Ollama + Streamlit 部署本地大模型,构建聊天机器人
【摘要】聊天机器人是基于人工智能的自然语言处理技术开发的程序。本文聚焦集成大语言模型(通过Ollama部署本地模型)的方式构建聊天机器人。技术实现采用模块化设计,前端用Streamlit构建交互界面,后端通过Ollama调用AI模型。开发流程包括模型部署、前端构建、后端调用LLM,最终实现部署本地大模型,搭建聊天机器人。
目录
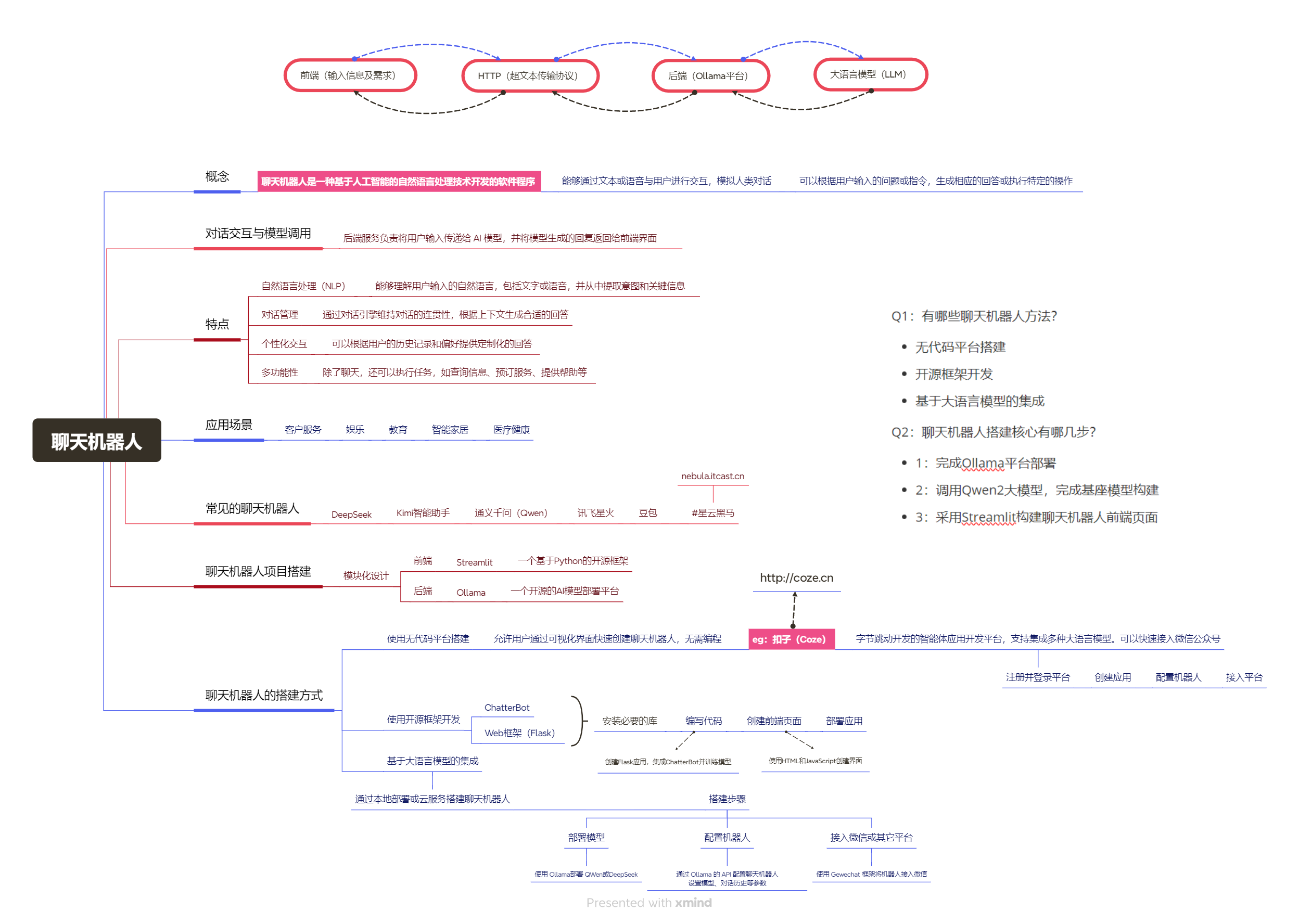
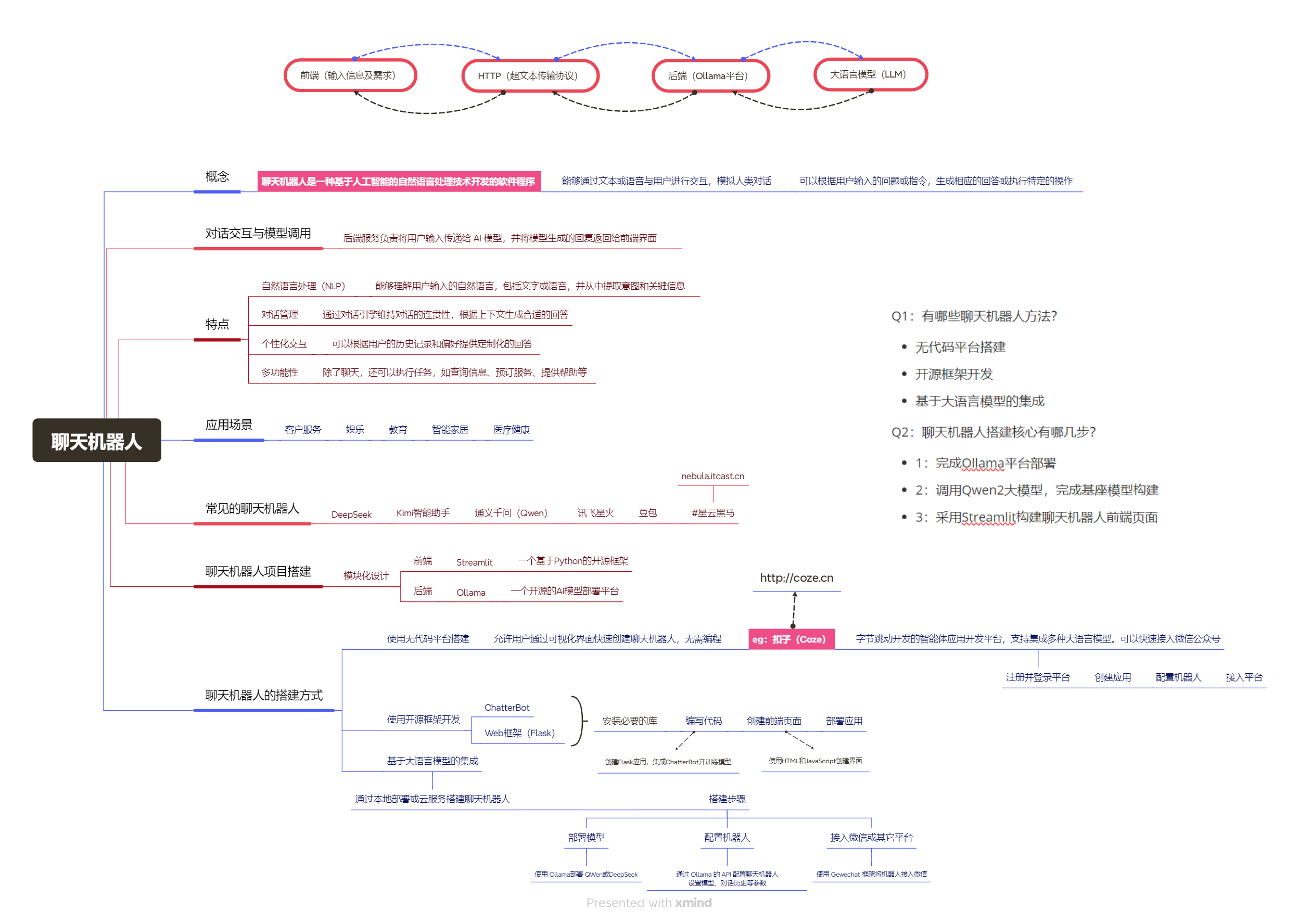
聊天机器人
概念:聊天机器人是一种__基于人工智能的自然语言处理技术__开发的软件程序
作用:能够通过文本或语音与用户进行交互,模拟人类对话。
可以根据用户输入的问题或指令,生成相应的回答或执行特定的操作
特点:
(1)自然语言处理(NLP)
能够理解用户输入的自然语言,包括文字或语音,并从中提取意图和关键信息
(2)对话管理
通过对话引擎维持对话的连贯性,根据上下文(记忆体)生成合适的回答
(3)个性化交互
可以根据用户的历史记录和偏好提供定制化的回答
(4)多功能性
除了聊天,还可以执行任务,如查询信息、预订服务、提供帮助等
常见的聊天机器人 :DeepSeek、豆包、通义千问、Kimi智能助手、讯飞星火等
应用场景:客服服务、娱乐、智能家居、教育、医疗健康等
- 聊天机器人的搭建方式
(1)使用无代码平台搭建
允许用户通过可视化界面快速创建聊天机器人,无需编程
进入 扣子(Coze) 官网:http://coze.cn
字节跳动 开发的智能体应用开发平台,支持集成多种大语言模型
注册并登录平台 —> 创建应用 —> 配置机器人 —> 接入平台
(2)使用开源框架开发
ChatterBot、Web框架(Flask)
安装必要的库 —> 编程(创建Flask应用,集成ChatterBot并训练模型) —>
创建前端界面(使用HTML和JavaScript创建界面) —> 部署应用
(3)基于大语言模型的集成
通过本地部署或云服务搭建聊天机器人。搭建步骤:
1、部署模型:使用 Ollama部署 QWen或DeepSeek
2、配置机器人:通过 Ollama 的 API 配置聊天机器人,设置模型、对话历史等参数
3、接入微信或其它平台:使用 Gewechat 框架将机器人接入微信
- 聊天机器人项目搭建
模块化设计:
前端:Streamlit 一个基于Python的开源框架
后端:Ollama 一个开源的AI模型部署平台
- 对话交互与模型调用
后端服务负责将用户输入传递给 AI 模型,并将模型生成的回复返回给前端界面

通过HTTP协议将前端接收的信息及需求向服务器发送请求,
后端通过Ollama平台调用大语言模型并将响应结果在前端输出。
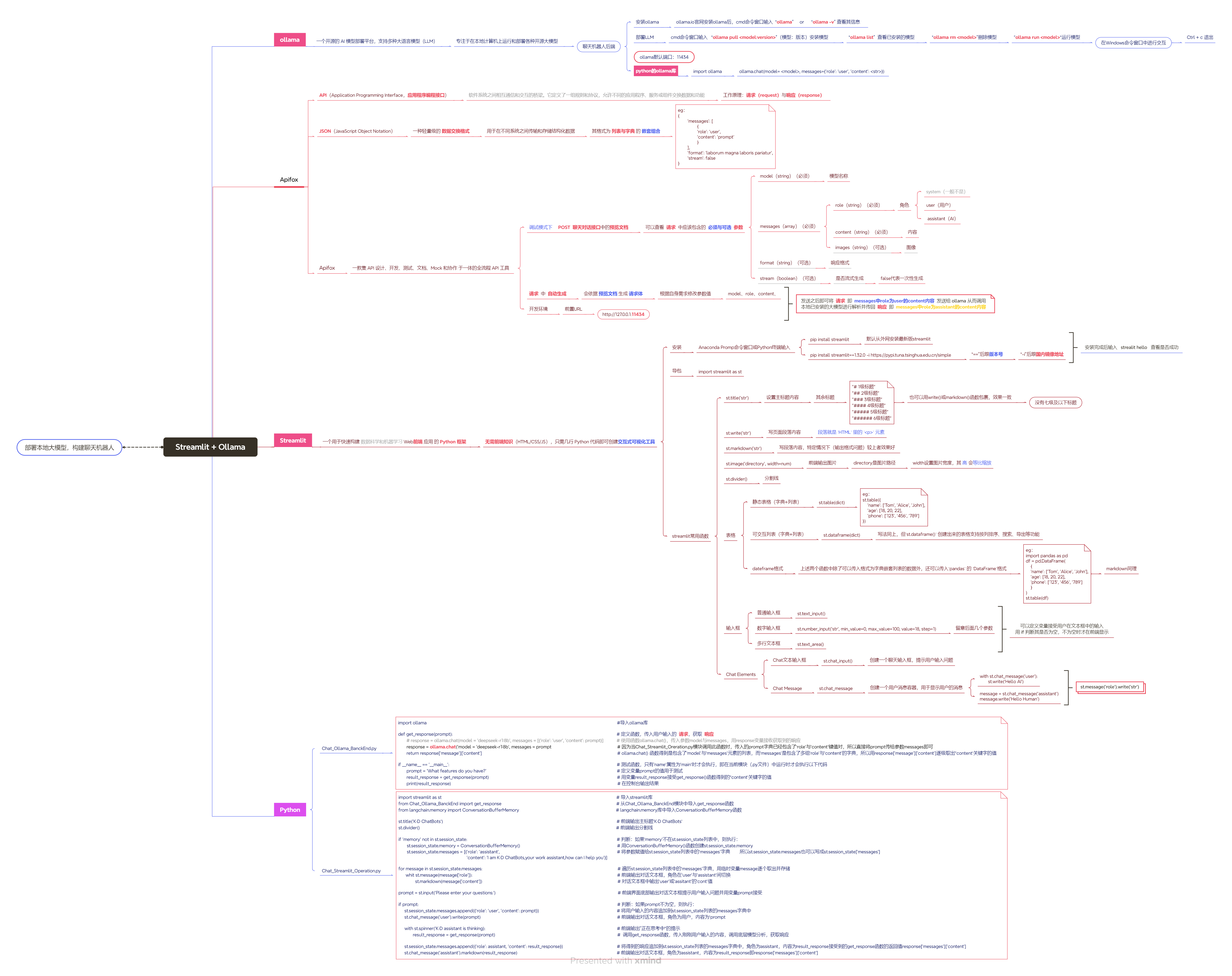
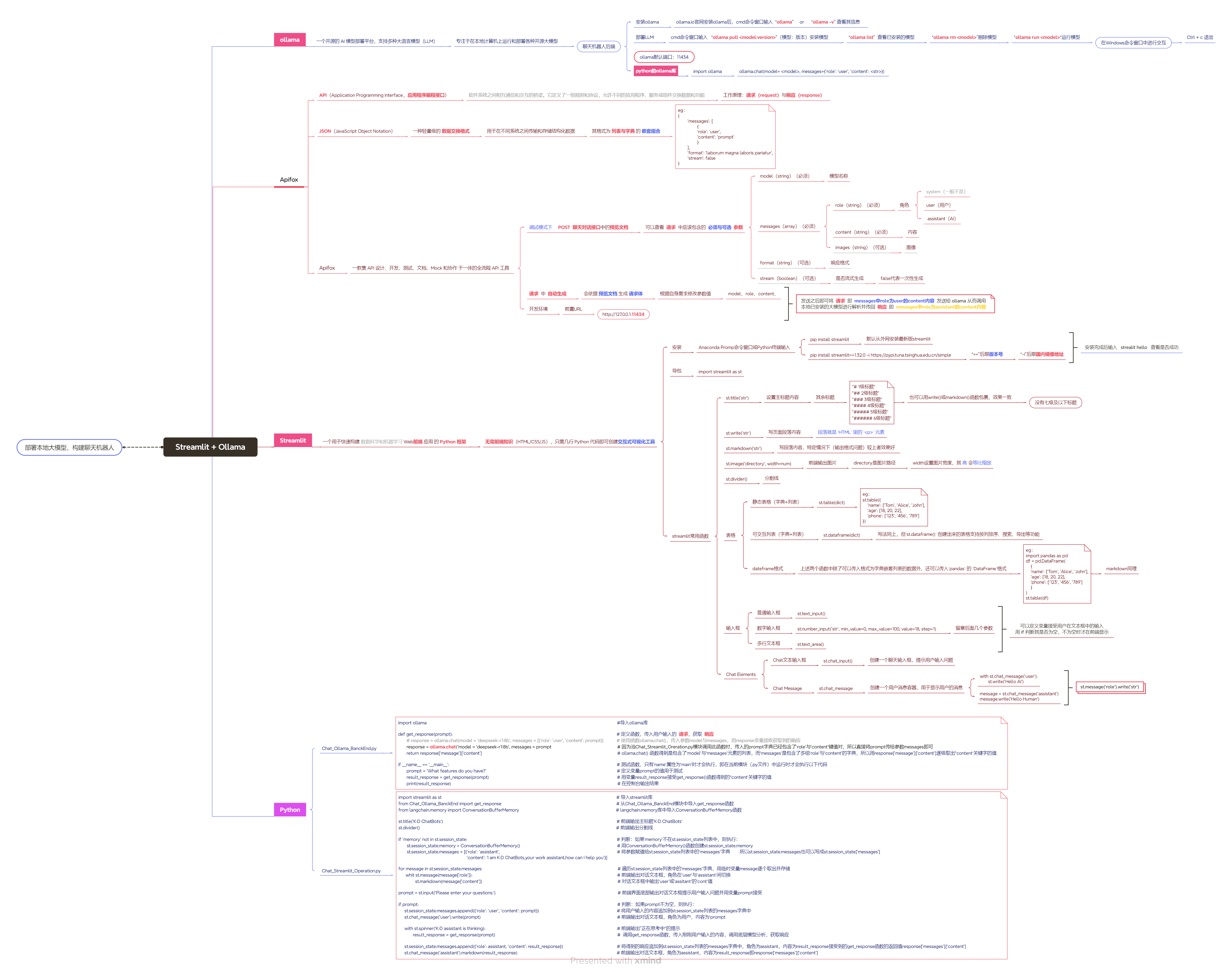
Ollama
Ollama是一个开源的 AI 模型部署平台,支持多种大语言模型(LLM)
专注于在本地计算机上运行和部署各种开源大模型
- 安装Ollama及部署本地大模型
ollama.io官网安装ollama后,cmd命令窗口输入 “ollama” or “ollama -v” 查看其信息
cmd命令窗口输入 “ollama pull <model:version>”(模型:版本)安装模型
“ollama list” 查看已安装的模型
“ollama rm <model>”删除模型
“ollama run <model>”运行模型
在Windows命令窗口中进行交互
Ctrl + c 退出交互
ollama默认端口:11434
API与JSON
- API(Application Programming Interface)应用程序接口
软件系统之间相互通信和交互的桥梁
它定义了一组规则和协议,允许不同的应用程序、服务或组件交换数据和功能
工作原理:请求(request)与 响应(response)
- JSON(Javascript Object Notation)一种轻量级的数据交互格式
用于在不同系统之间传输和存储结构化数据
其格式为 列表与字典 的 嵌套组合
{
'messages': [
{
'role': 'user',
'content': 'prompt'
}
],
'format': 'laborum magna laboris pariatur',
'stream': false
}Apifox
一款集 API 设计、开发、测试、文档、Mock 和协作 于一体的全流程 API 工具
调试模式下 POST 聊天对话接口中的预览文档中可以查看请求中应该包含的必须与可选参数
model(string)(必须) # 模型名称
messages(array)(必须)
role(string)(必须) # 角色 system(一般不是)、user(用户)、assistant(助手)
content(string)(必须) # 内容
images(string)(可选) # 图像
format(string)(可选) # 响应格式
stream(boolean)(可选) # 是否流式生成 False代表一次性生成
请求 中 自动生成,会依据 预览文档 生成 请求体
根据自身需求修改参数值:model、role、content等
开发环境 —> 前置URL:http://127.0.0.1:11434(ollama默认端口)
发送之后即可将 请求 即 messages中role为user的content内容 发送给 ollama 从而调用本地已安装的大模型进行解析 并传回 响应 即 messages中role为assistant的content内容
Streamlit
一个用于快速构建 数据科学和机器学习 Web前端 应用 的 Python框架
无需前端知识(HTML/CSS/JS),只需几行Python代码即可创建可视化交互式工具
- 安装streamlit库
Anaconda Promp命令窗口 或 Python终端输入:
pip install streamlit # 默认从外网安装最新版streamlit
pip install streamlit==1.32.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
# “==”后跟版本号 # “-i”后跟国内镜像地址
安装完成后输入 strealit hello 查看是否成功
成功之后即可 导包 import streamlit as st
- streamlit 常用函数
(1)st.title('str') 设置主标题内容
(2)其余标题
"# 1级标题" "## 2级标题" "### 3级标题"
"#### 4级标题" "##### 5级标题" "###### 6级标题"
也可以用write()或markdown()函数包裹,效果一致。没有7级标题
(3)st.write('str') 写页面段落内容 段落就是 `HTML` 里的 `<p>` 元素
(4)st.markdown('str') 写段落内容,特定情况下(输出格式问题)较上者效果好
(5)st.image('directory', width=num) 前端输出图片
directory是图片路径 width设置图片宽度,其 高 会等比缩放
(6)st.divider() 分割线
(7)表格
st.table(dict) 静态表格(字典+列表)
st.table({ 'name': ['Tom', 'Alice', 'John'], 'age': [18, 20, 22], 'phone': ['123', ‘456', '789'] })
st.dataframe(dict) 可交互列表(字典+列表)
写法同上,但`st.dataframe()` 创建出来的表格支持按列排序、搜索、导出等功能
dateframe格式:
上述两个函数中除了可以传入格式为字典嵌套列表的数据外
还可以传入`pandas` 的 `DataFrame`格式
import pandas as pd
df = pd.DataFrame({
'name': ['Tom', 'Alice', 'John'],
'age': [18, 20, 22],
'phone': ['123', ‘456', '789']
})
st.table(df)(8)输入框
st.text_input() 普通输入框
st.number_input('str', min_value=0, max_value=100, value=18, step=1) 数字
st.text_area() 多行文本输入框
可以定义变量接受用户在文本框中的输入 用 if 判断其是否为空,不为空时才在前端显示
(9)Chat Elements
Chat文本输入框 st.chat_input()
创建一个聊天输入框,提示用户输入问题
Chat Message st.chat_message()
创建一个用户消息容器,用于显示用户的消息
with st.chat_message('user'):
st.write('Hello AI')message = st.chat_message('assistant')
message.write('Hello Human')简化写法:
st.message('role').write('str')Python实现聊天机器人
ollama后端模块 Chat_Ollama_BanckEnd.py
import ollama #导入ollama库
def get_response(prompt): # 定义函数,传入用户输入的 请求,获取 响应
# response = ollama.chat(model='deepseek-r1:8b', messages=[{'role': 'user', 'content': prompt}]) # 使用函数ollama.chat(),传入参数model与messages,用response变量接收获取到的响应
response = ollama.chat(model='deepseek-r1:8b', messages=prompt[-30:]) # 因为当Chat_Streamlit_Oreration.py模块调用此函数时,传入的prompt字典已经包含了‘role’与‘content'键值对,所以直接将prompt传给参数messages即可
return response['message']['content'] # ollama.chat() 函数得到是包含了‘model’与‘messages’元素的列表,而‘messages’是包含了多组‘role’与‘content’的字典,所以用response['message']['content']逐级取出“content‘关键字的值
if __name__ == '__main__': # 测试函数,只有’name‘属性为’main‘时才会执行,即在当前模块(.py文件)中运行时才会执行以下代码
prompt = 'What features do you have?' # 定义变量prompt的值用于测试
response_result = get_response(prompt) # 用变量result_response接受get_response()函数得到的“content‘关键字的值
print(response_result) # 在控制台输出结果streamlit前端模块 Chat_Streamlit_Operation.py
import streamlit as st # 导入streamlit库
from Chatbots_BackEnd import get_response # 从Chat_Ollama_BanckEnd模块中导入get_response函数
from langchain.memory import ConversationBufferMemory # langchain.memory库中导入ConversationBufferMemory函数
st.title('K·D ChatBots') # 前端输出主标题'K·D ChatBots‘
st.divider() # 前端输出分割线
if 'memory' not in st.session_state: # 判断:如果‘memory’不在st.session_state列表中,则执行:
# st.session_state.memory = ConversationBufferMemory()
# st.session_state.messages = [{'role': 'assistant or user', 'content': 'Content_Information'}]
st.session_state['memory'] = ConversationBufferMemory() # 用ConversationBufferMemory()函数创建st.session_state.memory
st.session_state['messages'] = [{'role': 'assistant',
'content': "Hello, I'm KD chatbots, your work assistant, how can I help you"}] # 将参数赋值给st.session_state列表中的‘messages’字典 所以st.session_state.messages也可以写成st.session_state['messages']
for message in st.session_state.messages: # 遍历st.session_state列表中的‘messages’字典,用临时变量message逐个取出并存储
with st.chat_message(message['role']): # 前端输出对话文本框,角色在‘user’与‘assistant’间切换
st.markdown(message['content']) # 对话文本框中输出‘user’或‘assitant’的‘cont’值
prompt = st.chat_input('Please enter your question:') # 前端界面底部输出对话文本框提示用户输入问题并用变量prompt接受
if prompt: # 判断:如果prompt不为空,则执行:
# st.session_state.messages.append({'role': 'user', 'content': prompt})
st.session_state['messages'].append({'role': 'user', 'content': prompt}) # 将用户输入的内容追加到st.session_state列表的messages字典中
st.chat_message('user').markdown(prompt) # 前端输出对话文本框,角色为用户,内容为‘prompt
# msg_us = st.chat_message('user')
# msg_us.markdown(prompt)
with st.spinner('K·D assistant is thinking'): # 前端输出”正在思考中“的提示
result_response = get_response(st.session_state.messages) # 调用get_response函数,传入刚刚用户输入的内容,调用底层模型分析,获取响应
# st.session_state.messages.append({'role': 'assistant', 'content': result_response})
st.session_state['messages'].append({'role': 'assistant', 'content': result_response}) # 将得到的响应追加到st.session_state列表的messages字典中,角色为assistant,内容为result_response接受到的get_response函数的返回值response['messages']['content']
st.chat_message('assistant').markdown(result_response) # 前端输出对话文本框,角色为assistant,内容为result_response即response['messages']['content']
# msg_as = st.chat_message('assistant')
# msg_as.markdown(result_response)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)