【AI论文】MinMo:一种用于无缝语音交互的多模态大型语言模型
MinMo的模型架构如图3所示,主要包括语音编码器、输入投影器、大型语言模型(LLM)、语音令牌语言模型(Voice Token LM)、输出投影器、令牌到波形(Token2Wav)合成器以及全双工预测器。语音编码器:采用预训练的SenseVoice-large编码器模块,提供强大的语音理解能力,支持多语种语音识别、情感识别和音频事件检测。输入投影器:由两层Transformer和一个CNN层组成
摘要:近年来,大型语言模型(LLMs)和多模态语音-文本模型取得了最新进展,为无缝语音交互奠定了基础,实现了实时、自然且类似人类的对话。以往的语音交互模型分为原生型和对齐型两种。原生型模型在一个框架中集成了语音和文本处理,但在处理序列长度不同和预训练不足等问题时存在困难。对齐型模型保持了文本大型语言模型的功能,但往往受到数据集规模小和语音任务关注范围狭窄的限制。在本文中,我们介绍了MinMo,一种具有约80亿参数的多模态大型语言模型,用于无缝语音交互。我们解决了以往对齐型多模态模型的主要局限性。我们通过多个阶段的语音到文本对齐、文本到语音对齐、语音到语音对齐和双向交互对齐,对MinMo进行了训练,训练数据包括140万小时的多样化语音数据和广泛的语音任务。经过多阶段训练后,MinMo在语音理解和生成的各种基准测试中取得了最先进的性能,同时保持了文本大型语言模型的功能,还促进了全双工对话,即用户和系统之间的同时双向通信。此外,我们提出了一种新颖且简单的语音解码器,其在语音生成方面优于以往的模型。MinMo增强的指令遵循能力支持根据用户指令控制语音生成,包括各种细微差别,如情绪、方言、语速以及模仿特定声音。对于MinMo,语音到文本的延迟约为100毫秒,理论上的全双工延迟约为600毫秒,实际中约为800毫秒。MinMo项目网页为:https://funaudiollm.github.io/minmo,代码和模型将很快发布。Huggingface链接:Paper page,论文链接:2501.06282
1. 引言
近年来,大型语言模型(LLMs)和多模态语音-文本模型的快速发展为无缝语音交互提供了坚实的基础。无缝语音交互指的是用户与系统之间能够进行实时、自然、相关且类似人类的对话。然而,实现这一目标面临诸多挑战,包括系统需要准确全面地理解音频内容,包括内容理解和音频事件识别;系统需要生成自然且有表现力的语音响应;系统应针对用户请求提供合理且相关的响应,就像一个智能聊天机器人;同时,系统还应支持全双工对话,即用户和系统之间的同时双向通信。
MinMo是一种针对无缝语音交互设计的多模态大型语言模型,拥有约80亿参数。它旨在解决现有对齐型多模态模型的局限性,通过在大规模语音数据上进行多阶段训练,MinMo在语音理解和生成方面实现了最先进的性能,同时保留了文本LLMs的能力,并支持全双工对话。
2. MinMo模型概述
2.1 模型架构
MinMo的模型架构如图3所示,主要包括语音编码器、输入投影器、大型语言模型(LLM)、语音令牌语言模型(Voice Token LM)、输出投影器、令牌到波形(Token2Wav)合成器以及全双工预测器。
- 语音编码器:采用预训练的SenseVoice-large编码器模块,提供强大的语音理解能力,支持多语种语音识别、情感识别和音频事件检测。
- 输入投影器:由两层Transformer和一个CNN层组成,用于维度对齐和降采样。
- 大型语言模型(LLM):采用预训练的Qwen2.5-7B-instruct模型,因其在各种基准测试中的出色表现而被选中。
- 语音令牌语言模型(Voice Token LM):基于预训练的CosyVoice2 LM模块,自回归地生成语音令牌。
- 输出投影器:一个单层线性模块,用于维度对齐。
- 令牌到波形(Token2Wav)合成器:包括一个基于流的匹配模型和一个声码器,能够将语音令牌合成为波形。
- 全双工预测器:由一层Transformer和一个线性softmax输出层组成,用于实时预测是否响应用户命令或暂停当前系统广播以处理用户输入。
2.2 语音解码器
MinMo引入了一种新颖的语音解码器,将LLM的文本输出转换为语音。该解码器包括输出投影器、语音令牌语言模型(Voice Token LM)和流令牌到波形(Token2Wav)合成器。输出投影器对齐LLM与语音解码器的维度,语音令牌语言模型自回归地生成语音令牌,而令牌到波形合成器则将语音令牌合成为波形。
2.3 训练数据和任务
MinMo的训练数据涵盖了超过140万小时的语音数据,包括语音到文本、文本到语音、语音到语音以及语音到控制令牌等多种任务。具体任务和数据规模如表2所示。
- 语音到文本任务:包括自动语音识别(ASR)、语音到文本翻译(S2TT)、语言识别(LID)等,总时长约120万小时。
- 文本到语音任务:包括基本的语音合成数据和受指令控制的语音生成数据,总时长约17万小时。
- 语音到语音任务:包括多轮对话语音和受风格控制的对话语音,总时长约1万小时。
- 语音到控制令牌任务:包括从现有真实语音交互数据中提取的数据和通过文本对话数据模拟的数据,总时长约4000小时。
3. 模型训练
MinMo通过四个阶段的对齐训练来逐步获得音频理解和生成能力,同时保留文本LLM的能力:
3.1 语音到文本对齐
该阶段使用语音到文本数据对齐音频模态的输入潜在空间和预训练文本LLM的语义空间。训练过程包括预对齐(Pre-align)和全对齐(Full-align)两个阶段,以及随后的指令微调(SFT)。
3.2 文本到语音对齐
该阶段使用文本到语音数据对齐文本LLM的语义空间与音频模态的输出潜在空间。首先训练输出投影器,然后联合训练输出投影器和语音令牌语言模型,同时保持MinMo的其他参数冻结。
3.3 语音到语音对齐
该阶段继续使用约1万小时的配对音频数据训练MinMo,主要更新输出投影器和语音令牌语言模型。训练数据包括一般语音到语音对话和受风格控制的对话语音。
3.4 双工交互对齐
在完成前三个训练阶段后,MinMo获得了音频理解、音频生成和半双工语音对话能力。在此基础上,通过训练全双工预测器模块来进一步支持全双工对话。全双工预测器利用LLM的语义理解能力来决定是否需要生成响应,或暂停当前输出以处理用户输入。
4. 实验与评估
4.1 语音识别和翻译
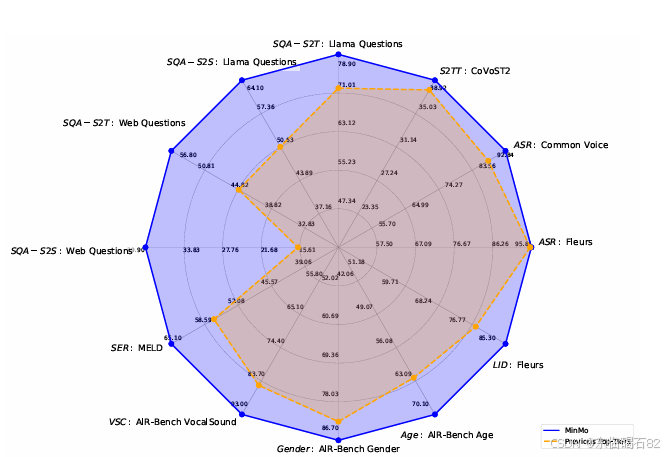
MinMo在语音识别和翻译任务上表现出色,特别是在多语种语音识别和多语种语音翻译方面。表5和表6展示了MinMo在公共测试集上的性能,包括字符错误率(CER)和词错误率(WER)。
- 多语种语音识别:MinMo在多种语言上均取得了优于基线模型的结果,特别是在中文、英文和日文等语言上。
- 多语种语音翻译:MinMo在中文↔英文和日文↔英文翻译上取得了最先进的性能,在其他语言对上也表现出色。
4.2 语音分析和理解
MinMo在语音情感识别、音频事件理解和说话人分析等任务上也表现出色。表11、表12和表13展示了MinMo在这些任务上的性能。
- 语音情感识别:MinMo在多个情感识别数据集上取得了高准确率,特别是在中文和英文数据集上。
- 音频事件理解:MinMo在音频事件理解任务上超越了所有基线模型,特别是在语音声音分类任务上。
- 说话人分析:MinMo在性别检测和年龄估计任务上均取得了优于基线模型的结果。
4.3 语音到文本增强
MinMo在口语平滑、标点符号插入和逆文本规范化等任务上也表现出色。表15和表16展示了MinMo在这些任务上的性能。
- 口语平滑:MinMo在口语平滑任务上取得了较高的BLEU、ROUGE和BLEURT分数,同时在人类和LLM评估中也获得了较高的保真度和正式度分数。
- 标点符号插入和逆文本规范化:MinMo在标点符号插入和逆文本规范化任务上均取得了优于基线模型的结果。
4.4 语音生成
MinMo在文本到语音和受指令控制的语音生成任务上也表现出色。表17和表18展示了MinMo在这些任务上的性能。
- 文本到语音:MinMo在文本到语音任务上取得了与基线模型相当的内容一致性和语音质量。
- 受指令控制的语音生成:MinMo在受指令控制的语音生成任务上取得了高准确率,特别是在情感、方言、语速和角色扮演等控制方面。
4.5 语音聊天
MinMo在语音问答和语音对话任务上也表现出色。表19和表20展示了MinMo在这些任务上的性能。
- 语音问答:MinMo在语音问答任务上取得了优于基线模型的结果,特别是在语音到语音模式下。
- 语音对话:MinMo在语音对话任务上保持了与基线模型相当的逻辑推理能力和闲聊响应能力。
4.6 全双工对话
MinMo在全双工对话任务上也表现出色。表22和表23展示了MinMo在全双工对话任务上的性能和延迟。
- 预测性能:MinMo在助理轮次和用户轮次预测任务上均取得了高准确率,特别是在K=10时接近99%。
- 延迟分析:MinMo在全双工对话中的平均延迟约为600毫秒,在用户轮次预测中的平均延迟为250毫秒。
5. 结论
MinMo是一种用于无缝语音交互的多模态大型语言模型,通过在大规模语音数据上进行多阶段训练,MinMo在语音理解和生成方面实现了最先进的性能,同时保留了文本LLMs的能力,并支持全双工对话。MinMo的语音解码器在结构简单性和语音生成性能之间取得了平衡,同时增强了指令跟随能力,能够生成反映用户指定情感、方言和语速的细致语音。此外,MinMo还支持全双工对话,为用户提供了无缝的对话体验。然而,MinMo仍存在一些局限性,如指令跟随能力的改进、长尾发音错误问题以及音频生成效率的提升等。未来工作将进一步探索这些问题,并努力提升MinMo的性能和用户体验。
6. 局限性
尽管MinMo在无缝语音交互方面取得了显著进展,但仍存在一些局限性:
- 指令跟随能力:MinMo的文本大型模型仅参与LoRA更新,其遵循多样指令(如语言和任务跟随)的能力需要改进。未来工作将探索使用更多高质量文本数据进行更全面的更新,以提升指令跟随能力。
- 长尾发音错误:MinMo的端到端音频生成中存在一些长尾发音错误问题,部分原因是保留了一些LLM的一对多令牌,以及部分特殊符号无法有效转换为语音。未来工作将通过数据扩展来解决这些问题。
- 音频生成效率:MinMo中受指令控制的音频生成整体效率需要提高,部分原因是当前指令数据规模较小且仅使用隐藏嵌入进行端到端对齐,限制了历史信息的传输。未来工作将探索更高效的音频生成方法。
- 全双工对话:尽管MinMo实现了全双工对话功能,但其整体效率和用户体验仍有提升空间。未来工作将进一步优化全双工对话模块,以提升用户体验。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献228条内容
已为社区贡献228条内容

所有评论(0)