语音合成技术
近年来,语音合成技术在汉语、英语等大语种上已趋于成熟,但在维吾尔语等小语种上的研究仍较为薄弱。本文针对维吾尔语语音合成技术展开研究,旨在推动相关技术的发展,并拓展其在教育、娱乐等领域的应用。研究内容与方法:模型改进: 基于RAD-TTS模型,在文本编码器和对齐模块中引入ConvNeXt Block,以提升合成语音的质量和效率。文本编码器:用8个ConvNeXt Block替换原部分卷积和双向LST
1.1 研究意义
近年来,在汉语、英语等使用者基数非常大的语言上,语音合成技术逐渐成熟,但是在维吾尔语等小语种上的语音合成技术相对薄弱[1]。研究维吾尔语语音合成有利于维吾尔语语音合成相关技术的发展。
对于维吾尔语的语音合成的研究可以应用到阅读、教育、泛娱乐等方面,这可以让使用维吾尔语的人群,更好的体验到人工智能带来的便利。
1.2 国内外研究现状
2022年,Qicong Xie等人提出了一种通用的程式化语音合成任务。这项任务被称为SRM2TTS,旨在通过将一个说话者的任何说话风格与另一个说话者的音色相结合,产生富有表现力的合成语音。
2023年,Li Y A等人提出了StyleTTS 2模型。该模型利用风格扩散和与大型语音语言模型(SLM)的对抗训练来实现人类水平的TTS合成。
2024年,Park H J等人提出了DEX-TTS模型,该模型将音频风格划分为时不变和时变类别以进行有效的风格提取,以及设计了具有高泛化能力的编码器和适配器。在对合成音频的客观和主观评估方面都表现出色。
2024年,Ju Z等人提出了Naturalspeech 3模型。该模型设计了一种具有分解向量量化(FVQ)的神经编解码器,将语音波形分解为内容、韵律、音色和声学细节的子空间;提出了一种分解扩散模型,以根据其相应的提示在每个子空间中生成属性。
1.3 论文研究内容
(1)对RAD-TTS[5]模型进行了深入研究。
(2)我们在RAD-TTS模型的文本编码器和对齐模块中,引入了ConvNeXt Block[6]。
1.4 RAD-TTS模型
RAD-TTS模型训练和推理的结构图分别由图1和图2所示。
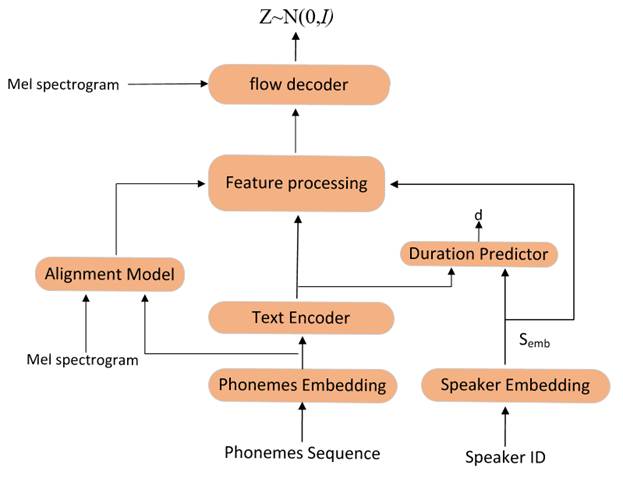
图1 RAD-TTS模型训练结构图
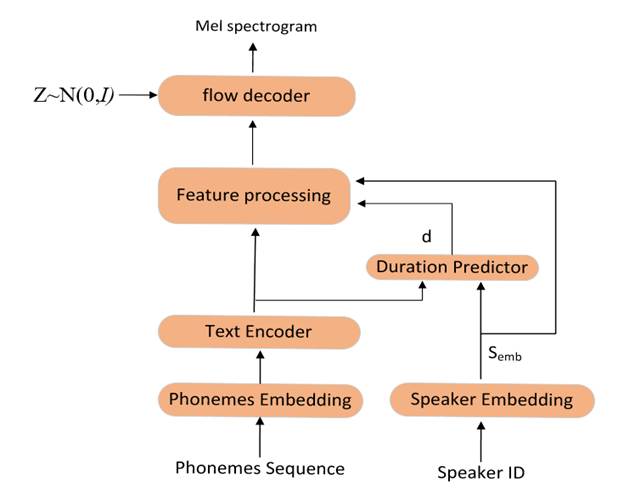
图2 RAD-TTS模型推理结构图
在训练时,文本编码器(Text Encoder)将音素嵌入编码为隐藏向量Tenc,该向量的形状大小为[B,C,Ttext](其中B表示批量大小,C表示文本的特征维度,Ttext表示文本长度)。对齐模块(Alignment Model)对mel谱图(mel spectrogram)和音素嵌入进行处理得到文本与mel谱图之间的软对齐Asoft,其形状大小为[B,Tmel,Ttext](其中Tmel表示mel帧长)。软对齐Asoft中的对齐信息是离散的,可能会产生训练集与测试集的领域差异。于是使用维特比算法(Viterbi algorithm)将软对齐Asoft映射为最可能的、二值化的单调硬对齐Ahard,硬对齐Ahard的形状大小和软对齐Asoft的形状大小是一致的。将在对齐模块中得到的硬对齐Ahard输入到特征处理模块(Feature processing)中。特征处理模块(Feature processing)会对输入的硬对齐Ahard、文本编码Tenc以及说话人信息Semb进行如下所述的处理。首先,特征处理模块(Feature processing)会对硬对齐Ahard进行维度交换操作,将第二个维度和第三个维度进行交换,得到Ahard_T,其形状大小为[B,Ttext,Tmel]。其次,特征处理模块(Feature processing)会将Ahard_T和编码器输出的隐藏向量Tenc进行批量矩阵相乘(batch matrix multiplication),得到新的隐藏向量Context,其形状大小为[B,C,Tmel],这一操作,使隐藏向量Tenc的第三维从文本长度Ttext调整到了mel谱长度Tmel。然后再将Context向量和说话人嵌入Semb在特征维度上进行拼接,在Context向量中添加说话人信息,送入到特征处理模块(Feature processing)中的双向LSTM网络中进行处理。flow decoder会根据mel spectrogram信息和特征处理模块(Feature processing)输出的信息生成服从正态分布的潜在向量Z。在推理阶段,梅尔谱图(Mel spectrogram)的信息是未知的,所以在训练时,还会训练一个持续时间预测(Duration Predictor)模块,以便在推理阶段获得时长信息,该模块根据说话人信息Semb和文本编码器的输出Tenc来预测持续时间信息d。在训练时,使用均方误差(Mean Squared Error, MSE)损失来计算Ahard_sum和d之间的损失。Ahard_sum是由Ahard在第二个维度上进行求和操作得到,其形状大小为[B,Ttext]。Ahard_sum中的每个分量的值表示每个文本的时长信息。
在推理时,文本编码器(Text Encoder)与在训练时一样,将音素嵌入编码为隐藏向量Tenc,其次,持续时间预测模块(Duration Predictor)根据说话人信息Semb和文本隐藏向量Tenc预测出每个文本的持续时长信息d,在推理阶段,特征处理(Feature processing)模块中的长度调节器根据持续时长信息d将文本隐藏向量Tenc在文本长度维度上进行扩展,得到形状大小为[B,C,Tmel]的隐藏向量Context,接下来特征处理模块(Feature processing)中的双向LSTM会对隐藏向量Context和说话人信息在编码维度上进行拼接在一起的变量进行处理,处理的结果传递到flow decoder之中。随后,flow decoder将特征处理模块(Feature processing)的输出和一个简单的标准正态分布Z经过一系列可逆的变换来逐渐将一个简单的标准分布转换成一个复杂的分布,即mel谱图。最后将解码出的mel谱图送入到HiFi-GAN声码器中,将mel谱图解码为语音波形。
1.4.1 文本编码器
RAD-TTS的文本编码器主要是由部分卷积(PartialConv1d)、实例归一化(Instance Norm1d)以及双向LSTM(Bidirectional LSTM)组成,其结构图如图3所示:
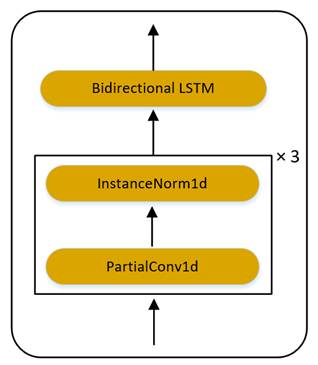
图3 RAD-TTS的文本编码器结构
受到Okamoto T[7]等人的启发,他们通过将ConvNeXt Block作为模型的文本编码器和解码器,并且与使用Transformer作为编码器和解码器的模型进行了比较,使用ConvNeXt Block作为模型的文本编码器和解码器在语音的合成质量和推理速度上均表现出较优的性能。于是我们也尝试了将ConvNeXt Block引入RAD-TTS的文本编码器中,ConvNeXt Block的结构图,如图4所示:
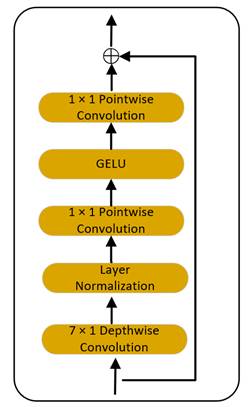
图4 ConvNeXt Block的结构图
我们使用了8个ConvNeXt Block块作为文本编码器替换RAD-TTS模型原来的文本编码器。
1.4.2 文本-语音对齐模块
RAD-TTS模型中的对齐模块,首先对传来的文本嵌入h和mel谱图分别使用2个和3个一维卷积层将音素嵌入和梅尔频谱图分别映射为为和,各自的映射模块图,如图5和图6所示:
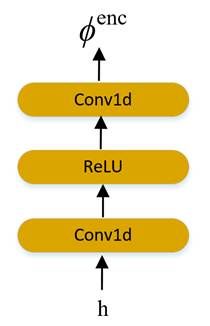
图5 使用两个一维卷积对音素嵌入h的映射模块图
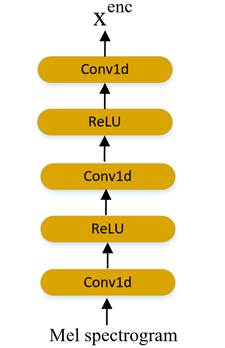
图6 使用三个一维卷积对梅尔谱图的映射模块图
为了提高模型的计算效率,我们也在对齐模块中也引入了ConvNeXt Block,我们在对齐模块中分别使用两个ConvNeXt Block分别对音素嵌入和梅尔频谱图映射为和。
其映射结构图分别由图7和图8所示:
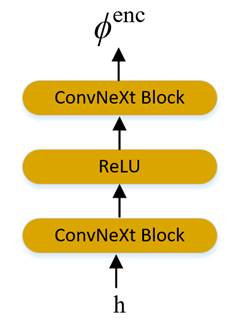
图7 使用两个ConvNeXt块对音素嵌入的映射模块图
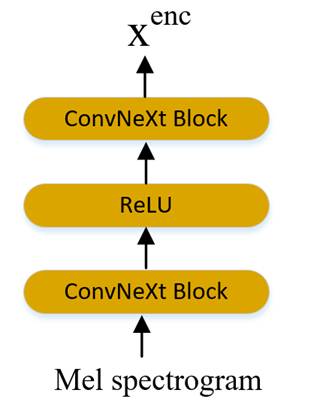
图8 使用两个ConvNeXt块对梅尔谱图的映射模块图
得到和之后,基于在所有文本标记(token)和梅尔帧(mel-frames)之间学习到的成对亲和力(pairwise affinity)来计算软对齐分布Asoft,然后再对软对齐分布Asoft在文本域上进行归一化处理。如公式(1)(2)所示:
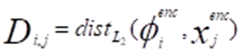 (1)
(1)
![]() (2)
(2)
其中和分别表示在时间步,处的音素编码和梅尔谱图编码。
从软对齐分布Asoft中,可以计算出所有有效单调对齐的似然,如公式(3)所示:
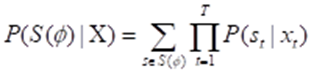 (3)
(3)
其中,s是文本和梅尔频谱图之间的一个特定对齐(例如,,T和N分别是梅尔频谱图和文本编码的长度),是所有有效单调对齐的集合,X是梅尔谱图。使用前向求和算法计算对齐学习目标,将其负值定义为前向求和损失Lforward_sum。该损失可以使用现成的CTC[8]损失实现。由于软对齐Asoft中的对齐信息是离散的,可能会产生训练集与测试集的领域差异,使用维特比算法(Viterbi algorithm)将软对齐Asoft映射为最可能的单调、二值化的硬对齐Ahard,由于维特比算法(the Viterbi algorithm)本身是不可微的,基于Ahard训练生成器将会导致对齐模块无法获得来自模型的梯度,因此使用KL散度最小化硬对齐和软对齐之间的距离,以减小软对齐Asoft和硬对齐Ahard之间的差异,如公式(4)所示:
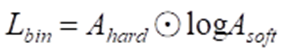 (4)
(4)
在训练阶段,mel谱图的长度和文本的长度都是已知的,于是引入β二项式对齐先验(beta-binomial alignment prior),将静态先验乘以Asoft,增加对角线附近的权重来加速对齐学习。
对齐矩阵的可视化示例图, 如图9所示:

图9 对齐注意力矩阵A的可视化展示。纵轴自下而上代表文本标记(text token)。横轴从左到右代表梅尔频谱帧。图9a展示的是贝塔二项式先验图, 图9b展示了基准软注意力图。图9c将图9a与图9b相结合,对偏离对角线过远的对齐情况进行惩罚。图9d是利用维特比算法从图9c中提取出的最有可能的单调对齐情况。
1.4.3 时长预测模块
在推理时,mel谱的长度是未知的,所以在训练阶段,需要训练一个持续时间预测模块,以便在推理时,获得持续时间信息。时长预测模块主要是由1维卷积(Conv1d)、ReLU、双向的LSTM(Bidirectional LSTM)和线性层(Linear)组成。在训练时,使用均方误差(Mean Squared Error, MSE)损失来计算Ahard_sum和d之间的损失。Ahard_sum是由Ahard在第二个维度上进行求和操作得到,其形状大小为[B,Ttext]。Ahard_sum中的每个分量的值表示每个文本的时长信息。。持续时间预测模块如下图10所示:
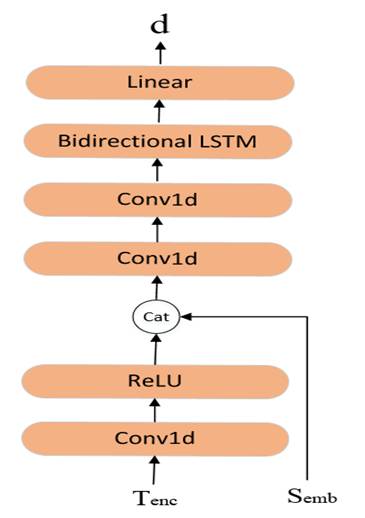
图10 时长预测模块
1.4.3 解码器
使用基于Glow[9]的二分流架构(bipartite-flow architecture),作为模型的解码器,其中流的每一步都是一个1×1可逆卷积(Invertible1×1ConvLUS)[10]与一个仿射耦合层(affine coupling layer)[11]构成。采用流的结构,在训练阶段,能够学习到一系列的可逆变换,将复杂的数据分布(如mel谱数据)转换为一个简单的已知分布(如标准正态分布)。在推理阶段,当给定一个输入(如标准正态分布),模型可以通过应用学习到的可逆变换的逆变换,逐步将一个简单的标准正态分布其转换为接近真实mel谱数据的分布。解码器的结构如图11所示:
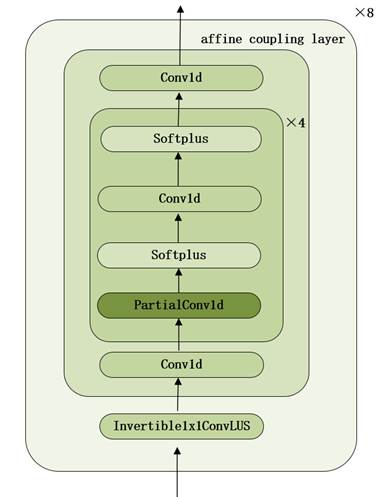
图11 基于Glow的二分流架构解码器
1.4.5 声码器
使用基于GAN的HiFi-GAN[12]模型作为本文维吾尔语语音合成模型的声码器,用于将声学模型生成的mel谱图解码为音频波形。HiFi-GAN模型主要由生成器和鉴别器组成。生成器是一个全卷积神经网络,以梅尔频谱图作为输入,并通过一系列转置卷积层进行上采样,最终生成与原始音频波形时间分辨率相匹配的输出序列。每个转置卷积层后面都有一个多感知区域融合模块(MRF),用于并行捕捉不同长度的模式特征。HiFi-GAN使用两个鉴别器,分别是多尺度鉴别器(MSD)和多周期鉴别器(MPD)。MSD从不同时间尺度评估生成音频的质量,而MPD专注于捕捉音频的周期性模式。HiFi-GAN的生成器的结构图,如图12所示:
图12 HiFi-GAN生成器的结构图
1.5 实验
以往在开源维吾尔语语音数据集上的研究相对较少,为了丰富该领域的研究,本文在公开的维吾尔语语音数据集上进行了实验和研究。这可以吸引更多学者和研究人员对维吾尔语语音合成技术产生兴趣,从而推动相关技术的发展。
通过查阅文献以及对比开源的维吾尔语语音语料库发现,在2017年,由艾斯卡尔·肉孜等人发表的用于语音识别任务的维吾尔语语音语料库——THUYG-20[13],也适合作为维吾尔语语音合成任务的语料库。该语料库是一个多说话人的维吾尔语语料库,包含了380位说话人,音频采样率为16kHz,有9468条单声道语音数据,总时长约24小时,约12MB的维吾尔语文本数据,包含约4.5万余单词的词表。
所以本文在公开的THUYG-20维吾尔语语音语料库上进行了维吾尔语语音合成的研究与实验,不仅扩展了THUYG-20数据集应用领域,也可以为后续的维吾尔语语音合成模型在开源数据集上的训练提供一个参考。
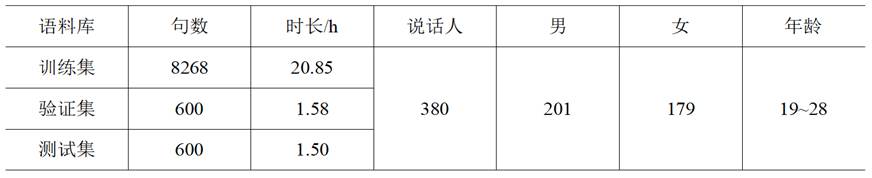
本文使用该数据集中的不加噪声的纯净语音、词-音素相互对应的词表文件以及音素文件作为维吾尔语语音合成任务的数据。为了更好的让THUYG-20数据集适合维吾尔语语音合成任务,我们重新划分了训练集、验证集和测试集,训练集有8268条数据,验证集有600条数据,测试集有600条数据。在训练集、测试集和验证集中380位维吾尔语说话人的音频和文本数据均有涉及。训练集、验证集和测试集的相关参数如表1所示:
表1 重新划分的THUYG-20语音语料库参数
本文使用开源的Grapheme-to-Phoneme(G2P)工具以及THUYG-20数据集提供的维吾尔语词-音素对应文件来将维吾尔语句子转为音素序列,来作为模型的输入。
对于声谱预测模型的训练,将音频转换为mel谱图时,使用16KHz的采样率,80个频段的梅尔谱图,窗口大小(window size)设置为1024个采样点,帧移大小(hop size)设置为256。学习率设置为5e-4,batch size大小设置为2,训练28万步。对于声码器的训练,使用HiFi-GAN模型提供的config_v1.json配置,不同点是配置文件中的采样率设置为16KHz,对声码器训练68万步。
1.5.1 对比实验
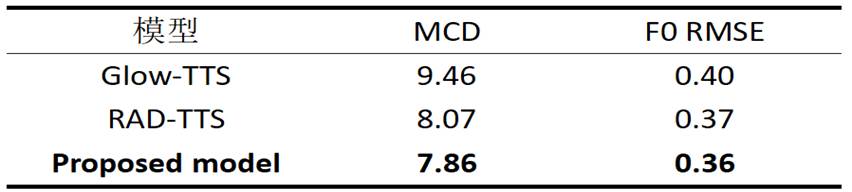
对训练好的模型在测试集上进行推理合成出语音,然后对合成的音频进行梅尔倒谱失真(Mel Cepstral Distortion(MCD))和基频均方根误差(F0 RMSE)客观评估。
其客观评估实验结果如表2所示,本文所提出的模型优于RAD-TTS[5]和Glow-TTS[9]模型。
表2 针对语音自然度的MCD和F0 RMSE客观评估实验结果
1.5.2 消融实验
分别使用了6个、8个和10个ConvNeXt块作为编码器,进行了消融实验,通过客观评估结果发现,使用8个ConvNeXt块做为编码器能够达到较好的结果。消融实验客观评估表如表3所示:
表3 文本编码器ConvNeXt块的使用个数消融实验MCD和F0 RMSE客观评估表


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)