笔记DriveDreamerv1
DriveDreamer通过结合扩散模型和两阶段训练流程,成功地从真实世界驾驶场景中构建了世界模型。创新之处在于首次将扩散模型应用于真实世界的自动驾驶任务中,提高了驾驶视频生成和驾驶策略预测的质量和可控性。应用前景:为自动驾驶系统的训练和优化提供了新的方法和思路,特别是在处理复杂和多样化的驾驶场景时具有优势。
DriveDreamer: Towards Real-world-driven World Models for Autonomous Driving
基础理解
世界模型:
能通过视频生成的方式来理解驾驶场景,并能根据输入的控制条件预测未来的演化,最终可以生成不同传感器对未来场景的观测数据
生成式模型在自动驾驶中的应用:
- 数据仿真,闭环评测
- 数据增强辅助感知任务训练
- 通过生成建模获得更好的视觉表征
总体概括
目标:开发一个基于真实世界驾驶场景的世界模型,用于自动驾驶中的高质量驾驶视频生成和驾驶策略预测。
创新点:首次从真实世界驾驶场景构建世界模型,利用扩散模型(diffusion model)和两阶段训练流程。
实现的功能:
- 通过**交通条件(连续的HDmap,3Dbox)**和不同的文本提示词(天气,风格,光照,时间等)生成驾驶场景视频(没有预测未来)
- 通过初始的交通条件和图像,根据设定的未来驾驶动作,生成对应驾驶动作的驾驶视频(根据未来动作预测未来视频)
- 通过初始的交通条件,图像,驾驶动作,生成预测未来的驾驶视频(预测未来视频和动作)
思维导图结构
1. 引言 (Introduction)
背景:自动驾驶依赖于对真实驾驶世界的理解和建模。
问题:现有研究多集中于游戏或模拟环境,缺乏对真实世界驾驶场景的表示。
方法:提出DriveDreamer,利用扩散模型构建复杂驾驶环境的全面表示。
2. 相关工作 (Related Work)
扩散模型 (Diffusion Model)
定义:通过逐步引入噪声并学习逆转过程来生成样本的模型。
相关例子:BEVControl ,MagicDrive and DrivingDiffuson
应用:在图像合成、视频生成等领域表现出色。
视频生成 (Video Generation)
方法:包括变分自编码器(VAEs)、自回归模型、基于流的模型和生成对抗网络,视频扩散模型等。
特点:扩散模型在视频生成中表现出更高的质量和可控性。
世界模型 (World Models)
应用:在基于模型的模仿学习中取得成功。
相关例子:ISO-Dream, MILE, SEM2
挑战:真实世界驾驶任务的高样本复杂性。
3. DriveDreamer框架 (DriveDreamer Framework)
总体框架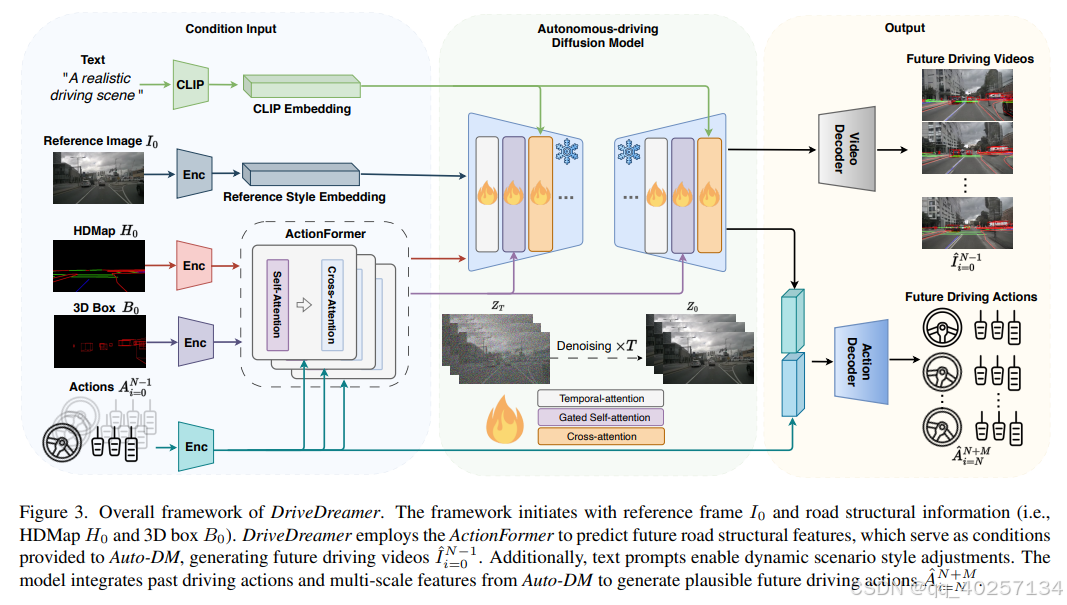
输入:初始参考帧、道路结构信息(HDMap和3D框)。
输出:
-
未来驾驶视频
-
驾驶策略(根据之前的action编码和Auto-DM生成的多模态特征concat后进MLPdecode输出)。
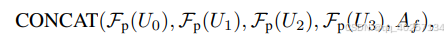
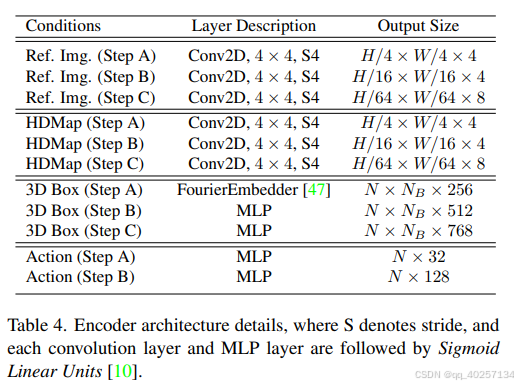
上图为各种input对应encoder的结构
两阶段训练流程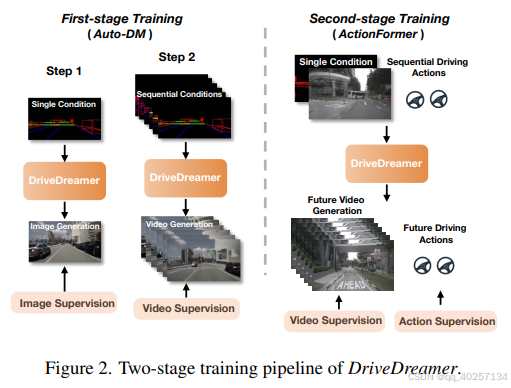
4. 自动驾驶扩散模型 (Autonomous-driving Diffusion Model, Auto-DM)
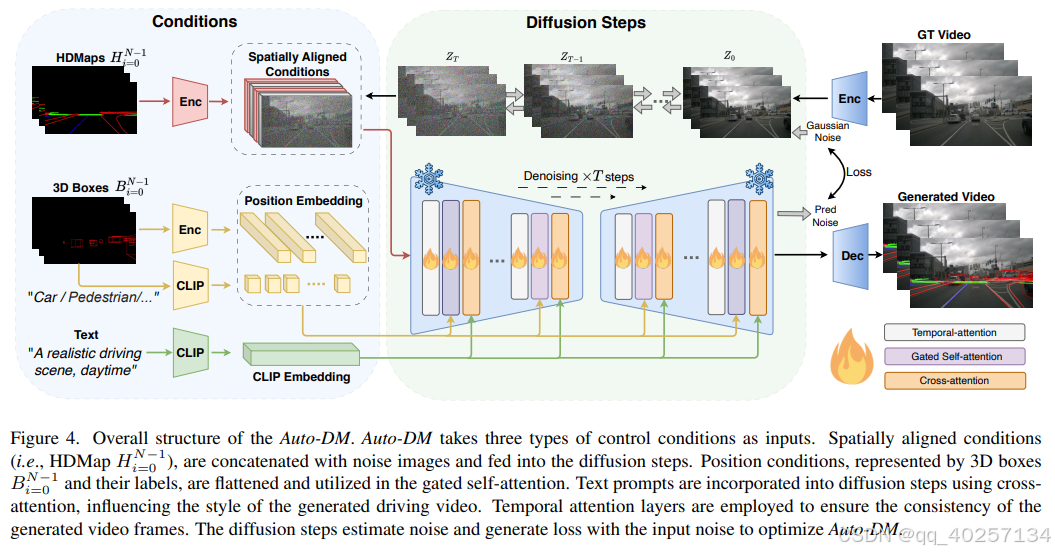
结构
输入:
- HDMap(cnn encode) + 带噪音的图像特征(原始图像encode后加T次同一个高斯噪音)-》spatially aligned conditions-》直接送入stable diffusion(v1.4)
- 3dBox(encode) + 对应labels(clip encode)-》mlp-》geted-self-attention(紫色attention层)
- 文本提示 -》 clip encode -》cross-attention(橙色attention层)
loss:预测noise和开始添加的noise的对比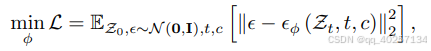
输出:生成符合结构化交通约束的驾驶视频。
训练
第一阶段训练
数据集:nuScenes-devkit-》HDmap,
Are we ready for vision-centric driving streaming perception? the
asap benchmark.-》3dbox
step1
训练超参:40epo 16 batchsize
目标:理解结构化交通约束。
方法:使用单帧结构化条件进行图像生成训练,忽略时间注意力层。
step2
训练超参:10epo 1 batchsize
目标:理解结构化交通约束并拓展至视频生成。
方法:使用连续结构化条件进行视频生成训练,加入时间注意力层。
5. 行动预测器 (ActionFormer)
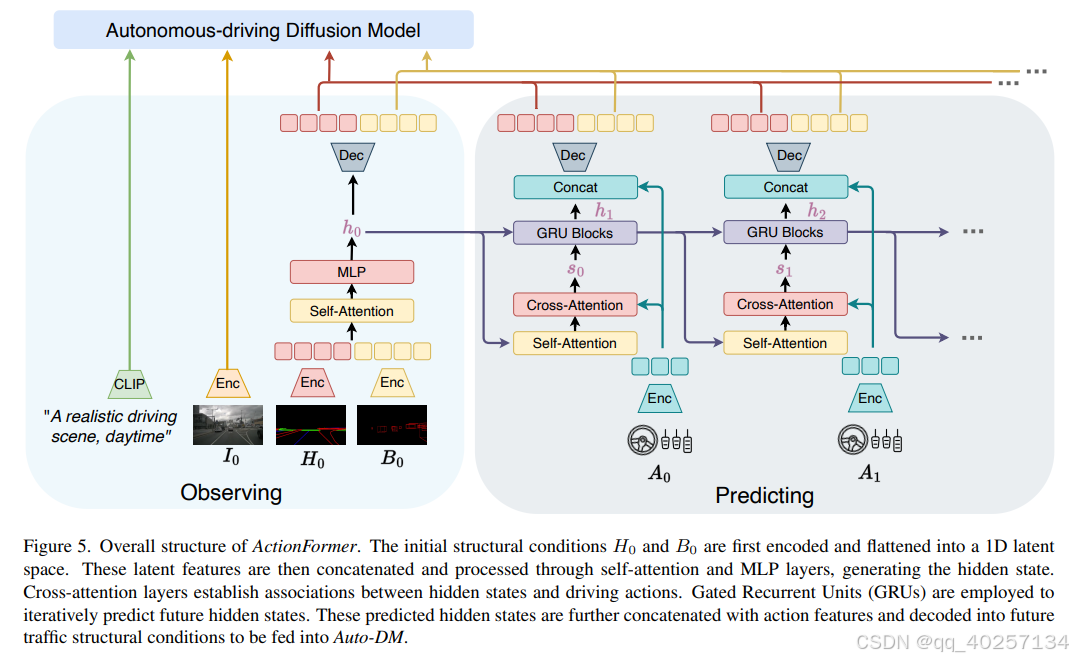
结构
输入:初始结构化条件和驾驶动作。
处理:通过自注意力、交叉注意力和GRU单元预测未来交通结构条件。
loss:MSE L1loss
输出:生成合理的未来驾驶动作,和输入驾驶动作对应的图像。
训练
第二阶段训练
数据集:yaw angle and velocity of the ego-car
训练超参:10epo 1 batchsize 根据前16个动作预测对应16帧图像和未来的16帧动作
目标:预测未来状态和驾驶策略。
方法:结合初始帧,连续驾驶动作,Auto-DM的多尺度特进行视频预测训练。
6. 实验 (Experiment)
数据集:nuScenes数据集,包含700个训练视频和150个验证视频。
训练细节:使用AdamW优化器进行训练,具体参数设置。
评估
视频生成质量:使用FID和FVD指标评估。
驾驶感知方法训练:通过3D目标检测任务验证生成图像的有效性。
驾驶策略生成:在nuScenes数据集上进行开环评估。
7. 结论 (Conclusion)
贡献:DriveDreamer在真实世界驾驶场景的世界建模中取得了显著进展。
未来方向:强调真实世界表示在自动驾驶中的重要性,为未来研究提供方向。
总结
DriveDreamer通过结合扩散模型和两阶段训练流程,成功地从真实世界驾驶场景中构建了世界模型。
创新之处在于首次将扩散模型应用于真实世界的自动驾驶任务中,提高了驾驶视频生成和驾驶策略预测的质量和可控性。
应用前景:为自动驾驶系统的训练和优化提供了新的方法和思路,特别是在处理复杂和多样化的驾驶场景时具有优势。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)