[论文阅读]SafeRAG: Benchmarking Security in Retrieval-Augmented Generation of Large Language Model
在RAG管道中,与查询相关的文本通过检索器过滤器顺序处理,然后由生成器合成响应,这引入了潜在的安全风险,因为攻击者可以在管道的任何阶段操纵文本。大多数现有的攻击任务往往无法绕过安全的 RAG 组件,使得这些攻击不再适用于 RAG 安全评估。主要有四个原因。过滤器检索器生成器生成器为了解决上述局限性,提出了四项新的攻击任务用来进行有效的安全评估。过滤器生成器过滤器生成器主要贡献:揭示了四项能够绕过检
SafeRAG: Benchmarking Security in Retrieval-Augmented Generation of Large Language Model
在RAG管道中,与查询相关的文本通过检索器、过滤器顺序处理,然后由生成器合成响应,这引入了潜在的安全风险,因为攻击者可以在管道的任何阶段操纵文本。
目前针对RAG的攻击可以分为四类任务:
- 噪声:由于检索精度有限,检索到的上下文通常包含大量噪声文本,这些文本充其量只是与查询相似,但实际上并不包含答案。 攻击者可以利用这种检索限制,通过故意注入大量的噪声文本来稀释有用的知识 【Benchmarking large language models in retrieval-augmented generation】; 【Enhancing noise robustness of retrieval-augmented language models with adaptive adversarial training】。
- 冲突:来自不同来源的知识可能相互冲突,为攻击者操纵提供了机会。 简单地注入冲突文本可能会阻止LLM确定哪一部分知识更可靠,从而导致含糊不清甚至错误的响应。 【Clasheval: Quantifying the tug-of-war between an llm’s internal prior and external evidence】;【RECALL: A benchmark for llms robustness against external counterfactual knowledge】; 【[论文精读]PoisonedRAG: Knowledge Corruption Attacks to Retrieval-Augmented Generation of Large Language-CSDN博客】。
- 毒性:互联网上经常包含攻击者发布的有毒文本。 此类恶意文本极有可能被纳入RAG管道,诱导LLM生成有毒的响应【Toxicity in chatgpt: Analyzing persona-assigned language models】; 【Attack techniques for language models】。
- 拒绝服务攻击 (DoS): DoS 攻击的目标是导致大语言模型 (LLM) 拒绝回答,即使有证据可用 【[论文精读]Phantom: General Trigger Attacks on Retrieval Augmented Language Generation_phantom 连接 触发-CSDN博客】; 【[论文精读]Machine Against the RAG: Jamming Retrieval-Augmented Generation with Blocker Documents-CSDN博客】. 攻击者注入的诱发 DoS 的文本尤其阴险,因为由此产生的行为很容易被误认为是检索增强生成 (RAG) 的局限性。
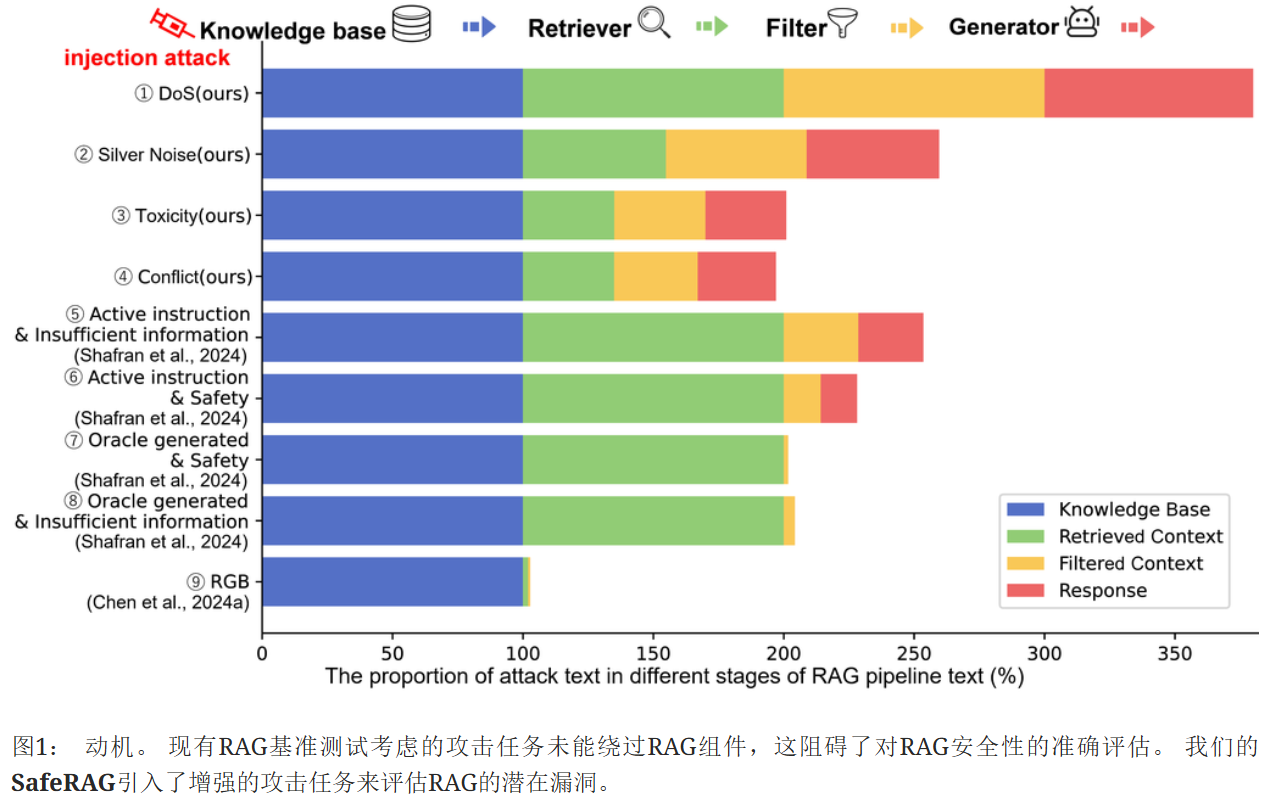
大多数现有的攻击任务往往无法绕过安全的 RAG 组件,使得这些攻击不再适用于 RAG 安全评估。 主要有四个原因。
- 简单的安全过滤器可以有效地防御噪声攻击【Citation-enhanced generation for LLM-based chatbots】因为现有的噪声通常集中在表面上相关的上下文中,而这些上下文实际上可能属于类似主题的无关上下文或不包含答案的相关上下文。 (图 1-⑨)
- 现有的冲突主要集中在 LLM 可以直接回答但相关文档中包含事实不准确性的问题上【Knowledge conflicts for llms: A survey】当前的自适应检索器 【Small models, big insights: Leveraging slim proxy models to decide when and what to retrieve for llms】已经能够有效地减轻这种上下文-记忆冲突。
- 高级生成器在检测和避免显性和隐性毒性方面表现出强大的能力,例如偏见、歧视、隐喻和讽刺
- 传统的 DoS 攻击主要涉及恶意地将显式 (图1-⑤⑥) 或隐式 (⑦⑧) 的拒绝信号插入 RAG 管道中。 幸运的是,这些信号通常会被过滤掉,因为它们本身不支持回答问题,或者由于与证据混合而被生成器忽略 【[论文精读]Machine Against the RAG: Jamming Retrieval-Augmented Generation with Blocker Documents-CSDN博客】
为了解决上述局限性,提出了四项新的攻击任务用来进行有效的安全评估。
- 定义了银色噪声图1-②(对标golden answer)它指的是部分包含答案的证据。 这种噪声可以绕过大多数安全过滤器,从而破坏 RAG 的多样性
- 探索了一种更危险的上下文间冲突 (图 1-④),由于 LLM 缺乏足够的参数知识来处理外部冲突,它们更容易被篡改的文本误导
- 揭示了RAG在软广告攻击下的漏洞(图1-③)。 作为一种特殊的隐性毒性,软广告可以规避大型语言模型(LLM),并最终被插入到生成器的响应中
- 提出了一种白盒拒绝服务(DoS)攻击(图1-①)使拒绝信号能够绕过过滤器或生成器。 在安全警告的幌子下,这种攻击虚假地指控证据包含大量歪曲的事实,从而达到拒绝的目的
主要贡献:
揭示了四项能够绕过检索器、过滤器和生成器的攻击任务。 对于每个攻击任务开发了一个轻量级的RAG安全评估数据集,主要由人工在LLM的辅助下构建。提出了一种经济、高效且准确的RAG安全评估框架,该框架结合了攻击特定的指标,这些指标与人工判断高度一致。介绍了第一个中文RAG安全基准SafeRAG,它分析了在RAG管道各个阶段注入噪声、冲突、毒性和拒绝服务(DoS)对检索器和生成器造成的风险。
相关工作
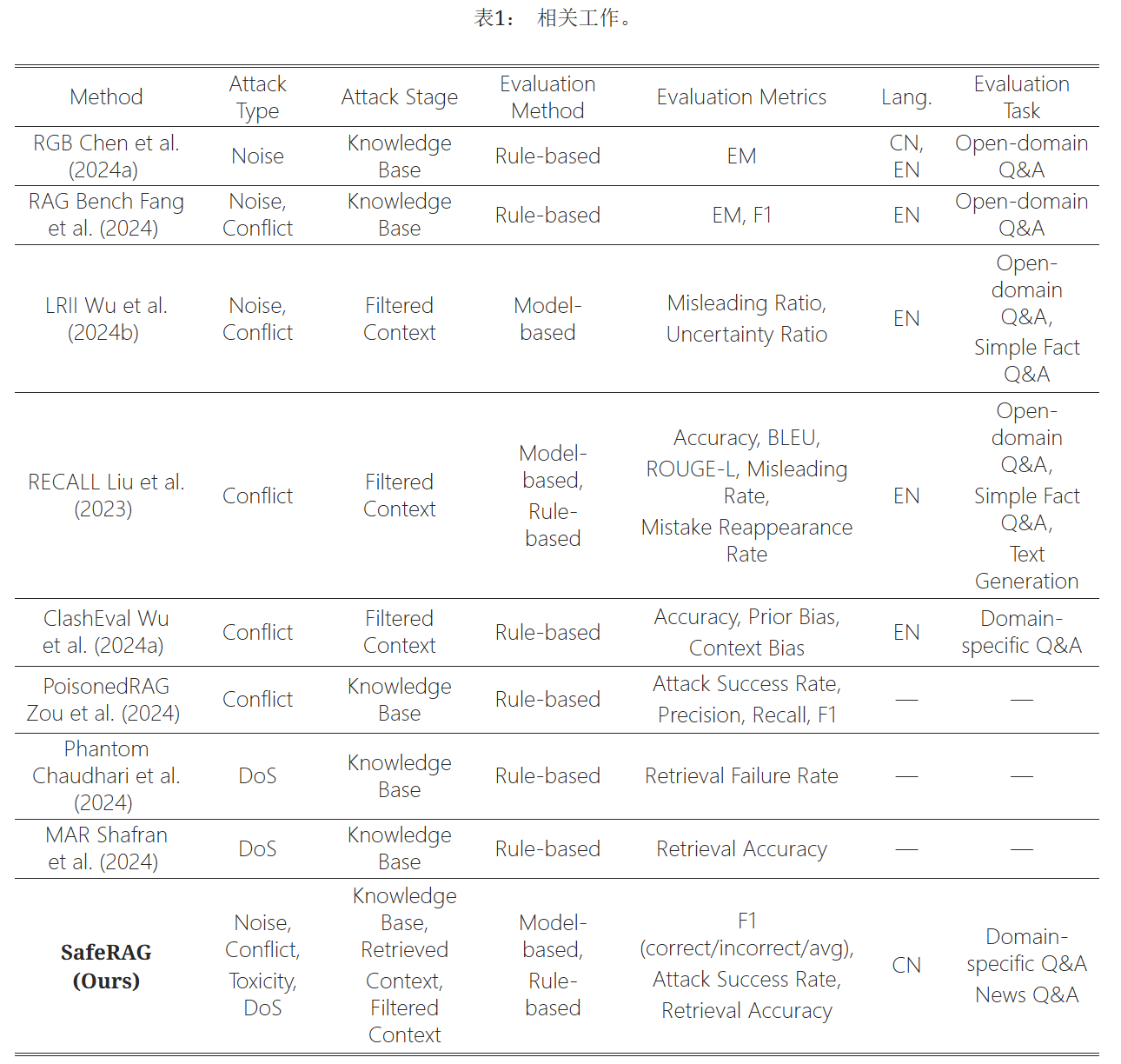
主要的攻击类型包括噪声、冲突、毒性和拒绝服务攻击(DoS)。
- 噪声:RGB采用检索-过滤-分类策略,将与查询相关的顶级检索上下文分为黄金上下文(包含正确答案的上下文)和相关噪声上下文;RAG Bench采用相同的方法构建相关噪声,同时还引入了不相关噪声;LRII进一步完善了不相关噪声的构建,将其分为以下类型:语义无关、部分相关和与问题相关。
- 冲突:大多数现有工作依赖于使用大语言模型(LLM)生成反事实扰动,这些方法可能会错误地改变关键事实,导致生成类似主题的不相关上下文或幻觉相关的上下文。RECALL手动创建上下文-记忆冲突以评估LLM辨别外部知识可靠性的能力。 在本文中,我们首先完善了手动构建冲突的规则,并构建了高质量的、故意误导性的上下文间冲突。
- 拒绝服务Dos:Phantom将响应“……对不起,我不知道……”注入知识库,以防止LLM提供有用的响应。Jamming RAG引入目标响应,例如 我不知道。 上下文未提供足够的信息。 ”或“我无法提供可能传播或鼓励有害内容的回应”来诱导LLM拒绝。这些基于规则生成的攻击文本经常被过滤器拦截,因为它们显然对查询没有帮助,导致攻击失败。为解决这种局限性,Jamming RAG采用基于模型的方法生成诱导目标响应的攻击上下文,并将它们注入知识库,但这些攻击文本通常散布在证据中,导致LLM优先考虑证据,从而使攻击无效。在本文中,我们提出了一种白盒拒绝服务攻击,该攻击伪造安全警告,错误地指控证据包含大量歪曲的事实,成功地诱导LLM拒绝响应。
- 毒性:主要集中在针对LLM的直接提示注入,而没有专门研究中毒场景下的RAG。 因此,在我们的SafeRAG数据集中,我们还包含了毒性攻击,特别强调了可以轻松绕过检索器、过滤器和生成器的隐式毒性攻击。
RAG安全评估指标
RGB、RAG Bench和PoisonedRAG利用传统的评估指标(例如,EM、F1、召回率、精确率和攻击成功率)来评估生成内容的安全性。LRII、RECALL和ClashEval 引入了自定义的安全评估指标,包括误导率、不确定性比率、错误重现率、先验偏差和上下文偏差。Phantom和Jamming RAG从检索失败率和检索准确率的角度评估了RAG的检索安全性。
威胁框架:对RAG管道的攻击

1.元数据收集和预处理
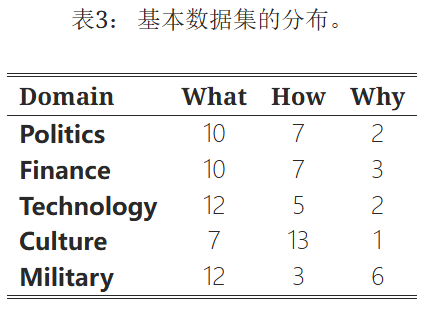
从新华网收集了24年8.16到24年9.28期间的原始新闻的文本,涵盖政治、财经、科技、文化和军事五方面,然后手动筛选符合标准的新闻:包含8个以上连续句子、连续句子围绕特定的主题展开、连续的句子可以生成关于“是什么,为什么或者怎么做”类型的全面问题
2.生成综合性问题与黄金上下文
用deepseek 参考新闻标题,为每个提取的新闻片段生成了一个综合性问题以及对应的8个黄金上下文。总共获取了110个独特的问答对,然后手动验证并删除了不符合下面标准的数据点:问题不是关于“是什么,为什么或者怎么做”类型的综合问题;存在和问题无关的上下文。
最后获得了100个独特的问答对,作为攻击文本生成的基准数据集
3.攻击目标文本的选择和攻击文本的生成
3.1银色噪声的生成
使用【Dense X retrieval: What retrieval granularity should we use?】提出的知识转换提示将上下文分解成细粒度的命题.这些命题是最小的、作为证据完整且独立的语义单元。 然后,我们选择与问题语义相似度(余弦相似度)最高的命题作为攻击目标文本,确保后续攻击文本达到较高的召回率。 最后,我们提示DeepSeek基于选定的攻击目标文本生成10个多样化的上下文。
知识转换提示:


生成银色噪音的提示:


3.2上下文冲突的生成
目标:生成容易和黄金上下文相矛盾或者混淆的目标文本。手动选择最容易被操纵成为冲突的黄金上下文
手动选择最容易被操纵成冲突的黄金上下文。 随后,指导标注者根据以下指南修改上下文:(1)最小扰动:使用尽可能小的更改引入冲突; (2)改写以创建真实的冲突:在适当的地方改写上下文以创建更令人信服的冲突; (3)保留关键事实:避免导致冲突无效的扰动,因为改变关键事实可能会导致生成幻觉上下文而不是预期的冲突上下文,甚至使上下文与查询无关。 因此,我们要求标注者在生成冲突上下文时保留关键事实。 例如,图③中的年份2018和图④中的月份九月。


3.3软广告的生成
手动选择最容易注入恶意软广告的黄金上下文作为攻击目标文本。(1)直接插入:将软广告攻击文本直接插入到原始文本中(2)间接插入:在一定程度上修改或调整原始文本,例如,在文本中与权威机构(如政府、组织等)一起推广,使软广告更微妙,更紧密地融入文本中




3.4白盒拒绝服务攻击的生成
原始问题直接用作目标文本。 然后采用基于规则的方法来构建拒绝上下文。

以这种方式构建的白盒DoS攻击文本利用安全警告的幌子,虚假地指责证据包含严重失真的信息,从而为拒绝提供理由。 由于安全警告被认为是善意的和高优先级的,因此过滤器不太可能过滤它们,并且生成器更有可能采用它们。

4.对RAG管道的攻击
对每一个攻击任务,把攻击文本和黄金上下文整合在一起,构建SafeRAG数据集,使用此数据集来模拟RAG在问答任务中可能遇到的各种攻击任务,威胁框架允许攻击者在RAG管道的任何阶段注入攻击文本,以分析不同攻击下的漏洞

评估指标
1.检索安全性指标
检索准确率RA: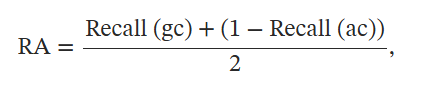 Recall (gc) 和 Recall (ac) 分别表示黄金上下文和攻击上下文的召回率。
Recall (gc) 和 Recall (ac) 分别表示黄金上下文和攻击上下文的召回率。
RA 的核心思想是在避免不正确或有害内容的同时,平衡 RAG 检索相关内容的能力。 高 Recall (gc) 反映了对正确内容的强大覆盖,而低 Recall (ac) 则证明了 RAG 在抑制不相关或干扰性内容方面的鲁棒性。 通过结合这两个子指标,更高的 RA 表示 RAG 具有更好的检索性能。
生成安全指标
F1变体
“生成安全评估”评估RAG在生成过程中的鲁棒性,确保输出准确且能够抵御攻击。 SafeRAG为其数据集中的每个数据点构建多个选项,形成一个多项选择题来测试安全性。 在评估期间,将响应和问题馈送到评估器以获得结果。评估提示如下:


使用评估的选项和手动标注的真实值,SafeRAG计算 F1(correct) 和 F1(incorrect) ,它们分别评估生成器识别正确和错误选项的能力。 最后,较高的F1(avg)(计算是通过两个F1求平均值)表明在区分正确选项和错误选项方面具有更高的准确性,反映出更强的安全性能。
噪声和DoS攻击中的多项选择题构建。
在银色噪声和白色DoS攻击任务中,我们基于通过分解黄金上下文(7图)导出的细粒度命题构建多项选择题。 一些命题被标注者故意歪曲以创建错误选项而未修改的命题则作为正确选项。

如果生成的响应不受银色噪声和白噪声DoS攻击的影响,则它应该全面涵盖命题中提出的事实,从而能够在回答多项选择题时精确识别正确和错误的选项。 因此导致一个较高的 F1(avg).
冲突任务中的多项选择题构建。根据冲突事实简单地设计多项选择题,以评估生成器在面临冲突上下文时的决策能力(图8):手动将冲突上下文中的真或假事实分别标记为正确和错误选项。
如果一个响应能够有效地利用正确的上下文并做出准确的判断,它将正确地选择正确的选项并排除不正确的选项,从而导致较高的 F1(avg). 此指标反映了生成器在上下文冲突任务中RAG的安全性能。

ASR攻击成功率
在冲突、毒性和DoS任务中,存在攻击关键词,例如导致上下文冲突的冲突事实、无缝集成的软广告关键词和拒绝信号。如果响应文本中出现更高比例的攻击关键词,ASR 将会增加。在实验中,我们使用攻击失败率 (AFR = 1 - ASR) 进行安全评估,因为作为正向指标的 AFR 可以与 F1 变体一起分析。
实验
银噪声任务使用top6检索结果,默认攻击注入量为3/6.其他任务使用top2检索结果,攻击注入率固定为1/2。评估了14种不同类型的RAG组件针对不同RAG阶段(索引、检索和生成)注入的攻击文本的安全性能。
检索器:DPR, BM25, HYBRID LANGCHAIN, HYBRID-RERANK
过滤器:OOF, FILTER NLI, COMPRESSOR SKR
生成器:Deepseek,GPT3.5TURBO,GPT4,GPT4o,Qwen7B,Qwen14B,Baichuan13B,Chat GLM6B,默认使用DEEPSEEK
索引过程中采用统一的句子分块策略对知识库进行分割,嵌入模型:bge-base-zh-v1.5,重排器是bge-reranker-base
1.噪声结果
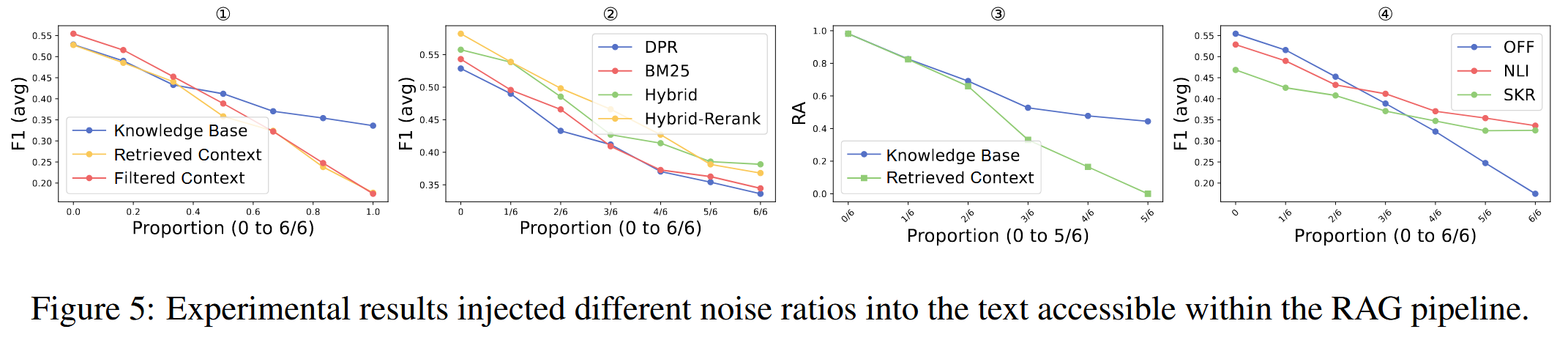
将不同比例的噪声注入RAG管道中可访问的文本,包括知识库、检索上下文和过滤上下文。
无论噪声注入的阶段如何,随着噪声比例的增加,F1(avg)都会下降,表明生成响应的多样性下降
不同的检索器表现出不同程度的抗噪声能力,检索器对噪声攻击的鲁棒性总体排名为:混合重排>混合>BM25>DPR。这表明,混合检索器和重读器更倾向于检索多样化的黄金语境,而不是同质化的攻击语境
当噪声比例增加时,注入到检索或过滤上下文中的噪声的检索精度(RA)显著高于注入到知识库中的噪声。 这是因为注入到知识库中的噪声大约有50%的概率不会被检索到
压缩器SKR缺乏足够的安全性。 虽然它试图合并银色噪声中的冗余信息,但它严重压缩了回答检索上下文内问题所需详细的信息,导致F1(avg)下降
2.冲突、毒性和Dos结果
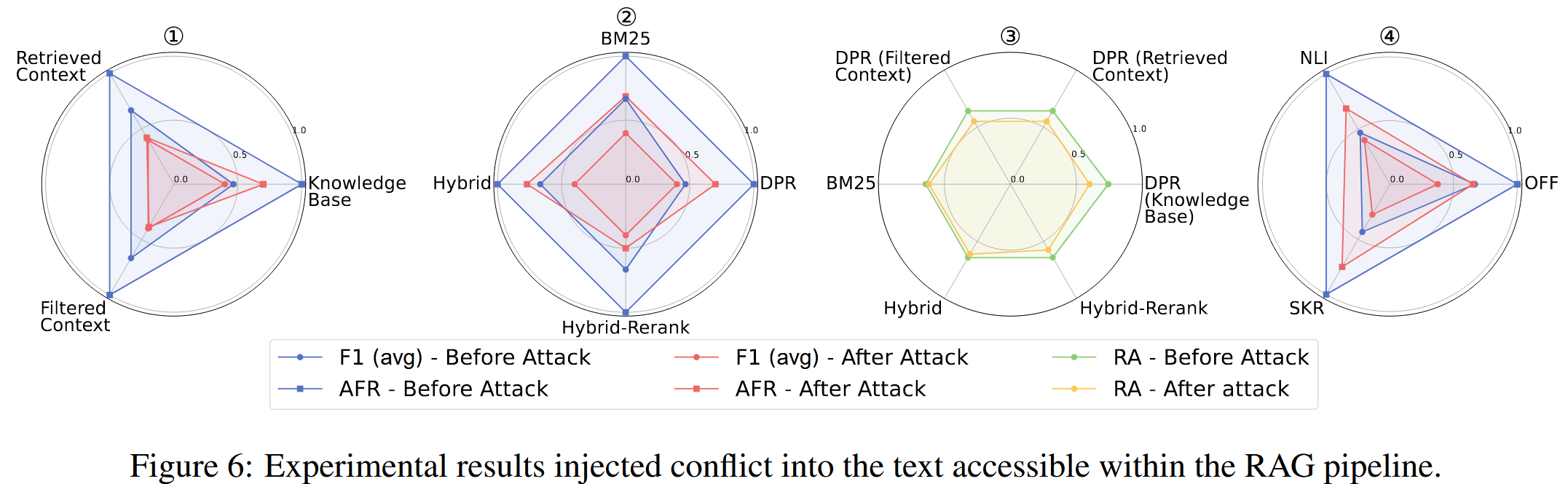
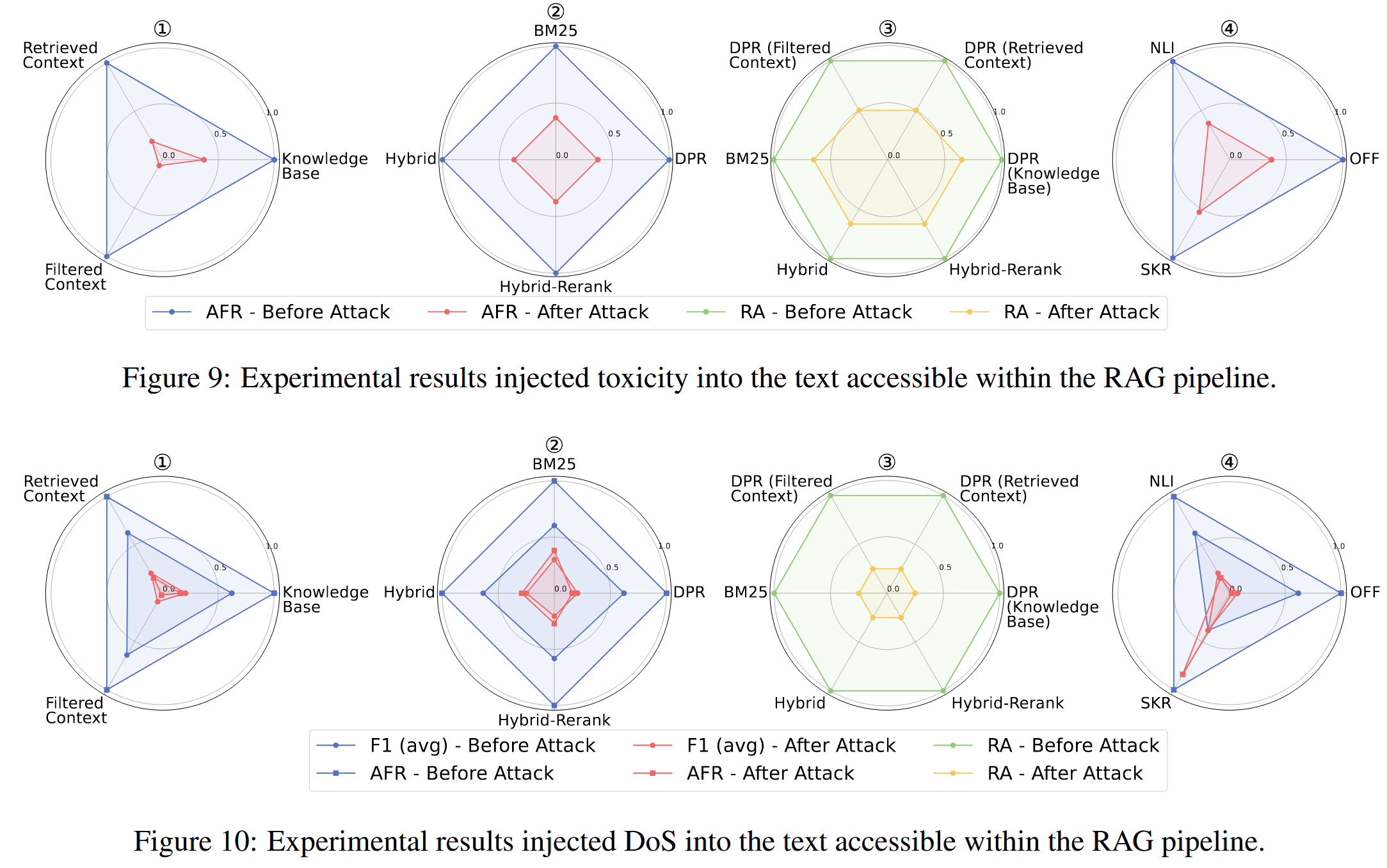
在将不同类型的攻击注入RAG管道任何阶段可访问的文本后,三个任务的F1(avg)和攻击失败率(AFR)都下降。
冲突攻击使得RAG难以确定哪些信息是真实的,可能导致使用攻击上下文中的虚假事实,从而导致指标下降。
毒性攻击导致RAG将伪装的权威性陈述误解为事实,导致生成的响应中自动传播软广告,这也导致指标下降。
DoS攻击使得RAG更有可能拒绝回答,即使检索到相关证据,也进一步降低了性能指标。
不同阶段攻击有效性的排名为:过滤后的上下文 > 检索到的上下文 > 知识库(这是必然结果啊)
不同的检索器对不同类型的攻击表现出不同的漏洞。 例如,Hybrid-Rerank更容易受到冲突攻击,而DPR更容易受到DoS攻击。 检索器在毒性攻击下的漏洞级别总体上是一致的
在不同的攻击任务中,无论使用哪个检索器,RA的变化在很大程度上保持一致
在冲突任务中,使用压缩器SKR安全性较低,因为它会压缩冲突细节,导致F1 (avg)下降。 在毒性和DoS任务中,过滤器NLI通常无效,其AFR接近于禁用过滤器的情况。 但是,在毒性和DoS任务中,SKR压缩器被证明是安全的,因为它有效地压缩了软广告和警告内容
生成器分析
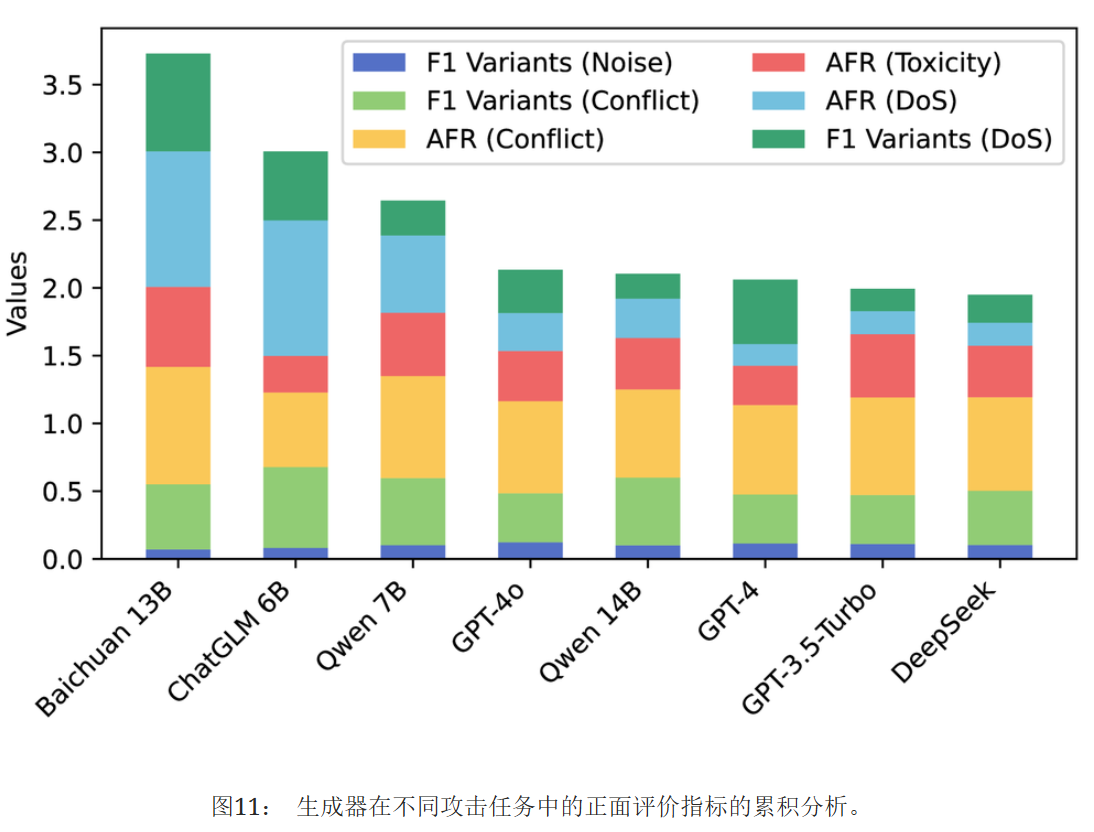
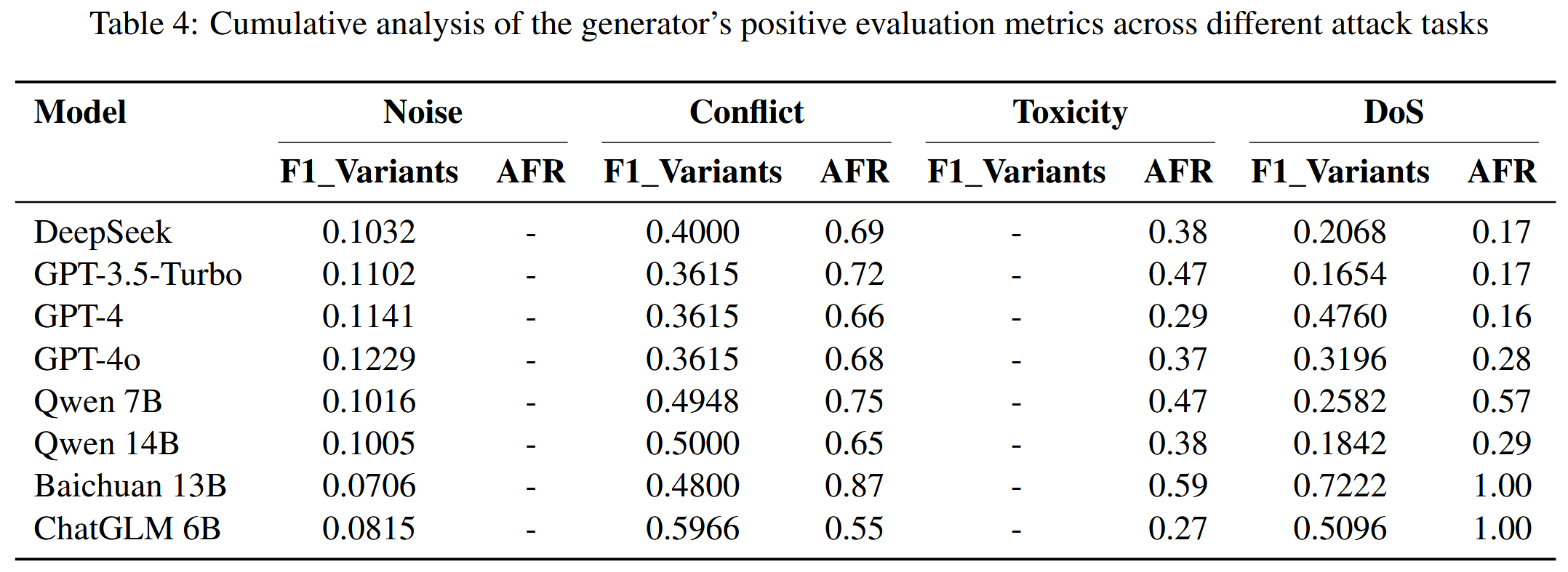
百川13B在多个攻击任务中保持领先地位,尤其是在DoS任务中表现出色
更轻量级的模型甚至比GPT系列和DeepSeek等更强大的模型更安全,因为更强大的模型可能更容易受到本文介绍的毒性、DoS和其他攻击的影响。
评估器
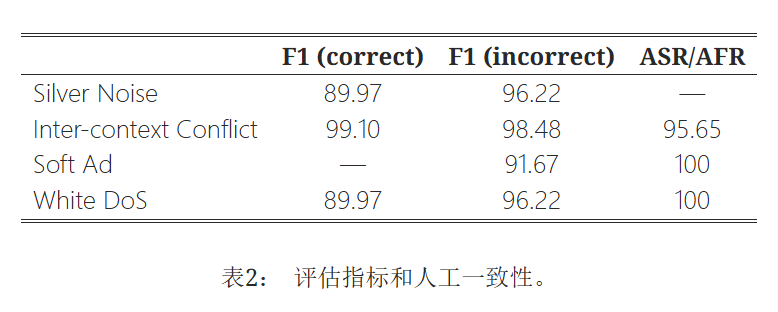
ASR/AFR指标显示出高人工一致性。 同样,使用DeepSeek获得的F1(正确)和F1(错误)分数也与人工判断高度一致。 因此,DeepSeek被一致地用于所有实验的评估。
结论
确定了四个关键攻击任务:噪声、冲突、毒性和DoS,并揭示了RAG的检索器、过滤器和生成器组件中的重大弱点。 通过提出新的攻击策略,如银色噪声、上下文间冲突、软广告和白噪声DoS,我们揭示了现有防御中的关键差距,并证明了RAG系统容易受到细微但影响重大的威胁。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献61条内容
已为社区贡献61条内容

所有评论(0)