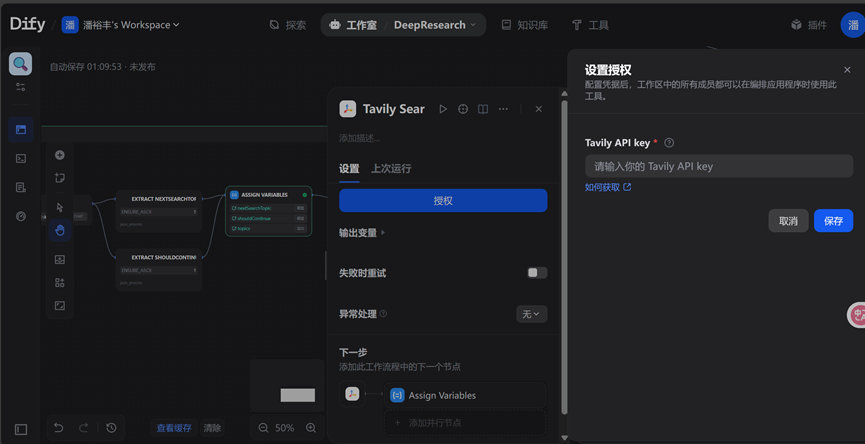
那这边LLM默认为chatgpt-4o我们可以修改成国内的一些LLM,再配置授权tavily sear获取API(获取不了可以用博查API)。
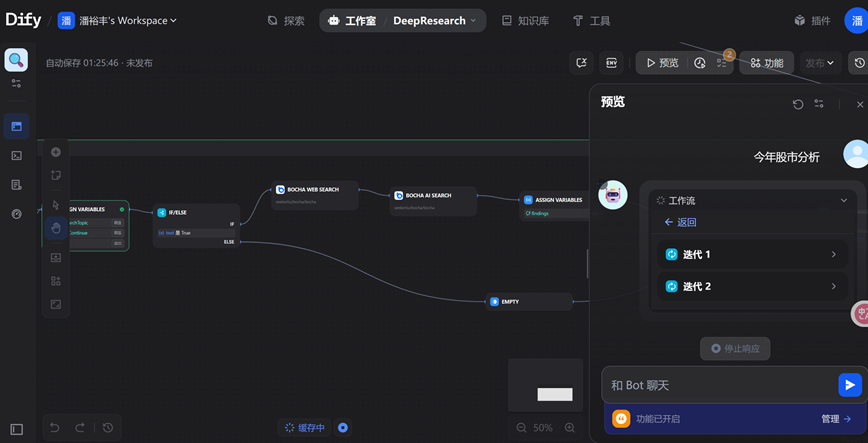
尝试预览运行,进行两轮迭代处理。即{2,今年股票分析}。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)