非常简单!本地用 llama.cpp 部署deepseek并开启 API 流程
当然,如果是有ollama的话直接下载模型就好了,b站也有详细的教程,我只是学习如何用llama.cpp生成api接口供其他接口调用,后面打算学点模型微调,可以整个自己的模型玩玩。检查你的llama-server安装到哪了,本人安装到了build/bin下,输入下面指令的时候记得修改地址(你模型的地址和llama-server安装的地址)再看日志,模型已经完整加载,llama-server已经监听
有关llama.cpp下载等的步骤见作者之前的博客llama.cpp运行deepseek MOE 16b chat,此部分因为要用server,所以cmake的命令需要修改一下:
# 如果你已经按照我之前的方法cmake的话,需要重新build+cmake一下
cd ~/llama.cpp
rm -rf build
#重新建build
mkdir build
cd build
#之前的方法+用新的cuda编译
CC=gcc-11 CXX=g++-11 cmake -B build -DCMAKE_BUILD_TYPE=Release -DCMAKE_C_FLAGS="-DLLAMA_QKK_64=1" -DCMAKE_CXX_FLAGS="-DLLAMA_QKK_64=1" -DGGML_CUDA=on # 在llama.cpp目录下输入这段指令
cmake --build . -j #在build目录下输入这段指令等待一段时间,看到最后的打印结果如下则说明server正常安装
检查你的llama-server安装到哪了,本人安装到了build/bin下,输入下面指令的时候记得修改地址(你模型的地址和llama-server安装的地址)
./bin/llama-server -m /ssd/users/wxy/llama.cpp/models/deepseek-moe-16b-chat-q8_0.gguf --port 8000 --host 0.0.0.0 -ngl 20解释一下port、host和ngl是什么:
m为指定模型路径,port为指定端口(我这里直接写 8000了),host设为0.0.0.0表示允许外部访问,最后ngl 20表GPU层数(根据显存调整,越大越多层放进 GPU)
确认无误后敲回车,我得到了下述内容(你可以和我的对比一下,按理来说照着流程走没有问题)
(torchenv) wxy@YUSN01:~/llama.cpp/build$ ./bin/llama-server -m /ssd/users/wxy/llama.cpp/models/deepseek-moe-16b-chat-q8_0.gguf --port 8000 --host 0.0.0.0 -ngl 20
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 3 CUDA devices:
Device 0: NVIDIA GeForce RTX 3090, compute capability 8.6, VMM: yes
Device 1: NVIDIA GeForce RTX 3090, compute capability 8.6, VMM: yes
Device 2: NVIDIA GeForce RTX 3090, compute capability 8.6, VMM: yes
build: 5891 (0d922676) with gcc-11 (Ubuntu 11.4.0-2ubuntu1~18.04) 11.4.0 for x86_64-linux-gnu
system info: n_threads = 40, n_threads_batch = 40, total_threads = 80
system_info: n_threads = 40 (n_threads_batch = 40) / 80 | CUDA : ARCHS = 500,610,700,750,800,860,890 | USE_GRAPHS = 1 | PEER_MAX_BATCH_SIZE = 128 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | BMI2 = 1 | AVX512 = 1 | AVX512_VNNI = 1 | LLAMAFILE = 1 | OPENMP = 1 | REPACK = 1 |
main: binding port with default address family
main: HTTP server is listening, hostname: 0.0.0.0, port: 8000, http threads: 79
main: loading model
srv load_model: loading model '/ssd/users/wxy/llama.cpp/models/deepseek-moe-16b-chat-q8_0.gguf'
llama_model_load_from_file_impl: using device CUDA0 (NVIDIA GeForce RTX 3090) - 23906 MiB free
llama_model_load_from_file_impl: using device CUDA1 (NVIDIA GeForce RTX 3090) - 23906 MiB free
llama_model_load_from_file_impl: using device CUDA2 (NVIDIA GeForce RTX 3090) - 23906 MiB free
llama_model_loader: loaded meta data with 39 key-value pairs and 363 tensors from /ssd/users/wxy/llama.cpp/models/deepseek-moe-16b-chat-q8_0.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = deepseek
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = Deepseek Moe 16b Chat
llama_model_loader: - kv 3: general.finetune str = chat
llama_model_loader: - kv 4: general.basename str = deepseek-moe
llama_model_loader: - kv 5: general.size_label str = 16B
llama_model_loader: - kv 6: general.license str = other
llama_model_loader: - kv 7: general.license.name str = deepseek
llama_model_loader: - kv 8: general.license.link str = https://github.com/deepseek-ai/DeepSe...
llama_model_loader: - kv 9: deepseek.block_count u32 = 28
llama_model_loader: - kv 10: deepseek.context_length u32 = 4096
llama_model_loader: - kv 11: deepseek.embedding_length u32 = 2048
llama_model_loader: - kv 12: deepseek.feed_forward_length u32 = 10944
llama_model_loader: - kv 13: deepseek.attention.head_count u32 = 16
llama_model_loader: - kv 14: deepseek.attention.head_count_kv u32 = 16
llama_model_loader: - kv 15: deepseek.rope.freq_base f32 = 10000.000000
llama_model_loader: - kv 16: deepseek.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 17: deepseek.expert_used_count u32 = 6
llama_model_loader: - kv 18: deepseek.rope.dimension_count u32 = 128
llama_model_loader: - kv 19: deepseek.rope.scaling.type str = none
llama_model_loader: - kv 20: deepseek.leading_dense_block_count u32 = 1
llama_model_loader: - kv 21: deepseek.vocab_size u32 = 102400
llama_model_loader: - kv 22: deepseek.expert_feed_forward_length u32 = 1408
llama_model_loader: - kv 23: deepseek.expert_weights_scale f32 = 1.000000
llama_model_loader: - kv 24: deepseek.expert_count u32 = 64
llama_model_loader: - kv 25: deepseek.expert_shared_count u32 = 2
llama_model_loader: - kv 26: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 27: tokenizer.ggml.pre str = deepseek-llm
llama_model_loader: - kv 28: tokenizer.ggml.tokens arr[str,102400] = ["!", "\"", "#", "$", "%", "&", "'", ...
llama_model_loader: - kv 29: tokenizer.ggml.token_type arr[i32,102400] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 30: tokenizer.ggml.merges arr[str,99757] = ["Ġ Ġ", "Ġ t", "Ġ a", "i n", "h e...
llama_model_loader: - kv 31: tokenizer.ggml.bos_token_id u32 = 100000
llama_model_loader: - kv 32: tokenizer.ggml.eos_token_id u32 = 100001
llama_model_loader: - kv 33: tokenizer.ggml.padding_token_id u32 = 100001
llama_model_loader: - kv 34: tokenizer.ggml.add_bos_token bool = true
llama_model_loader: - kv 35: tokenizer.ggml.add_eos_token bool = false
llama_model_loader: - kv 36: tokenizer.chat_template str = {% if not add_generation_prompt is de...
llama_model_loader: - kv 37: general.quantization_version u32 = 2
llama_model_loader: - kv 38: general.file_type u32 = 7
llama_model_loader: - type f32: 84 tensors
llama_model_loader: - type q8_0: 279 tensors
print_info: file format = GGUF V3 (latest)
print_info: file type = Q8_0
print_info: file size = 16.21 GiB (8.51 BPW)
load: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
load: special tokens cache size = 15
load: token to piece cache size = 0.6408 MB
print_info: arch = deepseek
print_info: vocab_only = 0
print_info: n_ctx_train = 4096
print_info: n_embd = 2048
print_info: n_layer = 28
print_info: n_head = 16
print_info: n_head_kv = 16
print_info: n_rot = 128
print_info: n_swa = 0
print_info: is_swa_any = 0
print_info: n_embd_head_k = 128
print_info: n_embd_head_v = 128
print_info: n_gqa = 1
print_info: n_embd_k_gqa = 2048
print_info: n_embd_v_gqa = 2048
print_info: f_norm_eps = 0.0e+00
print_info: f_norm_rms_eps = 1.0e-06
print_info: f_clamp_kqv = 0.0e+00
print_info: f_max_alibi_bias = 0.0e+00
print_info: f_logit_scale = 0.0e+00
print_info: f_attn_scale = 0.0e+00
print_info: n_ff = 10944
print_info: n_expert = 64
print_info: n_expert_used = 6
print_info: causal attn = 1
print_info: pooling type = 0
print_info: rope type = 0
print_info: rope scaling = none
print_info: freq_base_train = 10000.0
print_info: freq_scale_train = 1
print_info: n_ctx_orig_yarn = 4096
print_info: rope_finetuned = unknown
print_info: model type = 20B
print_info: model params = 16.38 B
print_info: general.name = Deepseek Moe 16b Chat
print_info: n_layer_dense_lead = 1
print_info: n_ff_exp = 1408
print_info: n_expert_shared = 2
print_info: expert_weights_scale = 1.0
print_info: vocab type = BPE
print_info: n_vocab = 102400
print_info: n_merges = 99757
print_info: BOS token = 100000 '<|begin▁of▁sentence|>'
print_info: EOS token = 100001 '<|end▁of▁sentence|>'
print_info: EOT token = 100001 '<|end▁of▁sentence|>'
print_info: PAD token = 100001 '<|end▁of▁sentence|>'
print_info: LF token = 185 'Ċ'
print_info: EOG token = 100001 '<|end▁of▁sentence|>'
print_info: max token length = 256
load_tensors: loading model tensors, this can take a while... (mmap = true)
load_tensors: offloading 20 repeating layers to GPU
load_tensors: offloaded 20/29 layers to GPU
load_tensors: CPU_Mapped model buffer size = 4682.48 MiB
load_tensors: CUDA0 model buffer size = 4172.33 MiB
load_tensors: CUDA1 model buffer size = 4172.33 MiB
load_tensors: CUDA2 model buffer size = 3576.28 MiB
..........................................................................................
llama_context: constructing llama_context
llama_context: n_seq_max = 1
llama_context: n_ctx = 4096
llama_context: n_ctx_per_seq = 4096
llama_context: n_batch = 2048
llama_context: n_ubatch = 512
llama_context: causal_attn = 1
llama_context: flash_attn = 0
llama_context: freq_base = 10000.0
llama_context: freq_scale = 1
llama_context: CPU output buffer size = 0.39 MiB
llama_kv_cache_unified: CPU KV buffer size = 256.00 MiB
llama_kv_cache_unified: CUDA0 KV buffer size = 224.00 MiB
llama_kv_cache_unified: CUDA1 KV buffer size = 224.00 MiB
llama_kv_cache_unified: CUDA2 KV buffer size = 192.00 MiB
llama_kv_cache_unified: size = 896.00 MiB ( 4096 cells, 28 layers, 1 seqs), K (f16): 448.00 MiB, V (f16): 448.00 MiB
llama_kv_cache_unified: LLAMA_SET_ROWS=0, using old ggml_cpy() method for backwards compatibility
llama_context: CUDA0 compute buffer size = 416.50 MiB
llama_context: CUDA1 compute buffer size = 172.25 MiB
llama_context: CUDA2 compute buffer size = 172.25 MiB
llama_context: CUDA_Host compute buffer size = 16.01 MiB
llama_context: graph nodes = 1662
llama_context: graph splits = 122 (with bs=512), 5 (with bs=1)
common_init_from_params: setting dry_penalty_last_n to ctx_size = 4096
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
srv init: initializing slots, n_slots = 1
slot init: id 0 | task -1 | new slot n_ctx_slot = 4096
main: model loaded
main: chat template, chat_template: {% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{{ bos_token }}{% for message in messages %}{% if message['role'] == 'user' %}{{ 'User: ' + message['content'] + '
' }}{% elif message['role'] == 'assistant' %}{{ 'Assistant: ' + message['content'] + eos_token }}{% elif message['role'] == 'system' %}{{ message['content'] + '
' }}{% endif %}{% endfor %}{% if add_generation_prompt %}{{ 'Assistant:' }}{% endif %}, example_format: 'You are a helpful assistant
User: Hello
Assistant: Hi there<|end▁of▁sentence|>User: How are you?
Assistant:'
main: server is listening on http://0.0.0.0:8000 - starting the main loop
srv update_slots: all slots are idle 再看日志,模型已经完整加载,llama-server已经监听在http://0.0.0.0:8000上了,这说明服务端正常运行,只等你发请求了。
再看日志,模型已经完整加载,llama-server已经监听在http://0.0.0.0:8000上了,这说明服务端正常运行,只等你发请求了。
在vscode中新增一个终端,输入下述代码开始测试。
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-moe-16b-chat-q8_0",
"messages": [
{"role": "user", "content": "你好,介绍一下你自己"}
],
"temperature": 0.7,
"max_tokens": 2000
}'敲击回车后右下角会显示这个提示,我们点击在浏览器中打开。
打开后页面是这样
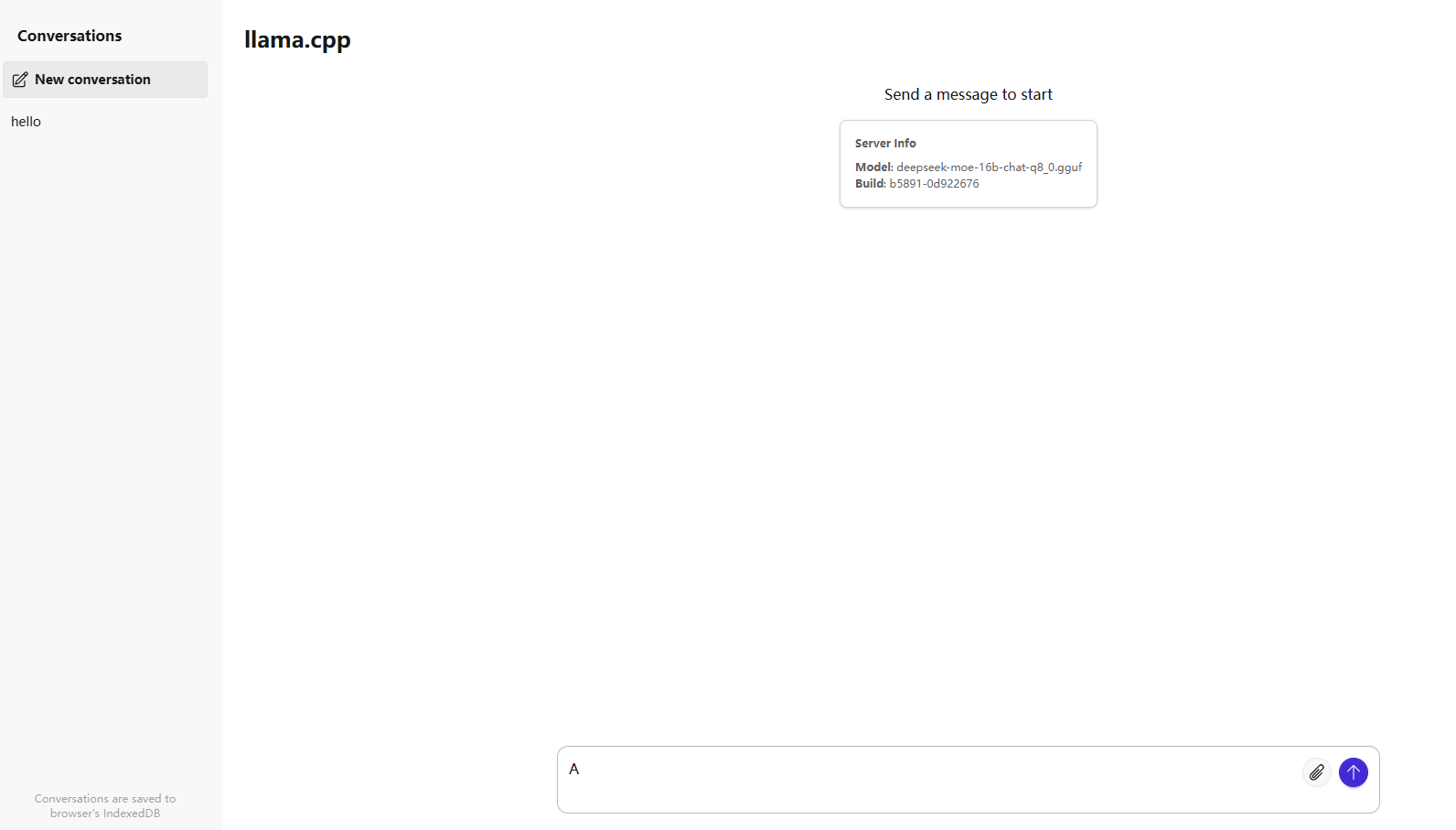
你可以和模型自由对话了!

当然,如果是有ollama的话直接下载模型就好了,b站也有详细的教程,我只是学习如何用llama.cpp生成api接口供其他接口调用,后面打算学点模型微调,可以整个自己的模型玩玩。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)