SDE-SQL:通过带有SQL探测的自我驱动探索增强大型语言模型中的文本到SQL生成
本文提出SDE-SQL框架,通过自我驱动的数据库探索提升大型语言模型(LLM)在文本到SQL任务中的表现。现有方法依赖静态预处理数据库信息,限制了模型对数据库内容的理解。SDE-SQL创新性地引入SQL探测机制,使LLM能在推理过程中主动生成和执行探索性查询,迭代优化对数据库的理解。在BIRD基准测试中,该方法使用Qwen2.5-72B-Instruct模型实现了67.67%的执行准确率(零样本设
谢文轩1{ }^{1}1, 戴亚勋2{ }^{2}2, 姜文浩3∗{ }^{3 *}3∗
1{ }^{1}1 华南理工大学, 2{ }^{2}2 苏州大学
3{ }^{3}3 广东省人工智能与数字经济重点实验室(深圳)
lancelotxie601@gmail.com, cswhjiang@gmail.com
摘要
大型语言模型(LLMs)的最新进展在文本到SQL任务上取得了显著进步。然而,现有方法通常依赖于推理时提供的静态预处理数据库信息,这限制了模型深入理解底层数据库内容的能力。在缺乏动态交互的情况下,LLMs被局限于固定的、人工整理的上下文,并且缺乏自主查询或探索数据的能力。为克服这一局限性,我们引入SDE-SQL,一种新颖的框架,使LLMs能够在推理过程中进行自我驱动的数据库探索。这是通过生成和执行SQL探测实现的,使模型能够主动检索信息并迭代地改进其对数据库的理解。不同于先前的方法,SDE-SQL在零样本设置下运行,不需要上下文演示或问题- SQL配对。在BIRD基准测试中,使用Qwen2.5-72B-Instruct评估,SDE-SQL比原始Qwen2.5-72B-Instruct基线在执行准确率上实现了**8.02%的相对提升,成为在没有监督微调(SFT)或模型集成情况下的开源方法的新最佳水平。此外,当结合SFT时,SDE-SQL还带来了额外的0.52%**性能提升。
1 引言
文本到SQL是自然语言处理领域的一个长期任务,专注于将自然语言问题转化为可执行的SQL查询。这种能力不仅赋予非专家用户无缝交互结构化数据库的能力,而且通过基于事实数据库存储的信息来回应问题,缓解了问答系统中的幻觉问题。
大型语言模型(LLMs)的最新进展显著提升了文本到SQL系统的性能和准确性。基于LLM的方法在原始Spider数据集(Yu et al., 2019)上的执行准确率已超过90%,并在更复杂多样的基准测试如BIRD(Li et al., 2023)上展现了令人鼓舞的结果。尽管有这些进展,当前模型性能与人类水平能力之间仍存在明显差距,特别是在新推出的Spider 2.0基准测试(Lei et al., 2025)中,该测试提出了更为现实和具有挑战性的语义解析场景。目前基于大型语言模型(LLM)的文本到SQL方法通常包含三个核心组件:模式链接、SQL生成和SQL优化。在模式链接阶段,以前的工作主要集中在将自然语言问题与相关的数据库模式元素对齐,提高精度和上下文相关性。在SQL生成阶段,提出了各种方法来分解复杂问题并纳入推理策略。在优化阶段,SQL错误类型的分类变得更加系统化,使得开发针对性的修正机制成为可能。
尽管有这些进展,但SQL的一个关键方面仍未得到充分探索:其作为支持快速且信息丰富的执行的数据库接口的固有交互性。这种未充分利用的特性可能是导致基于LLM的系统与人类专家之间性能差距的部分原因。
为解决这个问题,我们提出了SDE-SQL,一个新颖的框架,在生成和优化阶段都融入了自我驱动探索,如图1所示。除了生成直接回答自然语言问题的最终SQL查询外,模型还会自主生成和执行一系列辅助查询——称为SQL探测——专门设计用于探索和提取数据库中的信息信号。
对于模式链接,我们利用基于实体的技术,包括值检索和软链接。在生成阶段,模型基于问题和模式进行两阶段探索过程,使其能够迭代改进对数据库内容的理解,并基于检索到的信息进行零样本推理。
生成之后,我们在优化阶段也引入了一个两阶段探索过程。对于返回明确执行错误的SQL查询,模型根据错误反馈直接修改它们。对于成功执行但返回空结果的查询,第一阶段的探索使用分解子查询(Sub-SQLs)的执行结果帮助模型诊断潜在问题。在第二阶段,模型生成目标明确的SQL探测以探索可能的解决方案,并选择最有希望的一个来生成最终优化的查询。
实证上,SDE-SQL在BIRD基准测试中使用Qwen2.5-72B-Instruct在零样本设置下达到了67.67%的执行准确率。经过监督微调(SFT),性能进一步提升至68.19%。
我们的主要贡献如下:
- 我们提出了SDE-SQL,这是一种新颖的框架,利用自我驱动探索来增强LLMs在文本到SQL任务中的推理和交互能力,显著缩小了与人类专家之间的差距。
-
- 我们在整个SQL生成和优化阶段引入了一个统一的探索机制,使LLMs能够主动查询数据库,诊断潜在错误,并迭代改善查询质量。
-
- 我们在BIRD和Spider基准测试上进行了广泛的实验,并进行了消融研究,验证了自我驱动探索的有效性。
-
- 我们构建了一个小规模的数据集用于监督微调(SFT)在探索和生成任务上,并展示了针对模块级的微调进一步提高了SDE-SQL的性能。
2 相关工作
将自然语言问题转换为数据库查询是一项经典任务,最早的工作使用归纳逻辑编程和人工设计的模板完成此任务(Zelle and Mooney, 1996)。近年来,随着自然语言处理技术的进步,文本到SQL技术的发展大致可分为两个阶段。
2.1 基于传统Seq2Seq模型的方法
以前的工作主要集中在改进编码或解码方法,因为seq2seq模型框架由两个主要组件组成,即编码器和解码器。IRNet采用双向LSTM来编码问题,并使用自注意力机制来编码数据库模式,最终使用LSTM作为基于语法的解码器(Guo et al., 2019)。为了有效捕捉数据库模式与问题之间的关系,RAT-SQL开发了一种具有关系感知自注意力机制的编码器(Wang et al., 2020)。此后,Cai et al. (2022) 和 Cao et al. (2021) 利用图神经网络来编码模式与查询之间的关系。利用预训练语言模型(PLMs)在各种NLP任务中的卓越能力,Hwang et al. (2019) 首次将BERT作为编码器。为了改进解码器,Xu et al. (2017) 和 Choi et al. (2020) 专注于基于草图的解码方法。为了减少推理期间的时间消耗,SDSQL提出了模式依赖学习并去除了执行引导(EG)解码策略(Hui et al., 2021)。
2.2 基于LLM的方法
随着LLM的出现,文本到SQL领域经历了一场突破性的创新,给任务处理方法带来了重大变化。
基于提示工程的方法 Rajkumar et al. (2022) 评估了LLM在文本到SQL任务中的潜力,展示了LLM在此任务中的非凡能力。基于上下文学习,DAIL-SQL (Gao et al., 2023) 引入了一种新的提示工程方法,通过问题表示、演示选择和演示组织来提升LLM的文本到SQL性能。基于思维链(CoT)推理风格(Wei et al., 2023),DIN-SQL(Pourreza and Rafiei, 2023)、Divide-and-Prompt(Liu and Tan, 2023)、CoE-SQL(Zhang et al., 2024a) 和 SQLfuse(Zhang et al., 2024b) 设计了包含推理步骤的CoT模板以激发链式思考。为了增强LLM处理复杂问题的能力,QDecomp(Tai et al., 2023)、DIN-SQL(Pourreza and Rafiei, 2023)、MAC-SQL(Wang et al., 2025) 和 MAG-SQL(Xie et al., 2024) 分解复杂的自然语言问题并逐步求解。此外,MCS-SQL(Lee et al., 2024)、CHASESQL(Pourreza et al., 2024a) 和 CHESS(Talaei et al., 2024) 通过在推理阶段生成大量候选SQL查询并选择最合适的查询来提升性能。
基于微调的方法 尽管基于闭源模型(如 GPT-4o(OpenAI et al., 2024))的提示工程方法在文本到SQL任务中表现良好,但它们面临高成本、无法保证隐私和灵活性有限等问题。因此,针对文本到SQL任务微调开源模型具有重要的实际价值和应用潜力。DTS-SQL(Pourreza and Rafiei, 2024) 和 SQLfuse(Zhang et al., 2024b) 探索了对LLM进行模式链接和SQL生成的微调。SQL-PaLM(Sun et al., 2024)、Open-SQL(Chen et al., 2024)、XiYan-SQL(Gao et al., 2025) 和 CodeS(Li et al., 2024) 在精心挑选的数据上微调开源LLM,而CodeS特别采用了增量预训练方法,使用专门策划的以SQL为中心的语料库。此外,还有一些新视角。DELLMHong et al. (2024) 特别微调了一个提供领域知识的数据专家语言模型,而SQL-GENPourreza et al. (2024b) 提出了一种新颖的专家混合(MoE)架构来处理多种SQL方言。
3 方法论
3.1 基于实体的模式链接
在文本到SQL任务中,模式链接是指根据输入的自然语言问题识别和选择相关表、列和值的过程。为了提高链接的准确性,我们使用基于实体的链接方法,包括值检索和软模式链接。
3.1.1 基于实体的值检索
类似于Talaei等人(2024年)的研究中的检索模块,我们首先通过少样本学习使用LLM从自然语言问题中提取实体。然后,值检索器基于局部敏感哈希(LSH)和语义相似性识别数据库中的相似值。
3.1.2 基于实体的软模式链接
为了提高模式链接阶段的容忍度,我们选择了软模式链接方法,如Xie等人(2024年)的方法。我们采用一次性方式提示LLM根据每个实体选择相关列。对于选定的列,在后续SQL生成过程中提供尽可能详细的信息,包括列名、类型、列描述、值示例和值描述。对于未选中的列,仅保留列名和类型。这种方法不仅显著减少了输入长度,使语言模型在生成过程中聚焦于最相关的数据库模式,还通过防止删除未被选中但有用的列增强了容忍度。
3.2 基于自我驱动探索的生成
在以往的文本到SQL研究中,SQL往往被视为中间结果或最终输出,其固有功能大多被忽视。因此,我们引入了SQL探测的概念。字面意思是作为探针的SQL查询,SQL探测专门设计用于基于当前自然语言问题探索数据库。形式上,我们将任务定义为从自然语言查询QQQ和数据库模式DDD到相应SQL查询SSS的映射。自然语言查询QQQ由两部分组成:目标和条件(Xie et al., 2024)。通常,目标对应于SQL查询SSS中的主SELECT子句,而条件则对应于SSS中的其他子句,例如WHERE子句。图2是一个例子。
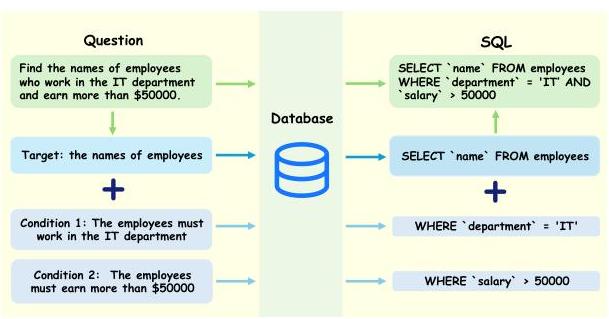
图2:文本到SQL的一个例子。
为了获得特定的SQL表示,必须首先将实体映射到数据库中的相应列和值。这一步能否准确执行取决于语言模型对数据库的理解程度。
然而,之前处理的数据库模式所提供的信息远远不够。现实世界的数据库往往高度复杂且混乱。不同的表可能包含许多意义相同的列(代表同一项),并且这些列中的值可能有不同的格式,有些值甚至只存在于特定的表中。在缺乏足够信息的情况下,LLM只能随机识别这些相似列和值的组合。这也是LLM在此任务中表现尤其不稳定的关键原因之一。在评估过程中,经常观察到模型有时能正确预测某些例子,而在其他时候却在同一例子上失败。在以往工作中,一些方法涉及使用语言模型生成多个SQL候选,然后选择最合适的一个。然而,这种方法并未解决根本问题。我们认为最根本的解决办法是赋予LLM动态与数据库互动的能力。在SDE-SQL中,LLM在生成前会在数据库内进行两阶段自我驱动探索。
3.2.1 候选探索
此阶段探索的目标是使大型语言模型能够查询有关目标和单一条件的信息,并为每个目标和条件选择适当的候选。由于自然语言问题中的实体可以映射到列或值(或两者都有),LLM需要确定每个实体的候选列和候选值。最初,语言模型生成几个基础SQL探测,列举目标的候选列。这些SQL仅关注查询目标而不带任何附加条件。接下来创建条件SQL探测,其中每个探测通常在基础SQL探测的基础上添加一个列候选和可能的一个值候选,对应特定条件。假设每组候选包含两个选项,则条件SQL探测的生成过程如图3所示,其中每条根到叶路径对应一个特定的条件SQL探测。我们将每个条件SQL探测的条件描述称为条件描述候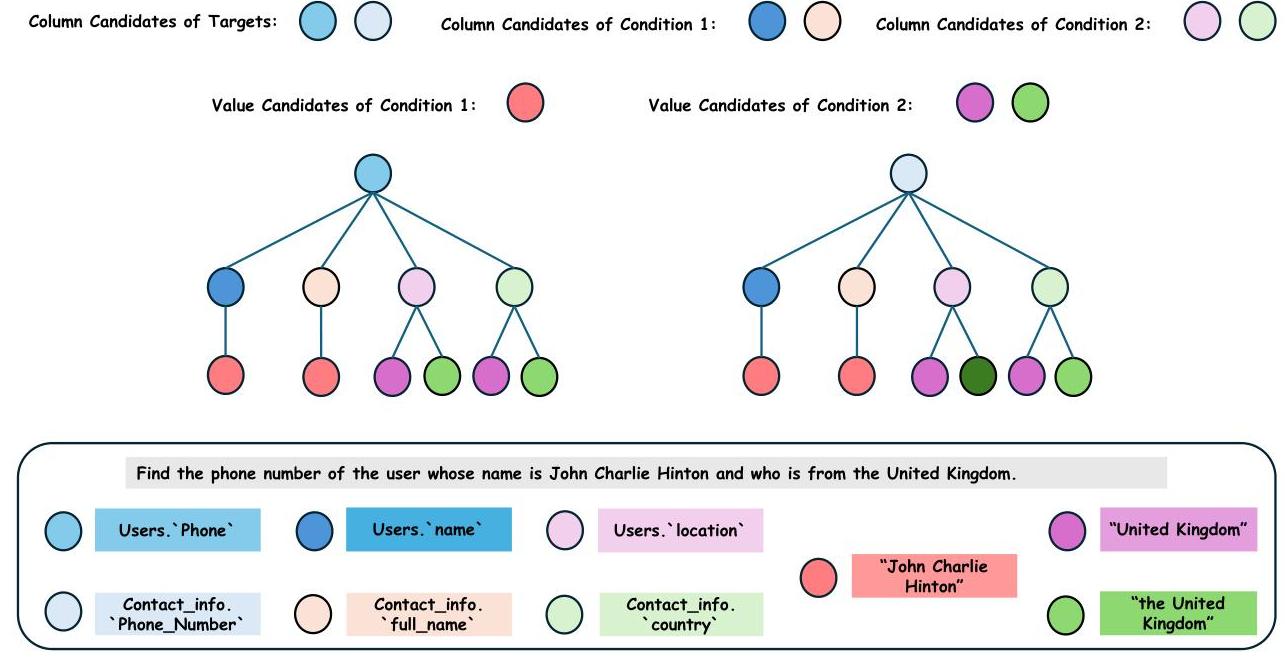
图3:条件SQL探测生成过程,用树结构说明。
date。例如,在图3中,一个条件描述候选是:
SELECT Phone FROM users WHERE name = 'John_Charlie_Hinton’AND location = ‘United_Kingdom’;
3.2.2 组合探索
基于前一阶段探索的结果,候选范围已被缩小。现在,有必要将所有条件结合起来,找到最适合的候选组合。对于返回无结果的SQL查询,对应的候选组合肯定是不合适的。
3.2.3 使用探索结果进行零样本生成
在我们的实验中,我们发现现有方法并没有充分利用大型语言模型在SQL生成方面的潜力。例如,诸如设计新的分解方法让模型逐步解决复杂问题、使用各种提示技巧生成多个候选供选择,或采用蒙特卡洛树搜索(MCTS)等搜索策略来增强语言模型的推理能力等策略,可以带来模型性能的小幅提升。然而,这些提升仍然远小于提供充足信息所取得的效果。
因此,在SDE-SQL中,LLM生成器基于数据库模式和前两个探索阶段的结果生成SQL,而不依赖任何问题-SQL对作为少量样本示例,也不使用任何问题分解策略。为了提高SQL生成的准确性和鲁棒性,我们采用了一种一致性策略,通过比较多个生成SQL查询的执行结果选择最一致的答案。
3.3 基于自我驱动探索的优化
在过去,基于上下文学习的现有技术已经引入了文本到SQL错误的检测和修复解决方案,每种解决方案在其错误识别算法和为帮助LLM理解和纠正这些错误所提供的补充数据方面有所不同。(Shen et al., 2025)
对于语法错误和模式错误,执行后的错误反馈已经包含了足够的信息,允许LLM有效地完成SQL的修正。然而,对于一些其他更复杂的错误,它们通常会导致空查询结果而没有任何错误消息。即使人类尝试修正这些错误,也不能一次完成;相反,他们需要编写一些SQL语句进行调试,并根据这些查询的执行结果诊断问题。当前的方法是持续重新生成直到修复成功或达到尝试次数上限。在整个修复过程中,LLM没有接收到任何有用的信息,其推理能力也没有得到充分利用。换句话说,错误的原因从未被识别出来。
因此,在SDE-SQL中,我们在SQL修订之前引入了一个全面的自我驱动探索阶段。对于产生空结果的查询,优化过程分为三个不同的阶段:错误原因识别阶段、解决方案探索阶段和修改阶段,如图4所示。
3.3.1 错误原因识别阶段
在一个复杂的SQL语句中,可能会涉及多个表并同时应用多个条件,直接分析整个SQL很难准确定位问题。因此,我们需要进行细粒度的诊断。为了生成一系列用于诊断目的的子SQL作为SQL探测,我们开发了一个基于SQLGlot的分解器。分解器首先将复杂SQL查询转换为抽象语法树(AST),然后通过分析节点类型及其关系来识别不可分割的条件单元。这些在AST中识别出的子树将成为生成语义有效的子SQL的基础,这些子SQL的执行结果将提供给LLM,以帮助其准确诊断并定位原始查询中的问题。分解结果的例子如图8所示。
3.3.2 解决方案探索阶段
我们总结了可能导致空查询结果的五个可能原因。在这个阶段,LLM需要分析前一阶段的探测结果,推导出可能的错误原因假设,然后生成一系列SQL探测以协助探索这些问题的潜在解决方案。
条件冲突或条件重复
此错误指的是在单个条件下执行时能找到数据,但当多个条件结合时找不到满足要求的数据(导致空查询结果)。此错误有两个可能的原因:多个不同条件的组合冲突,或使用不同列对单个条件进行冗余描述。(i) 条件冲突通常发生在条件中的实体对应多个可能的候选列时,只有特定的候选列与其他条件结合才能找到相应的数据项。图5显示了一个例子。(ii) 条件重复发生在条件中的实体映射到多个候选列时,导致大型语言模型生成的SQL无意中使用这些不同的候选列来描述同一个条件,最终导致无法检索到满足预期条件的数据。
不必要的表连接
SQL可能包含不必要的表连接,导致最终交集中没有记录满足条件。
列与值不匹配
此错误发生在所选(但正确的)列的值格式不匹配,或者选择了类似外观的列但不包含预期值时。
子查询范围不一致
有时,子查询的范围可能与主查询不一致,尤其是在子查询中使用MIN/MAX函数时,这常常导致空查询结果。图6展示了一个例子,即子查询中检索到的数据行在两个表JOIN后结果中不存在。
3.3.3 修改后的目标检查
对于一个SQL查询,最重要的部分实际上是查询的目标,它指的是SELECT子句中选择的列。如果SQL中的查询目标与自然语言问题中的原始查询目标不一致,则转换无疑是失败的。然而,当LLM生成SQL时,它们有时会在SELECT子句中包含不属于查询目标的列,例如条件中使用的列。因此,在根据执行结果优化SQL后,有必要检查SQL中的查询目标是否与自然语言问题中的查询目标相匹配。为了避免在此阶段引入新错误,我们允许大型语言模型仅确定SQL中是否选择了不必要的目标列。如果发现此类列,将去除它们而不影响执行。该过程如图7所示。
3.4 监督微调(SFT)
为了进一步增强模型自主探索数据库和利用探索结果生成更准确SQL的能力,我们还对模型进行了监督微调(SFT)。训练数据来自BIRD的训练集。我们采用基于提示的流水线展开数据,最终生成正确SQL的例子被视为微调模型的有效数据。
在9,428个数据点中,通过抽样获得了5,231个有效样本。从每个示例的推理轨迹中,我们提取了两个组成部分:(i) 探索阶段,生成SQL探测;(ii) 预测阶段,基于探索结果生成最终SQL查询。
4 实验
在本节中,我们首先介绍实验设置,然后报告并分析结果。
4.1 实验设置
4.1.1 数据集和指标
Spider (Yu et al., 2019) 是文本到SQL任务中广泛采用的基准数据集。它是大规模的、跨领域的和复杂的,包含10,181个自然语言问题和5,693个对应的SQL查询,分布在200个不同的数据库中。作为文本到SQL任务的挑战性基准,最近提出的BIRD数据集 (Li et al., 2023) 包含95个大规模真实数据库,具有脏值,特征是12,751个独特的问题SQL对。BIRD数据集中的数据库类似于现实世界中的场景,表现出固有的模糊性。因此,每个列提供了详细的描述以及外部知识。在这项工作中,我们选择执行准确性(EX)作为衡量标准,因为它反映了执行SQL查询返回结果的准确性。这个指标考虑了同一问题的各种SQL表达方式,提供了更精确和公平的结果评估。
4.1.2 SFT 设置
对于探索任务和生成任务,我们在8块NVIDIA A800 GPU上对Qwen2.5-72B-Instruct进行了24小时的训练。详细的训练超参数见表4。
4.1.3 基线
为了进行全面比较,我们选择了基于闭源模型的代表性方法和基于开源模型且不进行模型集成的代表性方法作为基线。
4.2 主要结果
4.2.1 BIRD 结果
在BIRD开发数据集上评估时,基于Qwen2.5-72B-Instruct的SDE-SQL优于大多数基于GPT-4的方法和大多数开源模型,在微调后达到了68.19%\mathbf{68.19\%}68.19%的执行准确性,如表2所示。即使在无需训练的设置下,它也达到了67.67%\mathbf{67.67\%}67.67%的良好性能,进一步突出了我们方法的有效性。
4.2.2 Spider 结果
如表3所示,仅在BIRD训练集上微调的SDE-SQL在Spider基准测试中取得了具有竞争力的结果,超过了基于GPT-4的方法和大多数开源模型,
| 方法 | 简单 | 中等 | 具有挑战性 | 所有 |
|---|---|---|---|---|
| SDE-SQL + Qwen2.5-72B-Instruct | 74.92\mathbf{74.92}74.92 | 57.76\mathbf{57.76}57.76 | 53.10\mathbf{53.10}53.10 | 67.67\mathbf{67.67}67.67 |
| w/o Soft Schema Linker | 73.51 | 58.84 | 50.34 | 66.88↓0.7966.88_{\downarrow 0.79}66.88↓0.79 |
| w/o Exploration Before Generation | 72.97 | 56.46 | 48.97 | 65.71↓1.9665.71_{\downarrow 1.96}65.71↓1.96 |
| w/o Refinement Module | 72.97 | 55.60 | 48.97 | 65.45↓2.2265.45_{\downarrow 2.22}65.45↓2.22 |
| w/o Exploration in Refinement | 72.86 | 56.68 | 51.72 | 65.97↓1.7065.97_{\downarrow 1.70}65.97↓1.70 |
| w/o Target Checking | 73.19 | 57.76 | 49.66 | 66.30↓1.3766.30_{\downarrow 1.37}66.30↓1.37 |
| w/o Exploration in Generation & Refinement | 72.11 | 54.31 | 48.28 | 64.47↓3.2064.47_{\downarrow 3.20}64.47↓3.20 |
| SDE-SQL + Fine-tuned Explorer | 74.16 | 59.26 | 55.17 | 67.86↑0.1967.86_{\uparrow 0.19}67.86↑0.19 |
| SDE-SQL + Fine-tuned Generator | 74.49 | 58.19 | 55.86 | 67.80↑0.1367.80_{\uparrow 0.13}67.80↑0.13 |
| SDE-SQL + Fine-tuned Explorer & Generator | 74.70\mathbf{74.70}74.70 | 58.84\mathbf{58.84}58.84 | 56.55\mathbf{56.55}56.55 | 68.19↑0.52\mathbf{68.19}_{\uparrow 0.52}68.19↑0.52 |
表1:SDE-SQL在BIRD开发集上的消融研究中的执行准确性。
| 方法 | dev(EX) |
|---|---|
| AskData + GPT-4o | 75.36\mathbf{75.36}75.36 |
| CHASE-SQL + Gemini | 74.46 |
| XiYan-SQL | 73.34 |
| OpenSearch-SQL, v2 + GPT-4o | 69.30 |
| CHESS | 68.31 |
| Distillery + GPT-4o | 67.21 |
| MCS-SQL | 63.36 |
| MAC-SQL + GPT-4 | 59.39 |
| DAIL-SQL + GPT-4 | 54.76 |
| DIN-SQL + GPT-4 | 50.72 |
| GPT-4 | 46.35 |
| DTS-SQL + DeepSeek-7B | 55.80 |
| SFT CodeS-15B | 58.47 |
| SQL-o1 + Llama3-8B | 63.4 |
| OneSQL-v0.1-Qwen-32B | 64.60 |
| XiYanSQL-QwenCoder-32B | 67.01 |
| Qwen2.5-72B-Instruct | 60.17 |
| SDE-SQL + Qwen2.5-72B-Instruct | 67.67\mathbf{67.67}67.67 |
| SDE-SQL (SFT) | 68.19\mathbf{68.19}68.19 |
表2:竞争模型在BIRD数据集上的实验结果。
这表明其强大的泛化能力。然而,性能增益相对较小,因为Spider数据集中大量的SQL查询会产生空执行结果,从而限制了数据库探索反馈的有效性。
4.3 消融研究
对于SDE-SQL中的每个模块,我们在BIRD基准的开发集上进行了消融研究,如表1所示。此外,我们还评估了将经过微调的探索器和生成器整合进流程中的效果。结果显示,每个组件都起着重要作用,特别是引入两个探索阶段带来了显著的性能提升。此外,各模块在其各自的子任务上微调后还可以进一步增强整个工作流的整体性能。
| 方法 | dev(EX) | test(EX) |
|---|---|---|
| SDE-SQL (SFT) | 87.5\mathbf{87.5}87.5 | 88.5\mathbf{88.5}88.5 |
| SDE-SQL + Qwen2.5-72B-Instruct | 87.3\mathbf{87.3}87.3 | 88.3\mathbf{88.3}88.3 |
| MAC-SQL + GPT-4 | 86.8 | 82.8 |
| SENSE-13B | 84.1 | 83.5 |
| SQL-o1 + Llama3-8B | 87.4 | 85.4 |
| DAIL-SQL + GPT-4 | 84.4 | 86.6 |
| ROUTE + Qwen2.5-14B | 87.3 | 87.1 |
| DIN-SQL + GPT-4 | 82.8 | 85.3 |
| GPT-4 (zero-shot) | 73.4 | - |
| Qwen2.5-72B-Instruct | 73.9 | 84.0 |
表3:竞争模型在Spider数据集上的实验结果。
5 结论
在这项工作中,我们提出了一种新颖的文本到SQL框架SDE-SQL,该框架将自我驱动探索整合到SQL生成和优化阶段。通过使LLM能够通过SQL探测主动与数据库交互,SDE-SQL弥合了静态查询生成与动态、基于执行的推理之间的差距。这种探索机制使LLM能够揭示潜在的模式语义和执行模式,显著提高了其生成可执行且语义准确的SQL查询的能力。在BIRD和Spider数据集上的广泛实验验证了SDE-SQL的有效性,该模型在监督微调后在BIRD上达到了68.19%\mathbf{68.19\%}68.19%的执行准确率。消融研究表明了关键组件的贡献,特别是探索流程和微调策略。未来的工作计划探索将探索信号更紧密地整合到模型训练中,以进一步加强模型的推理能力。
6 局限性
尽管自我驱动探索显著增强了大型语言模型在文本到SQL任务中的潜力,但我们目前的方法仍有一些局限性。在SDE-SQL中,数据库探索完全依赖于提示驱动,这意味着探索过程的有效性在很大程度上取决于手动设计提示的质量和设计。构造不良的提示可能导致模型生成无信息量或冗余的SQL探测,从而限制其获取有意义的模式知识或执行洞察力的能力。此外,仅依赖提示工程可能会限制模型基于环境反馈进行深度学习的能力。
另一个局限性是模型无法随着时间的推移自主完善其探索策略。由于每个SQL探测都是静态地从提示中生成的,模型无法根据探索过程中的先前成功或失败动态调整其行为。这种限制降低了系统的整体灵活性和学习效率。
为了解决这些问题,未来的工作将着重于使数据库探索更加内在于模型本身。一个有前途的方向是引入强化学习或其他基于反馈的学习范式,允许模型根据执行结果迭代改进其探测策略。通过使模型能够从与数据库的自身交互中学习,我们希望开发出一种更强大、适应性强的框架,能够在复杂的数据库环境中进行更深层次的情境感知推理。
参考文献
Ruichu Cai, Jinjie Yuan, Boyan Xu, and Zhifeng Hao. 2022. Sadga: Structure-aware dual graph aggregation network for text-to-sql. Preprint, arXiv:2111.00653.
Ruisheng Cao, Lu Chen, Zhi Chen, Yanbin Zhao, Su Zhu, and Kai Yu. 2021. Lgesql: Line graph enhanced text-to-sql model with mixed local and nonlocal relations. Preprint, arXiv:2106.01093.
Xiaojun Chen, Tianle Wang, Tianhao Qiu, Jianbin Qin, and Min Yang. 2024. Open-sql framework: Enhancing text-to-sql on open-source large language models. Preprint, arXiv:2405.06674.
DongHyun Choi, Myeong Cheol Shin, EungGyun Kim, and Dong Ryeol Shin. 2020. Ryansql: Recur-
sively applying sketch-based slot fillings for complex text-to-sq1 in cross-domain databases. Preprint, arXiv:2004.03125.
Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. 2023. Text-to-sql empowered by large language models: A benchmark evaluation. Preprint, arXiv:2308.15363.
Yingqi Gao, Yifu Liu, Xiaoxia Li, Xiaorong Shi, Yin Zhu, Yiming Wang, Shiqi Li, Wei Li, Yuntao Hong, Zhiling Luo, Jinyang Gao, Liyu Mou, and Yu Li. 2025. A preview of xiyan-sql: A multi-generator ensemble framework for text-to-sql. Preprint, arXiv:2411.08599.
Jiaqi Guo, Zecheng Zhan, Yan Gao, Yan Xiao, Jian-Guang Lou, Ting Liu, and Dongmei Zhang. 2019. Towards complex text-to-sql in cross-domain database with intermediate representation. Preprint, arXiv:1905.08205.
Zijin Hong, Zheng Yuan, Hao Chen, Qinggang Zhang, Feiran Huang, and Xiao Huang. 2024. Knowledge-to-sql: Enhancing sql generation with data expert llm. Preprint, arXiv:2402.11517.
Binyuan Hui, Xiang Shi, Ruiying Geng, Binhua Li, Yongbin Li, Jian Sun, and Xiaodan Zhu. 2021. Improving text-to-sql with schema dependency learning. Preprint, arXiv:2103.04399.
Wonseok Hwang, Jinyaong Yim, Seunghyun Park, and Minjoon Seo. 2019. A comprehensive exploration on wikisql with table-aware word contextualization. Preprint, arXiv:1902.01069.
Dongjun Lee, Choongwon Park, Jaehyuk Kim, and Heesoo Park. 2024. Mcs-sql: Leveraging multiple prompts and multiple-choice selection for text-to-sql generation. Preprint, arXiv:2405.07467.
Fangyu Lei, Jixuan Chen, Yuxiao Ye, Ruisheng Cao, Dongchan Shin, Hongjin Su, Zhaoqing Suo, Hongcheng Gao, Wenjing Hu, Pengcheng Yin, Victor Zhong, Caiming Xiong, Ruoxi Sun, Qian Liu, Sida Wang, and Tao Yu. 2025. Spider 2.0: Evaluating language models on real-world enterprise text-to-sql workflows. Preprint, arXiv:2411.07763.
Haoyang Li, Jing Zhang, Hanbing Liu, Ju Fan, Xiaokang Zhang, Jun Zhu, Renjie Wei, Hongyan Pan, Cuiping Li, and Hong Chen. 2024. Codes: Towards building open-source language models for text-to-sql. Preprint, arXiv:2402.16347.
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Rongyu Cao, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin C. C. Chang, Fei Huang, Reynold Cheng, and Yongbin Li. 2023. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sq1s. Preprint, arXiv:2305.03111.
Xiping Liu and Zhao Tan. 2023. Divide and prompt: Chain of thought prompting for text-to-sql. Preprint, arXiv:2304.11556.
OpenAI, :, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weliłinda, Alan Hayes, Alec Radford, Aleksander Madry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov, Alexi Christakis, Alexis Conneau, Ali Kamali, Allan Jabri, Allison Moyer, Allison Tam, Amadou Crookes, Amin Tootoochian, Amin Tootoonchian, Ananya Kumar, Andrea Vallone, Andrej Karpathy, Andrew Braunstein, Andrew Cann, Andrew Codispoti, Andrew Galu, Andrew Kondrich, Andrew Tulloch, Andrey Mishchenko, Angela Baek, Angela Jiang, Antoine Pelisse, Antonia Woodford, Anuj Gosalia, Arka Dhar, Ashley Pantuliano, Avi Nayak, Avital Oliver, Barret Zoph, Behrooz Ghorbani, Ben Leimberger, Ben Rossen, Ben Sokolowsky, Ben Wang, Benjamin Zweig, Beth Hoover, Blake Samic, Bob McGrew, Bobby Spero, Bogo Giertler, Bowen Cheng, Brad Lightcap, Brandon Walkin, Brendan Quinn, Brian Guarraci, Brian Hsu, Bright Kellogg, Brydon Eastman, Camillo Lugaresi, Carroll Wainwright, Cary Bassin, Cary Hudson, Casey Chu, Chad Nelson, Chak Li, Chan Jun Shern, Channing Conger, Charlotte Barette, Chelsea Voss, Chen Ding, Cheng Lu, Chong Zhang, Chris Beaumont, Chris Hallacy, Chris Koch, Christian Gibson, Christina Kim, Christine Choi, Christine McLeavey, Christopher Hesse, Claudia Fischer, Clemens Winter, Coley Czarnecki, Colin Jarvis, Colin Wei, Constantin Koumouzelis, Dane Sherburn, Daniel Kappler, Daniel Levin, Daniel Levy, David Carr, David Farhi, David Mely, David Robinson, David Sasaki, Denny Jin, Dev Valladares, Dimitris Tsipras, Doug Li, Duc Phong Nguyen, Duncan Findlay, Edede Oiwoh, Edmund Wong, Ehsan Asdar, Elizabeth Proehl, Elizabeth Yang, Eric Antonow, Eric Kramer, Eric Peterson, Eric Sigler, Eric Wallace, Eugene Brevdo, Evan Mays, Farzad Khorasani, Felipe Petroski Such, Filippo Raso, Francis Zhang, Fred von Lohmann, Freddie Sulit, Gabriel Goh, Gene Oden, Geoff Salmon, Giulio Starace, Greg Brockman, Hadi Salman, Haiming Bao, Haitang Hu, Hannah Wong, Haoyu Wang, Heather Schmidt, Heather Whitney, Heewoo Jun, Hendrik Kirchner, Henrique Ponde de Oliveira Pinto, Hongyu Ren, Huiwen Chang, Hyung Won Chung, Ian Kivlichan, Ian O’Connell, Ian O’Connell, Ian Osband, Ian Silber, Ian Sohl, Ibrahim Okuyucu, Ikai Lan, Ilya Kostrikov, Ilya Sutskever, Ingmar Kanitscheider, Ishaan Gulrajani, Jacob Coxon, Jacob Menick, Jakub Pachocki, James Aung, James Betker, James Crooks, James Lennon, Jamie Kiros, Jan Leike, Jane Park, Jason Kwon, Jason Phang, Jason Teplitz, Jason Wei, Jason Wolfe, Jay Chen, Jeff Harris, Jenia Varavva, Jessica Gan Lee, Jessica Shieh, Ji Lin, Jiahui Yu, Jiayi Weng, Jie Yang, Jieqi Yu, Joanne Jang, Joaquin Quinonero Candela, Joe Beutler, Joe Landers, Joel Parish, Johannes Heidecke, John Schulman, Jonathan Lachman, Jonathan McKay, Jonathan
Uesato, Jonathan Ward, Jong Wook Kim, Joost Huizinga, Jordan Sitkin, Jos Kraaijeveld, Josh Gross, Josh Kaplan, Josh Snyder, Joshua Achiam, Joy Jiao, Joyce Lee, Juntang Zhuang, Justyn Harriman, Kai Fricke, Kai Hayashi, Karan Singhal, Katy Shi, Kavin Karthik, Kayla Wood, Kendra Rimbach, Kenny Hsu, Kenny Nguyen, Keren Gu-Lemberg, Kevin Button, Kevin Liu, Kiel Howe, Krithika Muthukumar, Kyle Luther, Lama Ahmad, Larry Kai, Lauren Itow, Lauren Workman, Leher Pathak, Leo Chen, Li Jing, Lia Guy, Liam Fedus, Liang Zhou, Lien Mamitsuka, Lilian Weng, Lindsay McCallum, Lindsey Held, Long Ouyang, Louis Feuvrier, Lu Zhang, Lukas Kondraciak, Lukasz Kaiser, Luke Hewitt, Luke Metz, Lyric Doshi, Mada Aflak, Maddie Simens, Madelaine Boyd, Madeleine Thompson, Marat Dukhan, Mark Chen, Mark Gray, Mark Hudnall, Marvin Zhang, Marwan Aljubeh, Mateusz Litwin, Matthew Zeng, Max Johnson, Maya Shetty, Mayank Gupta, Meghan Shah, Mehmet Yatbaz, Meng Jia Yang, Mengchao Zhong, Mia Glaese, Mianna Chen, Michael Janner, Michael Lampe, Michael Petrov, Michael Wu, Michele Wang, Michelle Fradin, Michelle Pokrass, Miguel Castro, Miguel Oom Temudo de Castro, Mikhail Pavlov, Miles Brundage, Miles Wang, Minal Khan, Mira Murati, Mo Bavarian, Molly Lin, Murat Yesildal, Nacho Soto, Natalia Gimelshein, Natalie Cone, Natalie Staudacher, Natalie Summers, Natan LaFontaine, Neil Chowdhury, Nick Ryder, Nick Stathas, Nick Turley, Nik Tezak, Niko Felix, Nithanth Kudige, Nitish Keskar, Noah Deutsch, Noel Bundick, Nora Puckett, Ofir Nachum, Ola Okelola, Oleg Boiko, Oleg Murk, Oliver Jaffe, Olivia Watkins, Olivier Godement, Owen Campbell-Moore, Patrick Chao, Paul McMillan, Pavel Belov, Peng Su, Peter Bak, Peter Bakkum, Peter Deng, Peter Dolan, Peter Hoeschele, Peter Welinder, Phil Tillet, Philip Pronin, Philippe Tillet, Prafulla Dhariwal, Qiming Yuan, Rachel Dias, Rachel Lim, Rahul Arora, Rajan Troll, Randall Lin, Rapha Gontijo Lopes, Raul Puri, Reah Miyara, Reimar Leike, Renaud Gaubert, Reza Zamani, Ricky Wang, Rob Donnelly, Rob Honsby, Rocky Smith, Rohan Sahai, Rohit Ramchandani, Romain Huei, Rory Carmichael, Rowan Zellers, Roy Chen, Ruby Chen, Ruslan Nigmatullin, Ryan Cheu, Saachi Jain, Sam Altman, Sam Schoenholz, Sam Toizer, Samuel Miserendino, Sandhini Agarwal, Sara Culver, Scott Ethersmith, Scott Gray, Sean Grove, Sean Metzger, Shamez Hermani, Shantanu Jain, Shengjia Zhao, Sherwin Wu, Shino Jomoto, Shirong Wu, Shuaiqi, Xia, Sonia Phene, Spencer Papay, Srinivas Narayanan, Steve Coffey, Steve Lee, Stewart Hall, Suchir Balaji, Tal Broda, Tal Stramer, Tao Xu, Tarun Gogineni, Taya Christianson, Ted Sanders, Tejal Patwardhan, Thomas Cunningham, Thomas Degry, Thomas Dimson, Thomas Raoux, Thomas Shadwell, Tianhao Zheng, Todd Underwood, Todor Markov, Toki Sherbakov, Tom Rubin, Tom Stasi, Tomer Kaftan, Tristan Heywood, Troy Peterson, Tyce Walters, Tyna Eloundou, Valerie Qi, Veit Moeller, Vinnie Monaco, Vishal Kuo, Vlad Fomenko, Wayne Chang, Weiyi Zheng, Wenda Zhou, Wesam Manasea, Will Sheu, Wojciech Zaremba, Yash Patil, Yilei Qian, Yongjik Kim, Youlong Cheng, Yu Zhang, Yuchen
He, Yuchen Zhang, Yujia Jin, Yunxing Dai, and Yury Malkov. 2024. Gpt-4o system card. Preprint, arXiv:2410.21276.
Mohammadreza Pourreza, Hailong Li, Ruoxi Sun, Yeounoh Chung, Shayan Talaei, Gaurav Tarlok Kakkar, Yu Gan, Amin Saberi, Fatma Ozcan, and Sercan O. Arik. 2024a. Chase-sql: Multi-path reasoning and preference optimized candidate selection in text-to-sql. Preprint, arXiv:2410.01943.
Mohammadreza Pourreza and Davood Rafiei. 2023. Din-sql: Decomposed in-context learning of text-tosql with self-correction. Preprint, arXiv:2304.11015.
Mohammadreza Pourreza and Davood Rafiei. 2024. Dts-sql: Decomposed text-to-sql with small large language models. arXiv preprint arXiv:2402.01117.
Mohammadreza Pourreza, Ruoxi Sun, Hailong Li, Lesly Miculicich, Tomas Pfister, and Sercan O. Arik. 2024b. Sql-gen: Bridging the dialect gap for text-to-sql via synthetic data and model merging. Preprint, arXiv:2408.12733.
Nitarshan Rajkumar, Raymond Li, and Dzmitry Bahdanau. 2022. Evaluating the text-to-sql capabilities of large language models. Preprint, arXiv:2204.00498.
Jiawei Shen, Chengcheng Wan, Ruoyi Qiao, Jiazhen Zou, Hang Xu, Yuchen Shao, Yueling Zhang, Weikai Miao, and Geguang Pu. 2025. A study of in-context-learning-based text-to-sql errors. Preprint, arXiv:2501.09310.
Ruoxi Sun, Sercan Ö. Arik, Alex Muzio, Lesly Miculicich, Satya Gundabathula, Pengcheng Yin, Hanjun Dai, Hootan Nakhost, Rajarishi Sinha, Zifeng Wang, and Tomas Pfister. 2024. Sql-palm: Improved large language model adaptation for text-to-sql (extended). Preprint, arXiv:2306.00739.
Chang-You Tai, Ziru Chen, Tianshu Zhang, Xiang Deng, and Huan Sun. 2023. Exploring chain-ofthought style prompting for text-to-sql. Preprint, arXiv:2305.14215.
Shayan Talaei, Mohammadreza Pourreza, Yu-Chen Chang, Azalia Mirhoseini, and Amin Saberi. 2024. Chess: Contextual harnessing for efficient sql synthesis. Preprint, arXiv:2405.16755.
Bailin Wang, Richard Shin, Xiaodong Liu, Oleksandr Polozov, and Matthew Richardson. 2020. RAT-SQL: Relation-aware schema encoding and linking for text-to-SQL parsers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7567-7578, Online. Association for Computational Linguistics.
Bing Wang, Changyu Ren, Jian Yang, Xinnian Liang, Jiaqi Bai, LinZheng Chai, Zhao Yan, Qian-Wen Zhang, Di Yin, Xing Sun, and Zhoujun Li. 2025. Mac-sql: A multi-agent collaborative framework for text-to-sql. Preprint, arXiv:2312.11242.
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. Chain-of-thought prompting elicits reasoning in large language models. Preprint, arXiv:2201.11903.
Wenxuan Xie, Gaochen Wu, and Bowen Zhou. 2024. Mag-sql: Multi-agent generative approach with soft schema linking and iterative sub-sql refinement for text-to-sql. Preprint, arXiv:2408.07930.
Xiaojun Xu, Chang Liu, and Dawn Song. 2017. Sqlnet: Generating structured queries from natural language without reinforcement learning. Preprint, arXiv:1711.04436.
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. 2019. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. Preprint, arXiv:1809.08887.
John M. Zelle and Raymond J. Mooney. 1996. Learning to parse database queries using inductive logic programming. In Proceedings of the Thirteenth National Conference on Artificial Intelligence - Volume 2, AAAI’96, page 1050-1055. AAAI Press.
Hanchong Zhang, Ruisheng Cao, Hongshen Xu, Lu Chen, and Kai Yu. 2024a. Coe-sql: In-context learning for multi-turn text-to-sql with chain-ofeditions. Preprint, arXiv:2405.02712.
Tingkai Zhang, Chaoyu Chen, Cong Liao, Jun Wang, Xudong Zhao, Hang Yu, Jianchao Wang, Jianguo Li, and Wenhui Shi. 2024b. Sqlfuse: Enhancing text-tosql performance through comprehensive llm synergy. Preprint, arXiv:2407.14568.
A 错误原因示例

图5:条件冲突的一个例子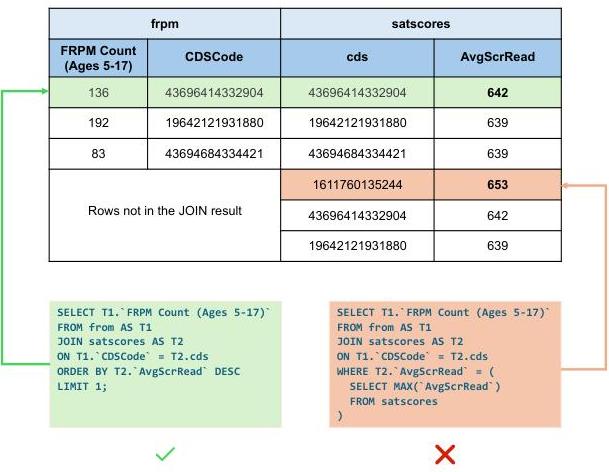
图6:子查询范围不一致的一个例子
B 目标检查模块
目标检查模块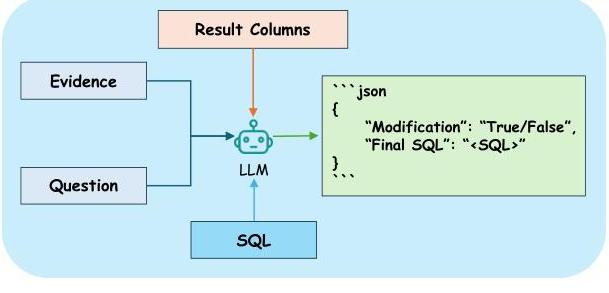
图7:目标检查模块
C 训练设置
| 参数 | 值 |
|---|---|
| per_device_train_batch_size | 1 |
| gradient_accumulation_steps | 8 |
| learning_rate | 1.0e−41.0 \mathrm{e}-41.0e−4 |
| num_train_epochs | 2.0 |
| lr_scheduler_type | cosine |
| lora_rank | 16 |
表4:训练超参数配置。
D 图表

图8:错误原因识别阶段的SQL探测
E 在无需训练设置下SDE-SQL使用的提示
对于不依赖监督训练的方法来说,精心设计和制定提示模板变得尤为重要,这些模板能够有效地引导模型在受控和有意义的方式下进行自我驱动探索行为。在本节中,我们提供了一套全面的提示模板,这些模板将在SDE-SQL流水线的不同阶段使用以支持这一能力。由于可用空间的限制,某些详细元素和具体的提示示例已被省略,但保留了基本结构和核心思想。
[指令]
您的任务是生成一系列SQL探测以探索数据库并识别问题中提到的正确列。这些探测将有助于确定哪些列包含必要的数据,并确保最终的SQL查询返回非空结果。请遵循以下要求:
[要求]
-
在这项任务中,您应识别并列出问题中提到的所有实体及其在数据库模式中的对应候选列。对于每个实体,除非数据库模式中包含多个相同或非常相似的意义一致的列,否则每个实体只有一个候选列。不要包含不必要的列为候选列。对于每个实体,如果它对应多个候选列,请生成SQL探测以检查每个候选列中是否存在相关值。如果某个实体提到了特定值(例如,“Mountain View”地区或入学人数 > 500),请生成SQL探测以验证候选列中是否存在该值。 - 问题中的实体分为两种类型:目标实体和条件实体。目标实体是查询的最终目标,而条件实体对应目标实体需要满足的条件。首先,您需要根据目标实体生成相应的基础SQL探测。然后,针对每个条件实体,基于基础SQL探测生成相应的条件SQL探测。基础SQL探测:首先生成用于搜索目标实体的基础SQL探测。所有其他SQL探测应基于此基础SQL探测生成。
-
条件SQL探测:基于基础SQL探测为每个条件实体生成SQL探测。
-
[注意]
-
- 如果[Evidence]指定了实体的候选列或候选值,请直接使用该列或值作为实体的映射,前提是[Evidence]合理且无需探索其他候选。如果[Evidence]中存在实体的计算公式,请优先使用此公式表示实体。这一点非常重要!!!
-
- 您不需要考虑结合多个条件的SQL探测。
-
- 基础SQL探测应仅选择目标而不带其他条件。
-
- 条件SQL探测将在基础SQL探测基础上添加新条件。
-
[注释]
-
[SQL技巧]
-
[数据库管理员指令]
-
[输出格式]
-
・.
图9:候选探索的提示模板
[指令]
提供给您的问题可以分解为目标和若干条件。此前,基于目标和条件生成了一系列SQL探测。其中,基础SQL探测是为目标生成的,而其他SQL探测是在基础SQL探测基础上增加探索特定条件生成的。我将为您提供这些SQL探测及其相应的执行结果(是否为空)。您需要做的是根据数据库模式和问题结合条件生成一系列新的SQL探测。这将有助于更深入地探索数据库,并帮助我生成问题的最终SQL。
[要求] -
执行结果可以是两种结果之一:NULL或Not NULL。!!!NULL意味着SQL查询的结果为空(没有数据匹配条件)。Not NULL意味着SQL查询的结果不为空(有数据匹配条件)!!!
-
- 您需要分析当前的执行结果,排除明显无效的候选列,只组合可能有效的列。
-
- 您需要结合所有条件以确保全面探索。例如,假设当前问题包含一个目标和三个条件。在分析执行结果后,候选列如下:基础SQL探测可以从目标确定唯一的候选列,第一个条件有两个可能的候选列,第二个条件有一个可能的候选列,第三个条件有三个可能的候选列。因此,组合后需要生成的SQL探测数量将是1 * 2 * 1 * 3=63=63=6。
-
[提示]
-
・.
-
[输出格式]
-
・.
图10:组合探索的提示模板
任务描述
您是一名SQLite数据库专家,任务是根据输入的用户问题生成SQL查询。
您将获得:
- 输入的用户问题,可能还有证据
-
- 数据库模式
-
- 列的描述(列名、数据格式、描述)
-
- 从数据库中检索到的值
-
- SQL探测结果
您的任务是生成正确的SQL查询。输入问题由查询目标和目标需要满足的条件组成。您需要分析问题的语义并将其转换为相应的SQL。您应该模仿人类,并逐步解决此任务。
注意事项
…
SQL技巧
…
数据库管理员指令
…
输出格式
…
图11:零样本生成的提示模板
[指令]
执行SQL语句时,可能会出现执行结果完全为空的情况。
您需要根据查询和数据库信息识别错误原因,并生成一些新的探测SQL以寻找解决方案。
为了帮助您找出原因,我从这条错误SQL中提取了一批探测SQL并执行了它们,向您提供了执行结果(NULL或Not NULL)。!!!NULL意味着SQL查询的结果为空(没有数据匹配条件)。Not NULL意味着SQL查询的结果不为空(有数据匹配条件)!!! 您可以根据这些探测SQL查询结果是否为空来确定问题所在。
修改后的SQL必须与查询一致,并且不应遗漏查询中描述的任何必要条件。
[可能原因]
原因1:不同列之间的冲突条件或冗余描述
–详情:两个条件的同时存在导致空,证明其中一个条件的列选择错误。冗余:对于某个条件,使用多个不同的列重复描述,导致此条件与其他条件冲突。
–修复:对于冲突情况,显然,一个条件可能由几个意义相似的列描述,但在SQL中选择了错误的列。要解决此问题,请识别并替换列名。对于冗余情况,删除同一条件的重复描述,保留最合适的那个。
原因2:条件值错误或大小写敏感性问题
–详情:查询中的条件可能使用了错误的值,或在比较字符串时不考虑大小写敏感性。
–修复:尝试使用LIKE,因为LIKE关键字默认是大小写不敏感的。(table. = ‘xxx’ -> table. LIKE ‘xxx’)
原因3:不必要的表连接导致没有满足条件的记录
–详情:查询可能包含不必要的表连接,导致最终交集中没有记录满足条件。
–修复:检查每个表连接是否确实必要,并丢弃不必要的表。
原因4:错误的列选择
–详情:在涉及的多个表中,某个条件可能有多个候选列,但旧SQL选择了错误的列。
–修复:确定是否有更适合的列,或使用另一张表中的类似列。
原因5:MAX(MIN)函数或ORDER BY的误用
–详情:在子查询(嵌套SQL)中使用MAX(MIN)函数或ORDER BY,对应最大或最小值的数据可能不在两张表的交集中,所以可能返回空值。
–修复:首先JOIN表,然后在JOIN结果上使用MAX(MIN)函数或ORDER BY。
[要求]
在逐步思考之后,您可能已经对错误原因有一些猜测和潜在解决方案,但您需要验证这些猜测和解决方案。请根据您的分析生成一组探测SQL以帮助未来的自己得出正确的SQL。
图12:解决方案探索的提示模板
[指令]
执行SQL语句时,可能会出现执行结果完全为空的情况。
您需要根据查询和数据库信息识别错误原因并进行必要的更正。
为了帮助您找出原因,我执行了一系列与此问题相关的SQL,向您提供了执行结果(NULL或Not NULL)。!!!NULL意味着SQL查询的结果为空(没有数据匹配条件)。Not NULL意味着SQL查询的结果不为空(有数据匹配条件)!!!
您可以使用这些探测SQL查询结果来确定问题所在,基于它们是否为空。
请注意,您修改后的SQL仍必须与查询中的目标和条件一一对应。
[可能原因]
原因1:不同列之间的冲突条件或冗余描述
–详情:两个条件的同时存在导致空,证明其中一个条件的列选择错误。冗余:对于某个条件,使用多个不同的列重复描述,导致此条件与其他条件冲突。
–修复:对于冲突情况,显然,一个条件可能由几个意义相似的列描述,但在SQL中选择了错误的列。要解决此问题,请识别并替换列名。
对于冗余情况,删除同一条件的重复描述,保留最合适的那个。
原因2:条件值错误或大小写敏感性问题
–详情:查询中的条件可能使用了错误的值,或在比较字符串时不考虑大小写敏感性。
–修复:尝试使用LIKE,因为LIKE关键字默认是大小写不敏感的。(table. = ‘xxx’ -> table. LIKE ‘xxx’)
原因3:不必要的表连接导致没有满足条件的记录
–详情:查询可能包含不必要的表连接,导致最终交集中没有记录满足条件。
–修复:检查每个表连接是否确实必要,并丢弃不必要的表。
原因4:错误的列选择,没有匹配的值
–详情:查询可能选择了错误的列或该列可能没有任何满足条件的值。
–修复:确定是否有更适合的列,或使用另一张表中的类似列。
原因5:MAX(MIN)函数或ORDER BY的误用
–详情:在子查询(嵌套SQL)中使用MAX(MIN)函数或ORDER BY,对应最大或最小值的数据可能不在两张表的交集中,所以可能返回空值。
–修复:首先JOIN表,然后在JOIN结果上使用MAX(MIN)函数和ORDER BY,而不是在子查询(嵌套查询)中使用。
图13:最终优化的提示模板
[指令]
您是一个乐于助人的助手。给定一个问题、一条SQL语句和可能的相关证据,您需要确定此SQL和问题的查询目标是否一致。
[要求]
- 首先,您需要识别问题试图查询的实际实体(目标列)。
-
- 确定问题期望在结果中看到多少列。
-
- 比较SQL查询返回的列数与期望的列数,以确定是否选择了多余的列。
-
- 如果选择了多余的列,您需要修改原SQL语句中SELECT关键字后的目标,以去除不必要的目标列。如果您认为所选列是正确的或不足的,则无需修改。
-
- 您的输出应为JSON格式:
-
`json - {{
-
"Modification":"<True or False>", -
"Final SQL":"<sql>"
10.}}.
[示例]
…
[注意]
只有在您绝对确定有多余的目标列时才进行修改。如果您觉得没有问题或不确定是否有问题,则不要做出任何更改。
图14:目标检查的提示模板
参考论文:https://arxiv.org/pdf/2506.07245

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)