GraphRAG 工作原理逐步解析:从图创建到搜索的实战示例
GraphRAG 工作原理逐步解析:从图创建到搜索的实战示例
本篇文章How GraphRAG Works Step-By-Step: From Graph Creation to Search with Real Examples | Towards AI详细介绍了GraphRAG的工作原理,适合对检索增强生成(RAG)和知识图谱感兴趣的读者。文章的技术亮点在于通过图结构提升信息检索效率,并且提供了本地搜索和全局搜索等多种查询方法。适用场景包括文本分析、信息提取和主题总结等。实际案例中,作者以书籍《Penitencia》为例,展示了如何构建图谱并进行有效查询,具体步骤清晰易懂,适合开发者和研究者参考。
你可能读过微软研究院关于使用知识图谱进行检索增强生成(RAG)的论文——《从局部到全局:一种面向查询摘要的 GraphRAG 方法》。或许你觉得论文中的某些部分有些模糊。或许你希望文档能更详细地解释信息是如何从图谱中检索出来的。如果这听起来像你,那就继续读下去吧!
我已经深入研究了代码,所以你无需再费力,在这篇文章中,我将详细描述 GraphRAG 过程的每个步骤。你甚至会学到论文中根本没有提及的一种搜索方法(局部搜索)。
1. 什么是 GraphRAG?
简而言之,GraphRAG 是一种利用图结构增强检索增强生成的方法。
它有不同的实现方式,这里我们主要关注微软的方法。它可以分解为两个主要步骤:图创建(即索引)和查询(其中有三种可能性:局部搜索、全局搜索和漂移搜索)。
我将使用一个真实世界的例子来引导你完成图创建、局部搜索和全局搜索。因此,事不宜迟,让我们使用 GraphRAG 来索引和查询 Pablo Rivero 的著作《Penitencia》。

GraphRAG 的关键步骤:图创建和图查询
2. 设置
GraphRAG 的文档会引导你完成项目设置。一旦初始化工作区,你会在 ragtest 目录中找到一个配置文件(settings.yaml)。
项目结构
我已将书籍《Penitencia》添加到 input 文件夹。为了本文,我未修改配置文件,以使用默认设置和索引方法(IndexingMethod.Standard)。
3. 图创建
要创建图,运行:
graphrag index --root ./ragtest
这会触发两个关键操作:从源文档中提取实体和将图划分为社区,这些操作在 GraphRAG 项目的 workflows 目录的模块中定义。
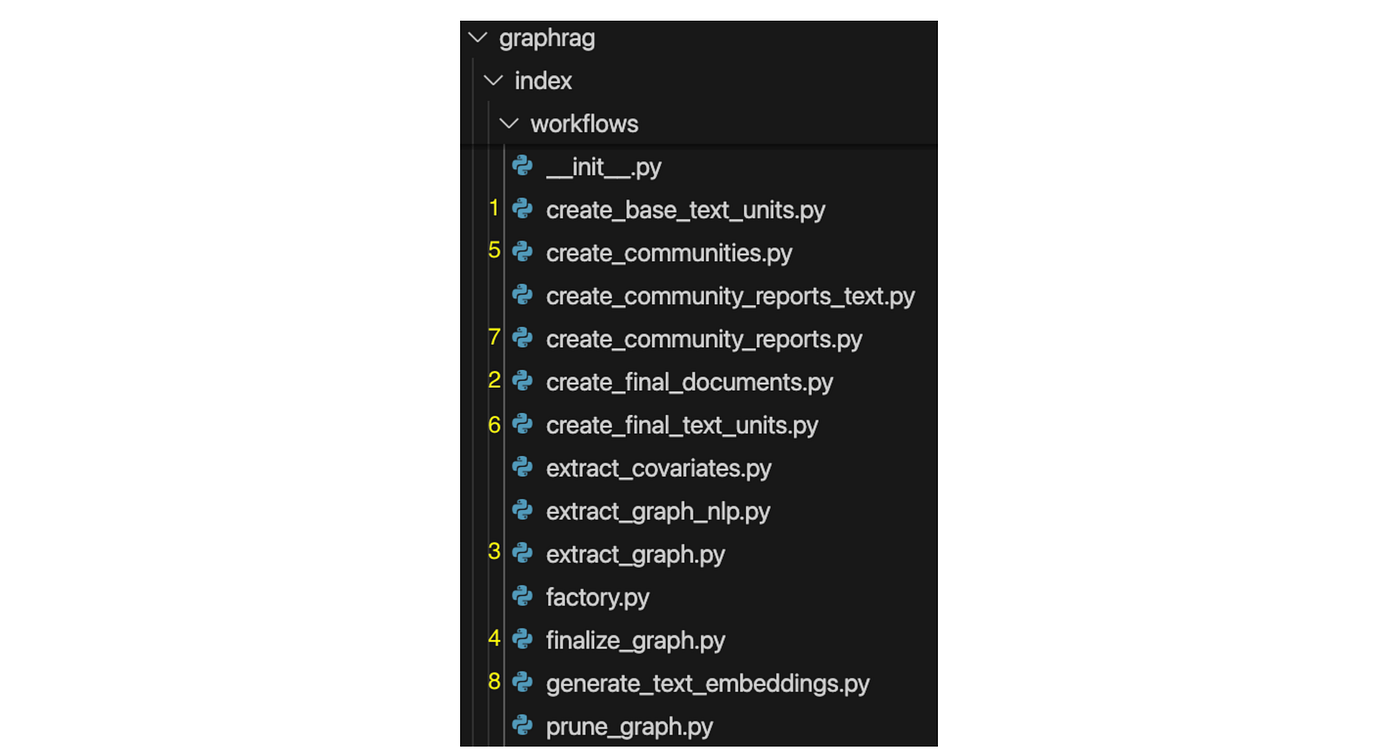
实现实体提取和图社区划分的模块。黄色数字显示了执行顺序。
3.1 实体提取
- 在
create_base_text_units模块中,文档(在我们的例子中是书籍《Penitencia》)被分割成 N 个 token 的小块。

书籍《Penitencia》的前五个文本块。每个文本块长 1200 个 token,并具有唯一的 ID。
- 在
create_final_documents中,创建一个查找表,将文档映射到其相关的文本单元。每一行代表一个文档,由于我们只处理一个文档,所以只有一行。

显示所有文档及其 ID 的表格。对于每个文档,所有相关的文本块(即文本单元)都按其 ID 列出。
- 在
extract_graph中,使用 LLM(来自 OpenAI)分析每个文本块,根据此提示提取实体和关系。
在此过程中,可能会出现重复的实体和关系。例如,主角 Jon 在 82 个不同的文本块中被提及,因此他被提取了 82 次——每个文本块一次。
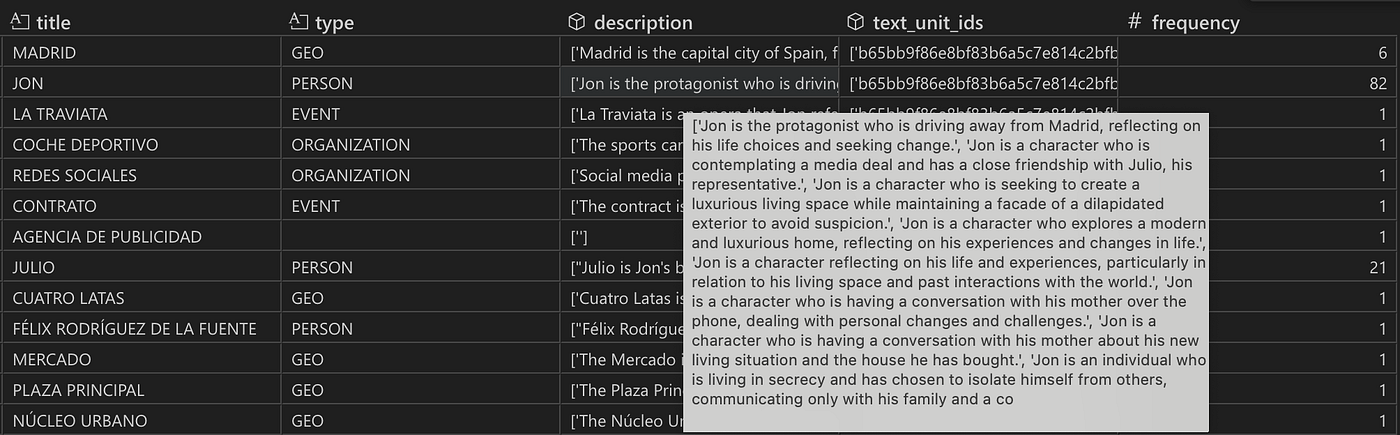
实体表的快照。实体按实体标题和类型分组。实体 Jon 被提取了 82 次,这可以从频率列中观察到。text_unit_ids 和 description 列分别包含 82 个 ID 和描述的列表,显示了 Jon 在哪些文本块中被识别和描述。默认情况下,有四种实体类型(地理、人物、事件和组织)。
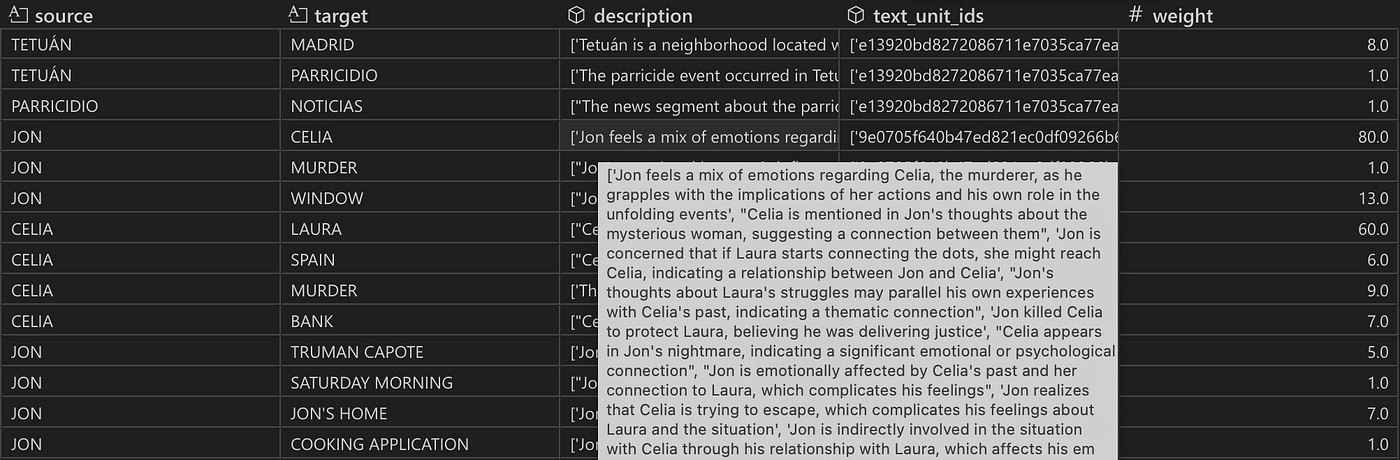
关系表的快照。关系按源实体和目标实体分组。对于 Jon 和 Celia,description 和 text_unit_ids 列分别包含 14 个条目的列表,表明这两个角色在 14 个不同的文本块中存在关系。weight 列显示了 LLM 分配的关系强度的总和(权重不是源节点和目标节点之间的连接数!)。
通过根据实体标题和类型对实体进行分组,以及根据源节点和目标节点对关系进行分组,尝试进行去重。然后,提示 LLM 通过分析所有出现位置的较短描述来为每个唯一实体和唯一关系编写详细描述(参见提示)。
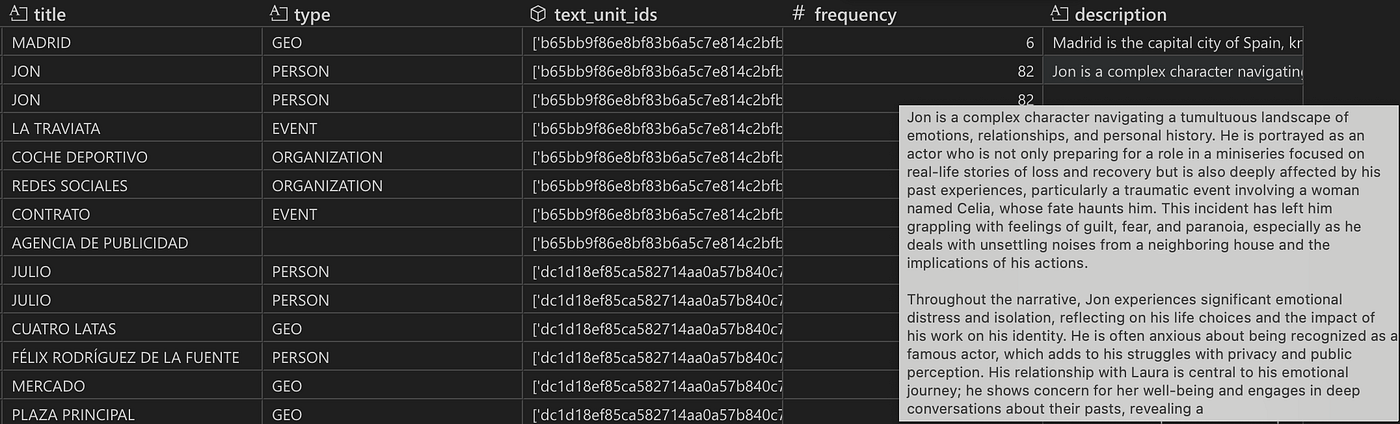
实体表的快照,包含最终的实体描述(由所有提取的短描述组成)。
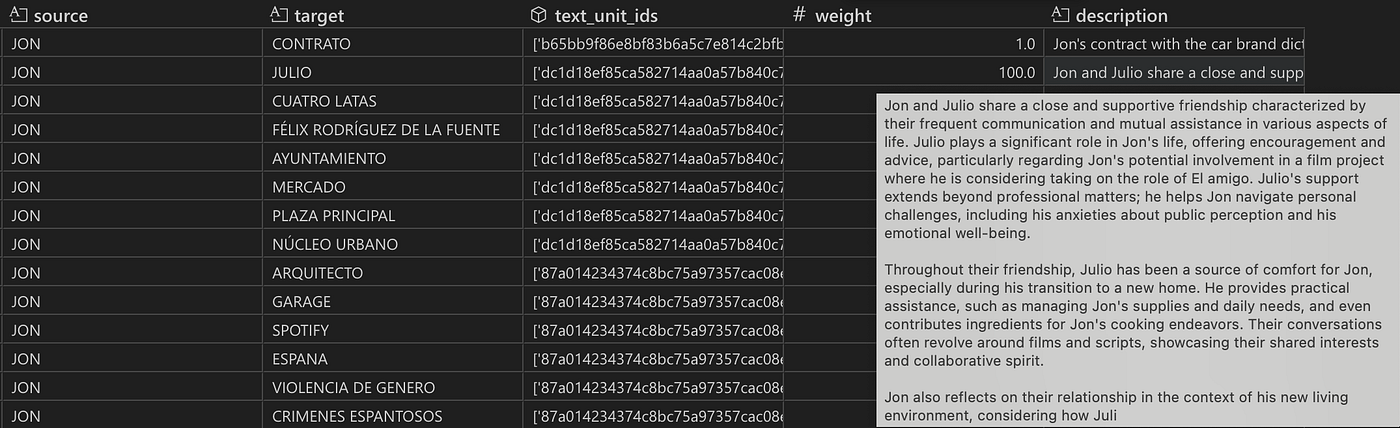
关系表的快照,包含最终的关系描述(由所有提取的短描述组成)。
如你所见,去重有时并不完美。此外,GraphRAG 不处理实体消歧(例如,Jon 和 Jon Márquez 尽管指代同一个人,但仍将是独立的节点)。
- 在
finalize_graph中,使用 NetworkX 库将实体和关系表示为图的节点和边,包括节点度等结构信息。

最终实体表的快照,其中每个实体代表图中的一个节点。节点的度是它拥有的边数(即它连接的其他节点的数量)。

最终关系表的快照,其中每个关系代表图中的一条边。边的 combined_degree 表示源节点和目标节点度的总和。具有高 combined_degree 的边很重要,因为它连接了高度连接的节点。
为了更好地理解,我发现实际查看图很有帮助,因此我使用 Neo4j 进行了可视化(notebook):
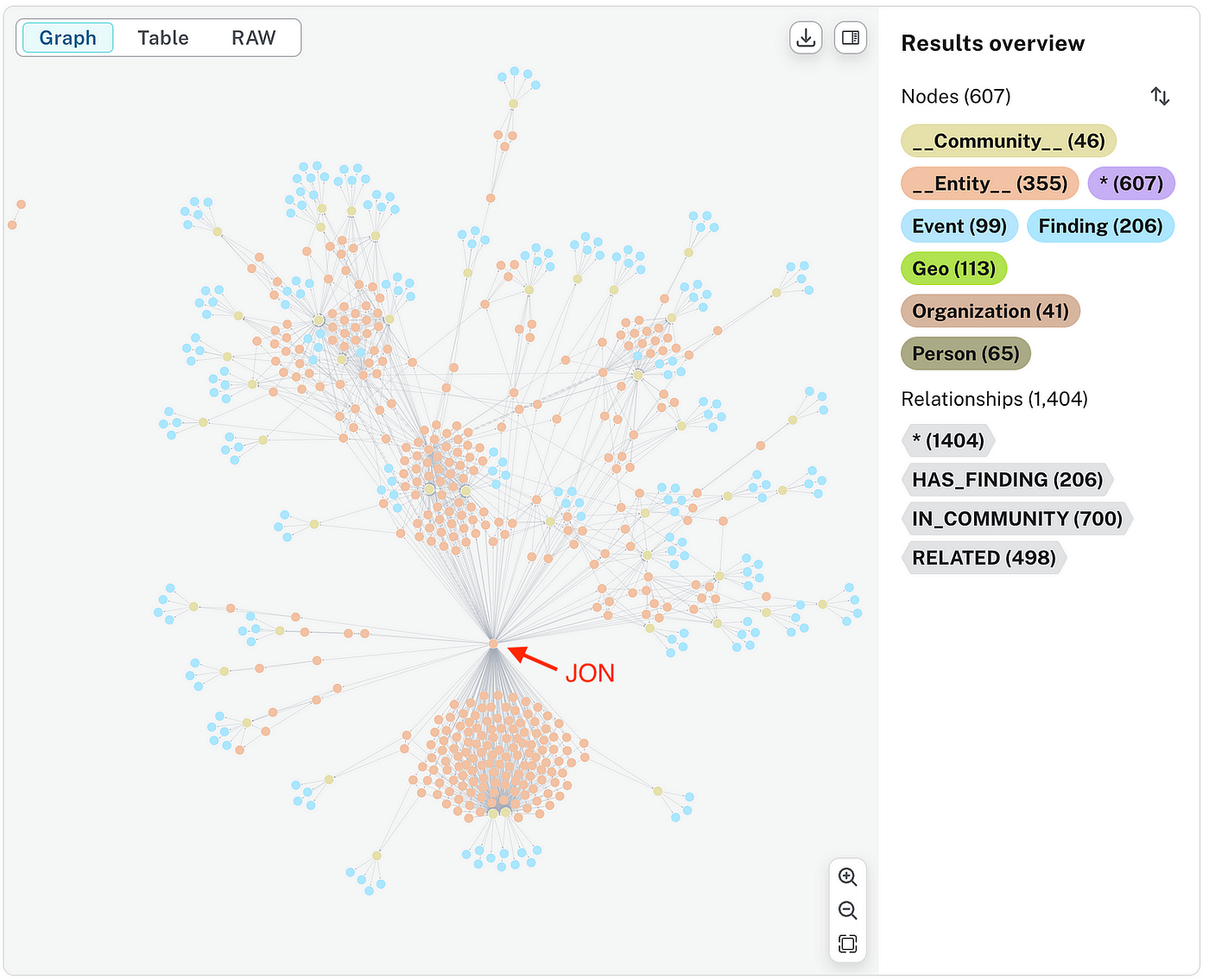
使用 Neo4j 将书籍《Penitencia》可视化为图
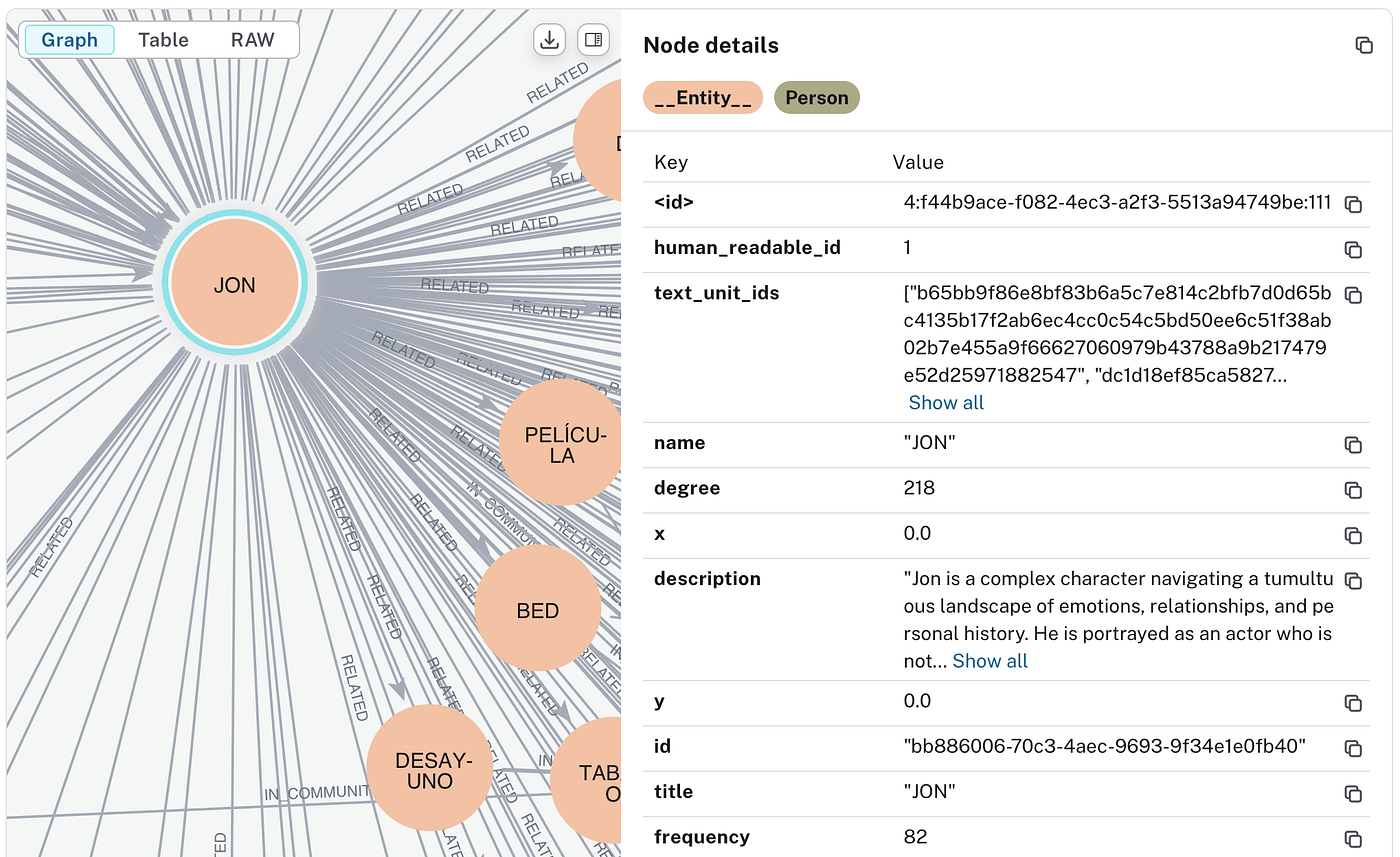
使用 Neo4j 可视化实体 Jon 及其关系

使用 Neo4j 将 Laura 和 Mario 之间的关系可视化为图边
3.2 图社区划分
- 在
create_communities中,使用 Leiden 算法(一种分层聚类算法)将图划分为社区。
社区是一组节点,它们彼此之间的关系比与图其余部分的关系更紧密。Leiden 算法的分层性质允许检测不同特异性的社区,这反映在它们的级别中。级别越高,社区越具体(例如,级别 3 相当具体,而级别 0 是根社区,非常通用)。

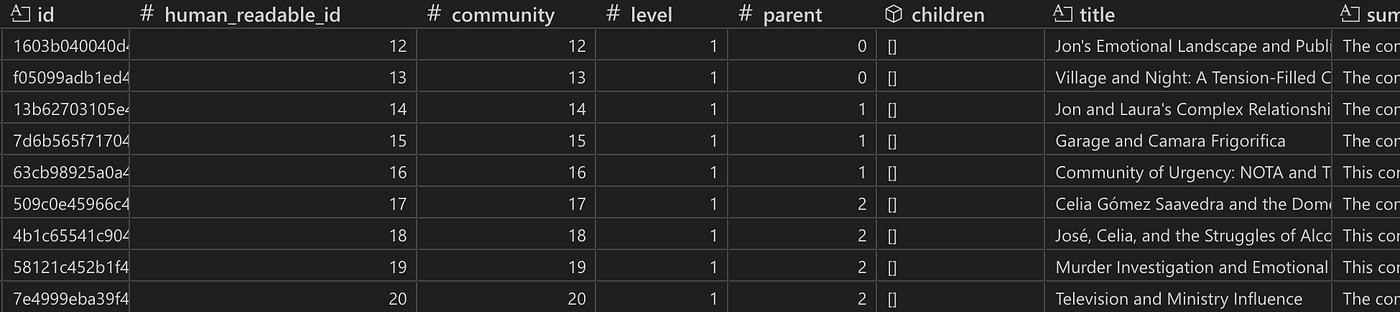
社区表的快照。社区 0 是一个级别 0 的社区,使其成为一个根社区(没有父级)。它有两个子社区,如 children 列所示。社区封装的所有关系、文本单元和实体都列在相应的列中。size 列显示该社区由 131 个实体组成。
如果我们将每个社区可视化为一个节点,包括属于该社区的实体,我们就可以识别出聚类。

过滤 IN_COMMUNITY 关系的《Penitencia》图揭示了 15 个根级别社区(红色圆圈)
社区的价值在于它们能够整合来自广泛来源的信息,如实体和关系,从而提供宏观的洞察。对于书籍而言,社区可以揭示文本中的主要主题或话题,正如我们将在步骤 8 中看到的那样。
![Neo4j visualization of three hierarchically connected communities: Community 2 (Celia Gómez and the Tetuán Incident) — [parent of]→ Community 23 (Celia’s Desperation and Familial Violence) — [parent of]→ Community 42 (Celia’s Struggle with Laura). Rank is the LLM-assigned importance of the community from 1 (lowest importance) to 10 (highest importance).](https://i-blog.csdnimg.cn/img_convert/127f973748da1a022a1fb4d801b7c337.png)
三个分层连接的社区的 Neo4j 可视化:社区 2(Celia Gómez 和 Tetuán 事件)— [父级]→ 社区 23(Celia 的绝望和家庭暴力)— [父级]→ 社区 42(Celia 与 Laura 的斗争)。Rank 是 LLM 分配的社区重要性(1 为最低,10 为最高)。
- 在
create_final_text_units中,步骤 1 中的文本单元表会映射每个文本单元 ID 对应的实体 ID、关系 ID 和协变量 ID(如果有),以便于查找。

最终文本单元表的快照
协变量本质上是声明。例如,“Celia 谋杀了她的丈夫和孩子(嫌疑)。” LLM 根据此提示从文本单元中推断出它们。默认情况下,不提取协变量。
- 在
create_community_reports中,LLM 为每个社区编写一份报告,详细说明其主要事件或主题,以及报告的摘要。LLM 遵循此提示,并接收来自社区的所有实体、关系和声明作为上下文。
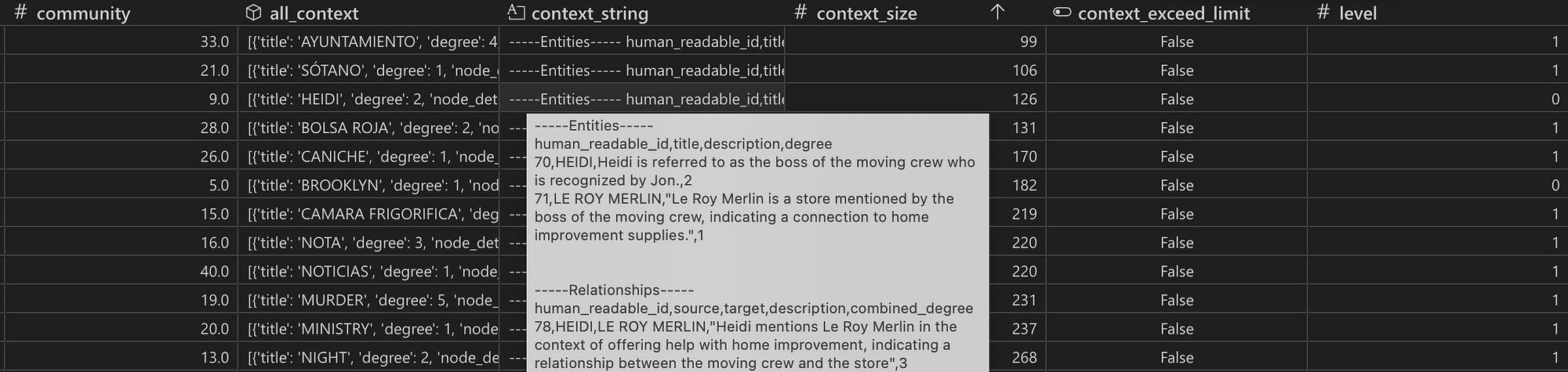
显示报告生成前中间步骤的表格快照。对于每个社区,收集所有实体和关系,然后将其结构化为字符串,作为上下文传递给 LLM。context_exceed_limit 列在 context_string 需要缩短时提醒算法。
对于大型社区,上下文字符串(包括实体、关系,可能还有协变量)可能会超过配置文件中指定的 max_input_length。如果发生这种情况,算法有一种方法可以减少上下文中的文本量,包括层次替换(Hierarch Substitution),如果需要,还可以进行截断(Trimming)。
在层次替换中,来自实体、关系、声明的原始文本被子社区的社区报告替换。
例如,假设社区 C(级别 0)有两个子社区 S1 和 S2(均为级别 1)。社区 S1 的规模(实体数量)大于 S2。在这种情况下,C 中属于 S1 的所有实体、关系和声明都将被 S1 的社区报告替换。这优先考虑最大程度地减少 token 数量。如果此更改后上下文长度仍超过 max_input_length,则使用 S2 替换 C 中的相关实体和关系。
如果在层次替换后,上下文仍然过长(或者社区根本没有子社区),则需要截断上下文字符串——不那么相关的数据将被简单地排除。实体和关系分别按其节点度数和组合度数排序,并删除值最低的那些。
最终,LLM 使用提供的上下文字符串生成关于社区的发现(5-10 个关键洞察的列表)和摘要。这些内容组合起来形成社区报告。

社区表的快照,包括 LLM 生成的报告(full_content 列)和报告摘要(summary 列)。报告文本是摘要(红色)和发现(蓝色)的组合。rank 和 rating_explanation 列分别包含 LLM 分配的社区重要性值(介于 1 到 10 之间)以及所选值的理由。
- 最后,在
generate_embeddings中,使用配置中指定的 OpenAI 嵌入模型为所有文本单元、实体描述和full_content文本(社区标题 + 社区摘要 + 社区报告 + 排名 + 评级解释)创建嵌入。向量嵌入允许基于用户查询对图进行高效的语义搜索,这在局部搜索和全局搜索中是必需的。
4. 查询
图构建完成后,我们就可以开始查询它了。搜索功能的实现可以在 GraphRAG 项目的structure_search目录中找到。
4.1 局部搜索
如果你有一个具体的问题,请使用 GraphRAG 提供的局部搜索功能(更多示例用法请参见notebook)。
graphrag query \
--root ./ragtest \
--method local \
--query "What kind of retribution is Laura seeking, and why?"
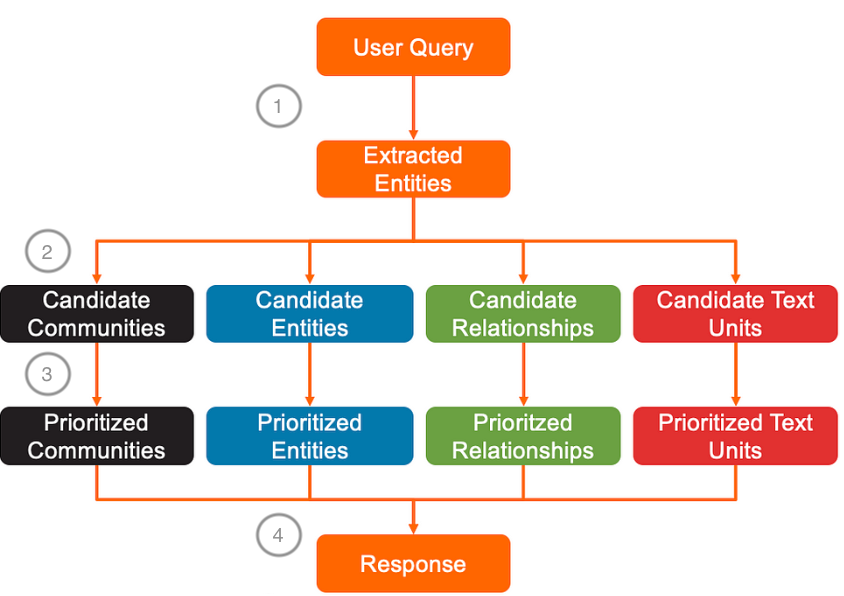
局部搜索的关键步骤
- 社区报告、文本单元、实体、关系和协变量(如果有)从
ragtest/output/中的 parquet 文件加载,它们在图创建后已自动保存。
然后,对用户查询进行嵌入,并计算其与每个实体描述嵌入的语义相似度。

实体及其与用户查询的余弦距离快照
检索到 N 个语义最相似的实体。N 的值由配置中的超参数 top_k_mapped_entities 定义。
奇怪的是,GraphRAG 会以 2 倍的因子进行过采样,有效地检索 2 * top_k_mapped_entities 个实体。这样做是为了确保提取足够的实体,因为有时检索到的实体具有无效 ID。

与用户查询语义最相似的实体快照。在此示例中,top_k_mapped_entities=10,因此通过过采样应该检索到 20 个实体,但只有 17 个具有有效 ID,因此实际检索到 17 个实体。rank 列显示实体节点的度数。
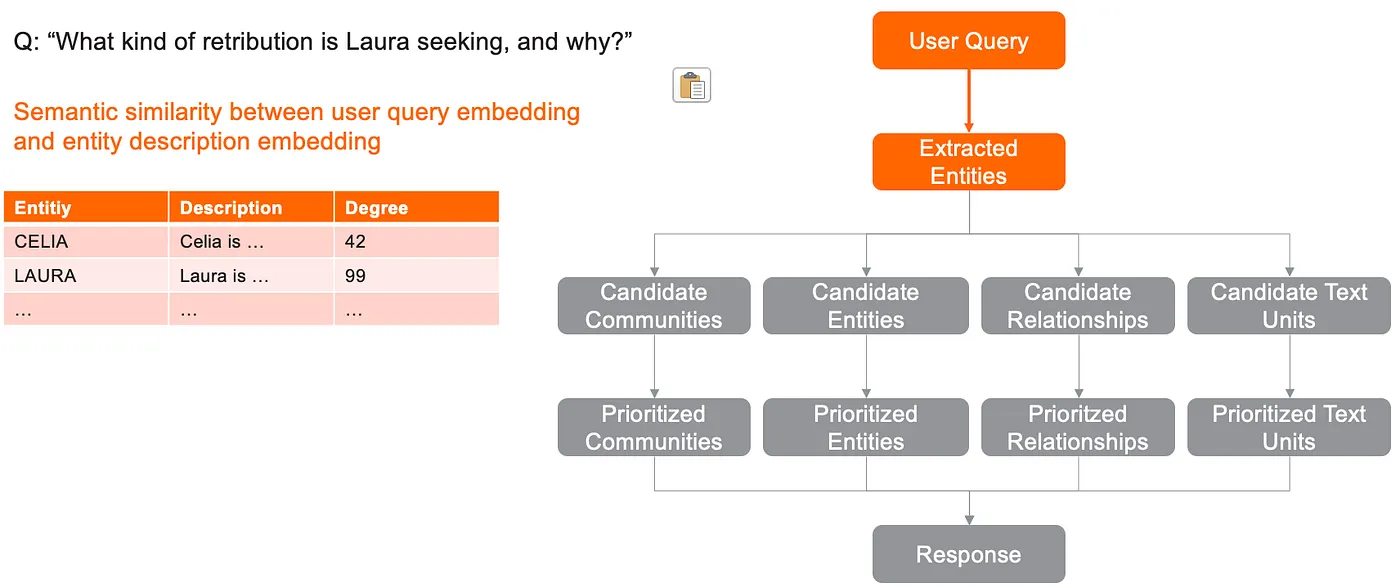
摘要图:局部搜索中提取实体的检索
- 所有提取的实体都成为候选实体。提取实体的社区、关系和文本单元成为候选社区、候选关系和候选文本单元。
具体来说:
- 候选社区是所有包含至少一个提取实体的社区。
- 候选关系是所有图边,其中提取的实体是源节点或目标节点。
- 候选文本单元是包含至少一个提取实体的书籍中的文本块。
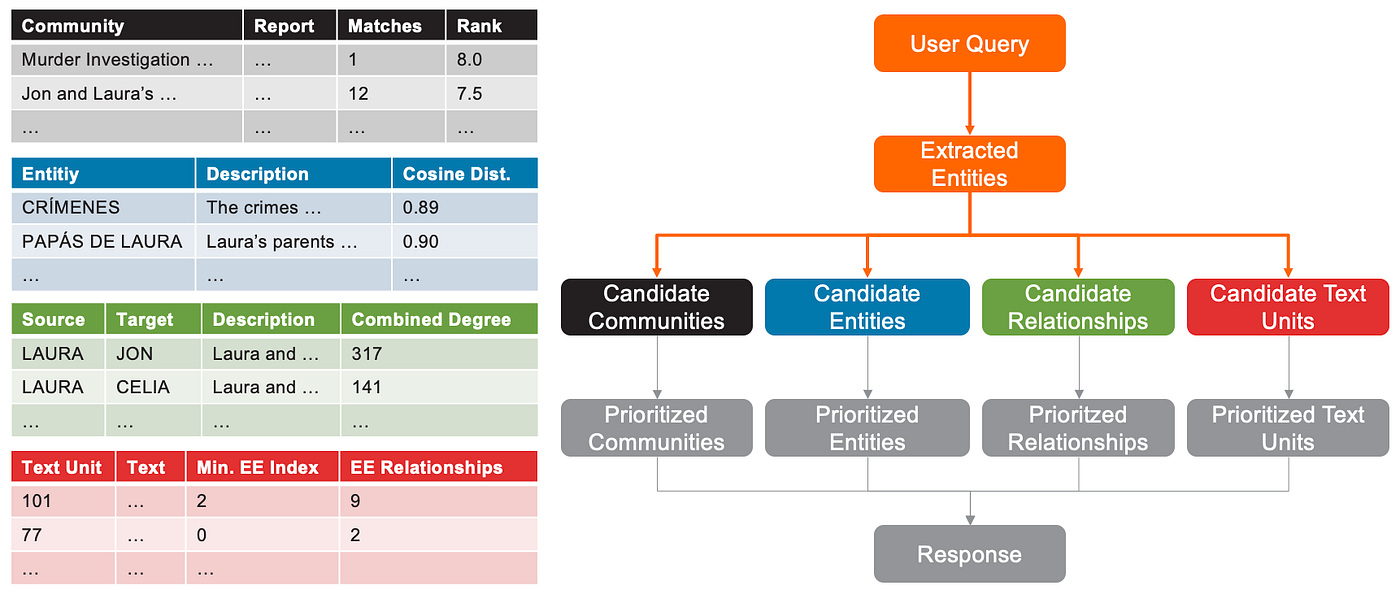
摘要图:局部搜索中候选社区、实体、关系和文本单元的选择
- 候选对象被排序,最相关的项目放在各自列表的顶部。这确保了最重要的信息被优先用于回答查询。
优先级是必要的,因为 LLM 上下文长度不是无限的。可以传递给模型的信息量是有限的。配置中设置的超参数决定了分配给实体、关系、文本单元和社区的上下文窗口 token 数量。默认情况下,text_unit_prop=0.5 和 community_prop=0.1,这意味着配置中指定的 max_tokens 的 50% 将被文本单元占用,10% 被社区报告占用,剩下 40% 用于实体和关系的描述。max_tokens 默认为 12000。
- 社区按其“匹配”数排序,即社区中提取实体出现的不同文本单元的数量。如果匹配数相同,则按其“排名”(LLM 分配的重要性)排序。给定
max_tokens=12000和community_prop=0.1,则社区报告最多可占用 1200 个 token。只允许完整的社区报告,这意味着没有截断——社区报告要么完整包含,要么完全不包含。

按匹配数和排名排序的候选社区快照。匹配数是提取实体出现的不同文本单元的数量。排名是社区的重要性得分,由 LLM 决定。
- 候选实体不进行排序,保持实体与其用户查询的语义相似度顺序。尽可能多的候选实体被添加到上下文中。如果
max_tokens的 40% 分配给实体和关系,这意味着最多有 4800 个 token 可用。

候选实体快照
- 候选关系根据其是网络内(in-network)关系还是网络外(out-network)关系进行不同优先级的处理。网络内关系是指两个提取实体之间的关系。网络外关系是指提取实体与另一个非提取实体集中的实体之间的关系。网络内候选关系按其
combined_degree(源节点和目标节点度的总和)排序。网络外候选关系首先按其链接(links)数量(即网络外实体与网络内实体之间的链接数量)排序,如果链接数量相同,则按combined_degree排序。

显示网络内关系的表格。rank 列显示 combined_degree。

显示网络外关系的表格快照。rank 列显示 combined_degree,attributes 列显示网络外实体与网络内实体(Crímenes, Papás de Laura, and Laura)的链接数量。
查找网络内和网络外关系是一个迭代过程,一旦可用 token 空间被填满(在我们的示例中,available_tokens = 4800 — entity_descriptions),就停止。网络内关系首先添加到上下文中,因为它们被认为更重要。然后,在空间允许的情况下,添加网络外关系。

优先级排序的候选关系快照。请注意,前两行是网络内关系。默认情况下不使用权重,并且网络内关系的链接已过时/不正确。
- 候选文本单元按提取实体顺序排序,然后按与文本单元相关的提取实体关系数量排序。实体顺序确保提及与用户查询语义最相似的实体的文本单元获得优先权。例如,如果 Crímenes 是与用户查询语义最相似的实体,并且文本单元 CB6F…是提取 Crímenes 的文本块,那么 CB6F…将位于列表顶部,即使与之相关的提取实体关系很少。

显示优先级排序的文本单元的表格快照
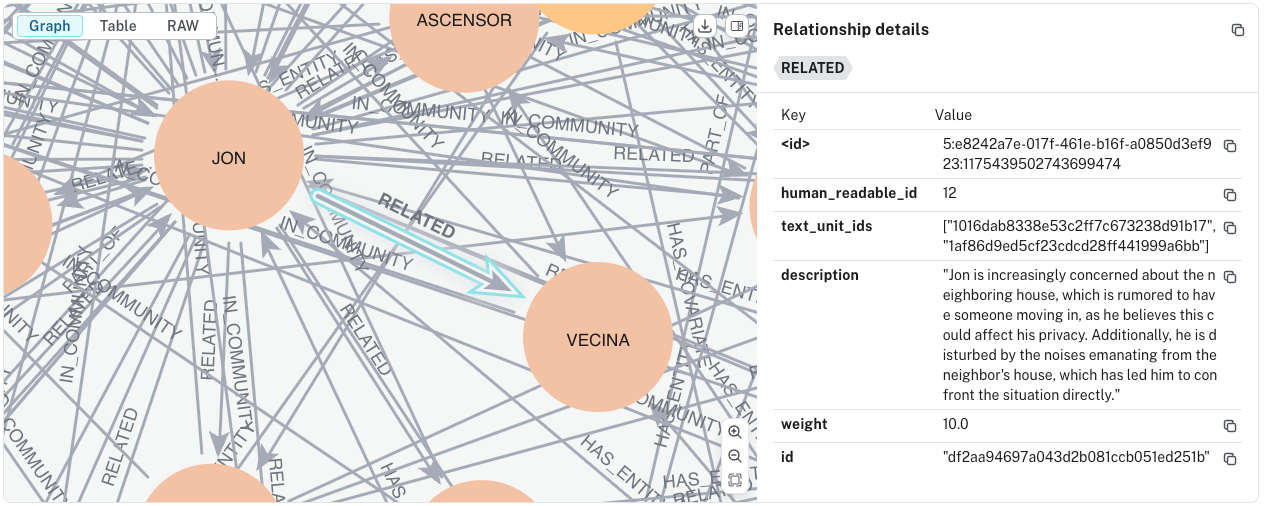
每个图边(关系)都有一个属性,指示它是从哪个文本单元中提取的。此属性使得追踪提取实体与检测到它的文本单元之间的关系成为可能。
给定 max_tokens=12000 和 text_unit_prop=0.5,则文本单元最多可占用 6000 个 token。与社区报告的情况一样,文本单元被添加到上下文中直到达到 token 限制,不进行截断。
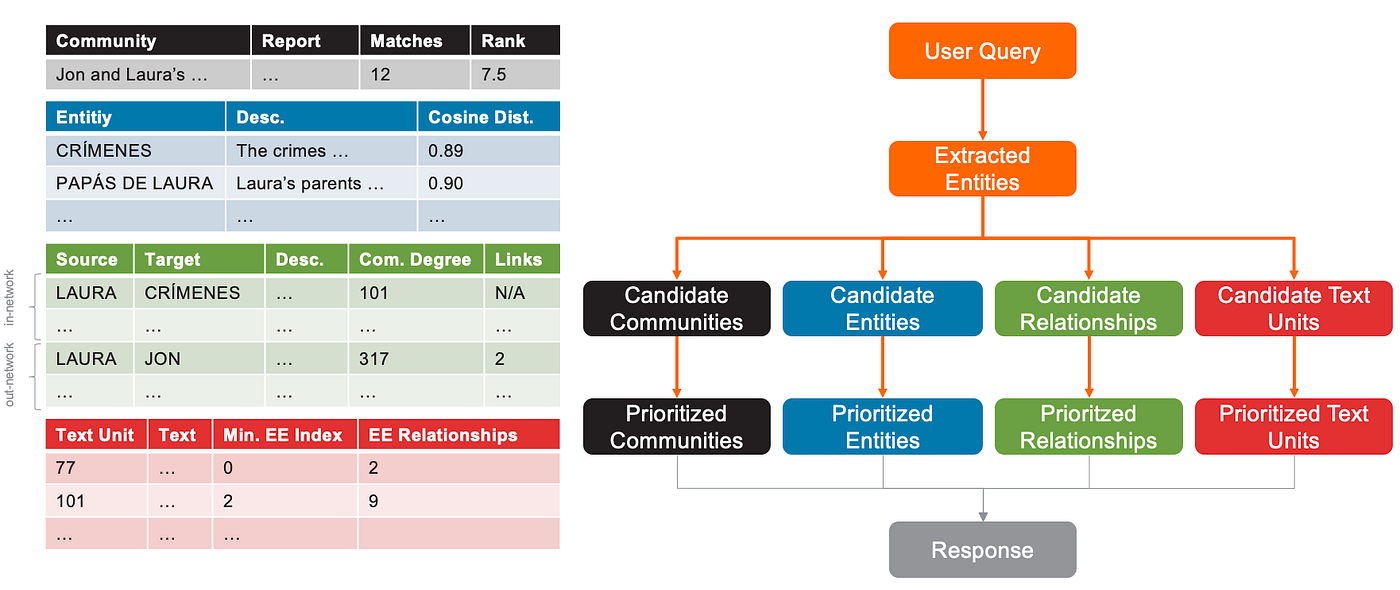
摘要图:局部搜索中候选社区、实体、关系和文本单元的排序
- 最后,按此顺序将优先级排序的社区报告、实体、关系和文本单元的描述连接起来,并作为上下文提供给 LLM,LLM 生成对用户查询的详细响应。
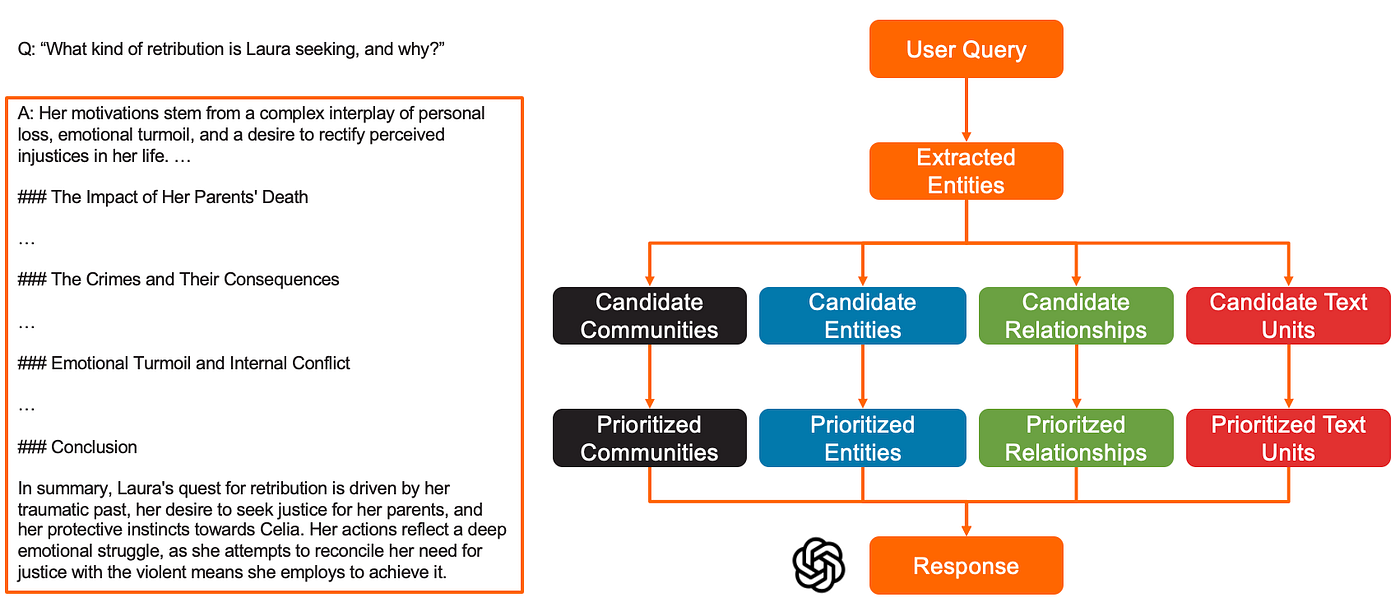
摘要图:局部搜索中对用户查询的响应生成
4.2 全局搜索
如果你有一个一般性问题,请使用全局搜索功能(更多示例用法请参见notebook)。
graphrag query \
--root ./ragtest \
--method global \
--query "What themes are explored in the book?"
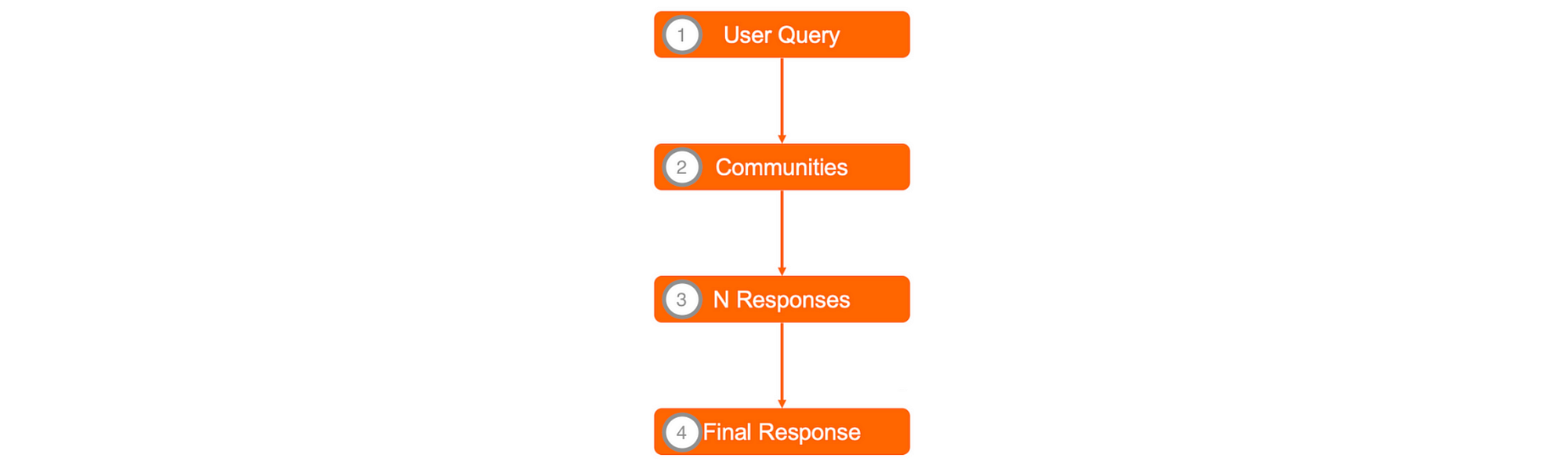
全局搜索的关键步骤
- 社区报告和实体从已保存的 parquet 文件中加载。
对于每个社区,计算一个 occurrence_weight。occurrence_weight 表示与社区相关的实体出现的不同文本单元的归一化计数。该值反映了社区在整个文档中的普遍程度。


社区表快照
2.所有社区都被打乱,然后分批处理。打乱有助于减少偏差,确保最相关的社区不会全部集中在同一批次中。
每批次的社区都按其 community_weight 排序。本质上,实体出现在多个文本块中的社区会获得优先权。

摘要图:全局搜索中的社区批处理
- 对于每个批次,LLM 使用社区报告作为上下文,生成对用户查询的多个响应,并为每个响应分配一个分数,以反映其在回答用户问题方面的帮助程度(提示)。通常每个批次生成 5 个响应。
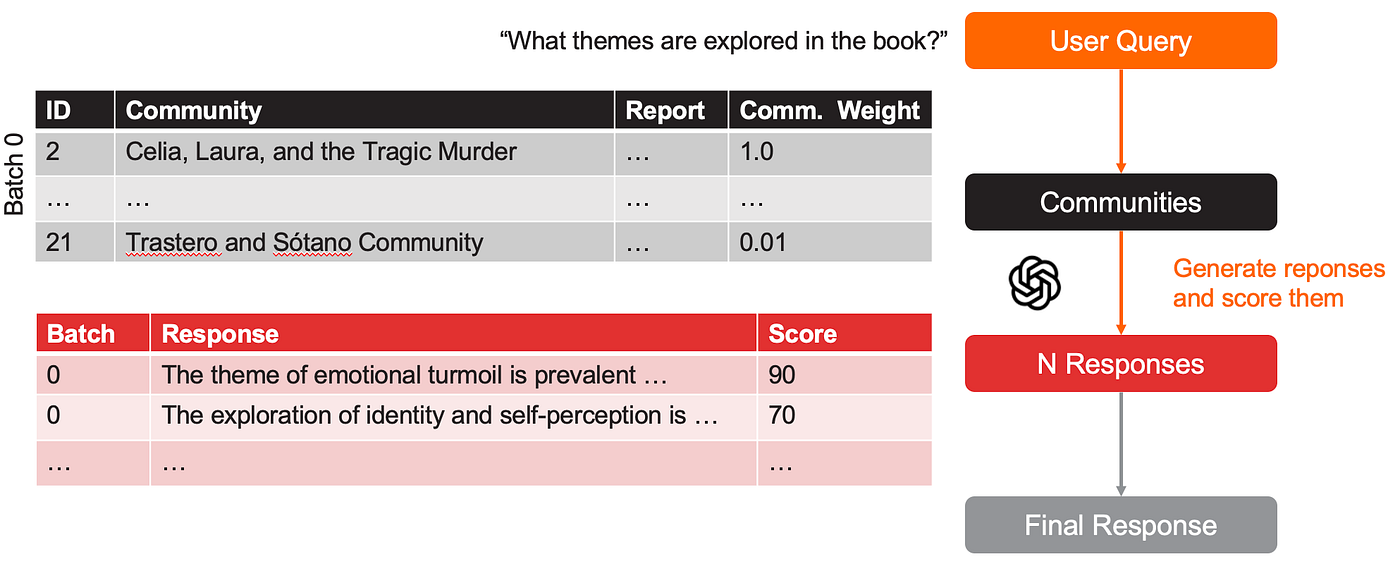
摘要图:全局搜索中每个批次的响应生成
所有响应都按其分数排名,任何分数为零的响应都将被丢弃。
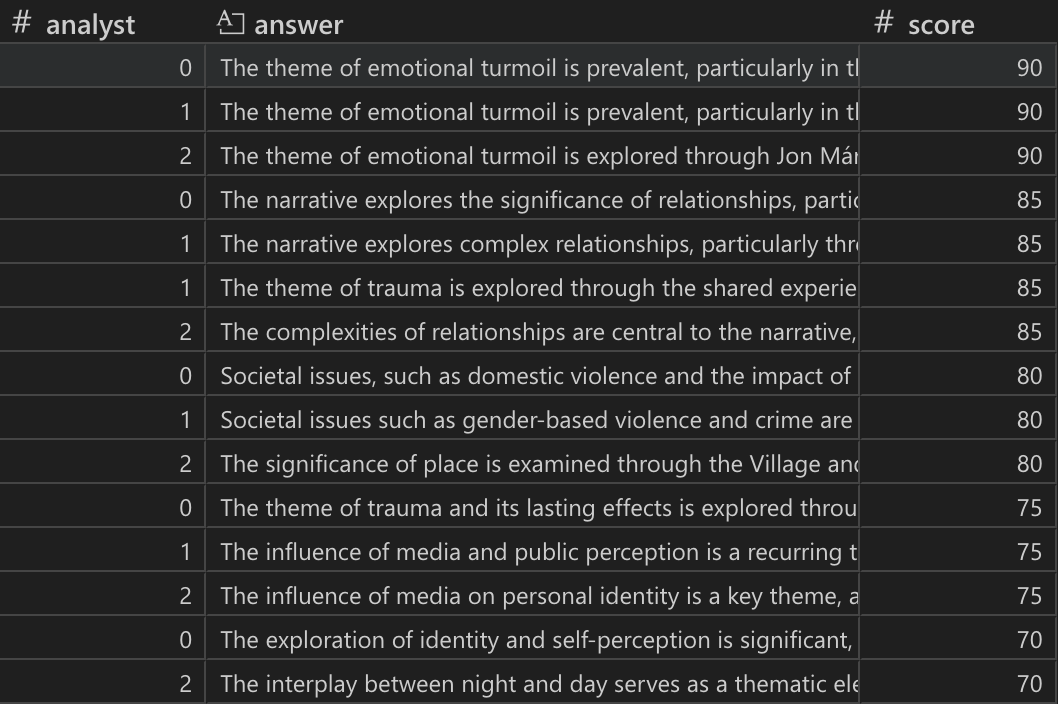
显示所有用户问题响应的表格,按分数排序。analyst 列代表批次 ID。
- 排序后的响应文本被连接成一个单一的输入,作为上下文传递给 LLM,LLM 生成对用户问题的最终答案(提示)。

摘要图:全局搜索中的最终响应生成
5. 结论
本文逐步引导你了解了 Microsoft GraphRAG 中图创建、局部搜索和全局搜索的实现方式,并结合了真实数据和代码层面的见解。尽管自 2024 年初我开始使用该项目以来,官方文档已显著改进,但这次深入探讨填补了知识空白,并揭示了幕后发生的事情。迄今为止,这是我遇到的关于 GraphRAG 最详细和最新的资源,我希望你觉得它有用。
现在,我鼓励你超越默认配置:尝试调整参数,微调实体提取提示,或使用不同的索引方法。进行实验,并利用 GraphRAG 的强大功能来完成你自己的项目!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)