微调BERT模型实现文本分类
模型微调只是针对某种下游任务,针对性的强化模型的能力,但是微调之后的模型在泛化能力上有所下降。
bert-base-chinese
bert-base-chinese是一款基于 BERT(Bidirectional Encoder Representations from Transformers)架构的预训练语言模型,专为中文自然语言处理任务而设计。BERT 是 Google 于 2018 年推出的具有开创性的预训练模型,借助大规模无监督训练方式,得以学习到极为丰富的语言表示。bert-base-chinese是 BERT 在中文语料上完成预训练的版本,内部包含 12 层 Transformer 编码器,拥有 110 万个参数。该模型在海量中文文本上进行了大规模预训练,因此可广泛应用于各类中文自然语言处理任务,诸如文本分类、命名实体识别、情感分析等等。
在运用bert-base-chinese模型时,既能够将其当作特征提取器,把输入文本转化为固定长度的向量表示,随后将这些向量输入至其他机器学习模型中开展训练或推断;也能够对bert-base-chinese进行微调,使其适配特定任务的训练。预训练的bert-base-chinese模型可通过 Hugging Face 的 Transformers 库来加载与使用。模型加载完毕后,可利用其encode方法将文本转换为向量表示,或者运用forward方法针对文本进行特定任务的预测。需留意的是,bert-base-chinese属于通用型中文语言模型,在某些特定任务上或许难以展现出卓越性能。在部分情形下,可能需要采用更大规模的模型,亦或是进行微调操作,以此获取更为理想的性能表现。
本文就将介绍如何微调bert-base-chinese模型来实现文本分类。
bert-base-chinese文本分类
我们先来看看bert-base-chinese模型文本分类的效果。代码如下:
BertForSequenceClassification是transformers库中用于序列分类任务的一个类。它基于 BERT 模型进行构建,主要用于将输入的序列(比如文本)分类到不同的类别中。这里将他分到三个类别中。同时下载他的分词器来进行分词。以此来构建基础模型。
from transformers import BertTokenizer, BertForSequenceClassification, AutoModelForSequenceClassification, \
AutoTokenizer, pipeline
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=3)
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
classifier = pipeline('text-classification', model=model, tokenizer=tokenizer)
output = classifier('我今天心情很好')
print(output)
output = classifier('你好,我是AI助手')
print(output)
output = classifier('我今天很生气')
print(output)
输出如下: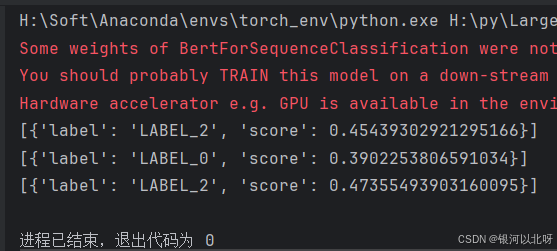
可以发现bert-base-chinese在实现文本分类的时候效果并不是很好。接下来,我们对该模型进行微调以实现文本分类。
bert-base-chinese微调
首先我们需要通过同样的方法来构建基础模型。然后通过语料样本来进行微调。这里我们使用lansinuote/ChnSentiCorp数据集。
lansinuote/ChnSentiCorp数据集是一个用于中文情感分析的数据集。该数据集汇集了来自网络平台的多样化评论数据,主要覆盖三大领域:酒店住宿体验、笔记本电脑使用评价以及书籍阅读感受。数据集分为训练集、验证集和测试集。其中,训练集包含约 9600 条数据,验证集和测试集各包含约 1200 条数据。每条数据包含一段评论文本和对应的情感标签,情感标签通常为二分类(如好评、差评),部分版本可能包含中性标签。
将lansinuote/ChnSentiCorp数据集下载之后,使用模型的分词器对其进行处理,将处理之后的数据放入模型进行训练,我们仅训练1轮看看效果。训练完之后再测试集上进行预测查看训练效果。并将模型保存。实现代码如下。
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
import re
from sklearn.metrics import accuracy_score
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
mode = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=3)
dataset = load_dataset('lansinuote/ChnSentiCorp')
def clean_text(text):
text = re.sub(r'[^\w\s]+', ' ', text)
text = text.strip()
return text
dataset = dataset.map(lambda x: {'text': clean_text(x['text']), 'label': x['label']})
def tokenize_function(examples):
return tokenizer(examples['text'], padding='max_length', truncation=True, max_length=128)
encoded_dataset = dataset.map(tokenize_function, batched=True)
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=1,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
evaluation_strategy='epoch',
logging_dir='./logs'
)
trainer = Trainer(
model=mode,
args=training_args,
train_dataset=encoded_dataset['train'],
eval_dataset=encoded_dataset['validation'],
)
trainer.train()
trainer.evaluate(encoded_dataset['test'],metric_key_prefix='eval')
mode.save_pretrained('./sentiment_model')
tokenizer.save_pretrained('./sentiment_model')
训练效果如下,我们可以发现经过一轮训练,验证集上的loss降低到了0.2。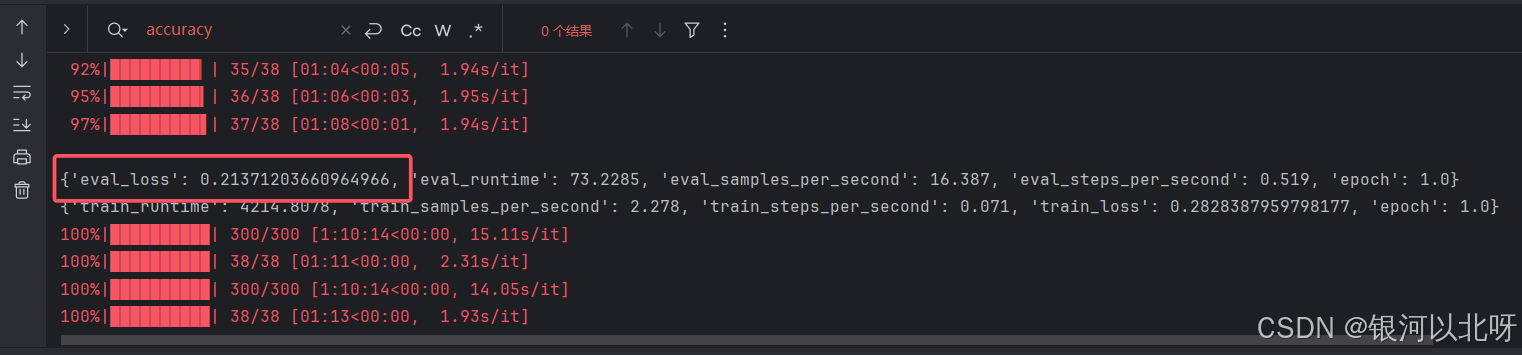
接下来我们使用训练之后的模型来对之前的语句进行评分,只需要加载训练之后的模型就好。代码实现如下:
from transformers import BertTokenizer, BertForSequenceClassification, AutoModelForSequenceClassification, \
AutoTokenizer, pipeline
mode_dir = './sentiment_model'
model = AutoModelForSequenceClassification.from_pretrained(mode_dir)
tokenizer = BertTokenizer.from_pretrained(mode_dir)
classifier = pipeline('text-classification', model=model, tokenizer=tokenizer)
output = classifier('我今天心情很好')
print(output)
output = classifier('你好,我是AI助手')
print(output)
output = classifier('我今天很生气')
print(output)
效果如下: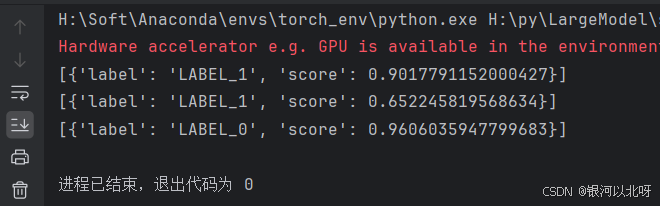
我们可以发现,使用lansinuote/ChnSentiCorp数据集对模型训练之后,模型在对文本分类方面的能力得到了大幅加强。
总结
模型微调只是针对某种下游任务,针对性的强化模型的能力,但是微调之后的模型在泛化能力上有所下降。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)