清华与上海AI Lab发布LLM推理能力强化学习综述
智能体在环境中观察到“状态”(State),并根据其“策略”(Policy)选择一个“动作”(Action),执行动作后,智能体会得到一个“奖励”(Reward),并进入一个新的状态。这篇论文的发布,不仅为研究人员提供了宝贵的参考,也向所有人揭示了RL与LLM结合所蕴含的巨大潜力,预示着一个由RL驱动的,能够自主推理、自我完善的超智能时代的到来。动态采样允许模型在与环境互动时生成新的、多样化的数据
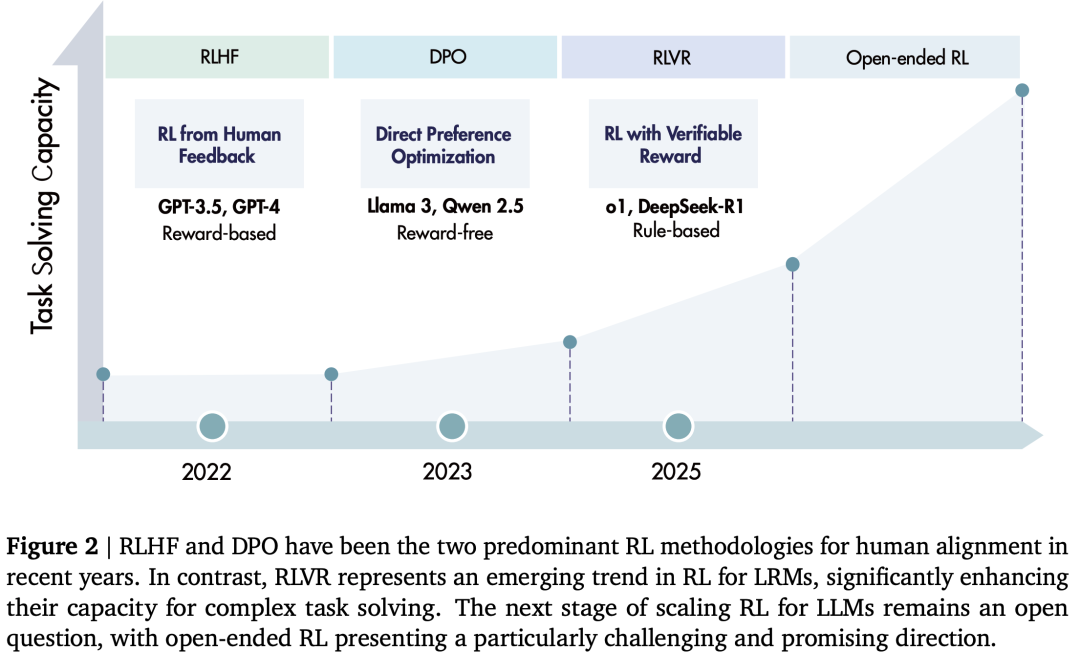
长久以来,强化学习(RL)一直被视为驱动人工智能迈向超人能力的关键技术,其成功的典范莫过于DeepMind的AlphaGo,它通过自我博弈和奖励信号,超越了围棋世界冠军的水平。在大语言模型(LLM)的浪潮中,RL最初以“从人类反馈中学习的强化学习”(RLHF)形式崭露头角,主要用于将模型行为与人类偏好对齐,使其输出更具帮助性、诚实性和无害性。
然而,一个全新的、更具野心的趋势正在涌现:利用RL来直接激励模型的推理能力,从而催生出“大型推理模型”(LRMs)。这与以往仅仅调整模型“说话方式”的做法截然不同。OpenAI的o1和DeepSeek-R1等开创性工作证明,通过对数学题的正确答案或代码的单元测试通过率等“可验证奖励”(RLVR)进行强化训练,模型能够执行诸如规划、反思和自我纠正等复杂的长篇推理 。这揭示了一个除了预训练数据和模型参数规模之外,新的、互补的性能扩展维度——“推理计算”(reasoning compute) 。
 论文:A Survey of Reinforcement Learning for Large Reasoning Models
论文:A Survey of Reinforcement Learning for Large Reasoning Models
地址:https://arxiv.org/pdf/2509.08827
该综述正是在这一背景下应运而生,它旨在全面回顾RL在LRMs中的应用,深入剖析其基本组成、核心问题、训练资源和下游应用,并展望未来的发展方向。它不仅仅是对过往成就的梳理,更是对未来如何进一步利用RL推动人工智能迈向“人工超智能”(ASI)的战略性思考。
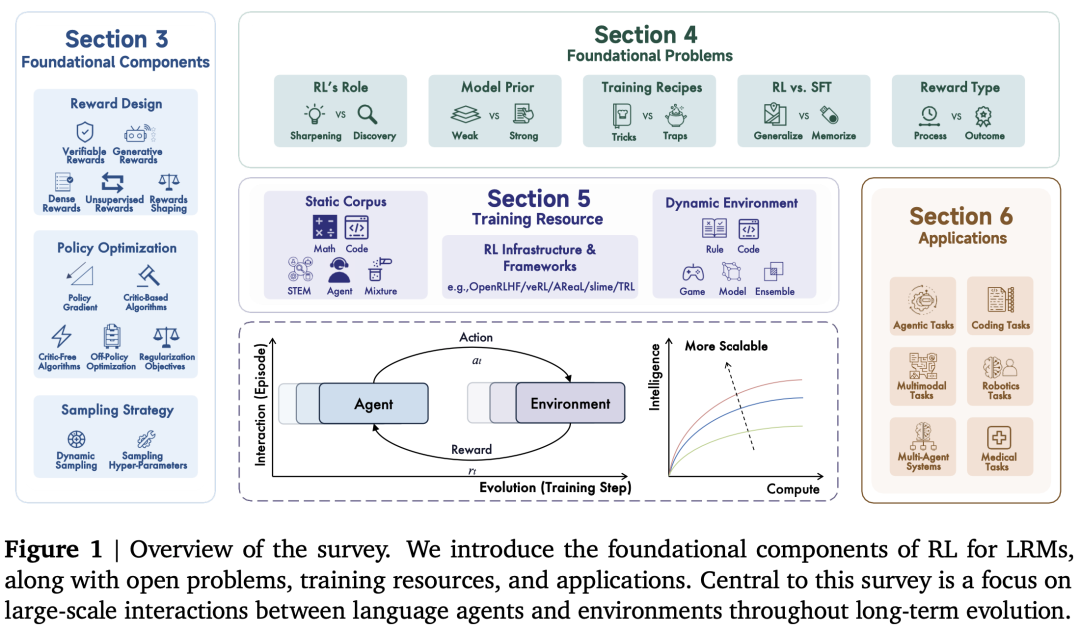
理论基础:RL与LLM的结合
RL核心概念与LLM的角色映射
要理解RL如何赋能LLM,首先需要把握RL的基本框架。在一个标准的RL循环中,有一个“智能体”(Agent)和一个“环境”(Environment)。智能体在环境中观察到“状态”(State),并根据其“策略”(Policy)选择一个“动作”(Action),执行动作后,智能体会得到一个“奖励”(Reward),并进入一个新的状态 。这个过程持续进行,智能体的目标就是通过不断地尝试和学习,最大化其获得的累积奖励 。
当我们将LLM置于这个框架中时,概念的映射变得直观且有趣。一个提示或任务(Prompt/Task)被视为初始状态。LLM本身就是智能体,而它生成的一系列标记(token)则被看作是智能体在每一步所采取的动作 。已生成的文本序列和原始提示共同构成了当前状态。奖励通常在模型完成整个响应后一次性给予,不过也有一些方法会赋予每一步生成标记一个奖励。
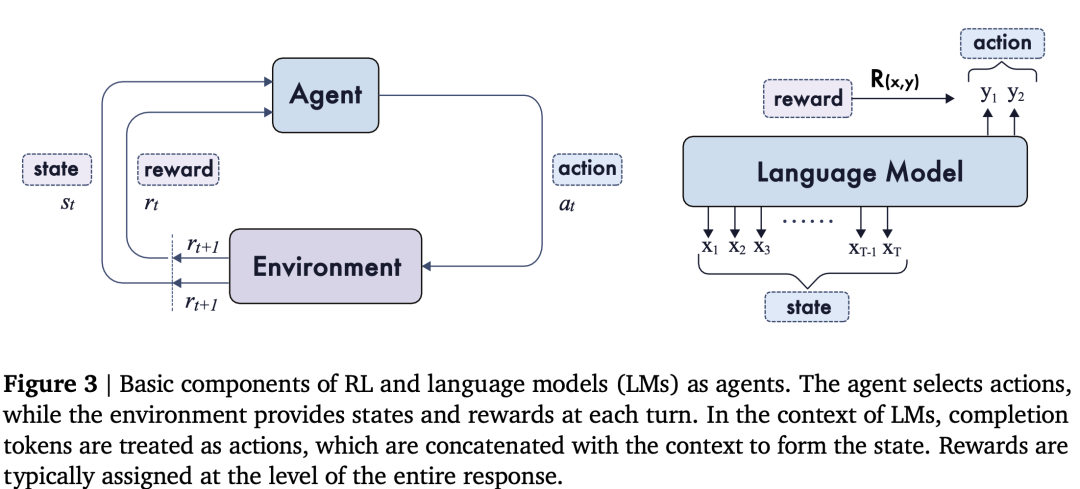
如上图所示,RL的基本组成部分与LLM作为智能体的角色得到了清晰的映射。
关键数学公式:目标函数
在RL中,智能体的学习目标是最大化其在所有可能轨迹上的期望累积奖励 。这个目标可以通过以下数学公式来表示:
这个公式看起来复杂,但思想非常简单:
-
:我们的目标是找到一组最佳的模型参数 (也就是语言模型本身),来最大化某个目标函数。
-
:这就是我们要最大化的目标函数,它代表了策略 的性能。
-
:这表示“期望值”,即在所有可能的输入( )和模型生成的响应( )上的平均性能。
-
:输入 来自一个数据分布 ,这代表了现实世界中可能遇到的所有任务或提示。
-
:模型的响应 是根据当前模型参数 所决定的策略 生成的。
-
:这是模型对输入 给出响应 后获得的奖励。
简单来说,这个公式的核心思想是:通过不断调整模型的参数 ,使模型在面对各种任务时,能够生成获得最高平均奖励的响应 。这篇论文后续探讨的各种RL算法,都是基于这个基本思想,并在此之上加入了不同的技巧和约束来提高训练的稳定性和效率 。在实践中,为了保持模型的语言流畅性并防止其偏离预训练时的能力,通常会加入一些正则化项(如KL散度惩罚),将学习后的策略约束在与原始模型相近的范围内 。
构建RL-for-LRMs的基石
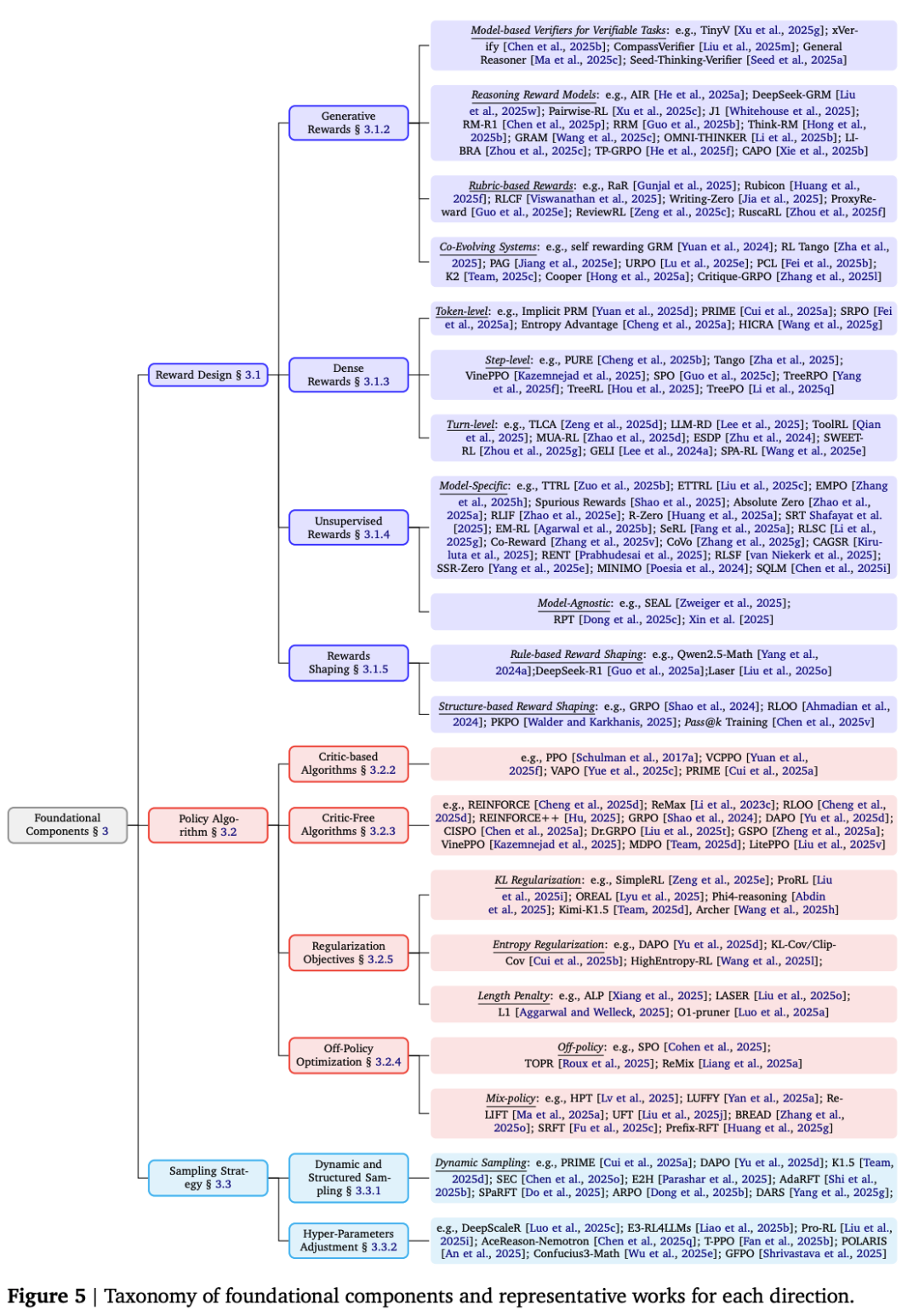
奖励设计(Reward Design)
奖励信号是驱动RL训练的“灵魂”,本综述详细讨论了多种奖励设计方法,揭示了奖励设计的艺术和科学。
-
可验证奖励(Verifiable Rewards): 这是最直接、最客观的奖励类型。例如,在数学任务中,如果模型的答案正确,它就获得正奖励;在编程任务中,如果代码通过了单元测试,它也获得奖励 。这种奖励的优点是客观、明确,但缺点是只适用于有明确正确答案的任务,并且可能忽略了模型生成答案的过程质量。
-
生成式奖励(Generative Rewards): 这种奖励不依赖于预定义的规则,而是由一个单独训练的“奖励模型”来评分 。例如,一个奖励模型可以评估LLM生成的回应是否符合人类偏好或特定的标准。这种方法更具通用性,但奖励模型本身可能存在偏见或不一致性。
-
无监督奖励(Unsupervised Rewards): 旨在从无标签数据中自动提取奖励信号。例如,通过最大化熵(MaxEnt)来鼓励模型探索更多样的行为,或者利用模型自身的困惑度(Perplexity)来衡量生成质量。
-
奖励塑形(Reward Shaping): 这是一种通过提供额外、密集的奖励信号来引导模型学习过程的技术。它不是改变最终的目标,而是像给模型“提供路标”一样,帮助它更快地找到正确的方向。一个例子是,在长篇推理任务中,为模型每一步正确的思考链提供奖励,以鼓励其生成高质量的中间步骤 。
策略优化(Policy Optimization)
有了奖励信号,下一步就是优化模型的策略以最大化累积奖励 。
-
策略梯度(Policy Gradient): 这是最基础的RL优化方法,它直接通过计算策略对目标函数的梯度来进行优化。例如,PPO(Proximal Policy Optimization)就是一种广泛使用的策略梯度算法,它在每次更新时对策略变化进行限制,从而保证训练的稳定。
-
基于评论家(Critic-based Algorithms): 这类算法引入了一个名为“评论家”(Critic)的额外网络,它负责估计当前状态下采取某个动作的长期价值。智能体(即LLM)根据评论家的建议来调整其策略,从而更有效地进行学习。
-
无评论家(Critic-Free Algorithms): 与上述方法相反,这类算法不使用单独的价值网络,而是直接通过比较不同轨迹的奖励来优化策略。例如,DPO(Direct Preference Optimization)就是一种流行的无评论家算法,它直接从人类偏好数据中学习一个最优策略,而无需显式地训练奖励模型或价值网络。
-
正则化目标(Regularization Objectives): 为了防止模型在强化学习过程中“忘记”其原始的语言能力,通常会在优化目标中加入正则化项,例如KL散度(KL-Divergence),它确保学习后的策略不会与原始策略(SFT模型)相差太远。
采样策略(Sampling Strategy)
采样策略决定了智能体如何从环境中收集数据来学习 。
-
动态与结构化采样(Dynamic and Structured Sampling): 动态采样允许模型在与环境互动时生成新的、多样化的数据,而结构化采样则确保生成的数据具有特定的格式或结构,例如,遵循逻辑链或特定的问题解决步骤 。
-
采样超参数(Sampling Hyper-parameters): 这包括温度(temperature)和束搜索(beam search)等参数的调整,它们可以影响模型的探索性或确定性,从而在生成内容的创造性和准确性之间取得平衡 。
前沿探索:当前面临的根本性挑战
该综述不仅回顾了技术,更直面了RL应用于LRMs的五个根本性问题,这些问题至今仍存在争议 。
-
RL的角色:精炼还是发现?
-
精炼(Sharpening): RL是否仅仅是用来“精炼”或“微调”模型已有的能力?就像用磨刀石磨砺一把刀,让其变得更锋利?
-
发现(Discovery): RL是否能够帮助模型“发现”全新的、在预训练数据中从未见过的推理能力?这就像是教一个从未用过刀的人如何用刀来雕刻艺术品。
-
该综述认为,RL在两个角色中都扮演着重要作用,但其在“发现”新能力方面的潜力仍有待充分挖掘。
-
RL vs. SFT:泛化还是记忆?
-
-
SFT(Supervised Fine-Tuning): 通过在高质量数据集上进行监督微调,可以使模型学会“记忆”特定的模式和知识。
-
RL: 通过与环境互动,RL能使模型学会“泛化”,即使遇到新的、未见过的任务,也能应用已有的推理能力。
-
一个关键的挑战是,这两种训练范式之间存在潜在的“紧张关系”:提升推理能力可能会损害指令遵循能力。
-
-
模型先验:弱先验与强先验
-
-
弱先验(Weak Prior): 指那些未经过大量SFT训练,或未针对特定任务进行优化的基础模型。这些模型在RL训练下,推理能力有显著提升。
-
强先验(Strong Prior): 指那些已经通过SFT或指令微调的模型。研究表明,RL也可以进一步提升这些模型的性能,但需要更精心的设计和控制。
-
这篇综述指出,对于弱先验模型,一种有效的策略是先通过SFT增强其推理先验,然后再进行RLVR训练。
-
-
训练秘籍:技巧还是陷阱?
-
-
在RL训练中,有大量的“技巧”被提出,如特定的数据混合、课程学习(curriculum learning)等。然而,这些技巧中哪些是真正有效的,哪些可能只是在特定条件下凑效的“陷阱”,仍是未解之谜。
-
-
奖励类型:过程还是结果?
-
-
结果奖励(Outcome Reward): 仅在任务完成后给予,例如答案正确或不正确。
-
过程奖励(Process Reward): 在推理的每一步骤中给予奖励,例如模型生成的思考链(Chain-of-Thought)是否逻辑清晰、步骤正确。
-
这两种奖励类型各有优劣,结果奖励简单客观,而过程奖励则能更细致地引导模型的推理过程。
应用与展望
广泛应用
RL-for-LRMs的应用已超越了传统的语言任务,深入到多个前沿领域 。
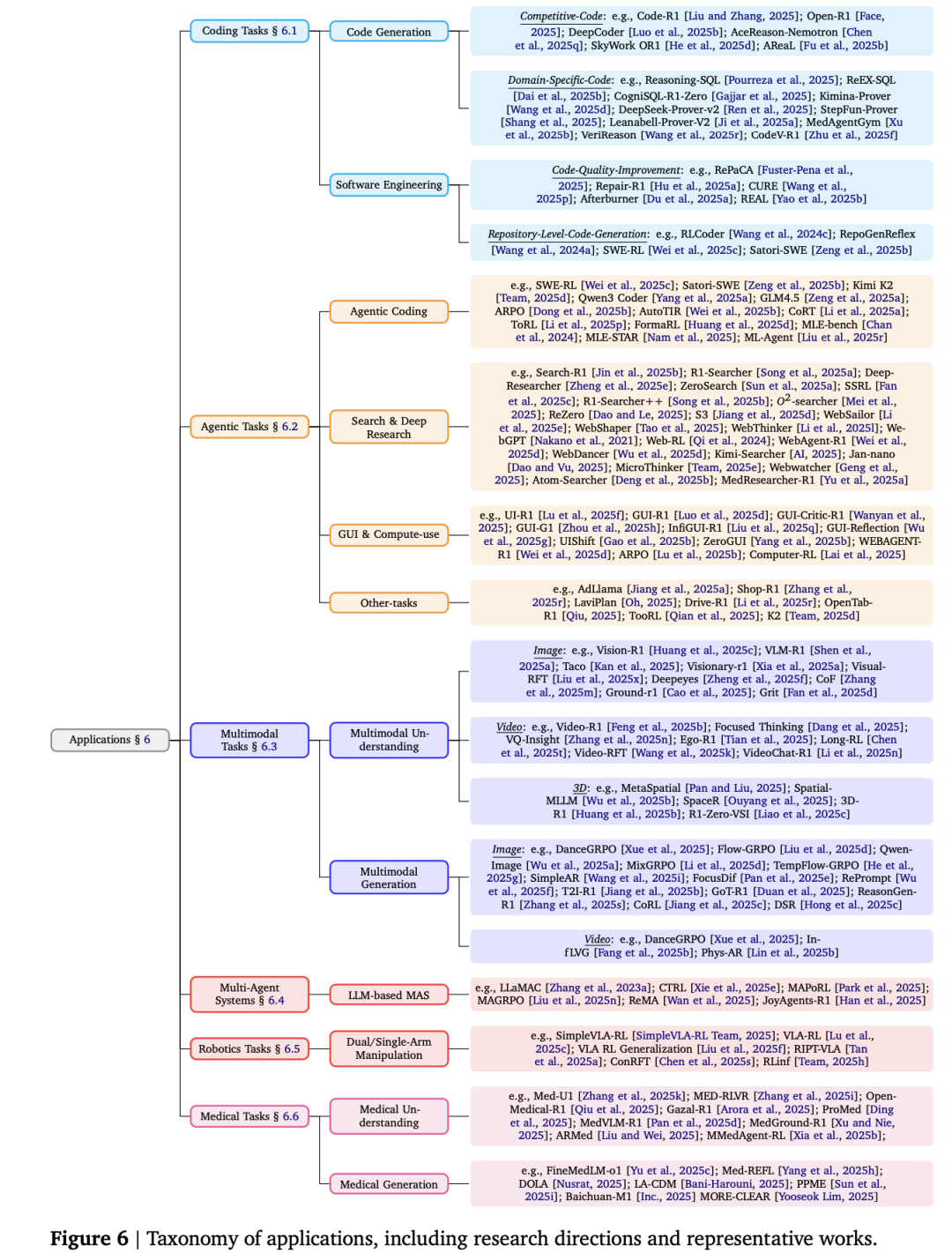
-
编程任务: RL在编程中表现出色,它能根据单元测试的通过情况来优化代码生成,甚至在多模态理解方面也取得了显著进步。
-
智能体任务(Agentic Tasks): RL被用于训练可以与外部工具和环境交互的“智能体”,例如执行网页浏览、API调用等复杂任务。
-
多模态任务: RL能够增强模型在图像、视频和3D空间中的推理能力,通过为多模态任务设计可验证的奖励函数,实现了强大的泛化能力。
-
机器人与医疗: RL被应用于机器人控制,使其能从网络知识中学习并执行复杂任务 。在医疗领域,RL也用于增强模型的医学知识推理能力,例如通过分析电子病历来辅助临床决策。
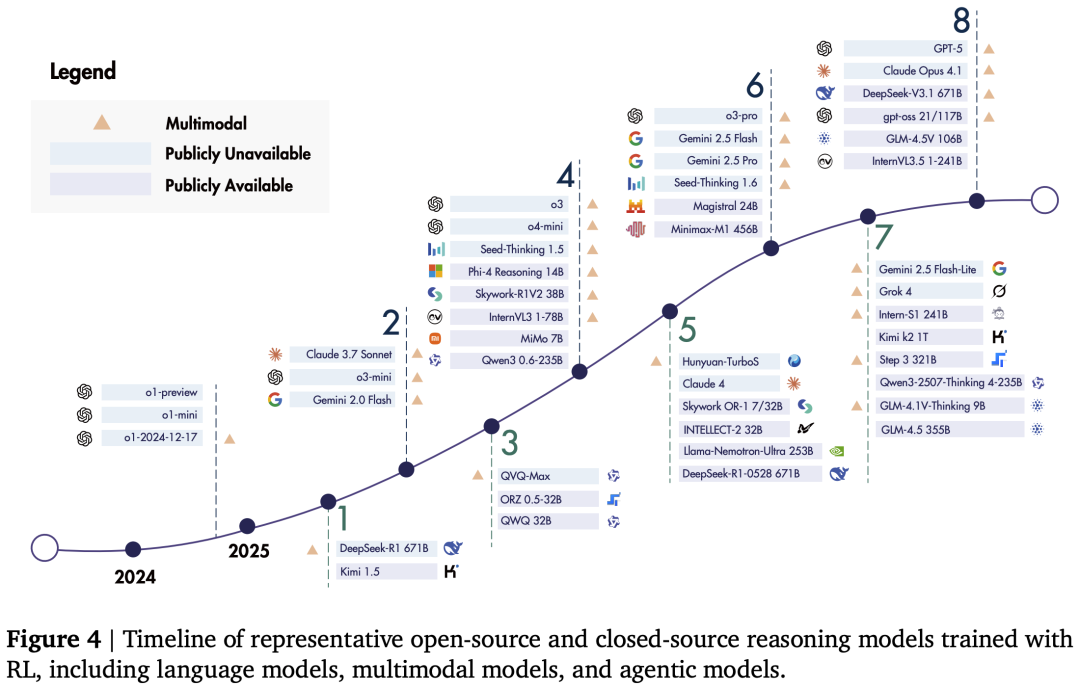
以下图表展示了近年来RL赋能下的代表性模型发展历程:
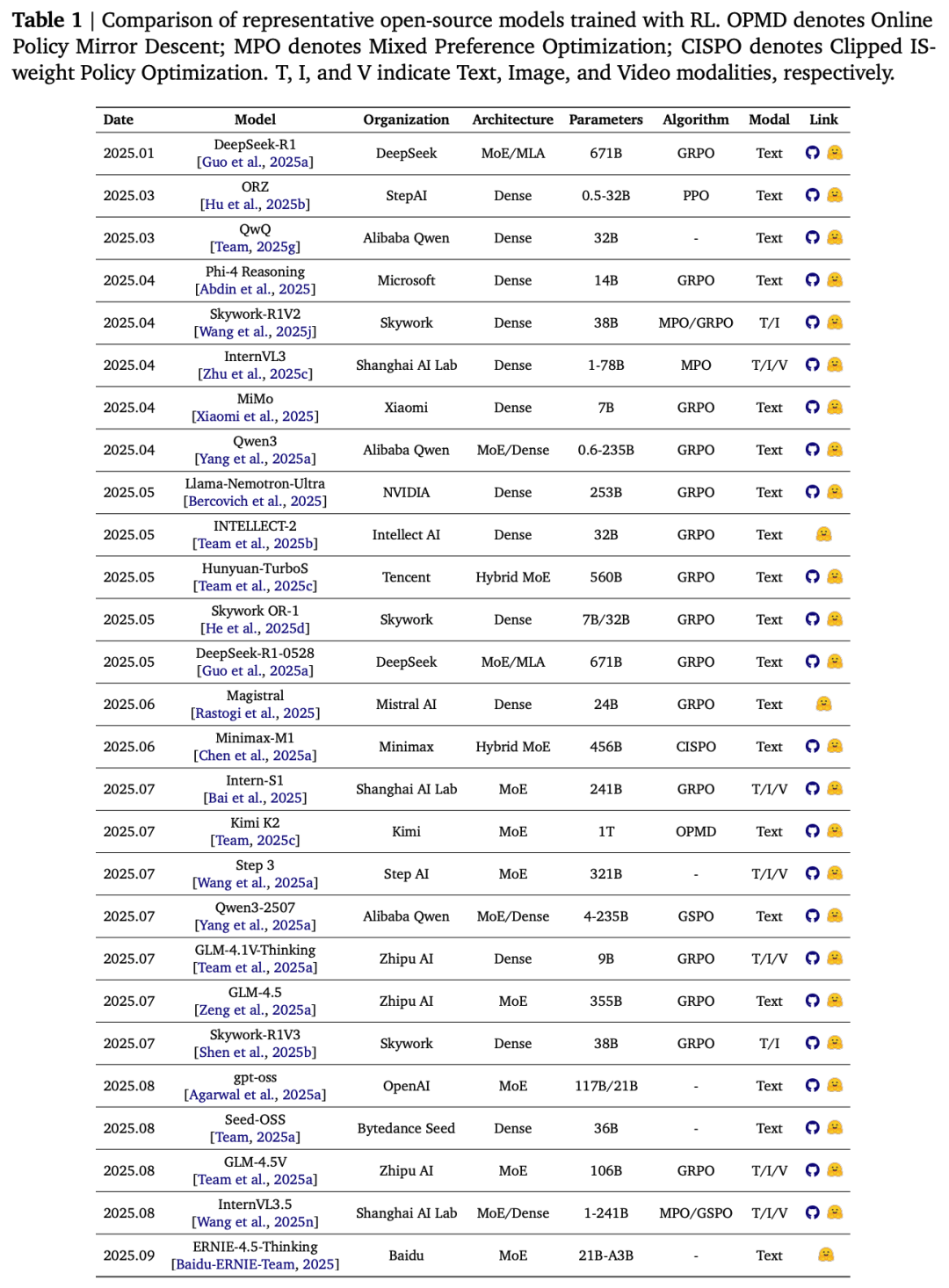
以下表格详细列举了部分开源推理模型的关键信息:
未来方向
该综述还为RL和LLM的未来研究指明了九个充满潜力的方向 。
-
持续强化学习(Continual RL): 使模型能够像人类一样,在面对新任务时不断学习和适应 。
-
基于记忆的RL(Memory-based RL): 赋予LLM强大的记忆能力,使其能够在长时间的互动中更好地利用和回忆信息 。
-
基于模型的RL(Model-based RL): 让LLM学会构建一个内部的“世界模型”,从而能够像人类一样进行前瞻性规划和预测 。
-
RL用于LLM预训练: 将RL集成到LLM的预训练阶段,而不仅仅是作为微调手段 。
结论
这篇综述全面且深入地解读了RL在推动大语言模型向更强大的推理模型(LRMs)演进中的关键作用 。论文的核心贡献在于,它系统性地梳理了RL的基本理论、核心技术、前沿挑战以及在广泛应用中的实践,并为未来的研究提供了明确的方向性指导 。
通过RL,我们看到了LLM能力扩展的崭新路径,即通过激励推理本身,而非仅仅依赖数据和参数规模的增长 。从最初的RLHF到如今的RLVR,RL已经从一个用于“对齐行为”的工具,蜕变为一个能够“铸造智能”的核心技术 。这篇论文的发布,不仅为研究人员提供了宝贵的参考,也向所有人揭示了RL与LLM结合所蕴含的巨大潜力,预示着一个由RL驱动的,能够自主推理、自我完善的超智能时代的到来 。


-

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)